Здравствуйте, уважаемые читатели,
в этом посте мы расскажем о своем поиске идеального сетевого решения для облачной инфраструктуры и о том, почему мы решили остановиться на OpenFlow.

Понятие облака неразрывно связано с двумя абстракциями — гарантированное качество ресурсов и их взаимная изоляция. Рассмотрим, как эти понятия применяются к устройству сети в облачном решении. Изолированность ресурсов подразумевает следующее:
Гарантированное качество ресурсов — это QoS в общем понимании, то есть обеспечение требуемой полосы и требуемого отклика внутри сети облака. Далее — подробный разбор реализации упомянутых концепций в облачных инфраструктурах.
Оптимизация маршрутов таким образом, чтобы использовать возможности сетевых линков по-максимуму (иначе говоря, нахождение максимума cуммы min-cut [4] для всех пар взаимодействующих конечных точек с учетом их весов, то есть приоритетов QoS), считается наиболее сложной задачей в распределенных сетях. IGP, призванные решать эту проблему, в общем случае являются недостаточно гибкими — трафик может быть отсортирован только на основании заранее выделенных меток QoS и о динамическом анализе и перераспределении трафика приходится не думать. Для OpenFlow, поскольку средства анализа отдельных элементов трафика являются неотъемлемой частью протокола, решить эту задачу достаточно несложно — достаточно построить корректно работающий классификатор отдельных потоков [5, 6]. Еще один несомненный плюс OpenFlow в этом случае — в централизованном подсчете стратегии форвардинга возможно учесть множество дополнительных параметров, которые просто не включены ни в один из стандартов IGP.
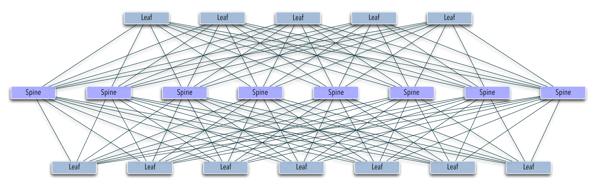
Проектирование сети даже небольшого датацентра с гетерогенным наполнением (содержание одновременно множества розничных пользоватей без физической привязки группы машин к стойке), приводит к задаче построения распределенных L2-over-L3 сетей (overlay networks) [7] с помощью одного из существующих механизмов, из-за невозможности технически поместить десятки тысяч виртуальных хостов в один широковещательный сегмент обычными способами. Указанные технологии позволяют «разгрузить» логику форвардинга, поскольку оборудование теперь оперирует метками, соответствующим группам хостов вместо отдельных адресов в приватных (и, возможно, публичных) сегментах пользовательских сетей. За дешевизной и сравнительной простотой внедрения кроется привязка как минимум к производителю сетевого оборудования и конечная недетерминированность — если отвлечься от детализации, все оверлейные протоколы предоставляют обучаемый свич внутри отдельной метки, что может вызвать затруднения при оптимизации трафика внутри оверлейного сегмента, из-за «развязанности» протоколов маршрутизации третьего уровня и механизмов самого оверлея. Выбирая OpenFlow, мы сводим все управление трафиком к одному уровню принятия решений — сетевому контроллеру. Оверлеи или замещающий их собственный механизм, безусловно, могут выполнять ту же роль по уменьшению объема правил в свичах-аггрегаторах (spine на картинке ниже), а оптимизация направления трафика на ToR свичах (leaf) будет происходить, базируясь на произвольном наборе метрик, в отличие от простой балансировки (как, к примеру, в ECMP).
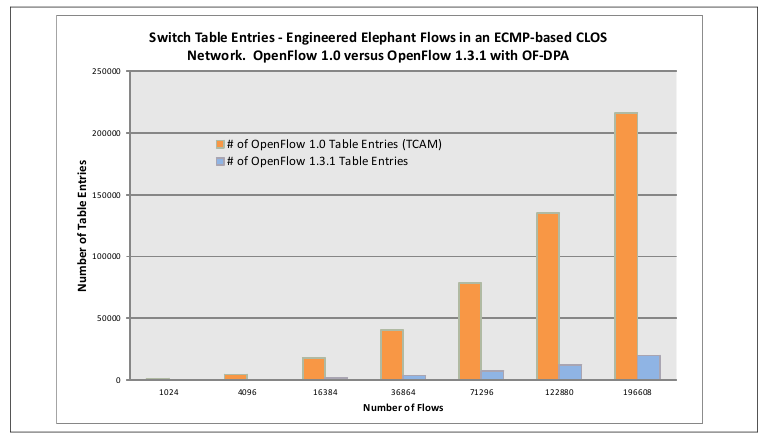
Стандарт OpenFlow в первом промышленно доступном варианте, 1.0, стал доступен в составе железных свичей более года назад, но эта версия имела несколько архитектурных ограничений, препятствовавших массовому внедрению, и наиболее проблемное из них — отсутствие множественных последовательных таблиц для обработки, то есть одно правило соответствовало ровно одной паре взаимодействовавших конечных точек, без учета дополнительных совпадений [8]. Использование OpenFlow 1.0 проактивным образом (то есть с созданием всех необходимых правил заранее) вело бы к квадратичному росту числа правил от числа взаимодействующих хостов, как представлено на на картинке ниже.
Частичным выходом из ситуации является использование механизма learning switch — то есть реактивной работы OpenFlow свича, когда правила запрашиваются каждый раз, когда они не совпадают ни с одним, уже помещенным в таблицу форвардинга свича, а через определенный TTL — удаляются из свича. Стратегия удаления может быть как «жесткой» — удаление через заданный промежуток времени после установки правила, так и «мягкой» — удаление происходит только в отсутствие активности за заданный промежуток времени «внутри» конкретного потока. На момент начала использования нами OF ни один из открытых программных контроллеров не поддерживал новые версии, упомянутая выше погоня за гибкостью подхода управления остановилась именно на стандарте 1.0. Модель learning switch оправдывает себя на значительном количестве нагрузок, непредолимым препятствием для нее становятся лишь приложения наподобие счетчиков, генерирующие сотни и тысячи уникальных запросов в секунду на уровне свича, также она подвержена атаке быстрого спуфинга — клиент, генерирующий пакеты с уникальными IP/MAC идентификаторами, как минимум, способен привести в нерабочее состояние свич уровня вычислительной ноды, а если заранее не позаботиться об ограничении PACKET_IN (сообщений на обработку потока для контроллера), то и целый сегмент сети.
После того, как все элементы нашей сети (базирующейся на OpenVSwitch), получили обновление, достаточное для использования стандарта 1.3, мы незамедлительно перешли на него, разгрузив контроллеры и обеспечив прирост производительности форвардинга (на пересчет по усредненному pps) на полтора-два порядка, за счет перехода на проактивные флоу для подавляющего объема трафика. Необходимость распределенного анализа трафика (без прокачивания всего объема через выделенные ноды-классификаторы с классическим фаерволом) оставляет место для реактивных флоу — ими мы анализируем необычный трафик.
Поддержка современных стандартов OpenFlow производителями доступного сетевого оборудования ToR в формате whitebox [9] на сегодняшний день ограничивается решениями на базе Windriver (Intel), Cumulus (Dell) и Debian в свичах Pica8, все прочие вендоры либо предоставляют свичи более высокой ценовой категории, либо злоупотребляют собственными несовместимыми расширениями/механизмами. По историческим обстоятельствам нами используется Pica8 в качестве ToR свичей, но политика производителя, переведшего GPL-дистрибутив на платную подписку, весьма ограничивает область потенциального взаимодействия. Сегодня открытые платформы Intel ONS или Dell (базирующийся на Trident II), при весьма скромной цене (<10K$ за 4*40G+48*10G), позволяют управлять трафиком нескольких десятков тысяч виртуальных машин в масштабе одной промышленной стойки с 1-6 Тб памяти, используя OpenFlow (1.3+).
Оглядываясь назад, отмечу дополнительные плюсы подобной разработки — погружение в проблематику программно-определяемых подсетей и расширение собственной экосистемы. Использование OpenFlow для управления трафиком и программного хранилища Ceph для обеспечения высокой доступности данных, позволяет заявить о себе, как о реализации software-defined datacenter, хотя впереди еще много работы на пути к идеалу.
Спасибо за внимание!
[1]. libvirt — nwfilter
[2]. NICE
[3]. OpenStack Neutron
[4]. Max-flow/Min-cut
[5]. B4 — WAN сеть гугля на OpenFlow
[6]. Подробный разбор одного из алгоритмов QoS-ориентированного TE
[7]. Хорошая статья про overlay networks
[8]. OF: 1.0 vs 1.3 table match
[9]. Why whitebox switches are good for you
в этом посте мы расскажем о своем поиске идеального сетевого решения для облачной инфраструктуры и о том, почему мы решили остановиться на OpenFlow.

Введение
Понятие облака неразрывно связано с двумя абстракциями — гарантированное качество ресурсов и их взаимная изоляция. Рассмотрим, как эти понятия применяются к устройству сети в облачном решении. Изолированность ресурсов подразумевает следующее:
- антиспуфинг,
- выделение приватного сегмента сети,
- фильтрация публичного сегмента для минимизации воздействий извне.
Гарантированное качество ресурсов — это QoS в общем понимании, то есть обеспечение требуемой полосы и требуемого отклика внутри сети облака. Далее — подробный разбор реализации упомянутых концепций в облачных инфраструктурах.
Изоляция трафика
- Антиспуфинг с помощью iptables/ebtables или статических правил в OpenVSwitch: максимально дешевое решение, но на практике неудобно — если для linux bridge правила создаются с помощью механизма nwfilter в libvirt и автоматически подтягиваются при запуске виртуальной машины, для ovs оркестровке придется отслеживать момент старта и проверять или обновлять соответствующие правила в свиче. Добавление или удаление адреса или миграция виртуальной машины превращаются в обоих случаях в нетривиальную задачу, перекладываемую на логику оркестровки. В момент запуска нашего сервиса в публичное использование мы применяли именно nwfilter [1], но были вынуждены перейти на OpenFlow 1.0 из-за недостаточной гибкости решения в целом. Также стоит упомянуть довольно экзотический метод фильтрации исходящего трафика с помощью netlink для технологий, работающих в обход сетевого стека хоста (macvtap/vf), который в свое время не был принят в ядро, несмотря на высокую коммерческую востребованность.
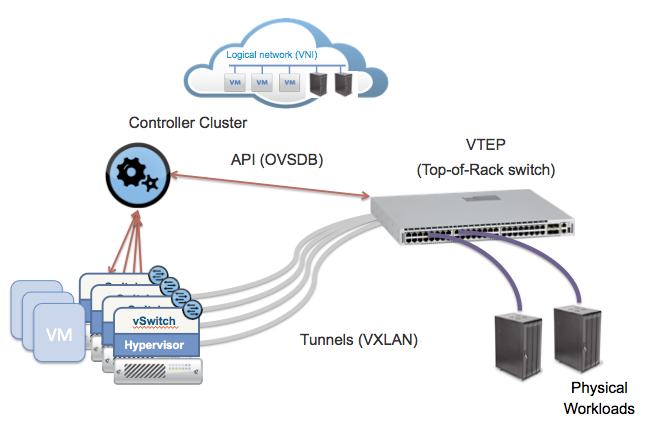
- Антиспуфинг с помощью правил в свиче уровня стойки (ToR switch) при переносе в него портов виртуальных машин с помощью одного из механизмов туннелирования трафика непосредственно от интерфейсов виртуальных машин (см. картинку ниже). В качестве плюсов такого решения можно отметить сосредоточение логики на свиче == отсутствие необходимости ее «размазывания» по программным свичам вычислительных нод. Маршрут трафика между машинами одной вычислительной ноды всегда будет проходить через свич, что может быть не всегда удобно.
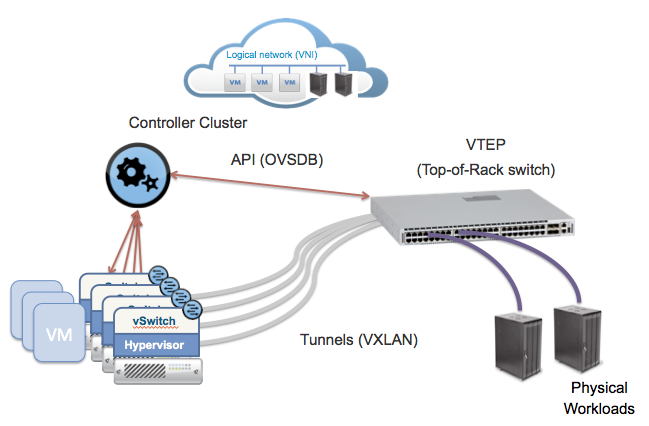
ToR filtering © networkheresy
- Антиспуфинг при проверке полей в OpenFlow сети — когда все свичи, физические и виртуальные, подключены к группе контроллеров, обеспечивающих, помимо перенаправления и трансформации полей трафика повсюду, его очистку на уровне программного свича вычислительной (compute) ноды. Это самый сложный и самый гибкий из возможных вариантов, поскольку абсолютно вся логика, начиная от пересылки датаграмм внутри обычного свича, будет вынесена в контроллер. Неполные или неконсистентные правила могут привести либо к нарушению связности, либо к нарушению изоляции, поэтому системы с большим процентом реактивных (задающихся динамически по запросу от свича) правил следует тестировать с помощью, фреймворков наподобие NICE [2].
- Выделение сегмента сети — решение, практикуемых в крупных гомогенных структурах, при этом за группой виртуальных машин закрепляется либо привязка к физическим машинам (и портам физического свича), либо к тегу инкапсуляции любого типа (vlan/vxlan/gre). Граница фильтрации находится на стыке L2 сегмента, иначе говоря, сегменту выделяется подсеть или набор подсетей и невозможность их подмены обуславливается роутингом в вышестоящей инфраструктуре, пример — OpenStack Neutron без гибридного драйвера Nova [3]. Глубокого теоретического интереса этот подход не представляет, но имеет широкую практическую распространенность, унаследованную от до-виртуализационной эпохи.
Управление трафиком
Оптимизация маршрутов таким образом, чтобы использовать возможности сетевых линков по-максимуму (иначе говоря, нахождение максимума cуммы min-cut [4] для всех пар взаимодействующих конечных точек с учетом их весов, то есть приоритетов QoS), считается наиболее сложной задачей в распределенных сетях. IGP, призванные решать эту проблему, в общем случае являются недостаточно гибкими — трафик может быть отсортирован только на основании заранее выделенных меток QoS и о динамическом анализе и перераспределении трафика приходится не думать. Для OpenFlow, поскольку средства анализа отдельных элементов трафика являются неотъемлемой частью протокола, решить эту задачу достаточно несложно — достаточно построить корректно работающий классификатор отдельных потоков [5, 6]. Еще один несомненный плюс OpenFlow в этом случае — в централизованном подсчете стратегии форвардинга возможно учесть множество дополнительных параметров, которые просто не включены ни в один из стандартов IGP.
Проектирование сети даже небольшого датацентра с гетерогенным наполнением (содержание одновременно множества розничных пользоватей без физической привязки группы машин к стойке), приводит к задаче построения распределенных L2-over-L3 сетей (overlay networks) [7] с помощью одного из существующих механизмов, из-за невозможности технически поместить десятки тысяч виртуальных хостов в один широковещательный сегмент обычными способами. Указанные технологии позволяют «разгрузить» логику форвардинга, поскольку оборудование теперь оперирует метками, соответствующим группам хостов вместо отдельных адресов в приватных (и, возможно, публичных) сегментах пользовательских сетей. За дешевизной и сравнительной простотой внедрения кроется привязка как минимум к производителю сетевого оборудования и конечная недетерминированность — если отвлечься от детализации, все оверлейные протоколы предоставляют обучаемый свич внутри отдельной метки, что может вызвать затруднения при оптимизации трафика внутри оверлейного сегмента, из-за «развязанности» протоколов маршрутизации третьего уровня и механизмов самого оверлея. Выбирая OpenFlow, мы сводим все управление трафиком к одному уровню принятия решений — сетевому контроллеру. Оверлеи или замещающий их собственный механизм, безусловно, могут выполнять ту же роль по уменьшению объема правил в свичах-аггрегаторах (spine на картинке ниже), а оптимизация направления трафика на ToR свичах (leaf) будет происходить, базируясь на произвольном наборе метрик, в отличие от простой балансировки (как, к примеру, в ECMP).
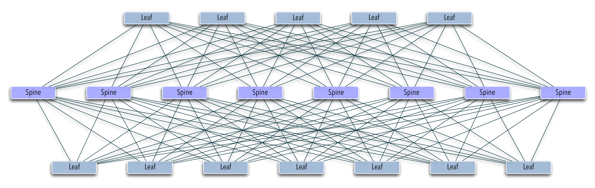
Двухуровневый spine-leaf
OpenFlow
Стандарт OpenFlow в первом промышленно доступном варианте, 1.0, стал доступен в составе железных свичей более года назад, но эта версия имела несколько архитектурных ограничений, препятствовавших массовому внедрению, и наиболее проблемное из них — отсутствие множественных последовательных таблиц для обработки, то есть одно правило соответствовало ровно одной паре взаимодействовавших конечных точек, без учета дополнительных совпадений [8]. Использование OpenFlow 1.0 проактивным образом (то есть с созданием всех необходимых правил заранее) вело бы к квадратичному росту числа правил от числа взаимодействующих хостов, как представлено на на картинке ниже.

Сравнение OF 1.0 и 1.3 © Broadcom Corp
Частичным выходом из ситуации является использование механизма learning switch — то есть реактивной работы OpenFlow свича, когда правила запрашиваются каждый раз, когда они не совпадают ни с одним, уже помещенным в таблицу форвардинга свича, а через определенный TTL — удаляются из свича. Стратегия удаления может быть как «жесткой» — удаление через заданный промежуток времени после установки правила, так и «мягкой» — удаление происходит только в отсутствие активности за заданный промежуток времени «внутри» конкретного потока. На момент начала использования нами OF ни один из открытых программных контроллеров не поддерживал новые версии, упомянутая выше погоня за гибкостью подхода управления остановилась именно на стандарте 1.0. Модель learning switch оправдывает себя на значительном количестве нагрузок, непредолимым препятствием для нее становятся лишь приложения наподобие счетчиков, генерирующие сотни и тысячи уникальных запросов в секунду на уровне свича, также она подвержена атаке быстрого спуфинга — клиент, генерирующий пакеты с уникальными IP/MAC идентификаторами, как минимум, способен привести в нерабочее состояние свич уровня вычислительной ноды, а если заранее не позаботиться об ограничении PACKET_IN (сообщений на обработку потока для контроллера), то и целый сегмент сети.
После того, как все элементы нашей сети (базирующейся на OpenVSwitch), получили обновление, достаточное для использования стандарта 1.3, мы незамедлительно перешли на него, разгрузив контроллеры и обеспечив прирост производительности форвардинга (на пересчет по усредненному pps) на полтора-два порядка, за счет перехода на проактивные флоу для подавляющего объема трафика. Необходимость распределенного анализа трафика (без прокачивания всего объема через выделенные ноды-классификаторы с классическим фаерволом) оставляет место для реактивных флоу — ими мы анализируем необычный трафик.
О настоящем
Поддержка современных стандартов OpenFlow производителями доступного сетевого оборудования ToR в формате whitebox [9] на сегодняшний день ограничивается решениями на базе Windriver (Intel), Cumulus (Dell) и Debian в свичах Pica8, все прочие вендоры либо предоставляют свичи более высокой ценовой категории, либо злоупотребляют собственными несовместимыми расширениями/механизмами. По историческим обстоятельствам нами используется Pica8 в качестве ToR свичей, но политика производителя, переведшего GPL-дистрибутив на платную подписку, весьма ограничивает область потенциального взаимодействия. Сегодня открытые платформы Intel ONS или Dell (базирующийся на Trident II), при весьма скромной цене (<10K$ за 4*40G+48*10G), позволяют управлять трафиком нескольких десятков тысяч виртуальных машин в масштабе одной промышленной стойки с 1-6 Тб памяти, используя OpenFlow (1.3+).
Оглядываясь назад, отмечу дополнительные плюсы подобной разработки — погружение в проблематику программно-определяемых подсетей и расширение собственной экосистемы. Использование OpenFlow для управления трафиком и программного хранилища Ceph для обеспечения высокой доступности данных, позволяет заявить о себе, как о реализации software-defined datacenter, хотя впереди еще много работы на пути к идеалу.
Спасибо за внимание!
Ссылки
[1]. libvirt — nwfilter
[2]. NICE
[3]. OpenStack Neutron
[4]. Max-flow/Min-cut
[5]. B4 — WAN сеть гугля на OpenFlow
[6]. Подробный разбор одного из алгоритмов QoS-ориентированного TE
[7]. Хорошая статья про overlay networks
[8]. OF: 1.0 vs 1.3 table match
[9]. Why whitebox switches are good for you
