 Привет, Хаброжители! Эта книга предназначена для людей, которые уже обладают опытом работы на одном или нескольких языках программирования и хотят по возможности быстро и просто изучить основы Python 3. Предполагается, что читатель уже знаком с управляющими конструкциями, ООП, работой с файлами, обработкой исключений и т. д. Книга также пригодится пользователям более ранних версий Python, которым нужен компактный справочник по Python 3.1.
Привет, Хаброжители! Эта книга предназначена для людей, которые уже обладают опытом работы на одном или нескольких языках программирования и хотят по возможности быстро и просто изучить основы Python 3. Предполагается, что читатель уже знаком с управляющими конструкциями, ООП, работой с файлами, обработкой исключений и т. д. Книга также пригодится пользователям более ранних версий Python, которым нужен компактный справочник по Python 3.1.Предлагаем ознакомиться с отрывком «Обработка файлов данных»
Как использовать книгу
В части 1 приводится общая информация о Python. Вы узнаете, как загрузить и установить Python в вашей системе. Также здесь приводится общий обзор языка, который будет полезен прежде всего для опытных программистов, желающих получить высокоуровневое представление о Python.
Часть 2 содержит основной материал книги. В ней рассматриваются ингредиенты, необходимые для получения практических навыков использования Python как языка программирования общего назначения. Материал глав был спланирован так, чтобы читатели, только начинающие изучать Python, могли последовательно двигаться вперед, осваивая ключевые моменты языка. В этой части также присутствуют более сложные разделы, чтобы вы могли потом вернуться и найти всю необходимую информацию о некоторой конструкции или теме в одном месте.
В части 3 представлены расширенные возможности Python — элементы языка, которые не являются абсолютно необходимыми, но, безусловно, очень пригодятся любому серьезному программисту Python.
Часть 4 посвящена специализированным темам, выходящим за рамки простого синтаксиса языка. Вы можете читать эти главы или пропустить их в зависимости от ваших потребностей.
Начинающим программистам Python рекомендуется начать с главы 3, чтобы составить общее впечатление, а затем перейти к интересующим главам части 2. Вводите интерактивные примеры, чтобы немедленно закрепить концепции. Вы также можете выйти за рамки примеров, приведенных в тексте, и искать ответы на любые вопросы, оставшиеся неясными. Такой подход повысит скорость обучения и углубит понимание. Если вы еще не знакомы с ООП или оно не требуется для вашего приложения, вы можете пропустить большую часть главы 15.
Читателям, уже знакомым с Python, также стоит начать с главы 3. Она содержит хороший вводный обзор и описание различий между Python 3 и более знакомыми версиями. По ней также можно оценить, готовы ли вы перейти к более сложным главам частей 3 и 4 этой книги.
Возможно, некоторые читатели, не имеющие опыта работы с Python, но имеющие достаточный опыт в других языках программирования, смогут получить большую часть необходимой информации, прочитав главу 3 и просмотрев модули стандартной библиотеки Python (глава 19) и справочное руководство по библиотеке Python в документации Python.
Отрывок. Обработка файлов данных
Большая часть данных распространяется в текстовых файлах. Это может быть как неструктурированный текст (например, подборка сообщений или собрание литературных текстов), так и более структурированные данные, в которых каждая строка представляет собой запись, а поля разделяются специальным символом-разделителем — запятой, символом табуляции или вертикальной чертой (|). Текстовые файлы могут быть огромными; набор данных может занимать десятки и даже сотни файлов, а содержащиеся в нем данные могут быть неполными или искаженными. При таком разнообразии вы почти неизбежно столкнетесь с задачей чтения и использования данных из текстовых файлов. В этой главе представлены основные стратегии для решения этой задачи в Python.
21.1. Знакомство с ETL
Необходимость извлекать данные из файлов, разбирать их, преобразовывать в удобный формат, а затем что-то делать появилась практически одновременно с файлами данных. Более того, для этого процесса даже существует стандартный термин: ETL (Extract-Transform-Load, то есть «извлечение–преобразование–загрузка»). Под извлечением подразумевается процесс чтения источника данных и его разбора при необходимости. Преобразование может подразумевать чистку и нормализацию данных, а также объединение, разбиение и реорганизацию содержащихся в них записей. Наконец, под загрузкой понимается сохранение преобразованных данных в новом месте (в другом файле или базе данных). В этой главе рассматриваются основы реализации ETL на языке Python, начиная с текстовых файлов данных и заканчивая сохранением преобразованных данных в других файлах. Более структурированные файлы данных рассматриваются в главе 22, а хранение информации в базе данных — в главе 23.
21.2. Чтение текстовых файлов
Первая составляющая ETL — извлечение — подразумевает открытие файла и чтение его содержимого. На первый взгляд звучит просто, но даже здесь могут возникнуть проблемы — например, размер файла. Если файл слишком велик для размещения в памяти, код необходимо структурировать так, чтобы он работал с меньшими сегментами файла (возможно, по одной строке).
21.2.1. Кодировка текста: ASCII, Юникод и другие
Другая возможная проблема связана с кодировкой. Эта глава посвящена работе с текстовыми файлами, и на самом деле большая доля данных, передаваемых в реальном мире, хранится в текстовых файлах. Тем не менее точная природа текста может изменяться в зависимости от приложения, от пользователя и, конечно, от страны.
Иногда текст несет информацию в кодировке ASCII, включающей 128 символов, только 95 из которых относятся к категории печатаемых. К счастью, кодировка ASCII является «наименьшим общим кратным» большинства ситуаций с передачей данных. С другой стороны, она никак не справится со сложностями многочисленных алфавитов и систем письменности, существующих в мире. Чтение файлов в кодировке ASCII почти наверняка приведет к тому, что при чтении неподдерживаемых символов, будь то немецкое ü, португальское ç или практически любой символ из языка, кроме английского, начнутся проблемы и появятся ошибки.
Эти ошибки возникают из-за того, что в ASCII используются 7-битовые значения, тогда как байты в типичном файле состоят из 8 бит, что позволяет представить 256 возможных значений вместо 128 для 7-разрядных значений. Эти дополнительные коды обычно используются для хранения дополнительных значений — от расширенных знаков препинания (таких, как среднее и короткое тире) до различных знаков (товарный знак, знак авторского права и знак градуса) и версий алфавитных символов с диакритическими знаками. Всегда существовала одна проблема: при чтении текстового файла вы могли столкнуться с символом, выходящим за пределы ASCII-диапазона из 128 символов, и не могли быть уверены в том, какой именно символ закодирован. Допустим, вам встречается символ с кодом 214. Что это? Знак деления, буква Ö или что-нибудь еще? Без исходного кода, создавшего этот файл, узнать это невозможно.
Юникод и UTF-8
Для устранения этой неоднозначности можно воспользоваться Юникодом. Кодировка Юникода, называемая UTF-8, поддерживает базовые ASCII-символы без каких-либо изменений, но при этом также допускает практически неограниченный набор других символов и знаков из стандарта Юникод. Благодаря своей гибкости UTF-8 используется более чем в 85 % веб-страниц, существовавших на момент написания этой главы. Это означает, что при чтении текстовых файлов лучше всего ориентироваться на UTF-8. Если файлы содержат только ASCII-символы, они будут прочитаны правильно, но вы также получаете страховку на случай, если другие символы закодированы в UTF-8. К счастью, строковый тип данных Python 3 по умолчанию рассчитан на поддержку Юникода.
Даже с Юникодом возможны ситуации, когда в тексте встречаются значения, которые невозможно успешно декодировать. Функция open в Python получает дополнительный параметр errors, который определяет, как следует поступать с ошибками кодирования при чтении или записи файлов. По умолчанию используется значение 'strict', с которым при каждом обнаружении ошибки кодирования инициируется ошибка. Другие полезные значения — 'ignore' (пропустить символ, вызвавший ошибку); 'replace' (символ заменяется специальным маркером — обычно ?); 'backslashreplace' (символ заменяется экранирующей последовательностью с \) и 'surrogateescape' (символ-нарушитель преобразуется в приватный кодовый пункт Юникода при чтении и обратно в исходную последовательность байтов при записи). Выбор способа обработки или разрешения ошибок кодирования зависит от конкретной ситуации.
Рассмотрим короткий пример файла, содержащего недопустимый символ UTF-8, и посмотрим, как этот символ обрабатывается в разных режимах. Сначала запишите файл с использованием bytes и двоичного режима:
>>> open('test.txt', 'wb').write(bytes([65, 66, 67, 255, 192,193]))В результате выполнения команды создается файл из символов «ABC», за которыми следуют три символа, не входящие в ASCII, которые могут по-разному отображаться в зависимости от используемого способа кодирования. Если воспользоваться vim для просмотра файла, результат будет выглядеть так:
ABCÿÀÁ
~Когда файл будет создан, попробуйте прочитать его в используемом по умолчанию режиме обработки ошибок 'strict':
>>> x = open('test.txt').read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3:
invalid start byteЧетвертый байт со значением 255 не является действительным символом UTF-8 в этой позиции, поэтому в режиме 'strict' происходит исключение. А теперь посмотрим, как другие режимы обработки ошибок справляются с тем же файлом, не забывая о том, что последние три символа инициируют ошибку:
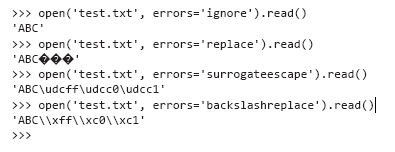
Если вы хотите, чтобы проблемные символы просто исчезли, используйте режим 'ignore'. Режим 'replace' только помечает позиции недействительных символов, а другие режимы по-разному пытаются сохранить недействительные символы без интерпретации.
21.2.2. Неструктурированный текст
Неструктурированные текстовые файлы читаются проще всего, но они же создают больше всего проблем с извлечением информации. Обработка неструктурированного текста может меняться в широчайших пределах в зависимости как от природы текста, так и от того, что вы собираетесь с ним делать, так что сколько-нибудь подробное обсуждение обработки текста выходит за рамки книги. Однако короткий пример поможет продемонстрировать некоторые базовые проблемы и заложит основу для обсуждения файлов со структурированными текстовыми данными.
Одна из самых простых проблем — выбор базовой логической единицы в файле. Если вы используете подборку из тысяч сообщений «Твиттера», текст «Моби Дика» или коллекцию новостей, их нужно как-то разбить на блоки. В случае твитов каждый блок может помещаться в одной строке, а чтение и обработка каждой строки файла организуется достаточно просто.
В случае с «Моби Диком» и даже отдельной новостью проблема усложняется. Конечно, текст романа и даже текст новости обычно нежелательно рассматривать как единый блок. В таком случае нужно решить, какие блоки вам нужны, а затем выработать стратегию разделения файла на блоки. Возможно, вы предпочтете обрабатывать текст по абзацам. В таком случае следует определить, как организована разбивка текста на абзацы в файле, и написать код соответствующим образом. Если абзацы совпадают со строками текстового файла, сделать это будет несложно. Однако нередко один абзац текстового файла может состоять из нескольких строк в текстовом файле, и вам придется потрудиться.
А теперь рассмотрим пару примеров.
Call me Ishmael. Some years ago--never mind how long precisely--
having little or no money in my purse, and nothing particular
to interest me on shore, I thought I would sail about a little
and see the watery part of the world. It is a way I have
of driving off the spleen and regulating the circulation.
Whenever I find myself growing grim about the mouth;
whenever it is a damp, drizzly November in my soul; whenever I
find myself involuntarily pausing before coffin warehouses,
and bringing up the rear of every funeral I meet;
and especially whenever my hypos get such an upper hand of me,
that it requires a strong moral principle to prevent me from
deliberately stepping into the street, and methodically knocking
people's hats off--then, I account it high time to get to sea
as soon as I can. This is my substitute for pistol and ball.
With a philosophical flourish Cato throws himself upon his sword;
I quietly take to the ship. There is nothing surprising in this.
If they but knew it, almost all men in their degree, some time
or other, cherish very nearly the same feelings towards
the ocean with me.
There now is your insular city of the Manhattoes, belted round by wharves
as Indian isles by coral reefs--commerce surrounds it with her surf.
Right and left, the streets take you waterward. Its extreme downtown
is the battery, where that noble mole is washed by waves, and cooled
by breezes, which a few hours previous were out of sight of land.
Look at the crowds of water-gazers there.
В этом примере (с началом текста «Моби Дика») строки разбиваются более-менее так, как они бы разбивались на страницы, а абзацы обозначаются одиночной пустой строкой. Если вы хотите обрабатывать каждый абзац как единое целое, необходимо разбить текст по пустым строкам. К счастью, эта задача легко решается методом строк split(). Каждый символ новой строки в тексте представляется комбинацией "\n". Естественно, последняя строка текста каждого абзаца завершается символом новой строки, и если следующая строка текста пуста, то за ней немедленно следует второй символ новой строки:

Разбиение текста на абзацы — очень простой шаг процесса обработки неструктурированного текста. Возможно, также потребуется провести дополнительную нормализацию текста перед дальнейшей обработкой. Допустим, вы хотите подсчитать частоту вхождения каждого слова в текстовом файле. Если просто разбить файл по пропускам, вы получите список слов в файле, однако точно подсчитать вхождения будет не так просто, потому что This, this, this. и this, не будут считаться одним и тем же словом. Чтобы этот код правильно работал, необходимо нормализовать текст, удалив знаки препинания и преобразовав весь текст к одному регистру перед обработкой. В приведенном выше примере текста код построения нормализованного списка слов может выглядеть так:

21.2.3. Неструктурированные файлы с разделителями
Неструктурированные файлы читаются очень просто, однако отсутствие структуры также является их недостатком. Часто бывает удобнее определить для файла некоторую структуру, чтобы упростить выборку отдельных значений. В простейшем варианте файл разбивается на строки, и в каждой строке хранится один информационный элемент. Например, это может быть список имен файлов для обработки, список имен людей или серия показаний температуры от удаленного датчика. В таких случаях разбор данных организуется очень просто: вы читаете строку и при необходимости преобразуете ее к нужному типу. Это все, что нужно, чтобы файл был готов к использованию.
Впрочем, ситуация не настолько проста. Чаще требуется сгруппировать несколько взаимосвязанных элементов данных, а ваш код должен прочитать их вместе. Обычно для этого взаимосвязанные данные размещаются в одной строке и разделяются специальным символом. В этом случае при чтении каждой строки файла специальные символы используются для разбиения данных на поля и сохранения значений полей в переменных для последующей обработки.
В следующем файле содержатся данные температуры в формате с разделителями:
State|Month Day, Year Code|Avg Daily Max Air Temperature (F)|Record Count for
Daily Max Air Temp (F)
Illinois|1979/01/01|17.48|994
Illinois|1979/01/02|4.64|994
Illinois|1979/01/03|11.05|994
Illinois|1979/01/04|9.51|994
Illinois|1979/05/15|68.42|994
Illinois|1979/05/16|70.29|994
Illinois|1979/05/17|75.34|994
Illinois|1979/05/18|79.13|994
Illinois|1979/05/19|74.94|994Данные в файле разделяются символом вертикальной черты (|). В данном примере они состоят из четырех полей: штата, даты наблюдений, средней максимальной температуры и количества станций, поставляющих данные. Другими стандартными разделителями являются символ табуляции и запятая. Пожалуй, запятая используется чаще всего, но разделителем может быть любой символ, который не будет встречаться в значениях (об этом чуть позже). Разделение данных запятыми настолько распространено, что этот формат часто называется CSV (Comma-Separated Values, то есть данные, разделенные запятыми), и файлы такого типа снабжаются расширением .csv как признаком формата.
Какой бы символ ни использовался в качестве разделителя, если вы знаете, что это за символ, вы можете написать собственный код на языке Python для разбиения строки на поля и возвращения их в виде списка. В предыдущем случае можно воспользоваться методом split() для преобразования строки в список значений:
>>> line = "Illinois|1979/01/01|17.48|994"
>>> print(line.split("|"))
['Illinois', '1979/01/01', '17.48', '994']Этот прием очень легко реализуется, но все значения сохраняются в строковом виде, а это может быть неудобно для последующей обработки.
21.2.4. Модуль csv
Если вам часто приходится обрабатывать файлы данных с разделителями, стоит поближе познакомиться с модулем csv и его возможностями. Когда меня просили назвать любимый модуль из стандартной библиотеки Python, я не раз называла модуль csv — не от того, что он эффектно выглядит (это не так), а из-за того, что он, пожалуй, экономил мне больше времени и спасал меня от моих же потенциальных ошибок чаще, чем любой другой модуль.
Модуль csv — идеальный пример философии Python «батарейки в комплекте». Хотя вы прекрасно можете написать собственный код чтения файлов с разделителями (более того, это не так уж сложно), намного проще и надежнее использовать модуль Python. Модуль csv был протестирован и оптимизирован, и он предоставляет ряд возможностей, которые вы вряд ли бы стали реализовывать самостоятельно, но которые тем не менее достаточно удобны и экономят время.
Взгляните на предыдущие данные и решите, как бы вы прочитали их с модулем csv. Код разбора данных должен прочитать каждую строку и удалить завершающий символ новой строки, а затем разбить строку по символам | и присоединить список значений к общему списку строк. Решение могло бы выглядеть примерно так:
>>> results = []
>>> for line in open("temp_data_pipes_00a.txt"):
... fields = line.strip().split("|")
... results.append(fields)
...
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]Если вы захотите сделать то же самое с модулем csv, код может выглядеть примерно так:
>>> import csv
>>> results = [fields for fields in
csv.reader(open("temp_data_pipes_00a.txt", newline=''), delimiter="|")]
>>> results
[['State', 'Month Day, Year Code', 'Avg Daily Max Air Temperature (F)',
'Record Count for Daily Max Air Temp (F)'], ['Illinois', '1979/01/01',
'17.48', '994'], ['Illinois', '1979/01/02', '4.64', '994'], ['Illinois',
'1979/01/03', '11.05', '994'], ['Illinois', '1979/01/04', '9.51',
'994'], ['Illinois', '1979/05/15', '68.42', '994'], ['Illinois', '1979/
05/16', '70.29', '994'], ['Illinois', '1979/05/17', '75.34', '994'],
['Illinois', '1979/05/18', '79.13', '994'], ['Illinois', '1979/05/19',
'74.94', '994']]В этом простом случае выигрыш по сравнению с самостоятельной реализацией решения не так уж велик. Тем не менее код получился на две строки короче и немного понятнее, и вам не нужно беспокоиться об отсечении символов новой строки. Настоящее преимущество проявляется, когда вы сталкиваетесь с более сложными случаями.
Данные в этом примере реальны, но в действительности они были упрощены и очищены. Реальные данные от источника будут более сложными. Реальные данные содержат больше полей, одни поля будут заключены в кавычки, а другие нет, а первое поле может быть пустым. Оригинал разделяется табуляциями, но в целях демонстрации я привожу их разделенными запятыми:
"Notes","State","State Code","Month Day, Year","Month Day, Year Code",Avg
Daily Max Air Temperature (F),Record Count for Daily Max Air Temp
(F),Min Temp for Daily Max Air Temp (F),Max Temp for Daily Max Air Temp
(F),Avg Daily Max Heat Index (F),Record Count for Daily Max Heat Index
(F),Min for Daily Max Heat Index (F),Max for Daily Max Heat Index
(F),Daily Max Heat Index (F) % Coverage
,"Illinois","17","Jan 01, 1979","1979/01/
01",17.48,994,6.00,30.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 02, 1979","1979/01/02",4.64,994,-
6.40,15.80,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 03, 1979","1979/01/03",11.05,994,-
0.70,24.70,Missing,0,Missing,Missing,0.00%
,"Illinois","17","Jan 04, 1979","1979/01/
04",9.51,994,0.20,27.60,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 15, 1979","1979/05/
15",68.42,994,61.00,75.10,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 16, 1979","1979/05/
16",70.29,994,63.40,73.50,Missing,0,Missing,Missing,0.00%
,"Illinois","17","May 17, 1979","1979/05/
17",75.34,994,64.00,80.50,82.60,2,82.40,82.80,0.20%
,"Illinois","17","May 18, 1979","1979/05/
18",79.13,994,75.50,82.10,81.42,349,80.20,83.40,35.11%
,"Illinois","17","May 19, 1979","1979/05/
19",74.94,994,66.90,83.10,82.87,78,81.60,85.20,7.85%Обратите внимание: некоторые поля включают запятые. По правилам в таких случаях поле заключается в кавычки, чтобы показать, что его содержимое не предназначено для разбора и поиска разделителей. На практике (как и в данном случае) в кавычки часто заключается лишь часть полей, прежде всего те, значения которых могут содержать разделитель. Впрочем (как опять-таки в данном примере), некоторые поля заключаются в кавычки даже тогда, когда они вряд ли будут содержать разделитель.
В таких случаях доморощенные решения становятся слишком громоздкими. Теперь простое разбиение строки по символу-разделителю уже не работает; нужно проследить за тем, чтобы при поиске использовались только те разделители, которые не находятся внутри строк. Кроме того, необходимо удалить кавычки, которые могут находиться в произвольной позиции или не находиться нигде. С модулем csv вам вообще не придется менять свой код. Более того, поскольку запятая считается разделителем по умолчанию, его даже не нужно указывать:
>>> results2 = [fields for fields in csv.reader(open("temp_data_01.csv",
newline=''))]
>>> results2
[['Notes', 'State', 'State Code', 'Month Day, Year', 'Month Day, Year Code',
'Avg Daily Max Air Temperature (F)', 'Record Count for Daily Max Air
Temp (F)', 'Min Temp for Daily Max Air Temp (F)', 'Max Temp for Daily
Max Air Temp (F)', 'Avg Daily Min Air Temperature (F)', 'Record Count
for Daily Min Air Temp (F)', 'Min Temp for Daily Min Air Temp (F)', 'Max
Temp for Daily Min Air Temp (F)', 'Avg Daily Max Heat Index (F)',
'Record Count for Daily Max Heat Index (F)', 'Min for Daily Max Heat
Index (F)', 'Max for Daily Max Heat Index (F)', 'Daily Max Heat Index
(F) % Coverage'], ['', 'Illinois', '17', 'Jan 01, 1979', '1979/01/01',
'17.48', '994', '6.00', '30.50', '2.89', '994', '-13.60', '15.80',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'Jan 02, 1979', '1979/01/02', '4.64', '994', '-6.40', '15.80', '-9.03',
'994', '-23.60', '6.60', 'Missing', '0', 'Missing', 'Missing', '0.00%'],
['', 'Illinois', '17', 'Jan 03, 1979', '1979/01/03', '11.05', '994', '-
0.70', '24.70', '-2.17', '994', '-18.30', '12.90', 'Missing', '0',
'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17', 'Jan 04, 1979',
'1979/01/04', '9.51', '994', '0.20', '27.60', '-0.43', '994', '-16.30',
'16.30', 'Missing', '0', 'Missing', 'Missing', '0.00%'], ['',
'Illinois', '17', 'May 15, 1979', '1979/05/15', '68.42', '994', '61.00',
'75.10', '51.30', '994', '43.30', '57.00', 'Missing', '0', 'Missing',
'Missing', '0.00%'], ['', 'Illinois', '17', 'May 16, 1979', '1979/05/
16', '70.29', '994', '63.40', '73.50', '48.09', '994', '41.10', '53.00',
'Missing', '0', 'Missing', 'Missing', '0.00%'], ['', 'Illinois', '17',
'May 17, 1979', '1979/05/17', '75.34', '994', '64.00', '80.50', '50.84',
'994', '44.30', '55.70', '82.60', '2', '82.40', '82.80', '0.20%'], ['',
'Illinois', '17', 'May 18, 1979', '1979/05/18', '79.13', '994', '75.50',
'82.10', '55.68', '994', '50.00', '61.10', '81.42', '349', '80.20',
'83.40', '35.11%'], ['', 'Illinois', '17', 'May 19, 1979', '1979/05/19',
'74.94', '994', '66.90', '83.10', '58.59', '994', '50.90', '63.20',
'82.87', '78', '81.60', '85.20', '7.85%']]» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Python
