 Знакомство с машинным обучением и библиотекой TensorFlow похоже на первые уроки в автошколе, когда вы мучаетесь с параллельной парковкой, пытаетесь переключить передачу в нужный момент и не перепутать зеркала, лихорадочно вспоминая последовательность действий, в то время как ваша нога нервно подрагивает на педали газа. Это сложное, но необходимое упражнение. Так и в машинном обучении: прежде чем использовать современные системы распознавания лиц или алгоритмы прогнозирования на фондовом рынке, вам придется разобраться с соответствующим инструментарием и набором инструкций, чтобы затем без проблем создавать собственные системы.
Знакомство с машинным обучением и библиотекой TensorFlow похоже на первые уроки в автошколе, когда вы мучаетесь с параллельной парковкой, пытаетесь переключить передачу в нужный момент и не перепутать зеркала, лихорадочно вспоминая последовательность действий, в то время как ваша нога нервно подрагивает на педали газа. Это сложное, но необходимое упражнение. Так и в машинном обучении: прежде чем использовать современные системы распознавания лиц или алгоритмы прогнозирования на фондовом рынке, вам придется разобраться с соответствующим инструментарием и набором инструкций, чтобы затем без проблем создавать собственные системы. Новички в машинном обучении оценят прикладную направленность этой книги, ведь ее цель — познакомить с основами, чтобы затем быстро приступить к решению реальных задач. От обзора концепций машинного обучения и принципов работы с TensorFlow, вы перейдете к базовым алгоритмам, изучите нейронные сети и сможете самостоятельно решать задачи классификации, кластеризации, регрессии и прогнозирования.
Отрывок. Сверточные нейронные сети
Покупки в магазинах после изнурительного дня — весьма обременительное занятие. Мои глаза атакует слишком большой объем информации. Распродажи, купоны, разнообразные цвета, маленькие дети, мерцающие огни и заполненные людьми проходы — вот только несколько примеров всех сигналов, которые направлены в зрительную кору головного мозга, независимо от того, хочу я или не хочу обращать на это внимание. Визуальная система поглощает изобилие информации.
Наверняка вам знакома фраза «лучше один раз увидеть, чем сто раз услышать». Это может быть справедливо для вас и для меня (то есть для людей), но сможет ли машина найти смысл в изображениях? Наши зрительные фоторецепторы подбирают длины волн света, но эта информация, по-видимому, не распространяется на наше сознание. В конце концов, я не могу точно сказать, какие длины световых волн наблюдаю. Точно так же камера получает пикселы изображения. Но мы хотим вместо этого получать что-то более высокого уровня, например названия или положения объектов. Как мы получаем из пикселов информацию, воспринимаемую на человеческом уровне?
Для получения определенного смысла из исходных данных потребуется спроектировать модель нейронной сети. В предыдущих главах было представлено несколько типов моделей нейронной сети, таких как полносвязные модели (глава 8) и автокодировщики (глава 7). В этой главе мы познакомимся с другим типом моделей, который называется сверточная нейронная сеть (CNN — convolutional neural network). Эта модель отлично работает с изображениями и другими сенсорными данными, такими как звук. Например, модель CNN может надежно классифицировать, какой объект отображается на картинке.
Модель CNN, которая будет рассмотрена в этой главе, будет обучена классифицировать изображения по одной из 10 возможных категорий. В данном случае «картинка лучше только одного слова», так как у нас всего 10 возможных вариантов. Это крошечный шаг к восприятию на человеческом уровне, но с чего-то нам надо начинать, верно?
9.1. Недостатки нейронных сетей
Машинное обучение представляет собой вечную борьбу за разработку модели, которая обладала бы достаточной выразительностью для представления данных, но при этом не была такой универсальной, чтобы доходить до переобученности и запоминать паттерны. Нейронные сети предлагаются как способ повышения выразительности; хотя, как можно догадаться, они сильно страдают от ловушек переобучения.
ПРИМЕЧАНИЕ Переобучение возникает, когда обученная модель исключительно точна на обучающем наборе данных и плоха на проверочном наборе данных. Эта модель, вероятно, чрезмерно универсальна для небольшого объема доступных данных, и в конце концов она просто запоминает обучающие данные.
Для сравнения универсальности двух моделей машинного обучения вы можете использовать быстрый и грубый эвристический алгоритм, чтобы подсчитать число параметров, которые требуется определить в результате обучения. Как показано на рис. 9.1, полносвязная нейронная сеть, которая берет изображение размером 256 × 256 и отображает его на слой из 10 нейронов, будет иметь 256 × 256 × 10 = 655 360 параметров! Сравните ее с моделью, содержащей только пять параметров. Можно предположить, что полносвязная нейронная сеть может представлять более сложные данные, чем модель с пятью параметрами.
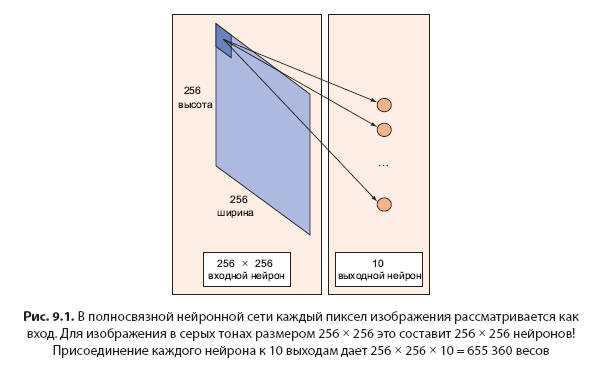
В следующем разделе рассматриваются сверточные нейронные сети, которые являются разумным способом снижения числа параметров. Вместо того чтобы заниматься полносвязными сетями, CNN многократно использует повторно те же параметры.
9.2. Сверточные нейронные сети
Главная идея, лежащая в основе сверточных нейронных сетей, состоит в том, что вполне достаточно локального осмысления изображения. Практическое преимущество сверточных нейронных сетей таково, что, имея несколько параметров, можно значительно сократить время на обучение, а также объем данных, необходимых для обучения модели.
Вместо полносвязных сетей с весами от каждого пиксела CNN имеет достаточное число весов, необходимых для просмотра небольшого фрагмента изображения. Это все равно что читать книгу с помощью лупы: в конечном счете вы прочитываете всю страницу, но в любой момент времени смотрите только на небольшой ее фрагмент.
Представьте изображение размером 256 × 256. Вместо использования кода TensorFlow, обрабатывающего все изображение сразу, можно сканировать изображение фрагмент за фрагментом, скажем, окном размером 5 × 5. Окно размером 5 × 5 скользит по изображению (обычно слева направо и сверху вниз), как показано на рис. 9.2. То, как «быстро» оно скользит, называют длиной шага (stride length). Например, длина шага 2 означает, что скользящее окно 5 × 5 перемещается на 2 пиксела за раз, пока не пройдет все изображение. В TensorFlow, как будет скоро показано, можно настроить длину шага и размер окна, используя встроенную библиотеку функций.
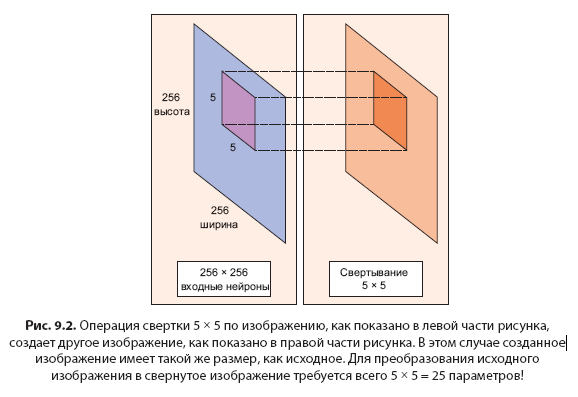
Это окно размером 5 × 5 имеет связанную с ним матрицу весов 5 × 5.
ОПРЕДЕЛЕНИЕ Сверткой (convolution) называют взвешенное суммирование значений интенсивности пикселов изображения по мере прохождения окна по всему изображению. Оказывается, что этот процесс свертки изображения с матрицей весов создает другое изображение (такого же размера, который зависит от свертывания). Свертыванием называют процесс применения свертки.
Все манипуляции скользящего окна происходят в сверточном слое нейронной сети. Типичная сверточная нейронная сеть имеет несколько сверточных слоев. Каждый сверточный слой обычно создает много дополнительных сверток, поэтому матрица весовых коэффициентов является тензором 5 × 5 × n, где n — число сверток.
В качестве примера пусть изображение проходит через сверточный слой с матрицей весовых коэффициентов размером 5 × 5 × 64. Это создает 64 свертки скользящим окном 5 × 5. Поэтому соответствующая модель имеет 5 × 5 × 64 = 1600 параметров, что значительно меньше числа параметров полносвязной сети: 256 × 256 = 65 536.
Привлекательность сверточных нейронных сетей (CNN) состоит в том, что число используемых моделью параметров не зависит от размера исходного изображения. Можно выполнить одну и ту же сверточную нейронную сеть на изображения размером 300 × 300, и число параметров в сверточном слое не изменится!
9.3. Подготовка изображения
Перед началом использования модели CNN с TensorFlow подготовим несколько изображений. Листинги в этом разделе помогут вам установить обучающий набор данных для оставшейся части главы.
Прежде всего, следует загрузить набор данных CIFAR-10 с сайта www.cs.toronto.edu/~kriz/cifar-10- python.tar.gz. В этом наборе содержатся 60 000 изображений, равномерно распределенных по 10 категориям, что представляет достаточно большой ресурс для задач классификации. Затем файл с изображениями следует поместить в рабочую директорию. На рис. 9.3 приведены примеры изображений из этого набора данных.
Мы уже использовали набор данных CIFAR-10 в предыдущей главе, посвященной автокодировщикам, и теперь снова рассмотрим этот код. Следующий листинг взят прямо из документации CIFAR-10, находящейся на сайте www.cs.toronto.edu/~kriz/cifar.html. Поместите код в файл cifar_tools.py.

Листинг 9.1. Загрузка изображений из файла CIFAR-10 в Python
import pickle
def unpickle(file):
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='latin1')
fo.close()
return dictНейронные сети предрасположены к переобучению, поэтому важно сделать все возможное для минимизации этой ошибки. Для этого необходимо не забывать выполнять очистку данных перед их обработкой.
Очистка данных является основным процессом конвейера машинного обучения. Приведенный в листинге 9.2 код для чистки набора изображений использует следующие три шага:
1. Если у вас изображение в цвете, попробуйте преобразовать его в оттенки серого, чтобы уменьшить размерность входных данных и, следовательно, уменьшить количество параметров.
2. Подумайте об обрезке изображения по центру, потому что края изображения не предоставляют никакой полезной информации.
3. Нормализуйте входные данные вычитанием средней величины и делением на среднеквадратическое отклонение каждой выборки данных, чтобы градиенты во время обратного распространения не изменялись слишком резко.
В следующем листинге показано, как очистить набор данных с помощью этих методов.

Сохраните все изображения из набора данных CIFAR-10 и запустите функцию очистки. В следующем листинге задается удобный метод считывания, очистки и структурирования данных для использования в TensorFlow. Туда же следует включить код из файла cifar_tools.py.
Листинг 9.3. Предварительная обработка всех файлов CIFAR-10
def read_data(directory):
names = unpickle('{}/batches.meta'.format(directory))['label_names']
print('names', names)
data, labels = [], []
for i in range(1, 6):
filename = '{}/data_batch_{}'.format(directory, i)
batch_data = unpickle(filename)
if len(data) > 0:
data = np.vstack((data, batch_data['data']))
labels = np.hstack((labels, batch_data['labels']))
else:
data = batch_data['data']
labels = batch_data['labels']
print(np.shape(data), np.shape(labels))
data = clean(data)
data = data.astype(np.float32)
return names, data, labelsВ файле using_cifar.py можно использовать метод, импортировав для этого cifar_tools. В листингах 9.4 и 9.5 показано, как делать выборку нескольких изображений из набора данных и визуализировать их.
Листинг 9.4. Использование вспомогательной функции cifar_tools
import cifar_tools
names, data, labels = \
cifar_tools.read_data('your/location/to/cifar-10-batches-py')Вы можете произвольно выбрать несколько изображений и отрисовать их в соответствии с меткой. Следующий листинг делает именно это, поэтому вы можете лучше понять тип данных, с которыми будете иметь дело.

Запустив этот код, вы создадите файл cifar_examples.png, который будет похож на рис. 9.3.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Машинное обучение
