Доброе утро всем!
Сегодня мы рады предложить вам перевод статьи, кратко рассказывающей о новом технологическом веянии под названием «Service mesh» (сервисная сеть). Наиболее интересным решением в этой сфере (на наш взгляд) является Istio, но предлагаемая статья интересна, в первую очередь, экспресс-сравнением имеющихся технологий такого рода и high-level обзором всей парадигмы. Автор Тобиас Кунце также написал вторую, более практически-ориентированную статью о service mesh — просьба высказаться, стоит ли опубликовать и ее перевод

Этот пост – первый из двух, рассказывающих о достоинствах сервисных сетей. В этой статье рассказано, что такое сервисная сеть, как она работает, и какая от нее польза. Во второй части исследовано, зачем, где и когда следует использовать такие сети, и что нас ждет впереди.
При декомпозиции приложения на микросервисы достаточно быстро выясняется, что вызов сервиса по сети – процесс значительно более сложный и менее надежный, чем предполагалось сначала. То, что по замыслу должно было «просто работать», теперь приходится четко артикулировать для каждого клиента и каждого сервиса. Клиентам приходится обнаруживать терминалы сервисов, гарантировать, что они согласуются по версиям API, упаковывать и распаковывать сообщения. Также клиентам нужно отслеживать выполнение вызовов и управлять такими операциями, отлавливая ошибки, повторяя неудавшиеся вызовы и при необходимости выдерживая тайм-аут. Еще клиентам может понадобиться удостоверяться в подлинности сервисов, логировать вызовы и инструментировать транзакции. Наконец, бывает, что все приложение должно соответствовать правилам IAM, требованиям шифрования или контроля доступа.
Разумеется, большинство из этих проблем – не новы, и уже давно в нашем распоряжении есть технологии, помогающие организовать механизмы обмена сообщениями, например, SOAP, Apache Thrift и gRPC. А вот что наблюдается недавно: бурное распространение контейнеров и сопутствующий ему взрывной рост сервисных вызовов, степень горизонтального масштабирования и связанная с ней недолговременность существования сервисных терминалов. Когда сложность и зыбкость выходят на новый уровень, возникает желание инкапсулировать сетевую коммуникацию и вынести ее на новый инфраструктурный уровень. Наиболее популярный подход к предоставлению такого уровня, применяемый сегодня, называется «сервисная сеть».
Сервисная сеть – это не «сетка из сервисов». Эта сеть API-посредников (прокси), к которым могут подключаться (микро)сервисы для полного абстрагирования сети. Как выразился Уильям Морган, это «выделенный инфраструктурный уровень, обеспечивающий безопасную, быструю и надежную коммуникацию между сервисами». Сервисные сети помогают справляться со множеством вызовов, которые встают перед разработчиками, когда приходится обмениваться информацией с удаленными терминалами. Однако, следует отметить, что крупные эксплуатационные проблемы при помощи сервисных сетей не решаются.
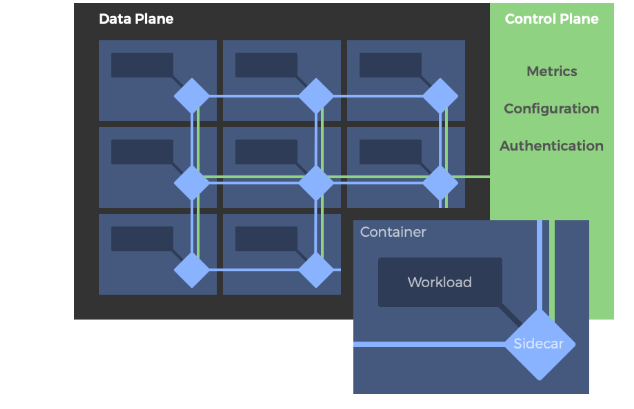
Типичная архитектура сервисной сети. Прокси в плоскости данных развернуты как компаньоны (sidecar), а плоскость управления располагается отдельно.
В типичной сервисной сети развернутые сервисы модифицируются таким образом, чтобы каждому из них сопутствовал собственный прокси-«компаньон». Сервисы не вызывают другие сервисы по сети напрямую, а вместо этого обращаются к своим локальным прокси-компаньонам, которые, в свою очередь, инкапсулируют всю сложность обмена информацией между сервисами. Такая взаимосвязанная совокупность прокси реализует так называемую плоскость данных.
Напротив, набор API и инструментов, используемых для управления поведением прокси в пределах всей сервисной сети называется ее «плоскостью управления». Именно в плоскости управления пользователи задают политики и конфигурируют плоскость данных в целом.
Для реализации сервисной сети нужны как плоскость данных, так и плоскость управления.

Envoy – опенсорсный прокси-сервер, разрабатываемый в компании Lyft. Сегодня он образует плоскость данных во многих сервисных сетях, в том числе, в Istio. Envoy быстро вытеснил другие прокси-серверы благодаря своему удобному конфигурационному API, позволяющему плоскостям управления корректировать его поведение в режиме реального времени.

Linkerd – опенсорсный проект, поддерживаемый Buoyant и, в то же время, самая первая сервисная сеть. Исходно он был написан на Scala, как и Finagle, от Twitter, от которого он произошел, а затем слился с легковесным проектом Conduit и был перезапущен как Linkerd 2.0.

Istio – пожалуй, наиболее популярная сервисная сеть нашего времени. Ее совместно запустили Google, IBM и Lyft; ожидается, что в конечном итоге она войдет в проект Cloud-Native Computing Foundation (CNCF). Строго говоря, Istio – это плоскость управления и, чтобы образовать сервисную сеть, она должна сочетаться с плоскостью данных. Как правило, Istio используется вместе с Envoy и лучше всего работает на Kubernetes.

Consul – сравнительно новое явление в экосистеме плоскостей управления. Он лучше всего работает с топологиями, охватывающими множество датацентров, и специализируется на обнаружении сервисов. Consul работает со множеством плоскостей данных, и может использоваться без привлечения других плоскостей управления, например, без Istio. Его поддержкой занимается HashiCorp.
Хотя, пространство сервисных сетей продолжает развиваться, большинство проектов, по-видимому, уже пришли к представлению об основном наборе фич, которые должны в такой сети поддерживаться:
Кроме этих возможностей (а иногда и на их основе) существует и более богатый уровень функций, на котором между разными сервисными сетями начинаются серьезные расхождения по поводу того, что может быть ценно для архитекторов, разработчиков и администраторов микросервисных систем. Например, Envoy поддерживает WebSockets, а Linkerd 2.0 (пока) нет. В то время, как и Istio, и Consul поддерживают разные плоскости данных, Linkerd работает только со своей собственной. У Consul есть собственная встроенная плоскость данных, которую можно заменить на более мощную, когда вопрос производительности становится приоритетным. Istio разработана как отдельная централизованная плоскость управления, а Consul и Linkerd являются полностью распределенными. Наконец, из всех рассмотренных выше сервисных сетей лишь Istio поддерживает внесение неисправностей (fault injection). Это лишь некоторые из ключевых различий, которые нужно учитывать, если вы подумываете о внедрении такой сети.
Несмотря на явную популярность и многообещающие привлекательные возможности, сервисные сети пока используются не столь широко, как можно было бы ожидать. Несомненно, это отчасти связано с их новизной и с тем фактом, что вся эта отрасль продолжает оформляться. Но, рассказывая о сервисных сетях, нельзя обойтись и без некоторой критики.
Скепсис, связанный с сервисными сетями, в первую очередь касается той дополнительной сложности, которую они привносят, их относительно низкой производительности и определенных пробелов, которые проявляются при работе с топологиями из множества кластеров.
Сервисные сети – это неоднозначные платформы, на начальном этапе внедрения которых требуются серьезные инвестиции в сборку самой системы и ее инструментальное оснащение. Может показаться, что добавить компаньон в контейнер достаточно легко, однако, грамотная обработка отказов и повторных попыток требует серьезных инженерных усилий. Бывает сложно обосновать такие инвестиции при работе с уже имеющимися приложениями с коротким жизненным циклом, либо со стремительно развивающимися приложениями.
Кроме того, сервисные сети могут серьезно снижать производительность приложений по сравнению с использованием прямых сетевых вызовов. Возникающие при этом проблемы порой сложно диагностировать, а тем более – устранять. Поскольку большинство сервисных сетей нацелено на работу с самодостаточными микросервисными приложениями, а не на целые ландшафты связанных приложений, в таких сетях обычно плохо реализована поддержка решений для множества кластеров и разных регионов.
Короче говоря, сервисные сети – не панацея для архитекторов и операторов, стремящихся гибко приспособиться к эксплуатации растущего парка цифровых сервисов. Такая сеть – тактическое решение, она представляет собой «фундаментальное» техническое усовершенствование, призванное решать проблемы, актуальные, прежде всего, для разработчиков. На уровне бизнеса они ситуацию не перевернут.
Сервисные сети пересекаются и с другими архитектурными компонентами, но, конечно, несводимы к ним. Среди таких элементов – API, шлюзы приложений, балансировщики нагрузки, контроллеры входящего и исходящего трафика (ingress и egress) или шлюзы доставки приложений. Основное назначение шлюза API – предоставлять сервисам выход во внешний мир, действуя при этом как единый API для обеспечения балансировки нагрузки, безопасности и базовых функций управления. Контроллеры входящего и исходящего трафика транслируют информацию между немаршрутизируемыми адресами в оркестровщике контейнеров и маршрутизируемыми адресами вне его. Наконец, контроллеры доставки приложений подобны шлюзам API, но их специализация – в ускорении доставки веб-приложений, а не только API.
Сегодня мы рады предложить вам перевод статьи, кратко рассказывающей о новом технологическом веянии под названием «Service mesh» (сервисная сеть). Наиболее интересным решением в этой сфере (на наш взгляд) является Istio, но предлагаемая статья интересна, в первую очередь, экспресс-сравнением имеющихся технологий такого рода и high-level обзором всей парадигмы. Автор Тобиас Кунце также написал вторую, более практически-ориентированную статью о service mesh — просьба высказаться, стоит ли опубликовать и ее перевод

Этот пост – первый из двух, рассказывающих о достоинствах сервисных сетей. В этой статье рассказано, что такое сервисная сеть, как она работает, и какая от нее польза. Во второй части исследовано, зачем, где и когда следует использовать такие сети, и что нас ждет впереди.
При декомпозиции приложения на микросервисы достаточно быстро выясняется, что вызов сервиса по сети – процесс значительно более сложный и менее надежный, чем предполагалось сначала. То, что по замыслу должно было «просто работать», теперь приходится четко артикулировать для каждого клиента и каждого сервиса. Клиентам приходится обнаруживать терминалы сервисов, гарантировать, что они согласуются по версиям API, упаковывать и распаковывать сообщения. Также клиентам нужно отслеживать выполнение вызовов и управлять такими операциями, отлавливая ошибки, повторяя неудавшиеся вызовы и при необходимости выдерживая тайм-аут. Еще клиентам может понадобиться удостоверяться в подлинности сервисов, логировать вызовы и инструментировать транзакции. Наконец, бывает, что все приложение должно соответствовать правилам IAM, требованиям шифрования или контроля доступа.
Разумеется, большинство из этих проблем – не новы, и уже давно в нашем распоряжении есть технологии, помогающие организовать механизмы обмена сообщениями, например, SOAP, Apache Thrift и gRPC. А вот что наблюдается недавно: бурное распространение контейнеров и сопутствующий ему взрывной рост сервисных вызовов, степень горизонтального масштабирования и связанная с ней недолговременность существования сервисных терминалов. Когда сложность и зыбкость выходят на новый уровень, возникает желание инкапсулировать сетевую коммуникацию и вынести ее на новый инфраструктурный уровень. Наиболее популярный подход к предоставлению такого уровня, применяемый сегодня, называется «сервисная сеть».
Что же такое “сервисная сеть” на самом деле?
Сервисная сеть – это не «сетка из сервисов». Эта сеть API-посредников (прокси), к которым могут подключаться (микро)сервисы для полного абстрагирования сети. Как выразился Уильям Морган, это «выделенный инфраструктурный уровень, обеспечивающий безопасную, быструю и надежную коммуникацию между сервисами». Сервисные сети помогают справляться со множеством вызовов, которые встают перед разработчиками, когда приходится обмениваться информацией с удаленными терминалами. Однако, следует отметить, что крупные эксплуатационные проблемы при помощи сервисных сетей не решаются.
Как работают сервисные сети?

Типичная архитектура сервисной сети. Прокси в плоскости данных развернуты как компаньоны (sidecar), а плоскость управления располагается отдельно.
В типичной сервисной сети развернутые сервисы модифицируются таким образом, чтобы каждому из них сопутствовал собственный прокси-«компаньон». Сервисы не вызывают другие сервисы по сети напрямую, а вместо этого обращаются к своим локальным прокси-компаньонам, которые, в свою очередь, инкапсулируют всю сложность обмена информацией между сервисами. Такая взаимосвязанная совокупность прокси реализует так называемую плоскость данных.
Напротив, набор API и инструментов, используемых для управления поведением прокси в пределах всей сервисной сети называется ее «плоскостью управления». Именно в плоскости управления пользователи задают политики и конфигурируют плоскость данных в целом.
Для реализации сервисной сети нужны как плоскость данных, так и плоскость управления.
Основные игроки: Envoy, Linkerd, Istio и Consul

Envoy – опенсорсный прокси-сервер, разрабатываемый в компании Lyft. Сегодня он образует плоскость данных во многих сервисных сетях, в том числе, в Istio. Envoy быстро вытеснил другие прокси-серверы благодаря своему удобному конфигурационному API, позволяющему плоскостям управления корректировать его поведение в режиме реального времени.

Linkerd – опенсорсный проект, поддерживаемый Buoyant и, в то же время, самая первая сервисная сеть. Исходно он был написан на Scala, как и Finagle, от Twitter, от которого он произошел, а затем слился с легковесным проектом Conduit и был перезапущен как Linkerd 2.0.

Istio – пожалуй, наиболее популярная сервисная сеть нашего времени. Ее совместно запустили Google, IBM и Lyft; ожидается, что в конечном итоге она войдет в проект Cloud-Native Computing Foundation (CNCF). Строго говоря, Istio – это плоскость управления и, чтобы образовать сервисную сеть, она должна сочетаться с плоскостью данных. Как правило, Istio используется вместе с Envoy и лучше всего работает на Kubernetes.

Consul – сравнительно новое явление в экосистеме плоскостей управления. Он лучше всего работает с топологиями, охватывающими множество датацентров, и специализируется на обнаружении сервисов. Consul работает со множеством плоскостей данных, и может использоваться без привлечения других плоскостей управления, например, без Istio. Его поддержкой занимается HashiCorp.
Основные достоинства и расхождения в приоритетах
Хотя, пространство сервисных сетей продолжает развиваться, большинство проектов, по-видимому, уже пришли к представлению об основном наборе фич, которые должны в такой сети поддерживаться:
- Обнаружение сервисов: обнаружение сервисов и ведение их реестра
- Маршрутизация: умная балансировка нагрузки и сетевая маршрутизация, более качественная проверка работоспособности, паттерны автоматического развертывания, например, сине-зеленые и канареечные конфигурации
- Устойчивость: повторные попытки, таймауты и автоматические выключатели
- Безопасность: Шифрование на основе TLS, в том числе, управление ключами
- Телеметрия: сбор метрик и отслеживание идентификаторов
Кроме этих возможностей (а иногда и на их основе) существует и более богатый уровень функций, на котором между разными сервисными сетями начинаются серьезные расхождения по поводу того, что может быть ценно для архитекторов, разработчиков и администраторов микросервисных систем. Например, Envoy поддерживает WebSockets, а Linkerd 2.0 (пока) нет. В то время, как и Istio, и Consul поддерживают разные плоскости данных, Linkerd работает только со своей собственной. У Consul есть собственная встроенная плоскость данных, которую можно заменить на более мощную, когда вопрос производительности становится приоритетным. Istio разработана как отдельная централизованная плоскость управления, а Consul и Linkerd являются полностью распределенными. Наконец, из всех рассмотренных выше сервисных сетей лишь Istio поддерживает внесение неисправностей (fault injection). Это лишь некоторые из ключевых различий, которые нужно учитывать, если вы подумываете о внедрении такой сети.
Критика сервисных сетей
Несмотря на явную популярность и многообещающие привлекательные возможности, сервисные сети пока используются не столь широко, как можно было бы ожидать. Несомненно, это отчасти связано с их новизной и с тем фактом, что вся эта отрасль продолжает оформляться. Но, рассказывая о сервисных сетях, нельзя обойтись и без некоторой критики.
Скепсис, связанный с сервисными сетями, в первую очередь касается той дополнительной сложности, которую они привносят, их относительно низкой производительности и определенных пробелов, которые проявляются при работе с топологиями из множества кластеров.
Сервисные сети – это неоднозначные платформы, на начальном этапе внедрения которых требуются серьезные инвестиции в сборку самой системы и ее инструментальное оснащение. Может показаться, что добавить компаньон в контейнер достаточно легко, однако, грамотная обработка отказов и повторных попыток требует серьезных инженерных усилий. Бывает сложно обосновать такие инвестиции при работе с уже имеющимися приложениями с коротким жизненным циклом, либо со стремительно развивающимися приложениями.
Кроме того, сервисные сети могут серьезно снижать производительность приложений по сравнению с использованием прямых сетевых вызовов. Возникающие при этом проблемы порой сложно диагностировать, а тем более – устранять. Поскольку большинство сервисных сетей нацелено на работу с самодостаточными микросервисными приложениями, а не на целые ландшафты связанных приложений, в таких сетях обычно плохо реализована поддержка решений для множества кластеров и разных регионов.
Короче говоря, сервисные сети – не панацея для архитекторов и операторов, стремящихся гибко приспособиться к эксплуатации растущего парка цифровых сервисов. Такая сеть – тактическое решение, она представляет собой «фундаментальное» техническое усовершенствование, призванное решать проблемы, актуальные, прежде всего, для разработчиков. На уровне бизнеса они ситуацию не перевернут.
Связанные технологии
Сервисные сети пересекаются и с другими архитектурными компонентами, но, конечно, несводимы к ним. Среди таких элементов – API, шлюзы приложений, балансировщики нагрузки, контроллеры входящего и исходящего трафика (ingress и egress) или шлюзы доставки приложений. Основное назначение шлюза API – предоставлять сервисам выход во внешний мир, действуя при этом как единый API для обеспечения балансировки нагрузки, безопасности и базовых функций управления. Контроллеры входящего и исходящего трафика транслируют информацию между немаршрутизируемыми адресами в оркестровщике контейнеров и маршрутизируемыми адресами вне его. Наконец, контроллеры доставки приложений подобны шлюзам API, но их специализация – в ускорении доставки веб-приложений, а не только API.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Актуальность follow-up
83.72% Интересует перевод второй части36
16.28% Спасибо, ознакомился. Первой части достаточно7
Проголосовали 43 пользователя. Воздержались 11 пользователей.
