
Привет! Меня зовут Екатерина Ванская, и я занимаюсь data science в компании Prequel. В этой статье я продолжу обзор рекомендательных алгоритмов, который мы начали в предыдущем материале
Область рекомендаций усложняется по мере расширения сферы ее применения, с каждым новым вызовом и нюансом использования. По мере увеличения объемов данных и усложнения задач появлялись новые подходы, отличные от рассмотренных ранее простых коллаборативных моделей. Мы для удобства разобьем их на несколько крупных направлений:
Learn to Rank алгоритмы, которые улучшают ранжирование за счет оценивания всего списка в совокупности а не поэлементно.
Sequential алгоритмы, которые учитывают последовательность действий, за счет чего точнее предсказывают следующий элемент в цепочке действий.
Variational Autoencoders, которые позволяют генерировать эмбеддинги из совокупности коллаборативной информации и содержимого контента.
Reinforcement Learning алгоритмы, которые позволяют значительно расширить палитру целевых метрик, которые мы можем улучшать своей рекомендательной системой.
Кроме того, рассмотрим некоторые другие способы улучшения рекомендаций.
Также, ближе к концу я обращусь к знаковому обзору исследователей из Миланского университета, который поднимает важные вопросы валидации и сравнения рекомендательных алгоритмов из разных семейств на разных датасетах. Их статья помогает осознать сложности численной оценки прогресса рекомендательных алгоритмов.
Если алгоритмы первой статьи использовали в качестве данных для обучения простую матрицу взаимодействий пользователь-контент, которая фиксировала только сами факты взаимодействия, то алгоритмы, которые мы рассмотрим сейчас, могут использовать дополнительную информацию.
Алгоритмы Learning to Rank
Главное отличие алгоритмов LTR от традиционного ML в том, что, если традиционно предсказание строится для одного объекта в один момент времени, то LTR работает со всем списком, оценивая ранжирование в целом. Это дает возможность отсортировать не просто по признаку «посмотрел пользователь или нет», а используя реальный порядок просмотра и оценивая взаимное расположение объектов в ленте. Тренировочные данные для LTR состоят из некоторого истинного порядка расположения рекомендаций, который модель обучается повторять. Есть несколько подходов к построению ранжирования.
Pointwise — это обычная задача регрессии: нужно проассоциировать каждый объект с неким числом (оценкой) и затем в соответствии с ним ранжировать.
Pairwise-подход — это попытка задать функцию отношения на множестве объектов. То есть, модель получает на вход два объекта и должна выдать вероятность того, что первый из них больше подходит пользователю, чем второй. Вообще говоря, при таком подходе мы не получаем математически выверенной операции, могут быть накладки в виде невыполнения ассоциативности, транзитивности или других свойств — методы обучения Pairwise модели не всегда гарантируют их соблюдение. Тем не менее, он гораздо лучше отвечает задаче ранжирования, чем Pointwise.
И, наконец, listwise-подход, когда оценивается все ранжирование целиком. Можно прямо оптимизировать такие метрики, как NDCG (метрики ранжирования рассматривались в предыдущей части этого обзора).
На картинке представлены списки популярных LTR-алгоритмов. Я возьму для рассмотрения по одному из категорий pairwise и listwise.

RankNet
RankNet — это вариант pairwise подхода, придуманный в 2005 году. Он предполагает наличие размеченных обучающих примеров для некоторых пар контента.
В RankNet модель может быть любой, обычно это нейросеть, хотя может быть и ансамбль деревьев. RankNet преобразует входной вектор фич x для элемента в оценку s. А затем пара оценок преобразуется в значение вероятности, что первый элемент более релевантен, чем второй.

Функцией ошибки выступает кросс-энтропия:

Если у нас есть точные оценки релевантности, и S для пары i,j принимает значения {-1, 0, +1}, то получаем симметричную ошибку:

Можно рассчитать градиент:

И градиент по весам:

И факторизовать:

Если мы упорядочим примеры так, чтобы x_i было больше x_j, тогда S будет всегда равно 1, тогда получим:

Обучается модель с помощью градиентного спуска. Получается алгоритм, направленный на минимизацию инверсий в ранжировании, где инверсии — это неправильно расставленные пары элементов. Уменьшая их количество, алгоритм приближается к идеальному ранжированию.
LambdaRank
Следующим шагом посмотрим на работу сразу с целым списком ранжирования.
Рассмотрим listwise-подход, который позволит оптимизировать напрямую NDCG. Рассматривая формулу метрики, можно вспомнить, что сама ошибка не нужна, а нужны только градиенты 𝜆. Нас не интересуют абсолютные значения NDCG, нам нужна такая «сила», которая будет толкать вниз некий элемент, если тот случайно расположился выше более релевантного, увеличивая таким образом NDCG по отношению к исходному значению (каким бы оно ни было).
Давайте просто представим себе некоторую функцию ошибки, у которой градиент 𝜆:

где ΔNDCG — это то, на сколько NDCG изменится, если поменять 𝑖 и 𝑗 местами.
NDCG нужно максимизировать, так что берём:

Оказывается, что такой подход фактически напрямую оптимизирует NDCG (сглаженную версию). Таким образом, можно не знать функцию, а просто придумать подходящие градиенты. По лемме Пуанкаре это такие, чтобы под них существовала функция, чтобы сходились вторые частные производные. Более того, если мы хотим оптимизировать некоторые другие метрикии, такие как MRR или MAP, то LambdaRank можно изменить для достижения этой цели.
LambdaRank — это старый подход, родом он из 2007 года. Я привела его в пример как одну из самых простых идей для ранжирования. Поскольку функции, работающие со списком, очевидно, вычислительно тяжелее, то чаще всего строятся двухэтапные системы: первый этап — это отбор кандидатов любым доступным образом, а вторым этапом идет ранжирование сокращенного списка.
Действительно, обычно не важно, насколько хорошо система ранжирует вторую тысячу элементов в списке, никто не станет так далеко листать. А вот для первого десятка критично получить не просто достаточно хорошее, но лучшее из возможных ранжирование, поскольку именно оно зачастую будет влиять на опыт использования сервиса для пользователя.
Модель Wide & Deep Learning for Recommender Systems
Embedding-based модели вроде factorization machines или Deep-NN хорошо обобщают, но исходная матрица взаимодействий крайне разрежена и велика, так что юзеры со специфическими вкусами (или специфический контент) часто получают не очень качественные рекомендации. Более простые линейные модели могут вычислить такие «исключения» по меньшему количеству параметров. Кроме того, линейные модели хорошо интерпретируются, но плохо обобщают — и неспособны ловить ложные зависимости.
В 2016 году Google разработал комбинированную модель для рекомендации приложений в Google Play. Поскольку число приложений велико, то предварительно производится отбор кандидатов (комбинацией модели и эмпирических правил), а затем список приложений-кандидатов поступает на вход модели, которая их оценивает по вероятности установки. Далее, исходя из этой оценки, приложения ранжируются и предлагаются пользователю.

Wide Component
Этот компонент описывается как: y = wT*x + b. Фичи x включают как сырые входные переменные (one-hot encoded категориальные признаки пользователя и контента), так и трансформированные. Главное преобразование, которое здесь применяется — это cross-product transformation, произведения фич. Для бинарных фич это эквивалентно логическому «И» оператору: добавляет нелинейности и помогает улавливать взаимное влияние разных фич.
Deep Component
Это нейросеть, где входные категориальные признаки предварительно кодируются one-hot. Затем это разреженное представление преобразуются в плотные вектора эмбеддингов (обычно размерности 10–100), по своему вектору на каждую категориальную фичу. Далее они конкатинируются и пропускаются через 3 полносвязных слоя с ReLU активацией.

От предсказаний wide- и deep- компонент берется взвешенная сумма и считается совместный log loss, обе части тренируются совместно. Цель wide-части — дополнить слабые места deep-компонента, потому сама по себе эта модель не обязана быть большой или по-настоящему точной (потому число cross-product фич может быть небольшим).
Этот алгоритм показывает необходимость учитывать как коллаборативные фичи, так и более простые (но содержащие полезную дополнительную информацию) фичи контента и пользователей. К тому же он учитывает интересы как активных, так и менее активных пользователей. Модели смешанного типа не ограничиваются Wide & Deep алгоритмом, но он имеет довольно широкое применение в настоящее время.
Модели Sequential Recommendation
Следующая большая категория это sequential рекомендательные алгоритмы.
Большой недостаток многих моделей в том, что они рассматривают действия пользователя без учета временного фактора: то есть, только как факт взаимодействия пользователя с контентом, но не как последовательность. Между тем, существуют нейросети, созданные для анализа именно последовательностей событий.
Существуют подходы для учета последовательностей в рекомендациях с использованием Цепей Маркова и алгоритмов recurrent neural network (RNN).
Цепи Маркова хорошо показывают себя на очень разреженных данных, где помогают экономить время для вычислений. RNN-модели лучше работают с более плотными данными, где они позволяют находить более сложные закономерности.
Рассмотрим на примерах.
Self-Attentive Sequential Recommendation (SASRec)
SASRec — это один из более новых (2018 года) и сложных подходов, использующих механизм внимания. Этот подход позволяет выделять сложные закономерности подобно RNN-моделям, но снизить требования к объемам обучающей выборки.
На каждом шаге SASRec пытается определить, какие действия являются наиболее важными из истории пользователя, и использовать их для прогнозирования следующего действия. еханизм self-attention, схема которого приведена ниже, отлично зарекомендовал себя в задачах описания изображений, обобщения текста, машинном переводе. В некотором смысле, эти задачи похожи на рекомендации.

SASRec вдохновлена Transformer-нейросетями. Кроме self-attention-механизма SASRec включает слой Embedding, который состоит из эмбеддингов контента и позиции его в последовательности.

Кроме того, здесь используется Point-Wise Feed-Forward Network для усложнения модели и добавления нелинейности. Она представляет из себя двухслойную сеть с общими для всех входов параметрами.

SASRec не только хорошо зарекомендовала себя как рекомендательный алгоритм, но и послужила базой для многих более сложных моделей, вроде появившейся в 2019 году BERT4Rec.
FISSA: Fusing Item Similarity Models with Self-Attention
Одна из таких производных моделей это FISSA (2020 года), как гибрид из более сложных новых и более старых базовых подходов.
Рекомендательные модели, учитывающие последовательность действий, увеличивают точность за счет учета динамики предпочтений. При этом постоянные и глобальные предпочтения недооцениваются. FISSA — это state-of-the-art модель на последовательностях событий с self-attention механизмом, которая балансирует локальные (динамические) предпочтения пользователя и глобальные.
Для локальных (динамических) предпочтений берется SASRec, как хорошо зарекомендовавший себя метод. Для учета глобальных предпочтений используется location-based (основанный на позиции в пространстве) attention-слой.

Здесь используется implicit feedback: то есть на вход поступает последовательность из L последних объектов с которыми взаимодействовал пользователь. Цель — выдать список рекомендаций, в котором реальный следующий объект взаимодействия будет как можно ближе к началу списка.
Здесь хочется заметить, что многие рекомендательные модели так или иначе приходят к идеи гибридных моделей. Вероятно причина в том, что хорошая рекомендательная система должна подходить большому числу разных в поведении пользователей и решать одновременно несколько задач (которые уже перечислялись в первой части).
Collaborative Memory Networks (CMN)
Немного отойдем от sequential, но продолжим с механизмом внимания.
Еще один пример комбинированной модели 2018 года, сочетающей в себе нейросеть типа Memory Augmented с attention-механизмом, которая при этом учитывает сильные стороны матричного разложения.

Схема модели на картинке. Компонент памяти состоит из матриц с факторами пользователей и объектов. Вектор рекомендаций строится на механизме схожести, где для каждого пользователя v, который взаимодействовал с объектом i, оценивается схожесть пользователей v и u (целевого), а также уверенность в предпочтениях пользователя v относительно объекта i. В качестве явного фидбэка в данной модели может использоваться просто рейтинг.

Это похоже по сути своей на матричное разложение или методы ближайших соседей (k-NN). Но в методе ближайших соседей заранее выбирается константа k – количество соседей, мнения которых мы усредняем. В матричном разложении заранее выбирается функция схожести, например косинусное сходство (cosine similarity).
Механизм внимания позволяет заменить эмпирический выбор на обучаемые коэффициенты для взвешенного вклада других пользователей.

В итоге эмбеддинги из компонента памяти взвешиваются с коэффициентами внимания и суммируются.

Collaborative Variational Autoencoder (CVAE)
Сейчас в рекомендациях широко используются адаптации моделей, хорошо зарекомендовавших себя в других различных областях. Например, вариационные автоэнкодеры (VAE).
Это модель 2017 года, которая учитывает и коллаборативную информацию, и содержание (в данном случае текст, но можно адаптировать под другие типы контента) внутри одной VAE-модели.
Гибридные (учитывающие оба вида информации) системы делятся на слабосвязные и сильносвязные. Слабосвязные по сути представляют собой две отдельные модели, связанные отдельной моделью или эвристиками. Большей отказоустойчивостью обладают, разумеется, сильносвязные модели. По сути, это модель генерации эмбеддингов, которые генерируются как из содержания (unsupervised), так и из коллаборативный информации.
В качестве основы используется модель probabilistic matrix factorization (PMF), которые сворачивают коллаборативную информацию каждого объекта в эмбеддинги (которые подчиняются нормальному распределению).

В отличии от классического PMF эта модель использует и данные о содержимом контента.
Общая схема сети выглядит таким образом (где 𝜆 — это гиперпараметры).

Скрытая переменная объекта при этом составляется из коллаборативный скрытой переменной и скрытой переменной содержимого контента.

Тестирование модели проводилось на датасетах сервиса для сбора статей CiteULike со случайным (а не по времени) разбиением на тренировочный и тестовый наборы. Метрикой выбрана recall@M. CVAE алгоритм показывает лучшие результаты по сравнению с такими методами, как Collaborative Deep Learning, Collaborative Topic Regression и DeepMusic.
Reinforcement Learning
Небольшой скачок к еще одному принципиально отличающемуся от предыдущих подходу.
Мы уже говорили о проблемах выбора метрик в рекомендательных системах в предыдущей части. Простые дифференцируемые метрики плохо коррелируют с реальными бизнес-метриками, к тому же запирают нас в кольцо самосбывающихся пророчеств. Возможный выход — Reinforcement Learning (RL), где существует награда (действующего агента), которая может быть вообще любой.
Для начала немного о базовых понятиях RL (напомнить тем, кто знает, познакомить остальных).

Так выглядит среда в которой мы существуем: состояния, действия, награды, переходы в новые состояния (могут быть вероятностными). Задача — максимизация суммарной награды. Policy — стратегия: набор действий для каждого состояния (или вероятностей, если наша стратегия стохастическая).
Value function — это ожидаемая суммарная награда в состоянии s.

Q — функция, которая оценивает, какова будет суммарная награда, если в состоянии s мы выберем действие a. Она создана так, что ее удобно выражать рекурсивно (это называется уравнением Беллмана). Мы можем использовать это, чтобы вычислять ошибку оценки и делать поправки. Такой подход носит название Q-learning.

Яндекс Дзен, например, использует для рекомендаций off-policy model-free Q-learning подход. Model-free значит, что нет отдельной модели для моделирования среды, а только модель для политики (стратегии).
Off-policy в отличии от on-policy использует накопленный уже датасет взаимодействий со средой (агентом с любой политикой) для оффлайн-обучения модели.
Deep Deterministic Policy Gradient
У применения RL в рекомендациях есть сложности. Одна из них — большое поле «возможных действий». Обычно это набор вида: пойти налево-направо-вперед-назад. Здесь же «действием» будет показ любого из миллионов (или сколько у нас есть) объектов в рекомендациях. Это делает расчёты очень дорогими.
Чтобы не считать ошибку на каждом шаге для всех возможных действий, используется подход называемый Deep Deterministic Policy Gradients (DDPG).

Актор предлагает лучшее действие в текущей ситуации. Пытается максимизировать оценку критика.
Критик обучается с помощью Q-learning.

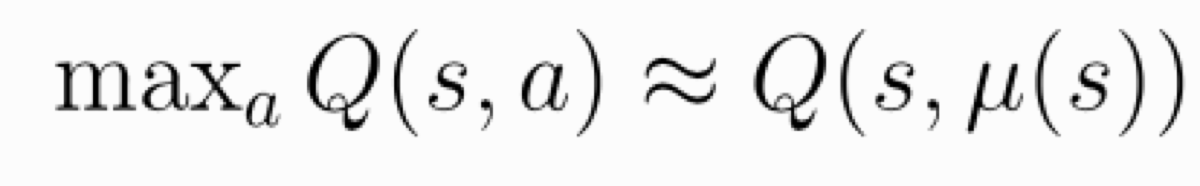
DDPG чередует обучение критика и актора. Проблема с непрерывным или большим полем возможных действий в выборе выделенного красным максимума. Там, где в обычном случае мы можем сделать выбор простым перебором, в случае непрерывного поля получаем очень дорогостоящие вычисления. С непрерывным пространством действий (для рекомендаций его роль может выполнять вектор эмбеддингов того, что нужно рекомендовать) мы можем предположить, что функция Q дифферинциируема относительно действий. Значит, можно, используя градиенты обучать стратегию (политику).
Так выглядит простая схема обучения, которая первый раз появилась в одной статье еще в 2015 году. С тех пор появилось много усовершенствованных подходов.
Может показаться, что RL идеален. Это, конечно, не совсем так. Есть ряд проблем в применении RL к рекомендательным системам. Кроме большого поля «возможных действий», есть еще проблема дорогостоящего exploration: эксперименты на пользователях могут стоить компании реальных юзеров. Еще одна сложность лежит в необходимости учить off-policy, так как большая часть оффлайн данных приходит от агента с другой policy чем та, которую мы хотим строить. Проблемой также является неявная и зашумленная «награда», поскольку мы не можем непосредственно измерить удовлетворенность пользователя. Тем не менее, плюсы весьма значительны, потому в компаниях, ориентированных на UGC, RL-подходы так или иначе пытаются сейчас внедрять.
Are We Really Making Much Progress
С увеличением количества статей, моделей, подходов делать выбор между ними становится все сложнее, особенно учитывая необходимость каждую модель адаптировать под свой домен рекомендаций и особенности системы, что требует времени. Возникает вопрос, настолько ли хороши новые подходы, чтобы тратить время на их внедрение?
Поэтому я не могу обойти вниманием статью, презентованную в 2019 году на конференции ACM Conference on Recommender Systems (и позже еще дополненную) о сравнении новых методов в области рекомендаций со старыми базовыми подходами.
Авторы обзора рассмотрели 18 статей, представленных на таких конференциях как KDD, SIGIR, TheWebConf (WWW) и RecSys в 2015–2018 годых. Из них 11 методов не получилось воспроизвести, а результаты 6 легко получилось побить с помощью простых методов вроде k-ближайших соседей.
Согласно авторам, при оценке своих алгоритмов разработчики часто бывают небрежны в выборе бейзлайн-алгоритмов для сравнения, допуская слишком простые или плохо настроенные (не делается тонкая настройка для baseline) варианты. Кроме того, в рекомендациях предварительная подготовка датасета и методика оценки играют большую роль и могут добавлять путаницы.
Кроме того, обычные для статей о машинном обучении факторы тоже играют свою роль: не все исследователи публикуют полный и рабочий исходный код к своим статьям, используется множество разных датасетов (и их подмножеств) для валидации алгоритмов.
Авторы попытались унифицировать бейзлайн-модели для сравнения с новыми алгоритмами из статей, используя простые, но надежные подходы.
TopPopular: неперсонализованный метод, который рекомендует популярный контент всем пользователям.
ItemKNN и UserKNN: традиционные необучаемые методы коллаборативной фильтрации. Чтобы рекомендовать пользователю объект, ищется несколько пользователей с похожими вкусами (UserKNN) или объекты, похожие на уже просмотренный пользователем (ItemKNN). Векторы для сравнения берутся из матрицы взаимодействия пользователь-объект.
ItemKNN-CBF: схожесть между объектами измеряется на основании векторов атрибутов (например, жанров и актеров для кино).
ItemKNN-CFCBF: гибрид схожести на основании действий пользователей и атрибутов.
P3α: алгоритм на графах. Объекты ранжируются в зависимости от вероятности случайного блуждания. За вероятность шага от пользователя к контенту берется нормированное значение из таблицы оценок пользователь-контент.
RP3β: вариация предыдущего алгоритма, где вероятности еще делятся на общую популярность конкретного объекта.
Все новые алгоритмы сравнивались с этим набором простых бейзлайнов.
Например, в обзор попали рассмотренные выше CMN и CVAE модели. По результатам авторов обзора на метриках NDCG и простое попадание в топ-N (на топе длиной 5 и 10) бейзлайны показали результат лучше чем CMN. А алгоритм CVAE показывает себя лучше бейзлайна только на очень больших последовательностях рекомендаций.
Сложность в том, что для реальной рекомендательной системой ни один из существующих тестовых детасетов не является достаточно убедительным полигоном для тестирования. В реальности, как уже говорилось, приходится смотреть одновременно на несколько метрик, иногда отдельно для разных групп пользователей. Тестовые метрики и датасеты могут показать лишь потенциальное качество модели.
Другие способы улучшения рекомендаций
Напоследок упомяну, что успех рекомендательной системы определяется не только выбранным алгоритмом. Для примера описание алгоритмов, побеждавших последние годы в RecSys Challenge.

Как видно из таблицы, год от года в списке победителей не появляется принципиально новых алгоритмов, большая часть успеха достигается работой с данными методами Feature Engineering. Статья победителей 2020 года даже носит название “GPU Accelerated Feature Engineering and Training for Recommender Systems” («Использование GPU для ускорения препроцессинга данных и обучения для рекомендательных систем»). Используются различные сглаживания, методы устранения шума. Для примера я расскажу про один из таких методов.
Уменьшение шума в сигнале неявного фидбэка
В рекомендательных системах де-факто стало обязательной практикой использование именно неявного фидбэка: данных такого типа обычно больше, и типы взаимодействий гораздо разнообразнее, чем традиционный явный фидбэк – оценки.
Проблема в том, что в таком сигнале много шума: достаточно взять датасет, где явный фидбэк представлен наряду с неявным чтобы убедиться, что за положительным неявным фидбэком (например, фактом просмотра контента) может следовать отрицательный явный (негативная оценка). Назовем такие примеры ложно-положительными. Авторы статьи взяли такие датасеты, чтобы убедиться, что исключение ложно-положительных примеров улучшает качество моделей.
Некоторые методы предлагают использовать дополнительный более надежный тип фидбэка для отсеивания части сигнала: например, добавление в избранное или оставление отзыва в дополнение к кликам или просмотрам. Проблема в том, что дополнительного сигнала обычно на порядок меньше, чем основного.
В статье предлагается метод шумоподавления без использования дополнительных данных. Шумные примеры дают значительно более высокие значения функции потерь, особенно на ранних этапах обучения. Идея в том, чтобы уменьшить их влияние, например, сократить влияние примеров с высоким значением loss-функции.
1. Truncated Loss — отбрасывает примеры с высоким значением loss-функции во время обучения, причем порог динамически изменяется во время обучения.

Где значение порога отсечки — функция от количества пройденных итераций обучения.
2. Reweighted Loss – не отбрасывает такие примеры, но использует уменьшающие коэффициенты.

Где формируется коэффициент:

В качестве функции потери используется стандартный cross-entropy loss. В качестве базового метода используется Neural Matrix Factorization (NeuMF), который рассматривался в первой статье серии, а также Collaborative Denoising Auto-Encoder.
Авторы статьи провели эксперименты с тремя датасетами: Adressa, Amazon-book и Yelp, использовав в качестве метрик Recall@K и NDCG@K.
Во всех случаях предложенные улучшения функции потерь улучшали производительность обучения, например, комбинация из NeuMF и Truncated Loss превзошла обычный NeuMF в среднем на 15,62% по трем наборам данных.
Заключение
В предыдущей части я уже упоминала про разнообразие задач, которые ставятся перед рекомендательными системами. В этой статье коснулись некоторых из специфических проблем и методов решения.
При этом выбор алгоритма остается делом творческим, поскольку напрямую зависит от основных задач, которые ставятся перед рекомендательной системой в конкретной области. От задач зависит также и выбор критериев сравнения и оценки качества работы алгоритмов. Для некоторых задач нет никакого смысла гнаться за новизной модели, но более новые модели могут помочь там, где у старых проверенных подходов не хватает гибкости для адаптации к вашим целям.
Надеюсь, мой обзор поможет определиться с выбором модели, отталкиваясь от их сильных сторон. Спасибо за внимание!
