Комментарии 40
А есть ли способ упростить распознавание 2х значного номера, например, наклеенного на борт или стекло машины? Например напечатать его каким либо особым образом или еще что то, чтобы при проезде мимо камеры, номер считывался? )
Номера печатаете вы сами? Так рисуйте рядом штрих- или QR-код.
qr/штрих коды на скорости ваще не читаются
да, одномерный штрихкод с линиями вдоль движения должен стабильнее читаться )
Тогда цветовой код. 4 разноцветных квадрата плюс метка для привязки — будет отлично распознаваться при любом смазывании картинки. Можно сами цифры делать цветными.
Цвет очень плохо запечатляется камерами, особенно в разных условиях освещения. Задача баланса белого тоже не тривиальная, там еще накладываются проблемы чувствительности элементов матрицы к ИК и много других. Да что говорить, даже для человека ночью все кошки серые. А у человека есть умная система баланса белого (здорово опирается на контекст), шикарный динамический диапазон чувствительности,
Только если какой-то мощный известный нам источник света есть, который освещает все. Такие условия на производстве при контроле качества можно обеспечить. Улица — значительно сложнее.
Только если какой-то мощный известный нам источник света есть, который освещает все. Такие условия на производстве при контроле качества можно обеспечить. Улица — значительно сложнее.
QR код человек не на лету схватывает. Ну мне кажется номер из цифр, как на почтовом конверте, читались бы отлично. Кто-то на хабре писал, что и их можно улучшить. Но да, там какой-то компромис будет между читаемым человеком и читаемым машиной. Штрих коды же действительно мощная штука, в том числе и одномерные.
Еще стоит обвести в какую-то рамку или поставить рядом крестик / какую-то метку дать для быстрого поиска области с цифрами в кадре
Еще стоит обвести в какую-то рамку или поставить рядом крестик / какую-то метку дать для быстрого поиска области с цифрами в кадре
А почему речь всё время идёт про 5 символов? Ведь три буквы плюс три цифры это шесть? Или здесь какая-то хитрость, оставленная читателю?
Объединитесь с авторами программы RoadAR. Видеорегистратор с распознаванием знаков, номеров и отсылкой жалоб на нарушения был бы отличной штукой.
Давно у меня была идея по созданию сервиса по сбору статистики о дорожном движении — ставим такой девайс в машину и он регулярно отправляет на сервер увиденные номера (в виде криптохеша, чтобы не подвергать риску личную жизнь автолюбителей). Такой ресурс мог бы предоставить бесценную инфу о городских транспортных потоках — откуда и куда люди регулярно перемещаются, что позволило бы оптимизировать дорожную сеть.
Второй вариант использования такого сервиса — ставить лайки и минусы другим водителям прямо в реальном времени. А система бы тебе потом подсказывала — впереди урод, держись от него подальше.
Второй вариант использования такого сервиса — ставить лайки и минусы другим водителям прямо в реальном времени. А система бы тебе потом подсказывала — впереди урод, держись от него подальше.
А такой сервис не попадет под незаконный сбор и обработку персональных данных? Ведь фактически можно будет в автоматическом режиме массово фиксировать типичные маршруты для всех автомобилистов.
Я там в скобочках написал, что на сервер будут отправляться только крипто-хэши номеров, а не сами номера. То есть владельцы сервиса никогда не смогут идентифицировать конкретного водителя, всё будет обезличено.
А в чём проблема просчитать хэши для двухсот миллионов реально возможных номеров, и тем самым получить базу для их идентификации? Или у каждого пользователя персональный ключ шифрования, и следовательно, своя база? Но тогда и сервер не нужен.
Да, логично. Про вариант просчета хешей я позабыл. Но, можно предложить следующий вариант (детали будут отличаться, но смысл, думаю, ясен) Берем таблицу всех возможных номеров, и каждому из номеров присваиваем id, который вычисляется как, скажем, floor( порядковый номер записи / 1000 ), таким образом мы разбиваем все номера на группы по 1000 знаков в каждом. Для статистических целей по анализу трафика этого может быть достаточно, а вот с вероятностью 100% сказать, что конкретный номер был там-то и там-то, уже не получится — 1000 номеров имеют одинаковый id.
Функция генерации не уникального id по номеру может быть какой-то иной, главное, что бы номера равномерно распределялись по группам. Как-то так…
Функция генерации не уникального id по номеру может быть какой-то иной, главное, что бы номера равномерно распределялись по группам. Как-то так…
В Нью-Йоркской городской думе не читали Хабр и наступили на эти самые грабли :)
По закону РФ номер не является собственностью автовладельца, а является собственностью РФ: автовладельцу его представляют в пользование. Он не имеет права его скрывать. Думаю, что противозаконной было бы привязывать номер к фамилии. А сам по себе сбор номеров не должен являться противозаконным.
У нас открытый сервер. Если они заинтересованны будут — им можно воспользоваться, если что, мощность попробуем нарастить. Навязываться с нашим открытым проектом в закрытый коммерческий проект как-то неприлично.
Мы сами, кстати, в восхищении от их системы. Сами такое давно обсуждали, но решимости браться за что-то настолько глобальное не было.
Мы сами, кстати, в восхищении от их системы. Сами такое давно обсуждали, но решимости браться за что-то настолько глобальное не было.
Очень познавательно, но читаю уже несколько статей и все задаюсь вопросом, можно ли обхитрить алгоритм? =)
Ну я так понимаю интеллектуально обхитрить? Чтобы не пришлось подтачивать завитушку у буквы В до Р?
Не знаю. вот конкретно второй алгоритм — как-то схитрить с границами. Границы слева-справо, например. Скосы подрисовать черной краской на номере или белой под 30 градусов. Получится как будто перспектива такая. Какие-то другие алгоритмы за другие характерные части номера цепляются (хотя за рамку довольно часто).
Не знаю. вот конкретно второй алгоритм — как-то схитрить с границами. Границы слева-справо, например. Скосы подрисовать черной краской на номере или белой под 30 градусов. Получится как будто перспектива такая. Какие-то другие алгоритмы за другие характерные части номера цепляются (хотя за рамку довольно часто).
Спасибо за весь цикл статей, очень познавательно и интересно.
У меня вопрос по обучению каскада Хаара: каким образом вы выбирали лучшие характеристики для тренировки (пропорции сэмплов, размеры сэмплов, количество стадий, maxFalseAlarm и тд)?
У меня вопрос по обучению каскада Хаара: каким образом вы выбирали лучшие характеристики для тренировки (пропорции сэмплов, размеры сэмплов, количество стадий, maxFalseAlarm и тд)?
решили не изобретать велосипед и воспользоваться утилитой из OpenCV. Она как-то сама. Хотя здесь как раз неприятное место — действительно оно как-то обучилось… а хорошо или плохо — ктож знает. Как раз сижу разбираюсь уже пару дней, что можно/нельзя сделать с этим Хааром.
Примерно так же как я писал в этой статье — habrahabr.ru/post/208092/
А настроечные параметры очень зависят от базы. Там изменится база на 100 объектов — всё уже значительно уйдёт.
А настроечные параметры очень зависят от базы. Там изменится база на 100 объектов — всё уже значительно уйдёт.
а я бы попробовал сервис распознавания капч для распознавания номеров… Уж больно любопытно, заработает ли эта связка(вырезанный номер вместо капчи)
А данные (картинки) выложите в открытый доступ?
НЛО прилетело и опубликовало эту надпись здесь
Два вопроса:
1) Предполагает ли ваш алгоритм калибровку камеры для устранения дисторсий, чтобы лини на изображении были прямыми?
2) Почему вы не используете ректификацию (гомографию в плоскость сенсора) изображения? По крайней мере в статье она не упоминается.
Просто я недавно экспериментировал с ректификацией изображения (гомографией) и мне казалось, что это должен быть неотъемлемый этап в процессе распознавания плоского номера.
Недавно получил “письмо счастья” (комплекс Стрелка СТ). Судя по фото они этого не делают. Понятно, что камеры длиннофокусные и расположены четко по методике, но мне все же кажется, что смысл есть.
1) Предполагает ли ваш алгоритм калибровку камеры для устранения дисторсий, чтобы лини на изображении были прямыми?
2) Почему вы не используете ректификацию (гомографию в плоскость сенсора) изображения? По крайней мере в статье она не упоминается.
Просто я недавно экспериментировал с ректификацией изображения (гомографией) и мне казалось, что это должен быть неотъемлемый этап в процессе распознавания плоского номера.
Недавно получил “письмо счастья” (комплекс Стрелка СТ). Судя по фото они этого не делают. Понятно, что камеры длиннофокусные и расположены четко по методике, но мне все же кажется, что смысл есть.
1) Дисторсию нельзя устранить без знания геометрии линзы, или без набора тестовых фотографий шаблона с известным изображением. Ни то ни другое невозможно сделать для десятков разных моделей телефонов. С другой стороны, дисторсию на 90% сегодняшних устройств делают программно и вшито. 100% веб-камер с которыми мы имели дело при попытки откалиброваться OpenCV-алгоритмом подавления дисторсии давали нулевые её коэффициенты: преобразование делается внутри камер.
2) Для того чтобы сделать гомографию номера сначала нужно точно найти его границы. После точного нахождения границ определить буквы уже не представляет никакой сложности. Но зачастую проблема в том, что границы нечёткие, много теней, граница загораживается рамками автомобиля. При её нахождении будет крупная погрешность. В нашем алгоритме используется перебор гипотез по масштабу (это описано в статье). По сути это является неявной гомографией.
2) Для того чтобы сделать гомографию номера сначала нужно точно найти его границы. После точного нахождения границ определить буквы уже не представляет никакой сложности. Но зачастую проблема в том, что границы нечёткие, много теней, граница загораживается рамками автомобиля. При её нахождении будет крупная погрешность. В нашем алгоритме используется перебор гипотез по масштабу (это описано в статье). По сути это является неявной гомографией.
кстати это кто-то нам отправил желтый номер такси, насколько я понял — формат не штатный
Вобще, есть очень много форматов номерных знаков.
НЛО прилетело и опубликовало эту надпись здесь
У меня несколько вопросов:
1) Удается ли распознавать смазанные номера, когда камера тряслась при съемке, типа такого:
2)Удается ли распознать расфокусированные номера:
3) Аналогичный вопрос — для непрямых, изогнутых номеров:
4) Что вы делаете с афинными искажениями (skew):
5) Ну и наконец номера типа таких удается распознать?
Спасибо.
1) Удается ли распознавать смазанные номера, когда камера тряслась при съемке, типа такого:
Скрытый текст

2)Удается ли распознать расфокусированные номера:
Скрытый текст

3) Аналогичный вопрос — для непрямых, изогнутых номеров:
Скрытый текст

4) Что вы делаете с афинными искажениями (skew):
Скрытый текст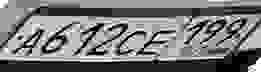

5) Ну и наконец номера типа таких удается распознать?
Скрытый текст

Скрытый текст

Скрытый текст

Спасибо.
Васи нет, отвечу я. Может чуть позже он добавит мой ответ изображениями, что распознаётся, что нет.
Так, начну в принципе с этого:
193.138.232.71:10000/uploadimage — сюда можно загрузить полноразмерную картинку и проверить как выделяется + распознаётся
193.138.232.71:10000/result — сюда можно загрузить обрезанный кусок и посмотреть на то, как распознаётся номер у него
1-2) С настолько жесткими примерами, думаю, не справится. Но за счёт того, что буквы мы анализируем без бинаризации со многими размазанными и смазанными оно всё же работает.
3) Не всегда, но часто работает. Так как достаточно много гипотез по размеру и сдвигу буквы, то если поворот осуществлён более-менее правильно, то схватится.
4) Нет, с такими сильными искажениями мы пока не занималсь.
5) 1 и 3 — нет, считается, что буква должна быть темнее номера. 2 — как повезёт конкретно этот нет, но зачастую бывают примеры где алгоритм справляется.
В целом, хотел бы повторится, что у нас очень простой алгоритм, не заточенный под редкие ситуации. Потихоньку мы его допиливаем, в свободное время, но от какой-бы то ни было универсальности он далёк:)
Так, начну в принципе с этого:
193.138.232.71:10000/uploadimage — сюда можно загрузить полноразмерную картинку и проверить как выделяется + распознаётся
193.138.232.71:10000/result — сюда можно загрузить обрезанный кусок и посмотреть на то, как распознаётся номер у него
1-2) С настолько жесткими примерами, думаю, не справится. Но за счёт того, что буквы мы анализируем без бинаризации со многими размазанными и смазанными оно всё же работает.
3) Не всегда, но часто работает. Так как достаточно много гипотез по размеру и сдвигу буквы, то если поворот осуществлён более-менее правильно, то схватится.
4) Нет, с такими сильными искажениями мы пока не занималсь.
5) 1 и 3 — нет, считается, что буква должна быть темнее номера. 2 — как повезёт конкретно этот нет, но зачастую бывают примеры где алгоритм справляется.
В целом, хотел бы повторится, что у нас очень простой алгоритм, не заточенный под редкие ситуации. Потихоньку мы его допиливаем, в свободное время, но от какой-бы то ни было универсальности он далёк:)
C757PP 949 54% B444HP 77 53%


Добрый день!
а можно как-нибудь получить Вашу базу изображений, а то хочется поиграться с настройками Хаара, а самому собирать такую базу очень муторно?
а можно как-нибудь получить Вашу базу изображений, а то хочется поиграться с настройками Хаара, а самому собирать такую базу очень муторно?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Распознавание автомобильных номеров в деталях