Комментарии 33
А нет желания сделать серверную реализацию всего этого дела и подцепить запуск анализатора через git hooks, а все результаты просто в виде html таблицы выдавать? И добавить варианты чтобы коммиты с некоторыми типами предупреждений оно не пропускало вовсе.
Чем закончилась история с Хромиумом?
Андрей, привествую!
Реквествую следующим на ревью AVISynth.
Реквествую следующим на ревью AVISynth.
А вы исходники PVS-Studio так же анализируете самой PVS-Stuio? :)
ps: почему вы не избавитесь от этого дурацкого дефиса в названии?
В статье упоминается ссылка вот на это. А что Вы думаете? Стали ли вы править такой свой код? А чужой? Стоит ли оставить всё как есть? Стоит ли бороться со странным, но работающим кодом? А что в плане поддержки чужого такого кода? В общем, интересуют любые мысли и мнения по этому поводу.
Вопрос не просто так. Не раз сталкивался с позицией: «Мы не будем искать и править ошибки/кривые места в старом коде, но готовы делать это в свежем коде». В результате, зреет идея сделать новый режим в PVS-Studio. Все ошибки после первой проверки считаются не ошибками. И выдаем сообщения на подозрительные места только в измененных или новых фрагментах кода. Глупость или мудрость?
Вопрос не просто так. Не раз сталкивался с позицией: «Мы не будем искать и править ошибки/кривые места в старом коде, но готовы делать это в свежем коде». В результате, зреет идея сделать новый режим в PVS-Studio. Все ошибки после первой проверки считаются не ошибками. И выдаем сообщения на подозрительные места только в измененных или новых фрагментах кода. Глупость или мудрость?
«Мы не будем искать и править ошибки/кривые места в старом коде, но готовы делать это в свежем коде»… Глупость или мудрость?Глупость!
Стали ли вы править такой свой код? А чужой? Стоит ли оставить всё как есть? Стоит ли бороться со странным, но работающим кодом? А что в плане поддержки чужого такого кода?Я в одном из своих топиков переводил Линуса, и я с ним согласен, где все можно свести к достаточно простым правилам: Код должен быть читаем. Должен соблюдаться баланс между фичами (не должно одно ломаться за счет другого). Код должен быть поддерживаемым, переносимым. Не нужно допускать того, чтобы приходилось править чей-то кривой код, просто его не должно оказаться в репозитории изначально, пока автор фичи не оформит все как полагается его код даже смотреть никто не будет. Почитайте, там много умных мыслей.
Бороться надо, но лучше, когда это делает мейнтейнер/автор проекта… А тут, похоже, ситуация печальная… Вместо благодарности — детские обиды…
НЛО прилетело и опубликовало эту надпись здесь
Но ведь старый код работает. Работает — не тронь! Что-то с ним делать — только тратить время и вносить новые ошибки.
Если код вообще никогда не меняется, не покрыт тестами и выделен в отдельную библиотеку то может лучше и не трогать пока работает без нареканий.
Если есть тесты (а их как правило нет) то можно менять!
Если код с ошибкой не выделен в отдельную библиотеку от основного кода или это отдельная библиотека и она частенько меняется то нужно менять!
Если есть тесты (а их как правило нет) то можно менять!
Если код с ошибкой не выделен в отдельную библиотеку от основного кода или это отдельная библиотека и она частенько меняется то нужно менять!
Смотря как «работает». Если работает, но нашли переполнение буфера или подобную дыру — надо исправлять.
У меня вопрос по поводу сдвигов отрицательных чисел.
Насколько я помню, в своей статье habrahabr.ru/company/pvs-studio/blog/141880/ вы рекомендуете вместо (-1 << x) использовать (~0 << x).
Однако, вот тут stackoverflow.com/questions/809227/is-it-safe-to-use-1-to-set-all-bits-to-true пишут, что ~0 не обязательно эквивалентен всем единичным битам в двоичном представлении (хотя, честно говоря, я не до конца понял, почему).
Возможно, наиболее безопасным будет сделать что-то вроде:
Насколько я помню, в своей статье habrahabr.ru/company/pvs-studio/blog/141880/ вы рекомендуете вместо (-1 << x) использовать (~0 << x).
Однако, вот тут stackoverflow.com/questions/809227/is-it-safe-to-use-1-to-set-all-bits-to-true пишут, что ~0 не обязательно эквивалентен всем единичным битам в двоичном представлении (хотя, честно говоря, я не до конца понял, почему).
Возможно, наиболее безопасным будет сделать что-то вроде:
unsigned long a = -1;
b = (a << x);Вот ведь язык… Никогда нельзя чувствовать себя в безопасности. :)
пишут, что ~0 не обязательно эквивалентен всем единичным битам в двоичном представлении
1) ~0 инвертирует все биты, если отрицательные числа хранятся на целевой машине в дополнительном коде (см. вики). Однако, может быть и по-другому: как пишет автор ответа, в обратном коде получится ноль (-0=1111...1, ~-0=0).
2) Ситуация с ~0u не зависит от представления отрицательных чисел. Однако, если long длиннее, чем int, при присваивании unsigned long = ~0u левая часть числа останется
Намного более скользкой темой являются операции сдвига
То, что код работает, это везение.
Если тест написан, то всё ок.
Диагностическое сообщение выданное PVS-Studio: V595 The 'lpbiOutput' pointer was utilized before it was verified against nullptr. Check lines: 82, 85. VirtualDub yuvcodec.cpp 82
LRESULT YUVCodec::DecompressGetFormat(BITMAPINFO *lpbiInput, BITMAPINFO *lpbiOutput) { BITMAPINFOHEADER *bmihInput = &lpbiInput->bmiHeader; BITMAPINFOHEADER *bmihOutput = &lpbiOutput->bmiHeader; LRESULT res; if (!lpbiOutput) return sizeof(BITMAPINFOHEADER); .... }
Это ложное срабатывание. Здесь нет ни разыменования нулевого указателя, ни UB. Сомневаетесь?
#define offsetof(Struct, Field) (uintptr_t)((char*)&(((Struct*)NULL)->Field) - (char*)((Struct*)NULL))
Примерно так выглядит макрос offsetof в stddef.h
Всегда читаю посты про PVS-студио, примеряя их на Java с разработкой в Eclipse. По данному посту вывод такой:
Неактуальные для Java проблемы:
Виртуальные деструкторы, неопределённое поведение со сдвигами (в Java эти операции не зависят от версии и ключей компилятора), ссылка на уничтоженный объект, приведённые неправильные сравнения (в Java нет типов, не включающих отрицательные значения).
Проблемы, о которых предупредит бесплатная IDE:
Проверка на null после создания объекта:

Проверка на null после использования объекта:
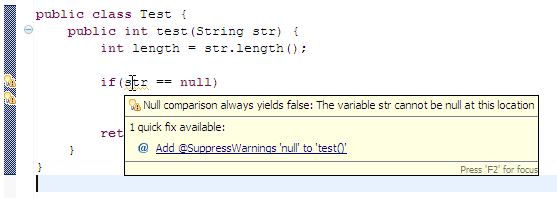
Присваивание самому себе:

Точка с запятой после while:

(если у вас этих предупреждений нет, поройтесь в настройках Eclipse)
Частично актуальные проблемы:
Магическая длина строк. С одной стороны, длина строки или массива хранится в Java в самом объекте строки и массива, поэтому подобной проблемы быть не должно. Но, например, такие конструкции я встречал в реальном коде:
Работа с типом HRESULT. Ну если б был такой тип, конечно, можно бы было неправильно проверять его значение. Но Java автоматом не приводит к логическому типу, поэтому программисту пришлось бы явно писать if( hResult != 0 ), и он бы, возможно, задумался, правильно ли это :-)
Неправильный аргумент printf. В Java есть аналогичные методы (например, String.format), и такая ошибка не будет поймана на этапе компиляции, но при любом несоответствии типов случится исключение на этапе выполнения, поэтому выстрелит сразу, а не неизвестно когда.
Актуальные проблемы:
Взаимоисключающие проверки. Eclipse не сечёт даже обращения к локальным переменным или параметрам типа таких:
Потенциальное отсутствие else, повторное присваивание Eclipse не подсвечивает. За абсолютные пути, конечно, тоже никто не поругает.
Неактуальные для Java проблемы:
Виртуальные деструкторы, неопределённое поведение со сдвигами (в Java эти операции не зависят от версии и ключей компилятора), ссылка на уничтоженный объект, приведённые неправильные сравнения (в Java нет типов, не включающих отрицательные значения).
Проблемы, о которых предупредит бесплатная IDE:
Проверка на null после создания объекта:

Проверка на null после использования объекта:

Присваивание самому себе:

Точка с запятой после while:

(если у вас этих предупреждений нет, поройтесь в настройках Eclipse)
Частично актуальные проблемы:
Магическая длина строк. С одной стороны, длина строки или массива хранится в Java в самом объекте строки и массива, поэтому подобной проблемы быть не должно. Но, например, такие конструкции я встречал в реальном коде:
if(str.startsWith("http://"))
return str.substring(7);Работа с типом HRESULT. Ну если б был такой тип, конечно, можно бы было неправильно проверять его значение. Но Java автоматом не приводит к логическому типу, поэтому программисту пришлось бы явно писать if( hResult != 0 ), и он бы, возможно, задумался, правильно ли это :-)
Неправильный аргумент printf. В Java есть аналогичные методы (например, String.format), и такая ошибка не будет поймана на этапе компиляции, но при любом несоответствии типов случится исключение на этапе выполнения, поэтому выстрелит сразу, а не неизвестно когда.
Актуальные проблемы:
Взаимоисключающие проверки. Eclipse не сечёт даже обращения к локальным переменным или параметрам типа таких:
public void test(boolean val) {
if(val) {
if(!val) {
System.out.println("Unreachable");
}
}
}Потенциальное отсутствие else, повторное присваивание Eclipse не подсвечивает. За абсолютные пути, конечно, тоже никто не поругает.




Прогнал анализ с помощью PVS Studio кода рабочего проекта, таки да, нашло много интересного (особенно с учетом того, что часть кода мы аутсорсили в китай). Было интересно и полезно, спасибо
Но вот некоторые вещи — PVS Studio через чур самоуверенно утрверждает не правильные утверждения ;) например, код:
PVS Studio выдает:
V584 The 'sign' value is present on both sides of the '<=' operator. The expression is incorrect or it can be simplified. XXXXX.h 2385
что принципиально не верно, т.к. в данном случае значение «sign» не известно в момент компиляции, а от него зависит знак оператора — если вдруг sign окажется отрицательным, то " x * sign <= end_x * sign" упрощается до " x >= end_x"
Но вот некоторые вещи — PVS Studio через чур самоуверенно утрверждает не правильные утверждения ;) например, код:
for (int x = start_x; x * sign <= end_x * sign; x += 16 * sign)
PVS Studio выдает:
V584 The 'sign' value is present on both sides of the '<=' operator. The expression is incorrect or it can be simplified. XXXXX.h 2385
что принципиально не верно, т.к. в данном случае значение «sign» не известно в момент компиляции, а от него зависит знак оператора — если вдруг sign окажется отрицательным, то " x * sign <= end_x * sign" упрощается до " x >= end_x"
Предлагаю вам прочекать реально большие продукты, например firefox, linux kernel
Про Chromium читали наш отчет?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Проверка VirtualDub