Комментарии 102
НЛО прилетело и опубликовало эту надпись здесь
— И что же главное? — спросил Нео.
— Тестов не существует, — ответил мальчик.
— Тестов не существует, — ответил мальчик.
Если об этом позаботиться.
И не панацея, есс-но.
И не панацея, есс-но.
Тесты это важно и нужно. Но это следующий этап. Если исправить ошибку на этапе кодирования или сразу вслед за этим (просмотрев отчет статического анализатора, отработавшего ночью), то её исправление обойдется в 10 раз дешевле, чем если она будет выловлена на этапе тестирования.
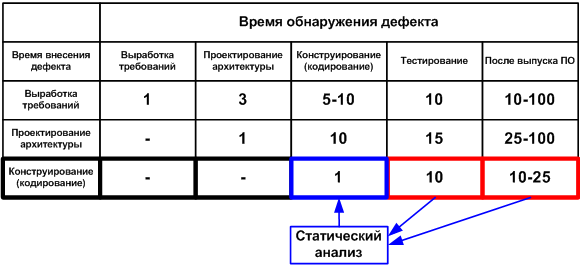
Средняя стоимость исправления дефектов в зависимости от времени их внесения и обнаружения (данные для таблицы взяты из книги С. Макконнелла «Совершенный Код»).
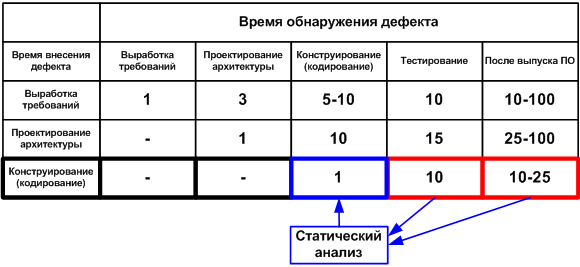
Средняя стоимость исправления дефектов в зависимости от времени их внесения и обнаружения (данные для таблицы взяты из книги С. Макконнелла «Совершенный Код»).
Разработчики в курсе? )
Идеальный код будущего
do cool project
if project not cool killyourself
do cool project
if project not cool killyourself
Статические анализаторы кода несомненно вещь полезная, жалко что не все разработчики OpenSource проектов ими пользуются. От ошибок не застрахован никто.
Написание тщательно выверенного кода требует большой сосредоточенности и скурпулёзности. Лёгкий драйв, который ищут опенсорсеры, плохо совместим с таким настроем.
Линус Торвальдс ищет лёгкий драйв [x]
Он фан ищет же, впрочем его он нашел с лихвой
Линус Торвальдс — создатель, а не участник.
К тому же тот зоопарк linux'ов (и *nix'ов), который развело opensource community ни разу не способствует тщательности, выверенности и работоспособности кода. В цифровых детерминированных технологиях разнообразию не место — в таких системах правильное решение, как правило, одно единственное. каким бы серым, скучным и нераскрашенным оно из-за своей единственности не оказалось. Вместо этого вместо серых стабильно работающих из коробки решений имеем цветное аниме в коде и ебалово с билдами под разные версии. Даже 100-килобайтные ./configure не спасают. Сплошной patch-driven coding style.
./configure вообще зло и должно быть уничтожено!
Ну если на то пошло, по «зоопарк Unixов» и API развели крупные корпорации которые стараются дефрагментировать рынок в надежде, что пользователю сложнее будет уйти на другую платформу. И ваш любимый Майкрофосфт ой как активно это использует.
en.wikipedia.org/wiki/Vendor_lock-in
Цитата Билли по этому поводу «The Windows API is so broad, so deep, and so functional that most ISVs would be crazy not to use it. And it is so deeply embedded in the source code of many Windows apps that there is a huge switching cost to using a different operating system instead»
Цель OpenSource это не только и не столько бесплатный софт. Цель — открытые доступные стандарты, которые каждый может использовать, и если эти стандарты окажутся успешными — они становятся общепринятыми.
Как то так.
en.wikipedia.org/wiki/Vendor_lock-in
Цитата Билли по этому поводу «The Windows API is so broad, so deep, and so functional that most ISVs would be crazy not to use it. And it is so deeply embedded in the source code of many Windows apps that there is a huge switching cost to using a different operating system instead»
Цель OpenSource это не только и не столько бесплатный софт. Цель — открытые доступные стандарты, которые каждый может использовать, и если эти стандарты окажутся успешными — они становятся общепринятыми.
Как то так.
Наверное всё-же имелось в виду «фрагментировать рынок»?
И я не совсем улавливаю мысль, как Майкрософт виноват в появлении новых linux-ов. Мне кажется, что тут как и везде в жизни имеют место быть личные амбиции и субъективность выбора/оценки лучшего решения.
ЗЫ Не являюсь защитником Майкрософт, так как у нас есть свой яблочный бох и он точно против фрагментации :)
И я не совсем улавливаю мысль, как Майкрософт виноват в появлении новых linux-ов. Мне кажется, что тут как и везде в жизни имеют место быть личные амбиции и субъективность выбора/оценки лучшего решения.
ЗЫ Не являюсь защитником Майкрософт, так как у нас есть свой яблочный бох и он точно против фрагментации :)
Не совсем понимаю про какие «новые linux» вы говорите. Linux он один, его можете скачать здесь www.kernel.org/ Да, разные дистрибутивы добавляют свои патчи к ядру, но они не такие уж и значительные, чтобы говорить о фрагментации Linux. По крайней мере мои программы отлично работают и на Ubuntu и на Gentoo и на Fedora.
ЗЗЫ В плане следования стандартам с уверенностью можно сказать что MacOSX намного лучше чем Windows.
ЗЗЫ В плане следования стандартам с уверенностью можно сказать что MacOSX намного лучше чем Windows.
OpenSource — это открытый исходный код, а не стандарты. Стандарты (спецификация) и у MS открыты. При этом закрытость сорса провоцирует следование именно спецификации, а не tweak'ам под конкретную подсмотренную реализацию.
Не каждый может похвастаться терпением и рыскать в коде отыскивая ошибки и разбирая их по полочкам. Главное, чтобы это не было напрасным, а если кому-то поможет, значит работа проделана не зря. Будем надеяться разработчики прислушаются к этому.
«Заметка N1» означает, что в продолжении при помощи PVS-Studio Вы планируете проанализировать другой продукт или обрисуете новые виды ошибок в текущем?
это уже не первый проанализированный проект, и надеюсь не последний!
Вы — автор?
нет, но я умею пользоваться хабром http://andrey2008.habrahabr.ru/blog/
Редко удается, чтобы проверив один проект, можно сразу привести много примеров разнородных ошибок. Думаю, следующая заметка будет основана на примерах взятых из разных проектов.
Как уменьшить вероятность ошибки на этапе написания кода.
0. Используйте С++ в C++ коде.
0. Используйте С++ в C++ коде.
1. Предельно аккуратно используйте:
1.1. Прямую работу с памятью и указателями.
1.2. Неявные приведения типов.
1.3. Переопределения операций.
1.4. Множественное наследование.
1.5. Сторонние библиотеки.
ИМХО, очень много пунктов…
Я, конечно, уважаю гуру плюсов, но лично мне кажется, что без анализотаров кода работать с такими потенциальными дырами = копать себе яму. Особенно при наличии в команде Junior'ов…
1.1. Прямую работу с памятью и указателями.
1.2. Неявные приведения типов.
1.3. Переопределения операций.
1.4. Множественное наследование.
1.5. Сторонние библиотеки.
ИМХО, очень много пунктов…
Я, конечно, уважаю гуру плюсов, но лично мне кажется, что без анализотаров кода работать с такими потенциальными дырами = копать себе яму. Особенно при наличии в команде Junior'ов…
bingo!
НЛО прилетело и опубликовало эту надпись здесь
Если проект на С++, то и следует использовать работу с памятью С++. Минимизировать использование указателей, а если и использовать, то только внутри закрытого кода. Передавать соответственно по ссылке или значению (не полениться с реализацией счетчиков ссылок, конструктора копий и оператора =).
Если мне память не изменяет, то изначально Миранда была таки на Си написана, потом её начали «портировать» на плюсы, от того и получилась такая каша и благодать для анализаторов.
Абсолютно согласен. Например, в моих программах (практически) нет оператора delete. Нету и всё. Зачем мне руками освобождать память, если за меня это могут сделать библиотечные средства, такие как умные указатели и boost::ptr_container?
А что касается С-шных функций в современном С++, то нужны очень (ОЧЕНЬ) серьёзные основания для их использования. В противном случае (а это 99.9%) их наличие в С++-коде говорит о недостаточной квалификации С++-разработчика.
А что касается С-шных функций в современном С++, то нужны очень (ОЧЕНЬ) серьёзные основания для их использования. В противном случае (а это 99.9%) их наличие в С++-коде говорит о недостаточной квалификации С++-разработчика.
Небезынтересно, но сложилось впечатление, что код просто скормили PVS-Studio и переписали нам результат, выданный программой.
Даже если и так (а так, скорее всего и есть), то в своей полезности
пост нисколько не теряет. Более того, автор не поленился дать
довольно развернутые комментарии, за что честь ему и хвала.
PS: миранда навсегда! :)
пост нисколько не теряет. Более того, автор не поленился дать
довольно развернутые комментарии, за что честь ему и хвала.
PS: миранда навсегда! :)
Да, мои предыдущие посты были в духе «вот какие ошибки можно найти статическим анализатором кода, например PVS-Studio». Теперь я перешел на следующий уровень, так сказать. Я насмотрелся на такое огромное количество ошибок, что начинаю выделять некоторые закономерности, как они возникают. Теперь буду пробовать суммировать мои знания в рекомендации. Сразу создать статью «55 способов писать лучше на Си++» я не готов. Буду постепенно.
На какой язык планируете перевести статью для авторов миранды?
На brainfuck :-)
Не уловил сути вопроса.
Там много русских разработчиков
Вероятно, имеется в виду, что разработчики миранды способны прочесть статью и на русском языке
Я по поводу этой цитаты:
На какой язык собираетесь перевести статью? Кстати, PVS-Studio будет предложена именно та, что бесплатно доступна на сайте? Или полная версия, но бесплатно? ;)
Однако, перевод этой статьи будет отправлен авторам Miranda IM и им будет предложена бесплатная версия анализатора PVS-Studio.
На какой язык собираетесь перевести статью? Кстати, PVS-Studio будет предложена именно та, что бесплатно доступна на сайте? Или полная версия, но бесплатно? ;)
НЛО прилетело и опубликовало эту надпись здесь
На какой язык собираетесь перевести статью?
На английский. Я видел в Miranda IM русские комментарии. Но считаю, что все разработчики Miranda должны иметь возможность понять, о чем идет речь. По этому и планирую послать им ссылку на английский вариант статьи.
Кстати, PVS-Studio будет предложена именно та, что бесплатно доступна на сайте? Или полная версия, но бесплатно? ;)
…
Начиная с января 2011, года мы объявляем о начале новой инициативы по сотрудничеству с разработчиками open-source программного обеспечения. Мы готовы предоставить бесплатную одиночную лицензию сроком на 3 месяца любому разработчику или автору статей в тематических IT изданиях/блогах, которому интересна тема статического анализа исходного кода C/C++/C++0x или если он просто хочет проверить свои проекты на наличие в них ошибок диагностируемых нашим анализатором.
…
Подробнее.
На английский. Я видел в Miranda IM русские комментарии. Но считаю, что все разработчики Miranda должны иметь возможность понять, о чем идет речь. По этому и планирую послать им ссылку на английский вариант статьи.
Кстати, PVS-Studio будет предложена именно та, что бесплатно доступна на сайте? Или полная версия, но бесплатно? ;)
…
Начиная с января 2011, года мы объявляем о начале новой инициативы по сотрудничеству с разработчиками open-source программного обеспечения. Мы готовы предоставить бесплатную одиночную лицензию сроком на 3 месяца любому разработчику или автору статей в тематических IT изданиях/блогах, которому интересна тема статического анализа исходного кода C/C++/C++0x или если он просто хочет проверить свои проекты на наличие в них ошибок диагностируемых нашим анализатором.
…
Подробнее.
На мой взгляд, большинство описанных ошибок происходит от излишней низкоуровневости кода. Возможно, я так думаю, потому что я джавист, но всё же, имхо, большинство описанных ошибок можно было бы избежать путём инкапсуляции и юнит-тестов.
Даже без юнит тестов, просто нужно проектировать так, чтобы код получался как можно более высокоуровневый, а уж все низкоуровневые операции собирать в одном месте, где их проще выверить.
Потеря производительности будет минимальной и возможно даже получится сделать прогу более быстрой за счет более выверенного кода
Потеря производительности будет минимальной и возможно даже получится сделать прогу более быстрой за счет более выверенного кода
Авторы PVS продолжают держать потенциальных клиентов за идиотов)
Скажите, ну где вы видели программиста С++, который «пугается амперсандов»?
Ну и для вашего сведения, взятие адреса массива через амперсанд хотя и не обязательно, но абсолютно корректно. В данном случае амперсанд не имеет целью никого пугать, он здесь подчеркивает, что берется именно адрес, а не первый элемент массива. Необходимость поставить такой хинт кажется естественной для программистов, много писавших на ассемблере. И вот как раз у них ошибок при работе с памятью почти не возникает)
Скажите, ну где вы видели программиста С++, который «пугается амперсандов»?
Ну и для вашего сведения, взятие адреса массива через амперсанд хотя и не обязательно, но абсолютно корректно. В данном случае амперсанд не имеет целью никого пугать, он здесь подчеркивает, что берется именно адрес, а не первый элемент массива. Необходимость поставить такой хинт кажется естественной для программистов, много писавших на ассемблере. И вот как раз у них ошибок при работе с памятью почти не возникает)
Не путайте сладкое с твёрдым. При чем здесь, пугает кого-то взятие адреса или нет? Такие конструкции потенциально опасны, так как в них легко ошибиться. Даже опытному программисту. Примеры соответствующие я привел. Следовательно, их надо не пугаться, а избегать. Например, использовать контейнеры, алгоритмы из stl и так далее.
Си++ вообще такой язык, в котором много где можно ошибиться. Перепутать порядок аргументов можно в любой функции, не только в memcpy. Ничего сложного в работе с памятью нет, нужно просто сесть и как следует разобраться. Поверьте, какие-нибудь хитрые деревья или лямбды намного сложнее для понимания.
Главное достоинство плюсов — полный контроль над всем кодом, влючая в первую очередь работу с памятью. Вы можете создать свой контейнер, который будет работать поверх вашего же менеджера памяти и сам будет вызывать деструкторы, когда вам это нужно. Да, такие вещи требуют аккуратности и серьезной подготовки, зато позволяют добиться производительности. Но если же вы не хотите со всем этим разбираться и пугаетесь амперсанда… ну, возмножно вам стоит посмотреть на С# или Java, в которых подумали за вас.
Главное достоинство плюсов — полный контроль над всем кодом, влючая в первую очередь работу с памятью. Вы можете создать свой контейнер, который будет работать поверх вашего же менеджера памяти и сам будет вызывать деструкторы, когда вам это нужно. Да, такие вещи требуют аккуратности и серьезной подготовки, зато позволяют добиться производительности. Но если же вы не хотите со всем этим разбираться и пугаетесь амперсанда… ну, возмножно вам стоит посмотреть на С# или Java, в которых подумали за вас.
Это Вы разработчику анализатора пишите «если же вы не хотите со всем этим разбираться»?
Уважаемый Евгений, вот только давайте не будем строить невинные глазки. Вы — ген. директор фирмы-производителя PVS, автор статьи Andrey2008 — ваш непосредственный подчиненный, и в этой статье вы пиарите свой продукт. Причем делаете это не в блоге имени вашей компании, который любой желающий может не читать, а в общем блоге, посвященном языку Си++.
Я не имею ничего против вашего продукта, но мне лично в вашей рекламе не нравятся передергивания вида «амперсанд пугает других разработчиков», о чем я, собственно, и заявляю. Можете и дальше набигать на мою карму всем своим тульским офисом, но аудитория хабра — не ваша личная вотчина.
Я не имею ничего против вашего продукта, но мне лично в вашей рекламе не нравятся передергивания вида «амперсанд пугает других разработчиков», о чем я, собственно, и заявляю. Можете и дальше набигать на мою карму всем своим тульским офисом, но аудитория хабра — не ваша личная вотчина.

Кстати, такой вопрос… А PVS-Studio работает только как аддон к вижуалу или его можно прикрутить как внешнюю тулзу к примеру к Qt Creator?
Автор clist_modern (по поводу этого плагина немало написано в статье) очень хочет зарегаться на хабре, если у кого есть взаимное желание, то вот его емейл для инвайта: ashpynov at gmail dot com
Использовать для обнуления структур напрямую memset это имхо даже в си плохо — уж лучше в макросы завернуть.
А можете написать сравнение своего продукта с конкурентами, например с PC-LINT?
Последний уже почти стандарт в мире разработки встроеного ПО. Многие среды разработки имеют интеграцию имеенно с ним. У вас есть готовые профили для проверки соответсвия MISRA С?
Последний уже почти стандарт в мире разработки встроеного ПО. Многие среды разработки имеют интеграцию имеенно с ним. У вас есть готовые профили для проверки соответсвия MISRA С?
Поможете нам сделать такое НЕЗАВИСИМОЕ сравнение? Лицензию предоставим, как пользоваться покажем, на вопросы ответим.
Можем. И со временем напишем.
<сарказм вкл.>
MISRA, этот Вы про того дедушку, который рекомендует использовать char вместо wchar_t? Ведь в его молодость у компиляторов с wchar_t плохо было.
(misra-008) Do not use wide string literals
Не рекомендуется:
wchar_t* x = L«Fred»; // нарушение
Рекомендуется:
char* x = «Fred»;
<сарказм выкл.>
Реализовывать MISRA для Visual C++ смысла сейчас для себя не видим. Усилий много, пользы мало.
<сарказм вкл.>
MISRA, этот Вы про того дедушку, который рекомендует использовать char вместо wchar_t? Ведь в его молодость у компиляторов с wchar_t плохо было.
(misra-008) Do not use wide string literals
Не рекомендуется:
wchar_t* x = L«Fred»; // нарушение
Рекомендуется:
char* x = «Fred»;
<сарказм выкл.>
Реализовывать MISRA для Visual C++ смысла сейчас для себя не видим. Усилий много, пользы мало.
MISRA для Visual C++ не знаю пользуется ли кто, а вот для embedded исспользуют, Keil, IAR, gcc, HiTech, ImageCraft.
Сам стандарт может выглядеть не очень, но его исполнение помогает пройти сертификацию для поставки решений для медицины, например.
Сам стандарт может выглядеть не очень, но его исполнение помогает пройти сертификацию для поставки решений для медицины, например.
Согласен с Вами и мысль понимаю. Но сейчас мы ориентируемся только на Visual C++ и даже поддержание одной платформы не простая задача. Это только кажется, что если ядро общее, то можно легко под разные платформы работать. К сожалению, пояснить причины, почему это так, непростая задача. Есть очень интересная статья от Coverity "Using Static Analysis to Find Bugs in the Real World" на тему сложности поддержки многих систем. Кстати, прочитав её, становится понятным, почему они не дают просто скачать и попробовать.
P.S. Но если кто-то готов финансировать адаптацию PVS-Studio для других систем, мы готовы. ;)
P.S. Но если кто-то готов финансировать адаптацию PVS-Studio для других систем, мы готовы. ;)
> wchar_t* x = L«Fred»; // нарушение
> char* x = «Fred»;
Вообще-то, и то, и другое нарушение, если уж на то пошло. Модификатор const здесь просто необходим.
> char* x = «Fred»;
Вообще-то, и то, и другое нарушение, если уж на то пошло. Модификатор const здесь просто необходим.
Корректным вариантом должен был стать следующий код:
if ((int)wParam>=0 && (int)wParam<nFramescount)
Ваш вариант ненамного более корректен, чем исходный: стоит изменить typedef так, что:
sizeof(int) > sizeof(WPARAM)
К примеру, так:
typedef unsigned short WPARAM;И вернётесь к тому с чего начали.
А еще можно написать #define true false
Впрочем всё равно if ((int)wParam>=0 && (int)wParam<nFramescount) выглядит не слишком читабельно. Я бы временные переменные ввёл, скорость работы не меняется, а читабельность повышается, ибо в условиях должно быть нечто максимально похожее на логические выкладки, а не на низкоуровневые операции.
Впрочем всё равно if ((int)wParam>=0 && (int)wParam<nFramescount) выглядит не слишком читабельно. Я бы временные переменные ввёл, скорость работы не меняется, а читабельность повышается, ибо в условиях должно быть нечто максимально похожее на логические выкладки, а не на низкоуровневые операции.
Можно конечно. Если нужно.
Дело не в читабельности предложенного решения, а в том, что оно постулируется как корректное, основываясь на ничем не обоснованном инварианте sizeof(int) <= sizeof(WPARAM).
Дело не в читабельности предложенного решения, а в том, что оно постулируется как корректное, основываясь на ничем не обоснованном инварианте sizeof(int) <= sizeof(WPARAM).
Это я коварно написал, чтобы потом пришлось еще модуль Viva64 использовать, в поисках подобных мест! :)
Спасибо за замечание. Вы правы. Когда писал, мысли были только про signed/unsigned. Остальные аспекты корректности кода из головы вылетели.
Спасибо за замечание. Вы правы. Когда писал, мысли были только про signed/unsigned. Остальные аспекты корректности кода из головы вылетели.
Хочу высказаться насчёт пункта 4 — «выравнивайте всё». Спорный пункт. Например, в книге Р. Мартина «Чистый код. Создание, анализ и рефакторинг.» автор выступает против выравнивания, причём вполне обоснованно. Кто ещё не читал, читайте. Книга действительно стоит прочтения, этакий концентрированный опыт, который приходит к разработчику с годами.
Уважаю вашу работу, PVS Studio вероятно один из лучших имеющихся на данный момент статических анализаторов. Однако, уже несколько раз после прочтения ваших статей порывался анализировать рабочие проекты, и анализатор не находил ничего кроме нескольких мелких оптимизаций, где аргументы были переданы по значению вместо ссылки.
Есть целых три возможных причины этого:
1. У вас очень качественный код.
2. У вас не очень большие проекты.
3. У нас слабенький анализатор :-).
Объем исходников какой у вас?
1. У вас очень качественный код.
2. У вас не очень большие проекты.
3. У нас слабенький анализатор :-).
Объем исходников какой у вас?
1) Мы в начале пути. И новые виды диагностик еще делать и делать. Так что вполне может быть, то что мы сейчас диагностируем не пересекается с набором ошибок, которые присутствуют в Ваших проектах. Я кстати версией PVS-Studio 4.00 Beta проверял уже Miranda IM. И тогда написать было практически не о чем. А вот теперь (4.14) есть. :)
2) Другой вариант — у Вас качественный код. Вы успешно вылавливаете ошибки, используя другие методики (юнитесты и т.д.). В этом случае статический анализ и не покажет что-то особое интересное для кода. Намного полезней он будет на этапе работы, помогая находить ошибки и опечатки еще до тестирования. Если хотите, мы можем дать ключ на 3 месяца использования и вы попробуете интегрировать его в процесс разработки. Например, запускать ночью. Мы подскажем и поможем.
2) Другой вариант — у Вас качественный код. Вы успешно вылавливаете ошибки, используя другие методики (юнитесты и т.д.). В этом случае статический анализ и не покажет что-то особое интересное для кода. Намного полезней он будет на этапе работы, помогая находить ошибки и опечатки еще до тестирования. Если хотите, мы можем дать ключ на 3 месяца использования и вы попробуете интегрировать его в процесс разработки. Например, запускать ночью. Мы подскажем и поможем.
Вот я и зарегистрировался, за что отдельное спасибо persei.
Для начала хочу искренне поблагодарить Andrey2008 за внимание к проекту Miranda IM в целом и за указание на ошибки от имени разработчика модуля «clist_modern» (то бишь меня), который собственно и поминался чаще всего в статье.
К сожалению приведенные примеры ошибок (кроме одного) либо как таковыми не являлись, либо были в неработающем коде, ну или просто оказывались «плохим кодом», но не ошибочным. Но нет предела совершенству — посему код упомянутый в статье вы можете уже на trunc не найти.
Кстати пример номер раз в статье неверен, ибо sizeof &a, где а есть char *a[n]; вернет размер всего массива, а не первого его элемента. Собственно в этом и разница между массивом и указателем на массив, но все равно спасибо.
Хотелось бы немного оправдаться: не забывайте что проекты подобные миранде максимум хобби для уже сложившихся программистов. А чаще всего — исследовательская площадка для новичков стремящихся в сеньоры. Например по коду модерна можно проследить мою эволюцию как программиста :).
К сожалению наступает момент когда новичок стал сеньором и даже больше. И на старые проекты просто не хватает времени. Да и интересы уже гораздо дальше. А в свой старый код «как посмотришь так вздрогнешь». Поэтому я бы поостерегся называть код миранды (как минимум модерна) неплохим. Плохо то что упомянутые ошибки в коде это лишь мелочь на поверхности. Архитектурные просчеты (а их там легион) не выявит никакой PVC. А вреда от них…
И напоследок «почему Open Source'ники не используют инструменты подобные PVC: Вы цену лицензии видели? Причем записать „умение работать с PVC“ себе в актив вообщем сомнительно, особенно навичку — он просто не поймет о чем ему мегажелезка вещает. Ну а пользовать его нелегально — ай ай ай.
В принципе даже в серьезных коммерческих проектах использование под вопросом. Хотябы потому, что серьезные проекты разворачиваются на кросс платформах, где винде часто достаются несерьезные вещи вроде морды лица, писаная и переписанная на коленке раз надцать на каких нибудь шарпах из одних компонентов. И зачастую дешевле набрать стаю тестеров-студентов по 5 копеек пучек, или уделить больше времени на ревью кода, чем заплатить за лицензию софтине которая поможет вытащить на свет божий несколько некритичных багов которые тестеры почему то пропустили.
Для начала хочу искренне поблагодарить Andrey2008 за внимание к проекту Miranda IM в целом и за указание на ошибки от имени разработчика модуля «clist_modern» (то бишь меня), который собственно и поминался чаще всего в статье.
К сожалению приведенные примеры ошибок (кроме одного) либо как таковыми не являлись, либо были в неработающем коде, ну или просто оказывались «плохим кодом», но не ошибочным. Но нет предела совершенству — посему код упомянутый в статье вы можете уже на trunc не найти.
Кстати пример номер раз в статье неверен, ибо sizeof &a, где а есть char *a[n]; вернет размер всего массива, а не первого его элемента. Собственно в этом и разница между массивом и указателем на массив, но все равно спасибо.
Хотелось бы немного оправдаться: не забывайте что проекты подобные миранде максимум хобби для уже сложившихся программистов. А чаще всего — исследовательская площадка для новичков стремящихся в сеньоры. Например по коду модерна можно проследить мою эволюцию как программиста :).
К сожалению наступает момент когда новичок стал сеньором и даже больше. И на старые проекты просто не хватает времени. Да и интересы уже гораздо дальше. А в свой старый код «как посмотришь так вздрогнешь». Поэтому я бы поостерегся называть код миранды (как минимум модерна) неплохим. Плохо то что упомянутые ошибки в коде это лишь мелочь на поверхности. Архитектурные просчеты (а их там легион) не выявит никакой PVC. А вреда от них…
И напоследок «почему Open Source'ники не используют инструменты подобные PVC: Вы цену лицензии видели? Причем записать „умение работать с PVC“ себе в актив вообщем сомнительно, особенно навичку — он просто не поймет о чем ему мегажелезка вещает. Ну а пользовать его нелегально — ай ай ай.
В принципе даже в серьезных коммерческих проектах использование под вопросом. Хотябы потому, что серьезные проекты разворачиваются на кросс платформах, где винде часто достаются несерьезные вещи вроде морды лица, писаная и переписанная на коленке раз надцать на каких нибудь шарпах из одних компонентов. И зачастую дешевле набрать стаю тестеров-студентов по 5 копеек пучек, или уделить больше времени на ревью кода, чем заплатить за лицензию софтине которая поможет вытащить на свет божий несколько некритичных багов которые тестеры почему то пропустили.
Кстати пример номер раз в статье неверен, ибо sizeof &a, где а есть char *a[n]; вернет размер всего массива, а не первого его элемента.
Тут Вы не правы. Он вернет размер указателя:
В статье не написано, что будет возвращен размер первого элемента. В тексте написано «Но вместо этого мы обнулим только первый элемент». А именно так и есть, так как здесь размер указателей на разные типы совпадает.
Тут Вы не правы. Он вернет размер указателя:
char *(ImgIndex[64]); cout << sizeof( ImgIndex) << endl; cout << sizeof(*ImgIndex) << endl; cout << sizeof(&ImgIndex) << endl; //Вывод (x86): 256 4 4
В статье не написано, что будет возвращен размер первого элемента. В тексте написано «Но вместо этого мы обнулим только первый элемент». А именно так и есть, так как здесь размер указателей на разные типы совпадает.
Интересно девки пляшут, оно еще и компиляторо-зависимое оказалось:
MS VC++ 2005
Вывод: 256, 256, 4
g++ ( x64)
Вывод: 512, 8, 8
Очередной довод: не надо так писать.
#include <conio.h>
int _tmain(int argc, _TCHAR* argv[])
{
char *(ImgIndex[64]);
printf( "%d, %d, %d \n",sizeof( ImgIndex ), sizeof( &ImgIndex ), sizeof( ImgIndex[0] ) );
return 0;
}
MS VC++ 2005
Вывод: 256, 256, 4
g++ ( x64)
Вывод: 512, 8, 8
Очередной довод: не надо так писать.
Не, это не компиляторо-зависимое. Это просто баг VS 2005. Следует установить SP1.
Недавно как раз на эту тему интересный код в Google C++ Mocking Framework видел:
Недавно как раз на эту тему интересный код в Google C++ Mocking Framework видел:
class TestForSP1 {
private: // GCC complains if x_ is used by sizeof before defining it.
static char x_[100];
// VS 2005 RTM incorrectly reports sizeof(&x) as 100, and that value
// is used to trigger 'invalid negative array size' error. If you
// see this error, upgrade to VS 2005 SP1 since Google Mock will not
// compile in VS 2005 RTM.
static char Google_Mock_requires_Visual_Studio_2005_SP1_or_later_to_compile_[
sizeof(&x_) != 100 ? 1 : -1];
};
Спасибо за пост, пошел читать вторую часть!
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Как уменьшить вероятность ошибки на этапе написания кода. Заметка N1