Предыдущий цикл был посвящен изоляции и многоверсионности PostgreSQL, а сегодня мы начинаем новый — о механизме журналирования (write-ahead logging). Напомню, что материал основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
Этот цикл будет состоять из четырех частей:
В процессе работы часть данных, с которыми имеет дело СУБД, хранится в оперативной памяти и записывается на диск (или на другой энергонезависимый носитель) отложенным образом. Чем реже это происходит, тем меньше ввод-вывод и тем быстрее работает система.
Но что произойдет в случае сбоя, например, при выключении электропитания или при ошибке в коде СУБД или операционной системы? Все содержимое оперативной памяти будет потеряно, а останутся лишь данные, записанные на диск (при некоторых видах сбоев может пострадать и диск, но в этом случае поможет лишь резервная копия). В принципе можно организовать ввод-вывод таким образом, чтобы данные на диске всегда поддерживались в согласованном состоянии, но это сложно и не слишком эффективно (насколько я знаю, только Firebird пошел таким путем).
Обычно же — в том числе и в PostgreSQL — данные, записанные на диск, оказываются несогласованными и при восстановлении после сбоя требуются специальные действия, чтобы согласованность восстановить. Журналирование — тот самый механизм, который делает это возможным.
Разговор о журналировании мы, как ни странно, начнем с буферного кеша. Буферный кеш — не единственная структура, которая хранится в оперативной памяти, но одна из самых важных и сложных. Понимание принципа его работы важно само по себе, к тому же на этом примере мы познакомимся с тем, как происходит обмен данными между оперативной памятью и диском.
Кеширование используется в современных вычислительных системах повсеместно, у одного только процессора можно насчитать три-четыре уровня кеша. Вообще любой кеш нужен для того, чтобы сглаживать разницу в производительности двух типов памяти, одна из которых относительно быстрая, но ее на всех не хватает, а другая — относительно медленная, но имеющаяся в достатке. Вот и буферный кеш сглаживает разницу между временем доступа к оперативной памяти (наносекунды) и к дисковой (миллисекунды).
Заметим, что у операционной системы тоже есть дисковый кеш, который решает ту же самую задачу. Поэтому обычно СУБД стараются избегать двойного кеширования, обращаясь к диску напрямую, минуя кеш ОС. Но в случае PostgreSQL это не так: все данные читаются и записываются с помощью обычных файловых операций.
Кроме того, свой кеш бывает также у контроллеров дисковых массивов, и даже у самих дисков. Этот факт нам еще пригодится, когда мы доберемся до вопроса надежности.
Но вернемся к буферному кешу СУБД.
Называется он так потому, что представляет собой массив буферов. Каждый буфер — это место под одну страницу данных (блок), плюс заголовок. Заголовок, в числе прочего, содержит:
Буферный кеш располагается в общей памяти сервера и доступен всем процессам. Чтобы работать с данными — читать или изменять, — процессы читают страницы в кеш. Пока страница находится в кеше, мы работаем с ней в оперативной памяти и экономим на обращениях к диску.
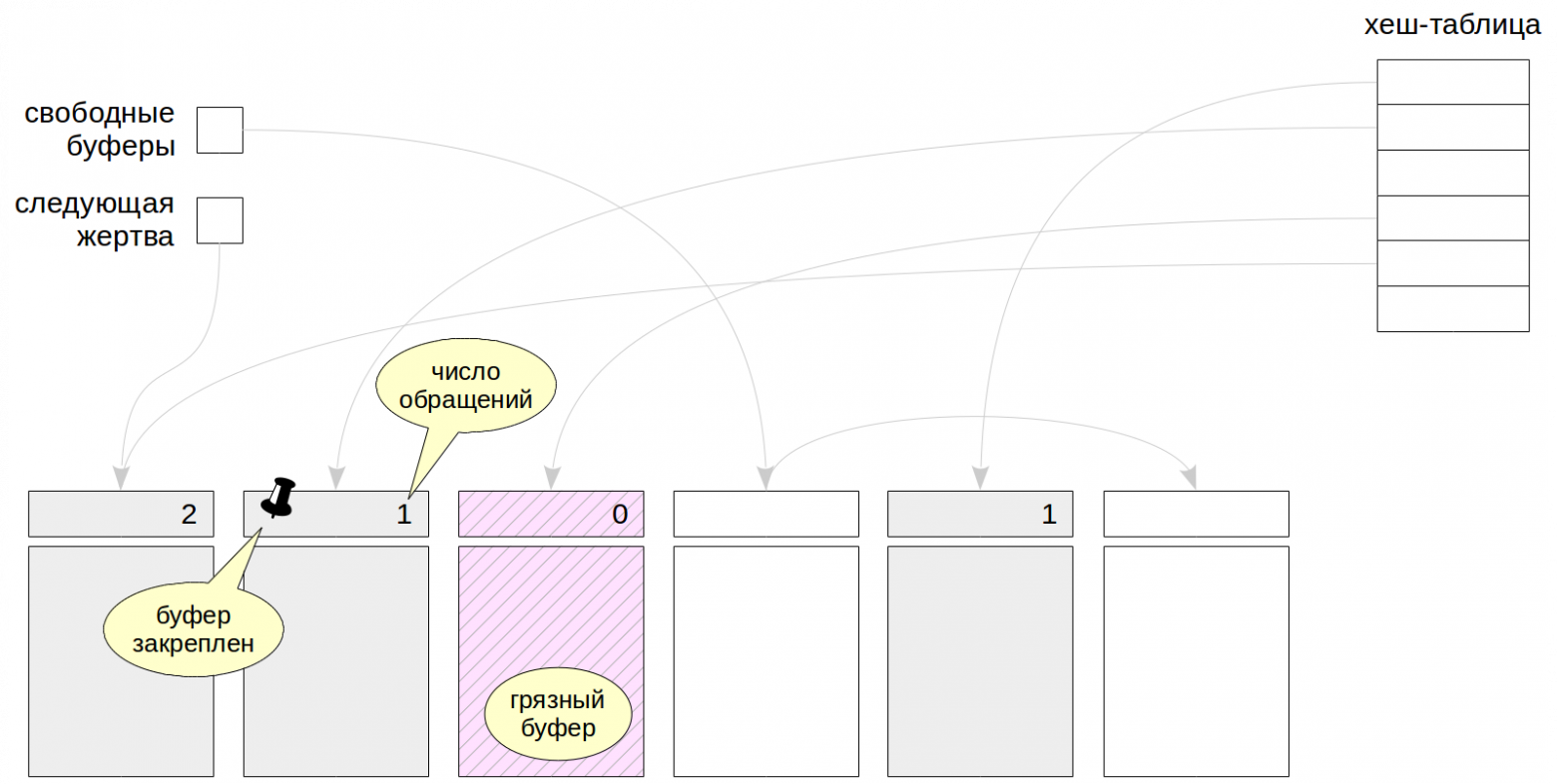
Изначально кеш содержит пустые буферы, и все они связаны в список свободных буферов. Смысл указателя на «следующую жертву» станет ясен чуть позже. Чтобы быстро находить нужную страницу в кеше, используется хеш-таблица.
Когда процессу требуется прочитать страницу, он сначала пытается найти ее в буферном кеше с помощью хеш-таблицы. Ключом хеширования служит номер файла и номер страницы внутри файла. В соответствующей корзине хеш-таблицы процесс находит номер буфера и проверяет, действительно ли он содержат нужную страницу. Как и с любой хеш-таблицей, здесь возможны коллизии; в таком случае процессу придется проверять несколько страниц.
Если нужная страница найдена в кеше, процесс должен «закрепить» буфер, увеличив счетчик pin count (несколько процессов могут сделать это одновременно). Пока буфер закреплен (значение счетчика больше нуля), считается, что буфер используется и его содержимое не должно «радикально» измениться. Например, в странице может появиться новая версия строки — это никому не мешает благодаря многоверсионности и правилам видимости. Но в закрепленный буфер не может быть прочитана другая страница.
Может получиться так, что необходимая страница не будет найдена в кеше. В этом случае ее необходимо считать с диска в какой-либо буфер.
Если в кеше еще остались свободные буферы, то выбирается первый же свободный. Но рано или поздно они закончатся (обычно размер базы данных больше чем память, выделенная под кеш) и тогда придется выбирать один из занятых буферов, вытеснить находящуюся там страницу и на освободившееся место прочитать новую.
Механизм вытеснения основан на том, что при каждом обращении к буферу процессы увеличивают счетчик числа обращений (usage count) в заголовке буфера. Таким образом те буферы, которые используются реже остальных, имеют меньшее значение счетчика и являются хорошими кандидатами на вытеснение.
Алгоритм clock-sweep перебирает по кругу все буферы (используя указатель на «следующую жертву»), уменьшая на единицу их счетчики обращений. Для вытеснения выбирается первый же буфер, который:
Можно заметить, что если все буферы будут иметь ненулевой счетчик обращений, то алгоритму придется сделать больше одного круга, сбрасывая значения счетчиков, пока какой-то из них не обратится наконец в ноль. Чтобы избежать «наматывания кругов» максимальное значение счетчика обращений ограничено числом 5. Но все равно при большом размере буферного кеша этот алгоритм может вызывать существенные накладные расходы.
После того, как буфер найден, с ним происходит следующее.
Буфер закрепляется, чтобы показать остальным процессам, что он используется. Помимо закрепления используются и другие средства блокировки, но подробнее об этом мы поговорим отдельно.
Если буфер оказался грязным, то есть содержит измененные данные, страницу нельзя просто выбросить — сначала ее требуется сохранить на диск. Это не очень хорошая ситуация, поскольку процессу, который собирается прочитать страницу, приходится ждать записи «чужих» данных, но этот эффект сглаживается процессами контрольной точки и фоновой записи, которые будут рассмотрены позже.
Далее в выбранный буфер читается с диска новая страница. Счетчик числа обращений устанавливается в единицу. Кроме того, ссылку на загруженную страницу необходимо прописать в хеш-таблицу, чтобы в дальнейшем ее можно было найти.
Теперь ссылка на «следующую жертву» указывает на следующий буфер, а у только что загруженного есть время нарастить счетчик обращений, пока указатель не обойдет по кругу весь буферный кеш и не вернется вновь.
Как это принято в PostgreSQL, существует расширение, которое позволяет заглянуть внутрь буферного кеша.
Создадим таблицу и вставим в нее одну строку.
Что окажется в буферном кеше? Как минимум, в нем должна появиться страница, на которую добавлена единственная строка. Проверим это следующим запросом, в котором мы выбираем только буферы, относящиеся к нашей таблице (по номеру файла relfilenode), и расшифровываем номер слоя (relforknumber):
Так и есть — в буфере одна страница. Она грязная (isdirty), счетчик обращений равен единице (usagecount), и она не закреплена ни одним процессом (pinning_backends).
Теперь добавим еще одну строку и повторим запрос. Для экономии букв мы вставляем строку в другом сеансе, а длинный запрос повторяем командой
Новых буферов не прибавилось — вторая строка поместилась на ту же страницу. Обратите внимание, что счетчик использований увеличился.
И после обращения к странице на чтение счетчик тоже увеличивается.
А если выполнить очистку?
Очистка создала карту видимости (одна страница) и карту свободного пространства (три страницы — минимальный размер этой карты).
Ну и так далее.
Размер кеша устанавливается параметром shared_buffers. Значение по умолчанию — смехотворные 128 Мб. Это один из параметров, которые имеет смысл увеличить сразу же после установки PostgreSQL.
Имейте в виду, что изменение параметра требует перезапуска сервера, поскольку вся необходимая под кеш память выделяется при старте сервера.
Из каких соображений выбирать подходящее значение?
Даже самая большая база имеет ограниченный набор «горячих» данных, с которыми ведется активная работа в каждый момент времени. В идеале именно этот набор и должен помещаться в буферный кеш (плюс некоторое место для «одноразовых» данных). Если размер кеша будет меньше, то активно используемые страницы будут постоянно вытеснять друг друга, создавая избыточный ввод-вывод. Но и бездумно увеличивать кеш тоже неправильно. При большом размере будут расти накладные расходы на его поддержание, и кроме того оперативная память требуется и для других нужд.
Таким образом, оптимальный размер буферного кеша будет разным в разных системах: он зависит от данных, от приложения, от нагрузки. К сожалению, нет такого волшебного значения, которое одинаково хорошо подойдет всем.
Стандартная рекомендация — взять в качестве первого приближения 1/4 оперативной памяти (для Windows до версии PostgreSQL 10 рекомендовалось выбирать размер меньше).
А дальше надо смотреть по ситуации. Лучше всего провести эксперимент: увеличить или уменьшить размер кеша и сравнить характеристики системы. Конечно, для этого надо иметь тестовый стенд и уметь воспроизводить типовую нагрузку — на производственной среде такие опыты выглядят сомнительным удовольствием.
Но некоторую информацию о происходящем можно почерпнуть прямо на живой системе с помощью того же расширения pg_buffercache — главное, смотреть под нужным углом.
Например, можно изучить распределение буферов по степени их использования:
В данном случае много пустых значений счетчика — это свободные буферы. Неудивительно для системы, в которой ничего не происходит.
Можно посмотреть, какая доля каких таблиц в нашей базе закеширована и насколько активно используются эти данные (под активным использованием в этом запросе понимаются буферы со счетчиком использования больше 3):
Тут, например, видно, что больше всего место занимает таблица vac (мы использовали ее в одной из прошлых тем), но к ней уже давно никто не обращался и она до сих пор не вытеснена только потому, что еще не закончились свободные буферы.
Можно придумать и другие разрезы, которые дадут полезную информацию для размышлений. Надо только учитывать, что такие запросы:
И еще один момент. Не следует забывать и о том, что PostgreSQL работает с файлами через обычные вызовы операционной системы и, таким образом, происходит двойное кеширование: страницы попадают как в буферный кеш СУБД, так и в кеш ОС. Таким образом, «непопадание» в буферный кеш не всегда приводит к необходимости реального ввода-вывода. Но стратегия вытеснения ОС отличается от стратегии СУБД: операционная система ничего не знает о смысле прочитанных данных.
При операциях, выполняющих массовое чтение или запись данных, есть опасность быстрого вытеснения полезных страниц из буферного кеша «одноразовыми» данными.
Чтобы этого не происходило, для таких операций используются так называемые буферные кольца (buffer ring) — для каждой операции выделяется небольшая часть буферного кеша. Вытеснение действует только в пределах кольца, поэтому остальные данные буферного кеша не страдают.
Для последовательного чтения (sequential scan) больших таблиц (размер которых превышает четверть буферного кеша) выделяется 32 страницы. Если в процессе чтения таблицы другому процессу тоже потребуются эти данные, он не начинает читать таблицу сначала, а подключается к уже имеющемуся буферному кольцу. После окончания сканирования он дочитывает «пропущенное» начало таблицы.
Давайте проверим. Для этого создадим таблицу так, чтобы одна строка занимала целую страницу — так удобнее считать. Размер буферного кеша по умолчанию составляет 128 Мб = 16384 страницы по 8 Кб. Значит, в таблицу надо вставить больше 4096 страниц-строк.
Проанализируем таблицу.
Теперь нам придется перезапустить сервер, чтобы очистить кеш от данных таблицы, которые прочитал анализ.
После перезагрузки прочитаем всю таблицу:
И убедимся, что табличными страницами в буферном кеше занято только 32 буфера:
Если же запретить последовательное сканирование, то таблица будет прочитана по индексу:
В этом случае буферное кольцо не используется и в буферном кеше окажется вся таблица полностью (и почти весь индекс тоже):
Похожим образом буферные кольца используются для процесса очистки (тоже 32 страницы) и для массовых операций записи COPY IN и CREATE TABLE AS SELECT (обычно 2048 страниц, но не больше 1/8 всего буферного кеша).
Исключение из общего правила представляют временные таблицы. Поскольку временные данные видны только одному процессу, им нечего делать в общем буферном кеше. Более того, временные данные существуют только в рамках одного сеанса, так что их не нужно защищать от сбоя.
Для временных данных используется кеш в локальной памяти того процесса, который владеет таблицей. Поскольку такие данные доступны только одному процессу, их не требуется защищать блокировками. В локальном кеше используется обычный алгоритм вытеснения.
В отличие от общего буферного кеша, память под локальный кеш выделяется по мере необходимости, ведь временные таблицы используются далеко не во всех сеансах. Максимальный объем памяти для временных таблиц одного сеанса ограничен параметром temp_buffers.
После перезапуска сервера должно пройти некоторое время, чтобы кеш «прогрелся» — набрал актуальные активно использующиеся данные. Иногда может оказаться полезным сразу прочитать в кеш данные определенных таблиц, и для этого предназначено специальное расширение:
Раньше расширение могло только читать определенные таблицы в буферный кеш (или только в кеш ОС). Но в версии PostgreSQL 11 оно получило возможность сохранять актуальное состояние кеша на диск и восстанавливать его же после перезагрузки сервера. Чтобы этим воспользоваться, надо добавить библиотеку в shared_preload_libraries и перезагрузить сервер.
Поле рестарта, если не менялось значение параметра pg_prewarm.autoprewarm, будет автоматически запущен фоновый процесс autoprewarm master, который раз в pg_prewarm.autoprewarm_interval будет сбрасывать на диск список страниц, находящихся в кеше (не забудьте учесть новый процесс при установке max_parallel_processes).
Сейчас в кеше нет таблицы big:
Если мы предполагаем, что все ее содержимое очень важно, мы можем прочитать ее в буферный кеш с помощью вызова следующей функции:
Список страниц сбрасывается в файл autoprewarm.blocks. Чтобы его увидеть, можно просто подождать, пока процесс autoprewarm master отработает в первый раз, но мы инициируем это вручную:
Число сброшенных страниц больше 4097 — сюда входят и уже прочитанные сервером страницы объектов системного каталога. А вот и файл:
Теперь снова перезапустим сервер.
И сразу после запуска наша таблица снова оказывается в кеше.
Это обеспечивает тот же самый процесс autoprewarm master: он читает файл, разделяет страницы по базам данных, сортирует их (чтобы чтение с диска было по возможности последовательным) и передает отдельному рабочему процессу autoprewarm worker для обработки.
Продолжение.
Этот цикл будет состоять из четырех частей:
- Буферный кеш (эта статья);
- Журнал предзаписи — как устроен и как используется при восстановлении;
- Контрольная точка и фоновая запись — зачем нужны и как настраиваются;
- Настройка журнала — уровни и решаемые задачи, надежность и производительность.
Читайте и другие серии.
Индексы:
- Механизм индексирования;
- Интерфейс метода доступа, классы и семейства операторов;
- Hash;
- B-tree;
- GiST;
- SP-GiST;
- GIN;
- RUM;
- BRIN;
- Bloom.
Изоляция и многоверсионность:
- Изоляция, как ее понимают стандарт и PostgreSQL;
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Блокировки:
- Блокировки отношений;
- Блокировки строк;
- Блокировки других объектов и предикатные блокировки;
- Блокировки в оперативной памяти.
Зачем нужно журналирование?
В процессе работы часть данных, с которыми имеет дело СУБД, хранится в оперативной памяти и записывается на диск (или на другой энергонезависимый носитель) отложенным образом. Чем реже это происходит, тем меньше ввод-вывод и тем быстрее работает система.
Но что произойдет в случае сбоя, например, при выключении электропитания или при ошибке в коде СУБД или операционной системы? Все содержимое оперативной памяти будет потеряно, а останутся лишь данные, записанные на диск (при некоторых видах сбоев может пострадать и диск, но в этом случае поможет лишь резервная копия). В принципе можно организовать ввод-вывод таким образом, чтобы данные на диске всегда поддерживались в согласованном состоянии, но это сложно и не слишком эффективно (насколько я знаю, только Firebird пошел таким путем).
Обычно же — в том числе и в PostgreSQL — данные, записанные на диск, оказываются несогласованными и при восстановлении после сбоя требуются специальные действия, чтобы согласованность восстановить. Журналирование — тот самый механизм, который делает это возможным.
Буферный кеш
Разговор о журналировании мы, как ни странно, начнем с буферного кеша. Буферный кеш — не единственная структура, которая хранится в оперативной памяти, но одна из самых важных и сложных. Понимание принципа его работы важно само по себе, к тому же на этом примере мы познакомимся с тем, как происходит обмен данными между оперативной памятью и диском.
Кеширование используется в современных вычислительных системах повсеместно, у одного только процессора можно насчитать три-четыре уровня кеша. Вообще любой кеш нужен для того, чтобы сглаживать разницу в производительности двух типов памяти, одна из которых относительно быстрая, но ее на всех не хватает, а другая — относительно медленная, но имеющаяся в достатке. Вот и буферный кеш сглаживает разницу между временем доступа к оперативной памяти (наносекунды) и к дисковой (миллисекунды).
Заметим, что у операционной системы тоже есть дисковый кеш, который решает ту же самую задачу. Поэтому обычно СУБД стараются избегать двойного кеширования, обращаясь к диску напрямую, минуя кеш ОС. Но в случае PostgreSQL это не так: все данные читаются и записываются с помощью обычных файловых операций.
Кроме того, свой кеш бывает также у контроллеров дисковых массивов, и даже у самих дисков. Этот факт нам еще пригодится, когда мы доберемся до вопроса надежности.
Но вернемся к буферному кешу СУБД.
Называется он так потому, что представляет собой массив буферов. Каждый буфер — это место под одну страницу данных (блок), плюс заголовок. Заголовок, в числе прочего, содержит:
- расположение на диске страницы, находящейся в буфере (файл и номер блока в нем);
- признак того, что данные на странице изменились и рано или поздно должны быть записаны на диск (такой буфер называют грязным);
- число обращений к буферу (usage count);
- признак закрепления буфера (pin count).
Буферный кеш располагается в общей памяти сервера и доступен всем процессам. Чтобы работать с данными — читать или изменять, — процессы читают страницы в кеш. Пока страница находится в кеше, мы работаем с ней в оперативной памяти и экономим на обращениях к диску.

Изначально кеш содержит пустые буферы, и все они связаны в список свободных буферов. Смысл указателя на «следующую жертву» станет ясен чуть позже. Чтобы быстро находить нужную страницу в кеше, используется хеш-таблица.
Поиск страницы в кеше
Когда процессу требуется прочитать страницу, он сначала пытается найти ее в буферном кеше с помощью хеш-таблицы. Ключом хеширования служит номер файла и номер страницы внутри файла. В соответствующей корзине хеш-таблицы процесс находит номер буфера и проверяет, действительно ли он содержат нужную страницу. Как и с любой хеш-таблицей, здесь возможны коллизии; в таком случае процессу придется проверять несколько страниц.
Использование хеш-таблицы давно вызывает нарекания. Такая структура позволяет быстро найти буфер по странице, но совершенно бесполезна, если, например, надо найти все буферы, занятые определенной таблицей. Но хорошую замену пока никто не предложил.
Если нужная страница найдена в кеше, процесс должен «закрепить» буфер, увеличив счетчик pin count (несколько процессов могут сделать это одновременно). Пока буфер закреплен (значение счетчика больше нуля), считается, что буфер используется и его содержимое не должно «радикально» измениться. Например, в странице может появиться новая версия строки — это никому не мешает благодаря многоверсионности и правилам видимости. Но в закрепленный буфер не может быть прочитана другая страница.
Вытеснение
Может получиться так, что необходимая страница не будет найдена в кеше. В этом случае ее необходимо считать с диска в какой-либо буфер.
Если в кеше еще остались свободные буферы, то выбирается первый же свободный. Но рано или поздно они закончатся (обычно размер базы данных больше чем память, выделенная под кеш) и тогда придется выбирать один из занятых буферов, вытеснить находящуюся там страницу и на освободившееся место прочитать новую.
Механизм вытеснения основан на том, что при каждом обращении к буферу процессы увеличивают счетчик числа обращений (usage count) в заголовке буфера. Таким образом те буферы, которые используются реже остальных, имеют меньшее значение счетчика и являются хорошими кандидатами на вытеснение.
Алгоритм clock-sweep перебирает по кругу все буферы (используя указатель на «следующую жертву»), уменьшая на единицу их счетчики обращений. Для вытеснения выбирается первый же буфер, который:
- имеет нулевой счетчик обращений (usage count),
- и не закреплен (нулевой pin count).
Можно заметить, что если все буферы будут иметь ненулевой счетчик обращений, то алгоритму придется сделать больше одного круга, сбрасывая значения счетчиков, пока какой-то из них не обратится наконец в ноль. Чтобы избежать «наматывания кругов» максимальное значение счетчика обращений ограничено числом 5. Но все равно при большом размере буферного кеша этот алгоритм может вызывать существенные накладные расходы.
После того, как буфер найден, с ним происходит следующее.
Буфер закрепляется, чтобы показать остальным процессам, что он используется. Помимо закрепления используются и другие средства блокировки, но подробнее об этом мы поговорим отдельно.
Если буфер оказался грязным, то есть содержит измененные данные, страницу нельзя просто выбросить — сначала ее требуется сохранить на диск. Это не очень хорошая ситуация, поскольку процессу, который собирается прочитать страницу, приходится ждать записи «чужих» данных, но этот эффект сглаживается процессами контрольной точки и фоновой записи, которые будут рассмотрены позже.
Далее в выбранный буфер читается с диска новая страница. Счетчик числа обращений устанавливается в единицу. Кроме того, ссылку на загруженную страницу необходимо прописать в хеш-таблицу, чтобы в дальнейшем ее можно было найти.
Теперь ссылка на «следующую жертву» указывает на следующий буфер, а у только что загруженного есть время нарастить счетчик обращений, пока указатель не обойдет по кругу весь буферный кеш и не вернется вновь.
Своими глазами
Как это принято в PostgreSQL, существует расширение, которое позволяет заглянуть внутрь буферного кеша.
=> CREATE EXTENSION pg_buffercache;
Создадим таблицу и вставим в нее одну строку.
=> CREATE TABLE cacheme(
id integer
) WITH (autovacuum_enabled = off);
=> INSERT INTO cacheme VALUES (1);
Что окажется в буферном кеше? Как минимум, в нем должна появиться страница, на которую добавлена единственная строка. Проверим это следующим запросом, в котором мы выбираем только буферы, относящиеся к нашей таблице (по номеру файла relfilenode), и расшифровываем номер слоя (relforknumber):
=> SELECT bufferid,
CASE relforknumber
WHEN 0 THEN 'main'
WHEN 1 THEN 'fsm'
WHEN 2 THEN 'vm'
END relfork,
relblocknumber,
isdirty,
usagecount,
pinning_backends
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('cacheme'::regclass);
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 1 | 0
(1 row)
Так и есть — в буфере одна страница. Она грязная (isdirty), счетчик обращений равен единице (usagecount), и она не закреплена ни одним процессом (pinning_backends).
Теперь добавим еще одну строку и повторим запрос. Для экономии букв мы вставляем строку в другом сеансе, а длинный запрос повторяем командой
\g.| => INSERT INTO cacheme VALUES (2);
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 2 | 0
(1 row)
Новых буферов не прибавилось — вторая строка поместилась на ту же страницу. Обратите внимание, что счетчик использований увеличился.
| => SELECT * FROM cacheme;
| id
| ----
| 1
| 2
| (2 rows)
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15735 | main | 0 | t | 3 | 0
(1 row)
И после обращения к странице на чтение счетчик тоже увеличивается.
А если выполнить очистку?
| => VACUUM cacheme;
=> \g
bufferid | relfork | relblocknumber | isdirty | usagecount | pinning_backends
----------+---------+----------------+---------+------------+------------------
15731 | fsm | 1 | t | 1 | 0
15732 | fsm | 0 | t | 1 | 0
15733 | fsm | 2 | t | 2 | 0
15734 | vm | 0 | t | 2 | 0
15735 | main | 0 | t | 3 | 0
(5 rows)
Очистка создала карту видимости (одна страница) и карту свободного пространства (три страницы — минимальный размер этой карты).
Ну и так далее.
Настройка размера
Размер кеша устанавливается параметром shared_buffers. Значение по умолчанию — смехотворные 128 Мб. Это один из параметров, которые имеет смысл увеличить сразу же после установки PostgreSQL.
=> SELECT setting, unit FROM pg_settings WHERE name = 'shared_buffers';
setting | unit
---------+------
16384 | 8kB
(1 row)
Имейте в виду, что изменение параметра требует перезапуска сервера, поскольку вся необходимая под кеш память выделяется при старте сервера.
Из каких соображений выбирать подходящее значение?
Даже самая большая база имеет ограниченный набор «горячих» данных, с которыми ведется активная работа в каждый момент времени. В идеале именно этот набор и должен помещаться в буферный кеш (плюс некоторое место для «одноразовых» данных). Если размер кеша будет меньше, то активно используемые страницы будут постоянно вытеснять друг друга, создавая избыточный ввод-вывод. Но и бездумно увеличивать кеш тоже неправильно. При большом размере будут расти накладные расходы на его поддержание, и кроме того оперативная память требуется и для других нужд.
Таким образом, оптимальный размер буферного кеша будет разным в разных системах: он зависит от данных, от приложения, от нагрузки. К сожалению, нет такого волшебного значения, которое одинаково хорошо подойдет всем.
Стандартная рекомендация — взять в качестве первого приближения 1/4 оперативной памяти (для Windows до версии PostgreSQL 10 рекомендовалось выбирать размер меньше).
А дальше надо смотреть по ситуации. Лучше всего провести эксперимент: увеличить или уменьшить размер кеша и сравнить характеристики системы. Конечно, для этого надо иметь тестовый стенд и уметь воспроизводить типовую нагрузку — на производственной среде такие опыты выглядят сомнительным удовольствием.
Обязательно посмотрите доклад Николая Самохвалова на PgConf-2019: "Промышленный подход к тюнингу PostgreSQL: эксперименты над базами данных"
Но некоторую информацию о происходящем можно почерпнуть прямо на живой системе с помощью того же расширения pg_buffercache — главное, смотреть под нужным углом.
Например, можно изучить распределение буферов по степени их использования:
=> SELECT usagecount, count(*)
FROM pg_buffercache
GROUP BY usagecount
ORDER BY usagecount;
usagecount | count
------------+-------
1 | 221
2 | 869
3 | 29
4 | 12
5 | 564
| 14689
(6 rows)
В данном случае много пустых значений счетчика — это свободные буферы. Неудивительно для системы, в которой ничего не происходит.
Можно посмотреть, какая доля каких таблиц в нашей базе закеширована и насколько активно используются эти данные (под активным использованием в этом запросе понимаются буферы со счетчиком использования больше 3):
=> SELECT c.relname,
count(*) blocks,
round( 100.0 * 8192 * count(*) / pg_table_size(c.oid) ) "% of rel",
round( 100.0 * 8192 * count(*) FILTER (WHERE b.usagecount > 3) / pg_table_size(c.oid) ) "% hot"
FROM pg_buffercache b
JOIN pg_class c ON pg_relation_filenode(c.oid) = b.relfilenode
WHERE b.reldatabase IN (
0, (SELECT oid FROM pg_database WHERE datname = current_database())
)
AND b.usagecount is not null
GROUP BY c.relname, c.oid
ORDER BY 2 DESC
LIMIT 10;
relname | blocks | % of rel | % hot
---------------------------+--------+----------+-------
vac | 833 | 100 | 0
pg_proc | 71 | 85 | 37
pg_depend | 57 | 98 | 19
pg_attribute | 55 | 100 | 64
vac_s | 32 | 4 | 0
pg_statistic | 27 | 71 | 63
autovac | 22 | 100 | 95
pg_depend_reference_index | 19 | 48 | 35
pg_rewrite | 17 | 23 | 8
pg_class | 16 | 100 | 100
(10 rows)
Тут, например, видно, что больше всего место занимает таблица vac (мы использовали ее в одной из прошлых тем), но к ней уже давно никто не обращался и она до сих пор не вытеснена только потому, что еще не закончились свободные буферы.
Можно придумать и другие разрезы, которые дадут полезную информацию для размышлений. Надо только учитывать, что такие запросы:
- надо повторять несколько раз: цифры будут меняться в определенных пределах;
- не надо выполнять постоянно (как часть мониторинга) из-за того, что расширение кратковременно блокирует работу с буферным кешем.
И еще один момент. Не следует забывать и о том, что PostgreSQL работает с файлами через обычные вызовы операционной системы и, таким образом, происходит двойное кеширование: страницы попадают как в буферный кеш СУБД, так и в кеш ОС. Таким образом, «непопадание» в буферный кеш не всегда приводит к необходимости реального ввода-вывода. Но стратегия вытеснения ОС отличается от стратегии СУБД: операционная система ничего не знает о смысле прочитанных данных.
Массовое вытеснение
При операциях, выполняющих массовое чтение или запись данных, есть опасность быстрого вытеснения полезных страниц из буферного кеша «одноразовыми» данными.
Чтобы этого не происходило, для таких операций используются так называемые буферные кольца (buffer ring) — для каждой операции выделяется небольшая часть буферного кеша. Вытеснение действует только в пределах кольца, поэтому остальные данные буферного кеша не страдают.
Для последовательного чтения (sequential scan) больших таблиц (размер которых превышает четверть буферного кеша) выделяется 32 страницы. Если в процессе чтения таблицы другому процессу тоже потребуются эти данные, он не начинает читать таблицу сначала, а подключается к уже имеющемуся буферному кольцу. После окончания сканирования он дочитывает «пропущенное» начало таблицы.
Давайте проверим. Для этого создадим таблицу так, чтобы одна строка занимала целую страницу — так удобнее считать. Размер буферного кеша по умолчанию составляет 128 Мб = 16384 страницы по 8 Кб. Значит, в таблицу надо вставить больше 4096 страниц-строк.
=> CREATE TABLE big(
id integer PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
s char(1000)
) WITH (fillfactor=10);
=> INSERT INTO big(s) SELECT 'FOO' FROM generate_series(1,4096+1);
Проанализируем таблицу.
=> ANALYZE big;
=> SELECT relpages FROM pg_class WHERE oid = 'big'::regclass;
relpages
----------
4097
(1 row)
Теперь нам придется перезапустить сервер, чтобы очистить кеш от данных таблицы, которые прочитал анализ.
student$ sudo pg_ctlcluster 11 main restart
После перезагрузки прочитаем всю таблицу:
=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;
QUERY PLAN
---------------------------------------------------------------------
Aggregate (actual time=14.472..14.473 rows=1 loops=1)
-> Seq Scan on big (actual time=0.031..13.022 rows=4097 loops=1)
Planning Time: 0.528 ms
Execution Time: 14.590 ms
(4 rows)
И убедимся, что табличными страницами в буферном кеше занято только 32 буфера:
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
32
(1 row)
Если же запретить последовательное сканирование, то таблица будет прочитана по индексу:
=> SET enable_seqscan = off;
=> EXPLAIN (ANALYZE, COSTS OFF) SELECT count(*) FROM big;
QUERY PLAN
-------------------------------------------------------------------------------------------
Aggregate (actual time=50.300..50.301 rows=1 loops=1)
-> Index Only Scan using big_pkey on big (actual time=0.098..48.547 rows=4097 loops=1)
Heap Fetches: 4097
Planning Time: 0.067 ms
Execution Time: 50.340 ms
(5 rows)
В этом случае буферное кольцо не используется и в буферном кеше окажется вся таблица полностью (и почти весь индекс тоже):
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
Похожим образом буферные кольца используются для процесса очистки (тоже 32 страницы) и для массовых операций записи COPY IN и CREATE TABLE AS SELECT (обычно 2048 страниц, но не больше 1/8 всего буферного кеша).
Временные таблицы
Исключение из общего правила представляют временные таблицы. Поскольку временные данные видны только одному процессу, им нечего делать в общем буферном кеше. Более того, временные данные существуют только в рамках одного сеанса, так что их не нужно защищать от сбоя.
Для временных данных используется кеш в локальной памяти того процесса, который владеет таблицей. Поскольку такие данные доступны только одному процессу, их не требуется защищать блокировками. В локальном кеше используется обычный алгоритм вытеснения.
В отличие от общего буферного кеша, память под локальный кеш выделяется по мере необходимости, ведь временные таблицы используются далеко не во всех сеансах. Максимальный объем памяти для временных таблиц одного сеанса ограничен параметром temp_buffers.
Прогрев кеша
После перезапуска сервера должно пройти некоторое время, чтобы кеш «прогрелся» — набрал актуальные активно использующиеся данные. Иногда может оказаться полезным сразу прочитать в кеш данные определенных таблиц, и для этого предназначено специальное расширение:
=> CREATE EXTENSION pg_prewarm;
Раньше расширение могло только читать определенные таблицы в буферный кеш (или только в кеш ОС). Но в версии PostgreSQL 11 оно получило возможность сохранять актуальное состояние кеша на диск и восстанавливать его же после перезагрузки сервера. Чтобы этим воспользоваться, надо добавить библиотеку в shared_preload_libraries и перезагрузить сервер.
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_prewarm';
student$ sudo pg_ctlcluster 11 main restart
Поле рестарта, если не менялось значение параметра pg_prewarm.autoprewarm, будет автоматически запущен фоновый процесс autoprewarm master, который раз в pg_prewarm.autoprewarm_interval будет сбрасывать на диск список страниц, находящихся в кеше (не забудьте учесть новый процесс при установке max_parallel_processes).
=> SELECT name, setting, unit FROM pg_settings WHERE name LIKE 'pg_prewarm%';
name | setting | unit
---------------------------------+---------+------
pg_prewarm.autoprewarm | on |
pg_prewarm.autoprewarm_interval | 300 | s
(2 rows)
postgres$ ps -o pid,command --ppid `head -n 1 /var/lib/postgresql/11/main/postmaster.pid` | grep prewarm
10436 postgres: 11/main: autoprewarm master
Сейчас в кеше нет таблицы big:
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
0
(1 row)
Если мы предполагаем, что все ее содержимое очень важно, мы можем прочитать ее в буферный кеш с помощью вызова следующей функции:
=> SELECT pg_prewarm('big');
pg_prewarm
------------
4097
(1 row)
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
Список страниц сбрасывается в файл autoprewarm.blocks. Чтобы его увидеть, можно просто подождать, пока процесс autoprewarm master отработает в первый раз, но мы инициируем это вручную:
=> SELECT autoprewarm_dump_now();
autoprewarm_dump_now
----------------------
4340
(1 row)
Число сброшенных страниц больше 4097 — сюда входят и уже прочитанные сервером страницы объектов системного каталога. А вот и файл:
postgres$ ls -l /var/lib/postgresql/11/main/autoprewarm.blocks
-rw------- 1 postgres postgres 102078 июн 29 15:51 /var/lib/postgresql/11/main/autoprewarm.blocks
Теперь снова перезапустим сервер.
student$ sudo pg_ctlcluster 11 main restart
И сразу после запуска наша таблица снова оказывается в кеше.
=> SELECT count(*)
FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('big'::regclass);
count
-------
4097
(1 row)
Это обеспечивает тот же самый процесс autoprewarm master: он читает файл, разделяет страницы по базам данных, сортирует их (чтобы чтение с диска было по возможности последовательным) и передает отдельному рабочему процессу autoprewarm worker для обработки.
Продолжение.
