Всем привет!
Сегодня вашему вниманию предлагается перевод вдумчиво написанной статьи об одной из базовых проблем Java — изменяемости, и о том, как она сказывается на устройстве структур данных и на работе с ними. Материал взят из блога Николая Парлога (Nicolai Parlog), чей блестящий литературный стиль мы очень постарались сохранить в переводе. Самого Николая замечательно характеризует отрывок из блога компании JUG.ru на Хабре; позволим себе привести здесь этот отрывок целиком:

Читаем и голосуем. Кому пост особенно понравится — рекомендуем также посмотреть комментарии читателей к оригиналу поста.
Изменяемость – это плохо, так? Соответственно, неизменяемость – это хорошо. Основные структуры данных, при использовании которых неизменяемость оказывается особенно плодотворной, это коллекции: в Java это список (
В терминологии JDK значения слов «неизменяемый» (immutable) и «немодифицируемый» (unmodifiable) за последние несколько лет изменились. Изначально «немодифицируемым» называли экземпляр, не допускавший изменяемости (мутабельности): в ответ на изменяющие методы он выбрасывал
Поначалу термином "неизменяемые" обозначались коллекции, возвращаемые фабричными методами коллекций Java 9. Сами коллекции никаким образом нельзя было изменить (да, есть рефлексия, но она не считается), поэтому, представляется, что они оправдывают свое название. Увы, часто из-за этого возникает путаница. Допустим, есть метод, выводящий на экран все элементы из неизменяемой коллекции – всегда ли он будет давать один и тот же результат? Да? Или нет?
Если вы сходу не ответили нет – значит, вас только что озарило, какая именно путаница здесь возможна. «Неизменяемая коллекция тайных агентов» – казалось бы, звучит чертовски похоже на «неизменяемая коллекция неизменяемых тайных агентов», но две эти сущности могут быть неидентичны. Неизменяемая коллекция не поддается редактированию с применением операций вставки/удаления/очистки и т.д., но, если тайные агенты являются изменяемыми (правда, проработка характеров в шпионских фильмах такая плохая, что в это не очень верится), то это еще не значит, что и вся коллекция тайных агентов является неизменяемой. Поэтому, теперь наблюдается сдвиг в сторону именования таких коллекций немодифицируемыми, а не неизменяемыми, что закреплено и в новой редакции JavaDoc.
Неизменяемые коллекции, рассматриваемые в этой статье, могут содержать изменяемые элементы.
Лично мне не нравится такой пересмотр терминологии. На мой взгляд, термин «неизменяемая коллекция» должен означать лишь то, что сама коллекция не поддается изменениям, но никак не должен характеризовать содержащиеся в ней элементы. В таком случае есть и еще один положительный момент: термин «неизменяемость» в экосистеме Java не превращается в полную бессмыслицу.
Так или иначе, в этой статье мы поговорим о неизменяемых коллекциях, где…
Остановимся на том, что теперь мы поупражняемся в добавлении неизменяемых коллекций. Если быть точным – неизменяемого списка. Все, что будет сказано о списках, в той же степени применимо и к коллекциям других типов.
Приступаем к добавлению неизменяемых коллекций!
Создадим интерфейс

Красиво, у
В этом примере показано, что можно передать такой не совсем неизменяемый список в API, работа которого может быть построена на неизменяемости и, соответственно, обнулять все гарантии, на которые может намекать название этого типа. Вот вам рецепт, который может привести к катастрофе.
Хорошо, тогда
Теперь, если API ожидает неизменяемый список, то именно такой список он и получит, но здесь есть два недостатка:
Таким образом, получается, что использовать
Именно это я и имел в виду, говоря, что тип
Если
Проблема, с которой мы столкнулись при первых двух попытках добавить неизменяемые типы, заключалась в нашем заблуждении, будто неизменяемость – это просто отсутствие чего-то: берем
Если просто удалить изменяющие методы из
Теперь мы можем добавить к этой картине еще две вещи:
Неизменяемость – это не отсутствие изменяемости, а гарантия, что никаких изменений не будет
В данном случае важно понять, что в обоих случаях мы говорим о полноценных фичах – неизменяемость является не отсутствием изменений, а гарантией, что изменений не будет. Имеющаяся фича не обязательно может быть чем-то, что используется во благо, она также может гарантировать, что в коде не произойдет чего-то плохого – в данном случае подумайте, например, о потокобезопасности.
Очевидно, изменяемость и неизменяемость конфликтуют друг с другом, и поэтому мы не можем одновременно задействовать две вышеупомянутые иерархии наследования. Типы наследуют возможности от других типов, поэтому, как их ни нарезай, если один из типов наследует от другого, то будет содержать обе фичи.
Итак, хорошо,

Хотя, я и не называл бы вещи именно этими именами, сама иерархия такого рода разумна. В Scala, например, практически так и делается. Разница заключается в том, что разделяемый супертип, который мы назвали
Что же насчет Java? Можно ли модернизировать подобную иерархию, добавив в нее новые супертипы и сиблинги?
Можно ли усовершенствовать немодифицируемые и неизменяемые коллекции?
Разумеется, нет никакой проблемы в том, чтобы добавить типы
Самое классное в том, чтобы иметь
Однако, если только вы не начинаете проект с нуля, такой функционал, скорее всего, уже у вас будет, и выглядеть он будет примерно так:
Это нехорошо, так как, чтобы новые коллекции, только что введенные нами, были полезны, нам как бы нужно с ними работать! (уф). То, что приведено выше, напоминает код приложения, поэтому здесь напрашивается рефакторинг в сторону
Что же насчет фреймворков, библиотек и самого JDK как такового? Здесь все выглядит безрадостно. Попытка изменить параметр или возвращаемый тип с
При введении новых типов потребуется вносить изменения и проводить перекомпиляцию в масштабах всей экосистемы.
Однако, даже если расширить тип параметра с
Любое изменение в параметре или возвращаемом типе метода приведет к тому, что байт-код будет при ссылке на метод указывать неверную сигнатуру; в результате во время исполнения возникнет ошибка
Единственный мыслимый способ воспользоваться такими новыми коллекциями, не нарушив совместимости – продублировать существующие методы каждый под новым именем, изменить API, после чего пометить старый вариант как нежелательный. Вы можете себе представить, насколько монументальной и фактически бесконечной была бы такая задача?!
Конечно, неизменяемые типы коллекций – отличная штука, которую очень хотелось бы иметь, но мы вряд ли увидим что-то подобное в JDK. Грамотные реализации
Вне контекста каких-либо специфических отношений между типами изменение существующих сигнатур методов всегда сопряжено с проблемами, так как такие изменения несовместимы с байт-кодом. При их внесении требуется как минимум перекомпиляция, а это разрушительное изменение, которое отразится на всей экосистеме Java.
Поэтому я считаю, что ничего подобного не произойдет – ни за что и никогда.
Сегодня вашему вниманию предлагается перевод вдумчиво написанной статьи об одной из базовых проблем Java — изменяемости, и о том, как она сказывается на устройстве структур данных и на работе с ними. Материал взят из блога Николая Парлога (Nicolai Parlog), чей блестящий литературный стиль мы очень постарались сохранить в переводе. Самого Николая замечательно характеризует отрывок из блога компании JUG.ru на Хабре; позволим себе привести здесь этот отрывок целиком:

Николай Парлог — такой масс-медиа чувак, который делает обзоры на фичи Java. Но он при этом не из Oracle, поэтому обзоры получаются удивительно откровенными и понятными. Иногда после них кого-то увольняют, но редко. Николай будет рассказывать про будущее Java, что будет в новой версии. У него хорошо получается рассказывать про тренды и вообще про большой мир. Он очень начитанный и эрудированный товарищ. Даже простые доклады приятно слушать, всё время узнаёшь что-то новое. При этом Николай знает за пределами того, что рассказывает. То есть можно приходить на любой доклад и просто наслаждаться, даже если это вообще не ваша тема. Он преподаёт. Написал «The Java Module System» для издательства Manning, ведёт блоги о разработке ПО на codefx.org, давно участвует в нескольких опенсорсных проектах. Прямо на конференции его можно нанять, он фрилансер. Правда, очень дорогой фрилансер. Вот доклад.
Читаем и голосуем. Кому пост особенно понравится — рекомендуем также посмотреть комментарии читателей к оригиналу поста.
Изменяемость – это плохо, так? Соответственно, неизменяемость – это хорошо. Основные структуры данных, при использовании которых неизменяемость оказывается особенно плодотворной, это коллекции: в Java это список (
List), множество (Set) и словарь (Map). Однако, хотя JDK поставляется с неизменяемыми (или немодифицируемыми?) коллекциями, системе типов об этом ничего не известно. В JDK нет ImmutableList, и этот тип из Guava кажется мне совершенно бесполезным. Но почему же? Почему просто не добавить Immutable... в эту смесь и не сказать, что так и надо?Что такое неизменяемая коллекция?
В терминологии JDK значения слов «неизменяемый» (immutable) и «немодифицируемый» (unmodifiable) за последние несколько лет изменились. Изначально «немодифицируемым» называли экземпляр, не допускавший изменяемости (мутабельности): в ответ на изменяющие методы он выбрасывал
UnsupportedOperationException. Однако, его можно было менять по-другому – может быть, потому что он был просто оберткой вокруг изменяемой коллекции. Данные представления отражены в методах Collections::unmodifiableList, unmodifiableSet и unmodifiableMap, а также в их JavaDoc.Поначалу термином "неизменяемые" обозначались коллекции, возвращаемые фабричными методами коллекций Java 9. Сами коллекции никаким образом нельзя было изменить (да, есть рефлексия, но она не считается), поэтому, представляется, что они оправдывают свое название. Увы, часто из-за этого возникает путаница. Допустим, есть метод, выводящий на экран все элементы из неизменяемой коллекции – всегда ли он будет давать один и тот же результат? Да? Или нет?
Если вы сходу не ответили нет – значит, вас только что озарило, какая именно путаница здесь возможна. «Неизменяемая коллекция тайных агентов» – казалось бы, звучит чертовски похоже на «неизменяемая коллекция неизменяемых тайных агентов», но две эти сущности могут быть неидентичны. Неизменяемая коллекция не поддается редактированию с применением операций вставки/удаления/очистки и т.д., но, если тайные агенты являются изменяемыми (правда, проработка характеров в шпионских фильмах такая плохая, что в это не очень верится), то это еще не значит, что и вся коллекция тайных агентов является неизменяемой. Поэтому, теперь наблюдается сдвиг в сторону именования таких коллекций немодифицируемыми, а не неизменяемыми, что закреплено и в новой редакции JavaDoc.
Неизменяемые коллекции, рассматриваемые в этой статье, могут содержать изменяемые элементы.
Лично мне не нравится такой пересмотр терминологии. На мой взгляд, термин «неизменяемая коллекция» должен означать лишь то, что сама коллекция не поддается изменениям, но никак не должен характеризовать содержащиеся в ней элементы. В таком случае есть и еще один положительный момент: термин «неизменяемость» в экосистеме Java не превращается в полную бессмыслицу.
Так или иначе, в этой статье мы поговорим о неизменяемых коллекциях, где…
- Экземпляры, содержащиеся в коллекции, определяются на этапе работы конструктора
- Этих экземпляров – ровное количество, ни убавить, ни прибавить
- Не делается никаких утверждений относительно изменяемости этих элементов
Остановимся на том, что теперь мы поупражняемся в добавлении неизменяемых коллекций. Если быть точным – неизменяемого списка. Все, что будет сказано о списках, в той же степени применимо и к коллекциям других типов.
Приступаем к добавлению неизменяемых коллекций!
Создадим интерфейс
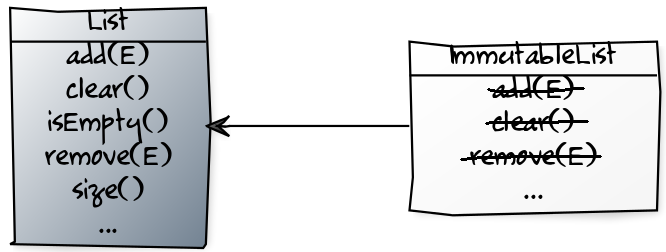
ImmutableList и сделаем его, относительно List, эээ…, чем? Супертипом или субтипом? Давайте остановимся на первом варианте. 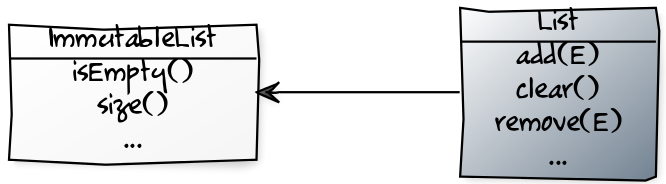
Красиво, у
ImmutableList нет изменяющих методов, поэтому использовать его всегда безопасно, так? Так?! Нет-с.List<Agent> agents = new ArrayList<>();
// компилируется, поскольку `List` расширяет `ImmutableList`
ImmutableList<Agent> section4 = agents;
// ничего не выводит
section4.forEach(System.out::println);
// теперь давайте изменим `section4`
agents.add(new Agent("Motoko");
// выводит "Motoko" – обождите, через какую дырку она сюда вкралась?!
section4.forEach(System.out::println);В этом примере показано, что можно передать такой не совсем неизменяемый список в API, работа которого может быть построена на неизменяемости и, соответственно, обнулять все гарантии, на которые может намекать название этого типа. Вот вам рецепт, который может привести к катастрофе.
Хорошо, тогда
ImmutableList расширяет List. Может быть?
Теперь, если API ожидает неизменяемый список, то именно такой список он и получит, но здесь есть два недостатка:
- Неизменяемые списки все равно должны предлагать изменяющие методы (так как они определены в супертипе), а единственная возможная реализация приводит к выбросу исключения
- Экземпляры
ImmutableListтакже являются экземплярамиListи при присвоении такой переменной, передаче в виде такого аргумента или возвращении такого типа логично предположить, что изменяемость разрешена.
Таким образом, получается, что использовать
ImmutableList можно только локально, поскольку он передает границы API как List, что требует от вас сверхчеловеческого уровня предосторожности, либо взрывается во время исполнения. Это не так плохо, как List, расширяющий ImmutableList, но такое решение все равно далеко от идеала.Именно это я и имел в виду, говоря, что тип
ImmutableList из Guava практически бесполезен. Это отличный образчик кода, очень надежный при работе с локальными неизменяемыми списками (поэтому я им активно пользуюсь), но, прибегая к нему, очень легко выйти за пределы неприступной, гарантированно компилируемой цитадели, стены который были сложены из неизменяемых типов – и только в таком виде неизменяемые типы могут полностью раскрыть свой потенциал. Это лучше, чем ничего, но неэффективно в качестве решения на уровне JDK.Если
ImmutableList не может расширять List, а обходной путь все равно не работает, то как вообще предполагается заставить все это работать?Неизменяемость – это фича
Проблема, с которой мы столкнулись при первых двух попытках добавить неизменяемые типы, заключалась в нашем заблуждении, будто неизменяемость – это просто отсутствие чего-то: берем
List, удаляем из него изменяющий код, получаем ImmutableList. Но, на самом деле, все это не так работает.Если просто удалить изменяющие методы из
List, то у нас получится список, доступный только для чтения. Либо, придерживаясь сформулированной выше терминологии, его можно назвать UnmodifiableList – он все-таки может меняться, просто менять его будете не вы.Теперь мы можем добавить к этой картине еще две вещи:
- Мы можем сделать его изменяемым, добавив соответствующие методы
- Мы можем сделать его неизменяемым, добавив соответствующие гарантии
Неизменяемость – это не отсутствие изменяемости, а гарантия, что никаких изменений не будет
В данном случае важно понять, что в обоих случаях мы говорим о полноценных фичах – неизменяемость является не отсутствием изменений, а гарантией, что изменений не будет. Имеющаяся фича не обязательно может быть чем-то, что используется во благо, она также может гарантировать, что в коде не произойдет чего-то плохого – в данном случае подумайте, например, о потокобезопасности.
Очевидно, изменяемость и неизменяемость конфликтуют друг с другом, и поэтому мы не можем одновременно задействовать две вышеупомянутые иерархии наследования. Типы наследуют возможности от других типов, поэтому, как их ни нарезай, если один из типов наследует от другого, то будет содержать обе фичи.
Итак, хорошо,
List и ImmutableList не могут расширять друг друга. Но нас привела сюда работа с UnmodifiableList, и действительно оказывается, что оба типа имеют один и тот же API, доступный только для чтения, а значит – должны его расширять.
Хотя, я и не называл бы вещи именно этими именами, сама иерархия такого рода разумна. В Scala, например, практически так и делается. Разница заключается в том, что разделяемый супертип, который мы назвали
UnmodifiableList, определяет изменяющие методы, возвращающие модифицированную коллекцию, а исходную оставляющие нетронутой. Таким образом, неизменяемый список получается персистентным и дает изменяемому варианту два набора изменяющих методов – унаследованный для получения модифицированных копий и свой собственный для изменений на месте.Что же насчет Java? Можно ли модернизировать подобную иерархию, добавив в нее новые супертипы и сиблинги?
Можно ли усовершенствовать немодифицируемые и неизменяемые коллекции?
Разумеется, нет никакой проблемы в том, чтобы добавить типы
UnmodifiableList и ImmutableList и создать такую иерархию наследования, которая описана выше. Проблема в том, что в краткосрочной и среднесрочной перспективе это будет практически бесполезно. Давайте я объясню.Самое классное в том, чтобы иметь
UnmodifiableList, ImmutableList и List в качестве типов – в таком случае API смогут четко выражать, что им требуется, и что они предлагают.public void payAgents(UnmodifiableList<Agent> agents) {
// изменяющие методы для платежей не требуются,
// но и и неизменяемость не является необходимым условием
}
public void sendOnMission(ImmutableList<Agent> agents) {
// миссия опасна (много потоков),
// и важно, чтобы команда оставалась стабильной
}
public void downtime(List<Agent> agents) {
// во время простоя члены команды могут уходить,
// и на их место могут наниматься новые сотрудники, поэтому список должен быть изменяемым
}
public UnmodifiableList<Agent> teamRoster() {
// можете просмотреть команду, но не можете ее редактировать,
// а также не можете быть уверены, что ее не редактирует кто-нибудь еще
}
public ImmutableList<Agent> teamOnMission() {
// если команда на задании, то ее состав не изменится
}
public List<Agent> team() {
// получение изменяемого списка подразумевает, что список можно редактировать,
// а затем просмотреть изменения в этом объекте
}Однако, если только вы не начинаете проект с нуля, такой функционал, скорее всего, уже у вас будет, и выглядеть он будет примерно так:
// есть хорошие шансы, что `Iterable<Agent>`
// будет достаточно, но давайте предположим, что нам на самом деле нужен список
public void payAgents(List<Agent> agents) { }
public void sendOnMission(List<Agent> agents) { }
public void downtime(List<Agent> agents) { }
// лично мне больше нравится возвращать потоки,
// так как они немодифицируемые, но `List` все равно более распространен
public List<Agent> teamRoster() { }
// аналогично, это уже может быть `Stream<Agent>`
public List<Agent> teamOnMission() { }
public List<Agent> team() { }Это нехорошо, так как, чтобы новые коллекции, только что введенные нами, были полезны, нам как бы нужно с ними работать! (уф). То, что приведено выше, напоминает код приложения, поэтому здесь напрашивается рефакторинг в сторону
UnmodifiableList и ImmutableList, и осуществить его можно, как было показано в вышеприведенном листинге. Это может быть большой кусок работы, сопряженный с путаницей, когда нужно организовать взаимодействие старого и обновленного кода, но, как минимум, он кажется осуществимым.Что же насчет фреймворков, библиотек и самого JDK как такового? Здесь все выглядит безрадостно. Попытка изменить параметр или возвращаемый тип с
List на ImmutableList приведет к несовместимости с исходным кодом, т.e. существующий исходный код не скомпилируется с новой версией, так как эти типы не связаны друг с другом. Аналогично, при изменении возвращаемого типа с List на новый супертип UnmodifiableList приведет к ошибкам компиляции.При введении новых типов потребуется вносить изменения и проводить перекомпиляцию в масштабах всей экосистемы.
Однако, даже если расширить тип параметра с
List до UnmodifiableList, мы столкнемся с проблемой, поскольку такое изменение вызывает несовместимость на уровне байт-кода. Когда исходный код вызывает метод, компилятор преобразует этот вызов в байт-код, ссылающийся на целевой метод по:- Имени того класса, в качестве экземпляра которого объявлена цель
- Имени метода
- Типам параметров метода
- Возвращаемому типу метода
Любое изменение в параметре или возвращаемом типе метода приведет к тому, что байт-код будет при ссылке на метод указывать неверную сигнатуру; в результате во время исполнения возникнет ошибка
NoSuchMethodError. Если вносимое изменение совместимо с исходным кодом – например, если речь идет о сужении возвращаемого типа или расширения типа параметра – то перекомпиляции должно быть достаточно. Однако, при далеко идущих изменениях, например, при введении новых коллекций, все не так просто: чтобы такие изменения закрепились, нужно перекомпилировать всю экосистему Java. Это пропащее дело.Единственный мыслимый способ воспользоваться такими новыми коллекциями, не нарушив совместимости – продублировать существующие методы каждый под новым именем, изменить API, после чего пометить старый вариант как нежелательный. Вы можете себе представить, насколько монументальной и фактически бесконечной была бы такая задача?!
Рефлексия
Конечно, неизменяемые типы коллекций – отличная штука, которую очень хотелось бы иметь, но мы вряд ли увидим что-то подобное в JDK. Грамотные реализации
List и ImmutableList никогда не смогут расширять друг друга (на самом деле, оба они расширяют один и тот же списковый тип UnmodifiableList, доступный только для чтения), что затрудняет внедрение таких типов в существующие API.Вне контекста каких-либо специфических отношений между типами изменение существующих сигнатур методов всегда сопряжено с проблемами, так как такие изменения несовместимы с байт-кодом. При их внесении требуется как минимум перекомпиляция, а это разрушительное изменение, которое отразится на всей экосистеме Java.
Поэтому я считаю, что ничего подобного не произойдет – ни за что и никогда.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Мнение о прочитанном
38.28%
Интересно, буду размышлять!
49
21.09%
Полностью согласен, также рекомендую перевести и издать книгу автора
27
16.41%
Спорно
21
32.03%
Дичь какая-то
41
Проголосовали 128 пользователей.
Воздержались 47 пользователей.
