
В прошлой статье я рассказал об основных понятиях SAN на примере небольших инсталляций. Сегодня копнем глубже и разберемся с построением сетей хранения для крупной организации. Разумеется, одна короткая статья никак не заменит объемные труды Brocade и HP, но хотя бы поможет сориентироваться и выбрать правильный курс при проектировании.
При построении крупных сетей хранения основной головной болью становится архитектура решения, а вовсе не типы оптики и производители коммутаторов. Узлов-потребителей значительно больше и многие из них критичны для бизнеса, поэтому использовать простую схему "подключил несколько серверов к хранилищу напрямую, да и все" не получится.
Пара слов о топологиях и надежности
Если немного упростить, то "большая" сеть SAN отличается от маленькой только надежность и, в меньшей степени, производительностью. Базовые технологии и протоколы аналогичны тем, что применяются в сетях из нескольких серверов. Как правило, отдельные сети SAN называют фабриками – в одной организации свободно может находиться с десяток фабрик.
В инфраструктуре уровня Enterprise балом по-прежнему правят протокол Fibre Channel и оптические линии. Последние годы активную экспансию ведут конвергентные решения, но о них я расскажу чуть позже.
Каскад. Самая ненадежная топология, которая иногда применяемая с небольшим количество узлов.
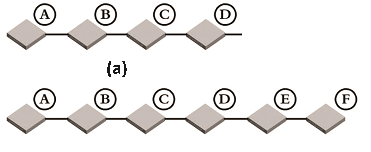
Устройства последовательно подключены друг к другу, что дает больше точек отказа и увеличение нагрузки при масштабировании. Частным случаем каскада можно назвать подключение точка-точка, когда СХД подключается напрямую к серверу.
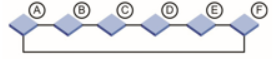
Кольцо. Тот же каскад, но оконечный коммутатор соединен с первым. Надежность и производительность больше, ведь протокол FSPF (Fabric Shortest Path First) поможет выбрать кратчайший маршрут. Однако, работоспособность такой сети часто нарушается в процессе масштабирования и не гарантируется при обрыве нескольких линков.
Полный граф (full mesh), где каждый коммутатор соединен с каждым. Такая топология обладает высокой отказоустойчивостью и производительностью, но стоимость решений и возможности масштабирования оставляют желать лучшего.
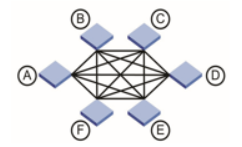
Граф удобно использовать для связи пограничных коммутаторов нескольких площадок.
- Ядро-периферия (core-edge). На практике используется чаще всего и по своей сути аналогична привычной сетевой топологии "звезда".
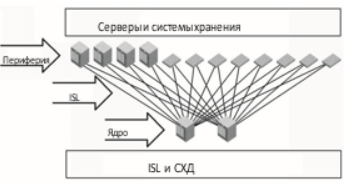
В центре размещаются несколько коммутаторов (ядро сети), к ним подключаются периферийные коммутаторы с оконечными устройствами. Решение выходит отказоустойчивым, производительным и хорошо масштабируемым.
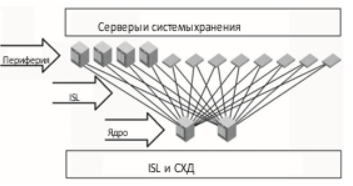
Основной схемой построения SAN в большинстве случаев является Core-Edge, с несколькими зарезервированными коммутаторами в центре. Рекомендую использовать в первую очередь ее, а всякую экзотику сохранить для нетипичных случаев. Кстати, кольцо, несмотря на свою моральную ветхость, активно используется внутри систем хранения для соединения дисков с контроллерами.
Если вам уже приходилось строить кластер какой-либо системы, то с понятием единой точки отказа уже знакомы.
Единая точка отказа – это любой компонент системы, чей выход из строя нарушает работоспособность всей системы самым радикальным образом. Таким компонентом может быть не зарезервированное сетевое соединение, единственный контроллер в системе хранения или коммутатор SAN.
Основная работа проектировщика сети хранения заключается в том, чтобы построить сеть без единой точки отказа, в которой оптимально сочетаются масштабируемость и стоимость. В качестве отправной точки выбирают построение двух независимых фабрик для подстраховки друг друга. Называется такое решение "резервированная фабрика", и все ее узлы подключаются одновременно к двум фабрикам с использованием технологии Multipath.
Если что-то случается с любым важным узлом одной из фабрик, то обмен данными происходит через ее дублера, без каких-либо негативных последствий. Разумеется, при построении нужно заложить в каждую фабрику некоторый запас производительности, как правило двукратный. Если этого не сделать, то при аварии может заметно просесть производительность любых использующих SAN сервисов.
Еще один момент, который стоит принимать в расчет, называется SAN Oversubscription.

Этот труднопереводимый термин означает конкуренцию нескольких устройств за одну линию связи. Типичная ситуация: к коммутатору подключено 10 клиентов, которые обращаются к СХД в другом сегменте через единственный линк ISL (Intersite Link, канал между коммутаторами). При таком сценарии Oversubscription будет равен 10:1. Если число линков ISL увеличить до двух, то соотношение станет 5:1.
То есть, при ситуации Oversubscription в канал пытается пролезть больше трафика, чем может осилить этот канал. Разумеется, возникают очереди на входе и падает производительность конкретных приложений. Чтобы такого не происходило, всегда оставляйте запас по пропускной способности "туннелей" между фабриками. Скорее всего, поддерживать соотношение 1:1 будет в большинстве случаев не рационально, но важно всегда контролировать этот момент при расширении сети.
Выбор оборудования для сетей FC
Как это обычно бывает, предпочтения тому или иному производителю – вопрос идеологический. Но есть несколько известных игроков на рынке SAN, чьи системы вы встретите в крупной сети с большей вероятностью:
Сетевые адаптеры QLoqic, коммутаторы и маршрутизаторы SAN от Brocade, HP и Cisco.
- Системы хранения HP, NetApp, IBM. Разумеется, список не полный.
Несмотря на то, что сервисы FC могут похвастаться высокой стандартизацией и долгой историей, по-прежнему действует золотое правило проектировщика: строй сеть на оборудовании одного производителя. То есть, все, что обеспечивает связь клиента и хранилища, стоит приобрести у одного производителя. Так вы избежите проблем совместимости и разнообразных "плавающих глюков".
Если по каким-то причинам золотое правило в вашей ситуации не применимо, то обязательно сверяйтесь с таблицами совместимости от производителей оборудования:
Лично я только два раза сталкивался с проблемами совместимости, но каждый раз это было довольно неприятно. По одному из случаев не вспомню уже конкретных участников, но у FC-адаптера стоечного сервера периодически и без всякой причины пропадали оба оптических линка (основной и резервный), приходилось вручную переподключать. Решилось, по-моему, установкой других трансиверов. А проблемные трансиверы спокойно работали в другой сети одного из филиалов компании.
О расстоянии
Если вы работаете на заводе или просто в большом офисном центре, то актуальным становится вопрос территориально-распределенных сетей. Банальные несколько этажей в здании могут вылиться в несколько сотен метров оптоволокна и придется учитывать технологические особенности:
Нужно выбирать правильные трансиверы для одномодового волокна, так как именно оно подходит для использования на больших расстояниях.
Если речь идет о протягивании оптики между зданиями (по столбам), то значительно дешевле может оказаться сеть FCoE на базе обычного Ethernet по витой паре.
- Длинные сегменты "темной оптики" (линк между двумя клиентами, в котором нет активных сетевых устройств) можно разделять на короткие с помощью тех же коммутаторов. Кстати, это популярный вариант для построения оптической сети в здании: по паре коммутаторов на каждом этаже.
Исходя из практики, я бы рекомендовал использовать для распределенных сегментов FCoE или даже обычную TCP/IP сеть. Отказоустойчивость и синхронизацию в таком случае можно выполнять на уровне конкретных приложений.

Яркий пример – MS SQL. Совсем необязательно строить 8 Гб оптическую сеть между строениями в промзоне, чтобы обеспечить доступ всех клиентов к единой базе. Достаточно организовать подключение на уровне терминального сервера или клиентской части приложения, которое использует MS SQL (1С, например). Не всегда нужно решать вопрос "в лоб" и проектировать сложную и дорогую сеть хранения.
Гиперконвергенция, перезагрузка
Лет 5 назад на многих технологических конференциях активно продвигалась идея конвергентной инфраструктуры. Ее преподносили как невероятное новшество и технологию построения ЦОД будущего, не объясняя толком, в чем суть. А суть очень простая – универсальный транспорт как для сетей хранения, так и для обычных LAN. То есть, нужно проложить только 1 высокопроизводительную сеть, которую можно использовать как для работа с хранилищами, так и для доступа пользователей к 1С.
Но дьявол, как всегда, кроется в деталях. Чтобы все так и работало, потребуется специальное сетевое оборудование и конвергентные адаптеры у каждого клиента. Разумеется, эти новшества стоят довольно дорого и в простые рабочие станции их ставить не целесообразно. Поэтому идея немного трансформировалась и теперь применяется только в рамках дата-центра.
Вообще, конвергентность как идея появилась значительно раньше, еще в Infiniband. Это высокоскоростная (до 300 Гбит) шина обмена данными с низкой латентностью. Разумеется, решение на базе Infiniband стоит значительно дороже того же FC и применяется только в действительно высокопроизводительных кластерах.
Ключевыми особенностями Infiniband являются поддержка прямого доступа к памяти другого устройства (RDMA) и TCP\IP, что позволяет использовать эти сети как для SAN, так и для LAN.

Конвергентные сети часто используются в блейд-системах, так как отлично вписываются в идею набора серверов с общими ресурсами и минимумом внешних подключений. Но сейчас в моде уже гиперконвергентные системы, где к общей идеи виртуализации сетей добавляется модульность и более гибкое масштабирование _ каждый узел в таких решениях является программно-определяемым. В качестве яркого примера можно упомянуть Cisco ASAv и модуль OpenStack Neutron.
Если в конвергентных решениях привычные дисковые массивы еще могут использоваться, то в гиперконвергентных системах их роль определяется программно для каждого конкретного модуля. Если у вас нет каких-то особенных требований к системе хранения, вроде поддержки специфической репликации, то я бы рекомендовал присмотреться к SDS-решениям (Software-Defined Storage).
Фактически, это просто сервер с набором дисков и специальным ПО. Яркие примеры: vSAN от VMware и Storage Spaces от Microsoft. В качестве аппаратной составляющей можно использовать нечто подобное с дисковой DAS-полкой. Главное, чтобы была большая дисковая корзина и достаточный объем оперативной памяти.
У SDS часто встречается интересная технология Cache Tiering. Два и более диска разных скоростей объединяются в один дисковый пул, часто используемые данные с которого хранятся на отдельных SSD-дисках. Подобный гибрид позволяет за минимум денег получить производительность уровня all-flash массивов, хотя и с некоторыми оговорками.
Итого
Время "чистой классики" постепенно уходит, и разрыв между классическими СХД и решениями SDS сокращается. Например, если судить по некоторым тестам, хранилище VMware vSAN отстает от обыкновенных классических массивов того же уровня менее чем на 10%.
Традиционно, вот небольшой список ресурсов, которые когда-то очень помогли мне в изучении технологий SAN и SDS:
