Здравствуйте, коллеги.
В рамках проработки темы С++20 нам в свое время попалась уже довольно старенькая (сентябрь 2018) статья из хаброблога «Яндекса», которая называется "Готовимся к С++20. Coroutines TS на реальном примере". Заканчивается она следующей весьма выразительной голосовалкой:

«Почему бы и нет», — решили мы и перевели статью Давида Пиларски (Dawid Pilarski) под названием «Coroutines introduction». Статья вышла чуть более года назад, но, надеемся, все равно покажется вам очень интересной.
Итак, свершилось. После долгих сомнений, споров и подготовки этой фичи WG21 пришел к общему мнению о том, как должны выглядеть корутины в С++ — и весьма вероятно, что они войдут в C++ 20. Поскольку это крупная фича, думаю, пора готовиться и изучать ее уже сейчас (как помните, предстоит учить еще модули, концепции, диапазоны…)
Очень многие до сих пор выступают против корутин. Зачастую жалуются на сложность их освоения, множество точек кастомизации и, возможно, неоптимальной производительности из-за, возможно, недооптимизированного выделения динамической памяти (возможно ;)).
Параллельно с разработкой одобренных (официально опубликованных) технических спецификаций (ТС) даже предпринимались попытки параллельной разработки другого механизма корутин. Здесь мы поговорим именно о тех корутинах, которые описаны в TS (технической спецификации). Альтернативный подход, в свою очередь, принадлежит Google. В итоге оказалось, что и подход Google страдает от многочисленных проблем, для решения которых зачастую требуются странные дополнительные возможности C++.
В конце концов, было решено принять версию корутин, разработанных Microsoft (авторами TS). Именно о таких корутинах и пойдет речь в этой статье. Итак, начнем с вопроса о том…
Корутины уже существуют во многих языках программирования, например, в Python или C#. Корутины – это еще один способ создания асинхронного кода. Чем они отличаются от потоков, почему корутины должны быть реализованы как выделенная языковая возможность и, наконец, какая от них польза – будет объяснено в этом разделе.
Существует серьезное недополнимание относительно того, что такое корутины. В зависимости от того, в какой среде они используются, их могут называть:
Хорошая новость: стековые корутины, зеленые потоки, волокна и горутины суть одно и то же (но используются они иногда по-разному). О них мы поговорим ниже в этой статье и будем называть их волокнами или стековыми корутинами. Но у бесстековых корутин есть некоторые особенности, о которых необходимо поговорить отдельно.
Чтобы понять корутины, в том числе, и на интуитивном уровне, давайте кратко познакомимся с функциями и (позволим себе такое выражение) “их API”. Стандартный способ работы с ними – вызвать и дожидаться, пока она завершится:
После вызова функцию уже невозможно приостановить, или возобновить ее работу. Над функциями можно производить всего две операции:
С корутинами ситуация иная. Их можно не только запускать и останавливать, но также приостанавливать и возобновлять. Они все равно отличаются от потоков ядра, поскольку сами по себе корутины не являются вытесняющими (с другой стороны, корутины обычно относятся к потоку, а поток является вытесняющим). Чтобы разобраться в этом, рассмотрим генератор, определенный на Python. Пусть в Python такая штука и называется генератором, в языке C++ она называлась бы корутиной. Пример взят с этого сайта:
Вот как работает этот код: вызов функции
Итак, теперь примерно понятно, что представляют из себя корутины. Возможно, вам известно, что существуют библиотеки для создания объектов-волокон. Вопрос в том, зачем нам корутины в виде выделенной языковой возможности, а не просто библиотеки, которая обеспечивала бы работу с корутинами.
Здесь мы пытаемся ответить на этот вопрос и продемонстрировать разницу между стековыми и бесстековыми корутинами. Эта разница имеет ключевое значение для понимания корутин как части языка.
Итак, давайте сначала обсудим, что такое стековые корутины, как они работают, и почему их можно реализовать как библиотеку. Объяснить их сравнительно просто, поскольку по устройству они напоминают потоки.
У волокон или стековых корутин есть отдельный стек, который может использоваться для обработки вызовов функций. Чтобы понять, как именно работают корутины такого рода, кратко рассмотрим фреймы функций и вызовы функций с низкоуровневой точки зрения. Но сначала давайте поговорим о свойствах волокон.
Из вышеупомянутых свойств проистекают такие следствия:
Теперь давайте детально разберемся в работе волокон и для начала объясним, как стек участвует в вызовах функций.
Итак, стек – это непрерывный блок памяти, нужный для хранения локальных переменных и аргументов функций. Но, что еще важнее, после каждого вызова функции (за немногими исключениями) в стек помещается дополнительная информация, сообщающая вызванной функции, как возвратиться к вызывающей стороне и восстановить регистры процессора.
У некоторых из этих регистров есть особые назначения, и при вызовах функций они сохраняются в стеке. Вот какие это регистры (в случае архитектуры ARM):
SP – указатель стека
LR – регистр связи
PC – счетчик программ
Указатель стека (SP) – это регистр, в котором содержится адрес начала стека, относящегося к текущему вызову функции. Благодаря имеющемуся значению, можно без труда ссылаться на аргументы и локальные переменные, сохраняемые в стеке.
Регистр связи (LR) очень важен при вызовах функций. В нем хранится адрес возврата (адрес вызывающей стороны), где должен будет выполняться код после того, как выполнение текущей функции завершится. При вызове функции PC сохраняется в LR. При возврате функции PC восстанавливается при помощи LR.
Счетчик программ (PC) – это адрес инструкции, выполняемой в данный момент.
Всякий раз при вызове функции список связей сохраняется, так что функции известно, куда должна вернуться программа после того как она завершится.
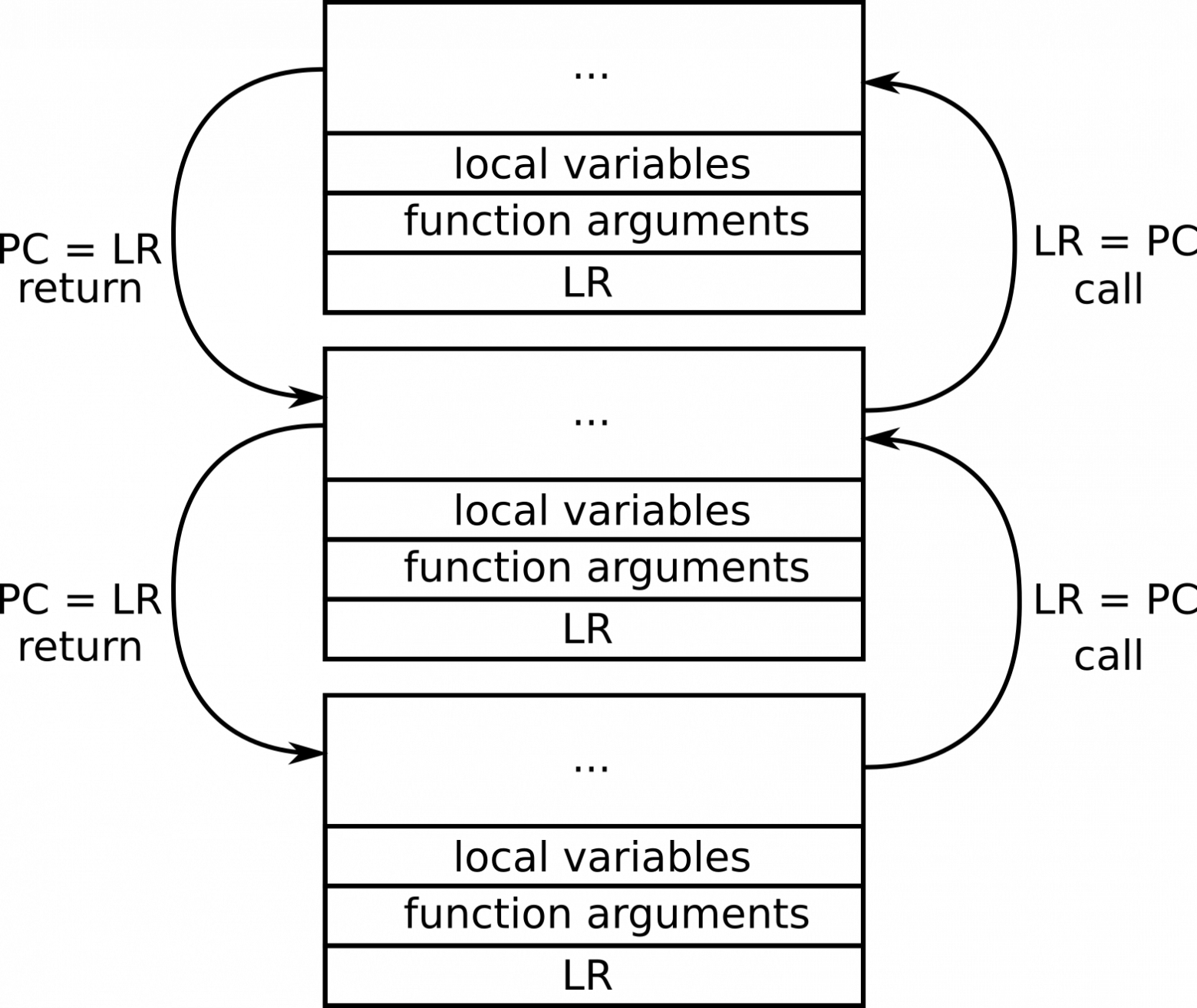
Поведение регистров PC и LR при вызове и возврате функции
При выполнении стековой корутины вызванные функции используют ранее выделенный стек для хранения ее аргументов и локальных переменных. Поскольку вся информация по каждой функции, вызываемой в стековой корутине, хранится в стеке, волокно может приостановить выполнение любой функции в рамках этой корутины.
Давайте теперь разберемся, что происходит на этой картинке. Во-первых, у каждого из волокон и потоков – свой отдельный стек. Зеленым цветом обозначены порядковые номера, указывающие, в какой последовательности происходят действия.
При работе со стековыми корутинами нет необходимости в выделенной языковой возможности, которая обеспечивала бы их использование. Целые стековые корутины вполне можно реализовать при помощи библиотек, и уже существуют библиотеки, предназначенные специально для этого:
swtch.com/libtask
code.google.com/archive/p/libconcurrency
www.boost.org Boost.Fiber
www.boost.org Boost.Coroutine
Из всех этих библиотек только Boost относится к C++, а все остальные — к C.
Подробное описание работы этих библиотек приводится в документации. Но, в целом, все эти библиотеки позволяют создать отдельный стек для волокна и предоставляют возможность возобновить корутину (по инициативе вызывающей стороны) и приостановить ее (изнутри).
Рассмотрим пример
В случае Boost.Fiber в библиотеке есть встроенный планировщик для корутин. Все волокна выполняются в одном и том же потоке. Поскольку планирование корутин является кооперативным, волокно сначала должно определиться с тем, когда возвращать контроль планировщику. В данном примере это происходит при вызове функции yield, которая приостанавливает корутину.
Поскольку другого волокна нет, планировщик волокон всегда решает возобновить работу корутины.
Бесстековые корутины немного отличаются по свойствам от стековых. Однако, основные характеристики у них те же, поскольку бесстековые корутины так же можно запускать, а после их приостановки – возобновлять. Корутины именно такого типа мы, скорее всего, найдем в C++20.
Если говорить о схожих свойствах корутин – корутины могут:
Однако, в случае бесстековых корутин нет необходимости выделять целый стек. Они потребляют гораздо меньше памяти, чем стековые, но именно этим и обусловлены некоторые их ограничения.
Начнем с того, что, если они не выделяют память для стека, то как же они работают? Куда в их случае идут все данные, которые при работе со стековыми корутинами должны храниться в стеке. Ответ: в стеке вызывающей стороны.
Секрет бесстековых корутин заключается в том, что они могут приостанавливать себя только из самой верхней функции. Для всех остальных функций их данные располагаются в стеке вызываемой стороны, поэтому все функции, вызванные из корутины должны завершиться до того, как работа корутины будет приостановлена. Все данные, необходимые корутине для сохранения ее состояния, динамически выделяются в куче. Обычно для этого требуется пара локальных переменных и аргументов, которые гораздо компактнее, чем целый стек, который пришлось бы выделять заранее.
Взгляните, как работают бесстековые корутины:
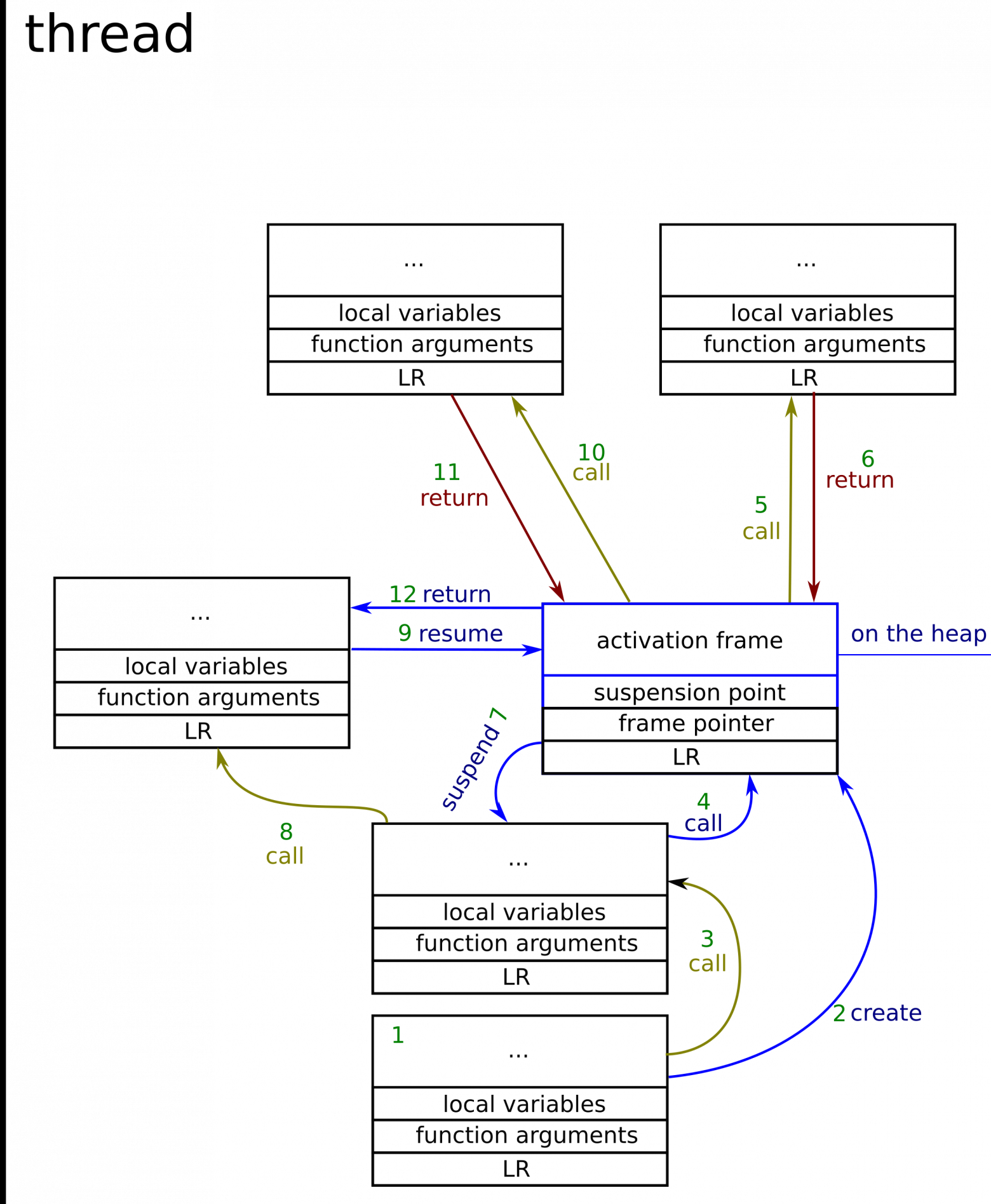
Вызов бесстековой корутины
Как видим, теперь стек всего один – это главный стек потока. Давайте пошагово разберем, что показано на этой картинке (фрейм активации корутины здесь двухцветный – черным показано, что сохранено в стеке, а синим – что сохранено в куче).
Итак, очевидно, что во втором случае требуется запоминать гораздо меньше данных для всех операций приостановки и возобновления работы корутин, однако корутина может возобновлять и приостанавливать только сама себя, причем, только из самой верхней функции. Все вызовы функций и корутин происходят одинаково, однако, между вызовами требуется сохранять некоторые дополнительные данные, а функция должна уметь перепрыгивать к точке приостановки и восстанавливать состояние локальных переменных. Никаких других отличий между фреймом корутины и фреймом функции нет.
Корутина также может вызывать другие корутины (в данном примере это не показано). В случае с бесстековыми корутинами каждый вызов приводит к выделению нового пространства для новых данных корутин (при многократном вызове корутины динамическая память также может выделяться по несколько раз).
Причина, по которой для корутин необходимо предусмотреть выделенную языковую возможность – в том, что компилятору требуется решать, какие переменные описывают состояние корутины, и создавать стереотипный код для перепрыгивания к точкам приостановки.
Корутины в C++ могут использоваться такими же способами, как и в других языках. Корутины позволят упростить написание:
Надеюсь, что, прочитав эту статью, вы узнали:
В рамках проработки темы С++20 нам в свое время попалась уже довольно старенькая (сентябрь 2018) статья из хаброблога «Яндекса», которая называется "Готовимся к С++20. Coroutines TS на реальном примере". Заканчивается она следующей весьма выразительной голосовалкой:

«Почему бы и нет», — решили мы и перевели статью Давида Пиларски (Dawid Pilarski) под названием «Coroutines introduction». Статья вышла чуть более года назад, но, надеемся, все равно покажется вам очень интересной.
Итак, свершилось. После долгих сомнений, споров и подготовки этой фичи WG21 пришел к общему мнению о том, как должны выглядеть корутины в С++ — и весьма вероятно, что они войдут в C++ 20. Поскольку это крупная фича, думаю, пора готовиться и изучать ее уже сейчас (как помните, предстоит учить еще модули, концепции, диапазоны…)
Очень многие до сих пор выступают против корутин. Зачастую жалуются на сложность их освоения, множество точек кастомизации и, возможно, неоптимальной производительности из-за, возможно, недооптимизированного выделения динамической памяти (возможно ;)).
Параллельно с разработкой одобренных (официально опубликованных) технических спецификаций (ТС) даже предпринимались попытки параллельной разработки другого механизма корутин. Здесь мы поговорим именно о тех корутинах, которые описаны в TS (технической спецификации). Альтернативный подход, в свою очередь, принадлежит Google. В итоге оказалось, что и подход Google страдает от многочисленных проблем, для решения которых зачастую требуются странные дополнительные возможности C++.
В конце концов, было решено принять версию корутин, разработанных Microsoft (авторами TS). Именно о таких корутинах и пойдет речь в этой статье. Итак, начнем с вопроса о том…
Что такое корутины?
Корутины уже существуют во многих языках программирования, например, в Python или C#. Корутины – это еще один способ создания асинхронного кода. Чем они отличаются от потоков, почему корутины должны быть реализованы как выделенная языковая возможность и, наконец, какая от них польза – будет объяснено в этом разделе.
Существует серьезное недополнимание относительно того, что такое корутины. В зависимости от того, в какой среде они используются, их могут называть:
- Бесстековые корутины
- Стековые корутины
- Зеленые потоки
- Волокна
- Горутины
Хорошая новость: стековые корутины, зеленые потоки, волокна и горутины суть одно и то же (но используются они иногда по-разному). О них мы поговорим ниже в этой статье и будем называть их волокнами или стековыми корутинами. Но у бесстековых корутин есть некоторые особенности, о которых необходимо поговорить отдельно.
Чтобы понять корутины, в том числе, и на интуитивном уровне, давайте кратко познакомимся с функциями и (позволим себе такое выражение) “их API”. Стандартный способ работы с ними – вызвать и дожидаться, пока она завершится:
void foo(){
return; // здесь мы выходим из функции
}
foo(); // здесь мы вызываем/запускаем функциюПосле вызова функцию уже невозможно приостановить, или возобновить ее работу. Над функциями можно производить всего две операции:
start и finish. Когда функция запущена, необходимо дожидаться, пока она завершится. Если функция будет вызвана повторно, то ее выполнение пойдет с самого начала.С корутинами ситуация иная. Их можно не только запускать и останавливать, но также приостанавливать и возобновлять. Они все равно отличаются от потоков ядра, поскольку сами по себе корутины не являются вытесняющими (с другой стороны, корутины обычно относятся к потоку, а поток является вытесняющим). Чтобы разобраться в этом, рассмотрим генератор, определенный на Python. Пусть в Python такая штука и называется генератором, в языке C++ она называлась бы корутиной. Пример взят с этого сайта:
def generate_nums():
num = 0
while True:
yield num
num = num + 1
nums = generate_nums()
for x in nums:
print(x)
if x > 9:
breakВот как работает этот код: вызов функции
generate_nums приводит к созданию объекта корутины. На каждом этапе перебора объекта корутины, сама корутина возобновляет работу и приостанавливает ее только после ключевого слова yield в коде; тогда же возвращается следующее целое число из последовательности (цикл for представляет собой синтаксический сахар для вызова функции next(), возобновляющей корутину). Код завершает цикл, встретив инструкцию break. В данном случае корутина не заканчивается никогда, но легко представить ситуацию, в которой корутина достигает конца и завершается. Как видим, к такой корутине применимы операции start, suspend, resume и, наконец, finish. [Замечание: в языке C++ также предусмотрены операции создания и разрушения, но они не важны в контексте интуитивного понимания корутины].Корутины как библиотека
Итак, теперь примерно понятно, что представляют из себя корутины. Возможно, вам известно, что существуют библиотеки для создания объектов-волокон. Вопрос в том, зачем нам корутины в виде выделенной языковой возможности, а не просто библиотеки, которая обеспечивала бы работу с корутинами.
Здесь мы пытаемся ответить на этот вопрос и продемонстрировать разницу между стековыми и бесстековыми корутинами. Эта разница имеет ключевое значение для понимания корутин как части языка.
Стековые корутины
Итак, давайте сначала обсудим, что такое стековые корутины, как они работают, и почему их можно реализовать как библиотеку. Объяснить их сравнительно просто, поскольку по устройству они напоминают потоки.
У волокон или стековых корутин есть отдельный стек, который может использоваться для обработки вызовов функций. Чтобы понять, как именно работают корутины такого рода, кратко рассмотрим фреймы функций и вызовы функций с низкоуровневой точки зрения. Но сначала давайте поговорим о свойствах волокон.
- У них есть собственный стек,
- Время жизни волокон не зависит от кода, который их вызывает (обычно у них есть планировщик, определяемый пользователем),
- Волокна можно откреплять от одного потока и прикреплять к другому,
- Кооперативное планирование (волокно должно принимать решение о переключении на другое волокно/планировщик),
- Не могут работать одновременно в одном и том же потоке.
Из вышеупомянутых свойств проистекают такие следствия:
- переключение контекста волокон должно осуществляться самим пользователем волокон, а не ОС (кроме того, ОС может отпустить волокно, отпустив тот поток, в котором оно работает),
- Не возникает никакой реальной гонки данных между двумя волокнами, поскольку в любой момент времени активно может быть лишь одно из них,
- Разработчик волокон должен уметь правильно выбирать место и время, где и когда уместно возвращать вычислительные мощности возможному планировщику или вызывающей стороне.
- Операции ввода/вывода в волокне должны быть асинхронными, так, чтобы другие волокна могли выполнять свои задачи, не блокируя друг друга.
Теперь давайте детально разберемся в работе волокон и для начала объясним, как стек участвует в вызовах функций.
Итак, стек – это непрерывный блок памяти, нужный для хранения локальных переменных и аргументов функций. Но, что еще важнее, после каждого вызова функции (за немногими исключениями) в стек помещается дополнительная информация, сообщающая вызванной функции, как возвратиться к вызывающей стороне и восстановить регистры процессора.
У некоторых из этих регистров есть особые назначения, и при вызовах функций они сохраняются в стеке. Вот какие это регистры (в случае архитектуры ARM):
SP – указатель стека
LR – регистр связи
PC – счетчик программ
Указатель стека (SP) – это регистр, в котором содержится адрес начала стека, относящегося к текущему вызову функции. Благодаря имеющемуся значению, можно без труда ссылаться на аргументы и локальные переменные, сохраняемые в стеке.
Регистр связи (LR) очень важен при вызовах функций. В нем хранится адрес возврата (адрес вызывающей стороны), где должен будет выполняться код после того, как выполнение текущей функции завершится. При вызове функции PC сохраняется в LR. При возврате функции PC восстанавливается при помощи LR.
Счетчик программ (PC) – это адрес инструкции, выполняемой в данный момент.
Всякий раз при вызове функции список связей сохраняется, так что функции известно, куда должна вернуться программа после того как она завершится.

Поведение регистров PC и LR при вызове и возврате функции
При выполнении стековой корутины вызванные функции используют ранее выделенный стек для хранения ее аргументов и локальных переменных. Поскольку вся информация по каждой функции, вызываемой в стековой корутине, хранится в стеке, волокно может приостановить выполнение любой функции в рамках этой корутины.
Давайте теперь разберемся, что происходит на этой картинке. Во-первых, у каждого из волокон и потоков – свой отдельный стек. Зеленым цветом обозначены порядковые номера, указывающие, в какой последовательности происходят действия.
- Обычный вызов функции внутри потока. Выделение памяти производится в стеке.
- Функция создает объект волокна. В результате выделяется стек под волокно. Создание волокна еще не означает, что оно сразу же будет выполнено. Также выделяется фрейм активации. Данные во фрейме активации заданы таким образом, что сохранение его содержимого в регистры процессора приведет к переключению контекста на стек волокна.
- Обычный вызов функции.
- Вызов корутины. Для регистров процессора задается контент фрейма активации.
- Обычный вызов функции внутри корутины.
- Обычный вызов функции внутри корутины.
- Корутина приостанавливается. Содержимое фрейма активации обновляется, и устанавливаются регистры процессора, так, что контекст возвращается к стеку потока.
- Обычный вызов функции внутри потока.
- Обычный вызов функции внутри потока.
- Возобновление корутины – происходит примерно то же самое, что и при вызове корутины.
- Фрейм активации запоминает состояние тех регистров процессора внутри корутины, которые были установлены при приостановке корутины.
- Обычный вызов функции внутри корутины. Фрейм функции выделяется в стеке корутины.
- Ситуация на картинке показана в несколько упрощенном виде. Теперь происходит вот что: работа корутины заканчивается, и весь стек раскручивается. Однако, на самом деле возврат из корутины происходит через нижнюю (а не верхнюю) функцию.
- Обычный возврат функции, как и выше.
- Обычный возврат функции.
- Возврат корутины. Стек корутины пуст. Контекст переключается обратно к потоку. Начиная с этого момента, работа волокна не может быть возобновлена.
- Обычный вызов функции в контексте потока.
- Позже функции могут продолжать работу или завершаться, так, что раскрутка стека полностью завершится.
При работе со стековыми корутинами нет необходимости в выделенной языковой возможности, которая обеспечивала бы их использование. Целые стековые корутины вполне можно реализовать при помощи библиотек, и уже существуют библиотеки, предназначенные специально для этого:
swtch.com/libtask
code.google.com/archive/p/libconcurrency
www.boost.org Boost.Fiber
www.boost.org Boost.Coroutine
Из всех этих библиотек только Boost относится к C++, а все остальные — к C.
Подробное описание работы этих библиотек приводится в документации. Но, в целом, все эти библиотеки позволяют создать отдельный стек для волокна и предоставляют возможность возобновить корутину (по инициативе вызывающей стороны) и приостановить ее (изнутри).
Рассмотрим пример
Boost.Fiber:#include <cstdlib>
#include <iostream>
#include <memory>
#include <string>
#include <thread>
#include <boost/intrusive_ptr.hpp>
#include <boost/fiber/all.hpp>
inline
void fn( std::string const& str, int n) {
for ( int i = 0; i < n; ++i) {
std::cout << i << ": " << str << std::endl;
boost::this_fiber::yield();
}
}
int main() {
try {
boost::fibers::fiber f1( fn, "abc", 5);
std::cerr << "f1 : " << f1.get_id() << std::endl;
f1.join();
std::cout << "done." << std::endl;
return EXIT_SUCCESS;
} catch ( std::exception const& e) {
std::cerr << "exception: " << e.what() << std::endl;
} catch (...) {
std::cerr << "unhandled exception" << std::endl;
}
return EXIT_FAILURE;
}В случае Boost.Fiber в библиотеке есть встроенный планировщик для корутин. Все волокна выполняются в одном и том же потоке. Поскольку планирование корутин является кооперативным, волокно сначала должно определиться с тем, когда возвращать контроль планировщику. В данном примере это происходит при вызове функции yield, которая приостанавливает корутину.
Поскольку другого волокна нет, планировщик волокон всегда решает возобновить работу корутины.
Бесстековые корутины
Бесстековые корутины немного отличаются по свойствам от стековых. Однако, основные характеристики у них те же, поскольку бесстековые корутины так же можно запускать, а после их приостановки – возобновлять. Корутины именно такого типа мы, скорее всего, найдем в C++20.
Если говорить о схожих свойствах корутин – корутины могут:
- Корутина тесно связана со своей вызывающей стороной: при вызове корутины исполнение передается ей, а итог работы корутины передается обратно вызывающей стороне.
- Длительность жизни стековой корутины равна жизни ее стека. Длительность жизни бесстековой корутины равна жизни ее объекта.
Однако, в случае бесстековых корутин нет необходимости выделять целый стек. Они потребляют гораздо меньше памяти, чем стековые, но именно этим и обусловлены некоторые их ограничения.
Начнем с того, что, если они не выделяют память для стека, то как же они работают? Куда в их случае идут все данные, которые при работе со стековыми корутинами должны храниться в стеке. Ответ: в стеке вызывающей стороны.
Секрет бесстековых корутин заключается в том, что они могут приостанавливать себя только из самой верхней функции. Для всех остальных функций их данные располагаются в стеке вызываемой стороны, поэтому все функции, вызванные из корутины должны завершиться до того, как работа корутины будет приостановлена. Все данные, необходимые корутине для сохранения ее состояния, динамически выделяются в куче. Обычно для этого требуется пара локальных переменных и аргументов, которые гораздо компактнее, чем целый стек, который пришлось бы выделять заранее.
Взгляните, как работают бесстековые корутины:

Вызов бесстековой корутины
Как видим, теперь стек всего один – это главный стек потока. Давайте пошагово разберем, что показано на этой картинке (фрейм активации корутины здесь двухцветный – черным показано, что сохранено в стеке, а синим – что сохранено в куче).
- Обычный вызов функции, чей фрейм сохраняется в стеке
- Функция создает корутину. То есть, выделяет для нее фрейм активации где-нибудь в куче.
- Обычный вызов функции.
- Вызов корутины. Тело корутины выделяется в обычном стеке. Программа выполняется таким же образом, как и в случае обычной функции.
- Обычный вызов функции из корутины. Опять же, все по-прежнему происходит в стеке [Примечание: из этой точки корутину приостановить нельзя, поскольку это не самая верхняя функция в корутине]
- Функция возвращается к самой верхней функции корутины [Примечание: теперь корутина может приостановить себя.]
- Корутина приостанавливается – все данные, которые нужно было сохранить из всех вызовов корутин, теперь записываются во фрейм активации.
- Обычный вызов функции
- Корутина возобновляет работу – это происходит как обычный вызов функции, но с прыжком к предыдущей точке приостановки + восстановлением переменных из фрейма активации.
- Вызов функции как в пункте 5.
- Возврат функции как в пункте 6.
- Возврат корутины. С этого момента возобновить работу корутины уже невозможно.
Итак, очевидно, что во втором случае требуется запоминать гораздо меньше данных для всех операций приостановки и возобновления работы корутин, однако корутина может возобновлять и приостанавливать только сама себя, причем, только из самой верхней функции. Все вызовы функций и корутин происходят одинаково, однако, между вызовами требуется сохранять некоторые дополнительные данные, а функция должна уметь перепрыгивать к точке приостановки и восстанавливать состояние локальных переменных. Никаких других отличий между фреймом корутины и фреймом функции нет.
Корутина также может вызывать другие корутины (в данном примере это не показано). В случае с бесстековыми корутинами каждый вызов приводит к выделению нового пространства для новых данных корутин (при многократном вызове корутины динамическая память также может выделяться по несколько раз).
Причина, по которой для корутин необходимо предусмотреть выделенную языковую возможность – в том, что компилятору требуется решать, какие переменные описывают состояние корутины, и создавать стереотипный код для перепрыгивания к точкам приостановки.
Практическое применение корутин
Корутины в C++ могут использоваться такими же способами, как и в других языках. Корутины позволят упростить написание:
- генераторов
- асинхронного кода ввода/вывода
- ленивых вычислений
- событийно-ориентированных приложений
Итоги
Надеюсь, что, прочитав эту статью, вы узнали:
- почему в C++ требуется реализовать корутины в виде выделенной языковой возможности
- в чем разница между стековыми и бесстековыми корутинами
- зачем нужны корутины
