 Привет, Хаброжители! Эта книга подойдет для любого разработчика, который хочет разобраться в потоковой обработке. Понимание распределенного программирования поможет лучше изучить Kafka и Kafka Streams. Было бы неплохо знать и сам фреймворк Kafka, но это не обязательно: я расскажу вам все, что нужно. Опытные разработчики Kafka, как и новички, благодаря этой книге освоят создание интересных приложений для потоковой обработки с помощью библиотеки Kafka Streams. Java-разработчики среднего и высокого уровня, уже привычные к таким понятиям, как сериализация, научатся применять свои навыки для создания приложений Kafka Streams. Исходный код книги написан на Java 8 и существенно использует синтаксис лямбда-выражений Java 8, так что умение работать с лямбда-функциями (даже на другом языке программирования) вам пригодится.
Привет, Хаброжители! Эта книга подойдет для любого разработчика, который хочет разобраться в потоковой обработке. Понимание распределенного программирования поможет лучше изучить Kafka и Kafka Streams. Было бы неплохо знать и сам фреймворк Kafka, но это не обязательно: я расскажу вам все, что нужно. Опытные разработчики Kafka, как и новички, благодаря этой книге освоят создание интересных приложений для потоковой обработки с помощью библиотеки Kafka Streams. Java-разработчики среднего и высокого уровня, уже привычные к таким понятиям, как сериализация, научатся применять свои навыки для создания приложений Kafka Streams. Исходный код книги написан на Java 8 и существенно использует синтаксис лямбда-выражений Java 8, так что умение работать с лямбда-функциями (даже на другом языке программирования) вам пригодится.Отрывок. 5.3. Агрегирование и оконные операции
В этом разделе мы перейдем к изучению наиболее многообещающих частей Kafka Streams. Пока мы рассмотрели следующие аспекты Kafka Streams:
- создание топологии обработки;
- использование состояния в потоковых приложениях;
- выполнение соединений потоков данных;
- различия между потоками событий (KStream) и потоками обновлений (KTable).
В следующих же примерах мы соберем все эти элементы воедино. Кроме того, вы познакомитесь с оконными операциями — еще одной замечательной возможностью потоковых приложений. Первым нашим примером будет простое агрегирование.
5.3.1. Агрегирование объема продаж акций по отраслям промышленности
Агрегирование и группировка — жизненно необходимые инструменты при работе с потоковыми данными. Исследования отдельных записей по мере поступления часто оказывается недостаточно. Для извлечения из данных дополнительной информации необходимы их группировка и комбинирование.
В этом примере вам предстоит примерить костюм внутридневного трейдера, которому нужно отслеживать объемы продаж акций компаний в нескольких отраслях промышленности. В частности, вас интересуют пять компаний с наибольшими объемами продаж акций в каждой из отраслей промышленности.
Для подобного агрегирования потребуется несколько следующих шагов по переводу данных в нужный вид (если говорить в общих чертах).
- Создать источник на основе топика, публикующий необработанную информацию по торговле акциями. Нам придется отобразить объект типа StockTransaction в объект типа ShareVolume. Дело в том, что объект StockTransaction содержит метаданные продаж, а нам нужны только данные о количестве продаваемых акций.
- Сгруппировать данные ShareVolume по символам акций. После группировки по символам можно свернуть эти данные до промежуточных сумм объемов продаж акций. Стоит отметить, что метод KStream.groupBy возвращает экземпляр типа KGroupedStream. А получить экземпляр KTable можно, вызвав далее метод KGroupedStream.reduce.
Что такое интерфейс KGroupedStream
Методы KStream.groupBy и KStream.groupByKey возвращают экземпляр KGroupedStream. KGroupedStream является промежуточным представлением потока событий после группировки по ключам. Он вовсе не предназначен для непосредственной работы с ним. Вместо этого KGroupedStream используется для операций агрегирования, результатом которых всегда является KTable. А поскольку результатом операций агрегирования является KTable и в них применяется хранилище состояния, то, возможно, не все обновления в результате отправляются дальше по конвейеру.
Метод KTable.groupBy возвращает аналогичный KGroupedTable — промежуточное представление потока обновлений, перегруппированных по ключу.
Сделаем небольшой перерыв и посмотрим на рис. 5.9, на котором показано, чего мы добились. Эта топология должна быть вам уже хорошо знакома.
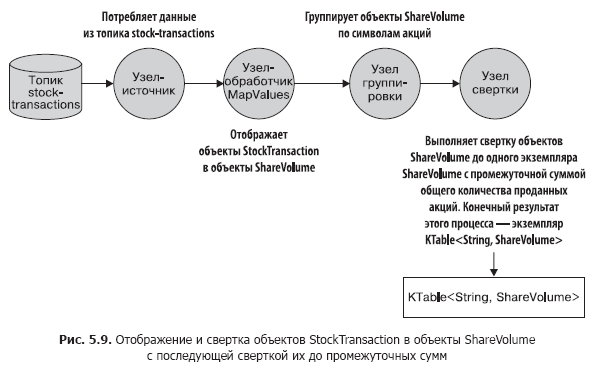
Взглянем теперь на код для этой топологии (его можно найти в файле src/main/java/bbejeck/chapter_5/AggregationsAndReducingExample.java) (листинг 5.2).

Приведенный код отличается краткостью и большим объемом производимых в нескольких строках действий. В первом параметре метода builder.stream вы можете заметить нечто новое для себя: значение перечисляемого типа AutoOffsetReset.EARLIEST (существует также и LATEST), задаваемое с помощью метода Consumed.withOffsetResetPolicy. С помощью этого перечисляемого типа можно указать стратегию сброса смещений для каждого из KStream или KTable, он обладает приоритетом над параметром сброса смещений из конфигурации.
GroupByKey и GroupBy
В интерфейсе KStream есть два метода для группировки записей: GroupByKey и GroupBy. Оба возвращают KGroupedTable, так что у вас может появиться закономерный вопрос: в чем же различие между ними и когда использовать какой из них?
Метод GroupByKey применяется, когда ключи в KStream уже непустые. А главное, флаг «требует повторного секционирования» никогда не устанавливался.
Метод GroupBy предполагает, что вы меняли ключи для группировки, так что флаг повторного секционирования установлен в true. Выполнение после метода GroupBy соединений, агрегирования и т. п. приведет к автоматическому повторному секционированию.
Резюме: следует при малейшей возможности использовать GroupByKey, а не GroupBy.
Что делают методы mapValues и groupBy — понятно, так что взглянем на метод sum() (его можно найти в файле src/main/java/bbejeck/model/ShareVolume.java) (листинг 5.3).

Метод ShareVolume.sum возвращает промежуточную сумму объема продаж акций, а результат всей цепочки вычислений представляет собой объект KTable<String, ShareVolume>. Теперь вы понимаете, какую роль играет KTable. При поступлении объектов ShareVolume в соответствующем объекте KTable сохраняется последнее актуальное обновление. Важно не забывать, что все обновления отражаются в предшествующем shareVolumeKTable, но не все отправляются далее.
Далее с помощью этого KTable мы выполняем агрегирование (по количеству продаваемых акций), чтобы получить пять компаний с наибольшими объемами продаж акций в каждой из отраслей промышленности. Наши действия при этом будут аналогичны действиям при первом агрегировании.
- Выполнить еще одну операцию groupBy для группировки отдельных объектов ShareVolume по отраслям промышленности.
- Приступить к суммированию объектов ShareVolume. На этот раз объект агрегирования представляет собой очередь по приоритету фиксированного размера. В такой очереди фиксированного размера сохраняются только пять компаний с наибольшими количествами проданных акций.
- Отобразить очереди из предыдущего пункта в строковое значение и вернуть пять наиболее продаваемых по количеству акций по отраслям промышленности.
- Записать результаты в строковом виде в топик.
На рис. 5.10 показан граф топологии движения данных. Как вы видите, второй круг обработки достаточно прост.
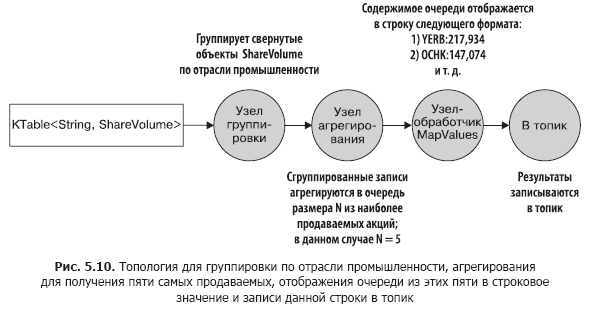
Теперь, четко уяснив себе структуру этого второго круга обработки, можно обратиться к его исходному коду (вы найдете его в файле src/main/java/bbejeck/chapter_5/AggregationsAndReducingExample.java) (листинг 5.4).
В данном инициализаторе есть переменная fixedQueue. Это пользовательский объект — адаптер для java.util.TreeSet, который применяется для отслеживания N наибольших результатов в порядке убывания количества проданных акций.

Вы уже встречались с вызовами groupBy и mapValues, так что не будем на них останавливаться (мы вызываем метод KTable.toStream, поскольку метод KTable.print считается устаревшим). Но вы пока еще не видели KTable-версию метода aggregate(), так что мы потратим немного времени на его обсуждение.
Как вы помните, KTable отличает то, что записи с одинаковыми ключами считаются обновлениями. KTable заменяет старую запись новой. Агрегирование происходит подобным же образом: агрегируются последние записи с одним ключом. При поступлении записи она добавляется в экземпляр класса FixedSizePriorityQueue с помощью сумматора (второй параметр в вызове метода aggregate), но если уже существует другая запись с тем же ключом, то старая запись удаляется с помощью вычитателя (третий параметр в вызове метода aggregate).
Это все значит, что наш агрегатор, FixedSizePriorityQueue, вовсе не агрегирует все значения с одним ключом, а хранит скользящую сумму количеств N наиболее продаваемых видов акций. В каждой поступающей записи содержится общее количество проданных до сих пор акций. KTable даст вам информацию о том, акций каких компаний продается больше всего в настоящий момент, скользящее агрегирование каждого из обновлений не требуется.
Мы научились делать две важные вещи:
- группировать значения в KTable по общему для них ключу;
- выполнять над этими сгруппированными значениями такие полезные операции, как свертка и агрегирование.
Умение выполнять эти операции важно для понимания смысла данных, движущихся через приложение Kafka Streams, и выяснения того, какую информацию они несут.
Мы также соединили воедино некоторые из ключевых понятий, обсуждавшихся ранее в этой книге. В главе 4 мы рассказывали, насколько важно для потокового приложения отказоустойчивое, локальное состояние. Первый пример из этой главы продемонстрировал, почему настолько важно локальное состояние — оно дает возможность отслеживать, какую информацию вы уже видели. Локальный доступ позволяет избежать сетевых задержек, благодаря чему приложение становится более производительным и устойчивым к ошибкам.
При выполнении любой операции свертки или агрегирования необходимо указать название хранилища состояния. Операции свертки и агрегирования возвращают экземпляр KTable, а KTable использует хранилище состояния для замены старых результатов новыми. Как вы видели, далеко не все обновления отправляются далее по конвейеру, и это важно, поскольку операции агрегирования предназначены для получения итоговой информации. Если не применять локальное состояние, KTable будет отправлять дальше все результаты агрегирования и свертки.
Далее мы посмотрим на выполнение таких операций, как агрегирование, в пределах конкретного промежутка времени — так называемых оконных операций (windowing operations).
5.3.2. Оконные операции
В предыдущем разделе мы познакомились со «скользящими» сверткой и агрегированием. Приложение производило непрерывную свертку объема продаж акций с последующим агрегированием пяти наиболее продаваемых на бирже акций.
Иногда подобные непрерывные агрегирование и свертка результатов необходимы. А иногда нужно выполнить операции только над заданным промежутком времени. Например, вычислить, сколько было произведено биржевых операций с акциями конкретной компании за последние 10 минут. Или сколько пользователей нажало на новый рекламный баннер за последние 15 минут. Приложение может производить такие операции многократно, но с результатами, относящимися только к заданным промежуткам времени (временным окнам).
Подсчет биржевых транзакций по покупателю
В следующем примере мы займемся отслеживанием биржевых транзакций по нескольким трейдерам — либо крупным организациям, либо смышленым финансистам-одиночкам.
Существует две возможные причины для подобного отслеживания. Одна из них — необходимость знать, что покупают/продают лидеры рынка. Если эти крупные игроки и искушенные инвесторы видят для себя открывающиеся возможности, имеет смысл следовать их стратегии. Вторая причина заключается в желании заметить любые возможные признаки незаконных сделок с использованием внутренней информации. Для этого вам понадобится проанализировать корреляцию крупных всплесков продаж с важными пресс-релизами.
Такое отслеживание состоит из таких этапов, как:
- создание потока для чтения из топика stock-transactions;
- группировка входящих записей по идентификатору покупателя и биржевому символу акции. Вызов метода groupBy возвращает экземпляр класса KGroupedStream;
- возвращение методом KGroupedStream.windowedBy потока данных, ограниченного временным окном, что позволяет выполнять оконное агрегирование. В зависимости от типа окна возвращается либо TimeWindowedKStream, либо SessionWindowedKStream;
- подсчет транзакций для операции агрегирования. Оконный поток данных определяет, учитывается ли при этом подсчете конкретная запись;
- запись результатов в топик или вывод их в консоль во время разработки.
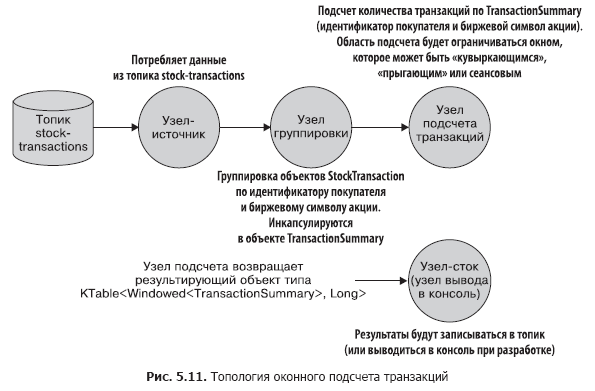
Топология данного приложения проста, но наглядная ее картинка не помешает. Взглянем на рис. 5.11.
Далее мы рассмотрим функциональность оконных операций и соответствующий код.
Типы окон
В Kafka Streams существует три типа окон:
- сеансовые;
- «кувыркающиеся» (tumbling);
- скользящие/«прыгающие» (sliding/hopping).
Какое выбрать — зависит от бизнес-требований. «Кувыркающиеся» и «прыгающие» окна ограничиваются по времени, в то время как ограничения сеансовых связаны с действиями пользователей — длительность сеанса (-ов) определяется исключительно тем, насколько активно ведет себя пользователь. Главное — не забывать, что все типы окон основываются на метках даты/времени записей, а не на системном времени.
Далее мы реализуем нашу топологию с каждым из типов окон. Полный код будет приведен только в первом примере, для других типов окон ничего не изменится, кроме типа оконной операции.
Сеансовые окна
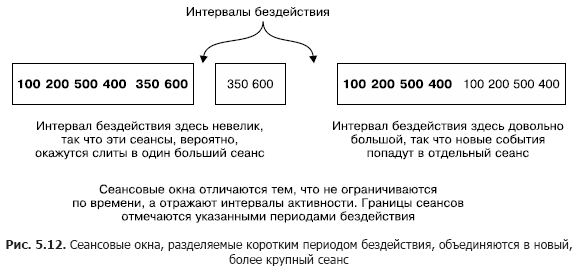
Сеансовые окна сильно отличаются от всех остальных типов окон. Они ограничиваются не столько по времени, сколько активностью пользователя (или активностью той сущности, которую вы хотели бы отслеживать). Сеансовые окна разграничиваются периодами бездействия.
Рисунок 5.12 иллюстрирует понятие сеансовых окон. Меньший сеанс будет сливаться с сеансом слева от него. А сеанс справа будет отдельным, поскольку следует за длительным периодом бездействия. Сеансовые окна основываются на действиях пользователей, но применяют метки даты/времени из записей для определения того, к какому сеансу относится запись.
Использование сеансовых окон для отслеживания биржевых транзакций
Воспользуемся сеансовыми окнами для захвата информации о биржевых транзакциях. Реализация сеансовых окон показана в листинге 5.5 (который можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKTableJoinExample.java).

Большинство операций этой топологии вы уже встречали, так что нет нужды рассматривать их тут снова. Но есть здесь и несколько новых элементов, которые мы сейчас обсудим.
При всякой операции groupBy обычно выполняется какая-либо операция агрегирования (агрегирование, свертка или подсчет количества). Можно выполнить или накопительное агрегирование с нарастающим итогом, или оконное агрегирование, при котором учитываются записи в пределах заданного временного окна.
Код из листинга 5.5 выполняет подсчет количества транзакций в пределах сеансовых окон. На рис. 5.13 эти действия анализируются пошагово.
С помощью вызова windowedBy(SessionWindows.with(twentySeconds).until(fifteenMinutes)) мы создаем сеансовое окно с интервалом бездействия 20 секунд и интервалом сохранения 15 минут. Интервал бездействия 20 секунд означает, что приложение будет включать любую запись, которая поступит в пределах 20 секунд от окончания или начала текущего сеанса в текущий (активный) сеанс.
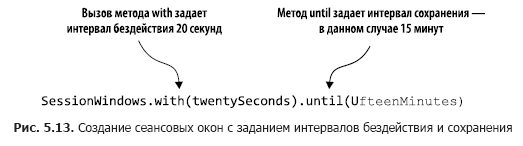
Далее мы указываем, какую операцию агрегирования нужно выполнить в сеансовом окне — в данном случае count. Если входящая запись выходит за пределы интервала бездействия (с любой из сторон от метки даты/времени), то приложение создает новый сеанс. Интервал сохранения означает поддержание сеанса в течение определенного времени и допускает запоздавшие данные, которые выходят за период бездействия сеанса, но все еще могут быть присоединены. Кроме того, начало и конец нового сеанса, получившегося в результате объединения, соответствуют самой ранней и самой поздней метке даты/времени.
Рассмотрим несколько записей из метода count, чтобы увидеть, как работают сеансы (табл. 5.1).

При поступлении записей мы ищем уже существующие сеансы с тем же ключом, временем окончания меньше чем текущая метка даты/времени — интервал бездействия и временем начала больше чем текущая метка даты/времени + интервал бездействия. С учетом этого четыре записи из табл. 5.1 сливаются в единый сеанс следующим образом.
1. Первой поступает запись 1, так что время начала равно времени окончания и равно 00:00:00.
2. Далее поступает запись 2, и мы ищем сеансы, заканчивающиеся не раньше 23:59:55 и начинающиеся не позднее 00:00:35. Находим запись 1 и объединяем сеансы 1 и 2. Берем время начала сеанса 1 (более раннее) и время окончания сеанса 2 (более позднее), так что наш новый сеанс начинается в 00:00:00 и заканчивается в 00:00:15.
3. Поступает запись 3, мы ищем сеансы между 00:00:30 и 00:01:10 и не находим ни одного. Добавляем второй сеанс для ключа 123-345-654,FFBE, начинающийся и заканчивающийся в 00:00:50.
4. Поступает запись 4, и мы ищем сеансы между 23:59:45 и 00:00:25. На этот раз находятся оба сеанса — 1 и 2. Все три сеанса объединяются в один, с временем начала 00:00:00 и временем окончания 00:00:15.
Из рассказанного в этом разделе стоит запомнить следующие важные нюансы:
- сеансы — не окна фиксированного размера. Длительность сеанса определяется активностью в рамках заданного промежутка времени;
- метки даты/времени в данных определяют, попадает событие в существующий сеанс или в промежуток бездействия.
Далее мы обсудим следующую разновидность окон — «кувыркающиеся» окна.
«Кувыркающиеся» окна
«Кувыркающиеся» (tumbling) окна захватывают события, попадающие в определенный промежуток времени. Представьте себе, что вам нужно захватывать все биржевые транзакции какой-то компании каждые 20 секунд, так что вы собираете все события за этот промежуток времени. По окончании 20-секундного интервала окно «кувыркается» и переходит на новый 20-секундный интервал наблюдения. Рисунок 5.14 иллюстрирует эту ситуацию.
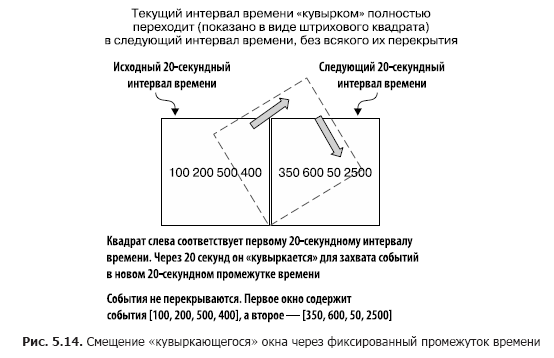
Как вы можете видеть, все поступившие за последние 20 секунд события включены в окно. По окончании этого промежутка времени создается новое окно.
В листинге 5.6 приведен код, демонстрирующий использование «кувыркающихся» окон для захвата каждые 20 секунд биржевых транзакций (его можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java).

Благодаря этому небольшому изменению вызова метода TimeWindows.of можно использовать «кувыркающееся» окно. В данном примере нет вызова метода until(), вследствие чего будет использоваться интервал сохранения по умолчанию, равный 24 часам.
Наконец, пора перейти к последнему из вариантов окон — «прыгающим» (hopping) окнам.
Скользящие («прыгающие») окна
Скользящие/«прыгающие» (sliding/hopping) окна похожи на «кувыркающиеся», но с небольшим отличием. Скользящие окна не ждут окончания интервала времени перед созданием нового окна для обработки недавних событий. Они запускают новые вычисления после интервала ожидания, меньшего чем длительность окна.
Для иллюстрации различий «кувыркающихся» и «прыгающих» окон вернемся к примеру с подсчетом биржевых транзакций. Наша цель по-прежнему состоит в подсчете числа транзакций, но нам не хотелось бы ждать весь промежуток времени перед обновлением счетчика. Вместо этого мы будем обновлять счетчик через более короткие промежутки времени. Например, подсчитывать число транзакций мы будем по-прежнему каждые 20 секунд, но обновлять счетчик — каждые 5 секунд, как показано на рис. 5.15. При этом у нас оказывается три окна результатов с перекрывающимися данными.
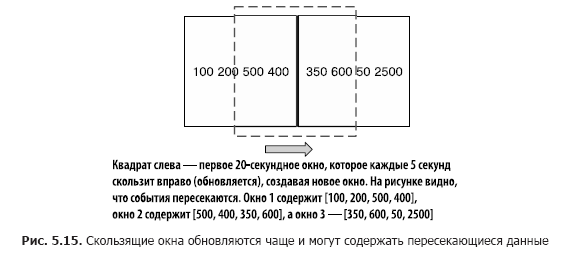
В листинге 5.7 приведен код для задания скользящих окон (его можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java).

«Кувыркающееся» окно можно преобразовать в «прыгающее» с помощью добавления вызова метода advanceBy(). В приведенном примере интервал сохранения равен 15 минутам.
Вы увидели в этом разделе, как ограничивать результаты агрегирования временными окнами. В частности, хотелось бы, чтобы вы запомнили из этого раздела следующие три вещи:
- размер сеансовых окон ограничивается не промежутком времени, а активностью пользователей;
- «кувыркающиеся» окна дают представление о событиях в рамках заданного периода времени;
- длительность работы «прыгающих» окон фиксирована, но они часто обновляются и могут содержать во всех окнах пересекающиеся записи.
Далее мы узнаем, как преобразовать KTable обратно в KStream для соединения.
5.3.3. Соединение объектов KStream и KTable
В главе 4 мы обсуждали соединение двух объектов KStream. Теперь нам предстоит научиться соединять KTable и KStream. Понадобиться это может по следующей простой причине. KStream — поток записей, а KTable — поток обновлений записей, но иногда может быть нужно добавить дополнительный контекст к потоку записей с помощью обновлений из KTable.
Возьмем данные о количестве биржевых транзакций и соединим их с биржевыми новостями по соответствующим отраслям промышленности. Вот что нужно сделать, что добиться этого с учетом уже имеющегося кода.
- Преобразовать объект KTable с данными о количестве биржевых транзакций в KStream с последующей заменой ключа на ключ, обозначающий отрасль промышленности, соответствующую данному символу акций.
- Создать объект KTable, читающий данные из топика с биржевыми новостями. Этот новый KTable будет категоризован по отраслям промышленности.
- Соединить обновления новостей с информацией о количестве биржевых транзакций по отраслям промышленности.
Теперь посмотрим, как реализовать этот план действий.
Преобразование KTable в KStream
Для преобразования KTable в KStream необходимо сделать следующее.
- Вызвать метод KTable.toStream().
- С помощью вызова метода KStream.map заменить ключ названием отрасли промышленности, после чего извлечь из экземпляра Windowed объект TransactionSummary.
Мы свяжем эти операции цепочкой следующим образом (код можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) (листинг 5.8).

Поскольку мы выполняем операцию KStream.map, то повторное секционирование для возвращаемого экземпляра KStream производится автоматически при его использовании в соединении.
Мы завершили процесс преобразования, далее нам нужно создать объект KTable для чтения биржевых новостей.
Создание KTable для биржевых новостей
К счастью, для создания объекта KTable достаточно одной строки кода (этот код можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) (листинг 5.9).

Стоит отметить, что никаких объектов Serde указывать не требуется, поскольку в настройках используются строковые Serde. Также благодаря применению перечисления EARLIEST таблица заполняется записями в самом начале.
Теперь мы можем перейти к заключительному шагу — соединению.
Соединение обновлений новостей с данными о числе транзакций
Создание соединения не представляет сложностей. Мы воспользуемся левым соединением на случай, если по соответствующей отрасли промышленности нет биржевых новостей (нужный код можно найти в файле src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) (листинг 5.10).

Этот оператор leftJoin достаточно прост. В отличие от соединений из главы 4, метод JoinWindow не используется, поскольку при выполнении соединения KStream-KTable для каждого ключа в KTable присутствует только одна запись. Такое соединение не ограничивается по времени: запись или есть в KTable, или отсутствует. Основной вывод: с помощью объектов KTable можно обогащать KStream реже обновляемыми справочными данными.
А теперь мы рассмотрим более эффективный способ обогащения событий из KStream.
5.3.4. Объекты GlobalKTable
Как вы поняли, существует необходимость обогащения потоков событий или добавления к ним контекста. В главе 4 вы видели соединения двух объектов KStream, а в предыдущем разделе — соединение KStream и KTable. Во всех этих случаях необходимо повторное секционирование потока данных при отображении ключей на новый тип или значение. Иногда повторное секционирование выполняется явным образом, а иногда Kafka Streams делает это автоматически. Повторное секционирование необходимо, поскольку ключи изменились и записи должны оказаться в новых секциях, иначе соединение окажется невозможным (это обсуждалось в главе 4, в пункте «Повторное секционирование данных» подраздела 4.2.4).
Повторное секционирование имеет свою цену
Повторное секционирование требует затрат — дополнительных затрат ресурсов на создание промежуточных топиков, сохранение дублирующихся данных в еще одном топике; оно также означает повышение задержки вследствие записи и чтения из этого топика. Кроме того, при необходимости выполнить соединение более чем по одному аспекту или измерению нужно организовать соединения цепочкой, отобразить записи с новыми ключами и снова провести процесс повторного секционирования.
Соединение с наборами данных меньшего размера
В некоторых случаях объем справочных данных, с которыми планируется соединение, относительно невелик, так что полные их копии вполне могут поместиться локально на каждом из узлов. Для подобных ситуаций в Kafka Streams предусмотрен класс GlobalKTable.
Экземпляры GlobalKTable уникальны, поскольку приложение реплицирует все данные на каждый из узлов. А поскольку на каждом из узлов присутствуют все данные, нет необходимости секционировать поток событий по ключу справочных данных, чтобы он был доступен всем секциям. С помощью объектов GlobalKTable можно также выполнять бесключевые соединения. Вернемся к одному из предыдущих примеров для демонстрации этой возможности.
Соединение объектов KStream с объектами GlobalKTable
В подразделе 5.3.2 мы выполнили оконное агрегирование биржевых транзакций по покупателям. Результаты этого агрегирования выглядели примерно следующим образом:
{customerId='074-09-3705', stockTicker='GUTM'}, 17
{customerId='037-34-5184', stockTicker='CORK'}, 16Хотя эти результаты соответствовали поставленной цели, было бы удобнее, если бы выводилось также имя клиента и полное название компании. Чтобы добавить имя покупателя и название компании, можно выполнять обычные соединения, но при этом понадобится произвести два отображения ключей и повторное секционирование. С помощью GlobalKTable можно избежать затрат на подобные операции.
Для этого мы воспользуемся объектом countStream из листинга 5.11 (соответствующий код можно найти в файле src/main/java/bbejeck/chapter_5/GlobalKTableExample.java), соединив его с двумя объектами GlobalKTable.

Мы уже обсуждали это ранее, так что не стану повторяться. Но отмечу, что код в функции toStream().map ради удобочитаемости абстрагирован в объект-функцию вместо встраиваемого лямбда-выражения.
Следующий этап — объявление двух экземпляров GlobalKTable (приведенный код можно найти в файле src/main/java/bbejeck/chapter_5/GlobalKTableExample.java) (листинг 5.12).

Обратите внимание, что названия топиков описываются с помощью перечисляемых типов.
Теперь, когда мы подготовили все компоненты, осталось написать код для соединения (который можно найти в файле src/main/java/bbejeck/chapter_5/GlobalKTableExample.java) (листинг 5.13).

Хотя в этом коде присутствуют два соединения, они организованы в виде цепочки, поскольку отдельно ни один из их результатов не используется. Результаты выводятся в конце всей операции.
При запуске вышеприведенной операции соединения вы получите результаты следующего вида:
{customer='Barney, Smith' company="Exxon", transactions= 17}Суть не изменилась, но эти результаты выглядят более понятно.
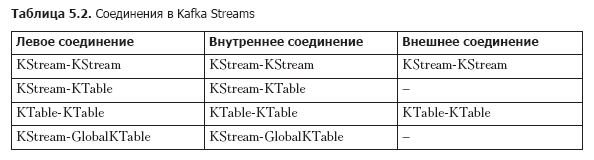
Если считать главу 4, вы уже видели несколько типов соединений в действии. Они перечислены в табл. 5.2. Эта таблица отражает возможности соединения, актуальные для версии 1.0.0 Kafka Streams; в будущих выпусках, возможно, что-то поменяется.
В заключение напомню основное: вы можете соединять потоки событий (KStream) и потоки обновлений (KTable) с помощью локального состояния. Кроме того, если размер справочных данных не слишком велик, можно воспользоваться объектом GlobalKTable. GlobalKTable реплицируют все секции на каждый из узлов приложения Kafka Streams, обеспечивая тем самым доступность всех данных независимо от того, какой секции соответствует ключ.
Далее мы увидим возможность Kafka Streams, благодаря которой можно наблюдать изменения состояния без потребления данных из топика Kafka.
5.3.5. Доступное для запросов состояние
Мы уже выполняли несколько операций с участием состояния и всегда выводили результаты в консоль (для целей разработки) или записывали их в топик (для целей промышленной эксплуатации). При записи результатов в топик приходится использовать потребитель Kafka для их просмотра.
Чтение данных из этих топиков можно считать разновидностью материализованных представлений (materialized views). Для наших задач можно использовать определение материализованного представления из «Википедии»: «…физический объект базы данных, содержащий результаты выполнения запроса. Например, оно может быть локальной копией удаленных данных, или подмножеством строк и/или столбцов таблицы или результатов соединения, или сводной таблицей, полученной с помощью агрегирования» (https://en.wikipedia.org/wiki/Materialized_view).
Kafka Streams также позволяет выполнять интерактивные запросы (interactive queries) к хранилищам состояния, что дает возможность непосредственного чтения этих материализованных представлений. Важно отметить, что запрос к хранилищу состояния носит характер операции «только для чтения». Благодаря этому вы можете не бояться случайно сделать состояние несогласованным во время обработки данных приложением.
Возможность непосредственных запросов к хранилищам состояния имеет большое значение. Она значит, что можно создавать приложения — информационные панели без необходимости сначала получать данные от потребителя Kafka. Повышает она и эффективность приложения, благодаря тому что не требуется снова записывать данные:
- благодаря локальности данных к ним можно быстро обратиться;
- исключается дублирование данных, поскольку они не записываются во внешнее хранилище.
Главное, что я хотел бы, чтобы вы запомнили: можно напрямую выполнять запросы к состоянию из приложения. Нельзя переоценить возможности, которые это вам дает. Вместо того чтобы потреблять данные из Kafka и сохранять записи в базе данных для приложения, можно выполнять запросы к хранилищам состояния с тем же результатом. Непосредственные запросы к хранилищам состояния означают меньший объем кода (отсутствие потребителя) и меньше программного обеспечения (отсутствие потребности в таблице базы данных для хранения результатов).
Мы охватили немалый объем информации в настоящей главе, поэтому на время прекратим наше обсуждение интерактивных запросов к хранилищам состояния. Но не волнуйтесь: в главе 9 мы будем создавать простое приложение — информационную панель с интерактивными запросами. Для демонстрации интерактивных запросов и возможностей их добавления в приложения Kafka Streams в нем будут использоваться некоторые из примеров этой и предыдущих глав.
Резюме
- Объекты KStream олицетворяют потоки событий, сравнимые со вставками в базу данных. Объекты KTable олицетворяют потоки обновлений, они больше схожи с обновлениями в базе данных. Размер объекта KTable не растет, старые записи заменяются новыми.
- Объекты KTable необходимы для операций агрегирования.
- С помощью оконных операций можно разбить агрегированные данные по временным корзинам.
- Благодаря объектам GlobalKTable можно получить доступ к справочным данным в любой точке приложения, независимо от разбиения по секциям.
- Возможны соединения между собой объектов KStream, KTable и GlobalKTable.
До сих пор мы концентрировали внимание на создании приложений Kafka Streams с помощью высокоуровневого DSL KStream. Хотя высокоуровневый подход позволяет создавать аккуратные и лаконичные программы, его использование представляет собой определенный компромисс. Работа с DSL KStream означает повышение лаконичности кода за счет снижения степени контроля. В следующей главе мы рассмотрим низкоуровневый API узлов-обработчиков и попробуем другие компромиссы. Программы станут длиннее, чем были до сих пор, зато у нас появится возможность создания практически любого узла-обработчика, который только может нам понадобиться.
→ Более подробно с книгой можно ознакомиться на сайте издательства
→ Для Хаброжителей скидка 25% по купону — Kafka Streams
→ По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
