Всем привет, меня зовут Семен Левенсон, я работаю teamlead’ом на проекте «Поток» от Rambler Group и хочу рассказать о нашем опыте использования Apollo.
Объясню, что такое «Поток». Это автоматизированный сервис для предпринимателей, позволяющий привлекать клиентов из Интернета в бизнес, не вовлекаясь в рекламу, и быстро создавать простые сайты, не являясь экспертом в верстке.
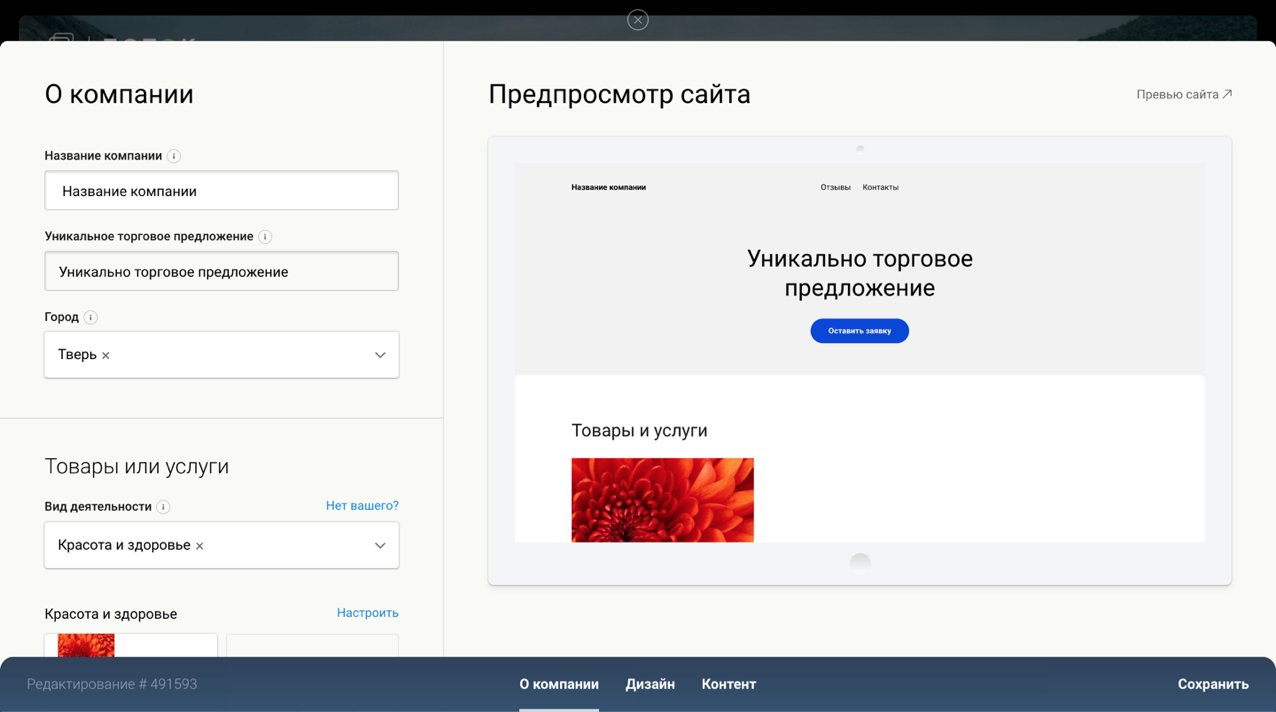
На скришноте показан один из шагов создания лендинга.
Что было вначале?
А в начале было MVP, много Twig, JQuery и очень сжатые сроки. Но мы пошли нестандартным путем и решили сделать редизайн. Редизайн не в смысле «стили подлатать», а решили пересмотреть полностью работу системы. И это стало для нас хорошим этапом для того, чтобы собрать идеальный frontend. Ведь нам – команде разработчиков – дальше поддерживать это и реализовывать на основе этого другие задачи, достигать новых целей, поставленных продуктовой командой.
В нашем отделе уже было накоплено достаточно экспертизы по использованию React. Не хотелось тратить 2 недели на настройку webpack, поэтому решили использовать CRA (Create React App). Для стилей был взят Styled Components, и куда же без типизации – взяли Flow. Для State Management взяли Redux, однако в результате оказалось, что он нам вообще не нужен, но об этом чуть позже.
Мы собрали свой идеальный frontend и поняли, что о чем-то забыли. Как выяснилось, забыли мы про backend, а точнее про взаимодействие с ним. Когда задумались, что можем использовать для организации этого взаимодействия, то первое, что пришло на ум – конечно, это Rest. Нет, мы не пошли отдыхать (smile), а начали рассуждать на тему RESTful API. В принципе история знакомая, тянется давно, но также нам известны и проблемы с ним. О них мы и поговорим.
Первая проблема – это документация. RESTful, конечно, не говорит, как организовать документацию. Здесь существует вариант использования того же swagger, но фактически — это внедрение дополнительной сущности и усложнение процессов.
Вторая проблема – это как организовать поддержку версионности API.
Третья важная проблема – это большое количество запросов или кастомные endpoint’ы, которые мы можем нагородить. Допустим, нам нужно запрашивать посты, по этим постам – комменты и еще авторов этих комментов. В классическом Rest’е нам приходится делать 3 запроса минимум. Да, мы можем нагородить кастомные endpoint’ы, и все это свернуть в 1 запрос, но это уже усложнение.
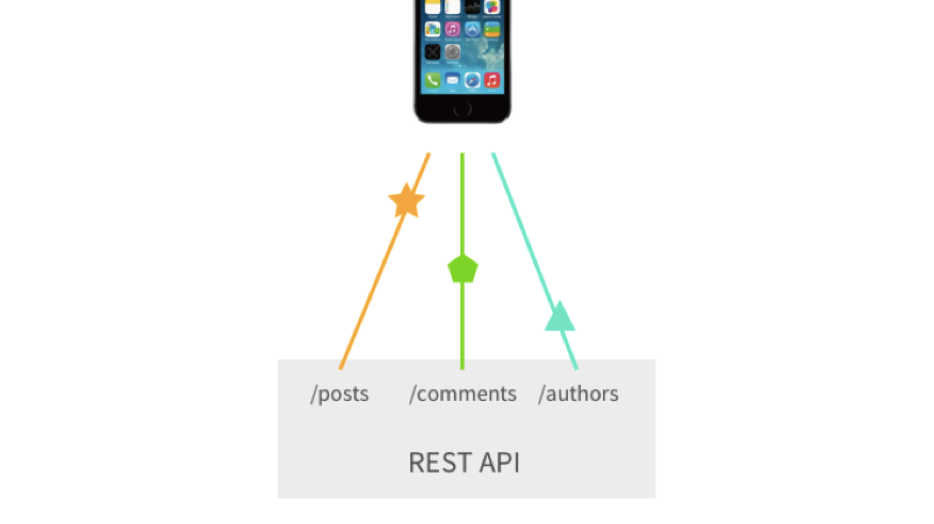
За иллюстрацию спасибо Sashko Stubailo
Решение
И в этот момент нам на помощь приходит Facebook c GraphQL. Что такое GraphQL? Это платформа, но сегодня мы рассмотрим одну из ее частей – это Query Language for your API, просто язык, причем довольно примитивный. И работает он максимально просто – как мы запрашиваем какую-то сущность, также мы ее и получаем.
Запрос:
{
me {
id
isAcceptedFreeOffer
balance
}
}Ответ:
{
"me": {
"id": 1,
"isAcceptedFreeOffer": false,
"balance": 100000
}
}Но GraphQL — это не только про чтение, это и про изменение данных. Для этого в GraphQL существуют мутации. Мутации примечательны тем, что мы можем декларировать желаемый ответ от backend’а, при успешном изменении. Однако тут есть свои нюансы. Например, если наша мутация затрагивает данные за пределом графа.
Пример мутации, в которой применяем бесплатную оферту:
mutation {
acceptOffer (_type: FREE) {
id
isAcceptedFreeOffer
}
} В ответ получаем ту же структуру, которую запросили
{
"acceptOffer": {
"id": 1,
"isAcceptedFreeOffer": true
}
}Взаимодействие с GraphQL бекендом может совершается с помощью обычного fetch.
fetch('/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: '{me { id balance } }' })
});Какие же плюсы у GraphQL?
Первый и очень крутой плюс, который можно оценить, когда вы начинаете с ним работать, в том, что этот язык – строготипизированный и самодокументируемый. Проектируя схему GraphQL на сервере, мы можем сразу описывать типы и атрибуты непосредственно в коде.

Как уже было сказано выше, у RESTful есть проблема с версионированием. В GraphQL для этого осуществлено весьма элегантное решение – deprecated.
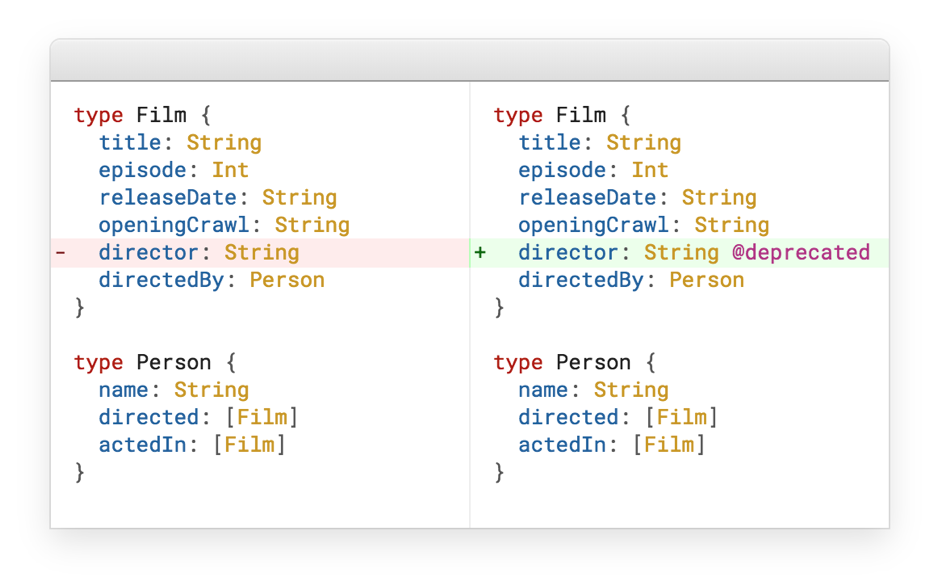
Допустим, у нас есть Film, мы расширяем его, так у нас появляется director. И в какой-то момент мы просто выносим director в отдельный тип. Возникает вопрос, что делать с прошлым полем director? На него есть два ответа: либо мы удаляем это поле, либо же помечаем его deprecated, и оно автоматически пропадает из документации.
Самостоятельно решаем, что нам нужно.
Вспоминаем предыдущую картинку, где у нас все шло REST’ом, здесь же у нас все объединяется в один запрос и не требует какой-то кастомизации со стороны backend-разработки. Они один раз это все описали, а мы уже крутим-вертим-жонглируем.
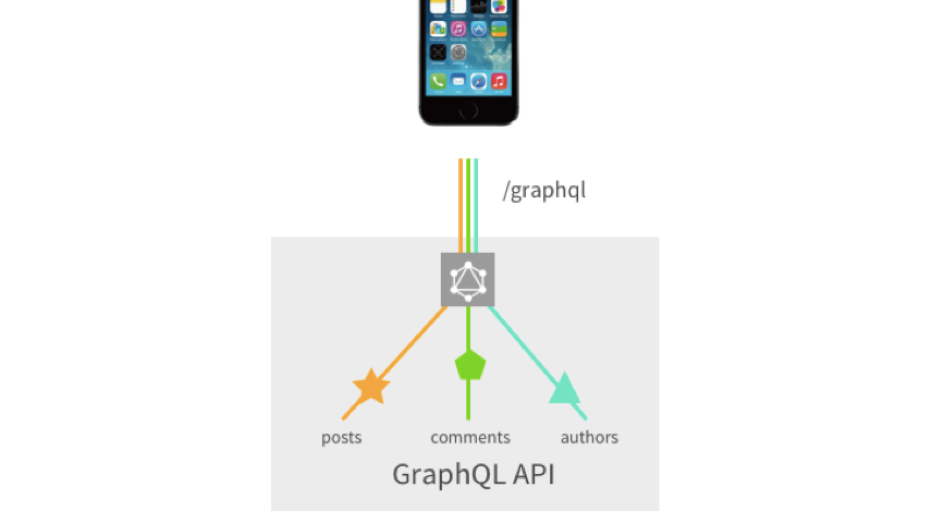
Но не обошлось без ложки дегтя. В принципе на frontend’е у GraphQL минусов не так уж и много, потому что он изначально разрабатывался для того, чтобы решать проблемы frontend’а. А у backend’а не все так гладко… У них есть такая проблема, как N+1. Возьмем в качестве примера запрос:
{
landings(_page: 0, limit: 20) {
nodes {
id
title
}
totalCount
}
}Простой запрос, мы запрашиваем 20 сайтов и количество, сколько у нас есть сайтов. И в backend’е это может обернуться 21 запросом к базе данных. Эта проблема известная, решаемая. Для Node JS есть пакет dataloader от Facebook. Для других языков можно найти свои решения.
Также существует проблема глубокой вложенности. К примеру, у нас есть альбомы, у этих альбомов есть песни, и через песню мы также можем получить альбомы. Для этого необходимо составить следующие запросы:
{
album(id: 42) {
songs {
title
artists
}
}
}{
song(id: 1337) {
title
album {
title
}
}
}Таким образом, у нас получается рекурсивный запрос, который тоже элементарно кладет нам базу.
query evil {
album(id: 42) {
songs {
album {
songs {
album {Данная проблема тоже известная, решение для Node JS – это GraphQL depth limit, для других языков также существуют свои решения.
Таким образом, мы определились с GraphQL. Самое время – выбрать библиотеку, которая будет работать с GraphQL API. Пример в пару строк с fetch’ем, который показан выше, это только транспорт. Но благодаря схеме и декларативности, мы можем кэшировать еще и запросы на front’е, и работать с большей производительностью с GraphQL backend’ом.
Так у нас есть два основных игрока – это Relay и Apollo.
Relay
Relay — это разработка Facebook, они используют его сами. Как и Oculus, Circle CI, Arsti и Friday.
Какие плюсы есть у Relay?
Непосредственный плюс — то что разработчиком является Facebook. React, Flow и GraphQL – это разработки Facebook, всё это заточенные друг под друга паззлы. Куда же нам без звездочек на Github, у Relay их почти 11 000, у Apollo для сравнения – 7600. Крутая вещь, которая есть у Relay – это Relay-compiler, инструмент, который оптимизирует и анализирует ваши GraphQL-запросы на уровне сборки вашего проекта. Можно считать, что это uglify только для GraphQL:
# до Relay-compiler
foo { # type FooType
id
... on FooType { # matches the parent type, so this is extraneous
id
}
}
# После
foo {
id
}Какие минусы у Relay
Первый минус* – отсутствие SSR из коробки. На Github до сих пор открыт issue. Почему под звездочкой – потому что уже есть решения, но они сторонние, а кроме того, довольно неоднозначные.
Опять же, Relay — это спецификация. Дело в том, что GraphQL – это уже спецификация, а Relay – это спецификация над спецификацией.
Например, пагинация у Relay реализована иначе, здесь появляются курсоры.
{
friends(first: 10, after: "opaqueCursor") {
edges {
cursor
node {
id
name
}
}
pageInfo {
hasNextPage
}
}
}Мы уже не используем привычные оффсеты и лимиты. Для фидов в ленте – это отличная тема, но когда мы начинаем делать всякие grid’ы, то тут появляется боль.
Facebook решил свою проблему, написав для React’a свою библиотеку. Существуют решения для других библиотек, для vue.js, например – vue-relay. Но если мы обратим внимание на количество звездочек и commit-ов, то тут тоже не всё так гладко и может быть нестабильно. Например, Create React App из коробки CRA не дает использовать Relay-compiler. Но можно обойти это ограничение с помощью react-app-rewired.
Apollo
Второй наш кандидат – это Apollo. Разрабатывает его команда Meteor. Apollo используют такие известные команды как: AirBnB, ticketmaster, Opentable и т.д.
Какие есть плюсы у Apollo
Первый значительный плюс в том, что Apollo разрабатывался, как framework agnostic библиотека. Например, если мы захотим сейчас все переписать на Angular, то это не будет проблемой, Apollo с этим работает. А можно вообще написать все на Vanilla.
У Apollo крутая документация, есть готовые решения на типичные проблемы.

Очередной плюс Apollo – мощный API. В принципе, кто работал с Redux, здесь найдут общие подходы: есть ApolloProvider (как Provider у Redux), и вместо store у Apollo это называется client:
import { ApolloProvider } from 'react-apollo';
import { ApolloClient } from './ApolloClient';
const App = () => (
<ApolloProvider client={ApolloClient}>
...
</ApolloProvider>
);На уровне уже самого компонента, у нас предоставляется graphql HOC, как connect. И GraphQL-запрос мы пишем уже внутри, как MapStateToProps в Redux.
import { graphql } from 'react-apollo';
import gql from 'graphql-tag';
import { Landing } from './Landing';
graphql(gql`
{
landing(id: 1) {
id
title
}
}
`)(Landing);Но когда мы делаем MapStateToProps в Redux, мы забираем данные локальные. Если же локальных данных нет, то Apollo сам идет за ними на сервер. В сам компонент нам падают очень удобные Props-ы.
function Landing({
data,
loading,
error,
refetch,
...other
}) {
...
}Это:
• данные;
• статус загрузки;
• ошибка, если она произошла;
вспомогательные функции, например refetch для перезагрузки данных или fetchMore для пагинации. Также есть огромный плюс и у Apollo, и у Relay, это Optimistic UI. Он позволяет совершать undo/redo на уровне запросов:
this.props.setNotificationStatusMutation({
variables: {
…
},
optimisticResponse: {
…
}
});Например, пользователь нажал на кнопку «лайк», и «лайк» сразу засчитался. При этом запрос на сервер будет отправлен в фоне. Если в процессе отправки произойдет какая-то ошибка, то, изменяемые данные, вернуться в первоначальное состояние самостоятельно.
Server side rendering реализован хорошо, на клиенте выставляем один флаг и всё готово.
new ApolloClient({
ssrMode: true,
...
});Но здесь хотелось бы рассказать про Initial State. Когда Apollo сам себе его готовит, все хорошо работает.
<script>
window.__APOLLO_STATE__ = client.extract();
</script>
const client = new ApolloClient({
cache: new InMemoryCache().restore(window.__APOLLO_STATE__),
link
});Но у нас нет Server side rendering, а нам backend подсовывает в глобальную переменную определенный GraphQL-запрос. Тут нужен небольшой костыль, необходимо написать Transform-функцию, которая GraphQL-ответ от backend’а уже превратит в нужный для Apollo формат.
<script>
window.__APOLLO_STATE__ = transform({…});
</script>
const client = new ApolloClient({
cache: new InMemoryCache().restore(window.__APOLLO_STATE__),
link
});Ещё один плюс Apollo в том, что он хорошо кастомизируется. Все мы помним middleware из Redux, здесь всё тоже самое, только это называется link.

Хотелось бы отдельно отметить два link’а: apollo-link-state, который нужен для того, чтобы в отсутствие Redux хранить локальное состояние, и apollo-link-rest, если мы хотим писать GraphQL-запросы к Rest API. Однако с последним нужно быть крайне аккуратным, т.к. могут возникнуть определенные проблемы.
Минусы у Apollo тоже есть
Рассмотрим на примере. Возникла неожиданная проблема с производительностью: запрашивали 2000 элементов на frontend (это был справочник), и начались проблемы с производительностью. После просмотра в отладчике оказалось, что на чтении Apollo отъедал очень много ресурсов, issue в принципе закрыт, сейчас все хорошо, но такой грешок был.
Также refetch оказался очень неочевидный…
function Landing({
loading,
refetch,
...other
}) {
...
}Казалось бы, когда мы делаем перезапрос данных, тем более, если предыдущий запрос завершился с ошибкой, то loading должен стать true. Но нет!
Для того, чтобы это было, нужно указывать notifyOnNetworkStatusChange: true в graphql HOC, или refetch state хранить локально.
Apollo vs. Relay
Таким образом, у нас получилась такая таблица, мы все взвесили, подсчитали, и у нас 76% оказалось за Apollo.
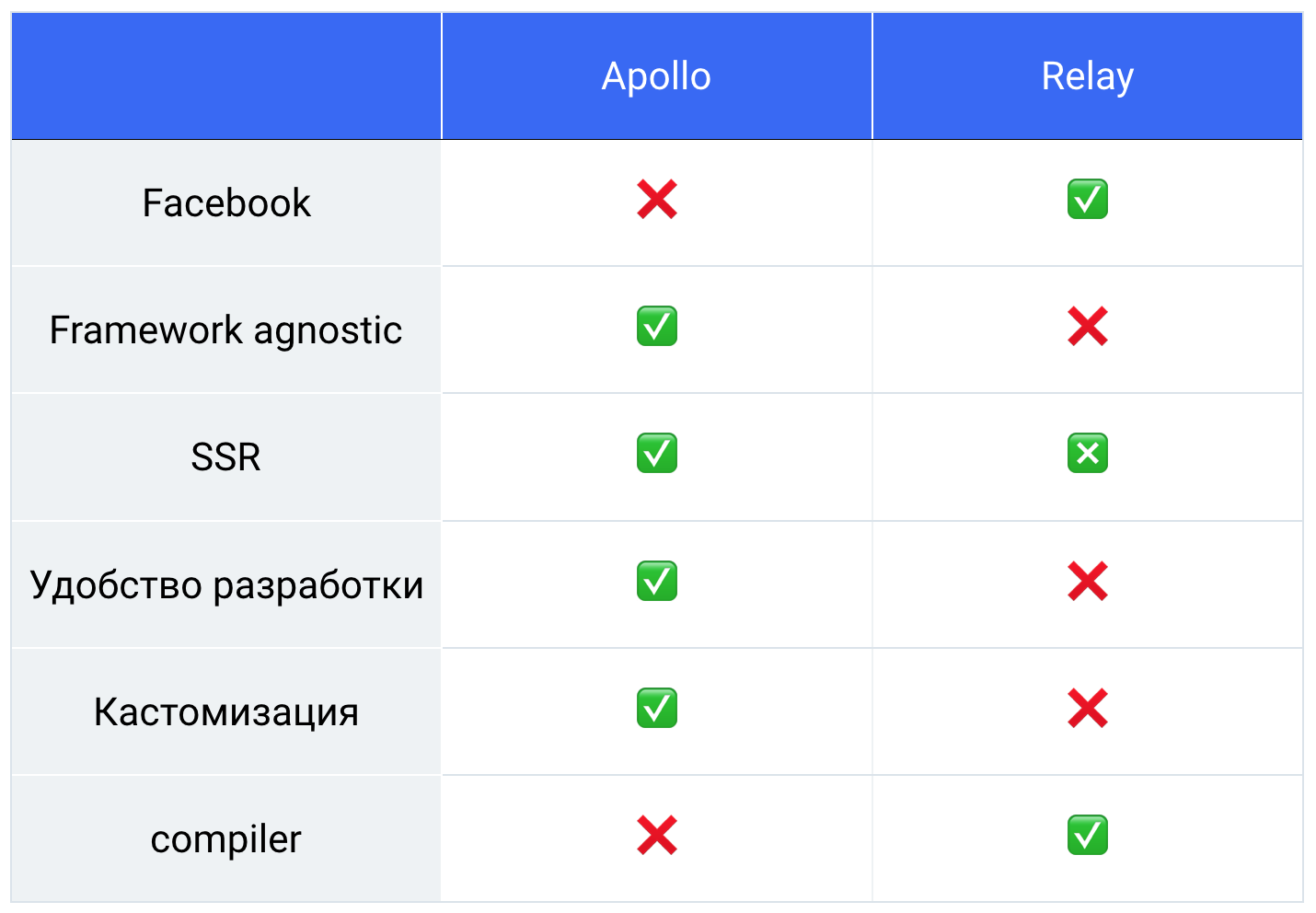
Таким образом, мы выбрали библиотеку и пошли работать.
Но хотелось бы подробнее сказать про toolchain.
Здесь вообще все очень хорошо, существуют различные дополнения для редакторов, где-то лучше, где-то хуже. Также есть еще apollo-codegen, который генерирует полезные файлы, к примеру, flow-типы, и в принципе вытаскивает схему из GraphQL API.
Рубрика «Очумелые ручки» или что мы сделали у себя
Первое, с чем мы столкнулись, — что нам в принципе надо как-то запрашивать данные.
graphql(BalanceQuery)(BalanceItem);У нас есть общие состояния: загрузка, обработка ошибки. Мы написали свой хок (asyncCard), который подключается через композицию graqhql и asyncCard’а.
compose(
graphql(BalanceQuery),
AsyncCard
)(BalanceItem);Хотелось бы еще рассказать про фрагменты. Есть компонент LandingItem и он знает, какие данные ему нужны из GraphQL API. Мы задали свойство fragment, где указали поля из сущности Landing.
const LandingItem = ({ content }: Props) => (
<LandingItemStyle>
…
</LandingItemStyle>
);
LandingItem.fragment = gql`
fragment LandingItem on Landing {
...
}
`;Теперь на уровне использования компонента мы используем его фрагмент в конечном запросе.
query LandingsDashboard {
landings(...) {
nodes {
...LandingItem
}
totalCount
}
${LandingItem.Fragment}
}И допустим к нам прилетает задача на то, чтобы добавить статус в этот лендинг — не проблема. Мы добавляем в рендер отображение и в фрагменте свойство. И все, готово. Single responsibility principle во всей красе.
const LandingItem = ({ content }: Props) => (
<LandingItemStyle>
…
<LandingItemStatus … />
</LandingItemStyle>
);
LandingItem.fragment = gql`
fragment LandingItem on Landing {
...
status
}
`;Какая у нас еще была проблема?
У нас на сайте есть ряд виджетов, которые делали свои отдельные запросы.
Во время тестирования оказалось, что всё это тормозит. У нас очень долгие security-проверки, и каждый запрос очень дорогой. Это тоже оказалась не проблема, есть Apollo-link-batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });Он конфигурируется следующим образом: мы передаем количество запросов, которые мы можем объединить и сколько времени будет ждать этот link после появления первого запроса.
И получилось так: одновременно всё загружается, и одновременно всё приходит. Стоит отметить, что если во время этого объединения какой-то из подзапросов вернется с ошибкой, то ошибка будет только у него, а не у всего запроса.
Хочется отдельно рассказать, что прошлой осенью произошло обновление с первого Apollo на второй
Вначале был Apollo и Redux
'react-apollo'
'redux'Потом Apollo стал более модульным и расширяемым, эти модули можно разрабатывать самостоятельно. Тот же самый apollo-cache-inmemory.
'react-apollo'
'apollo-client'
'apollo-link-batch-http'
'apollo-cache-inmemory'
'graphql-tag'Стоит обратить внимание, что Redux нет, и как оказалось, он, в принципе, не нужен.
Выводы:
- Feature-delivery time у нас уменьшился, мы не тратим времени на описание action, reduce в Redux, и меньше трогаем backend
- Появилась антихрупкость, т.к. статический анализ API позволяет свести к нулю проблемы, когда frontend ожидает одно, а backend отдает совершенно другое.
- Если вы начнете работать с GraphQL – попробуйте Аполло, не разочаруетесь.
P.S. Вы также можете посмотреть видео с моей презентации на Rambler Front& Meet up #4
