Представьте: в очередной раз ваш любимый вендор дисков рассказал, почему NVMe-накопители лучше, чем SAS и SATA. В вашем любимом издании написали, что вышла новая версия спецификации и появилось 5 новых стартапов, которые делают разные прикольные вещи. А вы, наконец, получили долгожданный бюджет на обновление и задумались: а что всё-таки стоит приобрести и какие подводные камни меня ждут?
Но для начала давайте посчитаем, насколько переход на NVMe может быть целесообразен экономически. Вот сколько IOps мы можем получить за $1, использовав серверные накопители объемом 7.68TB:
NVMe: 357 IOps/$
SATA: 82 IOps/$
Для сравнения, на HDD объемом 8TB за $1 мы получим лишь 1 IOps.
Получается, всего 1 NVMe может заменить 4 SATA SSD (уровни задержек мы пока оставим в стороне).

Звучит очень неплохо. Но значит ли это, что теперь вы сможете за тот же бюджет получить от storage-hungry приложения в 4 раза большую отдачу?
Скорее всего, нет. Для того, чтобы внедрить новые технологии с максимальной отдачей, нужно немного постараться:
правильно подобрать платформу,
решить задачи организации RAID и томов,
правильно настроить ОС и приложение.
Мы поставили уже несколько сотен лицензий на высокопроизводительный СХД и провели более 500 тестов — и далеко не всегда удавалось добиться положительного результата с первого раза.
Еще одним из плюсов NVMe стала возможность работы с накопителями, вынесенными за пределы сервера по высокопроизводительной фабрике, не замечая разницы между локальными и «удаленными» SSD. И, в отличие от SAS, такое решение прекрасно масштабируется до тысяч накопителей и сотен хостов.
Сегодня существуют продукты, которые могут экспортировать NVMe-накопители в сеть у различных вендоров:
Western Digital OpenFlex Data24

HPE J2000

GIGABYTE SF260-NF0/1

Подобные продукты становятся основой компонуемых систем хранения данных, которые значительно меняют подход к построению инфраструктуры ЦОД.
Итак, как правильно и безболезненно (почти) подойти к переходу на технологии NVMe?
Чаще всего дают совет начинать с задачи определения того, чего мы хотим добиться.
В теории, NVMe-накопители могут помочь нам сделать следующее:
увеличить производительность транзакционной системы и снизить время отклика,
снизить время обработки больших объемов данных,
увеличить плотность размещения виртуальных машин и десктопов,
увеличить плотность хранения больших объемов данных (да-да, мы можем хранить большие объемы на flash).
К решению обозначенных задач мы рекомендуем идти по пунктам.
Пункт 1. Изучение особенностей вашего приложения
Если вам требуется увеличить количество транзакций или пропускную способность, а ваше приложение имеет однопоточные компоненты, то, скорее всего, ничего не выйдет — NVMe показывает свое превосходство в указанных параметрах именно там, где к дискам создаются множество глубоких очередей. А вот уровни задержек снизятся практически при любом типе нагрузок.
Также стоит обратить внимание на то, какой стек системного ПО поддерживает ваше приложение: чем свежее ядра Linux, тем больше будет выхлоп. Идеально — чтобы ваше приложение поддерживало новые фреймворки, такие как io_uring или SPDK.
Надеюсь, что вы произвели предварительную работу и уже точно знаете, что проблема с производительностью где-то на стороне СХД. А если нет, то начните с изучения таких инструментов как systat, ebpf (использование для трассировки) и работы со счетчиками в Windows. Погуглите результаты тестов вашего приложения на быстрых хранилищах — если повезет, то вы сможете скорректировать свои ожидания.
Пункт 2. Настройка системного программного обеспечения
Общее правило здесь такое: чем свежее ядро, тем лучше.
Самые влиятельные компоненты, которые колоссально влияют на производительность — это файловая система, менеджер томов и RAID. К сожалению, популярные файловые ZFS и BTRFS могут забрать у вас достаточно большой процент производительности, особенно при «транзакционной» нагрузке. В итоге вы получите более высокую стоимость IOps. Для NVMe мы рекомендуем использовать XFS или F2FS.
Системные настройки
Для того чтобы увеличить общую производительность системы, минимально проиграв в энергосбережении, сделать нужно следующее:
В конфигурации BIOS сделать следующие настройки:

Для оптимизации работы системы нужно:
Поставить утилиту tuned и выполнить команду tuned-adm profile throughput-performance.
Взять настройки отсюда: https://make-linux-fast-again.com.
Нужно списать параметры в /etc/defaults/grub и выполнить команду grub-update.
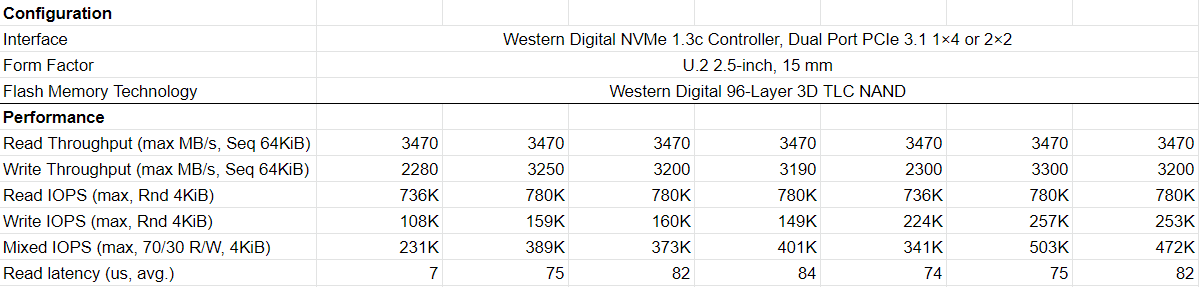
Для того чтобы вы могли оценить влияние изменений мы проводили тесты на следующей системе:
Платформа: HGST
Product Name: S2122-N24-4
2 CPU Intel® Xeon® Gold 6140 CPU: @2.30GHz
8 накопителей Western Ultrastar SN640 объемом 3.2TB
Операционная система: Ubuntu 20.04
Ядро: 5.8
Мы проводили тесты с использованием утилиты FIO 3.16 со следующими конфигурациями:
Тесты накопителей
[global]
direct=1
bs=4k
ioengine=libaio
numjobs=72
group_reporting
time_based
runtime=25m
direct=1
rw=randread
time_based
random_generator=tausworthe64
ramp_time=10s
nice=-5
buffered=0
randrepeat=1
nice=-5
buffered=0
randrepeat=1
norandommap
[nvme0]
filename=/dev/nvme0n1
[nvme1]
filename=/dev/nvme1n1
[nvme2]
filename=/dev/nvme2n1
[nvme3]
filename=/dev/nvme3n1
[nvme4]
filename=/dev/nvme4n1
[nvme5]
filename=/dev/nvme5n1
[nvme6]
filename=/dev/nvme6n1
[nvme7]
filename=/dev/nvme7n1
Тесты RAID
[global]
direct=1
bs=4k
ioengine=libaio
numjobs=72
group_reporting
time_based
runtime=25m
direct=1
rw=randread
time_based
random_generator=tausworthe64
ramp_time=10s
nice=-5
buffered=0
randrepeat=1
nice=-5
buffered=0
randrepeat=1
norandommap
[nvme0]
filename=/dev/era_dimec
Глубина очереди не указана, так как мы изменяем ее в скрипте.
При тестах накопителей без RAID с глубиной очереди 16 мы получаем следующие показатели.
Производителность до настройки системы составляла 3778121,2 IOps. После выполнения тюнинга производительность увеличилась до 4137231,56 IOps Неплохой выхлоп! Уровни средних задержек также снизились пропорционально.
На нашем же RAID ситуация схожая:
Глубина очереди | Производительность до настройки, IOps | Производительность после настройки, IOps | Средняя задержка до настройки, нс | Средняя задержка после настройки, нс |
16 | 3776282,277 | 4042446,855 | 298648,9689 | 279647,1881 |
32 | 3764625,672 | 4071110,26 | 604164,6937 | 560432,432 |
Менеджер томов
Начиная с версии device mapper 4.2 в Linux появилась поддержка работы с множеством очередей. Эта опция позволяет очень серьезно увеличить производительность. По нашему опыту ограничение одного тома составляет около 2 000 000 IOps без использования этой опции и 50 000 000 IOps с использованием.
Проверить это можно следующим образом:
cat /sys/module/dm_mod/parameters/use_blk_mq
cat /sys/block/dm-X/dm/use_blk_mq
Multipath
При использовании двухпортовых накопителей или накопителей, подключенных через несколько путей фабрики, потребуется использовать ПО для мультипасинга.
В OS Linux за это отвечает DM-multipath. Также можно использовать нативный NVMe-multipath.
На dm-multipath достижение высокой производительности возможно при включении режима bio.
Сейчас в ядрах Linux поддерживается два режима обработки IO: Bio Request и Multi-Queue. Режим bio проще и рекомендуется при работе с NVMe. Хотя, конечно, сравнение работы различных multipath — вопрос отдельной статьи. Правильный параметр конфигурационного файла выглядит следующим образом:
features "2 queue_mode bio"
Драйверы NVMe
Современные ядра Linux поддерживают драйверы, работающие как в режиме прерываний, так и в режиме polling. Задается этот параметр при загрузке модуля.
При этом polling поддерживается в трех режимах: классический, адаптивный гибридный поллинг, с фиксированным параметром задержки.
Включается поллинг следующим образом: modprobe -r nvme && modprobe nvme poll_queues=16
Можно сделать так, чтобы этот параметр применялся по умолчанию:
В файл /etc/modprobe.d/nvme.conf пропишите строку
options nvme poll_queues=4
и заребилдите initramfs.
Мы рекомендуем использовать гибридный поллинг.
Для каждого namespace нужно прописать 0 в файл /sys/block/nvmeXnY/queue/io_poll_delay.
Что же можно ожидать?
На удивление, на нашем полигоне мы не обнаружили значимого результата. Год назад, на другой системе, где процессор был послабее, дисков больше, а в качестве операционки использовался CentOS, включение поллинга дало нам несколько дополнительных сотен тысяч IOPS, а на низкоинтенисвных нагрузках задержка снизилась на 25%. Так это эту рекомендацию оставляем на ваше усмотрение.
Сеть
Тонкая настройка сети — дело непростое, и опять же требует отдельной статьи поэтому мы оставим только пару простых рекомендаций: использовать Jumbo Frames и в случае использования сети от Mellanox не стесняться использовать утилиту mlnx_tune.
RAID
Организация дисков в массив на сегодня является самой сложной storage-проблемой.
RAID 10 «съедает» половину объема и половину производительности на запись при любом объеме, а более экономные RAID5 и RAID6 имеют ограничения как по производительности, так и по уровням задержек, а иногда — по количеству и типу подключаемых дисков.
На сегодняшний момент мы можем использовать следующие решения:
аппаратные трехрежимные решения от Broadcom, Microchip и Areca,
программный RAID в ОС Linux,
решение Intel® VROC.

Как вы можете увидеть в таблице, полученной от независимых исследователей, все эти решения имеют ограничения по максимальному уровню производительности. Именно поэтому мы решили разработать свой собственный программный RAID.
Опять таки, же на нашей системе мы тестировали MD RAID и Intel® VROC (они демонстрируют идентичные результаты в связи с тем, что в основе VROC лежит код mdraid) и получили следующие результаты:
RAID Iops | RAID latency | |
16 | 1703389,964 | 634188,1794 |
32 | 1707676,114 | 1307190,139 |
При этом нагрузка на CPU была около 96%. RAID создавался с параметрами по умолчанию, размер chunk=64k. Журнал не включали.
echo 72 > /sys/block/md0/md/group_thread_cnt
Файловые системы с интегрированными функциями тома и RAID
Файловые системы типа ZFS и BTRFS имеют полный интегрированный стек, обеспечивающий все необходимые функции от дисков до интерфейса ФС. Но их архитектура на основе подхода CoW крайне негативно сказывается на производительности случайных операций и уровнях задержки — и мы не рекомендуем использовать их для работы с NVMe-накопителями.
SPDK
SPDK предлагает альтернативный путь работы с высокопроизводительными устройствами, но есть две проблемы.
Нет готового варианта RAID.
Тома не очень стабильны.
Так что этот подход мы рекомендуем только опытным компаниям.
Общие настройки блочной подсистемы
Убедитесь, что у ваших устройств выставлены следующие параметры:

Ещё можно выключить поддержку iostat для каждого накопителя.
Пункт 3. Правильно подобрать «железо»
Теперь перейдем к аппаратной конфигурации.
Наиболее часто узким местом при работе с высокопроизводительными накопителями являются CPU и шина PCIe. Начнем с CPU.
Здесь действует простое правило: нужно иметь одно дополнительное ядро дополнительно к нуждам приложения на один NVMe-накопитель.
Такой подход позволит как реализовать возможности накопителя, так и иметь достаточные ресурсы для работы вашего приложения.
А сколько нужно вашему приложению — помогут понять специальные сайзеры.
PCIe
Часто системы, ориентированные на обеспечение высокой плотности хранения, например, на основе накопителей форм-фактора Ruler, имеют переподписку по полосам PCle и шина ограничивает общую пропускную способность и, как следствие, количество операций ввода-вывода.
Мы столкнулись с такой особенностью при тестировании платформы Supermicro E1.S SuperMinute. Это система на 32 накопителя в формате EDSFF. Сервер Supermicro E1.S SuperMinute позволяет подключить 32 NVMe-накопителя. Накопители сгруппированы в слоты PCIe х16 по 4 шт. и подключаются в PCIe switch. PCIe switch подключается к процессорам по четырем шинам PCIe x8 на одну NUMA ноду (рис. 4). Из-за этого не получается достичь теоретической производительности при подключении всех 32 накопителей.

Лучшим соотношением объем/производительность для данной платформы будет использование 16 накопителей подключенных по схеме на рис. 5:

Если вам нужна производительность, то, конечно, стоит обратить внимание на то, как организован ваш сервер и EBOF.
Для начала посмотрим на сервер. В первую очередь обратим внимание на накопители и то, какими и какой производительности портами они обладают?
Максимальная производительность будет достигнута при обеспечении непосредственного подключения устройств к CPU — либо количество линий до «свитча» и от «свитча» будет соответствовать суммарному количеству на дисках.
При использовании EBOF нам нужно рассмотреть как архитектуру EBOF, так и сетевую инфраструктуру от контроллеров в EBOF до подключения адаптеров в серверах. Тут также нигде не должно возникать переподписок.
Особое внимание нужно уделить расположению накопителей на Numa nodes. Если ваше приложение способно это учитывать, то для достижения лучшего результата стоит правильно размещать массивы и тома на накопителях, которые «живут» на одной ноде.
Тестирование
Итак, вы закупили накопители и подобрали под них правильное железо, установили операционную систему и правильно ее настроили. Настало время провести тесты!
Делать это нужно, идя от меньшего к большему. Есть три ключевых принципа в проведении тестов:
Перед тем как начинать тесты, вы должны обозначить ожидания, и в случае несовпадения ожиданий и результатов предпринять меры по выяснению причин.
Тесты должны быть стабильно повторяемыми — результаты не должны отличаться при повторных запусках.
Тесты должны отражать реальную производительность системы.
Важным моментом является то, что накопители на основе NAND Flash должны быть должным образом подготовлены для удовлетворения критериям 2 и 3.
Мы рекомендуем ознакомиться со спецификацией SNIA SSS PTSE.
Все enterprise-накопители в спецификациях показывают данные, полученные в соответствии именно с этой методикой.
Итак, первый этап — ознакомиться со спецификацией и подсчитать ожидаемую производительность от вашего набора дисков. Затем — подготовить диски к тестам. После — запустить нагрузку и посмотреть результаты. Если есть проблемы, то разобраться в них и устранить.
Мы рекомендуем использовать утилиты Flexible IO tester или VDbench.
Есть типовые ошибки, которые допускают при тестировании дисков:
Отсутствие сдвига между потоками: все потоки читают один и тот же набор данных.
Неверно заданные сдвиги.
Неверно подобранные показатели количества потоков и глубины очереди. Для достижения максимальных показателей по количествам операций нужно указывать количество потоков равное количеству вычислительных ядер и глубину очереди 32-64 запроса.
Если ваша задача чувствительна к задержкам, то глубину очереди стоит уменьшить.
Использование буферизованных IO и некорректных io_engine.
Несоответствие размера блока задаче.
Если ваши диски не установлены локально в сервере, то стоит начать с тестов производительности сети между узлом и EBOF.
Отдельное внимание стоит уделить параметру, которые проявляют себя именно на системах, которые обеспечивают высокую производительность.
norandommap - хранение истории обращений и работа с ней начинает вляить на результаты установка этого параметра позволит избежать эту проблему
После того, как вы получите результаты на всех дисках и устраните узкие места, можно протестировать RAID и менеджер томов. Тут вам стоит полагаться на те же советы, что и при тестах диска, но при расчете ожидаемой производительности не забывать про RAID Penalty. Очень часто RAID тормозит, если в системе есть какие-то медленные диски, которые мы не исключили на предыдущем этапе. Используйте утилиту iostat.
Следующими по порядку идут уже тесты файловой системы и непосредственно тесты, имитирующие нагрузку приложений. В каждом случае есть свои рекомендации и особенности.
Также при тестировании решений следует увеличивать нагрузку для того чтобы понять, как система ведет себя при масштабировании. Особенно важно это проверять для дизагрегированных сред. Также можно увеличивать как глубину очереди, так и количество потоков, и контролировать не только среднии уровни задержек, но и задержки по персентилям.
И снова про RAID
В существующих RAID-решениях мы увидели явный недостаток, который мешает получить максимум от возможностей современных устройств. Именно поэтому мы решили разработать собственный RAID, исходя из следующего:
Мы хотим достичь максимальной возможной производительности от суммарной производительности устройств (при отсутствии других узких мест, конечно).
За основу мы берем RAID с parity, так как зеркалирование слишком дорого.
При этом мы хотим, чтобы RAID с parity как минимум не уступали по производительности R10.
Решение должно быть адаптировано к разным типам нагрузки — случайной или последовательной, для крупных и маленьких блоков, высокоинтенсивной и чувствительной к задержкам низкоинтенсивной нагрузке.
Простота настройки и управления.
И, самое главное, решение должно быть адаптировано к использованию с современным оборудованием на основе NVMf.
Мы наблюдаем серьезный рост спроса на решения для дизагрегированной инфраструктуры. И, конечно, при дизайне решения рассчитывали, что его будут использовать в рамках DIS.
Так как NVMe-накопители любят многопоточную запись, нам нужно было решить пару вопросов:
Быстро и эффективно рассчитывать контрольные суммы и восстанавливать данные — за это отвечает уже давно изобретенная нами схема расчета контрольных сумм на векторных регистрах (подробнее об этом можно прочитать в статье):
2. Обрабатывать запросы на запись и чтение с максимальной параллелизацией.

Проблема RAID-массивов с parity в том, что примерно в один момент времени в один страйп может прийти несколько запросов на изменение данных. А может еще происходить ребилд или инициализация массива! С одной стороны, нам нужно обрабатывать все запросы максимально эффективно, используя все вычислительные ядра, а с другой — не допускать искажения данных в стрипах с контрольными суммами. Блокировки тут — очень плохой вариант, ведь мы можем иметь сотни тысяч и даже миллионы запросов на запись в секунду. Именно поэтому мы придумали подход на основе lockless c динамическим маппингом потоков и страйпов.


Также мы полностью отказались от кэширования.
А для достижения высокой производительности на задачах потоковой операций записи для того, чтобы избегать постоянных read-modify-write мы разработали механизм объединения запросов для того, чтобы такие записи были полнострайповыми.
Управляется наш массив через cli, но скоро появится gRPC.
Так как движок RAIDIX ERA используется как внутри имеющихся СХД, так и совместно с решениями типа Openflex, мы разработали механизм Active-Active кластера, который со временем расширится до множества узлов.
О других особенностях перехода на NVMe расскажем во второй части статьи.
