Привет! Недавно мы провели небольшой митап для фронтендеров, куда пригласили троих интересных спикеров. Наш коллега Игорь Борзунов рассказал о том, как решать проблемы с плохим качеством изображений. Даниил Водолазкин из X5Tech поведал о неочевидных сложностях работы с GraphQL. И завершил программу Георгий Конюшков из «Леруа Мерлен» с темой «Time to market: микрофронтенды». В этом посте мы свели основные тезисы всех трех докладов.

Для начала — пара слов о том, что это у нас в банке за гильдии. Гильдии — это сообщества по профессиональным интересам, которые обмениваются знаниями, делают опенсорс-проекты в рамках контура банка, организуют менторинг и другие профессиональные активности. В том числе и митапы. А теперь слово спикерам.
Шакализация 21 века: решаем вечные проблемы изображений
На httparchive.org можно посмотреть статистику того, как менялся размер изображений за 11 лет развития интернета. В среднем он вырос с 225 до 979 Кб — и по моим наблюдениям это еще скромная оценка:

Теперь посмотрим на конкретные примеры разных лет. Вот картинка с сайта CNN тех лет — достаточно четкая для своих размеров, все отлично видно:

А вот пример современной иллюстрации с новостного портала «Афиша Daily». Размер несколько больше и объем достигает уже 2,2 Мб:

Почему размер картинок так быстро растет? Есть несколько причин. Появляются новые кодеки, которые пытаются сделать изображения качественней, в том числе за счет занимаемой памяти.
Вторая причина в том, что с каждым новым сохранением одной и той же картинки увеличивается ее объем (и за счет появления новых артефактов снижается качество). Фронтендеры традиционно с этим не парятся — в СНГ мы привыкли к скоростному интернету. Ну подождут люди с 3G чуть дольше, ничего критичного.
С этим связан случай из жизни. Я работаю в команде депозитов нашего интернет-банка для юридических лиц. В разговоре с одним клиентом я узнал, что у него уходит 3–4 минуты, чтобы разместить депозит в нашем приложении. Это показалось мне странным, я привык, что эта операция занимает несколько секунд. Я начал расспрашивать подробности: оказалось, что скорость соединения клиента составляет в лучшем случае 2–3 Мбит/с. Я ограничил в devtools скорость своего интернета и решил пройти этот путь глазами пользователя.

Вот отчет по скорости загрузки ассетов. JPEG в 48 Кб грузится секунд шесть, 332 Кб — уже секунд 15. И это только экран авторизации. Дальше свои картинки есть у главной страницы, у разделов… так и набегает несколько минут. Со скоростным же интернетом все гораздо оптимистичней:

Но мы говорим о банковском приложении, и любая просроченная операция здесь может обернуться ударом по репутации. Допускать такое не стоит. И если у разработчика приложение уже хоть немного тормозит, у клиента все наверняка станет хуже.
Что с этим делать? Первое, что приходит в голову — рефакторинг или исправление багов. Долго, дорого и не факт, что чего-то добьемся. Можно свалить вину на бэкенд :) Или… оптимизировать приложение. Давайте остановимся на последнем варианте и продумаем, что можно сделать в рамках этой оптимизации:
изменить подход к форматированию изображений, проанализировать, какие вообще есть изображения;
пережать все еще раз;
лучше встроить графику в экосистему проекта.
Остановимся пока на сжатии изображений. Будем говорить, в основном, о сжатии с потерей качества, хотя есть методы и без потери. Начнем, конечно, с самого популярного формата — JPEG, в котором закодировано 90% всей интернет-графики. Сжатие в JPEG происходит в несколько этапов:
замена цветового формата,
сабсемплинг,
блочное деление,
преобразование блоков,
квантизация.
Есть и другие, более новые форматы, которые также становятся популярными — WebP и Avif. Здесь встает вопрос поддержки форматов различными браузерами:

WebP поддерживается всеми браузерами кроме IE и некоего KaiOS. В целом, приемлемо. Чем отличается формат WebP сам по себе? Он работает примерно так же, как JPEG, но с некоторыми техническими фишками типа предикшенов и зигзаг-сравнений.

Теперь Avif — чуть более современный и менее популярный:

Поддержка браузерами здесь примерно в два раза хуже, чем у WebP, и это уже становится проблемой. Safari, Opera, Edge — за бортом. Теперь о том, как работает Avif:

Здесь используется сабсемплинг с разными характеристиками. На следующей картинке можно увидеть, как они влияют на результат:

Если сопоставить три формата по размеру, то WebP в среднем получается на 30% компактнее JPEG. Но Avif еще меньше JPEG — в среднем почти в два раза! Avif здесь предпочтительней, посмотрим теперь на характеристики сжатия:

У JPEG нет никакого предсказания в алгоритме, все довольно топорно, а также имеется только одна произвольная матрица, без зигзаг-сравнений, которые я упоминал выше. Везде используется дискретно-косинусное преобразование, но у WebP и AviF есть также другие возможности.
Теперь попробуем развернуть WebP на проекте. Самый простой и незатратный вариант — сделать это через готовый плагин, например, популярный imagemin:
const ImageminWebpWebpackPlugin= require("imagemin-webp-webpack-plugin");
module.exports = {
plugins: [new ImageminWebpWebpackPlugin()]
};Посмотрим, сколько плагин сэкономил места. Локально экономится чуть меньше, в продакшене чуть больше. У нас в проекте получилось 44 Мб, и это уже неплохо.
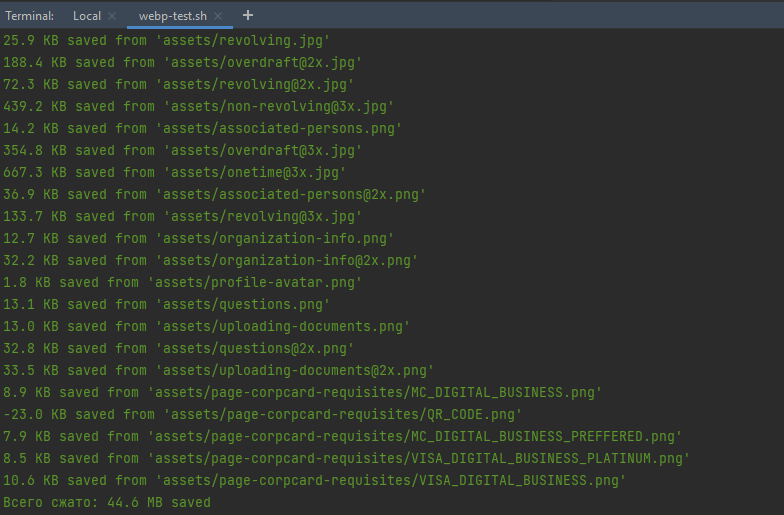
Для сравнения я протестировал и компрессию в Avif:
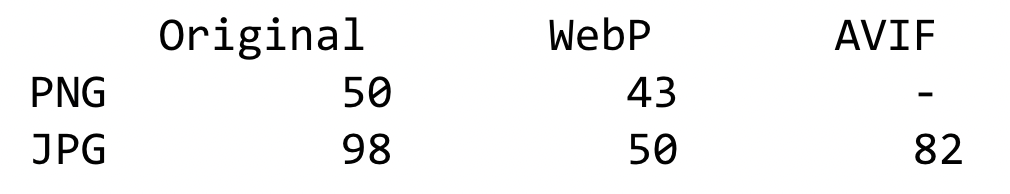
Стоит оговориться, что даже сами разработчики Avif не рекомендуют использовать его в продакшен-средах из-за текущей сырости и нестабильности. Вроде бы очевиден выбор в пользу WebP, но есть проблема — отсутствие поддержки Internet Explorer. А это все-таки второй по популярности браузер у наших клиентов.
Проблему можно решить через middleware, а точнее, с помощью nginx. Берем nginx-конфиг и через map указываем, что у нас есть WebP, а потом на уровне сервера через location и try_files подставляем нужные суффиксы и получаем Web
http {
map
default "";
"~image/webp" ".webp";
}
}
server {
# […]
location ~ ^/images/.*\.(png|jpe?g)" class="formula inline"> {
add_header Vary Accept;
try_files webp_suffix webp_suffix $uri =404;
}
}В результате вместо JPEG в content type у нас будет WebP:

Теперь для всех современных браузеров с поддержкой WebP мы отдаем этот формат, а остальные получают тот же JPEG.

Какие выводы можно сделать?
Сжатие изображений полезно для всех. Даже в строгом интернет-банке польза вполне ощутима, не говоря уже о более художественных сайтах с гифками-анимациями-видео.
Новые форматы все еще слабовато поддерживаются.
Самое важное: оптимизация форматов проста в реализации, можно потестировать ее с помощью готовых библиотек, а в дальнейшем уже сделать свой загрузчик.
А теперь — секция вопросов и ответов:
Разве не лучше использовать для сжатия SVG? — Не все можно легко преобразовать в векторную графику, к тому же на больших картинках экономии почти не будет.
Нормально ли сжимать картинки на уровне клиентского приложения после того, как их выбрали из файловой системы и отправили на бэкенд? — Нормально :)
Были ли ситуации, что переформатированные в WebP картинки весят больше, чем PNG? — Не было.
А как насчет Progressive JPEG? — У разработчиков формата много новых наработок, но здесь также возникает проблема в поддержке браузерами. Яркий пример — JPEG XL. К тому же многие пишут про сырость этого алгоритма. Так же как и с Avif, о внедрении на продакшен говорить рановато, но поиграться можно.
Если пользователь захочет скачать с вашего сайта картинке в формате WebP, нужно ли будет что-то дополнительно? — Нет, браузер сделает всё сам без проблем.
Насколько в итоге уменьшилось время загрузки интернет-банка? — В среднем на одной странице время загрузки уменьшилось на 10–30%, если судить по синтетическим тестам dev-tools.
Неочевидные сложности в работе с GraphQL
В этом выступлении я поделюсь опытом работы X5Tech с GraphQL на примере системы планирования ассортимента торговой сети «Пятерочка», самыми классными моментами и также проблемами, которые возникли в неожиданных местах.
Торговая сеть насчитывает 17600 магазинов в 7 федеральных округах России с ассортиментом от 3000 до 7000 наименований в каждом. Как следствие, мы получаем очень много данных. У нас есть bigdata-команда, которая собирает нужные показатели, аналитику, прогнозы и т.д. Мы на фронтенде работаем с такими сущностями как, например, товары. У каждого может быть сотня показателей, которые нужно отображать, модифицировать. Кроме того, с рядом сущностей приходится работать в реальном времени, то есть иметь всегда свежие данные.
Почему мы выбрали GraphQL? Когда-то мы начинали с обычным REST API, но постепенно пришли к тому, что в разных местах нам нужно по-разному преобразовывать похожие данные. В результате API стал обрастать большим количеством ручек и мы встали перед выбором:
Делаем ручки под каждую потребность, что приводит в долгой доработке бэкенда под каждую фичу.
Объединяем данные из атомарных запросов, что сильно нагрузит клиент для обработки данных.
Оба пути нас не устроили, поэтому было решено отказаться от REST. В этой ситуации переход на GraphQL дал сразу несколько важных преимуществ:
Уменьшились затраты на разработку бэкенда для каждой отдельной фичи.
Исчезли проблемы с over-fetching и under-fetching. У нас много данных, есть таблицы в десятки тысяч строк — в таких условиях приходится учитывать любые лишние данные в запросах.
Мы получили готовую инфраструктуру — Apollo-сервер, Apollo-клиент, кэш, подписки, обработка ошибок, сетевые статусы и т.д.
Как основу для демонстрационного приложения я использую The Rick and Morty API. Он умеет и в REST, и в GraphQL, предлагает удобную площадку для экспериментов, всем советую. На площадке вы можете запрашивать данные по известному мультсериалу. Вот как примерно выглядит подробно описанный запрос:
query {
characters {
results {
id
name
status
species
type
image
episode {
id
name
air_date
episode
created
}
created
}
}
}И вот такой такой ответ можно получить:
{
"data": {
"characters": {
"results": [
{
"id": "1",
"name": "Rick Sanchez",
"status": "Alive",
"species": "Human",
"type": "",
"gender": "Male",
"image": "https://rickandmortyapi.com/api/character/avatar/1.jpeg",
"episode": [
{
"id": "1",
"name": "Pilot",
"air_date": "December 2, 2013",
"episode": "S01E01",
"created": "2017-11-10T12:56:33.798Z"
}
]
}
]
}
}
}Одна из самый классных фичей GraphQL — это типизированный API, который позволяет точно понять, что вы получите на выходе. Сообщество GraphQL советует всегда как можно точнее указывать типы. Но попробуем вот что. В приложении для query я могу выставлять, информацию по какому количеству персонажей мне нужно получить. Выставляем, например, 100 персонажей, и посмотрим, сколько займет ответ на подробно описанный запрос:
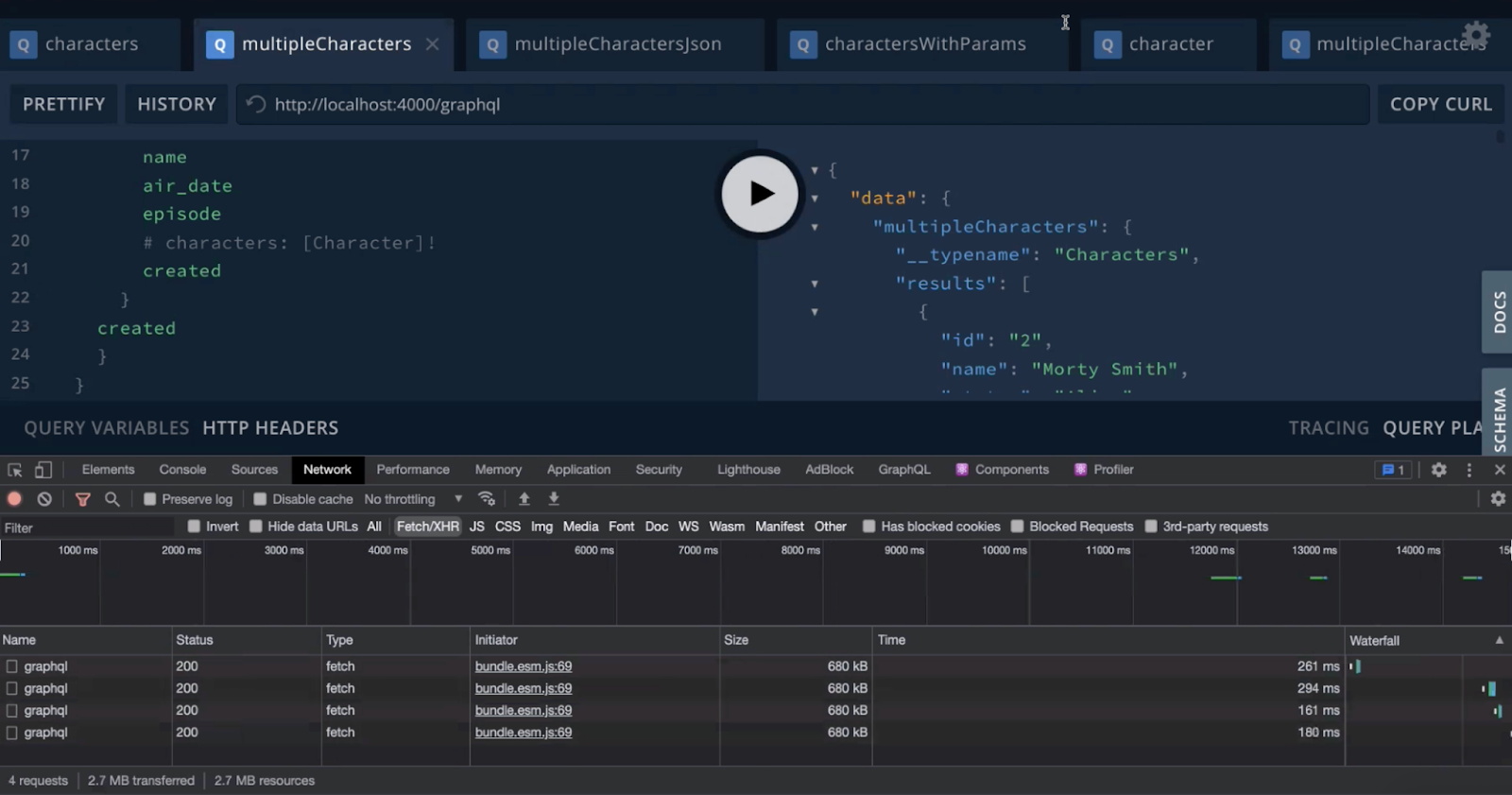
На ответы ушло 160–260 мс. Теперь попробуем провести другой запрос. Он будет брать такой же объем данных в том же месте, но будет прописан просто как json, без всяких типов. Весь код запроса — на трех строчках:

Время получения той же сотни строк уменьшилось в несколько раз, стоило нам обойтись без подробностей в запросах. Увеличив число строк до 1000, мы сохранили ту же кратную разницу в скорости ответа — в 4–5 раз. Возможно, на другом API мы получим чуть иное соотношение, но общий итог поменяется вряд ли. Есть подозрение, что увеличение времени связано с наличием валидации типов. То же самое было и у нас в проекте: согласно лучшим практикам, мы старались типизировать ответы, но в итоге частично их пришлось упростить. Тем не менее у типизации, конечно, есть преимущества. У Apollo есть свой code generator, который отлично все упрощает.
Теперь перейдем к фронтенду. У нас есть приложение, в котором мы получаем данные о персонажах — id, имена и ссылки на картинки:

При клике на персонажа получаем о нем более подробную информацию: показываем вид, статус, пол. Проходит новый запрос:

Переключатель над персонажами — это описание network policy для запросов: cache-first, cache-only и т.д. Мы получили ответы по методу cache-first: Apollo сходил в кэш, не нашел там данных и запросил их с сервера.
Если выставить cache-only, то по новым персонажам мы не получим ответа, так как в кэше их нет. Более интересен метод cache-and-network, когда Apollo сравнивает данные из бэкенда и кэша. В network-only обращения к кэшу нет, а при no-cache мы вообще ничего в кэш не кладем.
Apollo отслеживает параметры запросов, если вводные совпадают, данные перезаписываются. Каждый запрос с новыми параметрами — это новая запись в кэш. Это привело нас к проблеме на одной сводной таблице в 240 столбцов и несколько тысяч строк. Чтобы это все не показывать пользователю сразу, мы нарисовали фильтры, которые передаем на бэкенд через json. В ответ может прийти до 100–150 Мб — после нескольких перезагрузок этих фильтров браузер пользователя переставал отвечать. Решили вопрос, установив политику no-cache — в той задаче кэширование было некритично.
Что в итоге можно посоветовать в работе с Apollo Client?
В третьей версии появился Garbage Collector, который подчищает кэш (в нашей истории он бы пригодился). Не забывайте о нем.
Следите за network policy.
Используйте простые параметры query и дробите их на бэкенде по необходимости.
Настраивайте по необходимости частичное обновление полей, такая возможность есть.
Не могу не отметить, что есть практика использования Apollo Client как state manager. Посмотрите видео о нем, может, он вам подойдет.
В заключение расскажу о концептуальных сложностях, с которыми мы столкнулись при внедрении GraphQL.
В GraphQL отличается парадигма построения API, бывает непросто выстроить эту древовидную структуру.
Если вы используете для подготовки GraphQL BFF, бэкенд не всегда сможет поставлять вам данные удобным образом — с пагинациями и т.п.
Если вы решили внедрить GraphQL на Node.js, то поломка BFF обернется для фронтендера проблемами, с которыми он раньше не сталкивался. Но до этого времени все будет отлично.
Если вы хотите посмотреть все самостоятельно, вот демка, которую я использовал выше.
Time to market: микрофронтенды
В этой презентации я расскажу, как внедрение микрофронтендов помогло улучшить показатели «Леруа Мерлен» по TTM и вообще изменить подходы к разработке в компании.
Что было у нас до микрофронтендов? Конфликты релизов, которые оборачивались проблемами с новыми фичами, багфиксами и не только. Например, одна команда занимается страницами товара, а другая — корзиной. Эти проекты взаимосвязаны в рамках одного монолита, поэтому пока каждая команда не сделает свою часть, выкатить весь монолит мы не сможем. Возникали задержки до месяца и дольше, что, конечно, не могло радовать бизнес-заказчиков.
Основным нашим инструментом был Adobe Experience Manager — очень дорогая монолитная CMS-ка на Java с малым количеством специалистов, которых даже приходилось искать в других странах СНГ. Продакт быстро закидывал разработчиков задачами, но их было мало и поэтому дедлайны соблюдались плоховато.
Это нас не устраивало, и мы начали осторожно присматриваться к микрофронтендам. Какие проблемы они решают?
Релизы без конфликтов. Микрофронтенды обособлены, каждая команда пилит свой.
Удобный выбор технологии. Каждая команда может выбрать удобные инструменты и использовать их.
Эффективное A/B-тестирование.
Вот иллюстрация того, как это может выглядеть в интернет-магазине:

Сущности на странице делятся на отдельные приложения, поэтому могут разрабатываться независимо и на разных стеках. Но важно помнить, что идеальной инкапсуляции здесь может и не быть. Микрофронтенды могут связываться с чем-то еще, например, с дата-менеджером, но это, скорее, исключение из правил.
Архитектура микрофронтендов нам понравилась, и мы обсудили ее с коллегами из бизнес-подразделений. Вот их требования:
сохранение SEO (оптимизации для поисковиков), мы же все-таки интернет-магазин;
сохранение SSR (server-side rendering);
использование React для UI/UX, потому что это легко и удобно;
возможность A/B-тестирования.
Как видите, требования нормальные, можно подыскивать техническое решение. Здесь нас ждало большое разочарование: мы так и нашли инструмент, который сочетал бы и микрофронтенды, и SSR. Что ж, делаем сами, это даст нам свободу действий.
Создавать микрофронтенд для каждого отдельного элемента на странице — слишком дорого и неэффективно. Мы решили дробить всё более крупными кусками: почему бы не заложить в один микрофронтенд всю страницу товара и не тратить время на дополнительные связки и фреймворк-агностицизм? Кроме того, мы решили сделать полную инкапсуляцию приложений и недоступную в готовых решениях поддержку SSR — с этого и начали.
Выбрали имя для новой платформы: в итоге остановились на Okapi. Окапи — это лесной жираф, редкое животное, в котором смешались многие представители парнокопытных. Символично получилось :)
В базовой схеме приложения у нас есть клиент, который запрашивает приложение (App) и его ресурсы, а затем делает между ними связку (Service Discovery). Кроме того, мы сохранили AEM (Adobe Experience Manager) Dispatcher, так как он отлично подходит для создания контента и загрузки его на нужные страницы. Клиент заходит на наш сайт, AEM Dispatcher отправляет его в нужное место.

Нам, конечно, пригодится CDN, так как все наши файлы хранятся отдельно друг от друга в своих микрофронтендах под хешем. Дальше все это обрастает BFF-ами, которые фильтруют данные для каждого приложения из общего множества. У нас есть своя разработка, которая позволяет быстро создавать новые BFF чуть ли не простым драг-н-дропом. Также есть remote-компоненты, о которых мы поговорим позднее.

Рассмотрим более подробно сам Okapi. В него входит:
Роутинг, чтобы бесшовно переключаться между страницами. В Next.js, который позволяет на клиентской стороне переходить на другую версию без перезагрузки, у нас используется тот же принцип.
Server-side рендеринг.
Client-side рендеринг.
Remote-компоненты.
Остановимся на remote-компонентах. Мы смогли сделать так, чтобы компоненты с одного микрофронтенда могли переиспользоваться на другом. Например, одна команда занимается товарной выдачей, которая повторяется в шапке сайта, корзине и еще куче страниц. Нет смысла выделять это в отдельный npm-пакет, следить за версионностью и т.п. С помощью remote-компонентов мы можем выделить один компонент на микрофронтенде и переиспользовать его во всей сети.

У нас есть страница App 1, на ней список товаров Related products. Его можно перезапросить и использовать на App 2 без повторного рендеринга, как обычный компонент React — с отрисовкой, рабочими SSR и клиентской частью. В виде таких компонентов можно использовать весьма крупные сущности, такие как, например, товарную выдачу. Как мы их реализовали?
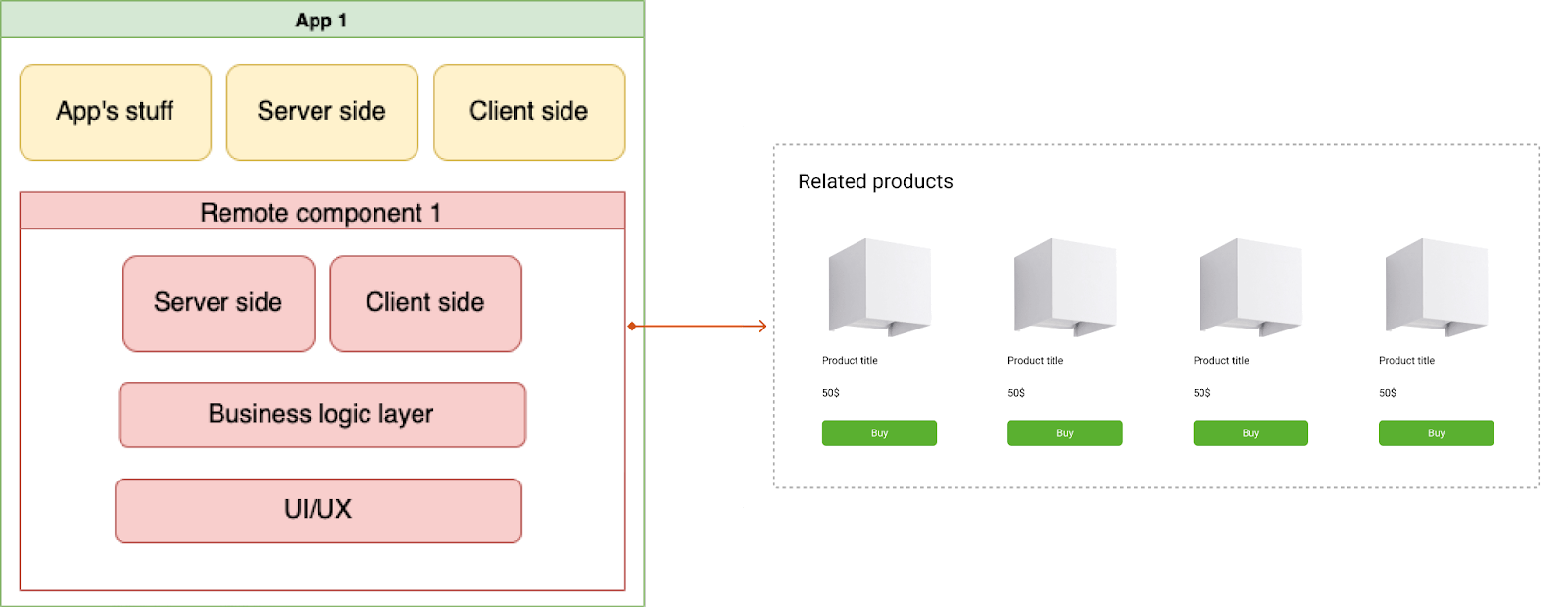
У каждого такого компонента есть своя клиентская, серверная и бизнес-логика, где реализуются запросы данных к BFF, а также UI/UX. Как это использовать в другом приложении?
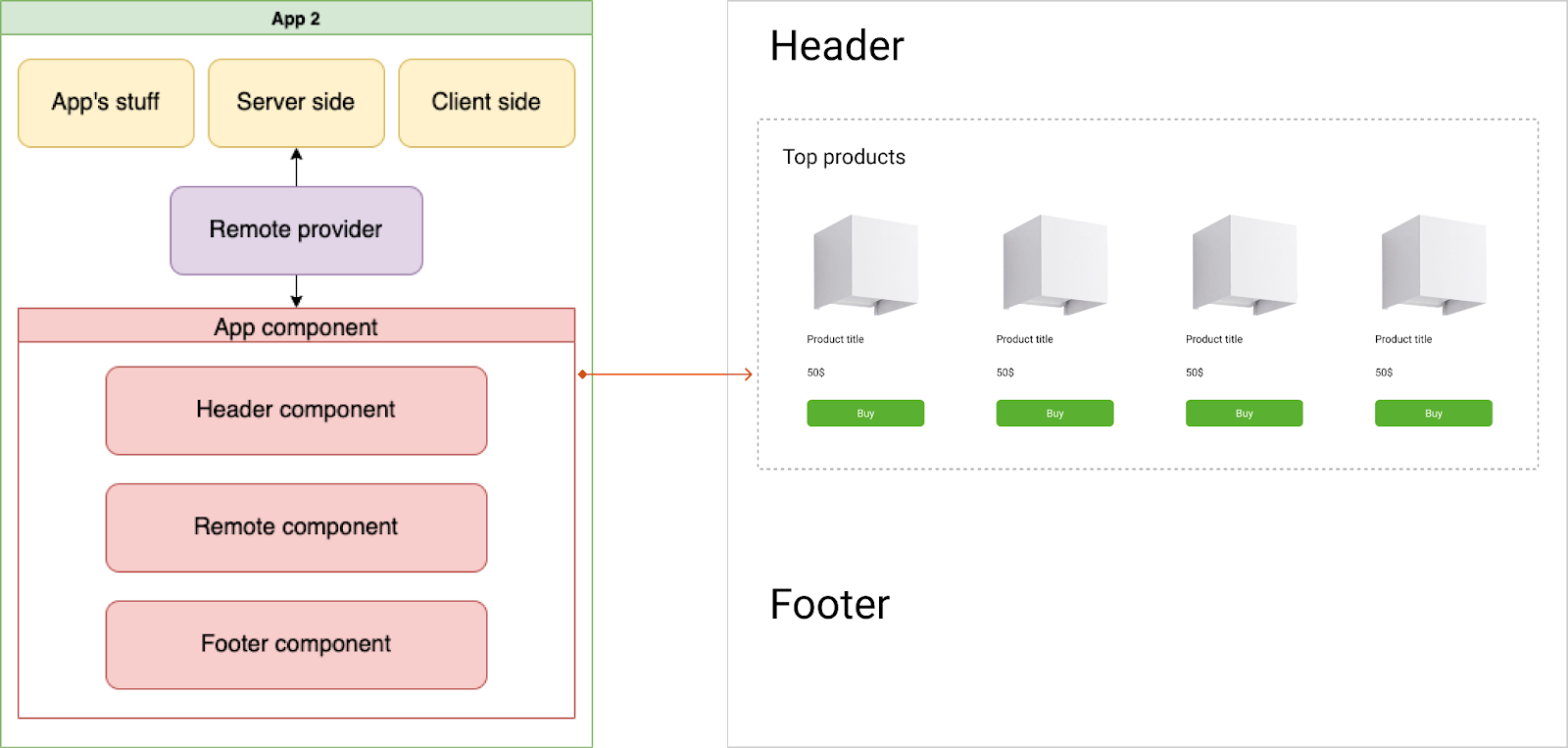
Здесь в игру вступает Remote Provider, который позволяет нам забрать данные у одного приложения и переслать другому. Вот так remote-компонент используется и может быть передан:
<Remote
widget="microfront_name/widget_name" // Откуда брать компонент
data={{ ids: ['1', '2'] }} // Контракты
fallback={() => <div>Something went wrong</div>} // Что-то пошло не так
/>Чем для нас оборачиваются микрофронтенды? Начнем с преимуществ:
Множество команд работаю автономно и быстро, сами формируют релизы, им не нужно договариваться, чтобы выкатить какой-нибудь A/B-тест.
Конфликт релизов отсутствует.
Быстрая доставка фичей в течение дня.
Просто искать разработчиков — под капотом React, в довесок к нему нужно знать особенности SSR, которые можно быстро понять в процессе работы
Полная поддержка SSR.
Простое переиспользование компонентов — сегодня это наша киллер-фича.
Без недостатков тоже не обошлось:
Все-таки у нас не совсем микрофронтенды, мы дробим интернет-магазин достаточно крупно, на целые страницы
Нет полной свободы выбора технологий при создании приложений — сейчас работаем только с React.
Нет возможности типизировать remote-компоненты при использовании на конечном приложении — пока не придумали, как их в таком случае передавать.
И, пожалуй, главный минус: каждый запрос remote-компонента идет отдельно. Если у вас, например, товарная выдача составляет 30 компонентов, и вы делаете 30 запросов выдачи… это уже не очень хорошо. Мы пробуем бороться с этим, например, путем склеивания запросов. Если вас заинтересовала тема, вы можете узнать больше о реализации микрофронтендов в нашем блоге.
В одном из следующих постов мы расскажем о выступлениях на IT Architecture Meetup Росбанка. Не пропустите!
