 В этом посте мы рассмотрим доступ к API Spark из различных языков программирования в JVM, а также некоторые вопросы производительности при выходе за пределы языка Scala. Даже если вы работаете вне JVM, данный раздел может оказаться полезен, поскольку не-JVM-языки часто зависят от API Java, а не от API Scala.
В этом посте мы рассмотрим доступ к API Spark из различных языков программирования в JVM, а также некоторые вопросы производительности при выходе за пределы языка Scala. Даже если вы работаете вне JVM, данный раздел может оказаться полезен, поскольку не-JVM-языки часто зависят от API Java, а не от API Scala.Работа на других языках программирования далеко не всегда означает необходимость выхода за пределы JVM, и работа в JVM имеет немало преимуществ с точки зрения производительности — в основном вследствие того, что не требуется копировать данные. Хотя для обращения к Spark не из языка Scala не обязательно нужны специальные библиотеки привязки или адаптеры, вызвать код на языке Scala из других языков программирования может быть непросто. Фреймворк Spark поддерживает использование в преобразованиях лямбда-выражений языка Java 8, а у тех, кто применяет более старые версии JDK, есть возможность реализовать соответствующий интерфейс из пакета org.apache.spark.api.java.function. Даже в случаях, когда не требуется копировать данные, у работы на другом языке программирования могут быть небольшие, но важные нюансы, связанные с производительностью.
Особенно ярко сложности с обращением к различным API Scala проявляют себя при вызове функций с тегами классов или при использовании свойств, предоставляемых с помощью неявных преобразований типов (например, всей относящейся к классам Double и Tuple функциональности наборов RDD). Для механизмов, зависящих от неявных преобразований типов, часто предоставляются эквивалентные конкретные классы наряду с явными преобразованиями к ним. Функциям, зависящим от тегов классов, можно передавать фиктивные теги классов (скажем, AnyRef), причем зачастую адаптеры делают это автоматически. Применение конкретных классов вместо неявного преобразования типов обычно не приводит к дополнительным накладным расходам, но фиктивные теги классов могут накладывать ограничения на некоторые оптимизации компилятора.
API Java не слишком отличается от API Scala в смысле свойств, лишь изредка отсутствуют некоторые функциональные возможности или API разработчика. Поддержка других языков программирования JVM, например языка Clojure с DSL Flambo и библиотеки sparkling, осуществляется с помощью различных API Java вместо непосредственного вызова API Scala. Поскольку большинство привязок языков, даже таких не-JVM-языков, как Python и R, идет через API Java, то полезно будет разобраться с ним.
API Java очень напоминают API Scala, хотя и не зависят от тегов классов и неявных преобразований. Отсутствие последних означает, что вместо автоматического преобразования наборов RDD объектов Tuple или double в специальные классы с дополнительными функциями приходится использовать функции явного преобразования типа (например, mapToDouble или mapToPair). Указанные функции определены только для наборов RDD языка Java; к счастью для совместимости, эти специальные типы представляют собой просто адаптеры для наборов RDD языка Scala. Кроме того, эти специальные функции возвращают различные типы данных, такие как JavaDoubleRDD и JavaPairRDD, с возможностями, предоставляемыми неявными преобразованиями языка Scala.
Вновь обратимся к каноническому образцу подсчета слов, воспользовавшись API Java (пример 7.1). Поскольку вызов API Scala из Java может иногда оказаться непростым делом, то API Java фреймворка Spark почти все реализованы на языке Scala со спрятанными тегами классов и неявными преобразованиями. Благодаря этому адаптеры Java представляют собой очень тонкий слой, в среднем состоящий лишь из нескольких строк кода, и их переписывание практически не требует усилий.
Пример 7.1. Подсчет слов (Java)
import scala.Tuple2;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaPairRDD
import org.apache.spark.api.java.JavaSparkContext;
import java.util.regex.Pattern;
import java.util.Arrays;
public final class WordCount {
private static final Pattern pattern = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
JavaSparkContext jsc = new JavaSparkContext();
JavaRDD<String> lines = jsc.textFile(args[0]);
JavaRDD<String> words = lines.flatMap(e -> Arrays.asList(
pattern.split(e)).iterator());
JavaPairRDD<String, Integer> wordsIntial = words.mapToPair(
e -> new Tuple2<String, Integer>(e, 1));
}
}Иногда может понадобиться преобразовать наборы RDD Java в наборы RDD Scala или наоборот. Чаще всего это бывает нужно для библиотек, требующих на входе или возвращающих наборы RDD Scala, но иногда базовые свойства Spark могут еще не быть доступны в API Java. Преобразование набора RDD Java в набор RDD Scala — простейший способ использовать эти новые свойства.
При необходимости передать набор RDD Java в библиотеку Scala, ожидающую на входе обычный RDD Spark, получить доступ к находящемуся в его основе RDD Scala можно с помощью метода rdd(). Чаще всего этого оказывается достаточно для передачи итогового RDD в любую нужную библиотеку Scala; в числе заслуживающих упоминания исключений — библиотеки Scala, полагающиеся в своей работе на неявные преобразования типов содержимого наборов или информацию тегов классов. В таком случае простейшим способом обращения к неявным преобразованиям будет написание небольшого адаптера на Scala. Если Scala-оболочки использовать нельзя, то можно вызвать соответствующую функцию класса JavaConverters и сформировать фиктивный тег класса.
Для создания фиктивного тега класса можно использовать метод scala.reflect.ClassTag$.MODULE$.AnyRef() или получить настоящий с помощью scala.reflect.ClassTag$.MODULE$.apply(CLASS), как показано в примерах 7.2 и 7.3.
Для преобразования из RDD Scala в RDD Java информация о теге класса часто важнее, чем для большинства библиотек Spark. Причина в том, что, хотя различные классы JavaRDD предоставляют общедоступные конструкторы, принимающие RDD Scala в качестве аргументов, они предназначены для вызова из кода на языке Scala, а потому требуют информации о теге класса.
Фиктивные теги классов чаще всего используются в обобщенном или шаблонизированном коде, где точные типы неизвестны в момент компиляции. Таких тегов часто бывает достаточно, хотя существует возможность потери некоторых нюансов на стороне Scala-кода; в очень редких случаях для кода на языке Scala необходима точная информация о теге класса. В этом случае придется использовать настоящий тег. В большинстве случаев это требует не намного больших усилий и улучшает производительность, так что старайтесь использовать такие теги везде, где только возможно.
Пример 7.2. Обеспечение совместимости RDD Java/Scala с помощью фиктивного тега класса
public static JavaPairRDD wrapPairRDDFakeCt(
RDD<Tuple2<String, Object>> RDD) {
// Формируем теги классов путем приведения типа AnyRef — это чаще
// всего делается в случае обобщенного или шаблонизированного кода,
// когда невозможно явным образом сформировать правильный тег класса,
// поскольку использование фиктивного тега класса может привести
// к снижению производительности
ClassTag<Object> fake = ClassTag$.MODULE$.AnyRef();
return new JavaPairRDD(rdd, fake, fake);
}Пример 7.3. Обеспечение совместимости RDD Java/Scala
public static JavaPairRDD wrapPairRDD(
RDD<Tuple2<String, Object>> RDD) {
// Формируем теги классов
ClassTag<String> strCt = ClassTag$.MODULE$.apply(String.class);
ClassTag<Long> longCt = ClassTag$.MODULE$.apply(scala.Long.class);
return new JavaPairRDD(rdd, strCt, longCt);
}API как Spark SQL, так и конвейера ML были по большей части сделаны единообразно в Java и Scala. Однако существуют предназначенные для Java вспомогательные функции, а функции языка Scala, эквивалентные им, вызвать непросто. Вот их примеры: различные числовые функции, такие как plus, minus и т. д., для класса Column. Вызвать их перегруженные эквиваленты из языка Scala (+, -) сложно. Вместо использования JavaDataFrame и JavaSQLContext необходимые для Java методы сделаны доступными в SQLContext и обычных наборах DataFrame. Это может смутить вас, ведь некоторые упомянутые в документации по Java методы нельзя задействовать из кода на языке Java, но в подобных случаях для вызова из Java предоставляются функции с аналогичными названиями.
Пользовательские функции (UDF) в языке Java, а если уж на то пошло, и в большинстве других языков, кроме Scala, требуют указания типа возвращаемого функцией значения, поскольку его невозможно логически вывести, подобно тому как это выполняется в языке Scala (пример 7.4).
Пример 7.4. Образец UDF для языка Java
sqlContext.udf()
.register("strlen",
(String s) -> s.length(), DataTypes.StringType);Хотя необходимые для API Scala и Java типы различаются, обертывание типов-коллекций языка Java не требует дополнительного копирования. В случае итераторов требуемое для адаптера преобразование типа выполняется отложенным образом по мере обращения к элементам, что позволяет фреймворку Spark сбрасывать данные в случае надобности (как обсуждалось в разделе «Выполнение преобразований “итератор — итератор” с помощью функции mapPartitions» на с. 121). Это очень важно, поскольку для многих простых операций стоимость копирования данных может оказаться выше затрат на само вычисление.
За пределами и Scala, и JVM
Если не ограничивать себя JVM, то количество доступных для работы языков программирования резко возрастает. Однако при текущей архитектуре Spark работа вне JVM — особенно на рабочих узлах — может приводить к существенному росту затрат из-за копирования данных в рабочих узлах между JVM и кодом на целевом языке. При сложных операциях доля затрат на копирование данных относительно невелика, но при простых она легко способна привести к удвоению общих вычислительных затрат.
Первый непосредственно поддерживаемый вне Spark не-JVM-язык программирования — Python, его API и интерфейс стали образцом, на котором основываются реализации для остальных не-JVM-языков программирования.
Как работает PySpark
PySpark подключается к JVM Spark с помощью смеси каналов на работниках и Py4J — специализированной библиотеки, обеспечивающей взаимодействие Python/Java — на драйвере. Под этой, на первый взгляд, простой архитектурой скрывается немало сложных нюансов, благодаря которым работает PySpark, как показано на рис. 7.1. Одна из основных проблем: даже когда данные скопированы из работника Python в JVM, они находятся не в том виде, который может легко разобрать виртуальная машина. Необходимы специальные усилия на стороне и работника Python, и Java, чтобы гарантировать наличие в JVM достаточного объема информации для таких операций, как секционирование.
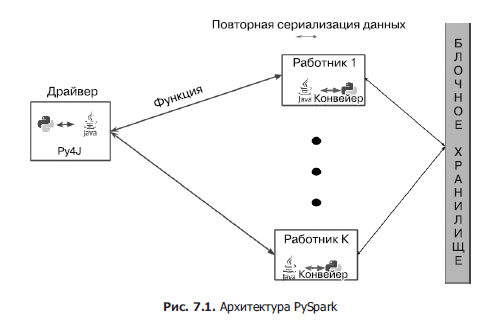
Наборы RDD PySpark
Затраты ресурсов на передачу данных в JVM и из нее, а также на запуск исполнителя Python весьма значительны. Избежать многих проблем с производительностью с API наборов RDD PySpark можно, используя API DataFrame/Dataset, благодаря тому что данные при этом как можно дольше остаются в JVM.
Копирование данных из JVM в Python выполняется с помощью сокетов и сериализованных байтов. Более общая версия для взаимодействия с программами на других языках доступна через интерфейс PipedRDD, применение которого показано в подразделе «Использование pipe».
Организация каналов для обмена данными (в двух направлениях) для каждого преобразования была бы слишком дорогостоящей. Вследствие этого PySpark организует (при возможности) конвейер преобразований Python внутри интерпретатора Python, соединяя в цепочку операцию filter, а после нее — map, на итераторе Python-объектов с помощью специализированного класса PipelinedRDD. Даже когда нужно перетасовать данные и PySpark не способен связать преобразования цепочкой в виртуальной машине отдельного работника, можно повторно использовать интерпретатор Python, так что затраты на запуск интерпретатора не приведут к дальнейшему замедлению работы.
Это только часть головоломки. Обычные PipedRDD работают с типом String, перетасовывать который не так уж просто из-за отсутствия естественного ключа. В PySpark же, а по его образу и подобию в библиотеках привязки ко многим другим языкам программирования, применяется специальный тип PairwiseRDD, где ключ представляет собой длинное целое, а его десериализация выполняется пользовательским кодом на языке Scala, предназначенном для синтаксического разбора Python-значений. Затраты на эту десериализацию не слишком велики, но она демонстрирует, что Scala в фреймворке Spark в основном рассматривает результаты работы кода Python как «непрозрачные» байтовые массивы.
При всей его простоте этот подход к интеграции работает на удивление хорошо, причем в языке Python доступно большинство операций над наборами RDD Scala. В некоторых наиболее сложных местах кода происходит обращение к библиотекам, например MLlib, а также загрузка/сохранение данных из различных источников.
Работа с различными форматами данных тоже накладывает свои ограничения, поскольку значительная часть кода загрузки/сохранения данных фреймворка Spark основана на Java-интерфейсах Hadoop. Это значит, что все загружаемые данные сначала загружаются в JVM, а лишь потом перемещаются в Python.
Для взаимодействия с MLlib обычно применяются два подхода: или в PySpark используется специализированный тип данных с преобразованиями типов Scala, или алгоритм заново реализуется в Python. Этих проблем можно избежать с помощью пакета Spark ML, в котором применяется интерфейс DataFrame/Dataset, обычно хранящий данные в JVM.
Наборы DataFrame и Dataset пакета PySpark
Наборы DataFrame и Dataset лишены многих проблем с производительностью API наборов RDD Python благодаря тому, что хранят данные в JVM как можно дольше. Тот же тест производительности, который мы провели для иллюстрации превосходства наборов DataFrame над наборами RDD (см. рис. 3.1), показывает значительные различия при запуске в Python (рис. 7.2).

При многих операциях с наборами DataFrame и Dataset, возможно, вообще не потребуется перемещать данные из JVM, хотя использование различных UDF, UDAF и лямбда-выражений языка Python, естественно, требует перемещения части данных в JVM. Это приводит к следующей упрощенной схеме для многих операций, выглядящей так, как показано на рис. 7.3.

Доступ к нижележащим Java-объектам и смешанному коду на Scala
Важное следствие архитектуры PySpark состоит в том, что многие из Python-классов фреймворка Spark фактически являются адаптерами, служащими для трансляции вызовов из кода на Python в понятную JVM-форму.
Если вы сотрудничаете с разработчиками на Scala/Java и хотите взаимодействовать с их кодом, то заранее никаких адаптеров для обращения к вашему коду не будет, но вы можете зарегистрировать свои Java/Scala UDF и воспользоваться ими из кода на Python. Начиная со Spark 2.1, это можно сделать с помощью метода registerJavaFunction объекта sqlContext.
Иногда эти адаптеры не имеют всех необходимых механизмов, и, поскольку в языке Python отсутствует жесткая защита от обращения к приватным методам, можно сразу обратиться к JVM. Такая же методика позволит обратиться к собственному коду в JVM и с небольшими усилиями преобразовать результаты обратно в объекты Python.
В подразделе «Большие планы запросов и итеративные алгоритмы» на с. 91 мы отмечали важность использования JVM-версии наборов DataFrame и RDD в целях сокращения плана запроса. Это обходной путь, ведь когда планы запросов становятся слишком большими для обработки оптимизатором Spark SQL, SQL-оптимизатор, из-за помещения набора RDD в середину теряет возможность заглянуть за пределы момента появления данных в RDD. Того же можно добиться с помощью общедоступных API Python, однако при этом потеряются многие преимущества наборов DataFrame, ведь все данные должны будут пройти туда и обратно через рабочие узлы Python. Вместо этого можно сократить граф происхождения, продолжая хранить данные в JVM (как показано в примере 7.5).
Пример 7.5. Усечение большого плана запроса для набора DataFrame с помощью Python
def cutLineage(df):
"""
Усечение графа происхождения DataFrame — используется для итеративных алгоритмов
.. Примечание: эта функция использует внутренние члены классов
и может перестать работать в следующих версиях
>>> df = RDD.toDF()
>>> cutDf = cutLineage(df)
>>> cutDf.count()
3
"""
jRDD = df._jdf.toJavaRDD()
jSchema = df._jdf.schema()
jRDD.cache()
sqlCtx = df.sql_ctx
try:
javaSqlCtx = sqlCtx._jsqlContext
except:
javaSqlCtx = sqlCtx._ssql_ctx
newJavaDF = javaSqlCtx.createDataFrame(jRDD, jSchema)
newDF = DataFrame(newJavaDF, sqlCtx)
return newDFВообще говоря, по соглашению для доступа к внутренним Java-версиям большинства объектов Python используется синтаксис _j[сокращенное_наименование]. Так, например, у объекта SparkContext есть _jsc, который позволяет получить внутренний Java-объект SparkContext. Это возможно только в драйверной программе, так что при отправке PySpark-объектов на рабочие узлы вы не сможете получить доступ к внутреннему Java-компоненту и большая часть API работать не будет.
Для обращения к классу Spark в JVM, у которого нет Python-адаптера, можно воспользоваться шлюзом Py4J на драйвере. Объект SparkContext содержит ссылку на шлюз в свойстве _gateway. Обратиться к любому Java-объекту позволит синтаксис sc._gateway.jvm.[полное_имя_класса_в_JVM].
Подобная методика сработает и для ваших собственных классов Scala, если они располагаются в соответствии с путем к классам. Добавить файлы JAR в путь к классам можно с помощью команды spark-submit с параметром --jars или задав свойства конфигурации spark.driver.extraClassPath. Пример 7.6, который помог сгенерировать рис. 7.2, умышленно устроен так, что генерирует данные для тестирования производительности с помощью существующего кода на языке Scala.
Пример 7.6. Вызов не-Spark-JVM-классов с помощью Py4J
sc = sqlCtx._sc
# Получение SQL Context, синтаксис версий 2.1, 2.0 и более ранних,
# чем 2.0, — ух ты, какие нюансы :p
try:
try:
javaSqlCtx = sqlCtx._jsqlContext
except:
javaSqlCtx = sqlCtx._ssql_ctx
except:
javaSqlCtx = sqlCtx._jwrapped
jsc = sc._jsc
scalasc = jsc.sc()
gateway = sc._gateway
# Вызов java-метода, возвращающего набор RDD JVM-объектов
# Row (Int, Double). Хотя наборы RDD языка Python представляют собой
# обернутые RDD языка Java (даже наборы объектов Row), содержимое их
# различается, так что непосредственное его обертывание невозможно.
# Он возвращает Java-RDD объектов Row — обычно лучше было бы
# вернуть непосредственно набор DataFrame, но для целей иллюстрации
# мы воспользуемся набором RDD объектов Row.
java_rdd = (gateway.jvm.com.highperformancespark.examples.
tools.GenerateScalingData.
generateMiniScaleRows(scalasc, rows, numCols))
# Схемы сериализуются в формат JSON и пересылаются туда и обратно.
# Формируем Python-схему и преобразуем ее в Java-схему.
schema = StructType([
StructField("zip", IntegerType()),
StructField("fuzzyness", DoubleType())])
# Синтаксис версии 2.1 / до 2.1
try:
jschema = javaSqlCtx.parseDataType(schema.json())
except:
jschema = sqlCtx._jsparkSession.parseDataType(schema.json())
# Преобразуем RDD (Java) в DataFrame (Java)
java_dataframe = javaSqlCtx.createDataFrame(java_rdd, jschema)
# Обертываем DataFrame (Java) в DataFrame (Python)
python_dataframe = DataFrame(java_dataframe, sqlCtx)
# Преобразуем DataFrame (Python) в набор RDD
pairRDD = python_dataframe.rdd.map(lambda row: (row[0], row[1]))
return (python_dataframe, pairRDD)Хотя многие классы языка Python представляют собой просто адаптеры Java-объектов, далеко не все Java-объекты можно обернуть в Python-объекты и затем использовать в Spark. Например, объекты в наборах RDD PySpark представлены в виде сериализованных строк, выполнить синтаксический разбор которых с легкостью можно только в коде на языке Python. К счастью, объекты DataFrame стандартизированы между разными языками программирования, так что если вы сумеете преобразовать свои данные в наборы DataFrame, то сможете затем обернуть их в Python-объекты и либо задействовать непосредственно в виде DataFrame языка Python, либо преобразовать DataFrame языка Python в RDD этого же языка.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Spark
