
Спустя два года после запуска Turing в сентябре 2020 года NVIDIA сменила архитектуру своих видеокарт на Ampere. AMD не осталась в стороне и вскоре после этого тоже обновила архитектуру RDNA до второй версии.
Всем хотелось, чтобы новые видеокарты RX 6000 могли составить конкуренцию лучшим продуктам NVIDIA. И теперь, когда обе серии вышли в продажу, геймеры оказались избалованы выбором (по крайней мере, теоретически), куда вложить свои деньги.
Но что насчет чипов, лежащих в их основе? Какой из них лучше?
Размеры кристаллов
На протяжении долгих лет графические процессоры были больше центральных и продолжают неуклонно расти. Площадь последнего ГП AMD составляет примерно 520 мм2, что более чем в два раза больше их предыдущего чипа Navi. При этом он все еще не самый большой: эта честь принадлежит графическому процессору в новом ускорителе Instinct MI100 с площадью порядка 750 мм2.
В последний раз AMD производила игровой процессор размером примерно с Navi 21 для карт Radeon R9 Fury и Nano, которые имели архитектуру GCN 3.0 в чипе Fiji. Его площадь составляла 596 мм2.
С 2018 года AMD использует в работе 7-нм процесс от TSMC, и самым большим чипом из этой производственной линейки был Vega 20 (из Radeon VII) с площадью 331 мм2. Все графические процессоры Navi созданы на основе слегка обновленной версии этого процесса, называемой N7P.
И все же, что касается размеров кристалла, корона остается за NVIDIA, но не то чтобы это было хорошо. Последний чип на базе Ampere, GA102, имеет площадь 628 мм2. Это примерно на 17% меньше, чем у его предка, TU102: он имел ошеломляющую площадь кристалла в 754 мм2. Но все это ничто по сравнению с монструозным чипом NVIDIA GA100: используемый в ИИ и обработке данных, этот 7-нм графический процессор имеет площадь 826 мм2. Он наглядно показывает, каких размеров может достичь графический процессор.
По сравнению с ГП NVIDIA Navi 21 выглядит довольно стройно, хотя стоит помнить, что процессор — это не только кристалл. GA102 содержит около 28,3 миллиарда транзисторов, тогда как новый чип AMD на 5% меньше — 26,8 миллиарда.

Мы не знаем, из скольких слоев состоит каждый из этих ГП, поэтому все, что мы можем сравнить, — это отношение транзисторов к площади кристалла, обычно называемое плотностью кристалла. Navi 21 имеет примерно 51,5 млн транзисторов на квадратный мм, в GA102 она заметно ниже — 41,1 млн.
Navi 21 производится у TSMC в соответствии с процессом N7P, который дает небольшое увеличение производительности по сравнению с N7. Свои новые чипы GA102 NVIDIA предпочла производить у Samsung. В них используется модифицированная специально для NVIDIA версия так называемого 8-нм узла (обозначаемого как 8N или 8NN). Значения узлов 7 и 8 имеют мало общего с фактическим размером компонентов: это просто маркетинговые термины, используемые для различения производственных технологий.
Теперь давайте углубимся в компоновку каждого графического процессора и посмотрим, что находится у них под капотами.
Внутри кристаллов
Общая структура Ampere GA102 и RDNA 2 Navi 21
Схемы ниже не обязательно показывают, как все устроено физически, но они дают четкое представление о том, из каких компонентов состоят процессоры.
В обоих случаях макеты очень знакомы, поскольку они по сути являются расширенными версиями своих предшественников. Добавление большего количества компонентов повышает производительность, что особенно полезно при условии, что при высоких разрешениях в современных 3D-приложениях рабочие нагрузки рендеринга включают огромное число параллельных вычислений.
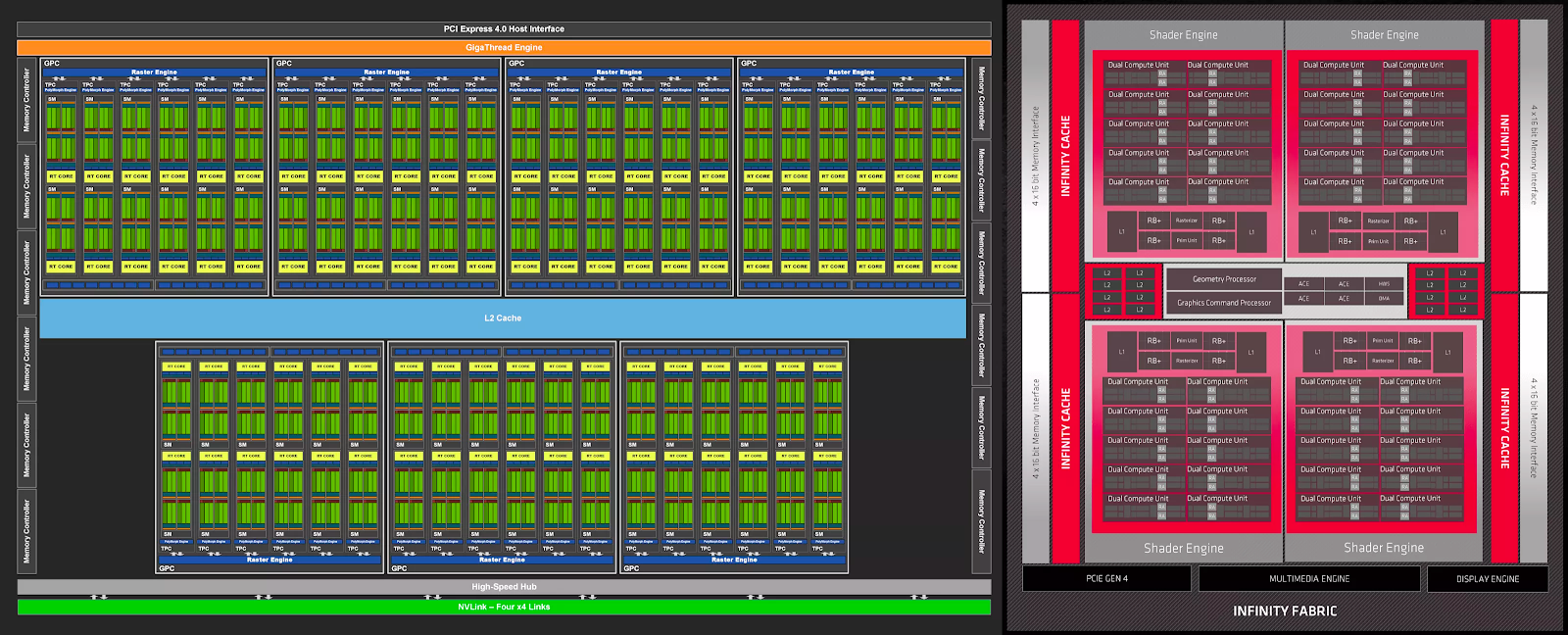
Такие схемы полезны, но для нашего анализа интереснее посмотреть, где находятся различные компоненты внутри самих кристаллов. При проектировании крупномасштабного процессора обычно требуется, чтобы общие ресурсы, такие как контроллеры и кэш, находились в центре, чтобы гарантировать, что все компоненты имеют одинаковый путь к ним.
Интерфейсные системы вроде контроллеров локальной памяти или видеовыходов должны располагаться по краям микросхемы, чтобы упростить их подключение к тысячам отдельных проводов, соединяющих графический процессор с остальной частью карты.
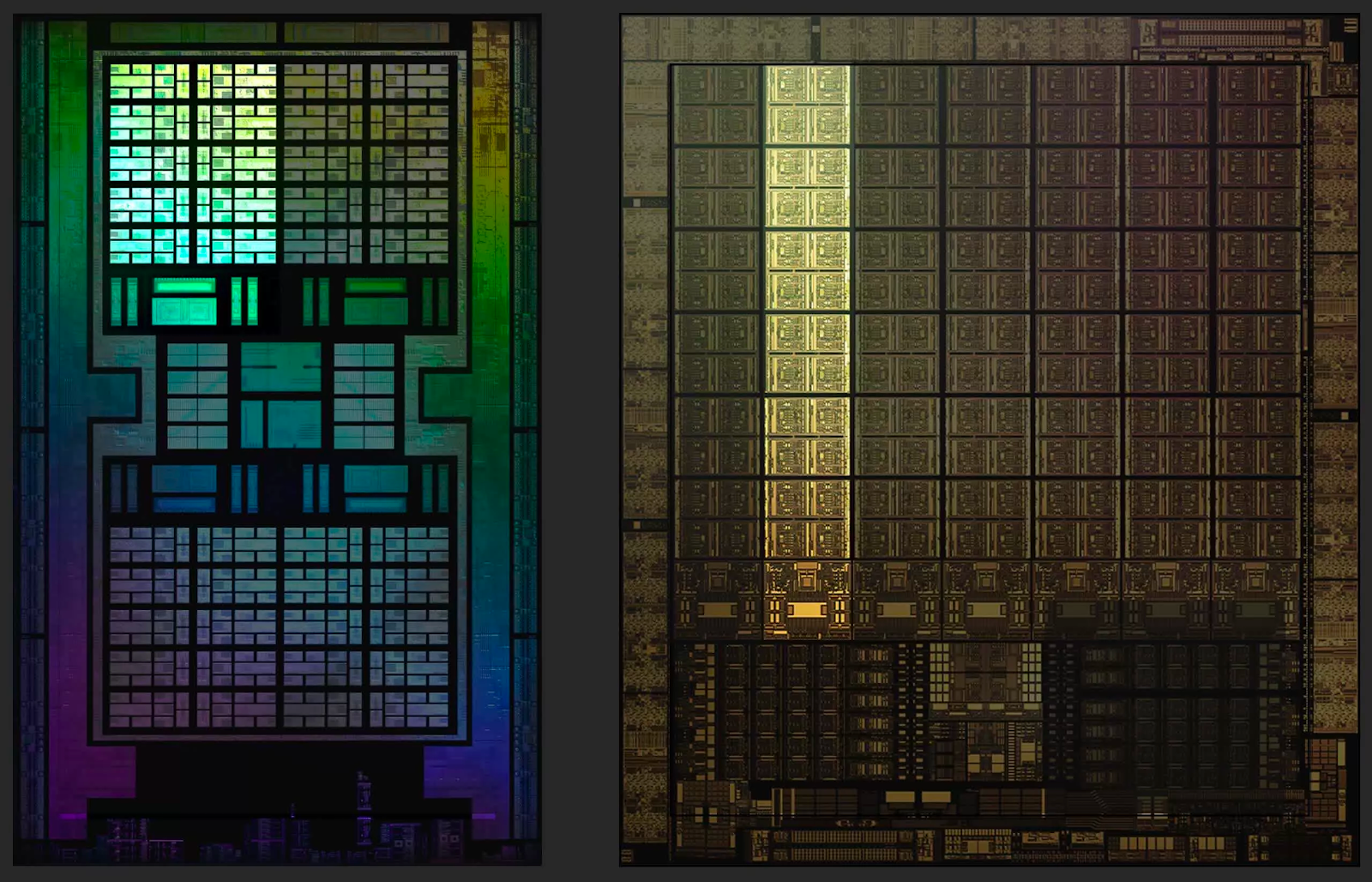
Ниже приведены изображения кристаллов AMD Navi 21 и NVIDIA GA102 в искусственных цветах. Оба изображения были подчищены и показывают только один слой внутри чипа, однако при этом дают хорошее представление о внутренностях современного графического процессора
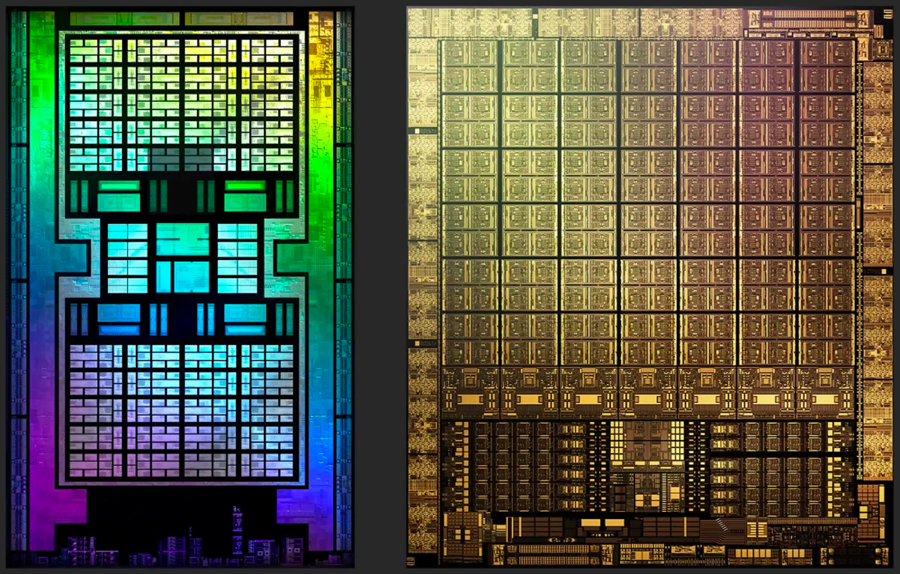
Наиболее очевидное различие между конструкциями заключается в том, что NVIDIA не следует централизованному подходу к компоновке микросхем: все системные контроллеры и основной кэш находятся внизу, а логические блоки расположены в длинных столбцах. Они проделывали это и раньше, но только с моделями среднего и нижнего ценового сегмента.
Например, Pascal GP106 (используемый в GeForce GTX 1060) был буквально вдвое меньше GP104 (из GeForce GTX 1070). В более ранней версии размер кристалла был больше, а кэш-память и контроллер располагались посередине. У младшего брата они переместились в сторону.

Для всех предыдущих топовых ГП NVIDIA использовала классическую централизованную компоновку. Зачем же было менять подход? Интерфейсы здесь ни при чем, ведь контроллеры памяти и PCI Express работают на краю кристалла. С тепловыми проблемами это тоже не связано, ведь даже если кэш-часть или контроллер кристалла будут нагреваться сильнее, чем логические секции, вам наверняка захочется, чтобы посередине схемы было больше теплопоглощающего кремния. Хотя причина этого изменения не вполне понятна, есть подозрение, что она связана с реализацией блоков вывода рендеринга (ROP).
Позже мы рассмотрим их более подробно, а пока просто скажем, что, хотя изменение макета выглядит странно, оно не оказывает существенного влияния на производительность. Это связано с тем, что 3D-рендеринг сопровождается большим количеством длительных задержек — как правило, из-за необходимости ожидания данных. Таким образом, дополнительные наносекунды, добавленные за счет того, что некоторые логические блоки находятся дальше от кэша, скрываются в общей схеме чипа.
Прежде чем мы продолжим, стоит отметить инженерные изменения, реализованные AMD в компоновке Navi 21 по сравнению с Navi 10, установленном в Radeon RX 5700 XT. Несмотря на то, что новый чип в два раза больше предыдущего как по площади, так и по количеству транзисторов, разработчикам удалось улучшить тактовые частоты без значительного увеличения энергопотребления. Например, Radeon RX 6800 XT имеет базовую частоту и частоту разгона 1825 и 2250 МГц, соответственно, при TDP, равном 300 Вт. Те же показатели для Radeon RX 5700 XT: 1605 МГц, 1905 МГц и 225 Вт.
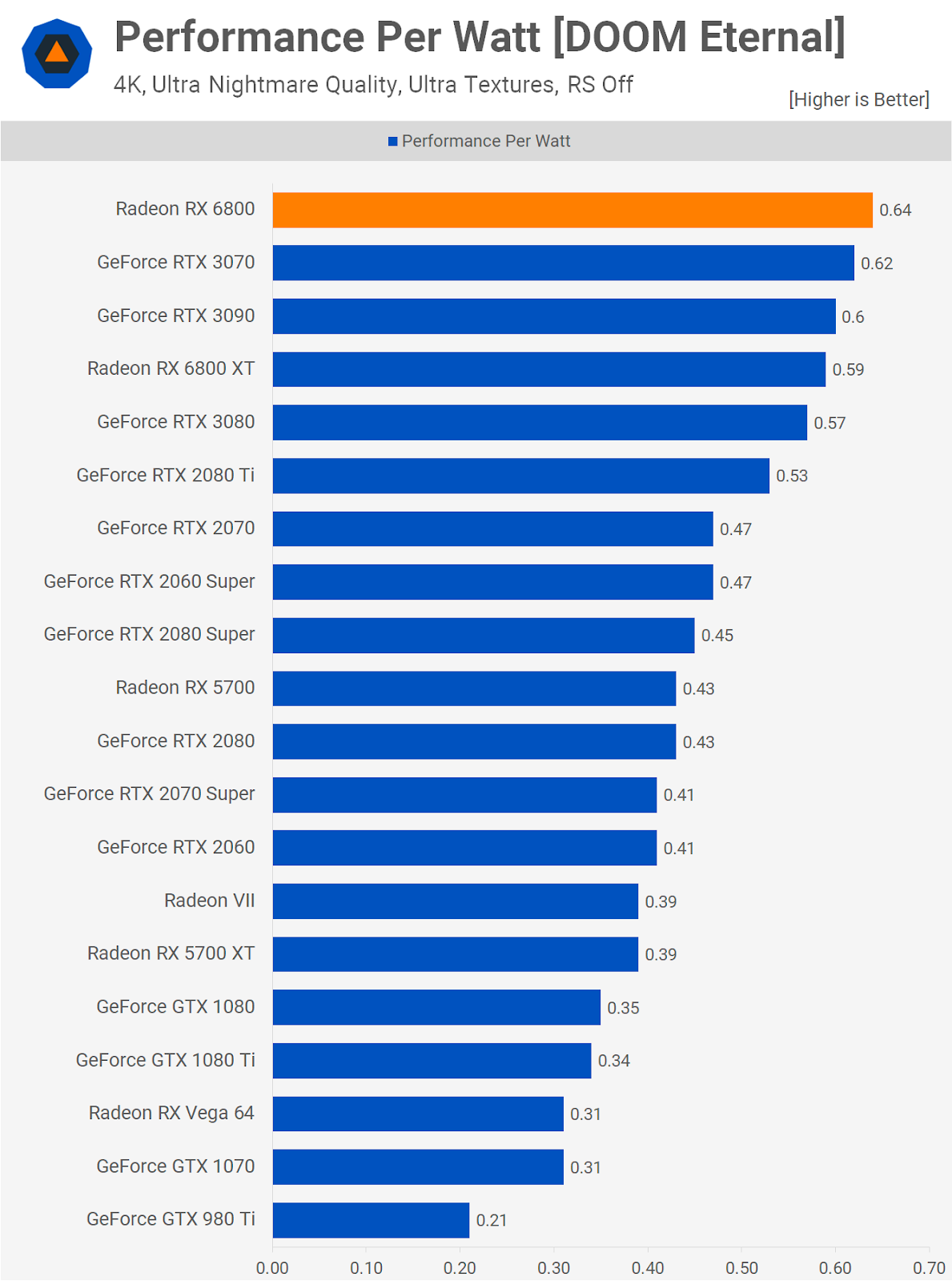
Исследование производительности на ватт карт Ampere и RDNA 2 показало, что оба производителя добились значительных улучшений в этой области, но AMD и TSMC достигли чего-то весьма примечательного — сравните разницу между Radeon RX 6800 и Radeon VII на графике выше.
Radeon VII — первая коллаборация AMD и TSMC с использованием 7-нм технологии, и менее чем за два года они увеличили производительность на ватт на 64%. Отсюда возникает вопрос: насколько лучше мог бы быть Ampere GA102, если бы NVIDIA осталась с TSMC.
Управление ГП
Как все устроено внутри чипов
Драйверы, которые AMD и NVIDIA создают для своих чипов, по сути работают как трансляторы: они преобразуют процедуры, выданные через API, в последовательность операций, понятную графическим процессорам. Затем все зависит от аппаратного обеспечения: какие инструкции выполняются в первую очередь, какая часть микросхемы их выполняет и так далее.
Этот начальный этап управления инструкциями обрабатывается набором модулей в микросхеме. В RDNA 2 графические и вычислительные шейдеры маршрутизируются через отдельные конвейеры, которые планируют и отправляют инструкции остальной части микросхемы: первый называется Graphics Command Processor, второй — асинхронными вычислительными блоками (ACE).

Графические процессоры достигают высокой производительности за счет параллельного выполнения задач, поэтому следующий уровень организации дублируется в чипе. Если проводить аналогию с реальным заводом, это будет похоже на компанию с центральным офисом в одном месте, но производством в нескольких других местах.
AMD называет это Shader Engine (SE), тогда как в NVIDIA они имеют название графических кластеров (GPC): названия разные, но суть одна.
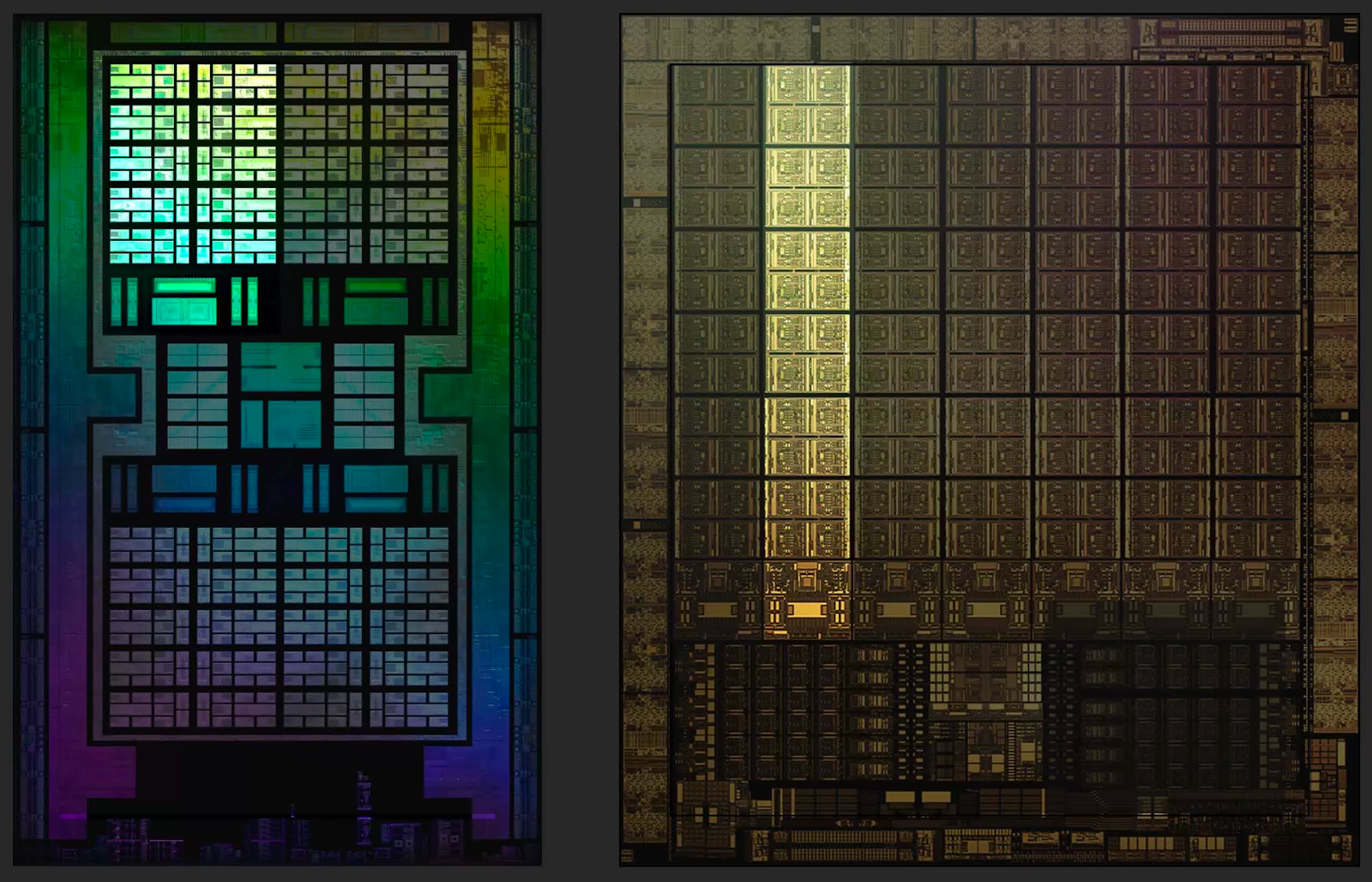
Причина такого разделения проста: блоки обработки графики просто не могут справиться со всем и сразу. Так что имеет смысл продвинуть некоторые обязанности по планированию и организации дальше. Это также означает, что каждый блок может делать что-то независимо от других: скажем, один — обрабатывать графические, другой — вычислительные шейдеры.
В случае RDNA 2 каждый SE содержит собственный набор фиксированных функциональных блоков — схем, предназначенных для выполнения одной конкретной задачи:
Блок Primitive Setup — подготавливает вершины к обработке, а также генерирует больше вершин (тесселяция) и отбраковывает их;
Растеризатор — преобразует трехмерный мир треугольников в двухмерную сетку пикселей;
Блоки вывода рендеринга (ROP) — считывают, записывают и смешивают пиксели.
Блок Primitive Setup работает с частотой 1 треугольник за такт. Параметр может показаться не очень большим, но не забывайте, что эти чипы работают на частотах между 1,8 и 2,2 ГГц, и эта настройка не должна оказываться узким местом ГП. Для Ampere этот блок находится на следующем уровне организации, и об этом мы еще поговорим позже.
Ни AMD, ни NVIDIA не особенно распространяются о своих растеризаторах. NVIDIA называют их Raster Engines. Мы знаем, что они обрабатывают 1 треугольник за такт, но больше никакой информации о них нет — например, о субпиксельной точности.
Каждый SE в чипе Navi 21 содержит 128 ROP; GA102 от NVIDIA включает в себя 112 ROP. Может показаться, что у AMD здесь есть преимущество, ведь большее количество ROP означает, что за такт может обрабатываться больше пикселей. Но такие устройства нуждаются в хорошем доступе к кэш-памяти и локальной памяти, и мы поговорим об этом позже в этой статье. А пока давайте дальше рассмотрим на разделение SE/GPC.
Shader Engines AMD разделены на то, что они сами называют двойными вычислительными блоками (DCU), при этом чип Navi 21 использует десять DCU для каждого SE — обратите внимание, что в некоторых документах они также классифицируются как Workgroup Processors (WGP). В случае Ampere и GA102 они называются кластерами обработки текстур (TPC), причем каждый графический процессор содержит 6 TPC. Они также работают со скоростью 1 треугольник за такт, и хотя графические процессоры NVIDIA работают на меньшей частоте, чем AMD, и у них намного больше TPC, чем у Navi 21 — SE. Таким образом, при той же тактовой частоте GA102 имеет здесь заметное преимущество, поскольку весь чип содержит 42 блока Primitive Setup, тогда как новый RDNA 2 от AMD — только 4. Но поскольку на один Raster Engine приходится шесть TPC, GA102 фактически имеет 7 систем примитивов, в то время как Navi 21 — четыре. Кажется, что NVIDIA имеет здесь явное лидерство.
Последний уровень организации чипов — вычислительные блоки (CU) в RDNA 2 и потоковые мультипроцессоры (SM) в Ampere — производственные линии в наших ГП-«заводах».

В значительной степени они составляют основную начинку ГП, поскольку содержат все программируемые блоки, используемые для обработки графики, вычислений, а теперь еще и трассировки лучей. На изображении выше видно, что каждый из них занимает очень небольшую часть общего пространства кристалла, но они по-прежнему чрезвычайно сложны и очень важны для общей производительности чипа.
Итак, номенклатура у чипов разная, но функции во многом схожи. И поскольку многое из того, что они делают, ограничивается программируемостью и гибкостью, любые преимущества одного из них по сравнению с другим сводятся к простому ощущению масштаба.
Но в случае с CU и SM AMD и NVIDIA используют разные подходы к обработке шейдеров. И пусть в некоторых областях у них много общего, но много и различий.
Подсчет ядер по методу NVIDIA
Если Turing имела множество существенных отличий от Pascal, то Ampere кажется довольно мягким обновлением предыдущей архитектуры — по крайней мере, на первый взгляд. Впрочем, мы точно знаем, что по сравнению с Turing новая архитектура имеет более чем в два раза большее количество ядер CUDA в каждом SM.
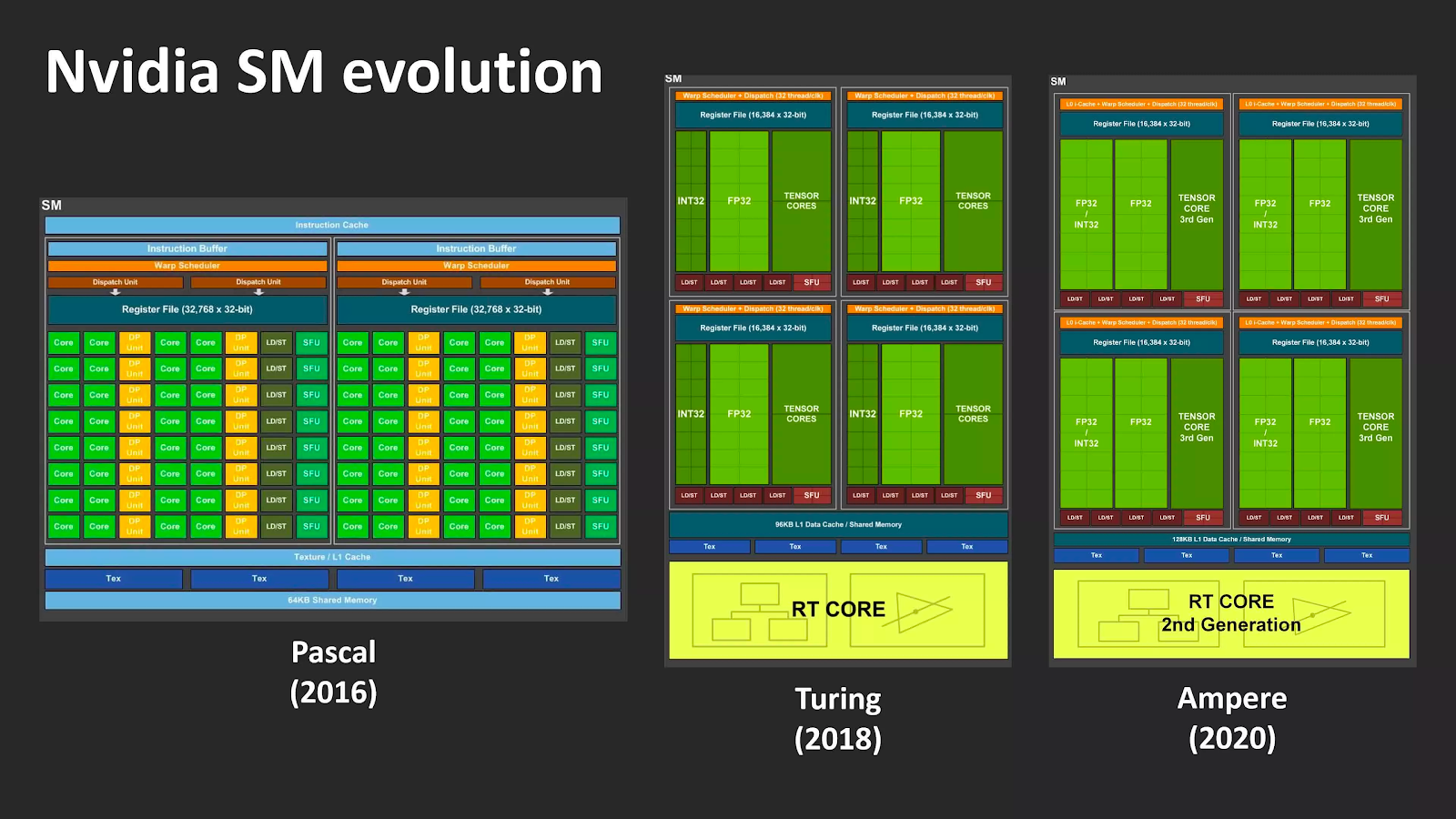
В Turing потоковые мультипроцессоры содержат четыре раздела (иногда называемых блоками обработки), каждый из которых содержит логические блоки 16x INT32 и 16x FP32. Эти схемы предназначены для выполнения очень специфических математических операций с 32-битными значениями данных: блоки INT обрабатывают целые числа, а FP — числа с плавающей запятой.
NVIDIA заявляет, что SM Ampere имеет в общей сложности 128 ядер CUDA, но, строго говоря, это неправда — или с таким же успехом можно считать, что у Turing их было столько же. Блоки INT32 действительно могли обрабатывать значения с плавающей запятой, но только в очень небольшом количестве простых операций. Для Ampere NVIDIA увеличила поддерживаемый диапазон математических операций с плавающей запятой, чтобы соответствовать другим модулям FP32. Это означает, что общее количество ядер CUDA на SM действительно не изменилось, просто половина из них теперь имеет больше возможностей.
Поскольку блоки INT/FP могут работать независимо, SM Ampere может обрабатывать до 128 вычислений FP32 за цикл или 64 операций FP32 и 64 операций INT32 одновременно. Turing же умела делать только последнее.
Таким образом, новый графический процессор может потенциально вдвое увеличить производительность FP32 по сравнению с предшественником. Для вычислительных рабочих нагрузок это большой шаг вперед, но для игр польза окажется гораздо меньшей. Это стало очевидно после тестирования GeForce RTX 3080, в которой используется чип GA102 с 68 включенными SM.
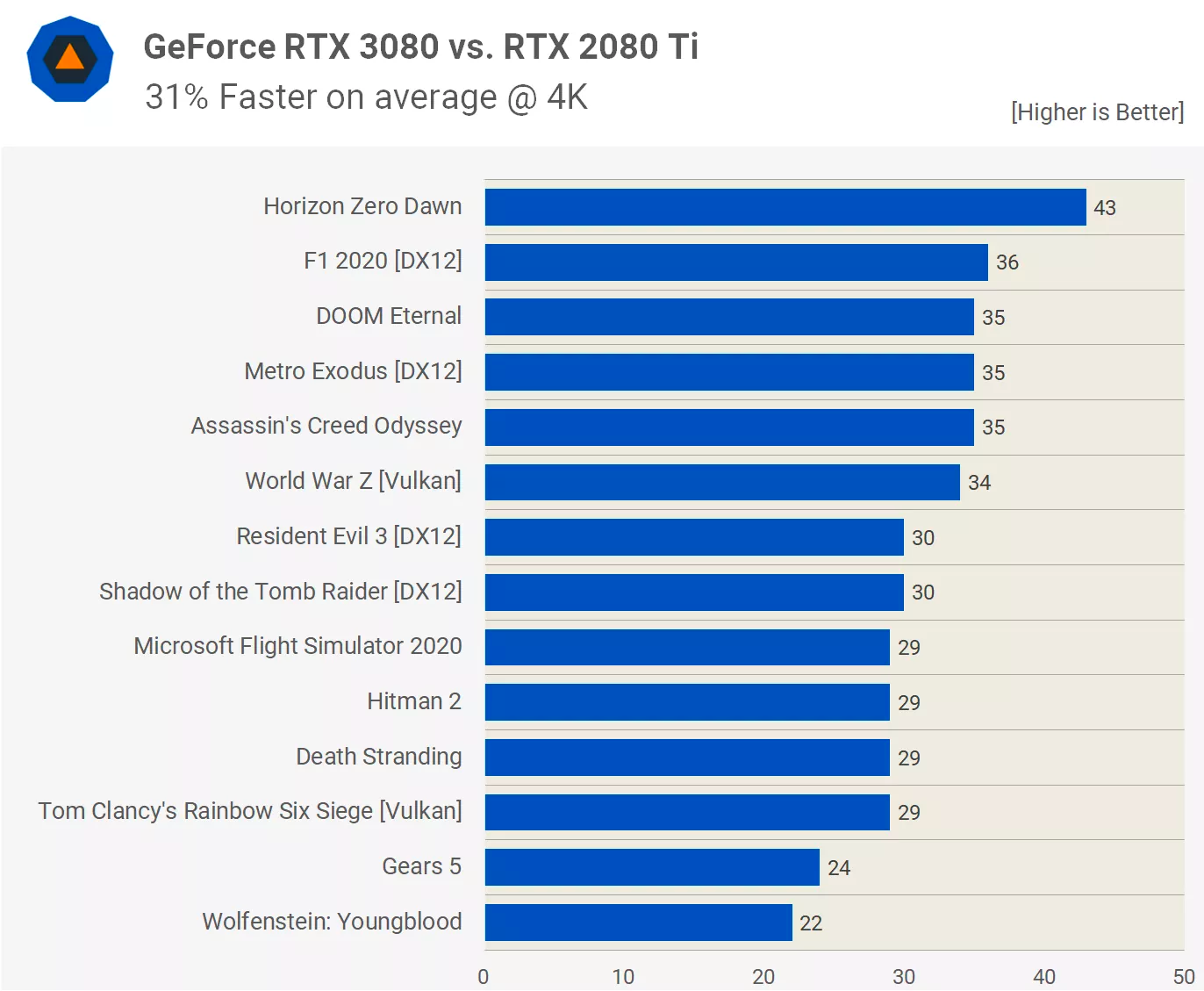
Несмотря на то, что пиковая пропускная способность FP32 составляет 121% по сравнению с GeForce 2080 Ti, в среднем она увеличивает частоту кадров только на 31%. Так почему же вся эта вычислительная мощность тратится зря?
Простой ответ: зря она не тратится, просто игры не всегда запускают инструкции FP32.
Когда NVIDIA выпустила Turing в 2018 году, компания отметила, что в среднем около 36% инструкций, обрабатываемых графическим процессором, связаны с процедурами INT32. Эти вычисления обычно выполняются для определения адресов памяти, сравнения двух значений и логического управления.
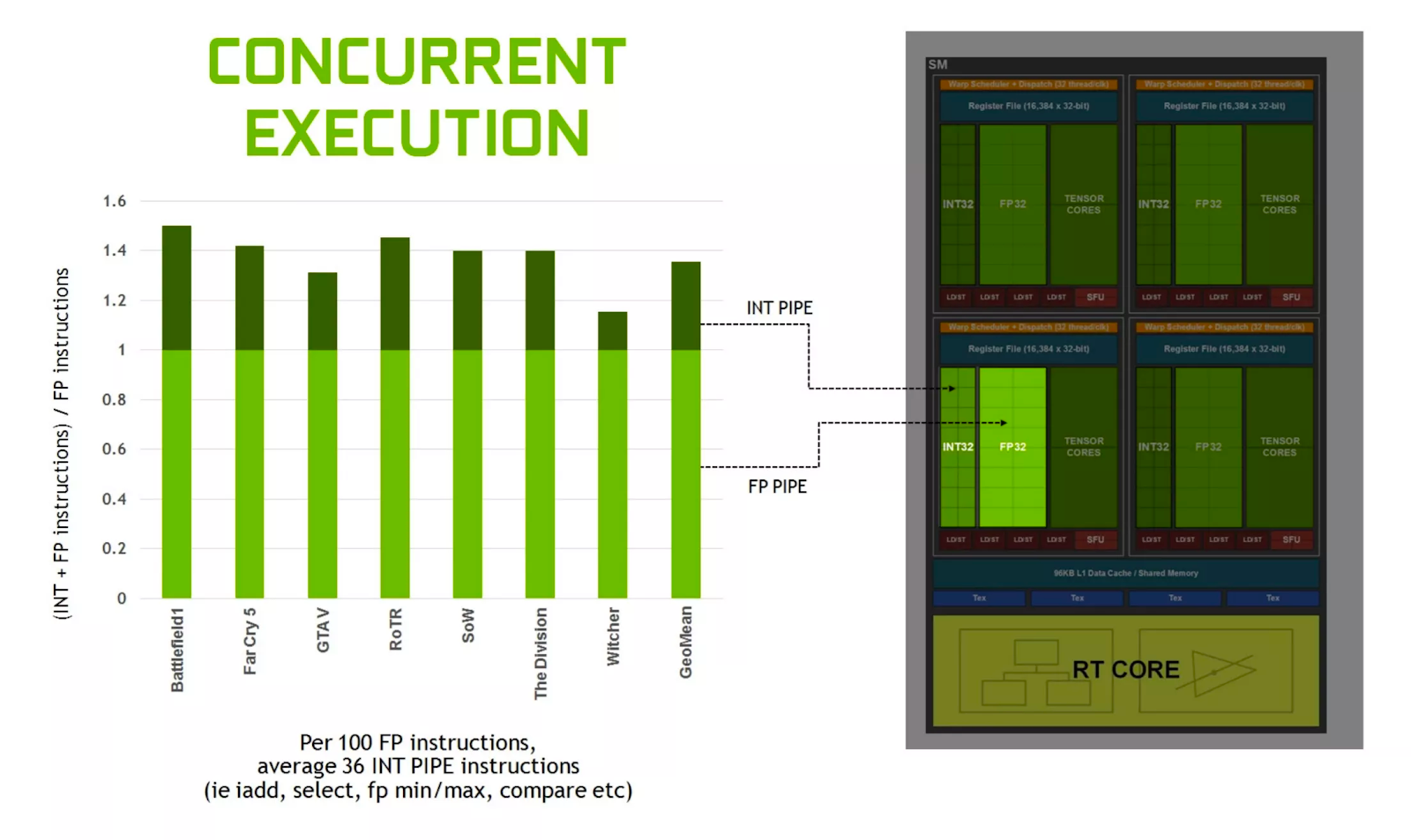
Таким образом, для этих операций функция двойной скорости FP32 не используется, поскольку блоки с двумя путями данных могут работать только с целыми числами или с плавающей запятой. SM переключится в этот режим только в том случае, если все выстроенные в очередь 32 потока, обрабатываемые им в данный момент, выполняют одну и ту же операцию FP32. Во всех остальных случаях SM в Ampere работают так же, как и в Turing.
Это означает, что GeForce RTX 3080 имеет только 11-процентное преимущество FP32 над 2080 Ti при работе в режиме INT+FP. Вот почему реальный прирост производительности в играх не так высок, как предполагают исходные данные.
Какие тут еще улучшения? На каждый SM приходится меньше тензорных ядер, но каждое из них оказывается намного более мощным, чем в Turing. Эти схемы выполняют очень специфические вычисления (например, умножают два значения FP16 и складывают ответ с другим FP16), и теперь каждое ядро выполняет 32 таких операции за цикл.
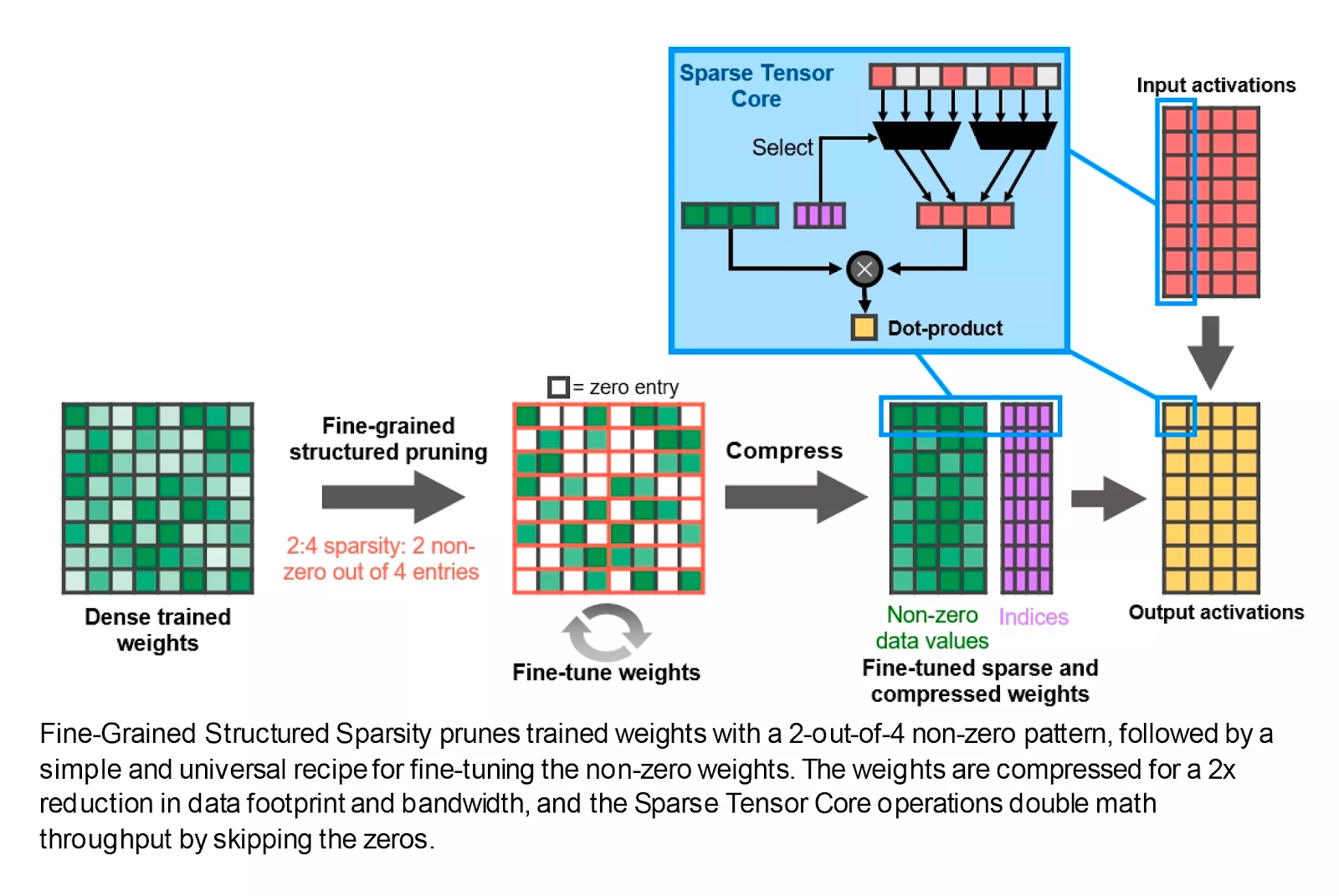
Также есть поддержка новой функции Fine-Grained Structured Sparsity. Если кратко, то с ее помощью математическая скорость может быть удвоена путем удаления данных, которые не влияют на ответ. Опять же, это хорошая новость для профессионалов, работающих с нейронными сетями и искусственным интеллектом, но на данный момент в этом нет никаких значительных преимуществ для игровых разработчиков.
Ядра трассировки лучей также претерпели доработки: теперь они могут работать независимо от ядер CUDA, поэтому, пока они выполняют обход BVH или математику пересечения примитивов лучей, остальная часть SM все еще может обрабатывать шейдеры. Часть ядер трассировки лучей, отвечающая за проверку пересечений, также имеет вдвое большую производительность.
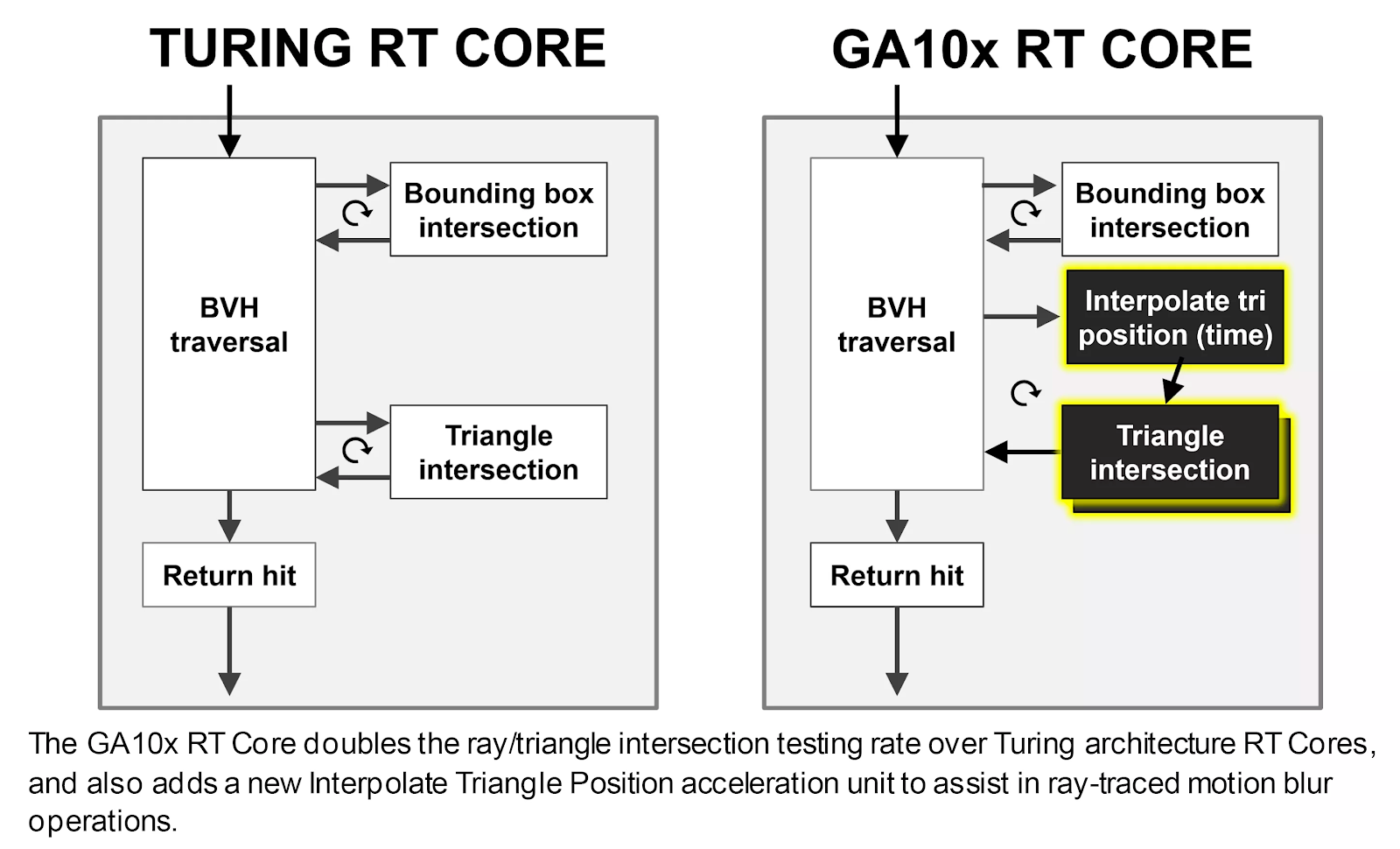
Ядра трассировки лучей также оснащены дополнительным оборудованием, которое помогает применять трассировку лучей к размытию движения, но эта функция в настоящее время доступна только через собственный Optix API от NVIDIA.
Есть и другие хитрости, но в целом подход основан на разумной, но неуклонной эволюции, а не на совершенно новом дизайне. Но учитывая, что в исходных возможностях Turing с самого начала не было ничего особенно плохого, это и неудивительно.
Что же насчет AMD — что они сделали с вычислительными модулями в RDNA 2?
Трассировка лучей по-особенному
На первый взгляд, AMD не сильно изменила вычислительные блоки: они по-прежнему содержат два набора векторных блоков SIMD32, скалярный блок SISD, блоки наложения текстур и стек различных кэшей. Произошли некоторые изменения в отношении того, какие типы данных и связанные с ними математические операции они могут выполнять. Но наиболее заметным изменением для обычного потребителя является то, что AMD теперь предлагает аппаратное ускорение для определенных процедур трассировки лучей.
Эта часть вычислительных блоков выполняет проверки пересечения лучевого бокса или лучевого треугольника — то же самое, что и ядра трассировки лучей в Ampere. Однако последние также ускоряют алгоритмы обхода BVH, тогда как в RDNA 2 это делается с помощью вычислительных шейдеров с использованием модулей SIMD 32.
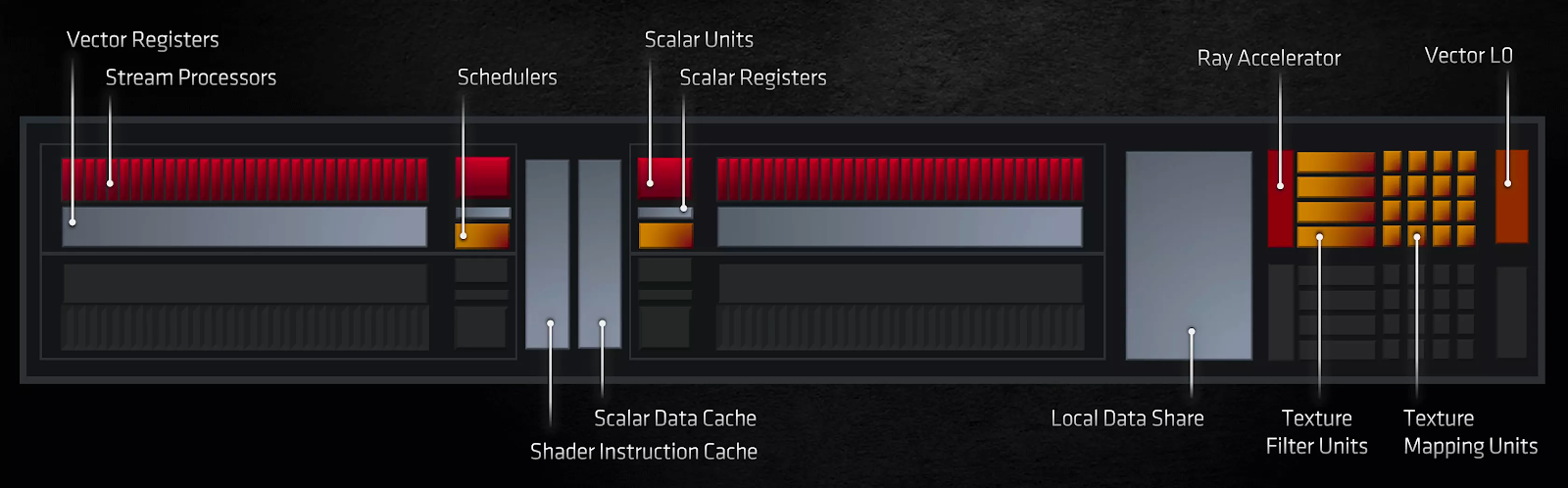
Независимо от того, сколько у вас шейдерных ядер или насколько высоки их тактовые частоты, использование специализированных схем, предназначенных для выполнения только одной задачи, всегда будет предпочтительнее, чем обобщенный подход. Именно поэтому и были изобретены графические процессоры: все в мире рендеринга можно сделать с помощью ЦП, но общий характер делает их непригодными для графических применений.
Блоки Ray Accelerator находятся рядом с текстурными процессорами, поскольку они фактически являются частью одной и той же структуры. Хотя эта система действительно предлагает большую гибкость и устраняет необходимость в том, чтобы части кристалла занимались только трассировкой лучей и ничем другим одновременно с ней, первая реализация ее имеет некоторые недостатки. Наиболее примечательным из них является то, что текстурные процессоры могут обрабатывать только операции, связанные с текстурами или пересечениями примитивов лучей. Учитывая, что ядра трассировки лучей NVIDIA теперь работают полностью независимо от остальной части SM, это дает Ampere явное преимущество по сравнению с RDNA 2 в проработке структур ускорения и тестах пересечений, необходимых для трассировки лучей.
Пока производительность трассировки лучей в новейших видеокартах AMD была исследована лишь вкратце, но уже заметно, что влияние трассировки лучей очень зависит от игры.
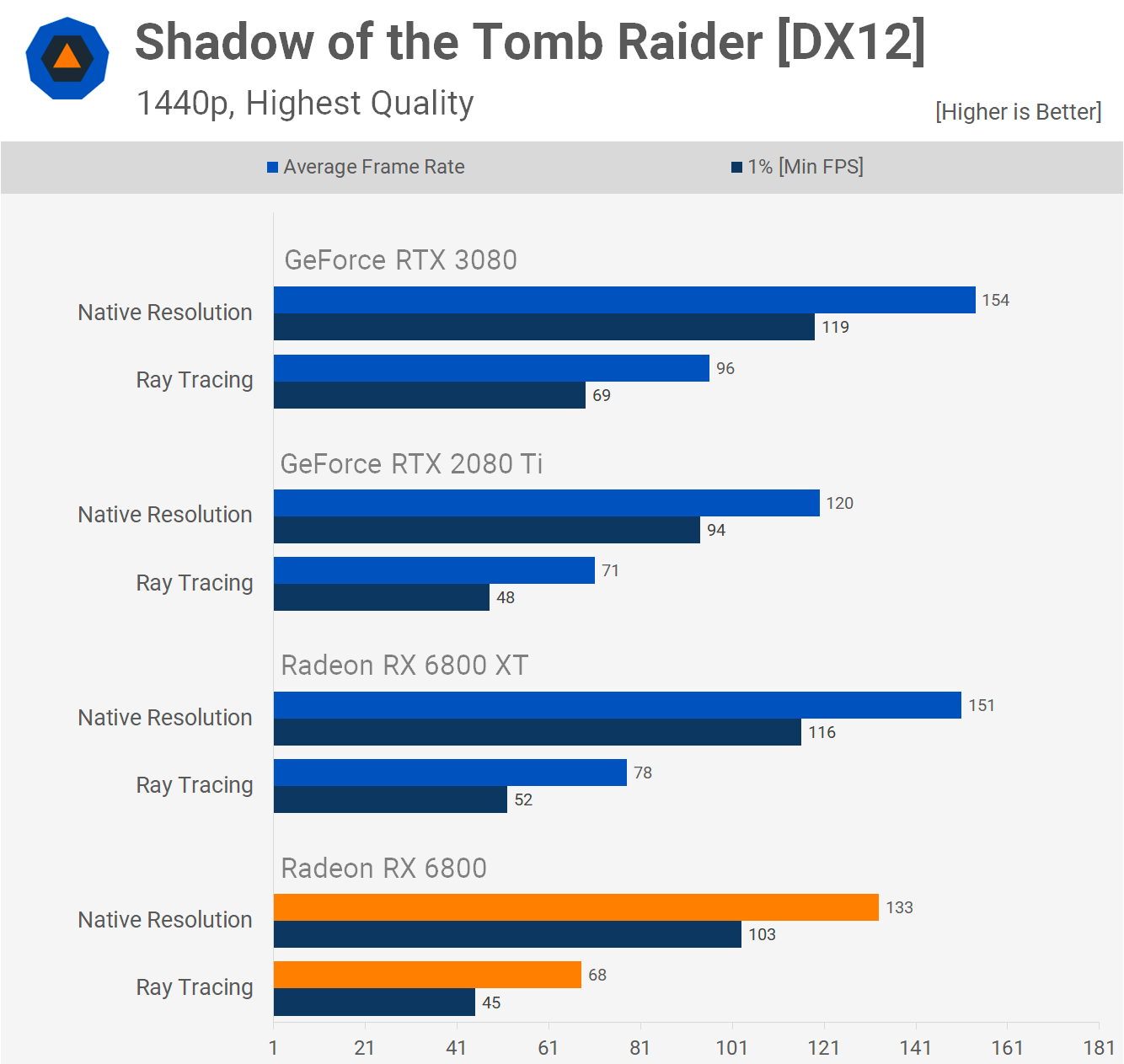
Например, в Gears 5 видеокарта Radeon RX 6800 (в которой используется вариант графического процессора Navi 21 с 60 CU) при включении трассировки лучей снизила частоту кадров только на 17%, тогда как в Shadow of the Tomb Raider — аж на 52%. Для сравнения, у NVIDIA RTX 3080 (с использованием 68 SM GA102) средняя потеря частоты кадров в этих двух играх составила 23% и 40% соответственно.
Чтобы больше рассказать о реализации AMD, необходим более подробный анализ трассировки лучей, однако в качестве первой итерации технологии она кажется вполне конкурентоспособной, но чувствительной к тому, какое приложение выполняет трассировку.
Как упоминалось ранее, вычислительные блоки в RDNA 2 теперь поддерживают больше типов данных: наиболее заметными из них являются типы данных с низкой точностью, такие как INT4 и INT8. Они используются для тензорных операций в алгоритмах машинного обучения, и хотя AMD имеет отдельную архитектуру (CDNA) для ИИ и центров обработки данных, это обновление предназначено для использования с DirectML.
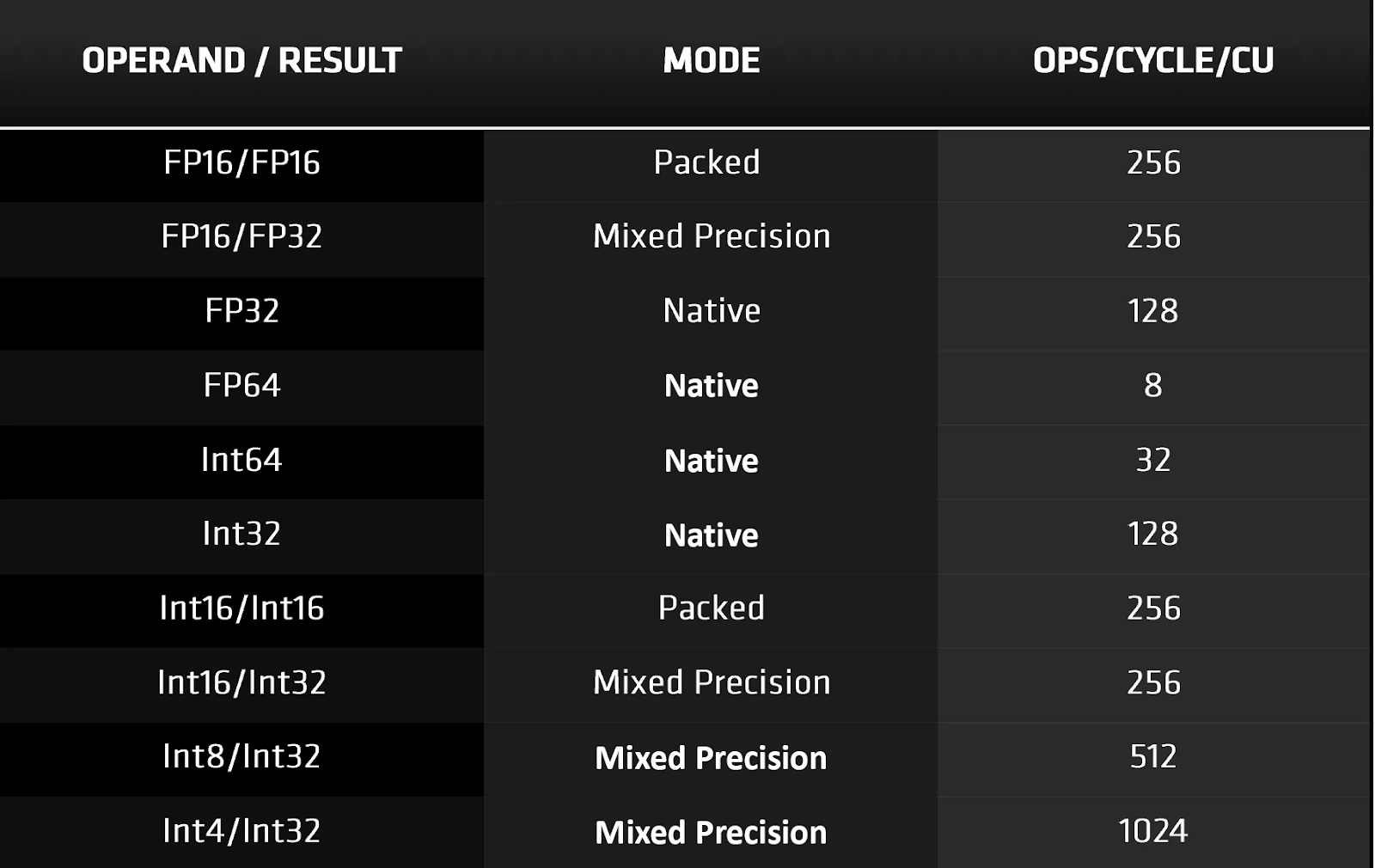
Этот API является недавним дополнением к семейству Microsoft DirectX 12. Комбинация аппаратного и программного обеспечения обеспечивает лучшее ускорение шумоподавления в алгоритмах трассировки лучей и временного масштабирования. В случае с последним у NVIDIA, конечно же, есть своя технология под названием DLSS. Она использует тензорные ядра в SM для выполнения части вычислений — но учитывая, что аналогичный процесс может быть построен и через DirectML, может показаться, что эти компоненты в некоторой степени избыточны. Однако и в Turing, и в Ampere тензорные ядра также обрабатывают все математические операции, связанные с форматами данных FP16.
В RDNA 2 такие вычисления выполняются с использованием шейдерных блоков и упакованных форматов — то есть, каждый 32-битный векторный регистр содержит два 16-битных.
Какой же подход лучше?
AMD преподносит свои блоки SIMD32 как векторные процессоры, поскольку они выдают одну инструкцию для нескольких значений данных. Один векторный блок содержит 32 потоковых процессора, и поскольку каждый из них работает только с одним фрагментом данных, по факту операции носят скалярный характер. По сути, это то же самое, что и SM в Ampere, где каждый блок обработки также применяет одну инструкцию для 32 значений данных.
Но если у NVIDIA весь SM может обрабатывать до 128 вычислений FMA FP32 за цикл , один вычислительный блок RDNA 2 производит только 64 таких вычисления. Использование FP16 увеличивает это значение до 128 FMA за цикл, что совпадает с тем, что делают тензорные ядра в Ampere при стандартных вычислениях FP16.
SM NVIDIA могут выполнять инструкции для одновременной обработки целочисленных значений и значений с плавающей запятой (например, 64 FP32 и 64 INT32) и имеют независимые блоки для операций FP16, тензорной математики и процедур трассировки лучей. Блоки управления AMD выполняют большую часть рабочей нагрузки блоков SIMD32, хотя у них есть отдельные скалярные блоки, которые поддерживают простую целочисленную математику.
Таким образом, может показаться, что у Ampere здесь преимущество: у GA102 больше SM, чем у Navi 21, и у них больше возможностей, когда дело доходит до пиковой пропускной способности, гибкости и предлагаемых функций. Но у AMD есть свой джокер в рукаве.
Система памяти и многоуровневые кэши
Давайте сначала взглянем на Ampere. В целом, внутри произошли некоторые заметные изменения: объем кэша 2-го уровня увеличился на 50% (Turing TU102 имел 4096 КБ, соответственно), а кэши 1-го уровня в каждом SM увеличились вдвое.

Как и раньше, кэш-память L1 здесь настраивается с точки зрения того, сколько места в кэше можно выделить для данных, текстур или общих вычислений. Для графических шейдеров (например, вершинных или пиксельных) и асинхронных вычислений кэш фактически установлен на:
64 КБ для данных и текстур;
48 КБ для общей памяти;
16 КБ для конкретных операций.
Остальная часть внутренней памяти осталась прежней, но за пределами графического процессора ждет приятный сюрприз. NVIDIA стала работать с Micron и теперь использует модифицированную версию GDDR6 для своих потребностей в локальной памяти. По сути, это тот же GDDR6, но шина данных полностью заменена. Вместо того, чтобы использовать обычную настройку 1 бит на вывод, при которой сигнал очень быстро колеблется между двумя значениями напряжения (PAM), GDDR6X использует четыре значения напряжения:
 и PAM4 в GDDR6X (снизу)")
Благодаря этому GDDR6X эффективно передает 2 бита данных на вывод за цикл, поэтому при той же тактовой частоте и количестве выводов полоса пропускания удваивается. GeForce RTX 3090 поддерживает 24 модуля GDDR6X, работающих в одноканальном режиме и рассчитанных на 19 Гбит/с, что дает пиковую пропускную способность 936 ГБ/с. Это на 52% больше, чем у GeForce RTX 2080 Ti. Таких показателей пропускной способности в прошлом можно было достигнуть только при помощи HBM2, реализация которого может быть куда более дорогостоящей, чем GDDR6.
Однако такую память производит только Micron, а использование PAM4 добавляет дополнительной сложности производственному процессу, требуя гораздо более жестких допусков при передаче сигналов. AMD пошла по другому пути: вместо того, чтобы обращаться за помощью к стороннему поставщику, они использовали свое подразделение ЦП, чтобы изобрести что-то новое. Общая система памяти в RDNA 2 не сильно преобразилась по сравнению с предшественницей — но есть два существенных изменения.
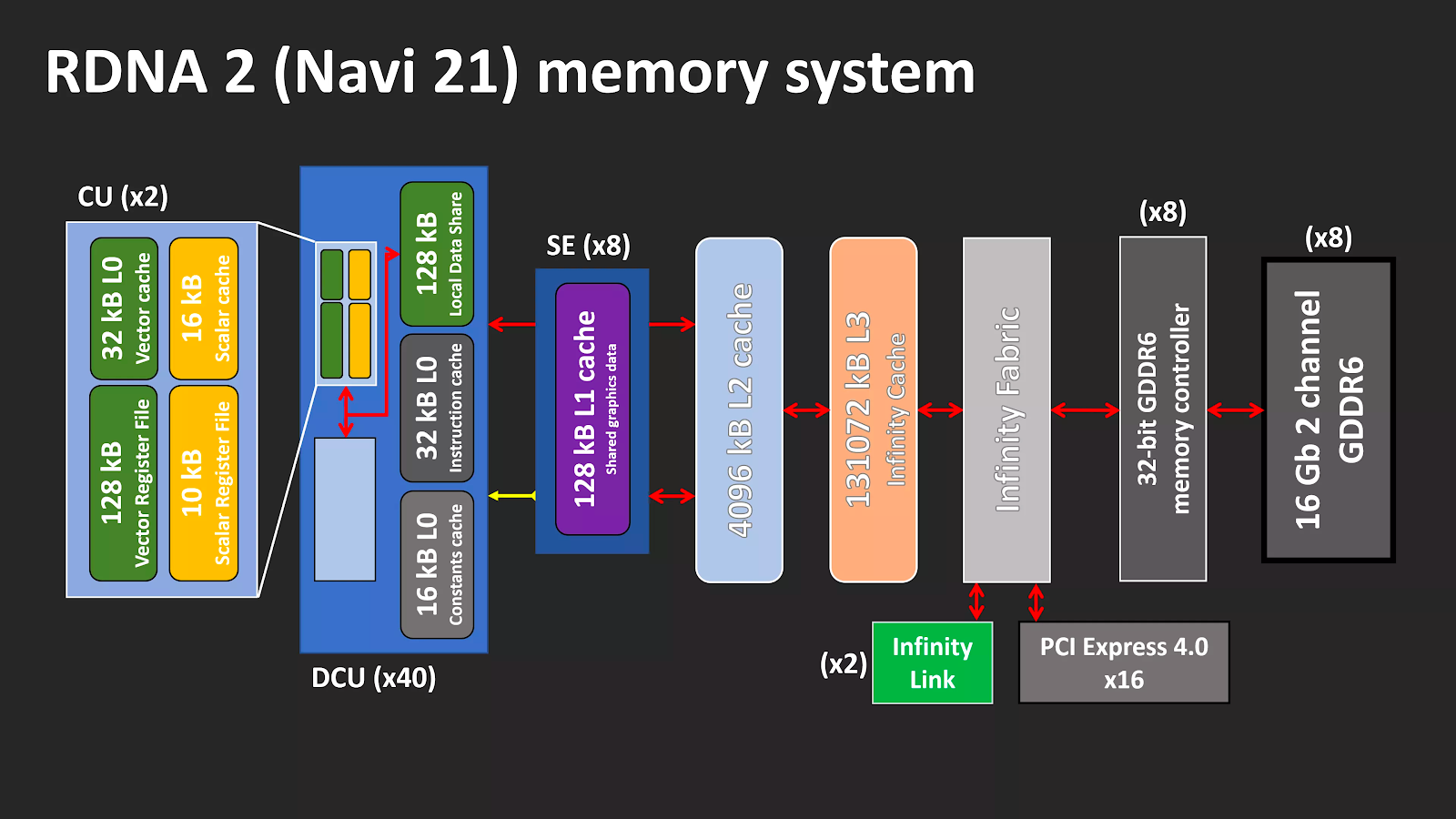
Каждый шейдерный движок теперь имеет два набора кэшей первого уровня. Но как можно втиснуть в графический процессор 128 МБ кэш-памяти третьего уровня? Используя конструкцию SRAM для кэша L3, AMD встроила в чип два набора кэш-памяти высокой плотности объемом 64 МБ. Транзакции данных обрабатываются 16 наборами интерфейсов, каждый из них сдвигает 64 байта за такт.
Так называемый Infinity Cache имеет свой собственный тактовый домен и может работать на частоте 1,94 ГГц, что дает пиковую внутреннюю пропускную способность 1986,6 ГБ/с. И поскольку это не внешняя DRAM, задержки здесь исключительно низкие. Такой кэш идеально подходит для хранения структур ускорения трассировки лучей, и поскольку обход BVH включает в себя множество проверок данных, Infinity Cache должен в этом особенно помочь.

На данный момент не ясно, работает ли кеш третьего уровня в RDNA 2 так же, как в ЦП Zen 2: то есть, как кэш жертвы (victim cache) второго уровня. Обычно, когда необходимо очистить последний уровень кэша, чтобы освободить место для новых данных, любые новые запросы этой информации должны поступать в DRAM.
В кэше жертвы хранятся данные, помеченные для удаления из следующего уровня памяти, и имея под рукой 128 МБ, Infinity Cache потенциально может хранить 32 полных набора кэша L2. Эта система снижает нагрузку на контроллеры GDDR6 и DRAM.
Старые конструкции графических процессоров AMD боролись с нехваткой внутренней пропускной способности — особенно после увеличения тактовой частоты, — но дополнительный кэш во многом поможет при решении этой проблемы.
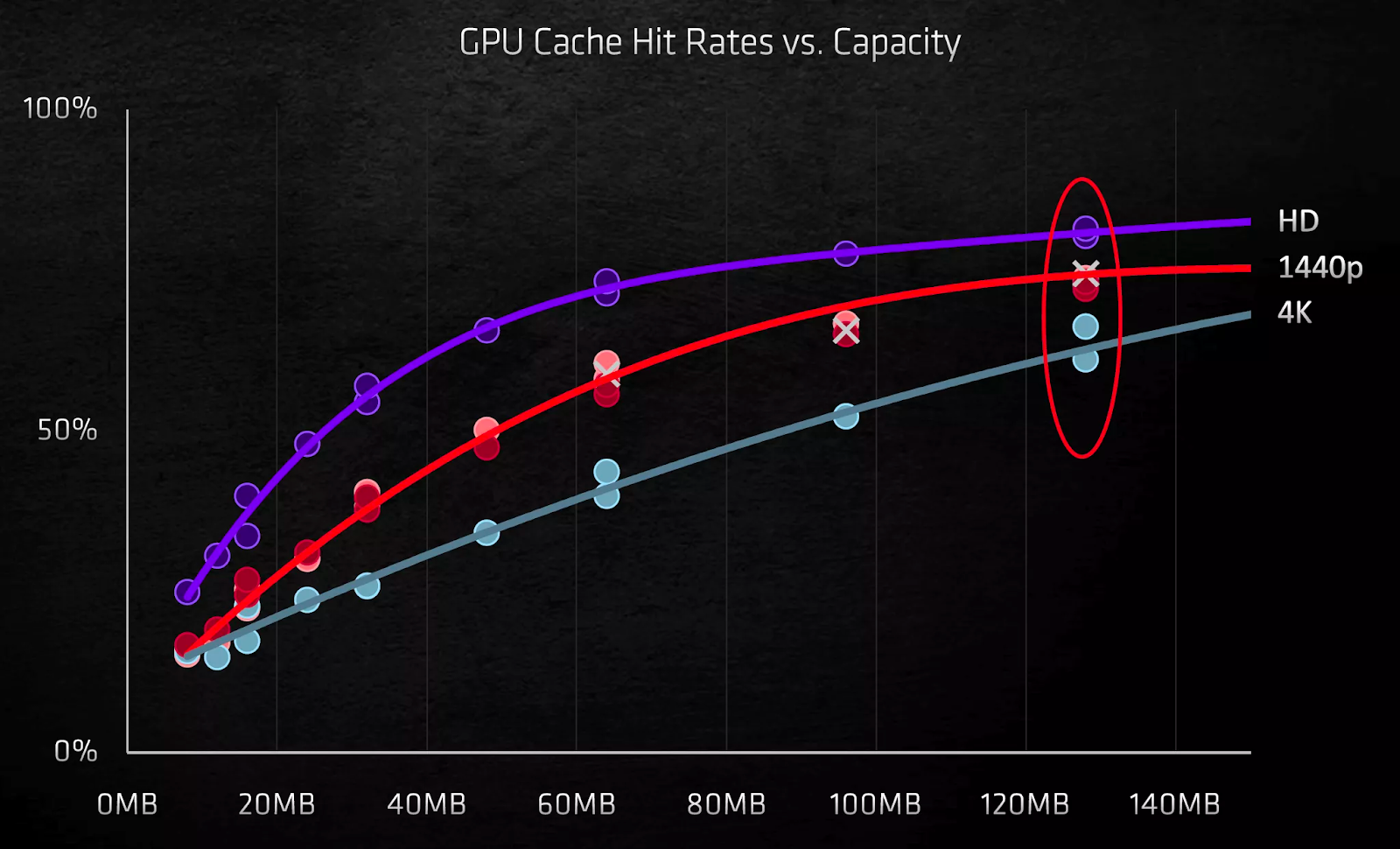
Так что же лучше?
Использование GDDR6X дает GA102 огромную полосу пропускания для локальной памяти, а большие кэши помогают уменьшить влияние промахов кэша. Массивная кэш-память 3-го уровня Navi 21 позволяет реже использовать DRAM, при этом графический процессор может работать на более высоких тактовых частотах без дефицита данных.
Решение AMD придерживаться GDDR6 означает, что сторонним поставщикам доступно больше источников памяти, в то время как любая компания, производящая GeForce RTX 3080 или 3090, будет вынуждена использовать Micron. И хотя GDDR6 поставляется с модулями различной плотности, GDDR6X в настоящее время ограничен 8 Гб.
Система кэширования в RDNA 2, возможно, является лучшим подходом, чем та, что используется в Ampere, поскольку использование нескольких уровней встроенной SRAM всегда обеспечивает более низкие задержки и лучшую производительность для заданного диапазона мощности, чем внешняя DRAM, независимо от пропускной способности последней.
Пайплайны рендеринга
Обе архитектуры содержат множество обновлений для фронтэнда и бэкэнда пайплайнов рендеринга. Ampere и RDNA 2 полностью поддерживают mesh-шейдеры и variable rate-шейдеры в DirectX12 Ultimate, хотя чип NVIDIA обладает большей геометрической производительностью благодаря большему количеству процессоров для этих задач.
Хотя использование mesh-шейдеров позволит разработчикам создавать еще более реалистичное окружение, ни в одной игре никогда не будет полной привязки производительности к этому этапу процесса рендеринга. Это связано с тем, что основная часть самой сложной работы приходится на этапы трассировки пикселей или лучей.
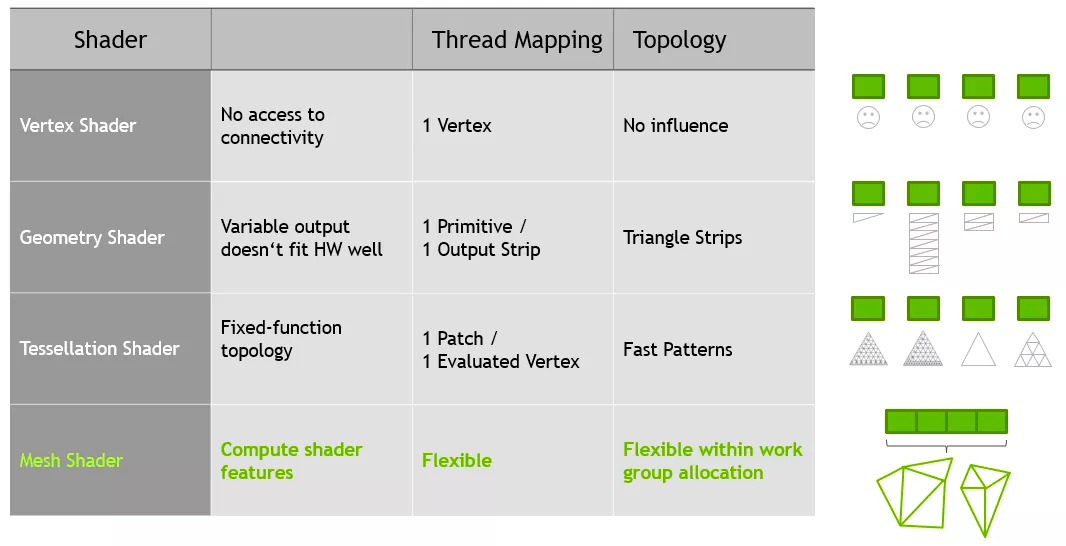
Именно здесь вступает в игру использование variable rate-шейдеров. В основном этот процесс включает применение шейдеров для освещения и цвета на блоке пикселей, а не на отдельных пикселях. Это похоже на уменьшение разрешения игры для повышения производительности, но, поскольку его можно применить только к выбранным областям, потеря визуального качества не всегда очевидна.
Обе архитектуры также получили обновление для блоков вывода рендеринга (ROP), поскольку это улучшит производительность при высоких разрешениях независимо от того, используются ли variable rate-шейдеры. Во всех предыдущих поколениях своих графических процессоров NVIDIA привязывала ROP к контроллерам памяти и кэшу 2-го уровня.
В Turing восемь блоков ROP были напрямую связаны с одним контроллером и фрагментом кэша размером 512 КБ. Добавление большего количества ROP представляется проблематичным, поскольку для этого требуется больше контроллеров и кэша, поэтому для Ampere ROP теперь полностью выделены для GPC. GA102 поддерживает 12 ROP на один GPC (каждый обрабатывает 1 пиксель за такт), что дает в общей сложности 112 блоков для всего чипа.
AMD следует системе, аналогичной старому подходу NVIDIA (т. е. привязке к контроллеру памяти и кэш-памяти L2), хотя их ROP в основном используют кэш первого уровня для чтения/записи и смешивания пикселей. В чипе Navi 21 ROP теперь обрабатывает 8 пикселей за цикл в 32-битном цвете и 4 пикселя в 64-битном.
RTX IO в NVIDIA — система обработки данных, которая позволяет графическому процессору напрямую обращаться к накопителю, копировать необходимые данные, а затем распаковывать их с помощью ядер CUDA.

Современные методы предполагают, что всем этим управляет центральный процессор: он получает запрос данных от драйверов графического процессора, копирует данные с накопителя в системную память, распаковывает их, а затем копирует в DRAM графической карты.
Этот механизм по своей природе является последовательным: ЦП обрабатывает один запрос за раз. NVIDIA заявляет о таких цифрах, как «100-кратная пропускная способность» и «20-кратное снижение нагрузки на ЦП», но до тех пор, пока система не будет протестирована в реальных условиях, их никак нельзя будет исследовать дальше.

Когда AMD представила RDNA 2 и новые видеокарты Radeon RX 6000, вместе с ними была представлена и так называемая Smart Access Memory. Это не ответ на RTX IO — на самом деле, это даже не новая функция. По умолчанию контроллер PCI Express в ЦП может адресовать до 256 МБ памяти видеокарты для каждого отдельного запроса доступа. Это значение устанавливается размером регистра базового адреса (BAR), и еще в 2008 году в спецификации PCI Express 2.0 была дополнительная функция, позволяющая изменять его размер. Преимущество его состоит в том, что нет нужды обрабатывать большое количество запросов на доступ, чтобы адресовать всю DRAM карты.
Функция требует поддержки операционной системой, центральным процессором, материнской платой, графическим процессором и его драйверами. В настоящее время на ПК с Windows система ограничена определенной комбинацией процессоров Ryzen 5000, материнских плат серии 500 и видеокарт Radeon RX 6000.
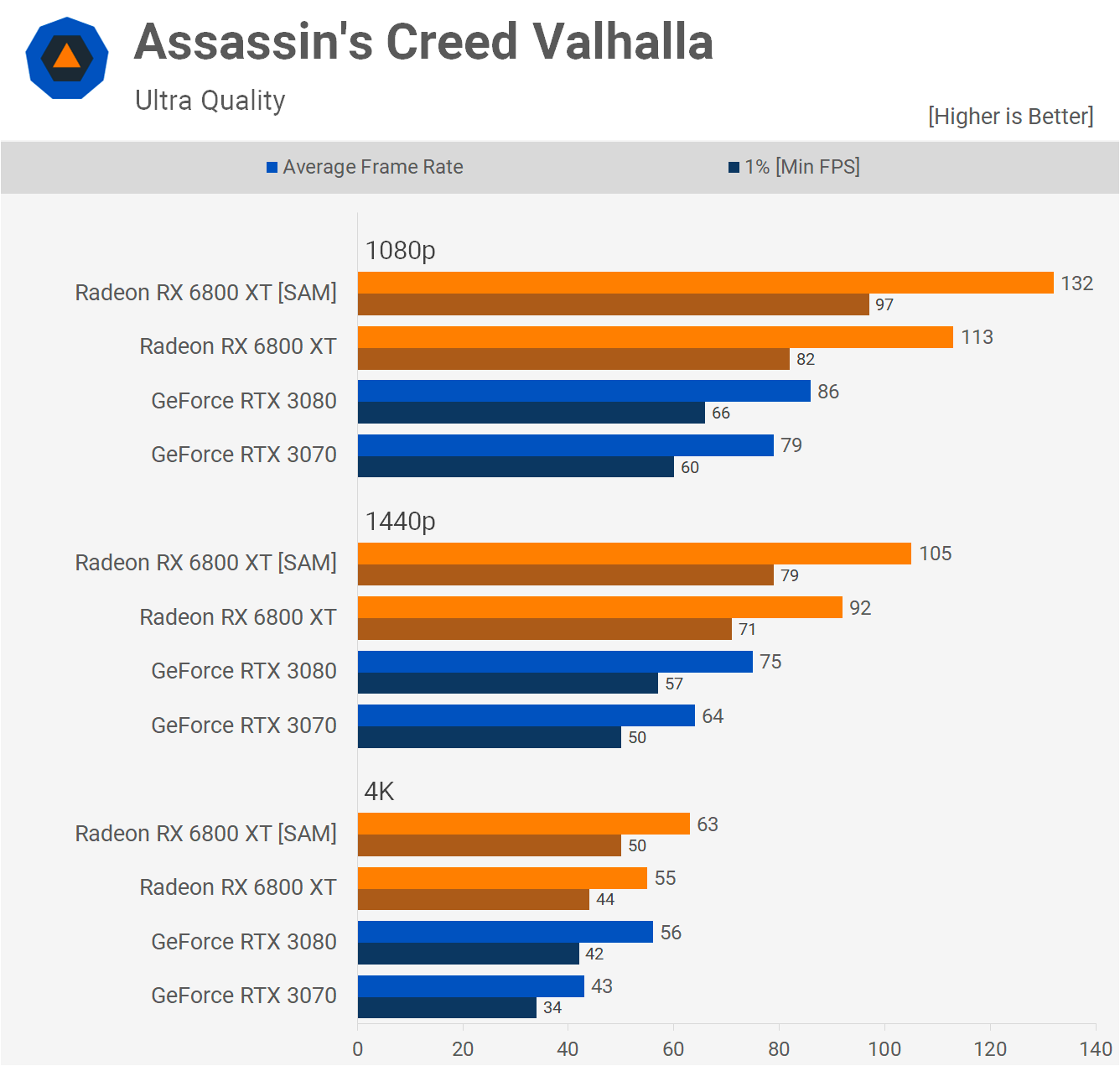
Эта простая функция дала поразительные результаты на тестах: повышение производительности на 15% при разрешении 4K. Неудивительно, что вскоре NVIDIA заявила, что реализует эту функцию для RTX 3000 в ближайшем будущем.
Мультимедиа-движок и видеовыход
Обе архитектуры обеспечивают вывод изображения через HDMI 2.1 и DisplayPort 1.4a. Первый предлагает более широкую полосу пропускания сигнала, но оба они рассчитаны на 4K при 240 Гц с HDR и 8K при 60 Гц. Это достигается при помощи либо цветовой субдискретизации 4:2:0, либо DSC 1.2a. Это алгоритмы сжатия видеосигнала, обеспечивающие значительное снижение требований к полосе пропускания без большой потери визуального качества. Без них даже пиковой пропускной способности HDMI 2.1 в 6 ГБ/с было бы недостаточно для передачи изображений 4K с частотой 60 Гц.

Ampere и RDNA 2 также поддерживают системы с переменной частотой обновления (FreeSync для AMD, G-Sync для NVIDIA), в кодировании и декодировании видеосигналов между ними также нет заметной разницы.
Независимо от того, какой процессор рассматривать, в обоих есть поддержка декодирования 8K AV1, 4K H.264 и 8K H.265, хотя и еще не было тщательно изучено, насколько хорошо они оба работают в таких ситуациях. Ни одна из компаний не раскрывает подробностей о внутреннем устройстве в этих областях. Какими бы важными они ни были в наши дни, все внимание по-прежнему привлекают другие аспекты графических процессоров.
Созданы для вычислений, созданы для игр
Раньше AMD и NVIDIA использовали разные подходы к выбору архитектуры и конфигурации. Но по мере того, как 3D-графика набирала все большую популярность, они становились все более похожими.
На данный момент у NVIDIA есть три чипа, использующих технологию Ampere: GA100, GA102 и GA104.

Последний — урезанная версия GA102. GA100 — совсем другое дело.
В нем нет ядер трассировки лучей и CUDA с поддержкой INT32+FP32 — вместо этого он содержит множество дополнительных модулей FP64, еще больше load/store систем и огромный объем кэш-памяти L1/L2. Все это объясняется тем, что он разработан для вычислений ИИ и анализа данных.
GA102/104, в свою очередь, должны охватывать все остальные рынки, на которые нацелена NVIDIA: геймеров, профессиональных графических художников и инженеров, а также маломасштабный ИИ и вычислительные системы. Ampere должен быть мастером на все руки — а это задача не из легких.

RDNA 2 была разработана только для игр на ПК и консолях, хотя могла с таким же успехом работать в тех же областях, что и Ampere. Однако AMD решила сохранить свою архитектуру GCN и обновить ее в соответствии с требованиями сегодняшних клиентов.
Там, где RDNA 2 породила Big Navi, можно сказать, что CDNA породила Big Vega: в Instinct MI100 находится их чип Arcturus — 50-миллиардный транзисторный графический процессор с 128 вычислительными блоками.
Хотя NVIDIA в значительной степени доминирует на профессиональном рынке с моделями Quadro и Tesla, Navi 21 просто не нацелена на конкуренцию с ними. Ограничивает ли это каким-либо образом требование, чтобы Ampere вписалась на несколько рынков?
Правильный ответ: нет.
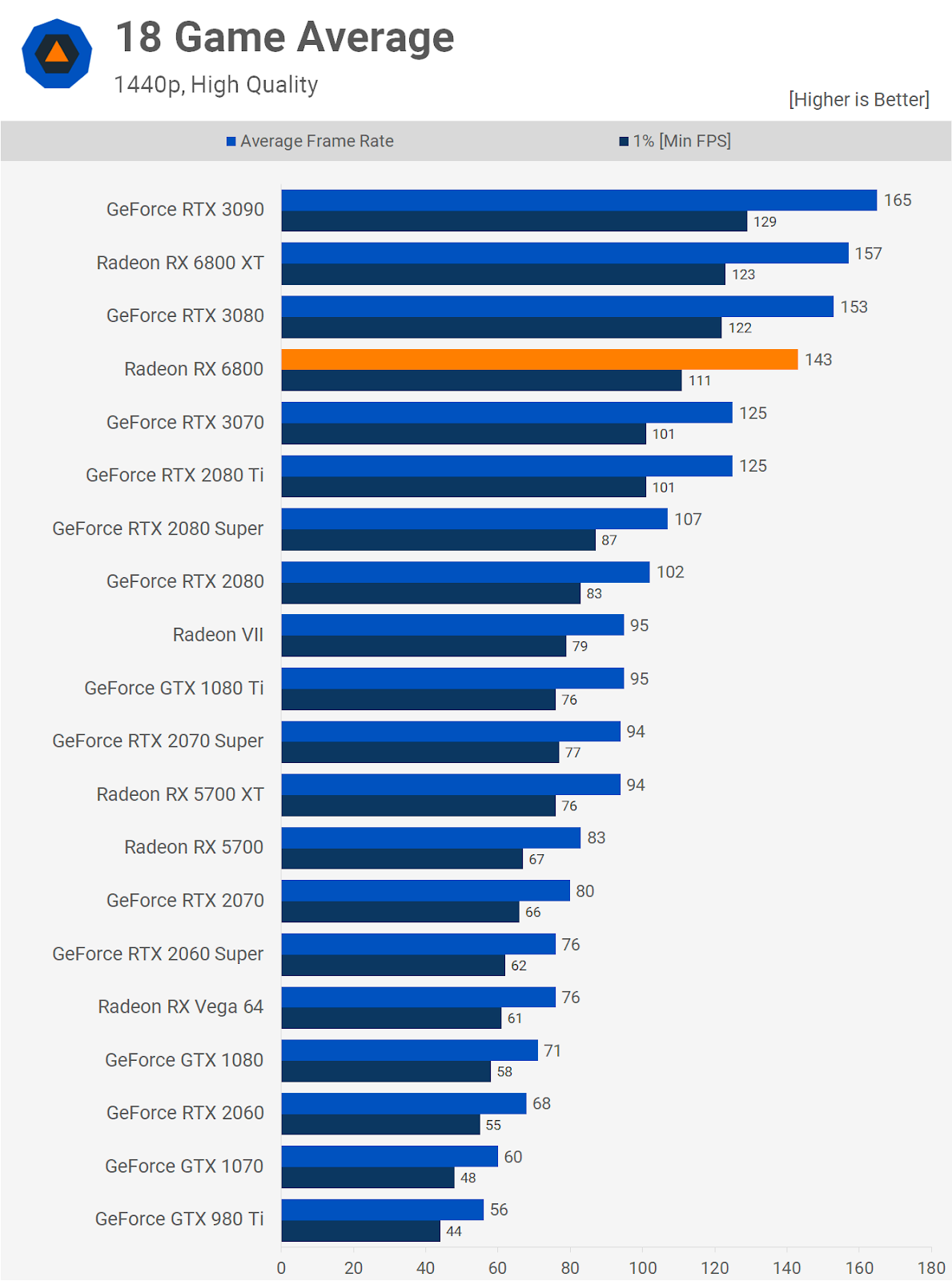
Скоро AMD выпустит Radeon RX 6900 XT, в котором используется полная версия Navi 21 (без отключенных CU), которая сможет работать так же хорошо, как GeForce RTX 3090 или даже лучше. Но GA102 на этой карте также не полностью включен, поэтому у NVIDIA всегда есть возможность обновить эту модель до «супер»-версии, как они это сделали с Turing в прошлом году.
Можно утверждать, что, поскольку RDNA 2 используется в Xbox Series X/S и PlayStation 5, разработчики игр будут отдавать предпочтение этой архитектуре для своих игровых движков. Но стоит просто вспомнить времена, когда GCN использовался в Xbox One и PlayStation 4, чтобы получить представление, как это, вероятно, будет происходить.
Первая версия, выпущенная в 2013 году, использовала графический процессор, построенный на архитектуре GCN 1.0, не появлявшийся в видеокартах для настольных ПК вплоть до следующего года. Xbox One X, выпущенный в 2017 году, использовал GCN 2.0, которому к тому времени было уже более 3 лет.

Так что же — все игры, созданные для Xbox One или PS4, а затем портированные на ПК, по умолчанию лучше работали на видеокартах AMD? А вот и нет. Поэтому мы не можем предположить, что на этот раз с RDNA 2 все будет иначе, несмотря на впечатляющий набор функций.
Но все это в конечном итоге не имеет значения, поскольку оба графических процессора обладают исключительными возможностями и представляют собой чудо того, что может быть достигнуто в производстве полупроводников. NVIDIA и AMD предлагают разные инструменты, поскольку пытаются решать разные проблемы: Ampere стремится быть всем для всех, RDNA 2 — только для игр.
На этот раз битва зашла в тупик, хотя каждый может претендовать на победу в определенной области. Войны ГП еще продолжатся в течение следующего года, когда в бой вступит новый участник: Intel со своей серией Xe. По крайней мере, нам не придется ждать еще два года, чтобы увидеть, как протекает эта борьба.
