Привет, Хабр!
В рамках проработки темы C#8 предлагаем обсудить следующую статью, посвященную новым правилам реализации интерфейсов.

Присматриваясь к тому, как в C# 8 устроены интерфейсы, необходимо учитывать, что при реализации интерфейсов по умолчанию можно наломать дров.
Допущения, связанные с реализацией по умолчанию, могут приводить к поврежденному коду, исключениям времени выполнения и низкой производительности.
Одна из активно рекламируемых фич интерфейсов C# 8 заключается в том, что к интерфейсу можно добавлять члены, не нарушая при этом имеющихся реализаторов. Но невнимательность в данном случае чревата большими проблемами. Рассмотрим код, в котором сделаны неверные допущения – так станет понятнее, насколько важно избегать подобных проблем.
Весь код к этой статье выложен на GitHub: jeremybytes/interfaces-in-csharp-8, конкретно в проекте DangerousAssumptions.
Замечание: в этой статье рассматриваются фичи C# 8, в настоящее время реализованные только в .NET Core 3.0. В приводимых примерах я использовал Visual Studio 16.3.0 и .NET Core 3.0.100.
Допущения о деталях реализации
Основная причина, по которой я артикулирую эту проблему, заключается в следующем: нашел в Интернете статью, где автор предлагает код с очень плохими допущениями о реализации (не буду указывать статью, так как не хочу, чтобы автора закатали комментариями; свяжусь с ним лично).
Статья рассказывает о том, как же хороша реализация по умолчанию, ведь она позволяет нам дополнять интерфейсы и после того, как в коде уже есть реализаторы. Однако, в этом коде делается ряд плохих допущений (код лежит в папке BadInterface of в моем проекте GitHub)
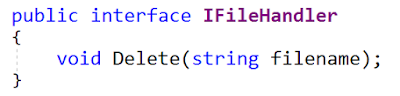
Вот оригинальный интерфейс:
Далее в статье демонстрируется реализация интерфейса «MyFile» (у меня – в файле MyFile.cs):
Затем в статье показано, как можно добавить метод
Вот обновленный интерфейс (из файла IFileHandler.cs):

MyFile по-прежнему работает, значит – все отлично. Так? Не совсем.
Плохие допущения
Главная проблема с методом «Rename» заключается в том, какое ОГРОМНОЕ допущение с ним связано: реализации используют физический файл, расположенный в файловой системе.
Рассмотрим реализацию, которую я создал для использования в файловой системе, расположенной в оперативной памяти. (Внимание: этой мой код. Он не из критикуемой мной статьи. Полную реализацию вы найдете в файле MemoryStringFileHandler.cs.)
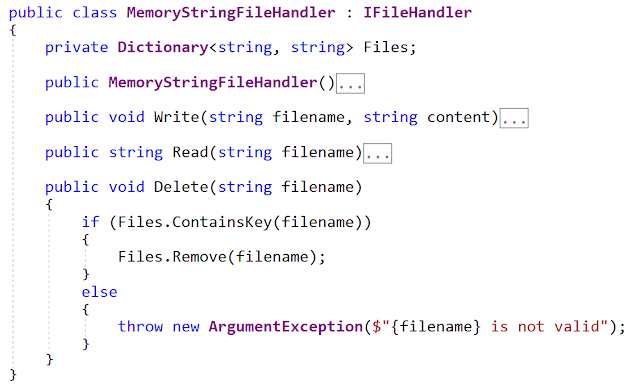
Этот класс реализует формальную файловую систему, использующую расположенный в оперативной памяти словарь, в котором содержатся текстовые файлы. Здесь нет ничего, что затрагивало бы физическую файловую систему, нет вообще никаких ссылок на
Неисправный реализатор
После обновления интерфейса этот класс оказывается поврежден.
Если клиентский код вызовет метод «Rename», то он сгенерирует ошибку времени выполнения (или, хуже того, переименует файл, хранящийся в файловой системе).
Даже если наша реализация будет работать с физическими файлами, она может обращаться к файлам, расположенным в облачном хранилище, а такие файлы не доступны через System.IO.File.
Также возможна потенциальная проблема, когда дело дойдет до модульного тестирования. Если имитационный или поддельный объект не обновлен, а тестируемый код – обновлен, то он попытается обращаться к файловой системе при выполнении модульных тестов.
Ничего не стоит счесть такие опасения необоснованными. Когда я говорю о злоупотреблениях в коде, мне отвечают: «ну, это просто человек программировать не умеет». Не могу с этим не согласиться.
Обычно поступаю так: выжидаю и присматриваюсь, как что будет работать. Например, я опасался, что возможностью «статического using» будут злоупотреблять. До сих пор в этом не пришлось убедиться.
Необходимо учитывать, что такие идеи витают в воздухе, поэтому в наших силах помочь другим свернуть на более удобный путь, идти по которому будет не так больно.
Проблемы с производительностью
Я стал задумываться о том, какие еще проблемы могут нас поджидать, если мы сделаем неверные допущения о реализаторах интерфейсов.
В предыдущем примере вызывается код, находящийся за пределами самого интерфейса (в данном случае – за пределами System.IO). Вероятно, вы согласитесь, что подобные действия – опасный звоночек. Но, если мы пользуемся вещами, уже входящими в состав интерфейса, все должно быть нормально, так ведь?
Не всегда.
В качестве экспресс-примера я создал интерфейс «IReader».
Исходный интерфейс и его реализация
Вот оригинальный интерфейс IReader (из файла IReader.cs – хотя, теперь в этом файле уже есть обновления):

Это обобщенный интерфейс с методом, позволяющий получать коллекцию элементов, доступную только для чтения.
Одна из реализаций этого интерфейса генерирует последовательность чисел Фибоначчи (да, у меня нездоровый интерес к генерации последовательностей Фибоначчи). Вот интерфейс
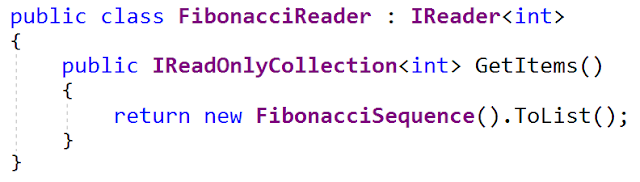
Класс

Если вас заинтересовала эта реализация, взгляните на мою статью TDDing into a Fibonacci Sequence in C#.
Проект DangerousAssumptions – это консольное приложение, выводящее на экран результаты FibonacciReader (из файла Program.cs):

А вот вывод:

Обновленный интерфейс
Итак, теперь у нас есть рабочий код. Но, рано или поздно нам может понадобиться получить из IReader отдельный элемент, а не всю коллекцию сразу. Поскольку мы используем с интерфейсом обобщенный тип, а еще у нас нет в объекте свойства «естественный ID», мы будем вытягивать элемент, расположенный по конкретному индексу.
Вот наш интерфейс, к которому добавлен метод

Отличия в производительности
Поскольку реализация по умолчанию вызывает
В случае

Так мы вызываем

Если мы поставим контрольную точку внутри файла FibonacciSequence.cs, то увидим, что для этого генерируется вся последовательность.
Запустив программу, мы дважды наткнемся на эту контрольную точку: сначала при вызове
Допущение, вредное для производительности
Наиболее серьезная проблема с этим методом заключается в том, что он требует извлечения всей коллекции элементов. Если этот
Работая с нашим
Возможно, вы скажете: «Ну, у нас же есть метод
Однако, вызывающий код ни о чем этом не знает. Если я вызываю
Конкретная оптимизация производительности
В случае

Метод
Здесь у меня используется тот же самый метод
Поскольку
Чтобы это попробовать, оставьте в приложении ту контрольную точку, которую мы сделали выше, и запустите приложение еще раз. На этот раз мы наткнемся на контрольную точку всего один раз (при вызове
Слегка надуманный пример
Этот пример немного надуманный, поскольку, как правило, не приходится выбирать элементы из множества данных по индексу. Однако, можно представить себе нечто подобное, что могло бы произойти, если бы мы работали со свойством natural ID.
Если бы мы вытягивали элементы по ID, а не по индексу, то могли бы столкнуться с теми же проблемами производительности и при реализации, заданной по умолчанию. Реализация по умолчанию требует возвращения всех элементов, после чего из них выбирается всего один. Если позволить базе данных или другому «считывателю» вытягивать конкретный элемент по его ID, такая операция была бы гораздо более эффективной.
Задумывайтесь о ваших допущениях
Без допущений не обойтись. Если бы мы пытались учесть в коде любые возможные варианты использования наших библиотек, то ни одна задача никогда не была бы завершена. Но тщательно продумывать допущения в коде все-таки нужно.
Это еще не означает, что реализация
Я, все-таки, не приветствую изменений в интерфейсе после того, как у него уже появились реализаторы. Но понимаю, что существуют и такие сценарии, в которых предпочтительны альтернативные варианты. Программирование – это решение задач, а при решении задач необходимо взвешивать все «за» и «против», присущие каждому инструменту и подходам, которые мы используем.
Реализация, задаваемая по умолчанию, потенциально может навредить реализаторам интерфейсов (а, возможно, и коду, который будет вызывать эти реализации). Поэтому нужно особенно внимательно подходить к допущениям, связанным с реализациями по умолчанию.
Удачи в работе!
В рамках проработки темы C#8 предлагаем обсудить следующую статью, посвященную новым правилам реализации интерфейсов.

Присматриваясь к тому, как в C# 8 устроены интерфейсы, необходимо учитывать, что при реализации интерфейсов по умолчанию можно наломать дров.
Допущения, связанные с реализацией по умолчанию, могут приводить к поврежденному коду, исключениям времени выполнения и низкой производительности.
Одна из активно рекламируемых фич интерфейсов C# 8 заключается в том, что к интерфейсу можно добавлять члены, не нарушая при этом имеющихся реализаторов. Но невнимательность в данном случае чревата большими проблемами. Рассмотрим код, в котором сделаны неверные допущения – так станет понятнее, насколько важно избегать подобных проблем.
Весь код к этой статье выложен на GitHub: jeremybytes/interfaces-in-csharp-8, конкретно в проекте DangerousAssumptions.
Замечание: в этой статье рассматриваются фичи C# 8, в настоящее время реализованные только в .NET Core 3.0. В приводимых примерах я использовал Visual Studio 16.3.0 и .NET Core 3.0.100.
Допущения о деталях реализации
Основная причина, по которой я артикулирую эту проблему, заключается в следующем: нашел в Интернете статью, где автор предлагает код с очень плохими допущениями о реализации (не буду указывать статью, так как не хочу, чтобы автора закатали комментариями; свяжусь с ним лично).
Статья рассказывает о том, как же хороша реализация по умолчанию, ведь она позволяет нам дополнять интерфейсы и после того, как в коде уже есть реализаторы. Однако, в этом коде делается ряд плохих допущений (код лежит в папке BadInterface of в моем проекте GitHub)
Вот оригинальный интерфейс:
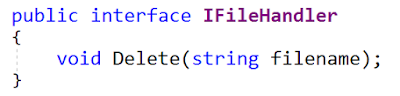
Далее в статье демонстрируется реализация интерфейса «MyFile» (у меня – в файле MyFile.cs):
Затем в статье показано, как можно добавить метод
Rename с реализацией по умолчанию, и он не сломает имеющийся класс MyFile.Вот обновленный интерфейс (из файла IFileHandler.cs):

MyFile по-прежнему работает, значит – все отлично. Так? Не совсем.
Плохие допущения
Главная проблема с методом «Rename» заключается в том, какое ОГРОМНОЕ допущение с ним связано: реализации используют физический файл, расположенный в файловой системе.
Рассмотрим реализацию, которую я создал для использования в файловой системе, расположенной в оперативной памяти. (Внимание: этой мой код. Он не из критикуемой мной статьи. Полную реализацию вы найдете в файле MemoryStringFileHandler.cs.)

Этот класс реализует формальную файловую систему, использующую расположенный в оперативной памяти словарь, в котором содержатся текстовые файлы. Здесь нет ничего, что затрагивало бы физическую файловую систему, нет вообще никаких ссылок на
System.IO.Неисправный реализатор
После обновления интерфейса этот класс оказывается поврежден.
Если клиентский код вызовет метод «Rename», то он сгенерирует ошибку времени выполнения (или, хуже того, переименует файл, хранящийся в файловой системе).
Даже если наша реализация будет работать с физическими файлами, она может обращаться к файлам, расположенным в облачном хранилище, а такие файлы не доступны через System.IO.File.
Также возможна потенциальная проблема, когда дело дойдет до модульного тестирования. Если имитационный или поддельный объект не обновлен, а тестируемый код – обновлен, то он попытается обращаться к файловой системе при выполнении модульных тестов.
Поскольку неверное допущение касается интерфейса, реализаторы этого интерфейса оказываются повреждены.Необоснованные страхи?
Ничего не стоит счесть такие опасения необоснованными. Когда я говорю о злоупотреблениях в коде, мне отвечают: «ну, это просто человек программировать не умеет». Не могу с этим не согласиться.
Обычно поступаю так: выжидаю и присматриваюсь, как что будет работать. Например, я опасался, что возможностью «статического using» будут злоупотреблять. До сих пор в этом не пришлось убедиться.
Необходимо учитывать, что такие идеи витают в воздухе, поэтому в наших силах помочь другим свернуть на более удобный путь, идти по которому будет не так больно.
Проблемы с производительностью
Я стал задумываться о том, какие еще проблемы могут нас поджидать, если мы сделаем неверные допущения о реализаторах интерфейсов.
В предыдущем примере вызывается код, находящийся за пределами самого интерфейса (в данном случае – за пределами System.IO). Вероятно, вы согласитесь, что подобные действия – опасный звоночек. Но, если мы пользуемся вещами, уже входящими в состав интерфейса, все должно быть нормально, так ведь?
Не всегда.
В качестве экспресс-примера я создал интерфейс «IReader».
Исходный интерфейс и его реализация
Вот оригинальный интерфейс IReader (из файла IReader.cs – хотя, теперь в этом файле уже есть обновления):

Это обобщенный интерфейс с методом, позволяющий получать коллекцию элементов, доступную только для чтения.
Одна из реализаций этого интерфейса генерирует последовательность чисел Фибоначчи (да, у меня нездоровый интерес к генерации последовательностей Фибоначчи). Вот интерфейс
FibonacciReader (из файла FibonacciReader.cs – у меня на гитхабе он также обновлен):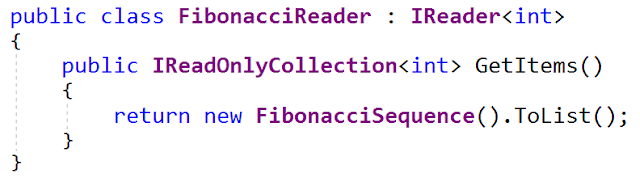
Класс
FibonacciSequence является реализацией IEnumerable <int> (из файла FibonacciSequence.cs file). В качестве типа данных он использует 32-разрядное целое число, поэтому переполнение наступает достаточно быстро.
Если вас заинтересовала эта реализация, взгляните на мою статью TDDing into a Fibonacci Sequence in C#.
Проект DangerousAssumptions – это консольное приложение, выводящее на экран результаты FibonacciReader (из файла Program.cs):

А вот вывод:

Обновленный интерфейс
Итак, теперь у нас есть рабочий код. Но, рано или поздно нам может понадобиться получить из IReader отдельный элемент, а не всю коллекцию сразу. Поскольку мы используем с интерфейсом обобщенный тип, а еще у нас нет в объекте свойства «естественный ID», мы будем вытягивать элемент, расположенный по конкретному индексу.
Вот наш интерфейс, к которому добавлен метод
GetItemAt (из окончательной версии файла IReader.cs):
GetItemAt здесь предполагает реализацию по умолчанию. На первый взгляд – не так плохо. Он использует существующий член интерфейса (GetItems), поэтому, никаких «внешних» допущений здесь не делается. С результатами он использует метод LINQ. Я большой фанат LINQ, и этот код, на мой взгляд, построен разумно.Отличия в производительности
Поскольку реализация по умолчанию вызывает
GetItems, здесь требуется, чтобы вся коллекция возвращалась еще до того, как будет выбран конкретный элемент.В случае
FibonacciReader это подразумевает, что все значения будут сгенерированы. В обновленном виде файл Program.cs будет содержать следующий код:
Так мы вызываем
GetItemAt. Вот вывод:
Если мы поставим контрольную точку внутри файла FibonacciSequence.cs, то увидим, что для этого генерируется вся последовательность.
Запустив программу, мы дважды наткнемся на эту контрольную точку: сначала при вызове
GetItems, а затем при вызове GetItemAt.Допущение, вредное для производительности
Наиболее серьезная проблема с этим методом заключается в том, что он требует извлечения всей коллекции элементов. Если этот
IReader собирается брать ее из базы данных, то из нее придется вытащить очень много элементов, а затем выбрать из них всего один. Было бы гораздо лучше, если бы такой окончательный выбор обрабатывался в базе данных.Работая с нашим
FibonacciReader, мы вычисляем каждый новый элемент. Таким образом, весь список должен быть вычислен целиком для получения всего одного элемента, который нам нужен. Расчет последовательности Фибоначчи – операция, не слишком нагружающая процессор, но что делать, если мы займемся чем-то более сложным, например, станем вычислять простые числа?Возможно, вы скажете: «Ну, у нас же есть метод
GetItems, который все возвращает. Если он работает слишком долго, то, вероятно, его здесь быть не должно. И это честное утверждение.Однако, вызывающий код ни о чем этом не знает. Если я вызываю
GetItems, то знаю, что (наверное) моя информация должна будет пройти по сети, и этот процесс будет датаинтенсивным. Если же я запрашиваю единственный элемент, то отчего бы мне ожидать подобных издержек?Конкретная оптимизация производительности
В случае
FibonacciReader мы можем добавить нашу собственную реализацию, чтобы значительно улучшить производительность (в окончательной версии файла FibonacciReader.cs):
Метод
GetItemAt переопределяет реализацию, заданную по умолчанию и предоставляемую в интерфейсе.Здесь у меня используется тот же самый метод
ElementAt из LINQ, что и в реализации по умолчанию. Однако, я применяю этот метод не с коллекцией только для чтения, которую мне возвращает „GetItems“, а с FibonacciSequence, который представляет собой IEnumerable.Поскольку
FibonacciSequence является IEnumerable, вызов ElementAt прекратится, как только программа доберется до выбранного нами элемента. Итак, мы будем генерировать не всю коллекцию, а только элементы, расположенные вплоть до указанной позиции в индексе.Чтобы это попробовать, оставьте в приложении ту контрольную точку, которую мы сделали выше, и запустите приложение еще раз. На этот раз мы наткнемся на контрольную точку всего один раз (при вызове
GetItems). При вызове GetItemAt этого не произойдет.Слегка надуманный пример
Этот пример немного надуманный, поскольку, как правило, не приходится выбирать элементы из множества данных по индексу. Однако, можно представить себе нечто подобное, что могло бы произойти, если бы мы работали со свойством natural ID.
Если бы мы вытягивали элементы по ID, а не по индексу, то могли бы столкнуться с теми же проблемами производительности и при реализации, заданной по умолчанию. Реализация по умолчанию требует возвращения всех элементов, после чего из них выбирается всего один. Если позволить базе данных или другому «считывателю» вытягивать конкретный элемент по его ID, такая операция была бы гораздо более эффективной.
Задумывайтесь о ваших допущениях
Без допущений не обойтись. Если бы мы пытались учесть в коде любые возможные варианты использования наших библиотек, то ни одна задача никогда не была бы завершена. Но тщательно продумывать допущения в коде все-таки нужно.
Это еще не означает, что реализация
GetElementAt, задаваемая по умолчанию, обязательно плоха. Да, с ней сопряжены потенциальные проблемы производительности. Однако, если множества данных невелики, либо вычисляемые элементы «дешевы», то реализация по умолчанию может быть разумным компромиссом.Я, все-таки, не приветствую изменений в интерфейсе после того, как у него уже появились реализаторы. Но понимаю, что существуют и такие сценарии, в которых предпочтительны альтернативные варианты. Программирование – это решение задач, а при решении задач необходимо взвешивать все «за» и «против», присущие каждому инструменту и подходам, которые мы используем.
Реализация, задаваемая по умолчанию, потенциально может навредить реализаторам интерфейсов (а, возможно, и коду, который будет вызывать эти реализации). Поэтому нужно особенно внимательно подходить к допущениям, связанным с реализациями по умолчанию.
Удачи в работе!
