
 Антон Чайников, разработчик Data Science, Redmadrobot
Антон Чайников, разработчик Data Science, Redmadrobot
Привет, Хабр! Сегодня я расскажу о терниях на пути к чатботу, облегчающему работу операторам чата страховой компании. А точнее, как мы учили бота отличать друг от друга запросы с помощью машинного обучения. С какими моделями экспериментировали и какие получили результаты. Как сделали четыре подхода к чистке и обогащению данных приличного качества и пять попыток чистки данных качества «неприличного».
Задача
В чат страховой компании приходит +100500 клиентских обращений в день. Большинство вопросов простейшие и повторяющиеся, но операторам от этого не легче, и клиентам всё равно приходится ждать по пять-десять минут. Как повысить качество сервиса и оптимизировать трудозатраты, чтобы у операторов было меньше рутинной работы, а у пользователей — больше приятных ощущений от быстрого решения их вопросов?
А сделаем-ка мы чатбота. Пусть читает сообщения пользователей, для простых случаев выдаёт инструкции, а для сложных — задаёт стандартные вопросы, чтобы получить нужные оператору сведения. У живого оператора есть дерево сценариев — скрипт (или блок-схема), в котором написано, какие вопросы могут задавать пользователи и как на них реагировать. Мы бы взяли эту схему и положили в чатбот, да вот незадача — чатбот не понимает по-человечески и не умеет соотносить вопрос пользователя с веткой сценария.
Значит, будем его учить с помощью старого доброго машинного обучения. Но нельзя просто взять кусок данных, сгенерированный пользователями, и научить на нём модель приличного качества. Для этого с архитектурой модели нужно экспериментировать, данные — чистить, а иногда и собирать заново.
Как учить бота:
- Рассмотрим варианты моделей: как сочетаются размер датасета, детали векторизации текстов, понижение размерности, классификатор и конечная точность.
- Почистим приличные данные: найдём классы, которые можно спокойно выбросить; узнаем, почему последние полгода разметки лучше предыдущих трёх; определим, где врёт модель, а где разметка; выясним, чем могут быть полезны опечатки.
- Почистим «неприличные» данные: разберёмся, в каких случаях кластеризация полезна и бесполезна, как разговаривают пользователи и операторы, когда пора перестать страдать и пойти собирать разметку.
Фактура
Клиентов — страховых компаний с онлайн-чатами — и проектов по обучению чатботов у нас было два (называть их не будем, это не принципиально), с резко разным качеством данных. Хорошо, если половину проблем второго проекта удалось решить манипуляциями из первого. Подробности — ниже.
С технической точки зрения наша задача — классифицировать тексты. Это делается в два этапа: сначала тексты векторизуются (с помощью tf-idf, doc2vec и т.д.), затем на полученных векторах (и классах) обучается классифицирующая модель — случайный лес, SVM, нейронная сеть, и проч. и проч.
Откуда берутся данные:
- Sql-выгрузка истории сообщений в чате. Релевантные поля выгрузки: текст сообщений; автор (клиент или оператор); группировка сообщений в диалоги; таймстамп; категория обращения клиента (вопросы про ОСАГО, КАСКО, ДМС; вопросы о работе сайта; вопросы про программы лояльности; вопросы про изменение условий страхования и т. д.).
- Дерево сценариев, или последовательности вопросов-ответов операторов клиентам с разными запросами.
Без валидации, конечно, никуда. Все модели обучались на 70% данных и оценивались по результатам на оставшихся 30%.
Метрики качества моделей, которые мы использовали:
- При обучении: логлосс, за дифференцируемость;
- При написании отчётов: точность классификации на тестовой выборке, за простоту и понятность (в т.ч. для заказчика);
- При выборе направления дальнейших действий: интуиция дата-сайентиста, пристально глядящего в результаты.
Эксперименты с моделями
Редко, когда по задаче сразу понятно, какая модель даст лучшие результаты. Так и здесь: без экспериментов никуда.
Будем пробовать варианты векторизации:
- tf-idf на отдельных словах;
- tf-idf на тройках символов (далее: 3-граммы);
- tf-idf на 2-, 3-, 4-, 5-граммах по отдельности;
- tf-idf на 2-, 3-, 4-, 5-граммах, взятых все вместе;
- Всё вышеперечисленное + приведение слов в исходном тексте к словарной форме;
- Всё вышеперечисленное + снижение размерности методом Truncated SVD;
- С числом измерений: 10, 30, 100, 300;
- doc2vec, тренированный на корпусе текстов из задачи.
Варианты классификации на этом фоне выглядят довольно бедно: SVM, XGBoost, LSTM, случайные леса, наивный байес, случайный лес поверх предсказаний SVM и XGB.
И хотя мы и проверяли воспроизводимость результатов на трёх независимо собранных датасетах и их фрагментах, поручиться за широкую применимость возьмёмся лишь отчасти.
Результаты экспериментов:
- В цепочке «предобработка-векторизация-понижение размерности-классификация» эффект от выбора на каждом шаге почти не зависит от остальных шагов. Что очень удобно, можно не перебирать десяток вариантов при каждой новой идее и на каждом шаге использовать лучший известный вариант.
- tf-idf на словах проигрывает 3-граммам (точность 0.72 vs 0.78). 2-, 4-, 5-граммы проигрывают 3-граммам (0.75–0.76 vs 0.78). {2;5}-граммы все вместе совсем немного выигрывают у 3-грамм. С учётом резкого увеличения необходимой памяти, для тренировки выигрышем в 0.4% точности мы решили пренебречь.
- По сравнению с tf-idf всех сортов doc2vec был беспомощен (точность 0.4 и ниже). Стоило бы попробовать тренировать его не на корпусе из задачи (~250000 текстов), а на сильно большем (2.5–25 миллионов текстов), но пока, увы, руки не дошли.
- Truncated SVD не помогло. Точность монотонно растёт с ростом измерений, плавно выходя на точность без TSVD.
- Среди классификаторов XGBoost побеждает с заметным отрывом (+5–10%). Ближайшие конкуренты — SVM и случайные леса. Наивный байес — не конкурент даже случайным лесам.
- Успех LSTM сильно зависит от размера датасета: на выборке в 100000 объектов оно способно конкурировать с XGB. На выборке в 6000 — в отстающих вместе с байесом.
- Случайный лес поверх SVM и XGB или всегда соглашается с XGB, или ошибается больше. Это весьма печально, мы надеялись, что SVM найдёт в данных хоть какие-то закономерности, недоступные XGB, но увы.
- У XGBoost всё сложно со стабильностью. Например, его обновление с версии 0.72 до 0.80 необъяснимым образом снизило точность тренируемых моделей на 5–10%. И ещё: XGBoost поддерживает изменение параметров тренировки в процессе тренировки и совместимость со стандартным API scikit-learn, но строго по отдельности. Сделать и то, и другое вместе нельзя. Пришлось исправить.
- Если привести слова к словарной форме, это немного улучшает качество, в сочетании с tf-idf на словах, но бесполезно во всех остальных случаях. В конце концов мы его отключили для экономии времени.
Опыт 1. Чистка данных, или что делать с разметкой
Операторы чата — всего лишь люди. При определении категории пользовательских запроса они часто ошибаются и по-разному понимают границы между категориями. Поэтому исходные данные приходится безжалостно и интенсивно чистить.
Наши данные на обучения модели на первом проекте:
- История сообщений онлайн-чата за несколько лет. Это 250000 сообщений в 60000 диалогах. В конце диалога оператор выбирал категорию, к которой относится обращение пользователя. В этом датасете около 50 категорий.
- Дерево сценариев. В нашем случае у операторов не было рабочих скриптов.
Чем именно данные плохи, мы формулировали в качестве гипотез, далее проверяли и, где могли, исправляли. Вот что получилось:
Подход первый. Из всего огромного списка классов можно безболезненно оставить 5–10.
Отбрасываем маленькие классы (<1% выборки): мало данных + маленький импакт. Объединяем сложноотличимые классы, на которые операторы всё равно реагируют одинаково. Например:
'дмс' + 'как записаться к врачу' + 'вопрос по наполнению программы'
'аннулирование' + 'статус аннулирования' + 'аннулирование оплаченного полиса'
'вопрос по продлению' + 'как продлить полис?'
Далее выбрасываем классы типа «другое», «прочее» и тому подобное: для чатбота они бесполезны (всё равно перенаправлять на оператора), и при этом сильно портят точность, поскольку 20% (30, 50, 90) запросов операторы классифицируют не куда положено, а сюда. Теперь выбрасываем класс, с которыми чатбот работать (пока) не может.
Результат: в одном случае — рост с точности 0.40 до 0.69, в другом — с 0.66 до 0.77.
Подход второй. В начале работы чата операторы сами плохо понимают, как выбирать класс для обращения пользователя, поэтому в данных много «шума» и ошибок.
Эксперимент: берём только последние два (три, шесть, …) месяцев диалогов и обучаем модель на
них.
Результат: в одном примечательном случае точность возросла с 0.40 до 0.60, в другом — с 0.69 до 0.78.
Подход третий. Иногда точность 0.70 означает не «в 30% случаев модель ошибается», а «в 30% случаев разметка врёт, а модель очень разумно её поправляет».
Метриками типа точности или логлосса эту гипотезу не проверишь. Для целей эксперимента мы ограничились пристальным взглядом дата-сайентиста, но в идеальном случае здесь нужно качественно переразметить датасет, не забывая о кроссвалидации.
Для работы с такими выборками мы придумали процесс «итеративного обогащения»:
- Разбить датасет на 3–4 фрагмента.
- Натренировать модель на первом фрагменте.
- Предсказать тренированной моделью классы второго.
- Пристально посмотреть на предсказанные классы и степень уверенности модели, выбрать граничное значение уверенности.
- Убрать из второго фрагмента тексты (объекты), предсказанные с уверенностью ниже граничной, натренировать модель на этом.
- Повторять, пока не надоест или не закончатся фрагменты.
С одной стороны, результаты получаются прекрасные: модель первой итерации имеет точность 70%, второй — 95%, третей — 99+%. Пристальный взгляд на результаты предсказаний такую точность вполне подтверждают.
С другой стороны, как в этом процессе систематически убедиться, что последующие модели не выучиваются заблуждениям предыдущих? Есть идея проверить процесс на вручную «зашумлённом» датасете с качественной исходной разметкой, типа MNIST. Но времени на это, увы, не хватало. А без верификации мы не рискнули запускать итеративное обогащение и полученные модели в продакшен.
Подход четвёртый. Датасет можно расширить — и тем самым повысить точность и уменьшить переобучение, добавив к имеющимся текстам множество вариантов опечаток.
Варианты опечаток — удвоение буквы, пропуск буквы, перестановка соседних букв местами, замена буквы на соседнюю на клавиатуре.
Эксперимент: Доля p букв, в которых произойдёт опечатка: 2%, 4%, 6%, 8%, 10%, 12%. Увеличение датасета: обычно до размера 60000 реплик. В зависимости от исходного размера (после фильтров) это означало увеличение в 3–30 раз.
Результат: зависит от датасета. На маленьком датасете (~300 реплик) 4–6% опечаток дают стабильный и существенный рост точности (0.40 → 0.60). На больших датасетах всё хуже. При доле опечаток 8% или больше тексты превращаются в ахинею и точность падает. При доле ошибок 2–8% точность колеблется в диапазоне нескольких процентов, очень редко превосходит точность без опечаток и, по ощущениям, не стоит увеличения времени тренировки в несколько раз.
В итоге получаем модель, различающую 5 классов обращений с точностью 0.86. Согласовываем с клиентом тексты вопросов и ответов по каждой из пяти развилок, прикручиваем тексты к чатботу, отправляем в QA.
Опыт 2. По колено в данных, или что делать без разметки
Получив на первом проекте неплохие результаты, ко второму мы подошли со всей уверенностью. Но, к счастью, мы не разучились удивляться.
С чем мы встретились:
- Дерево сценариев с пятью ветками, согласованное с клиентом около года назад.
- Размеченная выборка из 500 сообщений и 11 классов неизвестного происхождения.
- Размеченная операторами чата выборка из 220000 сообщений, 21000 диалогов и 50 других классов.
- SVM-модель, тренированная на первой выборке, с точностью 0.69, которая досталась в наследство от предыдущей команды дата-сайентистов. Почему именно SVM, история умалчивает.
Первым делом смотрим на классы: в дереве сценариев, в выборке SVM-модели, в основной выборке. И вот что видим:
- Классы SVM-модели примерно соответствуют веткам сценариев, но никак не соответствуют классам из большой выборки.
- Дерево сценариев писалось по бизнес-процессам годичной давности, и устарело почти до бесполезности. SVM-модель устарела вместе с ним.
- Два наибольших класса в большой выборке — это «Продажи» (50%) и «Прочее» (45%).
- Из пяти следующих по размеру классов три настолько же общие, как и «Продажи».
- Остальные 45 классов содержат менее 30 диалогов каждый. Т.е. дерева сценариев у нас нет, списка классов нет и разметки нет.
Что делать в таких случаях? Мы засучили рукава и пошли самостоятельно вытаскивать классы и разметку из данных.
Попытка первая. Попробуем-ка кластеризовать вопросы пользователей, т.е. первые сообщения в диалоге, за исключением приветствий.
Проверяем. Векторизируем реплики подсчётом 3-грамм. Понижаем размерность до первых десяти измерений TSVD. Кластеризируем аггломеративной кластеризацией с евклидовым расстоянием и целевой функцией Варда. Ещё раз понижаем размерность с помощью t-SNE (до двух измерений, чтобы на результаты можно было смотреть глазами). Рисуем точки-реплики на плоскости, раскрасив в цвета кластеров.
Результат: страх и ужас. Вменяемых кластеров, можно считать, что нет:
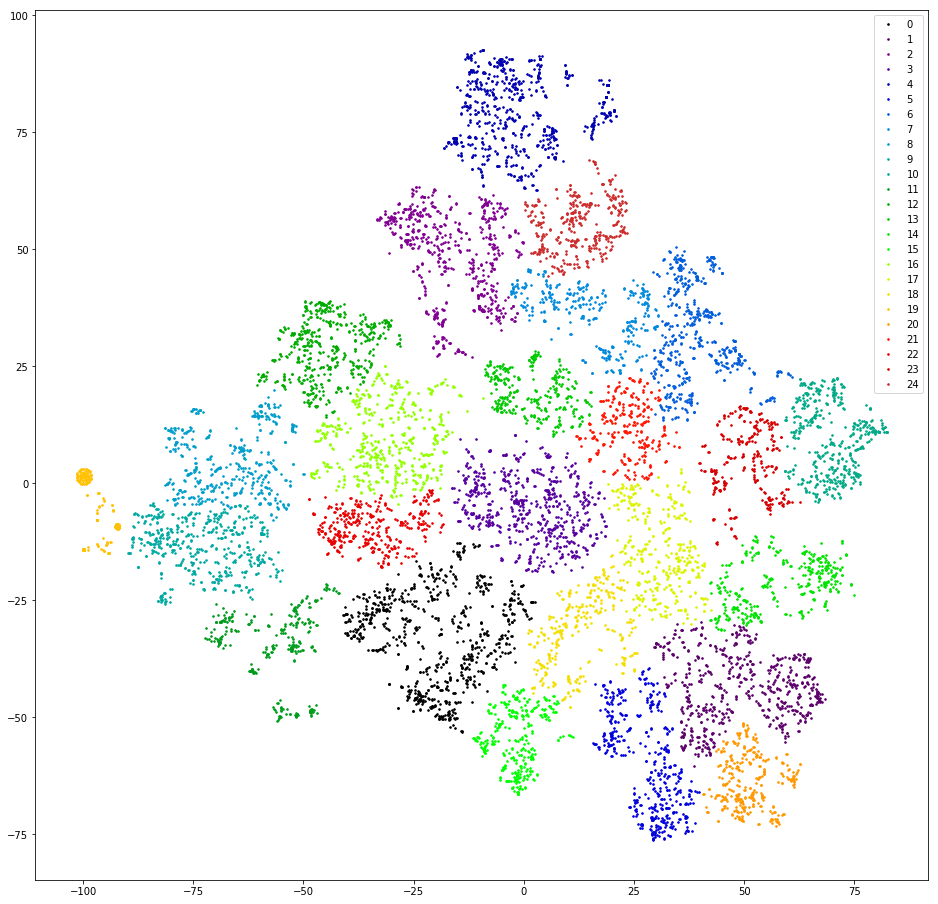
Почти нет — есть один, оранжевый слева, это потому, что все сообщения в нём содержат 3-грамму «@». Эта 3-грамма — артефакт предобработки. Где-то в процессе фильтрации знаков препинания «@» не только не отфильтровалась, но ещё и обросла пробелами. Зато артефакт полезный. В этот кластер попали пользователи, которые первым сообщением пишут свою электронную почту. К сожалению, только по наличию почты совсем непонятно, какой у пользователя запрос. Двигаемся дальше.
Попытка вторая. А вдруг операторы часто отвечают более-менее стандартными ссылками?
Проверяем. Вытаскиваем из сообщений операторов ссылко-подобные подстроки, немного правим ссылки, разные по написанию, но одинаковые по смыслу (http/https, /search?city=%city%), считаем частотности ссылок.
Результат: малоперспективно. Во-первых, операторы отвечают ссылками лишь на малую долю запросов (<10%). Во-вторых, даже после ручной чистки и отсеивания ссылок, встретившихся единожды, их остаётся больше тридцати. В-третьих, в поведении пользователей, которые заканчивают диалог ссылкой, нет особенного сходства.
Попытка третья. Поищем стандартные ответы операторов — вдруг они будут индикаторами какой-никакой классификации сообщений?
Проверяем. В каждом диалоге берём последнюю реплику оператора (не считая прощаний: «могу ещё чем-нибудь помочь» и т.п.) и считаем частотность уникальных реплик.
Результат: перспективно, но неудобно. 50% ответов операторов уникальны, ещё 10–20% встречаются дважды, оставшиеся 30–40% покрываются сравнительно небольшим количеством популярных шаблонов. Сравнительно небольшим — примерно тремястами. При пристальном взгляде на эти шаблоны видно, что многие из них являются вариантами одного и того же по смыслу ответа — отличаются где на одну букву, где на одно слово, где на один абзац. Хочется сгруппировать эти близкие по смыслу ответы.
Попытка четвёртая. Кластеризуем последние реплики операторов. Эти кластеризуются гораздо лучше:
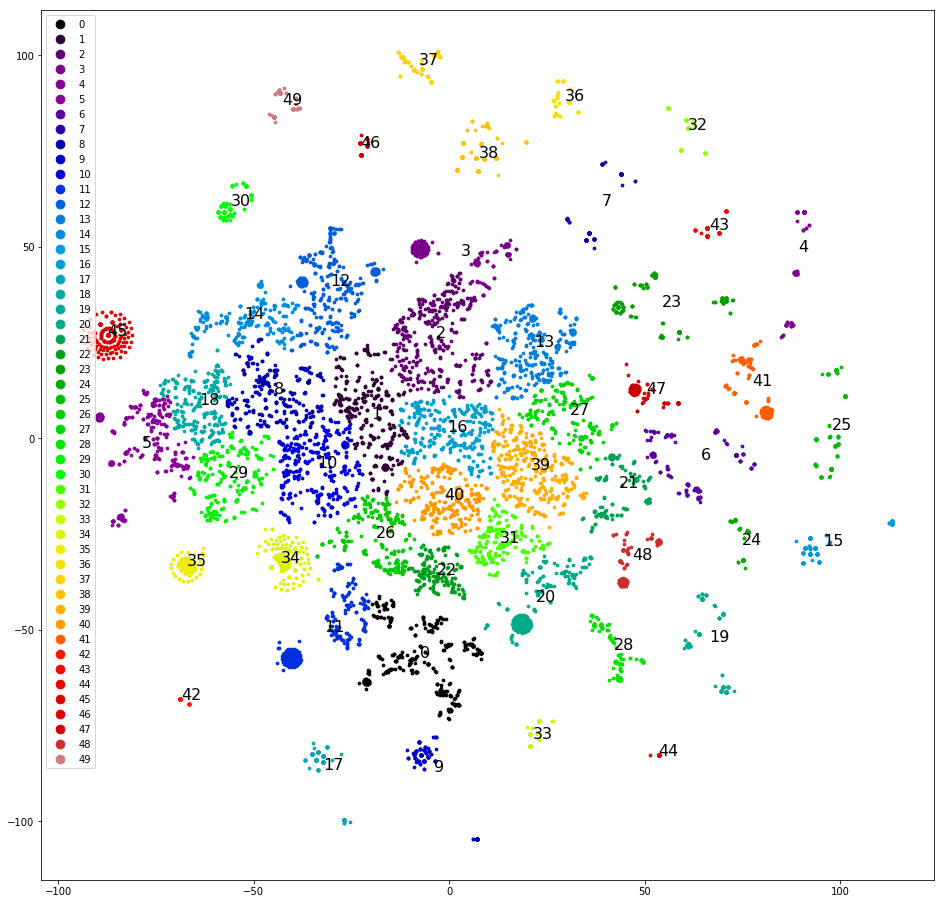
С этим уже можно работать.
Кластеризуем и рисуем реплики на плоскости, как в первой попытке, вручную определяем наиболее чётко отделившиеся кластеры, убираем их из датасета и кластеризуем заново. После отделения примерно половины датасета чёткие кластеры заканчиваются, и мы начинаем думать, какие бы им назначить классы. Разбрасываем кластеры по оригинальным пяти классам — выборка «перекошена», и три из пяти оригинальных классов не получают ни одного кластера. Плохо. Разбрасываем кластеры по пяти классам, которые намечаем произвольно, на: «звоните», «приезжайте», «ждите ответа сутки», «проблемы с капчей», «другое». Перекос поменьше, но точность всего 0.4–0.5. Опять плохо. Назначаем каждому из 30+ кластеров свой класс. Выборка снова «перекошена», и точность снова 0.5, хотя около пяти избранных классов имеют приличные точность и полноту (0.8 и выше). Но результат по-прежнему не впечатляет.
Попытка пятая. Нам нужна вся подноготная кластеризации. Извлекаем полную дендрограмму кластеризации вместо верхних тридцати кластеров. Сохраняем её в формате, доступном для аналитиков клиента, и помогаем им сделать разметку — делаем набросок списка классов.
Для каждого сообщения мы вычисляем цепочку кластеров, в которые входит каждое сообщение, начиная с корневого. Строим таблицу со столбцами: текст, id первого кластера в цепочке, id второго кластера в цепочке, ..., id кластера, соответствующего тексту. Сохраняем таблицу в csv/xls. Дальше с ней можно работать офисными инструментами.
Данные и набросок списка классов отдаём для разметки клиенту. Аналитики клиента разметили заново ~10000 первых сообщений пользователей. Мы, уже наученные опытом, попросили размечивать каждое сообщение минимум дважды. И не зря — 4000 из этих 10000 приходится выбросить, потому что два аналитика разметили по-разному. На оставшихся 6000 мы довольно быстро повторили успехи первого проекта:
- Baseline: никак не фильтруем — точность 0.66.
- Объединяем классы, одинаковые с точки зрения оператора. Получаем точность 0.73.
- Убираем класс «Прочее» — точность растёт до 0.79.
Модель готова, теперь нужно нарисовать дерево сценариев. По причинам, которые не возьмёмся объяснить, у нас не было доступа к скриптам ответов операторов. Мы не растерялись, притворились пользователями и за пару часов в поле собрали шаблоны ответов и уточняющие вопросы операторов на все случаи жизни. Оформили их в дерево, запаковали в бота и отправились тестировать. Клиент одобрил.
Выводы, или что показал опыт:
- Экспериментировать с частями модели (предобработка, векторизация, классификация и пр.) можно по отдельности.
- XGBoost по-прежнему правит бал, хотя если вам от него нужно что-то необычное, у вас проблемы.
- Пользователь — это периферийное устройство хаотического ввода, так что чистить пользовательские данные нужно обязательно.
- Итеративное обогащение — это круто, хотя и опасно.
- Иногда стоит отдать данные обратно на разметку клиенту. Но не забывайте ему помочь получить качественный результат.
To be concluded.
