
Несколько месяцев назад в ходе работы над очередным проектом, ребята из нашей исследовательской лаборатории проводили исследование NVMe-дисков и софтверных решений, с целью найти оптимальный вариант для сборки программного массива.
Результаты тестов тогда были удивительно обескураживающими — огромный потенциал скорости NVMe-дисков совершенно не соотносился с демонстрируемой производительностью имеющихся программных продуктов.
Нашим разработчикам это не понравилось. И они решили написать свой продукт… Продукт, которому маркетологи впоследствии радостно придумали название RAIDIX ERA.
Сегодня более десятка компаний выпускают сервера, адаптированные для использования NVMe накопителей. Рынок продуктов, поддерживающих и развивающих эту технологию, имеет огромный потенциал. В аналитическом отчете G2M представлены достаточно убедительные цифры, убеждающие в том, что этот протокол передачи данных будет главенствовать в ближайшем обозримом будущем.

Диаграмма из отчета G2M
В настоящий момент одним из лидеров в производстве NVMe компонентов является компания Intel. Именно на их оборудовании мы и проводили тесты, чтобы оценить возможности существующих программных продуктов для управления таким «инновационным» железом.
Совместно с нашим партнером, компанией Промобит (производителем серверов и систем хранения данных под торговой маркой BITBLAZE), мы организовали тестирование интеловских NVMe-накопителей и распространенного программного обеспечения для управления такими устройствами. Тестирование проводили по методике SNIA.
В этом материале мы поделимся цифрами, полученными в ходе тестирования аппаратной NVMe-системы Intel, программных массивов от MDRAID, Zvol поверх ZFS RAIDZ2 и, собственно, нашей новой разработки.
Конфигурация оборудования
За основу тестовой платформы мы взяли серверную систему Intel Server System R2224WFTZS. Она имеет 2 сокета для установки процессоров Intel Xeon Scalable и 12 каналов памяти (24 DIMMs всего) DDR 4 частотой до 2666 MHz.
Более подробную информацию о серверной платформе можно посмотреть на сайте производителя.
Все NVMe-накопители подключили через 3 бэкплейна (backplane) F2U8X25S3PHS.
Всего в системе у нас получилось 12 NVMe-дисков INTEL SSDPD2MD800G4 c прошивкой CVEK6256004E1P0BGN.
Серверная платформа была оснащена двумя процессорами Intel® Xeon® Gold 6130 CPU @ 2.10GHz с включенной функцией Hyper-Threading, позволяющей запускать два потока с каждого ядра. Таким образом, на выходе мы получали 64 вычислительных потока.
Подготовка к тестированию
Все тесты в этой статье выполнялись в соответствии со спецификацией методики SNIA SSS PTSe v 1.1. В том числе, проводилась предварительная подготовка хранилища для того, чтобы получить стабильный и честный результат.
SNIA позволяет пользователю выставлять параметры количества потоков и глубины очереди, поэтому мы выставили 64/32, обладая 64 вычислительными потоками на 32 ядрах.
Каждый тест выполнялся в 16 раундов, чтобы вывести систему на стабильный уровень показателей и исключить случайные значения.
Перед запуском тестов мы сделана предварительная подготовка системы:
- Установка ядра версии 4.11 на CentOS 7.4.
- Выключение C-STATES и P-STATES.
- Запуск утилиты tuned-adm и выставление профиля latency-performance.
Тестирование каждого продукта и элемента проходило у нас по следующим этапам:
Подготовка устройств по спецификации SNIA (зависимая и независимая от типа нагрузки).
- Тест на IOps блоками 4k, 8k, 16k, 32k, 64k, 128k, 1m с вариациями сочетаний чтения и записи 0/100, 5/95, 35/65, 50/50, 65/35, 95/5, 100/0.
- Тесты задержек (latency) c блоками 4k, 8k, 16k с вариациями сочетаний чтения и записи 0/100, 65/35 и 100/0. Количество потоков и глубина очереди 1-1. Результаты фиксируются в виде средней и максимальной величины задержек.
- Тест на пропускную способность (throughtput) с блоками 128k и 1M, в 64 очереди по 8 команд.
Начали мы с того, что провели тестирование производительности, задержек и пропускной способности аппаратной платформы. Это позволило нам оценить потенциал предлагаемого оборудования и сравнить с возможностями применяемых программных решений.
Тест 1. Тестирование аппаратной части
Для начала мы решили посмотреть, на что способен один NVMe-диск Intel DC D3700.
В спецификации производитель заявляет следующие параметры производительности:
Random Read (100% Span) 450000 IOPS
Random Write (100% Span) 88000 IOPS
Тест 1.1 Один NVMe-накопитель. Тест на IOPS
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 84017.8 | 91393.8 | 117271.6 | 133059.4 | 175086.8 | 281131.2 | 390969.2 |
| 8k | 42602.6 | 45735.8 | 58980.2 | 67321.4 | 101357.2 | 171316.8 | 216551.4 |
| 16k | 21618.8 | 22834.8 | 29703.6 | 33821.2 | 52552.6 | 89731.2 | 108347 |
| 32k | 10929.4 | 11322 | 14787 | 16811 | 26577.6 | 47185.2 | 50670.8 |
| 64k | 5494.4 | 5671.6 | 7342.6 | 8285.8 | 13130.2 | 23884 | 27249.2 |
| 128k | 2748.4 | 2805.2 | 3617.8 | 4295.2 | 6506.6 | 11997.6 | 13631 |
| 1m | 351.6 | 354.8 | 451.2 | 684.8 | 830.2 | 1574.4 | 1702.8 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.

На этом этапе мы получили результаты, которые совсем немного не дотягивают до заводских. Скорее всего, свою роль сыграла NUMA (схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору), но пока мы не будем обращать на нее внимание.
Тест 1.2 Один NVMe-накопитель. Тесты задержек
Среднее время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
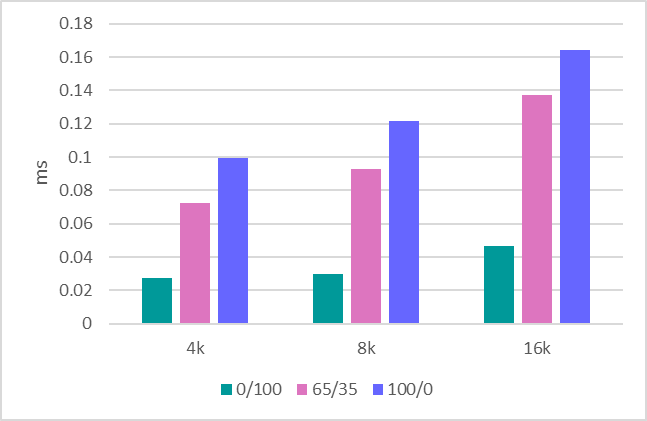
| 4k | 0.02719 | 0.072134 | 0.099402 |
| 8k | 0.029864 | 0.093092 | 0.121582 |
| 16k | 0.046726 | 0.137016 | 0.16405 |
Среднее время отклика (ms) в графическом виде. Read / Write Mix %.
Максимальное время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
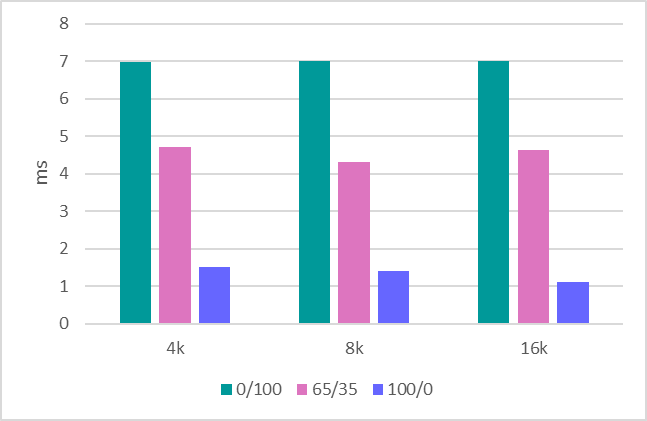
| 4k | 6.9856 | 4.7147 | 1.5098 |
| 8k | 7.0004 | 4.3118 | 1.4086 |
| 16k | 7.0068 | 4.6445 | 1.1064 |
Максимальное время отклика (ms) в графическом виде. Read / Write Mix %.
Тест 1.3 Пропускная способность
Заключительный этап — оценка пропускной способности. Здесь получились вот такие показатели:
1MБ последовательная запись — 634 MBps.
1MБ последовательное чтение — 1707 MBps.
128Kб последовательная запись — 620 MBps.
128Kб последовательное чтение — 1704 MBps.
Разобравшись с одним диском, мы переходим к оценке всей платформы целиком, которая состоит у нас из 12 накопителей.
Тест 1.4 Система в 12 накопителей. Тест на IOPS
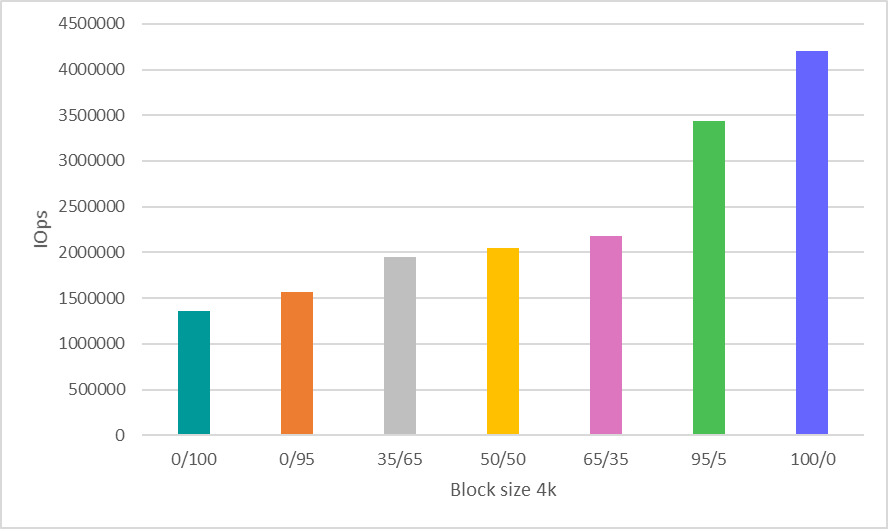
Здесь было принято волевое решение сэкономить время и показать результаты только для работы с блоком 4k, который на сегодняшний день является наиболее распространенным и показательным сценарием оценки производительности.
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 1363078.6 | 1562345 | 1944105 | 2047612 | 2176476 | 3441311 | 4202364 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.
Тест 1.5 Система в 12 накопителей. Тесты пропускной способности
1MБ последовательная запись — 8612 MBps.
1MБ последовательное чтение — 20481 MBps.
128Kб последовательная запись — 7500 MBps.
128Kб последовательное чтение — 20400 MBps.
На полученные показатели производительности «железа» мы еще раз посмотрим в конце статьи, сравнивая их с цифрами тестируемого на нем программного обеспечения.
Тест 2. Тестирование MDRAID
Когда мы говорим о программном массиве, то первым на ум приходит MDRAID. Напомним, это базовый программный RAID для Linux, который распространяется совершенно бесплатно.
Посмотрим, как MDRAID справится с предложенной ей системой из 12 дисков при уровне массива RAID 0. Мы все прекрасно понимаем, что построение RAID 0 на 12 дисках требует особой храбрости, но сейчас нам такой уровень массива нужен для демонстрации максимальных возможностей этого решения.
Тест 2.1 MDRAID. RAID 0. Тест на IOPS
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 1010396 | 1049306.6 | 1312401.4 | 1459698.6 | 1932776.8 | 2692752.8 | 2963943.6 |
| 8k | 513627.8 | 527230.4 | 678140 | 771887.8 | 1146340.6 | 1894547.8 | 2526853.2 |
| 16k | 261087.4 | 263638.8 | 343679.2 | 392655.2 | 613912.8 | 1034843.2 | 1288299.6 |
| 32k | 131198.6 | 130947.4 | 170846.6 | 216039.4 | 309028.2 | 527920.6 | 644774.6 |
| 64k | 65083.4 | 65099.2 | 85257.2 | 131005.6 | 154839.8 | 268425 | 322739 |
| 128k | 32550.2 | 32718.2 | 43378.6 | 66999.8 | 78935.8 | 136869.8 | 161015.4 |
| 1m | 3802 | 3718.4 | 3233.4 | 3467.2 | 3546 | 6150.8 | 8193.2 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.

Тест 2.2 MDRAID. RAID 0. Тесты задержек
Среднее время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 0.03015 | 0.067541 | 0.102942 |
| 8k | 0.03281 | 0.082132 | 0.126008 |
| 16k | 0.050058 | 0.114278 | 0.170798 |
Среднее время отклика (ms) в графическом виде. Read / Write Mix %.

Максимальное время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 6.7042 | 3.7257 | 0.8568 |
| 8k | 6.5918 | 2.2601 | 0.9004 |
| 16k | 6.3466 | 2.7741 | 2.5678 |
Максимальное время отклика (ms) в графическом виде. Read / Write Mix %.

Тест 2.3 MDRAID. RAID 0. Тесты пропускной способности
1MБ последовательная запись — 7820 MBPS.
1MБ последовательное чтение — 20418 MBPS.
128Kб последовательная запись — 7622 MBPS.
128Kб последовательное чтение — 20380 MBPS.
Тест 2.4 MDRAID. RAID 6. Тест на IOPS
Давайте теперь посмотрим, что получается у этой системы на уровне RAID 6.
Параметры создания массива
mdadm --create --verbose --chunk 16K /dev/md0 --level=6 --raid-devices=12 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 /dev/nvme4n1 /dev/nvme5n1 /dev/nvme8n1 /dev/nvme9n1 /dev/nvme10n1 /dev/nvme11n1 /dev/nvme6n1 /dev/nvme7n1
Суммарный объем массива составил 7450.87 GiB.
Запускаем тест после предварительной инициализации RAID-массива.
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 39907.6 | 42849 | 61609.8 | 78167.6 | 108594.6 | 641950.4 | 1902561.6 |
| 8k | 19474.4 | 20701.6 | 30316.4 | 39737.8 | 57051.6 | 394072.2 | 1875791.4 |
| 16k | 10371.4 | 10979.2 | 16022 | 20992.8 | 29955.6 | 225157.4 | 1267495.6 |
| 32k | 8505.6 | 8824.8 | 12896 | 16657.8 | 23823 | 173261.8 | 596857.8 |
| 64k | 5679.4 | 5931 | 8576.2 | 11137.2 | 15906.4 | 109469.6 | 320874.6 |
| 128k | 3976.8 | 4170.2 | 5974.2 | 7716.6 | 10996 | 68124.4 | 160453.2 |
| 1m | 768.8 | 811.2 | 1177.8 | 1515 | 2149.6 | 4880.4 | 5499 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.

Тест 2.5 MDRAID. RAID 6. Тесты задержек
Среднее время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 0.193702 | 0.145565 | 0.10558 |
| 8k | 0.266582 | 0.186618 | 0.127142 |
| 16k | 0.426294 | 0.281667 | 0.169504 |
Среднее время отклика (ms) в графическом виде. Read / Write Mix %.

Максимальное время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 6.1306 | 4.5416 | 4.2322 |
| 8k | 6.2474 | 4.5197 | 3.5898 |
| 16k | 5.4074 | 5.5861 | 4.1404 |
Максимальное время отклика (ms) в графическом виде. Read / Write Mix %.

Стоит отметить, что здесь MDRAID показал очень неплохой уровень задержек.
Тест 2.6 MDRAID. RAID 6. Тесты пропускной способности
1MБ последовательная запись — 890 MBPS.
1MБ последовательное чтение — 18800 MBPS.
128Kб последовательная запись — 870 MBPS.
128Kб последовательное чтение — 10400 MBPS.
Тест 3. Zvol поверх ZFS RAIDZ2
ZFS имеет встроенную функцию создания RAID и встроенный менеджер томов, который создает виртуальные блочные устройства, чем и пользуются многие производители СХД. Мы тоже воспользуемся этими функциями, создав пул с защитой RAIDZ2 (аналог RAID 6) и виртуальный блочный том поверх него.
Была собрана версия 0.79 (ZFS). Параметры создания массива и тома:
ashift=12 / compression – off / dedup – off / recordsize=1M / atime=off / cachefile=none / Тип RAID = RAIDZ2
ZFS показывает очень хорошие результаты при только что созданном пуле. Однако при многократных перезаписях, показатели производительности значительно снижаются.
Подход SNIA тем и хорош, что позволяет увидеть реальные результаты от тестирования подобных файловых систем (той, которая в основе ZFS) после многократных перезаписей на них.
Тест 3.1 ZVOL (ZFS). RAIDZ2. Тест на IOps
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 15719.6 | 15147.2 | 14190.2 | 15592.4 | 17965.6 | 44832.2 | 76314.8 |
| 8k | 15536.2 | 14929.4 | 15140.8 | 16551 | 17898.8 | 44553.4 | 76187.4 |
| 16k | 16696.6 | 15937.2 | 15982.6 | 17350 | 18546.2 | 44895.4 | 75549.4 |
| 32k | 11859.6 | 10915 | 9698.2 | 10235.4 | 11265 | 26741.8 | 38167.2 |
| 64k | 7444 | 6440.2 | 6313.2 | 6578.2 | 7465.6 | 14145.8 | 19099 |
| 128k | 4425.4 | 3785.6 | 4059.8 | 3859.4 | 4246.4 | 7143.4 | 10052.6 |
| 1m | 772 | 730.2 | 779.6 | 784 | 824.4 | 995.8 | 1514.2 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.

Цифры производительности получаются совсем невпечатляющие. При этом чистый zvol (до перезаписей) дает значительно лучшие результаты (в 5-6 раз выше). Здесь же тест показал, что после первой же перезаписи производительность падает.
Тест 3.2 ZVOL (ZFS). RAIDZ2. Тесты задержек
Среднее время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 0.332824 | 0.255225 | 0.218354 |
| 8k | 0.3299 | 0.259013 | 0.225514 |
| 16k | 0.139738 | 0.180467 | 0.233332 |
Среднее время отклика (ms) в графическом виде. Read / Write Mix %.

Максимальное время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 90.55 | 69.9718 | 84.4018 |
| 8k | 91.6214 | 86.6109 | 104.7368 |
| 16k | 108.2192 | 86.2194 | 105.658 |
Максимальное время отклика (ms) в графическом виде. Read / Write Mix %.

Тест 3.3 ZVOL (ZFS). RAIDZ2. Тесты пропускной способности
1MБ последовательная запись — 1150 MBPS.
1MБ последовательное чтение — 5500 MBPS.
128Kб последовательная запись — 1100 MBPS.
128Kб последовательное чтение — 5300 MBPS.
Тест 4. RAIDIX ERA
Давайте теперь посмотрим на тесты нашего нового продукта — RAIDIX ERA.
Мы создали RAID6. Размер страйпа: 16kb. После завершения инициализации запускаем тест.
Результат производительности (IOps) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 354887 | 363830 | 486865.6 | 619349.4 | 921403.6 | 2202384.8 | 4073187.8 |
| 8k | 180914.8 | 185371 | 249927.2 | 320438.8 | 520188.4 | 1413096.4 | 2510729 |
| 16k | 92115.8 | 96327.2 | 130661.2 | 169247.4 | 275446.6 | 763307.4 | 1278465 |
| 32k | 59994.2 | 61765.2 | 83512.8 | 116562.2 | 167028.8 | 420216.4 | 640418.8 |
| 64k | 27660.4 | 28229.8 | 38687.6 | 56603.8 | 76976 | 214958.8 | 299137.8 |
| 128k | 14475.8 | 14730 | 20674.2 | 30358.8 | 40259 | 109258.2 | 160141.8 |
| 1m | 2892.8 | 3031.8 | 4032.8 | 6331.6 | 7514.8 | 15871 | 19078 |
Результат производительности (IOps) в графическом виде. Read / Write Mix %.

Тест 4.2 RAIDIX ERA. RAID 6. Тесты задержек
Среднее время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
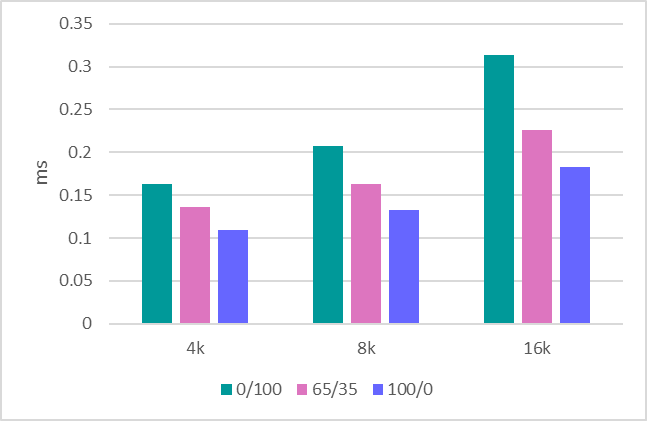
| 4k | 0.16334 | 0.136397 | 0.10958 |
| 8k | 0.207056 | 0.163325 | 0.132586 |
| 16k | 0.313774 | 0.225767 | 0.182928 |
Среднее время отклика (ms) в графическом виде. Read / Write Mix %.
Максимальное время отклика (ms) в табличном виде. Read / Write Mix %.
| Block size | R0% / W100% | R65% / W35% | R100% / W0% |
|---|---|---|---|
| 4k | 5.371 | 3.4244 | 3.5438 |
| 8k | 5.243 | 3.7415 | 3.5414 |
| 16k | 7.628 | 4.2891 | 4.0562 |
Максимальное время отклика (ms) в графическом виде. Read / Write Mix %.

Задержки похожи на то, что выдает MDRAID. Но для более точных выводов следует выполнять оценку задержек под более серьезной нагрузкой.
Тест 4.3 RAIDIX ERA. RAID 6. Тесты пропускной способности
1MБ последовательная запись — 8160 MBPS.
1MБ последовательное чтение — 19700 MBPS.
128Kб последовательная запись — 6200 MBPS.
128Kб последовательное чтение — 19700 MBPS.
Заключение
В качестве итога проведенных испытаний стоит сравнить полученные цифры от программных решений с тем, что предоставляет нам аппаратная платформа.
Для анализа производительности случайной нагрузки мы будем сравнивать скорость RAID 6 (RAIDZ2) при работе с блоком в 4k.
| MD RAID 6 | RAIDZ2 | RAIDIX ERA RAID 6 | Hardware | |
|---|---|---|---|---|
| 4k R100% / W0% | 1902561 | 76314 | 4073187 | 4494142 |
| 4k R65% / W35% | 108594 | 17965 | 921403 | 1823432 |
| 4k R0% / W100% | 39907 | 15719 | 354887 | 958054 |
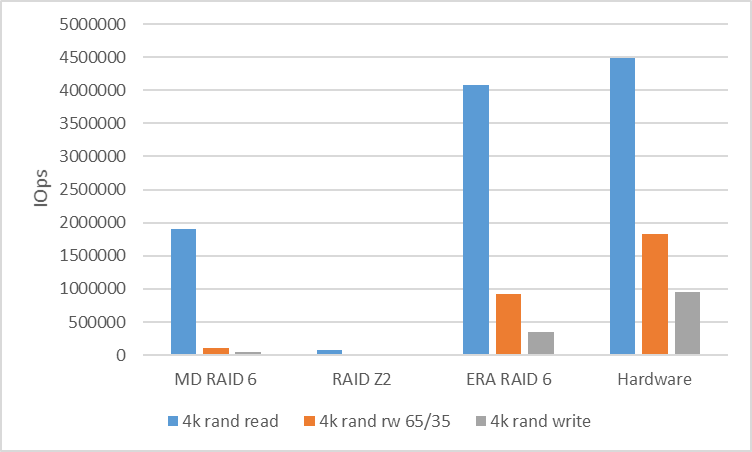
Для анализа производительности последовательной нагрузки мы посмотрим на RAID 6 (RAIDZ2) с блоком 128k. Между потоками мы использовали сдвиг в 10GB, чтобы устранить попадание в кэш и показать реальную производительность.
| MD RAID 6 | RAIDZ2 | RAIDIX ERA RAID 6 | Hardware | |
|---|---|---|---|---|
| 128k seq read | 10400 | 5300 | 19700 | 20400 |
| 128k seq write | 870 | 1100 | 6200 | 7500 |

Что же получается в итоге?
Популярные и доступные программные RAID-массивы для работы с NVMe-устройствами не могут показать той производительности, что заложена в аппаратном потенциале.
Здесь возникает вполне очевидная потребность в управляющем софте, который сможет расшевелить ситуацию и показать, что программно-управляющий симбиоз с NVMe-накопителями может быть очень производительным и гибким.
Понимая такой запрос, у нас в компании создали продукт RAIDIX ERA, разработка которого фокусировалась на решении следующих задач:
- Высокая производительность чтения и записи (несколько млн IOps) на массивах с Parity в режиме mix.
- Потоковая производительность от 30GBps в том числе во время отказов и восстановления.
- Поддержка RAID уровней 5, 6, 7.3.
- Фоновая инициализация и реконструкция.
- Гибкие настройки под разные типы нагрузки (со стороны пользователя).
На сегодняшний момент можно сказать, что данные задачи были выполнены и продукт готов к использованию.
При этом, понимая интерес многих заинтересованных лиц к подобным технологиям, мы подготовили к релизу не только платную, но и бесплатную лицензию, которая полноправно может быть использована для решения задач как на NVMe, так и на SSD накопителях.
Подробнее о продукте RAIDIX ERA читайте у нас на сайте.
UPD. Сокращенное тестирование ZFS с recordsize и volblocksize 8k
Таблица параметров ZFS
| NAME | PROPERTY | VALUE | SOURCE |
|---|---|---|---|
| tank | recordsize | 8K | local |
| tank | compression | off | default |
| tank | dedup | off | default |
| tank | checksum | off | local |
| tank | volblocksize | - | - |
| tank/raid | recordsize | - | - |
| tank/raid | compression | off | local |
| tank/raid | dedup | off | default |
| tank/raid | checksum | off | local |
| tank/raid | volblocksize | 8k | default |
Запись стала похуже, чтение получше.
Но все-равно все результаты значительно хуже остальных решений
| Block size | R0% / W100% | R5% / W95% | R35% / W65% | R50% / W50% | R65% / W35% | R95% / W5% | R100% / W0% |
|---|---|---|---|---|---|---|---|
| 4k | 13703.8 | 14399.8 | 20903.8 | 25669 | 31610 | 66955.2 | 140849.8 |
| 8k | 15126 | 16227.2 | 22393.6 | 27720.2 | 34274.8 | 67008 | 139480.8 |
| 16k | 11111.2 | 11412.4 | 16980.8 | 20812.8 | 24680.2 | 48803.6 | 83710.4 |
