
Больше всего расстраивает в ИИ-моделях генерации изображений по текстовым описаниям то, что они походят на «чёрный ящик». Мы знаем, что их обучали на скачанных из веба изображениях, но каких именно? Любому художнику или фотографу интересно, использовались ли его работы для обучения ИИ-модели, но на этот вопрос неожиданно трудно ответить.
Иногда данные полностью недоступны: OpenAI сообщает, что обучила DALL-E 2 на сотнях миллионов изображений с подписями, но не опубликовала проприетарные данные. Команда разработчиков Stable Diffusion, напротив, очень прозрачно говорит о том, как обучалась её модель. Так как недавно её опубликовали для общего доступа, Stable Diffusion испытала взрывную популярность, в основном благодаря своей свободной и мягкой лицензионной политике. Модель уже встроена в новую бету Midjourney, NightCafe и собственное приложение Stability AI под названием DreamStudio, а также доступна для работы на собственном компьютере.
Однако обучающие массивы данных Stable Diffusion большинству людей скачать невозможно, не говоря уже о том, чтобы выполнить по ним поиск: метаданные миллионов (или миллиардов!) изображений хранятся в таинственных форматах файлов, сложенных в большие архивы из множества частей.
Поэтому мы с моим другом Саймоном Уиллисоном скачали данные более двенадцати миллионов изображений, применённых для обучения Stable Diffusion, и воспользовались его проектом Datasette для создания браузера данных, чтобы вы могли исследовать их самостоятельно. Следует учесть, что это лишь небольшое подмножество всего объёма обучающих данных: примерно 2% из 600 миллионов изображений, использованных для обучения трёх последних чекпоинтов, и всего 0,5% от 2,3 миллиарда изображений, на которых модель обучалась изначально.
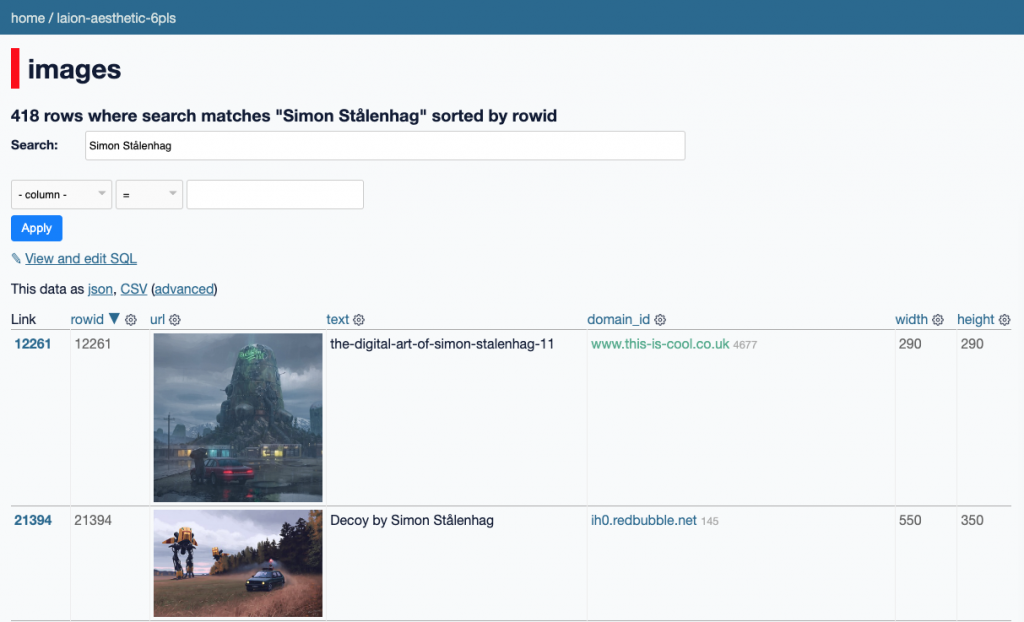
Скриншот браузера данных LAION-Aesthetic в Datasette
Вы можете протестировать его прямо сейчас: laion-aesthetic.datasette.io!
Ниже рассказывается о том, как собирался этот массив данных, о веб-сайтах, с которых чаще всего скачивались изображения, а также про художников, лица знаменитостей и вымышленных персонажей, чаще всего встречающихся в данных.
Источник данных
Stable Diffusion обучалась на трёх огромных массивах данных, собранных LAION — некоммерческой организацией, вычислительные ресурсы которой по большей мере финансировались владельцем Stable Diffusion — компанией Stability AI.
Все массивы данных изображений LAION собраны на основе данных Common Crawl — некоммерческой организации, ежемесячно выполняющей скрейпинг миллиардов веб-страниц и публикующей их в виде огромных массивов данных. LAION собрала все HTML-теги изображений, имеющих атрибуты
alt-текста, в результате получив пять миллиардов пар «изображение-текст» с учётом их языка, а затем отфильтровала результаты в отдельные массивы данных на основании их разрешения, спрогнозированной вероятности наличия водяных знаков и оценки их «эстетичности» (то есть субъективного визуального качества).
Коллаж из части изображений с наивысшей оценкой эстетичности: в основном это акварельные ландшафты и портреты женщин
Первоначальное обучение Stable Diffusion выполнялось на изображениях низкого разрешения размером 256×256 из LAION-2B-EN — массива в 2,3 миллиарда изображений с подписями на английском языке из полной коллекции LAION-5B (5,85 миллиарда пар «изображение-текст»), а также на LAION-High-Resolution — ещё одном подмножестве LAION-5B с 170 миллионами изображений разрешением более 1024×1024 (с даунсэмплингом до 512×512).
Последние три чекпоинта модели обучались на LAION-Aesthetics v2 5+ — подмножестве LAION-2B-EN с 600 миллионами изображений, имеющих спрогнозированную оценку эстетичности 5 или выше; из массива были отфильтрованы изображения низкого разрешения и изображения, потенциально имеющие водяные знаки.
Изначально мы хотели отобразить в своём браузере данных весь массив данных, однако хостинг базы данных из 600 миллионов записей дешёвым и быстрым способом — сложная задача. Поэтому мы решили использовать имеющий меньший размер LAION-Aesthetics v2 6+, содержащий 12 миллионов пар «изображение-текст» с прогнозируемой оценкой эстетичности от 6 и выше, а не 600 миллионов пар с оценкой от 5 и выше, которые использовались для обучения Stable Diffusion.
Это должно быть репрезентативной выборкой изображений, использованных для обучения последних трёх чекпоинтов Stable Diffusion, однако с уклоном в более эстетически привлекательные изображения. Стоит заметить, что организация LAION предоставляет удобный фронтенд для поиска эмбеддингов CLIP, вычисленных на основе массивов данных из 400 миллионов и пяти миллиардов изображений, но он не позволяет выполнять поиск исходных подписей к изображениям.
Домены источников
Мы знаем, что подписанные изображения, использованные для Stable Diffusion, были получены веб-скрейпингом, но откуда? Чтобы выяснить это, мы проиндексировали по доменам 12 миллионов изображений из нашей выборки.
Почти половина изображений, примерно 47%, была получена всего с 100 доменов, а самое большое количество изображений взято с Pinterest. Более миллиона изображений, или 8,5% от всего массива данных, скрейпировано с CDN Pinterest
pinimg.com.Важным источником данных об изображениях стали платформы генерируемого пользователями контента. Блоги WordPress на wp.com и wordpress.com суммарно представлены 819 тысячами изображений, или 6,8% от всех изображений. Другие сайты с фото, графикой и блогами представлены 232 тысячами изображений с Smugmug, 146 тысячами с Blogspot, 121 тысячью с Flickr, 67 тысячами с DeviantArt, 74 тысячами с Wikimedia, 48 тысячами с 500px и 28 тысячами с Tumblr.
Широко представлены сайты онлайн-магазинов. Вторым по величине доменом был Fine Art America, продающий принты и постеры, из него в массиве данных использовано 698 тысяч изображений (5,8%). 244 тысяч изображений взято с Shopify, по 189 тысяч с Wix и Squarespace, 90 тысяч с Redbubble и всего чуть больше 47 тысяч с Etsy.
Неудивительно, что большое количество взято с сайтов стоковых изображений. Среди множества прочих, с 123RF взято больше всех — 497 тысяч, 171 тысяч взято с CDN Adobe Stock по адресу
ftcdn.net, 117 тысяч с PhotoShelter, 35 тысяч с Dreamstime, 23 тысяч с iStockPhoto, 22 тысяч с Depositphotos, 22 тысяч с Unsplash, 15 тысяч с Getty Images, 10 тысяч с VectorStock и 10 тысяч с Shutterstock.Однако стоит заметить, что сами домены могут не представлять истинных источников изображений. Например, с домена Artstation.com взято всего 6292 изображения, однако ещё 2740 изображений со словом “artstation” в тексте описания хостились на сайтах наподобие Pinterest.
Художники
Мы хотели понять, как в массиве данных представлены художники, поэтому воспользовались списком из более 1,8 тысяч художников MisterRuffian’s Latent Artist & Modifier Encyclopedia, выполнив поиск по массиву данных и подсчитав количество изображений, в описаниях которых упоминается имя каждого художника. Просмотреть эту статистику по художникам можно здесь, также можно поискать по любому художнику в таблице изображений. (Рекомендуется выполнять поиск со строками, заключёнными в кавычки.)
Из 25 самых популярных в массиве данных художников живы всего трое: Фил Кох, Эрин Хэнсон и Стив Хендерсон. Кто же оказался самым часто встречающимся художником? «Томас Кинкейд, художник света™» собственной персоной, в массив попало 9268 его изображений.
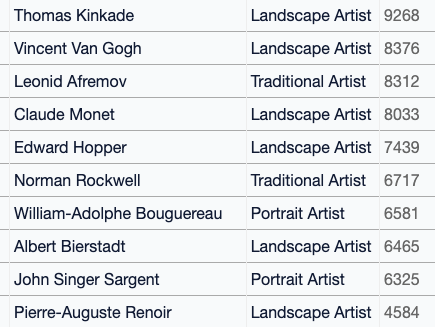
Из списка 1,8 тысяч популярных художников эта десятка чаще всего встречается в подписях к изображениям
При помощи поля “type” в базе данных можно посмотреть самых часто встречающихся художников в каждой из категорий: например, при просмотре художников-комиксистов чаще всего в подписях к изображениям встречается имя Стэна Ли. (Как верно заметил один из комментаторов, Стэн Ли был писателем комиксов, а не художником, но люди используют его имя для генерации изображений в стиле графики комиксов, с которыми он ассоциируется.)
Некоторые из самых часто упоминаемых рекомендуемых художников в запросах генерации изображений не так распространены в массиве данных, как можно было ожидать. В массиве данных всего 15 изображений с упоминанием фэнтези-художника Грега (Гжегоша) Рутковски, чьё имя часто используется в качестве модификатора запросов, и лишь 73 изображения Джеймса Гарни.
(Здесь снова стоит упомянуть, что эти изображения являются лишь подмножеством одного из трёх массивов данных, использованных для обучения ИИ, поэтому даже если данные не найдены среди этих 12 миллионов изображений, работы художника всё равно могут использоваться где-то ещё.)
Знаменитости
В отличие от DALL-E 2, Stable Diffusion не имеет никаких ограничений на генерацию изображений людей, имена которых указаны в массиве данных. Чтобы понять, насколько широко представлены в массиве известные люди, мы взяли два списка знаменитостей и других известных имён, и объединили их в список примерно из двух тысяч имён. Результаты подсчёта количества знаменитостей можно посмотреть здесь; также можно поискать любое имя в таблице изображений. (Очевидно, что самые популярные запросы наподобие “Pink” и “Prince” содержат результаты, не относящиеся к этому человеку.)
Дональд Трамп — одно из самых частых имён в массиве изображений, оно упоминается примерно в 11 тысячах фотографий. На втором месте находится Шарлиз Терон с 9576 изображениями.


Коллажи из сгенерированных Stable Diffusion портретов Дональда Трампа и Шарлиз Терон
Полная сортировка по полу заняла бы больше времени, но на первый взгляд кажется, что многие самые популярные имена в массиве являются женскими.
Как ни странно, чрезвычайно популярные Интернет-личности наподобие Дэвида Добрика [прим. пер.: ютубер], Эддисон Рэй [танцовщица], Чарли Д’Амелио [видеоблогер и танцовщица], Дикси Д’Амелио [видеоблогер и певица] и MrBeast [видеоблогер] полностью отсутствуют в подписях к массиву данных. Я подумал, что данные CommonCrawl были слишком старыми, поэтому в них не попали эти новые знаменитости, но судя по URL, в данных есть десятки тысяч изображений, сделанных в прошлом году. (Если вы можете решить эту загадку, то свяжитесь со мной или оставьте комментарий к оригиналу статьи!)
Вымышленные персонажи
Далее мы узнаем, как представлены в массиве данных популярные вымышленные персонажи, потому что эта тема генерации чрезвычайно популярна в генерации Stable Diffusion и Craiyon, но часто невозможна при работе с DALL-E 2, как видно из этого примера с Микки Маусом из моего предыдущего поста.


«realistic 3d rendering of mickey mouse working on a vintage computer doing his taxes» («реалистичный 3d-рендеринг микки мауса, считающего налоги на старом компьютере») в DALL·E 2 (наверху) и Stable Diffusion (внизу)
Для этой серии поисковых запросов мы использовали список из 600 вымышленных персонажей поп-культуры. Результаты можно просмотреть здесь; также можно поискать любого другого персонажа в таблице изображений. (Однако тут тоже стоит избегать использования имён персонажей из одного слова наподобие “Link,” “Data,” и “Mario”, потому что есть большая вероятность получения множества результатов, не связанных с этим персонажем.)
Лучше всего в массиве данных представлены персонажи вселенной Marvel Comics наподобие Капитана Марвел (4993 изображения), Чёрной Пантеры (4395) и Капитана Америки (3155). Бэтмен (2950) и Супермен (2739) идут нос к носу. Изображений Люка Скайуокера (2240) больше, чем Дарта Вейдера (1717) и Хана Соло (1013). Микки Маус едва попал в сотню самых популярных с 520 изображениями.
NSFW-контент
Наконец, давайте вкратце рассмотрим «взрослые» материалы — ещё одно сильное отличие Stable Diffusion от всех остальных моделей. OpenAI тщательно вычищает из обучающих данных сексуальный контент и контент с насилием и блокирует в запросах потенциальные ключевые NSFW-слова (NSFW — «not safe/suitable for work», материалы, которые не стоит просматривать на работе).
Команда разработчиков Stable Diffusion создала предиктор для выявления «взрослых» материалов и присвоила каждому изображению оценку вероятности NSFW, которая указана в поле “punsafe” таблицы изображения в интервале от 0 до 1. (Предупреждение: очевидно, сортировка по этому полю покажет самые NSFW-изображения в массиве данных.)
В заявлении о полном массиве данных LAION-5B представитель команды LAION Ромен Бельмонт сообщил, что примерно 2,9% изображений с англоязычными подписями были «небезопасными», но при просмотре данного массива непонятно, как предикторы это определяли.
В массиве изображений определённо присутствуют NSFW-материалы, но их на удивление мало. Всего 222 изображения получило оценку вероятности небезопасности “1”, показывающую, что они со стопроцентной уверенностью небезопасны. То есть всего 0,002% от общего количества изображений совершенно точно являются порнографией. Однако, похоже, нагота редко встречается за вне этого уровня уверенности: даже в изображениях с оценкой punsafe 0,9999 (уверенность 99,99%) редко содержат наготу.
Вполне возможно, что фильтрация по рейтингу эстетичности устраняет из массива данных огромное количество NSFW-контента, и в полном массиве его гораздо больше. А может быть, определение понятия «небезопасно» очень широкое.
Дополнительная информация
Снова выражаю огромную благодарность Саймону Уиллисону за совместную работу над этим проектом: он взял на себя все сложности, связанные с хостингом данных. Если вам интересны технические детали, Саймон написал подробный пост о создании поискового движка. Его Datasette — опенсорсный и невероятно гибкий проект, который определённо стоит оценить. Если вы хотите поэкспериментировать с данными самостоятельно, то можете использовать скрипты из его репозитория в GitHub для скачивания и импорта массива в базу данных SQLite.
