21 век можно по праву назвать веком социальных медиа. Бесчисленное количество постов, репостов, ответов на посты и комментариев, сотни ежесекундно загружаемых видео на Ютьюб и фотографий в Инстаграмм. Если ты не в сети — ты не в тренде. Крупнейшие университеты (как, например Массачусетский Институт Технологий MIT) выкладывают онлайн лекции и учебники. Вопросы, затрагивающие самые разные темы от политики и культуры до кулинарии и особенностей выполнения той или иной асаны в йоге, теперь обсуждаются не только и не столько на кухне или в курилке, а на интернет форумах. Что лучше? Правильная ли экранизация у книги? В том ли направлении двигается сюжет полюбившегося сериала? Будет ли новая модель телефона успешней и круче, чем у конкурентов? Сегодня на эти вопросы отвечает анализ биг дата, да и системы, производящие подобные исследование на данных социальных медиа, хотя еще и не вчерашний день, но уж утро сегодняшнего точно. Одна из подобных систем создана гигантом в сфере программного обеспечения и носит гордое имя верного соратника британского детектива. Стоит отметить, что речь пойдёт лишь о системе аналитики соцмедиа (IBM Watson Analytics for Social Media), а это лишь часть знаменитой когнитивной системы Watson, и приведенные ниже плюсы и минусы касаются непосредственно данного сервиса, который для простоты упоминания в дальнейшем условимся называть просто Ватсоном.
1. Как и у многих систем анализа больших данных основная цель Ватсона — дать пользователю в простом виде (графики да картинки) представление о том, как часто и в каком ключе пишут про продукты, компании, бренды и услуги в соц медиа. Ака частота упоминания на потоке сообщений, отсортированная с учетом результатов сентимент анализа. Одна из ключевых особенностей Ватсона спряталось уже на этом этапе. Поток покупной. То есть информация собирается отдельной компанией и затем передается на анализ. И если не нашлось твита или нового комментария, и он оказался не учтен в аналитике — все вопросы к… не Ватсону. На сегодня для анализа доступен материал из Твиттера, форумов, новостей, Ютьюба (точнее всех тех комментариев, что люди оставляют на стене), публичных страниц Фэйсбука, отзывов и блогов. При этом, сообщения из указанных выше источников используются только для количественного анализа, и согласно соглашению с Твиттером компания не имеет права дать пользователю прочитать, что же пишут люди в сети и чем общественность (не)довольна. В то же время в самом Твиттере сие проделать легко и просто, достаточно ввести нужное нам слово в строку поиска…
2. Положительной стороной, напрямую зависящей от предыдущего пункта, можно считать возможность завести неограниченное количество тем. Например: Машина 1, Машина 2, Машина 3, Машина 4… Машина N… А также дополнительный бонус системе за создание отдельных топиков к теме, или по-иному, характеристик: габариты, расход топлива, особенности двигателей и прочее. Внутри каждого топика можно указать как необходимые поисковые слова или термины, которые вам важно выловить в потоке сообщений, так и минус-слова. Например, в ситуации с анализом сообщений про немецкий гипермаркет OBI (ОБИ), нужно исключить персонажа «Звездных Войн». Для создания наиболее корректного поискового запроса, в случае многозначности объекта для анализа можно воспользоваться подсказкой: в правом поле видно облако наиболее частотных слов, употребляемых с объектом. Увы, система не всегда может распознать, многозначный объект или нет, и подсказки работают только со списком заранее известных полисемичных слов.

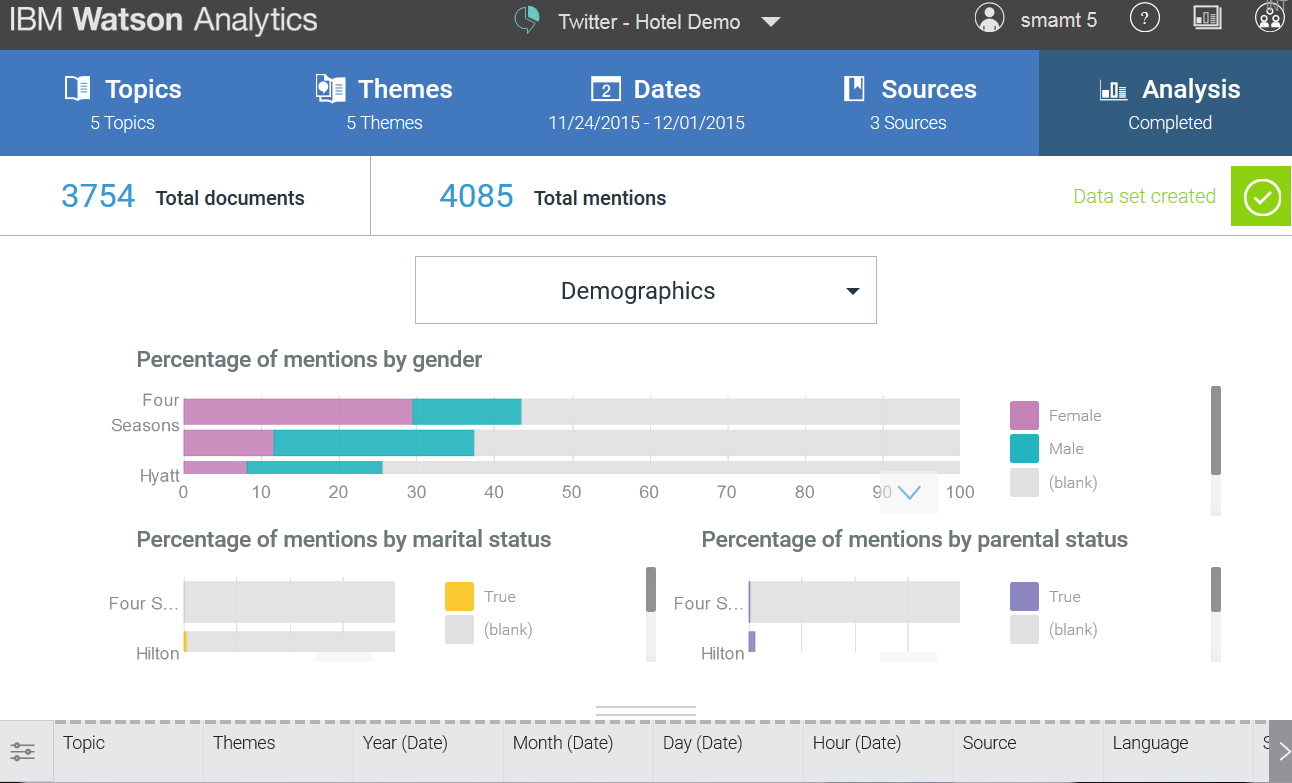
3. В этом пункте мы разбираем собственно аналитику, производимую Ватсоном. Одним из важнейших и основных пунктов анализа сообщений соцмедиа является демография. То есть распределение по полу, возрасту и гео положению. Здесь следует отметить, что данный анализ проводится благодаря лингвистике, а значит, с этим связан ряд проблем.
4. Спектр языков, которыми владеет Ватсон, достаточно широк, но, если нас интересует сентимент анализ сообщений (главный ингредиент тортика под названием Analysis of Social Media), то ситуация хуже. На добавление одного языка уходит примерно 9 месяцев. На данный момент уже весьма неплохо работают английский (кто бы сомневался), французский, немецкий, испанский, нидерландский, китайский (традиционный и упрощенный варианты), русский, а также португальский.
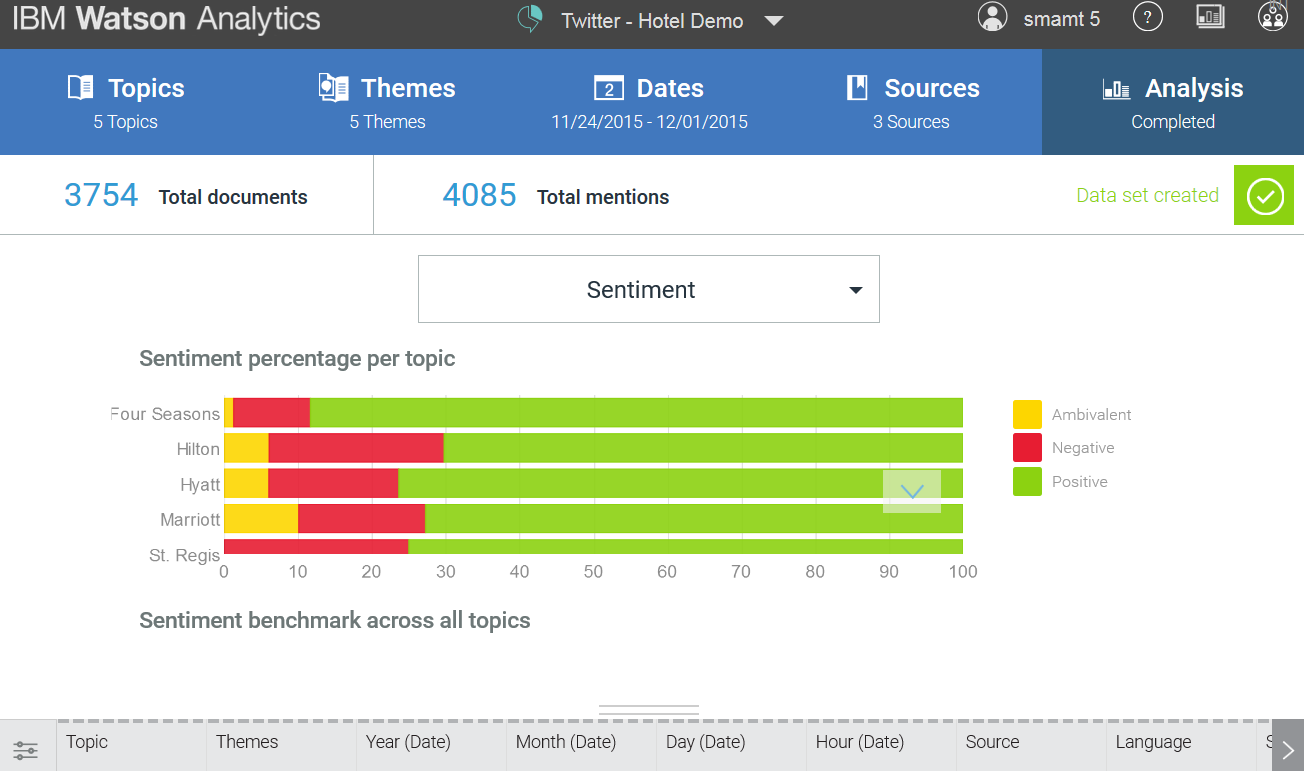
Ватсон различает следующие виды тональности: позитив, негатив и амбивалентность. Если первые два типа понятны и без объяснения, то под последним имеется в виду тот случай, когда неясно, позитивно или негативно высказывание. Пример: «У этой камеры хорошая цветопередача, но звук отстойный». Если мы берем во внимание только камеру, а не отдельные ее характеристики, то тональность становится амбивалентной. Одним из плюсов тональности Ватсона можно считать возможность собственноручно внести в «тональный словарь» те слова, что не должны обрабатываться позитивно или негативно. Пример — слоганы рекламных кампаний («Танки грязи не боятся!»). Если не добавить «в игнор» слоган — получим недостоверные данные по тональности, обилие позитива, которого на самом деле нет. Это работает только под конкретных клиентов, то есть меняет тональность только для определенного продукта, а не глобально, для всего. Один из больших минусов используемых словарей — не ведется учета силы тональности. То есть слова «плохой — ужасный — отвратительный» для Ватсона одинаково негативны. Но любой человек скажет, что это не так.
Далее, лингвистика (сентимент анализ, деление предложения на части и выше указанная демографика) работает на правилах. Для описания синтаксиса и работы тональности используется AQL (annotation query language). Посмотреть, как это работает, можно на официальном сайте IBM.
Преимущество подхода на правилах: при достаточной усидчивости можно описать 85 — 90% случаев и особенностей употребления тех или иных фраз в языке.
Недостатки: может выпасть иногда существенный пласт сообщений, что не были учтены при создании правил. И если машинный алгоритм можно достаточно просто переучить, то для прописывания новых правила (чтобы они не конфликтовали с предыдущими, чтобы приоритетность выполнения не нарушилась) требуется гораздо больше затрат. К тому же правила варьируются от языка к языку. Если для родственных языков одной группы можно использовать те же «формулировки» с небольшими корректировками, то для описания более редких языков так сделать не получится. Нет, какая-то база останется, но….
Увы, Ватсон не позволяет загружать свои сообщения, чтобы проверить работу тональности и нигде нельзя найти данных по точности работы модуля. Даже при работе с системой анализа в качестве позитивных или негативных сообщений пользователь видит не абсолютно каждое высказывание, а лишь малую часть, да и то только ту, что однозначно определилась.
Резюме
Система приятно радует глаз обилием ярких и красочных графиков и схем, а также разновидностью критериев сравнения (демография, тональность). Проста в использовании, то есть не надо быть Шерлоком, достаточно просто быть Ватсоном, чтобы с ней работать. Существенно большее количество предлагаемых языков. Но, отсутствие данных по возрасту, сомнительные данные по распределению по полу и географии, невозможность точно узнать, чем недовольны покупатели (скажем так, наиболее интересны именно амбивалентные высказывания, те самые, что можно превратить в позитив) вызывает некоторые опасения в достоверности системы. То есть, Ватсону ещё есть куда расти и развиваться, сказать, что он гораздо лучше отечественных систем анализа соцмедиа я, увы, пока не могу.
1. Как и у многих систем анализа больших данных основная цель Ватсона — дать пользователю в простом виде (графики да картинки) представление о том, как часто и в каком ключе пишут про продукты, компании, бренды и услуги в соц медиа. Ака частота упоминания на потоке сообщений, отсортированная с учетом результатов сентимент анализа. Одна из ключевых особенностей Ватсона спряталось уже на этом этапе. Поток покупной. То есть информация собирается отдельной компанией и затем передается на анализ. И если не нашлось твита или нового комментария, и он оказался не учтен в аналитике — все вопросы к… не Ватсону. На сегодня для анализа доступен материал из Твиттера, форумов, новостей, Ютьюба (точнее всех тех комментариев, что люди оставляют на стене), публичных страниц Фэйсбука, отзывов и блогов. При этом, сообщения из указанных выше источников используются только для количественного анализа, и согласно соглашению с Твиттером компания не имеет права дать пользователю прочитать, что же пишут люди в сети и чем общественность (не)довольна. В то же время в самом Твиттере сие проделать легко и просто, достаточно ввести нужное нам слово в строку поиска…
2. Положительной стороной, напрямую зависящей от предыдущего пункта, можно считать возможность завести неограниченное количество тем. Например: Машина 1, Машина 2, Машина 3, Машина 4… Машина N… А также дополнительный бонус системе за создание отдельных топиков к теме, или по-иному, характеристик: габариты, расход топлива, особенности двигателей и прочее. Внутри каждого топика можно указать как необходимые поисковые слова или термины, которые вам важно выловить в потоке сообщений, так и минус-слова. Например, в ситуации с анализом сообщений про немецкий гипермаркет OBI (ОБИ), нужно исключить персонажа «Звездных Войн». Для создания наиболее корректного поискового запроса, в случае многозначности объекта для анализа можно воспользоваться подсказкой: в правом поле видно облако наиболее частотных слов, употребляемых с объектом. Увы, система не всегда может распознать, многозначный объект или нет, и подсказки работают только со списком заранее известных полисемичных слов.

3. В этом пункте мы разбираем собственно аналитику, производимую Ватсоном. Одним из важнейших и основных пунктов анализа сообщений соцмедиа является демография. То есть распределение по полу, возрасту и гео положению. Здесь следует отметить, что данный анализ проводится благодаря лингвистике, а значит, с этим связан ряд проблем.
- Распределение по полу мужской/женский в основном идет по именам (словари), по никам (Мистер Х становится индикатором мужчины, а «Русалочка99» — женщины), а также по определенным словам, используемым в тексте сообщения «Я стала мамой» — женский пол, «я стал отцом» — мужской. Всегда ли это срабатывает правильно — вопрос отдельный. Часть ников не позволяет однозначно приписать определенный пол человеку, к тому же ироничное использование противоположного пола в комментариях никто не запрещал.
- Также есть метрика «женат/холост» — информация берется из профайла и текста сообщения. То есть, если встречается выражение «моя жена», то призывается статус «женат».
- Подобным образом работает и метрика «бездетный / с детьми». Последние две метрики на мой взгляд наиболее спорные. В Ватсон не различает прямую речь. Это значит, что сообщения типа: «Далее со слов подруги/друга… Мой муж/сын сделал то-то» будут обработаны неправильно. Информация от друга/подруги будет приписана говорящему.
- А что же с самыми важными метриками: возраст и география? А нет вот данных по возрасту. Совсем. Никаких. И география определяется по упоминанию названий городов и стран в сообщении. И сколько из нас писали, что мы в Москве или Питере, находясь в Саратове или Воронеже? Так что, без комментариев.
4. Спектр языков, которыми владеет Ватсон, достаточно широк, но, если нас интересует сентимент анализ сообщений (главный ингредиент тортика под названием Analysis of Social Media), то ситуация хуже. На добавление одного языка уходит примерно 9 месяцев. На данный момент уже весьма неплохо работают английский (кто бы сомневался), французский, немецкий, испанский, нидерландский, китайский (традиционный и упрощенный варианты), русский, а также португальский.
Ватсон различает следующие виды тональности: позитив, негатив и амбивалентность. Если первые два типа понятны и без объяснения, то под последним имеется в виду тот случай, когда неясно, позитивно или негативно высказывание. Пример: «У этой камеры хорошая цветопередача, но звук отстойный». Если мы берем во внимание только камеру, а не отдельные ее характеристики, то тональность становится амбивалентной. Одним из плюсов тональности Ватсона можно считать возможность собственноручно внести в «тональный словарь» те слова, что не должны обрабатываться позитивно или негативно. Пример — слоганы рекламных кампаний («Танки грязи не боятся!»). Если не добавить «в игнор» слоган — получим недостоверные данные по тональности, обилие позитива, которого на самом деле нет. Это работает только под конкретных клиентов, то есть меняет тональность только для определенного продукта, а не глобально, для всего. Один из больших минусов используемых словарей — не ведется учета силы тональности. То есть слова «плохой — ужасный — отвратительный» для Ватсона одинаково негативны. Но любой человек скажет, что это не так.
Далее, лингвистика (сентимент анализ, деление предложения на части и выше указанная демографика) работает на правилах. Для описания синтаксиса и работы тональности используется AQL (annotation query language). Посмотреть, как это работает, можно на официальном сайте IBM.
Преимущество подхода на правилах: при достаточной усидчивости можно описать 85 — 90% случаев и особенностей употребления тех или иных фраз в языке.
Недостатки: может выпасть иногда существенный пласт сообщений, что не были учтены при создании правил. И если машинный алгоритм можно достаточно просто переучить, то для прописывания новых правила (чтобы они не конфликтовали с предыдущими, чтобы приоритетность выполнения не нарушилась) требуется гораздо больше затрат. К тому же правила варьируются от языка к языку. Если для родственных языков одной группы можно использовать те же «формулировки» с небольшими корректировками, то для описания более редких языков так сделать не получится. Нет, какая-то база останется, но….
Увы, Ватсон не позволяет загружать свои сообщения, чтобы проверить работу тональности и нигде нельзя найти данных по точности работы модуля. Даже при работе с системой анализа в качестве позитивных или негативных сообщений пользователь видит не абсолютно каждое высказывание, а лишь малую часть, да и то только ту, что однозначно определилась.
Резюме
Система приятно радует глаз обилием ярких и красочных графиков и схем, а также разновидностью критериев сравнения (демография, тональность). Проста в использовании, то есть не надо быть Шерлоком, достаточно просто быть Ватсоном, чтобы с ней работать. Существенно большее количество предлагаемых языков. Но, отсутствие данных по возрасту, сомнительные данные по распределению по полу и географии, невозможность точно узнать, чем недовольны покупатели (скажем так, наиболее интересны именно амбивалентные высказывания, те самые, что можно превратить в позитив) вызывает некоторые опасения в достоверности системы. То есть, Ватсону ещё есть куда расти и развиваться, сказать, что он гораздо лучше отечественных систем анализа соцмедиа я, увы, пока не могу.
