Сотрудники Сеульского университета опубликовали исследование о симуляции движения двуногих персонажей на основе работы суставов и мышечных сокращений, использующей нейросеть с Deep Reinforcement Learning. Под катом перевод краткого обзора.

Меня зовут Jehee Lee. Я профессор Сеульского национального университета и исследователь компьютерной графики с более чем 25-летним опытом работы. Я изучаю новые способы понимания, представления и симуляции движений человека и животного.
Симуляция движений двуногих персонажей на основе физики — это известная проблема в области робототехники и компьютерной графики еще с середины 80-х. В 90-х годах большинство двуногих контроллеров были основаны на упрощенной динамической модели (например, на перевернутом маятнике), что позволяло использовать стратегию баланса, которую можно вывести в уравнении замкнутой формы. С 2007 года появились контроллеры, использующие динамику всего тела для достижения быстрого прогресса в этой области. Примечательно, что теория оптимального управления и методы стохастической оптимизации, такие как CMS-ES, были основными инструментами для поддержания баланса имитируемых двуногих.
Постепенно исследователи строили более детальные модели человеческого тела. В 1990 году модель перевернутого маятника имела менее пяти степеней свободы. В 2007 году динамическая модель представляла собой 2D-фигурку, приводимую в движение двигателями на стыках с десятками степеней свободы. В 2009-2010 появились полные 3D-модели со 100 степенями свободы.
В 2012-2014 появились контроллеры для биомеханических моделей, приводимые в движение мышцами. Контроллер посылает сигнал на каждую отдельную мышцу в каждый момент времени для их стимуляции. Сокращение мышц тянет прикрепленные кости и приводит их в движение. В своей работе мы использовали 326 мышц для перемещения модели, включая все основные мышцы нашего тела, за исключением некоторых небольших.
Количество степеней свободы динамической системы быстро увеличивалось с 2007 года. Предыдущие подходы к проектированию контроллеров страдали от «проклятия размерности» — когда требуемые вычислительные ресурсы (время и память) увеличиваются экспоненциально по мере увеличения количества степеней свободы.
Мы использовали Deep Reinforcement Learning для решения проблем, связанных со сложностью модели опорно-двигательного аппарата и масштабируемостью контроля двуногих существ. Сети могут эффективно представлять и хранить политики многомерного управления (функция, которая сопоставляет состояния с действиями) и исследовать невидимые состояния и действия.

Основное улучшение заключается в том, как мы справляемся с мышечной активацией всего тела. Мы создали иерархическую сеть, которая в верхних слоях учится имитировать движение суставов на низкой частоте кадров (30 Гц), а на нижних — учится стимулировать мышцы на высоких частотах (1500 Гц).
Динамика сокращения мышц требует большей точности, чем при симуляции скелета. Наша иерархическая структура позволяет устранить расхождения в требованиях.

Приятно видеть, как работает наш алгоритм на широком спектре движений человека. Мы еще не знаем, насколько он на самом деле широк и пытаемся понять границы. Пока что мы их не достигли из-за лимита вычислительных ресурсов.
Новый подход дает улучшенные результаты каждый раз, когда мы вкладываем больше ресурсов (в основном ядер процессора). Хороший момент в том, что Deep Reinforcement Learning требует вычислительных затрат только на этапе обучения. Как только политика многомерного управлениям изучена, симуляция и управление выполняются быстро. Симуляция костно-мышечной системы скоро будет работать в интерактивных приложениях в режиме реального времени. Например, в играх.
Мы используем мышечную модель Хилла, которая де-факто является стандартом в биомеханике. Наш алгоритм очень гибкий, поэтому в него можно включить любую динамическую модель сокращения мышц. Использование высокоточной модели мышц позволяет генерировать движения человека в различных условиях, включая патологии, протезы и так далее.
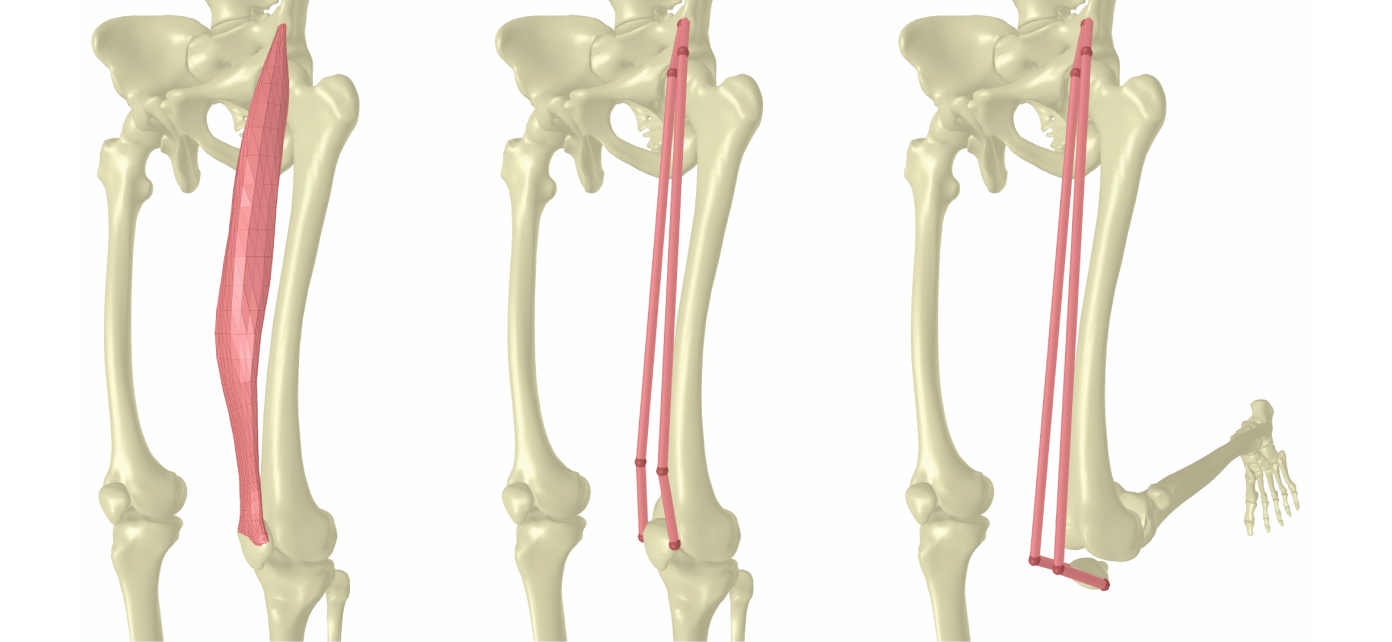
Прямая мышца бедра. 3D surface mesh (слева). Аппроксимация с путевыми точками (по центру). Приблизительные LBS-координаты путевых точек при сгибе колена (справа).
Мы разделяем ту же фундаментальную идею с исследованием передвижения Deepmind, которое основано на модели stick-and-motor. Удивительно, но стандартный алгоритм DRL хорошо работает с моделью stick-and-motor, но он не очень хорошо работает с биомеханическими моделями, приводимыми в действие мышцами.
На прошлой выставке NeurlPS 2018 прошел челлендж ИИ для протезирования. В конкурсной модели всего 20+ мышц, но даже у победителя результат выглядит не самым лучшим образом.
Этот пример показывает сложность обучения моделей, приводимых в действие мышцами. Наша иерархическая модель делает прорыв и позволяет применить DRL к биомеханической модели человека с большим количеством мышц.
Проект в PDF.
Проект на Github.
Тему исследовали: Jehee Lee, Seunghwan Lee, Kyoungmin Lee и Moonseok Park.
Меня зовут Jehee Lee. Я профессор Сеульского национального университета и исследователь компьютерной графики с более чем 25-летним опытом работы. Я изучаю новые способы понимания, представления и симуляции движений человека и животного.
Симуляция движений двуногих персонажей на основе физики — это известная проблема в области робототехники и компьютерной графики еще с середины 80-х. В 90-х годах большинство двуногих контроллеров были основаны на упрощенной динамической модели (например, на перевернутом маятнике), что позволяло использовать стратегию баланса, которую можно вывести в уравнении замкнутой формы. С 2007 года появились контроллеры, использующие динамику всего тела для достижения быстрого прогресса в этой области. Примечательно, что теория оптимального управления и методы стохастической оптимизации, такие как CMS-ES, были основными инструментами для поддержания баланса имитируемых двуногих.
Постепенно исследователи строили более детальные модели человеческого тела. В 1990 году модель перевернутого маятника имела менее пяти степеней свободы. В 2007 году динамическая модель представляла собой 2D-фигурку, приводимую в движение двигателями на стыках с десятками степеней свободы. В 2009-2010 появились полные 3D-модели со 100 степенями свободы.
В 2012-2014 появились контроллеры для биомеханических моделей, приводимые в движение мышцами. Контроллер посылает сигнал на каждую отдельную мышцу в каждый момент времени для их стимуляции. Сокращение мышц тянет прикрепленные кости и приводит их в движение. В своей работе мы использовали 326 мышц для перемещения модели, включая все основные мышцы нашего тела, за исключением некоторых небольших.
Сложность в управлении движением двуногого персонажа
Количество степеней свободы динамической системы быстро увеличивалось с 2007 года. Предыдущие подходы к проектированию контроллеров страдали от «проклятия размерности» — когда требуемые вычислительные ресурсы (время и память) увеличиваются экспоненциально по мере увеличения количества степеней свободы.
Мы использовали Deep Reinforcement Learning для решения проблем, связанных со сложностью модели опорно-двигательного аппарата и масштабируемостью контроля двуногих существ. Сети могут эффективно представлять и хранить политики многомерного управления (функция, которая сопоставляет состояния с действиями) и исследовать невидимые состояния и действия.
Новый подход
Основное улучшение заключается в том, как мы справляемся с мышечной активацией всего тела. Мы создали иерархическую сеть, которая в верхних слоях учится имитировать движение суставов на низкой частоте кадров (30 Гц), а на нижних — учится стимулировать мышцы на высоких частотах (1500 Гц).
Динамика сокращения мышц требует большей точности, чем при симуляции скелета. Наша иерархическая структура позволяет устранить расхождения в требованиях.
Чего мы достигли
Приятно видеть, как работает наш алгоритм на широком спектре движений человека. Мы еще не знаем, насколько он на самом деле широк и пытаемся понять границы. Пока что мы их не достигли из-за лимита вычислительных ресурсов.
Новый подход дает улучшенные результаты каждый раз, когда мы вкладываем больше ресурсов (в основном ядер процессора). Хороший момент в том, что Deep Reinforcement Learning требует вычислительных затрат только на этапе обучения. Как только политика многомерного управлениям изучена, симуляция и управление выполняются быстро. Симуляция костно-мышечной системы скоро будет работать в интерактивных приложениях в режиме реального времени. Например, в играх.
Мы используем мышечную модель Хилла, которая де-факто является стандартом в биомеханике. Наш алгоритм очень гибкий, поэтому в него можно включить любую динамическую модель сокращения мышц. Использование высокоточной модели мышц позволяет генерировать движения человека в различных условиях, включая патологии, протезы и так далее.

Прямая мышца бедра. 3D surface mesh (слева). Аппроксимация с путевыми точками (по центру). Приблизительные LBS-координаты путевых точек при сгибе колена (справа).
Использование Deep Reinforcement Learning (DRL)
Мы разделяем ту же фундаментальную идею с исследованием передвижения Deepmind, которое основано на модели stick-and-motor. Удивительно, но стандартный алгоритм DRL хорошо работает с моделью stick-and-motor, но он не очень хорошо работает с биомеханическими моделями, приводимыми в действие мышцами.
На прошлой выставке NeurlPS 2018 прошел челлендж ИИ для протезирования. В конкурсной модели всего 20+ мышц, но даже у победителя результат выглядит не самым лучшим образом.
Этот пример показывает сложность обучения моделей, приводимых в действие мышцами. Наша иерархическая модель делает прорыв и позволяет применить DRL к биомеханической модели человека с большим количеством мышц.
Проект в PDF.
Проект на Github.
Тему исследовали: Jehee Lee, Seunghwan Lee, Kyoungmin Lee и Moonseok Park.







