
В этом году статическому анализатору PVS-Studio исполнилось 10 лет. Правда, стоит уточнить, что 10 лет назад он назывался Viva64. И есть ещё одна интересная дата: прошло 5 лет с момента предыдущей проверки кода проекта Notepad++. С тех пор PVS-Studio был очень сильно доработан: добавлено около 190 новых диагностик, усовершенствованы старые. Впрочем, ожидать огромного количества ошибок в Notepad++ не стоит. Это небольшой проект, состоящий всего из 123 файлов с исходным кодом. Тем не менее, в коде найдены ошибки, которые будет полезно исправить.
Введение
Notepad++ — свободный текстовый редактор с открытым исходным кодом для Windows, с подсветкой синтаксиса большого количества языков программирования и разметки. Базируется на компоненте Scintilla, написан на C++ с использованием STL, а также Windows API и распространяется под лицензией GNU General Public License.
На мой взгляд, Notepad++ отличный текстовой редактор. Я сам его использую для всего, кроме написания кода. Для анализа исходников я воспользовался статическим анализатором PVS-Studio 6.15. Проект Notepad++ уже проверялся в 2010 и 2012 годах. Сейчас нашлось 84 предупреждения уровня High, 124 предупреждения уровня Medium и 548 предупреждений уровня Low. Уровни предупреждений указывают на достоверность найденных ошибок. Так, из 84-х наиболее достоверных предупреждений (High), 81, на мой взгляд, указывают на настоящие дефекты в коде — их стоит сразу исправить, не вникая глубоко в логику программы, т.к. проблемы очевидны.
Примечание. Кроме обработки результатов статического анализатора, будет полезно улучшить код, определившись: использовать для отступов пробелы или табы. Абсолютно весь код выглядит примерно так:
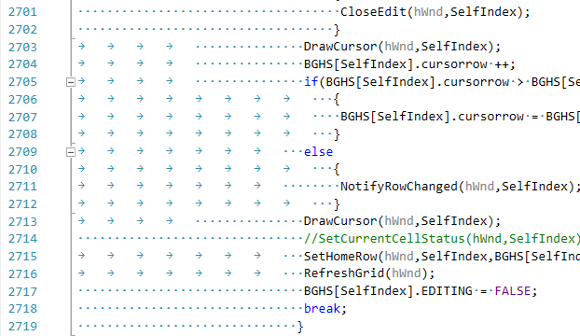
Рисунок 1 — Разные отступы в коде.
Давайте рассмотрим некоторые ошибки, которые показались мне наиболее интересными.
Проблемы наследования

V599 The virtual destructor is not present, although the 'FunctionParser' class contains virtual functions. functionparser.cpp 39
class FunctionParser
{
friend class FunctionParsersManager;
public:
FunctionParser(....): ....{};
virtual void parse(....) = 0;
void funcParse(....);
bool isInZones(....);
protected:
generic_string _id;
generic_string _displayName;
generic_string _commentExpr;
generic_string _functionExpr;
std::vector<generic_string> _functionNameExprArray;
std::vector<generic_string> _classNameExprArray;
void getCommentZones(....);
void getInvertZones(....);
generic_string parseSubLevel(....);
};
std::vector<FunctionParser *> _parsers;
FunctionParsersManager::~FunctionParsersManager()
{
for (size_t i = 0, len = _parsers.size(); i < len; ++i)
{
delete _parsers[i]; // <=
}
if (_pXmlFuncListDoc)
delete _pXmlFuncListDoc;
}Анализатором была найдена серьёзная ошибка, приводящая к неполному разрушению объектов. У базового класса FunctionParser присутствует виртуальная функция parse(), но отсутствует виртуальный деструктор. В иерархии наследования от этого класса присутствуют такие классы, как FunctionZoneParser, FunctionUnitParser и FunctionMixParser:
class FunctionZoneParser : public FunctionParser
{
public:
FunctionZoneParser(....): FunctionParser(....) {};
void parse(....);
protected:
void classParse(....);
private:
generic_string _rangeExpr;
generic_string _openSymbole;
generic_string _closeSymbole;
size_t getBodyClosePos(....);
};
class FunctionUnitParser : public FunctionParser
{
public:
FunctionUnitParser(....): FunctionParser(....) {}
void parse(....);
};
class FunctionMixParser : public FunctionZoneParser
{
public:
FunctionMixParser(....): FunctionZoneParser(....), ....{};
~FunctionMixParser()
{
delete _funcUnitPaser;
}
void parse(....);
private:
FunctionUnitParser* _funcUnitPaser = nullptr;
};Для наглядности я составил схему наследования для этих классов:
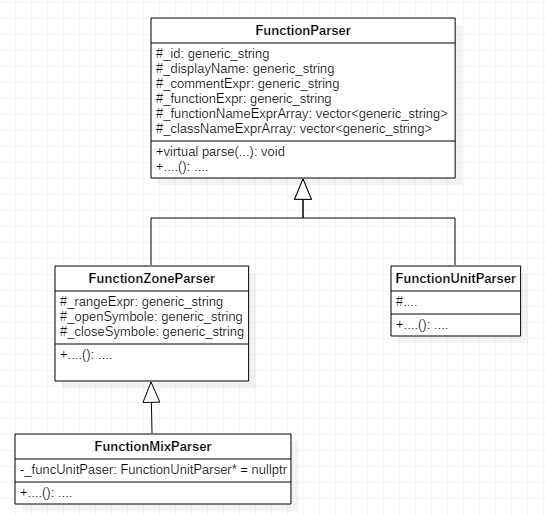
Рисунок 2 — Схема наследования от класса FunctionParser
Таким образом, созданные объекты будут разрушаться не полностью. Это приведёт к неопределённому поведению программы. Нельзя сказать как будет вести себя программа после того, как в ней возникнет UB, но на практике в данном случае, как минимум, произойдёт утечка памяти, так как код «delete _funcUnitPaser» не будет выполнен.
Рассмотрим следующую ошибку.
V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'redraw' in derived class 'SplitterContainer' and base class 'Window'. splittercontainer.h 61
class Window
{
....
virtual void display(bool toShow = true) const
{
::ShowWindow(_hSelf, toShow ? SW_SHOW : SW_HIDE);
}
virtual void redraw(bool forceUpdate = false) const
{
::InvalidateRect(_hSelf, nullptr, TRUE);
if (forceUpdate)
::UpdateWindow(_hSelf);
}
....
}
class SplitterContainer : public Window
{
....
virtual void display(bool toShow = true) const; // <= good
virtual void redraw() const; // <= error
....
}В коде Notepad++ найдено несколько проблем с перегрузкой функций. В классе SplitterContainer, унаследованного от класса Window, метод display() перегружен правильно, а при перегрузке метода redraw() допустили ошибку.
Ещё несколько неправильных мест:
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'UserDefineDialog' and base class 'StaticDialog'. userdefinedialog.h 332
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'FindReplaceDlg' and base class 'StaticDialog'. findreplacedlg.h 245
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'GoToLineDlg' and base class 'StaticDialog'. gotolinedlg.h 45
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'FindCharsInRangeDlg' and base class 'StaticDialog'. findcharsinrange.h 52
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'ColumnEditorDlg' and base class 'StaticDialog'. columneditor.h 45
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'WordStyleDlg' and base class 'StaticDialog'. wordstyledlg.h 77
- V762 It is possible a virtual function was overridden incorrectly. See first argument of function 'redraw' in derived class 'WordStyleDlg' and base class 'Window'. wordstyledlg.h 99
- V762 It is possible a virtual function was overridden incorrectly. See third argument of function 'create' in derived class 'PluginsAdminDlg' and base class 'StaticDialog'. pluginsadmin.h 107
Утечки памяти

V773 The function was exited without releasing the 'pXmlDocProject' pointer. A memory leak is possible. projectpanel.cpp 326
bool ProjectPanel::openWorkSpace(const TCHAR *projectFileName)
{
TiXmlDocument *pXmlDocProject = new TiXmlDocument(....);
bool loadOkay = pXmlDocProject->LoadFile();
if (!loadOkay)
return false; // <=
TiXmlNode *root = pXmlDocProject->FirstChild(TEXT("Note...."));
if (!root)
return false; // <=
TiXmlNode *childNode = root->FirstChildElement(TEXT("Pr...."));
if (!childNode)
return false; // <=
if (!::PathFileExists(projectFileName))
return false; // <=
....
delete pXmlDocProject; // <= free pointer
return loadOkay;
}Интересным примером утечки памяти является вот такая функция. Под указатель pXmlDocProject выделяется динамическая память, но освобождается она только при выполнении функции до конца. Что, скорее всего, является недоработкой, приводящей к утечкам памяти.
V773 Visibility scope of the 'pTextFind' pointer was exited without releasing the memory. A memory leak is possible. findreplacedlg.cpp 1577
bool FindReplaceDlg::processReplace(....)
{
....
TCHAR *pTextFind = new TCHAR[stringSizeFind + 1];
TCHAR *pTextReplace = new TCHAR[stringSizeReplace + 1];
lstrcpy(pTextFind, txt2find);
lstrcpy(pTextReplace, txt2replace);
....
}Функция processReplace() вызывается при каждой замене некой подстроки в документе. В коде выделяется память под два буфера: pTextFind и pTextReplace. В один буфер копируется искомая строка, а в другой — строка для замены. Тут присутствует несколько ошибок, следствием которых является утечка памяти:
- Буфер pTextFind не очищается и вообще не используется в функции. Для замены используется исходный буфер txt2find.
- Буфер pTextReplace в дальнейшем используется, но память тоже не освобождается.
Вывод: каждая операция автозамены приводит к утечке нескольких байт. Чем больше искомая строка и чем больше совпадений, тем больше течёт память.
Ошибки с указателями

V595 The 'pScint' pointer was utilized before it was verified against nullptr. Check lines: 347, 353. scintillaeditview.cpp 347
LRESULT CALLBACK ScintillaEditView::scintillaStatic_Proc(....)
{
ScintillaEditView *pScint = (ScintillaEditView *)(....);
if (Message == WM_MOUSEWHEEL || Message == WM_MOUSEHWHEEL)
{
....
if (isSynpnatic || makeTouchPadCompetible)
return (pScint->scintillaNew_Proc(....); // <=
....
}
if (pScint)
return (pScint->scintillaNew_Proc(....));
else
return ::DefWindowProc(hwnd, Message, wParam, lParam);
}В одном месте пропустили проверку указателя pScint на валидность.
V713 The pointer _langList[i] was utilized in the logical expression before it was verified against nullptr in the same logical expression. parameters.h 1286
Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ((_langList[i]->_langID == langID) || (!_langList[i]))
return _langList[i];
}
return nullptr;
}Автор кода допустил ошибку при записи условного выражения. Он сначала обращается к полю _langID, используя указатель _langList[i], а потом сравнивает этот указатель с нулём.
Скорее всего, правильный код должен быть таким:
Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ( _langList[i] && _langList[i]->_langID == langID )
return _langList[i];
}
return nullptr;
}Разные ошибки

V501 There are identical sub-expressions to the left and to the right of the '!=' operator: subject != subject verifysignedfile.cpp 250
bool VerifySignedLibrary(...., const wstring& cert_subject, ....)
{
wstring subject;
....
if ( status && !cert_subject.empty() && subject != subject)
{
status = false;
OutputDebugString(
TEXT("VerifyLibrary: Invalid certificate subject\n"));
}
....
}Помнится, в Notepad++ была найдена уязвимость, позволяющая подменять компоненты редактора на модифицированные. В код были добавлены проверки целостности. Я точно не знаю, этот код был написан для закрытия уязвимости или нет, но по названию функции можно судить, что служит она для важной проверки.
На фоне этого проверка:
subject != subjectвыглядит крайне подозрительно, скорее всего, правильно должно быть так:
if ( status && !cert_subject.empty() && cert_subject != subject)
{
....
}V560 A part of conditional expression is always true: 0xff. babygrid.cpp 711
TCHAR GetASCII(WPARAM wParam, LPARAM lParam)
{
int returnvalue;
TCHAR mbuffer[100];
int result;
BYTE keys[256];
WORD dwReturnedValue;
GetKeyboardState(keys);
result = ToAscii(static_cast<UINT>(wParam),
(lParam >> 16) && 0xff, keys, &dwReturnedValue, 0); // <=
returnvalue = (TCHAR) dwReturnedValue;
if(returnvalue < 0){returnvalue = 0;}
wsprintf(mbuffer, TEXT("return value = %d"), returnvalue);
if(result!=1){returnvalue = 0;}
return (TCHAR)returnvalue;
}Всегда истинные или всегда ложные условные выражения выглядят очень подозрительно. Константа 0xff всегда истинна. Возможно, допустили опечатку в операторе и параметр функции ToAscii() должен был быть таким:
(lParam >> 16) & 0xffV746 Type slicing. An exception should be caught by reference rather than by value. filedialog.cpp 183
TCHAR* FileDialog::doOpenSingleFileDlg()
{
....
try {
fn = ::GetOpenFileName(&_ofn)?_fileName:NULL;
if (params->getNppGUI()._openSaveDir == dir_last)
{
::GetCurrentDirectory(MAX_PATH, dir);
params->setWorkingDir(dir);
}
} catch(std::exception e) { // <=
::MessageBoxA(NULL, e.what(), "Exception", MB_OK);
} catch(...) {
::MessageBox(NULL, TEXT("....!!!"), TEXT(""), MB_OK);
}
::SetCurrentDirectory(dir);
return (fn);
}Перехватывать исключения лучше по ссылке. Проблема такого кода заключается в том, что будет создан новый объект, что приведёт к потере информации об исключении при перехвате. Всё, что хранилось в унаследованных от Exception классах, будет недоступно.
V519 The 'lpcs' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 3116, 3117. babygrid.cpp 3117
LRESULT CALLBACK GridProc(HWND hWnd, UINT message,
WPARAM wParam, LPARAM lParam)
{
....
case WM_CREATE:
lpcs = &cs;
lpcs = (LPCREATESTRUCT)lParam;
....
}Сразу перетёрли старое значение новым. Похоже на ошибку. Если сейчас всё работает правильно, то следует оставить только вторую строчку с присваиванием, а первую удалить.
V601 The 'false' value becomes a class object. treeview.cpp 121
typedef std::basic_string<TCHAR> generic_string;
generic_string TreeView::getItemDisplayName(....) const
{
if (not Item2Set)
return false; // <=
TCHAR textBuffer[MAX_PATH];
TVITEM tvItem;
tvItem.hItem = Item2Set;
tvItem.mask = TVIF_TEXT;
tvItem.pszText = textBuffer;
tvItem.cchTextMax = MAX_PATH;
SendMessage(...., reinterpret_cast<LPARAM>(&tvItem));
return tvItem.pszText;
}Возвращаемым значением функции является строка, но вместо пустой строки кто-то решил сделать «return false».
Чистка кода

Делать рефакторинг ради рефакторинга не стоит, в любом проекте есть много других полезных задач. Но избавляться от бесполезного кода однозначно нужно.
V668 There is no sense in testing the 'source' pointer against null, as the memory was allocated using the 'new' operator. The exception will be generated in the case of memory allocation error. notepad_plus.cpp 1149
void Notepad_plus::wsTabConvert(spaceTab whichWay)
{
....
char * source = new char[docLength];
if (source == NULL)
return;
....
}Вот зачем здесь эта проверка? Согласно современному стандарту C++, оператор new бросает исключение при нехватке памяти, а не возвращает nullptr.
Эта функция зовётся при замене всех символов табуляции на пробелы во всём документе. Взяв большой текстовый документ, я убедился, что нехватка памяти в этом месте действительно приводит к краху программы.
Если корректировать проверку, то при нехватке памяти будет происходить отмена операции замены символов, и редактором можно пользоваться дальше. Все такие места следует исправить, и их так много, что пришлось вынести список в отдельный файл.
V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3928
bool Notepad_plus::doBlockComment(comment_mode currCommentMode)
{
....
if ((!commentLineSymbol) || // <=
(!commentLineSymbol[0]) ||
(commentLineSymbol == NULL)) // <= WTF?
{ .... }
....
}Таких странных и бесполезных проверок найдено десять штук:
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3928
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3931
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 3931
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4228
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4228
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 4229
- V713 The pointer commentStart was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6554
- V713 The pointer commentEnd was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6554
- V713 The pointer commentLineSymbol was utilized in the logical expression before it was verified against nullptr in the same logical expression. notepad_plus.cpp 6555
V601 The 'true' value is implicitly cast to the integer type. pluginsadmin.cpp 603
INT_PTR CALLBACK PluginsAdminDlg::run_dlgProc(UINT message, ....)
{
switch (message)
{
case WM_INITDIALOG :
{
return TRUE;
}
....
case IDC_PLUGINADM_RESEARCH_NEXT:
searchInPlugins(true);
return true;
case IDC_PLUGINADM_INSTALL:
installPlugins();
return true;
....
}
....
}Функция run_dlgProc() и так возвращает значение далеко не логического типа, так ещё в коде возвращают то true/false, то TRUE/FALSE. Хотел написать, что в функции хотя бы отступы одного типа, но нет: из 90 строк функции в одной строке все равно присутствует смесь из табуляций и пробелов. В остальных строках используются символы табуляции. Да, это всё не критично, но код выглядит для меня, как стороннего наблюдателя, неаккуратным.
V704 '!this' expression in conditional statements should be avoided — this expression is always false on newer compilers, because 'this' pointer can never be NULL. notepad_plus.cpp 4980
void Notepad_plus::notifyBufferChanged(Buffer * buffer, int mask)
{
// To avoid to crash while MS-DOS style is set as default
// language,
// Checking the validity of current instance is necessary.
if (!this) return;
....
}К бесполезному коду я бы ещё отнёс такие проверки. Как видно из комментария, раньше проблема разыменования нулевого this была. Согласно же современному стандарту языка C++, такая проверка является лишней.
Список всех таких мест:
- V704 'this && type == DOCUMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 505
- V704 'this && type == ELEMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 506
- V704 'this && type == COMMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 507
- V704 'this && type == UNKNOWN' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 508
- V704 'this && type == TEXT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 509
- V704 'this && type == DECLARATION' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxmla.h 510
- V704 'this && type == DOCUMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 505
- V704 'this && type == ELEMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 506
- V704 'this && type == COMMENT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 507
- V704 'this && type == UNKNOWN' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 508
- V704 'this && type == TEXT' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 509
- V704 'this && type == DECLARATION' expression should be avoided: 'this' pointer can never be NULL on newer compilers. tinyxml.h 510
- V704 'this' expression in conditional statements should be avoided — this expression is always true on newer compilers, because 'this' pointer can never be NULL. nppbigswitch.cpp 119
Заключение
Были найдены и другие ошибки, которые не вошли в статью. При желании авторы Notepad++ могут самостоятельно проверить проект и внимательно изучить предупреждения. Мы готовы предоставить им для этого временную лицензию.
Конечно, обычному пользователю описанные проблемы не видны. Модули оперативной памяти сейчас больших объёмов и дешёвые :). Тем не менее, развитие проекта продолжается, а качество кода, как и удобство его поддержки, можно значительно улучшить, исправив найденные ошибки и удалив пласты устаревшего кода.
По моим расчётам, на 1000 строк кода анализатор PVS-Studio выявлял 2 настоящие ошибки. Конечно, это не все ошибки. Думаю, на самом деле их будет где-то 5-10 на 1000 строк кода, что соответствует небольшой плотности ошибок. Размер проекта Notepad++ составляет 95 KLoc, а значит типичная плотность ошибок для проектов этого размера: 0-40 ошибок на 1000 строк кода. Впрочем, источник этих чисел стар, и я считаю, что, в среднем, качество кода сейчас стало выше.
Ещё раз хочу поблагодарить авторов Notepad++ за их работу над крайне полезным инструментом и желаю им всевозможных успехов.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Svyatoslav Razmyslov. Checking Notepad++: five years later
Прочитали статью и есть вопрос?
Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: Ответы на вопросы читателей статей про PVS-Studio, версия 2015. Пожалуйста, ознакомьтесь со списком.
