
Хабр, это доклад инженера-программиста Алексея Старкова на конференции Moscow Python Conf++ 2018 в Москве. Видео в конце поста.Всем привет! Меня зовут Алексей Старков — это я, в свои лучшие годы, работаю на заводе.
Теперь я работаю в Qrator Labs. В основном, всю свою жизнь, я занимался C и C++ — люблю Александреску, «Банду Четырех», принципы SOLID — вот это всё. Что и делает меня архитектурным космонавтом. Последние пару лет пишу на Python, потому что мне это нравится.
Собственно, кто такие «архитектурные космонавты»? Первый раз я встретил данный термин у Джоэля Спольски, вы наверное его читали. Он описывает «космонавтов», как людей, которые хотят построить идеальную архитектуру, которые навешивают абстракцию, над абстракцией, над абстракцией, которая становится все более и более общей. В конце концов, эти уровни идут так высоко, что описывают все возможные программы, но не решают никаких практических задач. В этот момент у «космонавта» (это последний раз, когда данный термин окружен кавычками) кончается воздух и он умирает.
Я тоже имею тенденции к архитектурной космонавтике, но в этом докладе я расскажу немного о том, как это меня укусило и не позволило построить систему с необходимой производительностью. Главное — как я это поборол.
Краткое содержание моего доклада: было / стало.

Увеличение в тысячи и миллионы раз. Когда я сделал этот слайд, единственная мысль, которая у меня возникла, это: «Как?»

Где я мог так сильно накосячить? Если вы не хотите накосячить так же как я — читайте дальше.

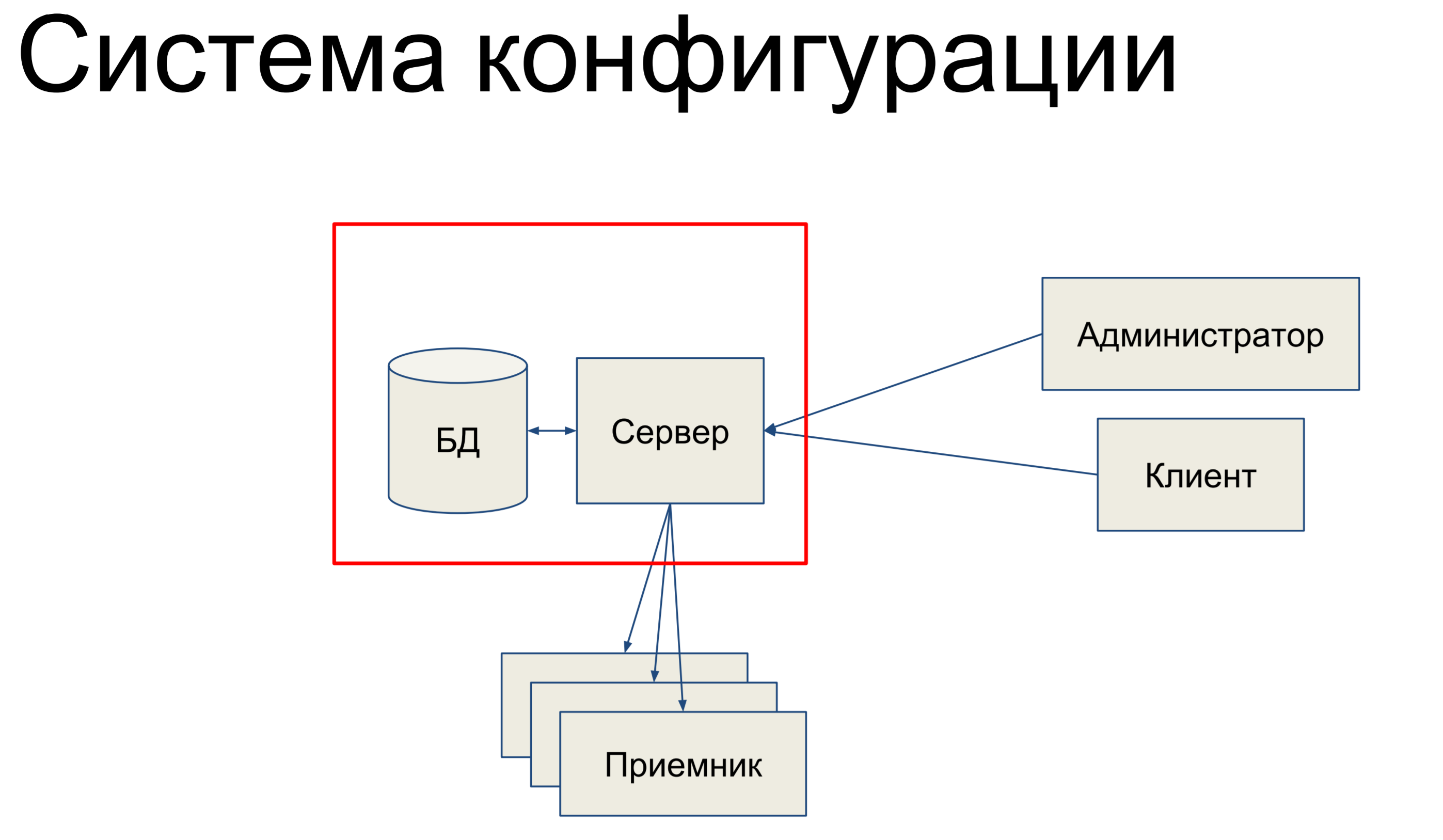
Я буду рассказывать про систему конфигурации. Система конфигурации — это внутренний инструмент в Qrator Labs, которая занимается тем, что хранит конфигурацию для Software Defined Network (SDN) — нашей сети фильтрации. Она занимается тем, что синхронизирует конфигурацию между компонентами и отслеживает ее состояние.

Из чего она, вкратце, состоит? У нас есть база данных, в которой хранится слепок нашей конфигурации для всей сети, и есть сервер, который обрабатывает команды, приходящие на него и каким то образом меняет конфигурацию.
Наши технические администраторы и клиенты приходят в этот сервер и с помощью консоли, через конечные API эндпойнты, REST API, JSON RPC и прочего выдают команды к серверу, вследствие чего он меняет нашу конфигурацию.
Команды могут быть как очень простые, так и посложнее. Затем, у нас есть некий набор приемников, которые составляют нашу SDN и сервер пушит конфигурацию на эти приемники. Звучит довольно просто. В основном, я буду рассказывать вот про эту часть.
Поскольку именно она имеет отношение к базе данных и к алхимии.

В чем особенность этой системы? Она достаточно небольшая — средненькая. Сотни тысяч, до миллионов, сущностей хранятся в этой базе. Особенность в том, что граф отношений между сущностями довольно сложный. Есть несколько иерархий наследования между сущностями, есть включения, есть просто зависимости между ними. Все эти ограничения обусловлены бизнес-логикой и мы их должны соблюдать.
Соотношение запросов на запись к запросам на чтение составляет примерно 15:1. Тут понятно: приходит много команд на изменение конфигурации и раз в некий продолжительный период времени у нас происходит пуш конфигурации на конечные точки.
Внутри используется MySQL — он имеется и в других продуктах нашей компании, у нас достаточно серьезная экспертиза по данной БД, есть люди которые умеют с ней работать: построить схему данных, проектировать запросы и все остальное. Поэтому мы взяли MySQL, как универсальную реляционную базу данных.

В чем возникла проблема после того, как мы спроектировали эту систему? Выполнение одной команды занимало от одной до тридцати секунд, в зависимости от сложности команды. Соответственно, задержка выполнения доходила до пяти минут. Одна команда пришла — 30 секунд, вторая и так далее, стопку накопили — задержка 5 минут.
Задержка на применение конфигурации — до десяти минут. Было принято решение, что для нас этого недостаточно и необходимо провести оптимизацию.

Первое — прежде чем проводить любую оптимизацию, необходимо провести расследование и выяснить, в чем же, собственно, дело.

Как оказалось, у нас не хватало самого важного компонента для расследования — у нас не было телеметрии. Поэтому, если вы какую то систему проектируете, сначала, на этапе проектирования, закладывайте в нее телеметрию. Даже если система изначально маленькая, потом чуть побольше, потом еще больше — в итоге все приходят к ситуации, когда нужно смотреть трейсы, а телеметрии нет.
Что можно сделать следующим, если у вас нет телеметрии? Можно анализировать логи. Здесь достаточно простые скрипты проходят наши логи и превращают их вот в такую таблицу, иллюстрирующую самое быстрое, самое медленное и среднее время выполнения команды. Начиная отсюда, мы уже видим, в каких местах у нас затыки: какие команды выполняются дольше, какие — быстрее.

Единственное, что нужно отметить — анализируя логи, мы считаем только время выполнения этих команд на сервере. Это первый этап — тот, что помечен как t2. t1 — это то, как клиент увидит время исполнения нашей команды: попадание в очередь, ожидание, выполнение на сервере. Это время будет больше, поэтому мы оптимизируем время t2, а после используем время t1 для того, чтобы определить, достигли ли мы цели.
t1 является метрикой качества нашего быстродействия.

Соответственно, так мы все команды попрофилировали — то есть взяли лог с сервера, прогнали его через наши скрипты, посмотрели и выявили компоненты, работающее наиболее медленно. Сервер построен достаточно модулярно, за каждую команду отвечает отдельный компонент, и мы можем профилировать компоненты индивидуально — и делать для них бенчмарки. Такой вот у нас был класс — для каждого проблемного компонента мы писали, в котором в code_under_test() мы делали некую активность, изображающую боевое использование компонента. И было два метода: profile() и bench(). Первый вызывает cProfile, показывая сколько раз что вызывалось, где бутылочные горлышки.
bench() запускался несколько раз и считал нам разные метрики — так мы оценивали производительность.
Но, оказалось, что проблема то не в этом!

Основная проблема оказалась в количестве запросов к базе данных. Запросов было очень много и, чтобы понять, почему их было так много — давайте посмотрим на то, как все было организовано.
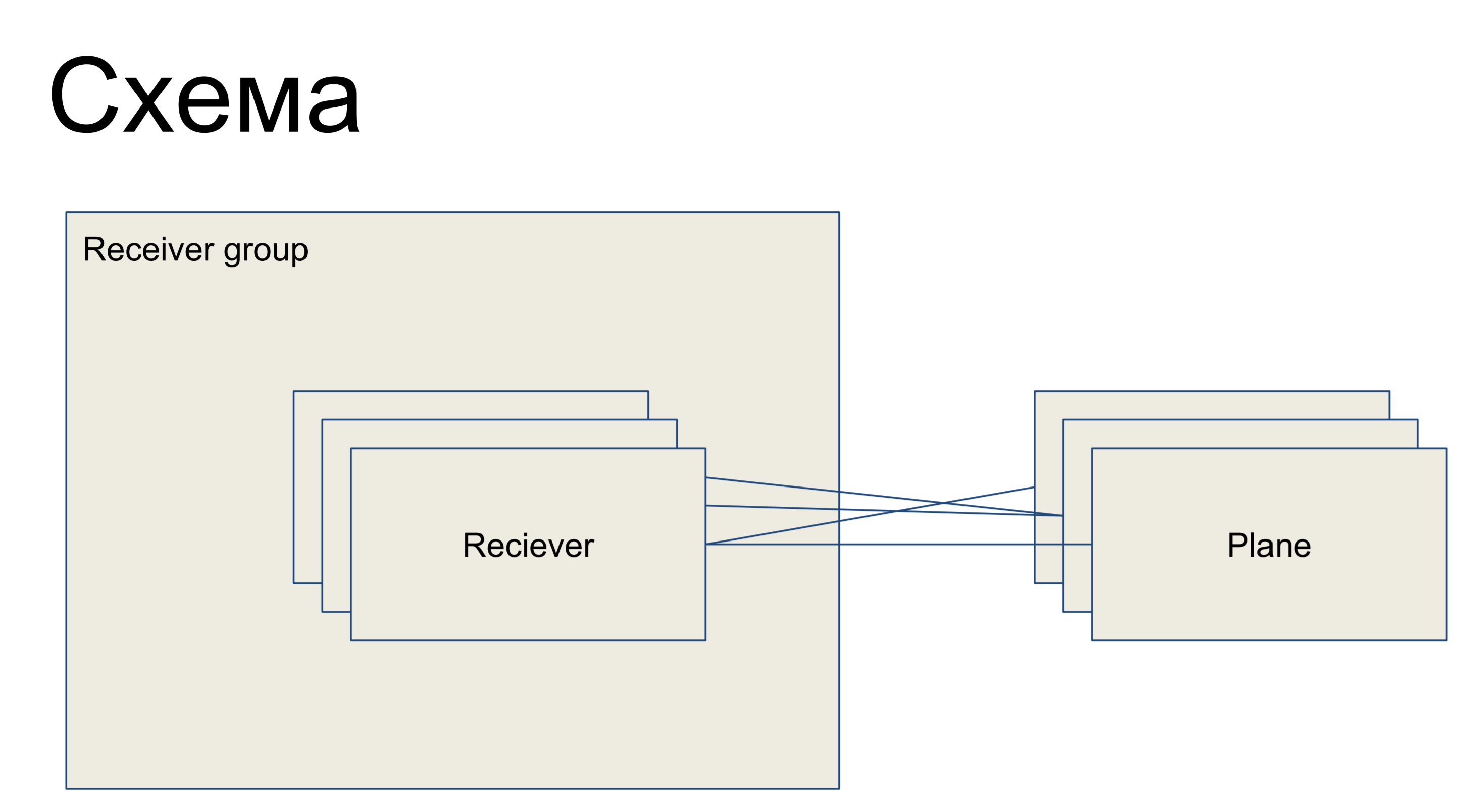
Перед нами кусочек простой схемы, представляющей наши приемники, представленные в виде класса Reciever. Они объединены в некоторую группу — receiver group. И, соответственно, есть какие-то конфигурационные плейны — срезы конфигурации, представляющие собой подмножество конфигураций, отвечающие за одну «роль» этого ресивера. Например, для раутинга — routing plane. Плейны с ресиверами могут быть связаны в любом порядке — то есть это отношение «многие ко многим».
Это кусочек большой схемы, который я привожу здесь для того, чтобы далее были понятны примеры.
Что хочет сделать каждый архитектурный космонавт, когда он видит чужой API? Он хочет спрятать его, абстрагировать и написать свой интерфейс, для того чтобы можно было убрать этот API, вернее спрятать его.
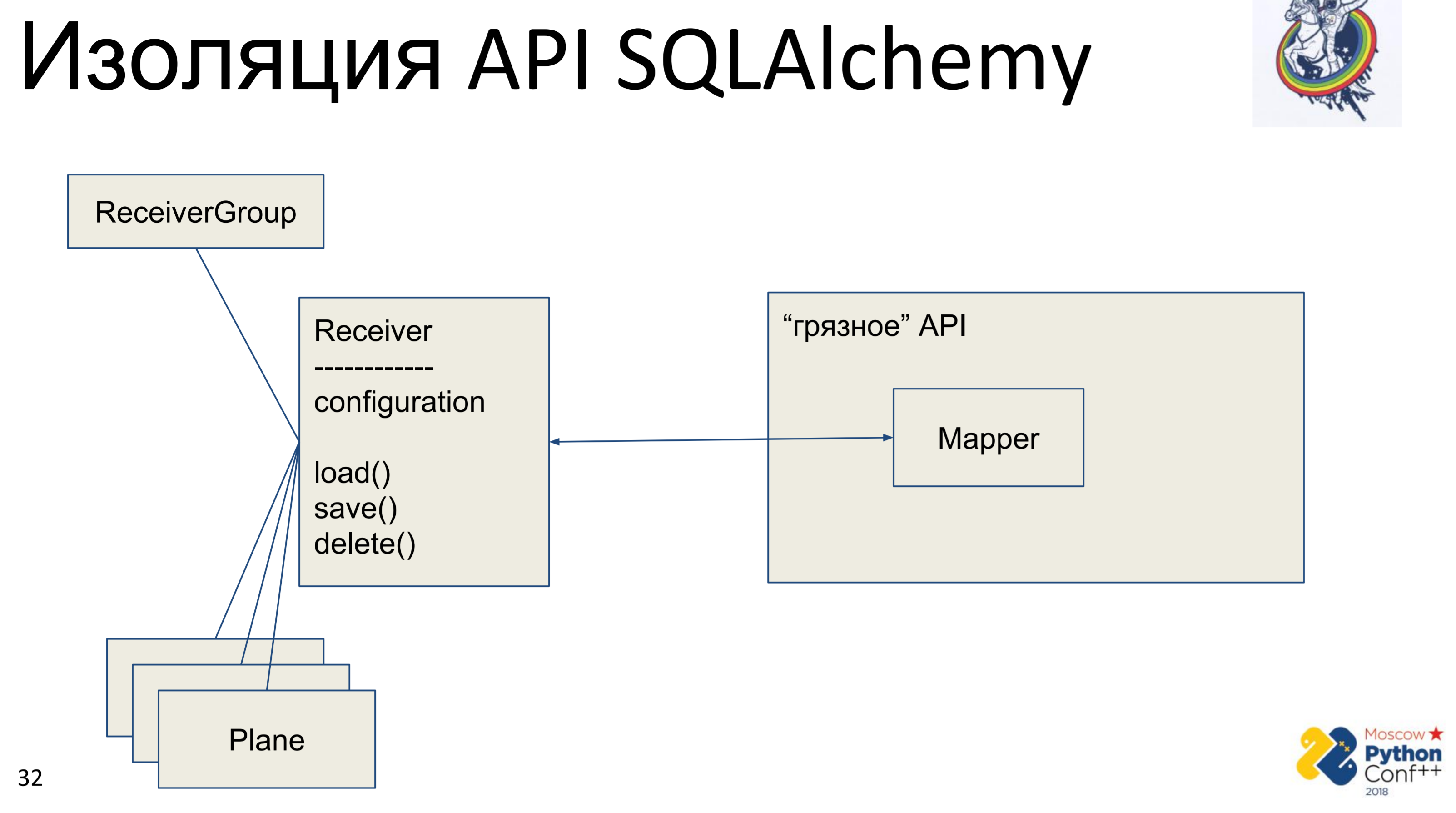
Соответственно, есть «грязный» API алхимии, в котором находятся, собственно, мэпперы и наш «чистый» класс — Receiver, в котором хранится какая-то конфигурация и есть методы: load(), save(), delete(). И все остальные, связанные с ним классы. У нас получается граф питоновских объектов, как-то связанных между собой — у каждого из них есть метод load(), save(), delete(), который обращается к мэпперу алхимии, который, в свою очередь, обращается в API.

Реализация тут очень простая. У нас есть метод load, который делает query в базу данных и для каждого полученного объекта создает свой питоновский объект. Есть метод save, который делает обратную операцию — смотрит, есть ли объект в базе данных, по первичному ключу, если нет — создает, добавляет и далее мы сохраняем состояние этого объекта. delete по первичному ключу получает и удаляет объект из базы.

Основная проблема сразу же видна — это мэппинг. Сначала мы делаем это один раз из питоновского объекта в мэппер, потом мэппер мэппит в базу. Дополнительный мэппинг — это один-два вызова, что может быть еще не так страшно. Основной проблемой оказалась ручная синхронизация. У нас есть два объекта нашего «чистого» интерфейса и у одного из них меняется атрибут — как мы увидим, что атрибут поменялся в другом? Никак. Необходимо слить изменения в базу и получить атрибут в другом объекте. Конечно, если мы знаем, что объекты присутствуют в одном контексте, мы можем как-то это отследить. Но если у нас две сессии в разных местах — только через базу, либо городить базу в памяти, чего мы делать не стали.
Этот load/save/delete — это еще один мэппер, который полностью дублирует внутренности алхимии, которая хорошо написана, оттестирована. Этому инструменту много лет, в интернете по нему куча помощи и дублировать это тоже не очень хорошо.
Видите значок в правом верхнем углу? Так я буду помечать слайды, на которых делается что-то для «чистоты», для повышения уровня абстракции, для архитектурной космонавтики. То есть слайды без этого значка — прагматичные и скучные, неинтересные и их можно не читать.
Что делать, если медленно работает много запросов. Много ли? На самом деле много. Представим себе цепь наследования: один объект, у него один родитель, у того еще один родитель. Мы синхронизируем дочерний объект — для того, чтобы это сделать, сначала необходимо синхронизировать родителей. Для того, чтобы синхронизировать родителя, нужно синхронизировать и его родителя. Хорошо, всех синхронизировали. На самом же деле, в зависимости от того, как у нас построен граф, мы могли ходить и по сто раз синхронизировать все эти объекты — отсюда большое количество запросов.
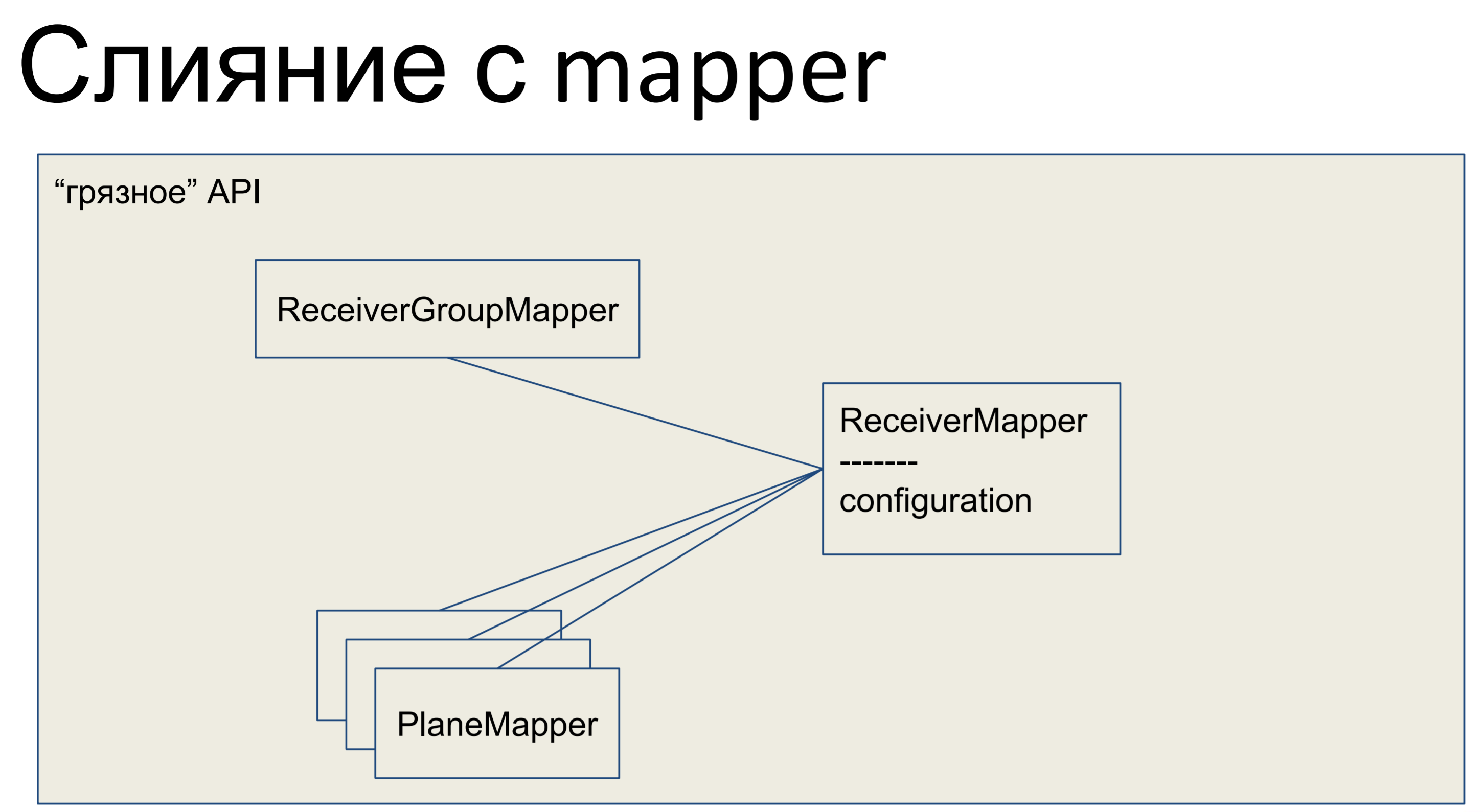
Что мы сделали? Мы взяли всю нашу бизнес-логику и засунули ее в мэппер. Все остальные объекты у нас тоже слились с мэпперами и всё наше API, весь data abstraction layer, оказался «грязным».

Вот как это выглядит в Python — у нашего мэппера есть какая-то бизнес-логика, тут же присутствует декларативное описание этой таблички. Колоночки перечислены, отношения. Вот такой вот мы имеем класс.

Конечно, с точки зрения любого космонавта, грязное API — недостаток. Бизнес-логика в декларативном описании базы. Схемы перемешаны с бизнес-логикой. Фу. Некрасиво.
Загромождается описание схемы. Это на самом деле проблема — если бизнес-логики у нас не две строчки, а больший объем, то у нас в этом же классе надо очень долго скроллить или искать, для того чтобы добраться до конкретных описаний. До этого все было красиво: в одном месте описание базы, декларативное, описание схем, в другом месте бизнес-логика. А тут схема загромождена.
Но, зато, мы сразу получаем механизмы алхимии: unit of work, позволяющий отслеживать, какие объекты грязные и какие релейшены нужно обновить; получаем relationship, позволяющие избавиться от дополнительных вопросов в базу данных, не следя за тем, чтобы соответствующие коллекции были наполнены; и identity map, который нам больше всего помог. Identity map гарантирует, что два питоновских объекта будут одними и тем же питоновским объектом, если у них совпадает первичный ключ.
Соответственно, у нас сразу же понизилась сложность до линейной.

Это промежуточные результаты. Быстродействие сразу же увеличилось в 10 раз, количество запросов в базу данных упало примерно в 40-80 раз и RPS поднялся до 1-5. Ну, хорошо. Но API то грязный. Что делать?
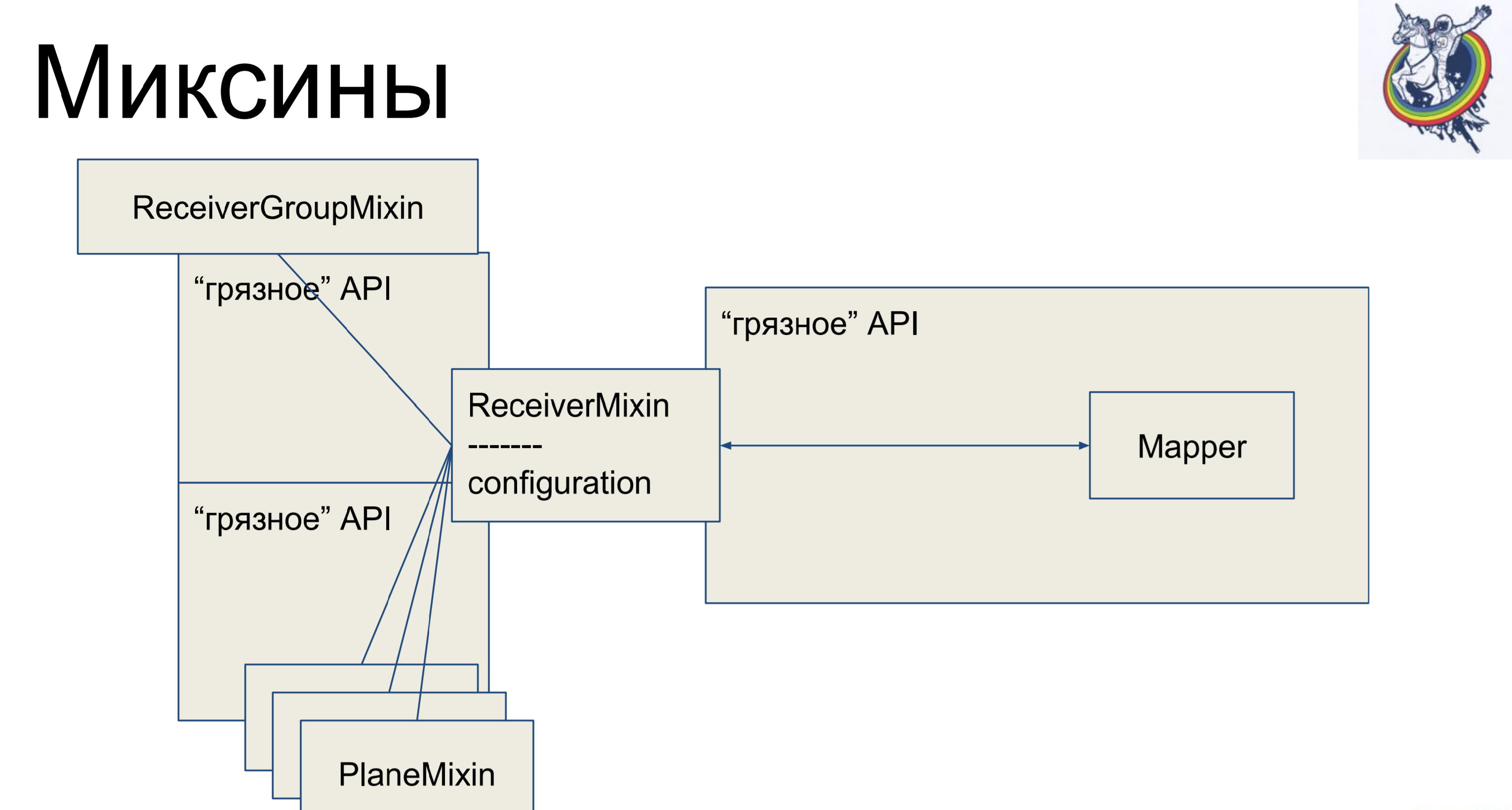
Миксины. Берем бизнес-логику, опять выносим ее из нашего мэппера но, чтобы опять не было мэппинга, мы наш мэппер внутри алхимии унаследуем от нашего миксина. Почему не в обратную сторону? В алхимии так не получится, она ругнется и скажет: «У тебя на одну табличку ссылается два разных класса, нет никакого полиформизма — иди отсюда». А так — можно.
Таким образом, у нас есть декларативное описание в мэппере, которое отнаследовано от миксина и получает всю бизнес-логику. Очень удобно. И остальные классы точно так же. Казалось бы — круто же, все чисто. Но есть один нюанс — связи и релейшены остаются внутри алхимии, а когда у нас есть, допустим, join через промежуточную табличку secondary table, то мэппер этой таблички каким-то образом будет присутствовать в клиентском коде, что не очень красиво.
Алхими бы не была таким хорошим, известным, фреймворком если бы не давала возможности побороться с этим.

Как выглядит миксин. У него бизнес-логика, мэпперы отдельно, декларативное описание таблички. Связи остаются внутри алхимии, но бизнес-логика отделена.
Как выглядит общая схема?
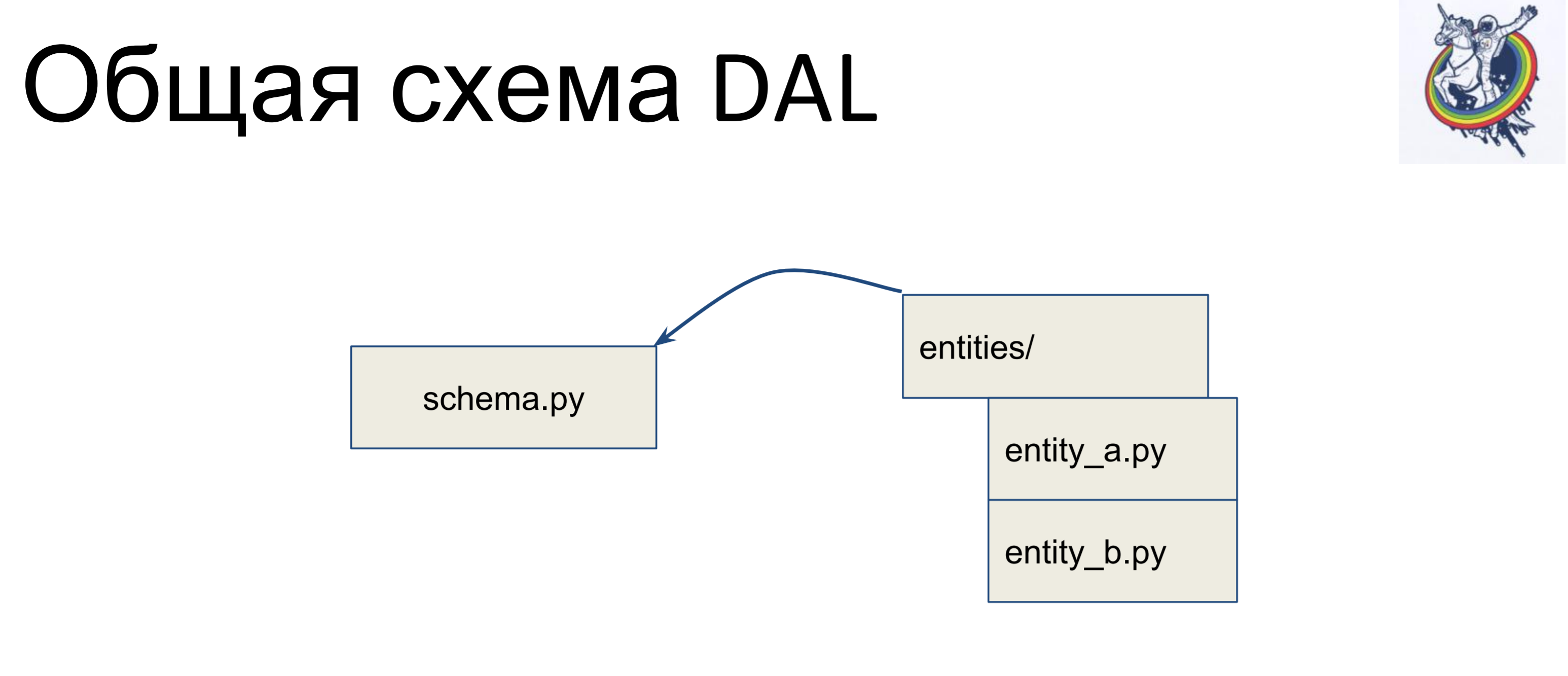
У нас есть файл со схемой, в которой собраны все наши декларативные классы — назовем ее schema.py. И у нас есть сущности в бизнес-логике, отдельно. И, данные сущности наследуются внутри файла схемы — мы для каждой entity пишем отдельный класс, и наследуем его в схеме. Таким образом, бизнес-логика лежит в одной кучке, схема — в другой и их можно независимо менять.
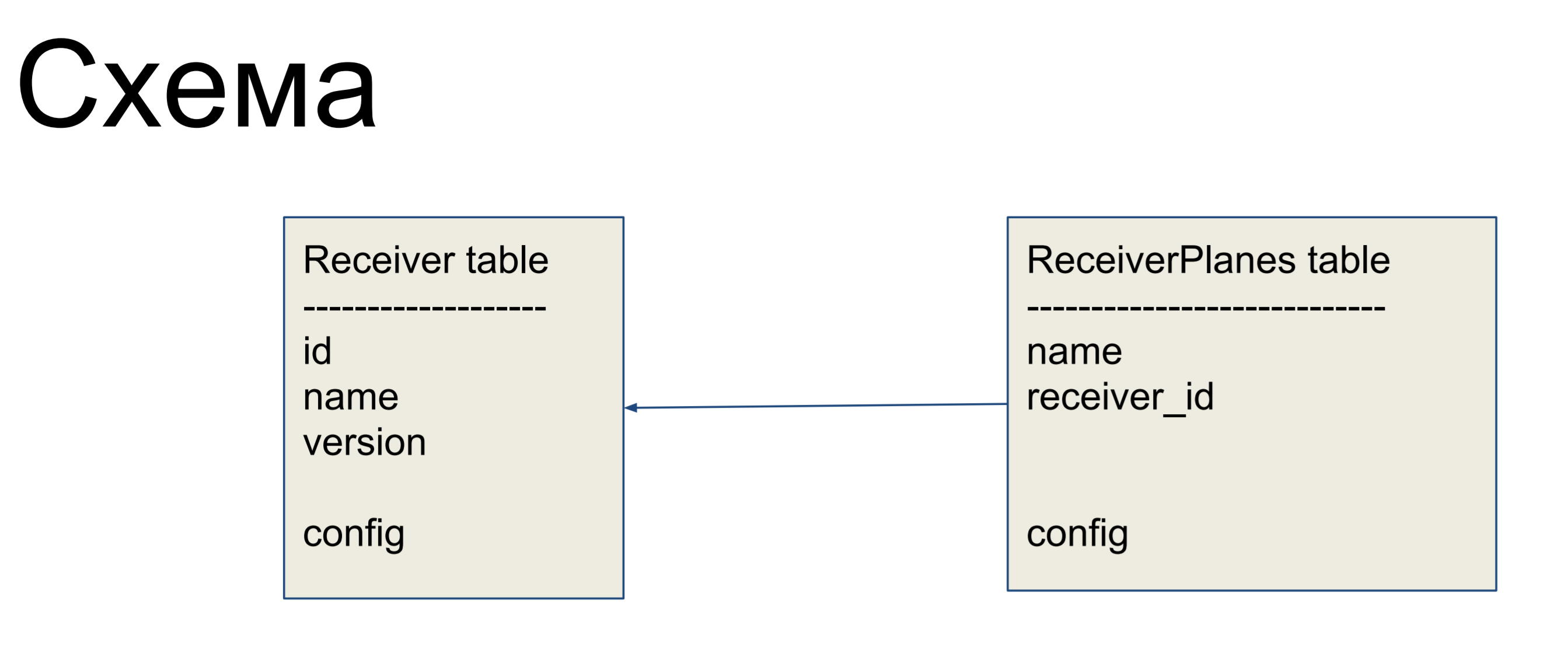
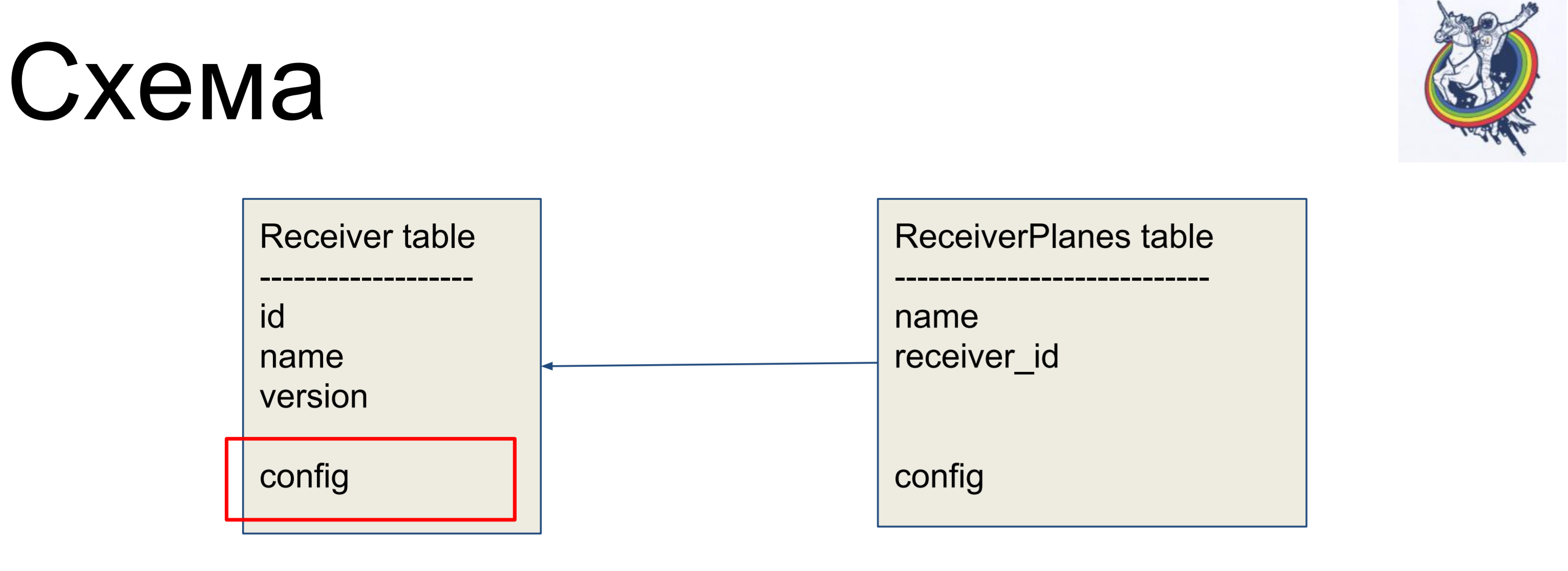
В качестве примера улучшения мы будем рассматривать простую схему из двух табличек: приемники (Receiver table) и срезы конфигурации (ReceiverPlanes table). Срезы конфигурации отношением «многие к одному» связаны с табличкой приемников. Особенно сложного ничего нет.
Для того, чтобы скрыть отношения внутри «грязного» интерфейса алхимии, мы используем отношения и коллекции.

Они позволяют спрятать наши мэпперы от клиентского кода.

В частности, две очень полезные коллекции это association_proxy и attribute_mapped_collection. Мы их применяем вместе. Как работает классическое отношение в алхимии: у нас есть relationship — это некая коллекция, список, мэпперов. Мэпперов объектов дальнего конца отношения. Attribute_mapped_collection позволяет заменить этот список на дикт, ключами в котором будут какие-то из атрибутов мэпперов, а значениями являются сами мэпперы.
Это первый шаг.
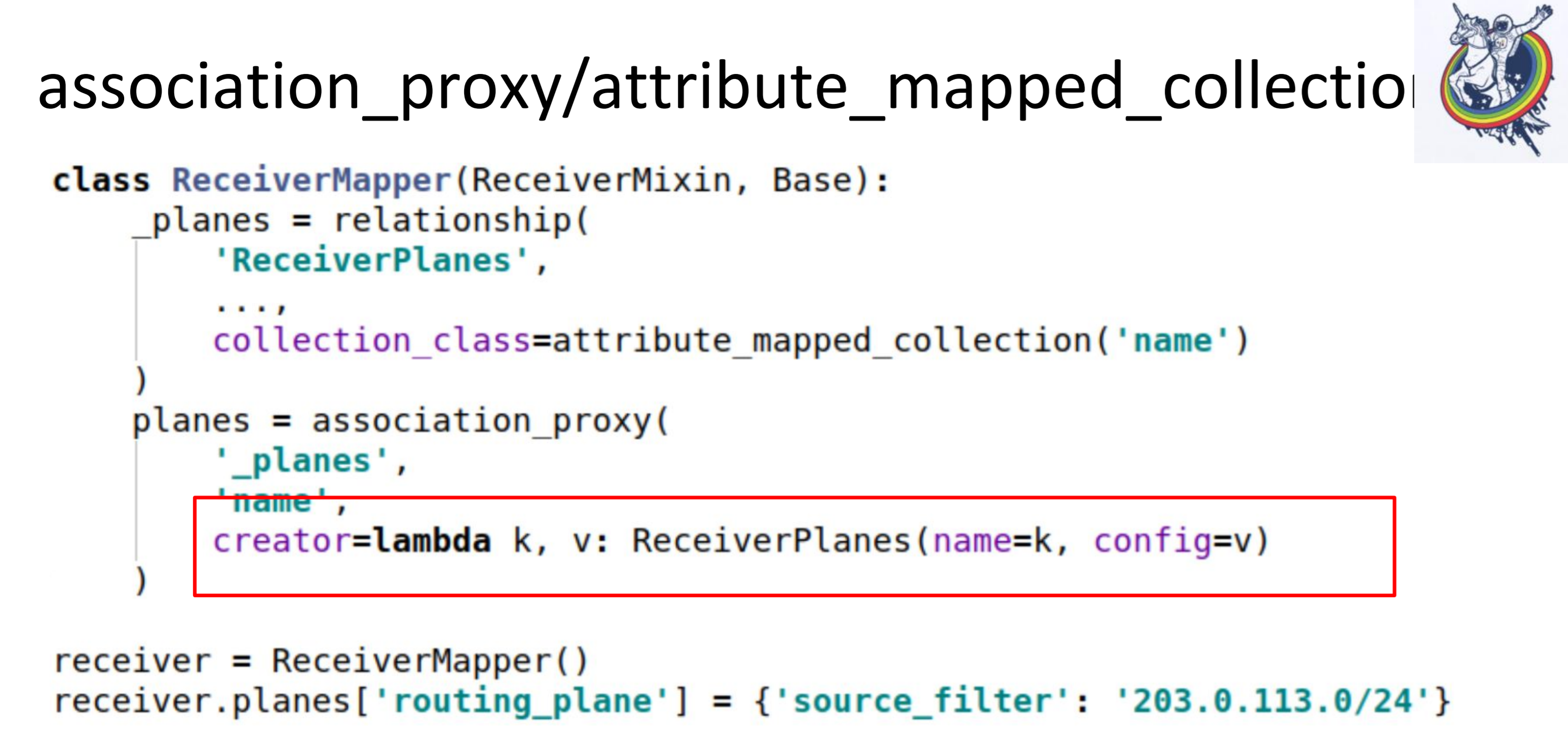
Вторым шагом, мы делаем association_proxy над этим отношением. Он позволяет нам не передавать мэппер в коллекцию, а передавать какое-то значение, которое после будет использовано для инициализации нашего мэппера, ReceiverPlanes.
Тут у нас lambda, в которой мы передаем ключ и значение. Ключ превращается в имя среза конфигурации, а значение — в значение среза конфигурации. В итоге, в клиентском коде, все выглядит вот так.

Мы просто в какой-то словарь кладем какой-то дикт. Все работает: никаких мэпперов, никакой алхимии, никаких баз данных.
Правда, есть подводные камни.

Если мы два раза одному ключу присваиваем разные, или даже одно, значения — на каждый такой set item вызывается lambda, создается объект — мэппер. И, в зависимости от того, как устроена схема это может привести к разным последствиям, от «просто нарушений констрейнтов», до непредсказуемых последствий. Например, вы вроде объект удалили из коллекции, а он там все-равно остался: вы удалили только один. Когда я только начинал, на такие вещи я убил уйму времени.
И немного неявная синхронизация. Association_proxy и attribute_mapped_collection могут немного задерживаться: когда мы создаем объект мэппера — он добавляется в базу данных, но при этом он еще не присутствует в атрибуте коллекции. Он появится там только тогда, когда атрибут истечет (expire) в этой сессии. Когда он экспайрится, произойдет новая синхронизация с базой данных и он туда попадет.
Чтобы с этим побороться мы применяли собственные, самописные, коллекции. Это даже не алхимия — можно просто создать свою коллекцию, чтобы все это побороть.
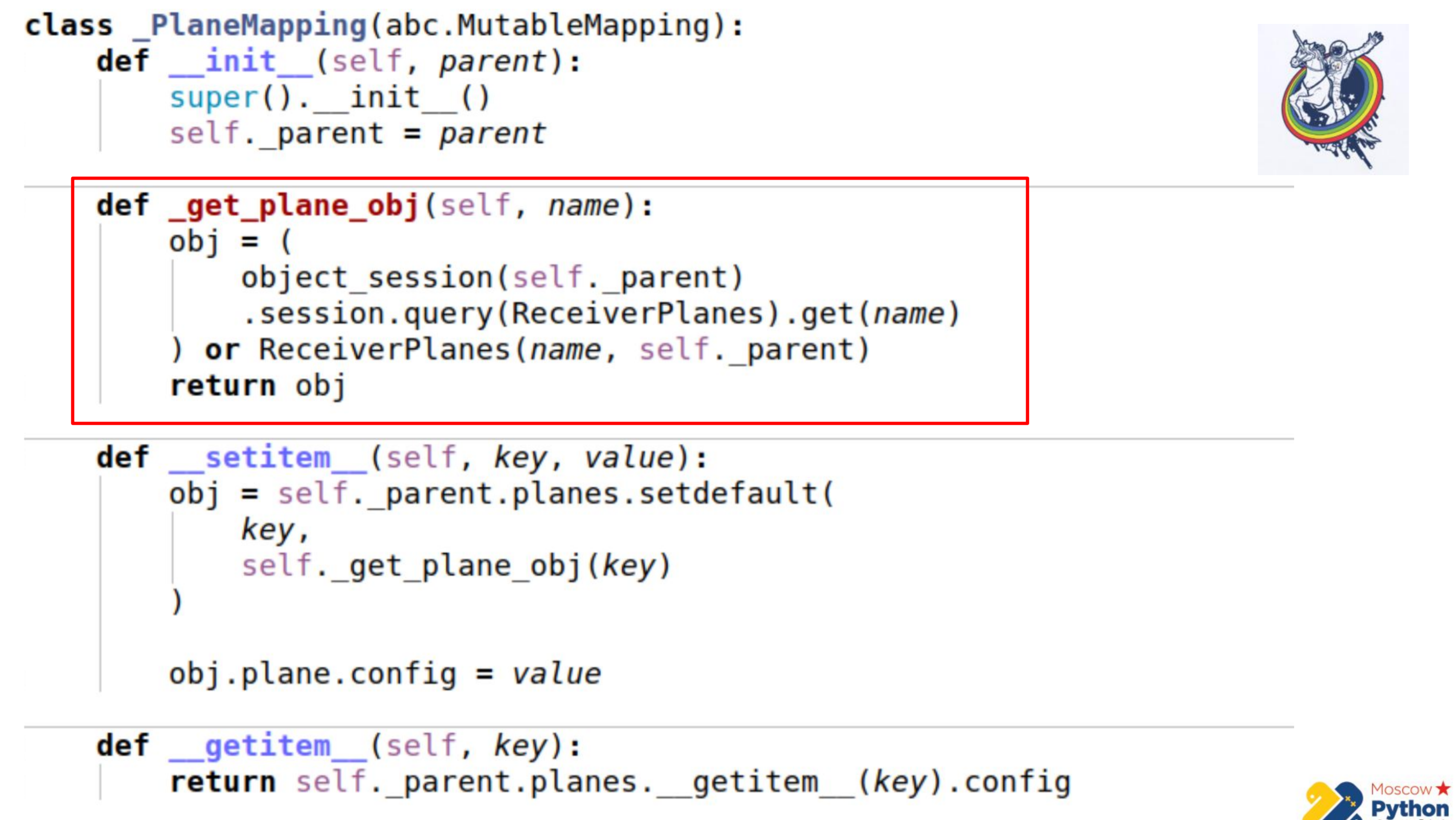
Тут побольше кода и выделен самый важный участок. У нас есть некая коллекция, которая наследует от мьютэбл мэппинга — это дикт, в ключах которого можно менять значения. И есть метод _get_plane_obj — получить объект среза конфигурации.
Тут мы делаем простые вещи — пытаемся получить его по имени, по какому-нибудь первичному ключу и, если его нет, то мы создаем и возвращаем этот объект.
Далее мы переопределяем всего два метода: __setitem__ и __getitem__
В __setitem__ мы складываем эти объекты в нашу коллекцию, в relationship. Единственное — значение мы присваиваем в самом конце. Таким образом, мы осуществляем тот же механизм, что и association_proxy — передаем туда значение, дикт, и он присваивается соответствующему атрибуту.
__getitem__ делает обратную манипуляцию. Он получает по ключу какой-то объект у релейшена и возвращает его атрибут. Здесь также присутствует небольшой подводный камень — если закешировать коллекцию внутри нашего мэппинга, то возможно немного рассинхронизироваться. Потому что когда у алхимии экспайрится атрибут коллекции, то коллекция заменяется на другую, после истечения. Поэтому мы можем сохранить референс на старую коллекцию и не знать, что старая истекла и уже появилась новая. Поэтому мы в последней части мы идем прямо к инстансу алхимии, опять получаем коллекцию через __getattr__ и у нее делаем __getitem__. То есть, коллекцию Planes мы здесь не можем закешировать.
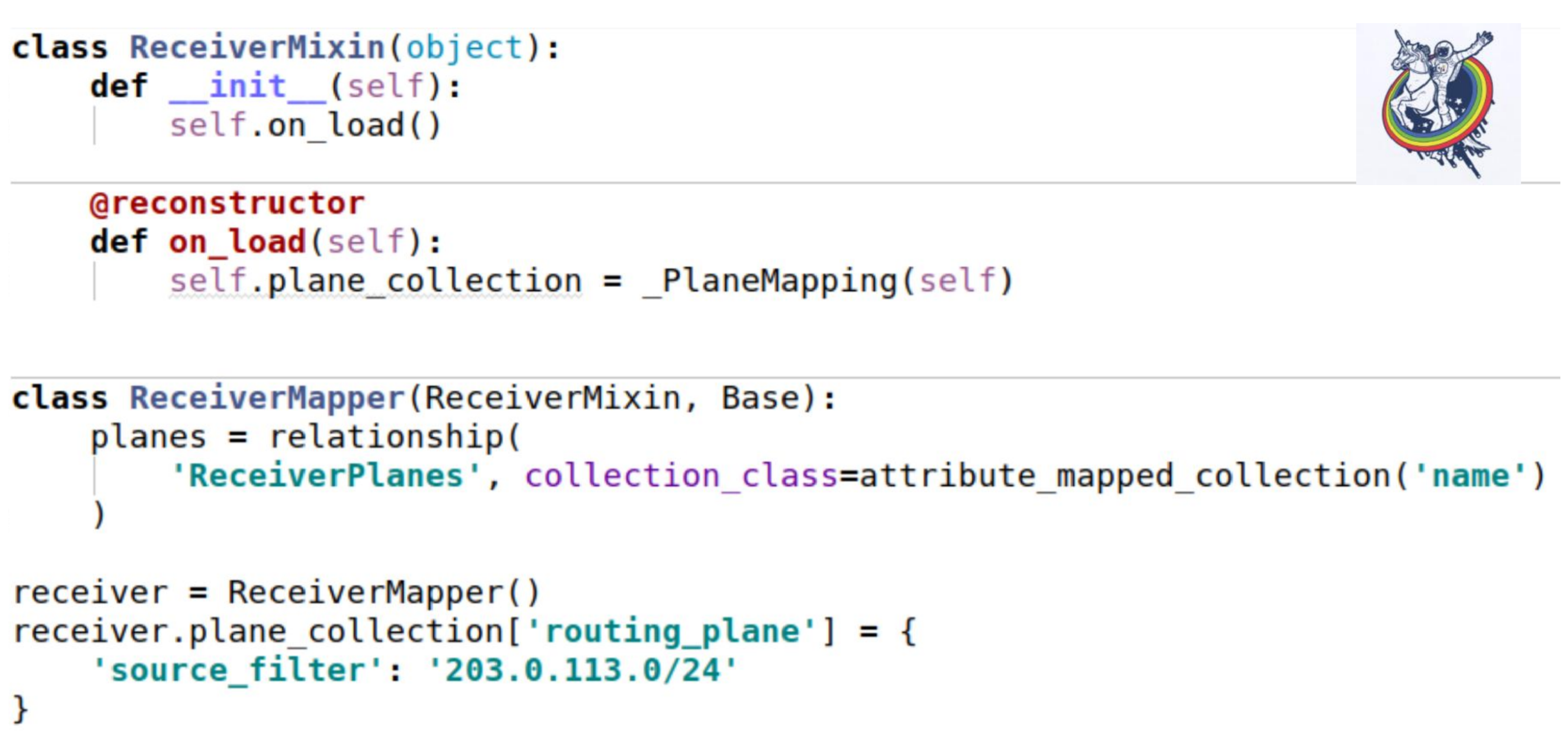
Как эта коллекция пришлепывается на наши миксины? Как обычно — заводим атрибут коллекции. Единственное интересное место заключается в том, что когда мы загружаем инстанс из базы, метод __init__ не вызывается. Все атрибуты подставляются постфактум.
Алхимия дает стандартный декоратор reconstructor, который позволяет какой-то метод пометить как вызывающийся после загрузки объекта из базы. И как раз во время загрузки мы должны инициализировать нашу коллекцию. Self — как раз этот инстанс. Использование точно такое же, как в предыдущем примере.
Но у нас в схеме все еще остались видны уши базы данных — это конфигурация. Какого типа конфигурация? Это varchar или это блоб? На самом деле, клиенту это не интересно. Он должен работать с абстрактными сущностями своего уровня. Для этого в алхимии предусмотрено декорирование типов.

Простой примерчик. В нашей базе хранится IPAddress в виде varchar’а. Мы используем класс TypeDecorator, входящий в алхимию, который позволяет, во-первых, указать какой нижележащий тип базы данных будет использоваться для данного типа и, во-вторых, определить два параметра: process_bind_param преобразующий значение к типу базы данных и process_result_value, когда мы значение от типа базы данных преобразуем в питоновский объект.
Атрибут от address приобретает как бы питоновский тип IPAddress. И мы можем как вызывать методы этого типа, так и присваивать ему объекты этого типа и у нас все работает. А в базе хранится… не знаю что хранится, varchar(45), а можем заменить ту строчку и будет хранится блоб. Или если какой-то нативный тип поддерживает IP-адреса, то можно и его использовать.
Клиентский код от этого никак не зависит, его не нужно переписывать.
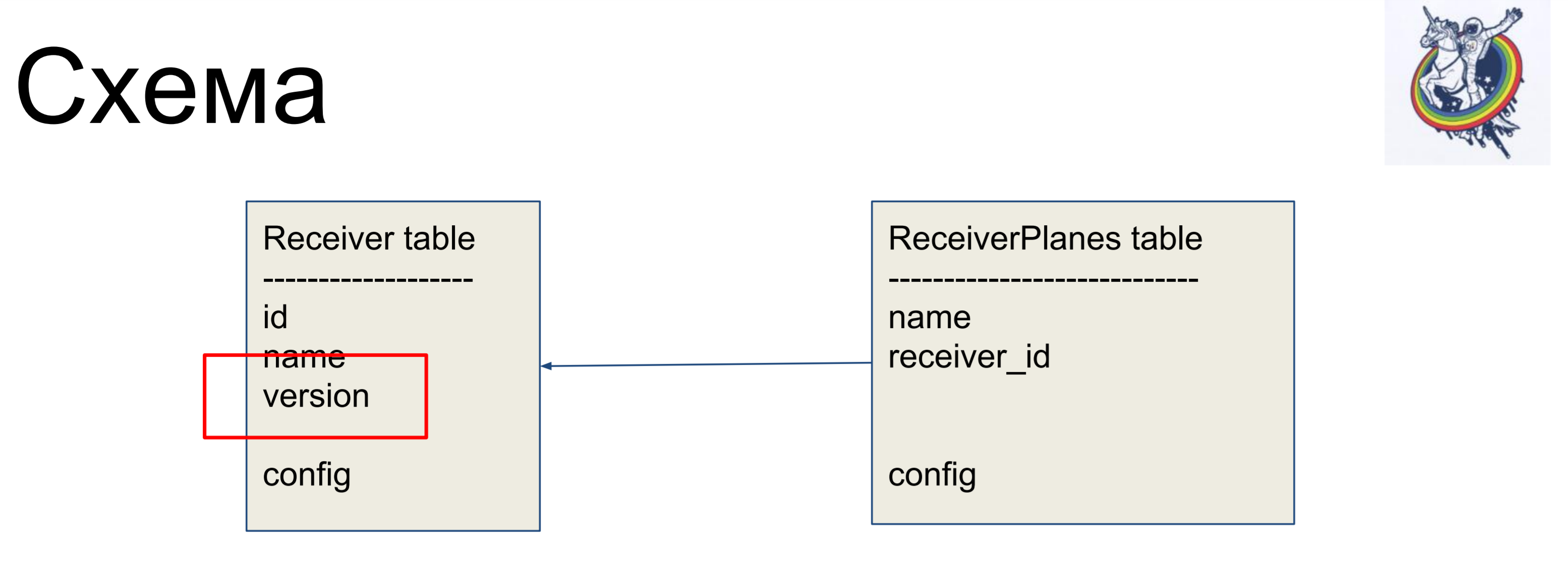
Еще одна интересная вещь — у нас есть версия. Мы хотим, чтобы как только мы поменяли наш объект, версию сразу увеличить. Какой-то счетчик версий у нас есть, мы объект поменяли — он поменялся, версия увеличилась. Делаем мы это автоматически, чтобы не забыть.

Для этого мы применяли эвенты. Эвенты — это события, возникающие на разных этапах жизни мэппера и они могут вызываться при изменении атрибутов, при переходе сущности из одного состояния в другое, например «создано», «сохранено в базу», «загружено из базы», «удалено»; а также — при событиях уровня сессии, перед тем, как sql-код эмитируется в базу данных, перед коммитом, после коммита, также после роллбэка.
Алхимия позволяет нам назначать хэндлеры для всех этих событий, но порядок выполнения хэндлеров для одного и того же события не гарантирован. То есть он определенный, но неизвестно какой. Поэтому, если вам важен порядок выполнения, то нужно делать механизм регистрации.
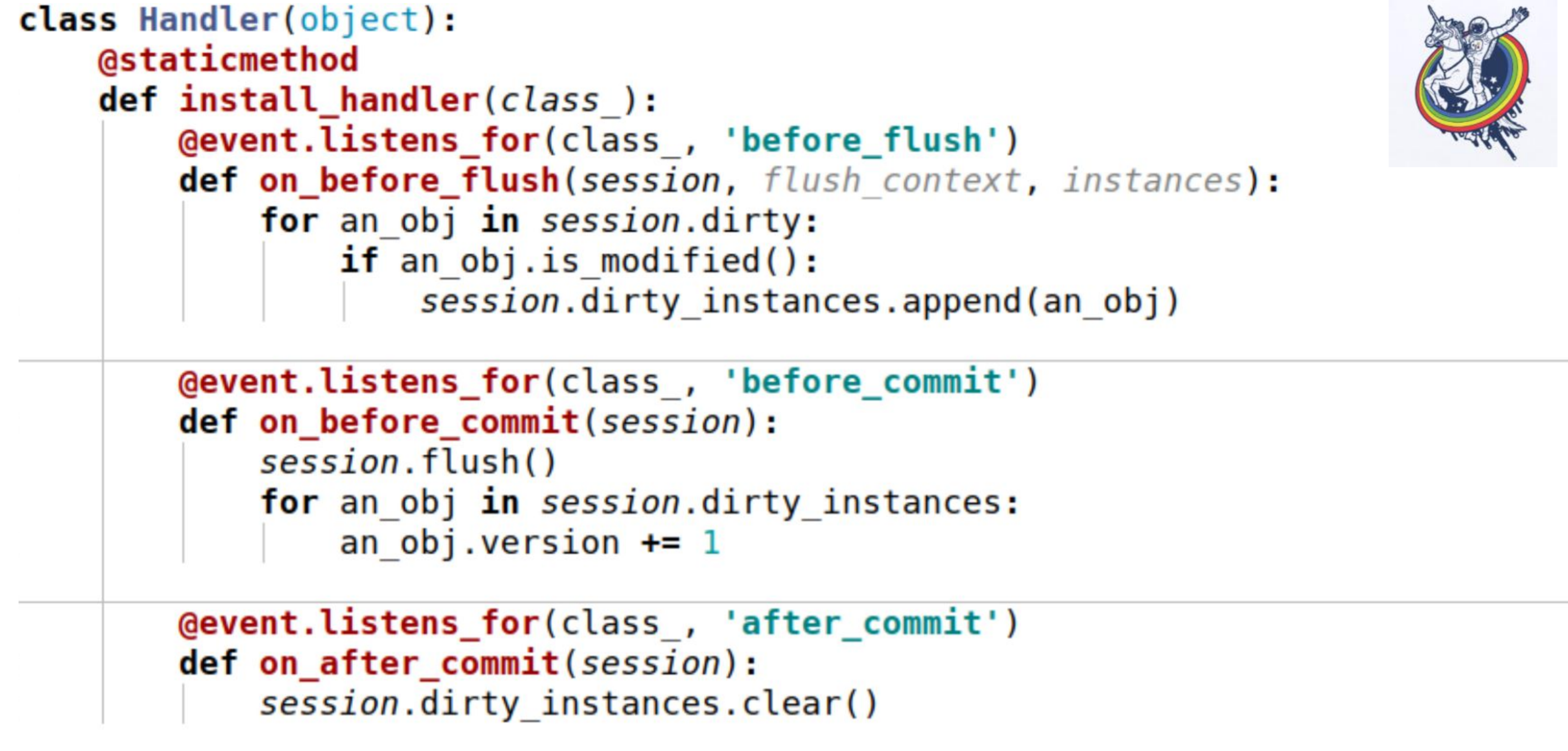
Вот пример. Здесь используется три события:
on_before_flush — перед тем, как sql-код будет эмитирован в базу данных, мы проходим по всем объектам, которые алхимия пометила как грязные в этой сессии и проверяем, модифицирован этот объект или нет. Зачем это нужно, если алхимия уже все пометила? Алхимия помечает объект грязным, как только изменился какой-то атрибут. Если мы присвоили этому атрибуту то же самое значение, которое у него было — он будет помечен как грязный. Для этого есть метод сессии is_modified — он используется внутри, я его не нарисовал. Далее, с точки зрения нашей семантики, с точки зрения нашей бизнес-логики, даже если атрибут изменился — объект все-равно может оставаться не модифицированным. Например, есть некий список, два элемента в котором поменяли местами — с точки зрения алхимии, атрибут изменился, но для бизнес-логики не важно, если в этом списке хранится, допустим, какое-то множество.
И, в итоге, мы вызываем еще один метод, специфический для каждого объекта, чтобы понять модифицирован объект действительно или нет. И добавляем их в некую переменную, связанную с сессией, которую мы завели сами — это наша переменная dirty_instances, в которую мы добавляем этот объект.
Следующее событие происходит перед коммитом — before_commit. Тут тоже есть небольшой подводный камень: если за всю транзакцию у нас не было ни одного flush’а, то flush вызовется перед коммитом — в моем случае хэндлер перед коммитом вызывался до flush.
Как видите, то, что мы проделали в предыдущем пункте нам может не помочь и session.dirty_instances будет пустой. Поэтому внутри хэндлера мы еще раз делаем flush, чтобы вызвались все хэндлеры перед flush’ем и просто инкрементируем версию на один.
after_commit, after_soft_rollback — после коммита просто чистим, чтобы в следующие разы не было никаких эксцессов.
Таким образом, вы видите — этот метод install_handler устанавливает обработчики сразу для трех событий. В качестве класса мы передаем сюда сессию, так как это событие ее уровня.

Ну вот. Я вам напомню, чего мы достигли — быстродействие 30-40 секунд на сложные и большие команды. Не на все, какие-то выполнялись за секунду, другие за 200 миллисекунд, как вы видите по RPS. Запросы в БД стали исчисляться сотнями.

В итоге получилась довольно сбалансированная система. Был, правда, один нюанс. Некоторые запросы у нас приходят пачками, выбросами. То есть прилетает штук 30 запросов и каждый из них — вот такой! (выступающий показывает большой палец)
Если мы их обрабатываем по одной секунде, то последний запрос в очереди будет работать 30 секунд. Первый — одну, второй — две и так далее.

Поэтому нам нужно еще ускориться. Что будем делать?
На самом деле, алхимия состоит из двух частей. Первая — это абстракция над sql базой данных, которая называется SQLAlchemy Сore. Вторая — это ORM, собственно мэппинг между реляционной базой данных и объектным представлением. Соответственно, alchemy core примерно один к одному совпадает с sql — если вы знаете последний, то проблем с core у вас не возникнет. Если вы не знаете sql — выучите sql.
Кроме этого, core представляет наименьший оверхэд. Нет практически никакой накачки — запросы генерируются с помощью генератора запросов, а после исполняются. Оверхэд над dbapi минимальный.
Запросы мы можем строить любой сложности, любого типа, можем оптимизировать их под задачу. То есть, если в общем случае ORM все равно, как у нас построена схема базы данных — есть некое описание таблиц, генерирует некие запросы, не зная, что в данном случае будет, например, оптимально выселектить отсюда, в другом — оттуда, тут такой фильтр применить, а там — другой, то тут мы можем запросы сделать под задачу.
Недостаток такой, что мы опять пришли к ручной синхронизации. Все эвенты, релейшены — все это в core не работает. Мы сделали селект, нам пришли объекты, мы с ними что-то сделали, потом апдейт, инсерт… версию надо руками инкрементить, констрейнты самостоятельно проверять. Core не позволяет все это сделать удобно, на высоком уровне.
Ну, мы не первый день живем.

Простой пример использования. Каждый мэппер внутри себя содержит объект __table__, который используется в core. Далее вы видите — берем обычный селект, перечисляем колонки, джойним две таблички, указываем левую и правую, указываем по какому условию мы ее джойним, ну и для вкуса добавляем ордер бай. Дальше мы этот сформированный запрос скармливаем в сессию и она нам возвращает iterable, в котором тапл-лайк объекты индексируемые как по названию колонки, так и по номеру. Номер соответствует тому порядку, по которому они перечислены в селекте.

Стало значительно лучше. Быстродействие в самом худшем случае упало до 2-4 секунд, самый сложный и самый длинный запрос содержал 14 команд и RPS 10-15. Солидно.

Что бы хотелось сказать в заключение.
Не плодите сущности там, где они не нужны — не наворачивайте свое там, где есть готовое.
Используйте SQLA ORM — это очень удобный инструмент, позволяющий отслеживать события на высоком уровне, реагировать на различные события, связанные с базой данных, спрятать все уши алхимии.
Если ничего не помогает, быстродействия не хватает — используйте SQLA Core. Это все еще лучше, чем использовать чистый raw SQL, потому что оно предоставляет именно реляционную абстракцию над базой данных. Автоматически эскейпит параметры, правильно делает биндинги, ей не важно, какая под ней база данных — можно менять и Core поддерживает разные диалекты. Это очень удобно.
Вот и все, что я вам хотел сегодня рассказать.
