В «Ростелекоме», как и в любой крупной компании, имеется корпоративное хранилище данных (ЦХД). Наше ЦХД постоянно разрастается и расширяется, мы строим на нем полезные витрины, отчеты и кубы данных. В какой-то момент мы столкнулись с тем, что некачественные данные мешают нам при построении витрин, получаемые агрегаты не сходятся с агрегатами систем источников и вызывают непонимание бизнеса. Например, данные с Null значениями в внешних ключах (foreign key) не соединяются с данными других таблиц.
Краткая схема ЦХД:
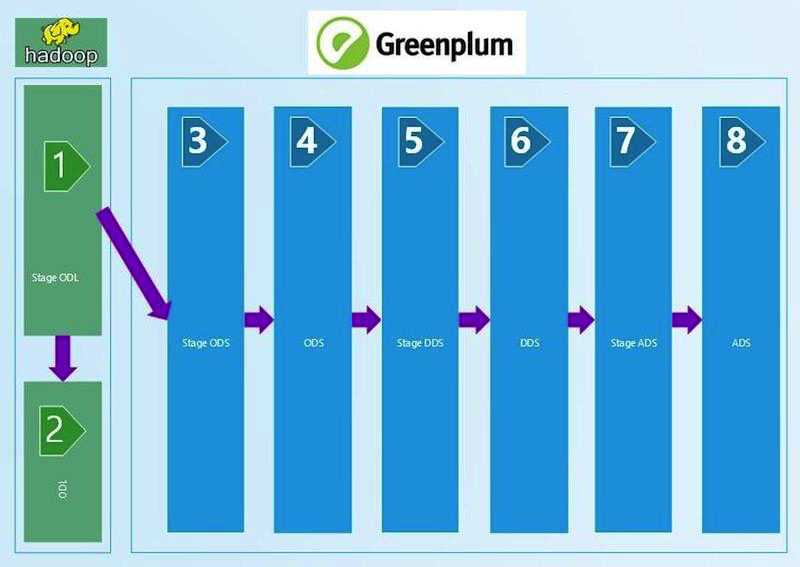
Мы понимали, что для обеспечения уверенности в качестве данных нам нужен регулярный процесс сверок. Конечно, автоматизированный и позволяющий каждому из технологических уровней быть уверенным в качестве данных и их сходимости, как по вертикали, так и по горизонтали. В итоге мы параллельно рассмотрели три готовые платформы для управления сверками от различных вендоров и написали свою собственную. Делимся опытом в этом посте.
Минусы готовых платформ всем известны: цена, ограниченная гибкость, отсутствие возможности дописать и исправить функциональность. Плюсы — закрываются также части mdm (золотые данные и прочее), обучение и поддержка. Оценив это, мы быстро забыли про покупку и сконцентрировались на разработке своего решения.
Ядро нашей системы написано на Python, а база данных метаданных хранения, журнализации и хранения результатов — на Oracle. Библиотек для Python написано много, мы используем необходимый минимум для коннектов Hive(pyhive), GreenPlum(pgdb), Oracle(cx_Oracle). Подключение источника другого типа также не должно составить проблем.
Полученные наборы данных (result set) мы складываем в результирующие таблицы Oracle, на ходу оценивая статус прохождения сверки (SUCCESS/ERROR). На результирующие таблицы настроен APEX в котором построена визуализация результатов, удобная как сопровождению, так и руководству.
Для запуска проверок в Хранилище используется оркестратор Informatica, который загружает данные. При получении статуса успешности загрузки эти данные автоматически начинают сверяться. Применение параметризации запросов и метаданных ЦХД позволяет использовать шаблоны запросов-сверок для наборов таблиц.
Теперь о реализованных на данной платформе сверках.
Начинали мы с технических сверок, которые сравнивают количество данных на входе и слоях ЦХД с наложением определенных фильтров. Берем пришедший на вход в ЦХД ctl-файл с данными, считываем из него количество записей и сравниваем с таблицей на Stage ODL и/или Stage ODS (1, 2, 3 на схеме). Критерий сверки определен в равенстве количества записей (count). Если количество сходится, то результат SUCCESS, нет — ERROR и ручной разбор ошибки.
Эта цепочка технических сверок по сравнению количества записей тянется до слоя ADS (8 на схеме). Меняются фильтры между слоями, которые зависят от типа загрузки — DIM (справочник), HDIM (исторический справочник), FACT (фактовые таблицы начислений) и т.д., — а также от версионности SCD и слоя. Чем ближе к витринному слою, тем более сложные алгоритмы фильтрации мы используем.
На входных данных также сделана техническая сверка на Python, обнаруживающая дубли в ключевых полях. У нас в GreenPlum ключевые поля (PK) не защищены от дублей системными средствами БД. Так что мы написали скрипт Python, который считывает из метаданных PK поля загруженной таблицы и генерирует SQL-скрипт, проверяющий отсутствие дублей по ним. Гибкость подхода позволяет нам использовать PK, состоящий из одного или нескольких полей, что крайне удобно. Такая сверка тянется до STG ADS слоя.
Пример python-кода сверки уникальности. Вызов, передача параметров коннекта и укладывание результатов в результирующую таблицу осуществляется управляющим модулем на Python.
Сверка на отсутствие NULL значений построена аналогично предыдущей и тоже на Python. Считываем из метаданных загрузки поля, которые не могут иметь пустых (NULL) значений и проверяем их наполненность. Сверка используется до слоя DDS (6 на первой схеме).
На входе в хранилище также реализован тренд-анализ поступающих на вход пакетов данных. Количество пришедших данных при поступлении нового пакета заносится в таблицу истории. При существенном изменении количества данных ответственный за таблицу и СИ (систем-источник) получает уведомление на почту (в планах), видит в APEX ошибку еще до попадания сомнительного пакета данных в Хранилище и выясняет с СИ причину этого.
Между STG (STAGE)_ODS и ODS (слоем оперативных данных) (3 и 4 на схеме) появляются технические поля удаления (индикатор удаления = deleted_ind), корректность заполнения которых мы тоже проверяем средствами SQL запросов. Отсутствующие на входе данные должны быть помечены удаленными в ODS.
Результатом работы скрипта сверки ожидаем увидеть нулевое количество ошибок. В представленном примере сверки параметры ~#PKG_ID#~ — передаются через управляющий блок Python, а параметры типа ~P_JOIN_CONDITION~ и ~PERIOD_COL~ заполняются из метаданных таблицы, само имя таблицы ~TABLE~ из параметров запуска.
Ниже приведена параметризованная сверка. Пример SQL кода сверки между STG_ODS и ODS для типа HDIM:
Пример SQL кода сверки между STG_ODS и ODS для типа HDIM с подставленными параметрами:
Начиная с ODS, в справочниках ведется история, следовательно, ее надо проверить на отсутствие пересечений и разрывов. Это сделано через подсчет количества некорректных значений в истории и запись полученного количества ошибок в результирующую таблицу. При наличии в таблице ошибок ведения истории их придется искать уже вручную. Сверка зависит от типа загрузки — HDIM (справочник с ведением истории) в первую очередь. Сверки корректности истории ведем для справочников до слоя ADS.
На слое DDS (6 на первой схеме) разные СИ (системы-источники) соединяются в одну таблицу, появляются HUB таблицы генерации суррогатных ключей для связки данных из разных систем источников. Их мы проверяем на уникальность python-проверкой, аналогичной stage-слою.
На слое DDS необходимо проверить, что после объединения с HUB-таблицей в ключевых полях не появилось значений типа 0, -1, -2, означающих некорректное объединение таблиц, отсутствие данных. Они могли появиться при отсутствии в HUB-таблице нужных данных. И это ошибка для ручного разбора.
Самые сложные сверки у данных витринного слоя ADS (8 на первой схеме). Для полной уверенности в сходимости полученного результата здесь развернута верификация с системой-источником по агрегации суммы начислений. С одной стороны, есть класс показателей, в которые входят агрегированные начисления. Мы собираем их за месяц из витрины ЦХД. С другой стороны, берем агрегаты этих же начислений из системы-источника. Допустимо расхождение не более 1% или определенного и согласованного абсолютного значения. Полученные сверкой наборы данных (result sets) помещаем в специально созданные под получаемые наборы данных, результирующие таблицы Oracle. Сравнение данных делаем в представлении Oracle. Визуализацию полученных результатов в APEX. Наличие целого набора данных (result set) позволяет нам, при наличии ошибок проваливаться глубже и анализировать детальные данные результата, находить конкретную статью по которой произошло расхождение, искать его причины.
Представление результатов сверок для пользователей в APEX
На данный момент у нас получилось работоспособное и активно используемое приложение для сверок данных. Конечно же у нас в планах дальнейшее развитие как количества и качества сверок, так и развития самой платформы. Собственная разработка позволяет нам изменять и дорабатывать функционал достаточно быстро.
Статья подготовлена командой управления данными «Ростелекома»
Краткая схема ЦХД:
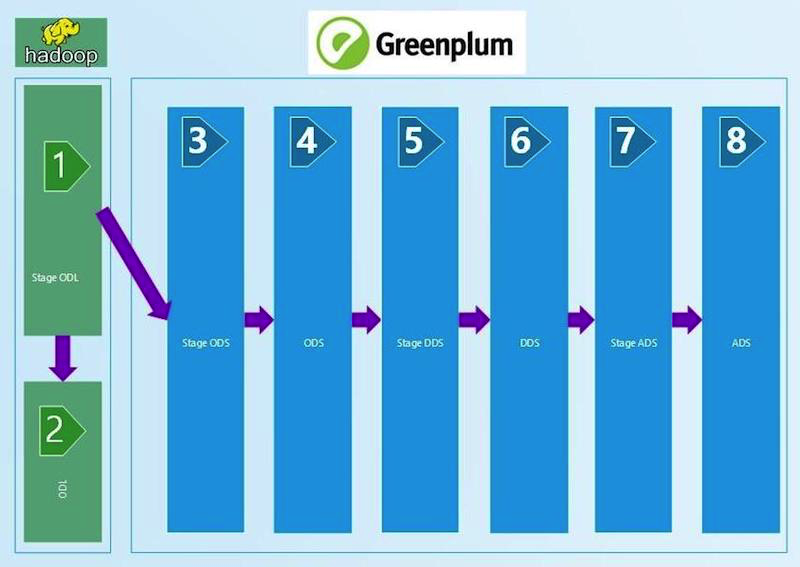
Мы понимали, что для обеспечения уверенности в качестве данных нам нужен регулярный процесс сверок. Конечно, автоматизированный и позволяющий каждому из технологических уровней быть уверенным в качестве данных и их сходимости, как по вертикали, так и по горизонтали. В итоге мы параллельно рассмотрели три готовые платформы для управления сверками от различных вендоров и написали свою собственную. Делимся опытом в этом посте.
Минусы готовых платформ всем известны: цена, ограниченная гибкость, отсутствие возможности дописать и исправить функциональность. Плюсы — закрываются также части mdm (золотые данные и прочее), обучение и поддержка. Оценив это, мы быстро забыли про покупку и сконцентрировались на разработке своего решения.
Ядро нашей системы написано на Python, а база данных метаданных хранения, журнализации и хранения результатов — на Oracle. Библиотек для Python написано много, мы используем необходимый минимум для коннектов Hive(pyhive), GreenPlum(pgdb), Oracle(cx_Oracle). Подключение источника другого типа также не должно составить проблем.
Полученные наборы данных (result set) мы складываем в результирующие таблицы Oracle, на ходу оценивая статус прохождения сверки (SUCCESS/ERROR). На результирующие таблицы настроен APEX в котором построена визуализация результатов, удобная как сопровождению, так и руководству.
Для запуска проверок в Хранилище используется оркестратор Informatica, который загружает данные. При получении статуса успешности загрузки эти данные автоматически начинают сверяться. Применение параметризации запросов и метаданных ЦХД позволяет использовать шаблоны запросов-сверок для наборов таблиц.
Теперь о реализованных на данной платформе сверках.
Начинали мы с технических сверок, которые сравнивают количество данных на входе и слоях ЦХД с наложением определенных фильтров. Берем пришедший на вход в ЦХД ctl-файл с данными, считываем из него количество записей и сравниваем с таблицей на Stage ODL и/или Stage ODS (1, 2, 3 на схеме). Критерий сверки определен в равенстве количества записей (count). Если количество сходится, то результат SUCCESS, нет — ERROR и ручной разбор ошибки.
Эта цепочка технических сверок по сравнению количества записей тянется до слоя ADS (8 на схеме). Меняются фильтры между слоями, которые зависят от типа загрузки — DIM (справочник), HDIM (исторический справочник), FACT (фактовые таблицы начислений) и т.д., — а также от версионности SCD и слоя. Чем ближе к витринному слою, тем более сложные алгоритмы фильтрации мы используем.
На входных данных также сделана техническая сверка на Python, обнаруживающая дубли в ключевых полях. У нас в GreenPlum ключевые поля (PK) не защищены от дублей системными средствами БД. Так что мы написали скрипт Python, который считывает из метаданных PK поля загруженной таблицы и генерирует SQL-скрипт, проверяющий отсутствие дублей по ним. Гибкость подхода позволяет нам использовать PK, состоящий из одного или нескольких полей, что крайне удобно. Такая сверка тянется до STG ADS слоя.
unique_check
import sys
import os
from datetime import datetime
log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def do_check(args, context):
tab = args[0]
data = []
fld_str = ""
try:
sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn
FROM src_column@meta_data
WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,)
for fld in context['ora_get_data'](context['ora_con'], sql):
fld_str = fld_str + (fld_str and ",") + fld[1]
if fld_str:
config = context['script_config']
con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname'])
sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq;
""" % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str )
data.extend(context['pg_get_data'](con_gp, sql))
con_gp.close()
except Exception as e:
raise
return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]]
if __name__ == '__main__':
sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))Пример python-кода сверки уникальности. Вызов, передача параметров коннекта и укладывание результатов в результирующую таблицу осуществляется управляющим модулем на Python.
Сверка на отсутствие NULL значений построена аналогично предыдущей и тоже на Python. Считываем из метаданных загрузки поля, которые не могут иметь пустых (NULL) значений и проверяем их наполненность. Сверка используется до слоя DDS (6 на первой схеме).
На входе в хранилище также реализован тренд-анализ поступающих на вход пакетов данных. Количество пришедших данных при поступлении нового пакета заносится в таблицу истории. При существенном изменении количества данных ответственный за таблицу и СИ (систем-источник) получает уведомление на почту (в планах), видит в APEX ошибку еще до попадания сомнительного пакета данных в Хранилище и выясняет с СИ причину этого.
Между STG (STAGE)_ODS и ODS (слоем оперативных данных) (3 и 4 на схеме) появляются технические поля удаления (индикатор удаления = deleted_ind), корректность заполнения которых мы тоже проверяем средствами SQL запросов. Отсутствующие на входе данные должны быть помечены удаленными в ODS.
Результатом работы скрипта сверки ожидаем увидеть нулевое количество ошибок. В представленном примере сверки параметры ~#PKG_ID#~ — передаются через управляющий блок Python, а параметры типа ~P_JOIN_CONDITION~ и ~PERIOD_COL~ заполняются из метаданных таблицы, само имя таблицы ~TABLE~ из параметров запуска.
Ниже приведена параметризованная сверка. Пример SQL кода сверки между STG_ODS и ODS для типа HDIM:
select
package_id as pkg_id,
'T_~TABLE~' as table_name,
to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'),
coalesce(empty_in_ods, 0) as empty_in_ods,
coalesce(not_equal_md5, 0) as not_equal_md5,
coalesce(deleted_in_ods, 0) as deleted_in_ods,
coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods,
max_load_dttm
from
(select
max (src.package_id) as package_id,
sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods,
sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5,
sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods
from EDW_STG_ODS.T_~TABLE~ src
left join EDW_ODS.T_~TABLE~ tgt
on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y'
where ~#PKG_ID#~ = 0
or src.package_id = ~#PKG_ID#~
) aa,
(select sum (case when src.~PK~ is null then 1 else 0 end) as not_deleted_in_ods,
max (tgt.load_dttm) as max_load_dttm
from EDW_STG_ODS.T_~TABLE~ src
right join EDW_ODS.T_~TABLE~ tgt
on ~P_JOIN_CONDITION~
where tgt.deleted_ind = 0 and tgt.active_ind ='Y'
and tgt.~PERIOD_COL~ between (select min(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~)
and (select max(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~)
) bb
where 1=1Пример SQL кода сверки между STG_ODS и ODS для типа HDIM с подставленными параметрами:
--------------HDIM_CHECKS---------------
select
package_id as pkg_id,
'TABLE_NAME' as table_name,
to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'),
coalesce(empty_in_ods, 0) as empty_in_ods,
coalesce(not_equal_md5, 0) as not_equal_md5,
coalesce(deleted_in_ods, 0) as deleted_in_ods,
coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods,
max_load_dttm
from
(select
max (src.package_id) as package_id,
sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods,
sum (case when src.md5<>tgt.md5 and tgt.ACTION_ID is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5,
sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods
from EDW_STG_ODS.TABLE_NAME src
left join EDW_ODS.TABLE_NAME tgt
on SRC.PK_ID=TGT.PK_ID and tgt.active_ind ='Y'
where 709083887 = 0
or src.package_id = 709083887
) aa,
(select sum (case when src.PK_ID is null then 1 else 0 end) as not_deleted_in_ods,
max (tgt.load_dttm) as max_load_dttm
from EDW_STG_ODS.TABLE_NAME src
right join EDW_ODS.TABLE_NAME tgt
on SRC.PK_ID =TGT.PK_ID
where tgt.del_ind = 0 and tgt.active_ind ='Y'
and tgt.DATE_SYS between (select min(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where 70908 = 0 or package_id = 70908)
and (select max(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where 70908 = 0 or package_id = 70908)
) bb
where 1=1Начиная с ODS, в справочниках ведется история, следовательно, ее надо проверить на отсутствие пересечений и разрывов. Это сделано через подсчет количества некорректных значений в истории и запись полученного количества ошибок в результирующую таблицу. При наличии в таблице ошибок ведения истории их придется искать уже вручную. Сверка зависит от типа загрузки — HDIM (справочник с ведением истории) в первую очередь. Сверки корректности истории ведем для справочников до слоя ADS.
На слое DDS (6 на первой схеме) разные СИ (системы-источники) соединяются в одну таблицу, появляются HUB таблицы генерации суррогатных ключей для связки данных из разных систем источников. Их мы проверяем на уникальность python-проверкой, аналогичной stage-слою.
На слое DDS необходимо проверить, что после объединения с HUB-таблицей в ключевых полях не появилось значений типа 0, -1, -2, означающих некорректное объединение таблиц, отсутствие данных. Они могли появиться при отсутствии в HUB-таблице нужных данных. И это ошибка для ручного разбора.
Самые сложные сверки у данных витринного слоя ADS (8 на первой схеме). Для полной уверенности в сходимости полученного результата здесь развернута верификация с системой-источником по агрегации суммы начислений. С одной стороны, есть класс показателей, в которые входят агрегированные начисления. Мы собираем их за месяц из витрины ЦХД. С другой стороны, берем агрегаты этих же начислений из системы-источника. Допустимо расхождение не более 1% или определенного и согласованного абсолютного значения. Полученные сверкой наборы данных (result sets) помещаем в специально созданные под получаемые наборы данных, результирующие таблицы Oracle. Сравнение данных делаем в представлении Oracle. Визуализацию полученных результатов в APEX. Наличие целого набора данных (result set) позволяет нам, при наличии ошибок проваливаться глубже и анализировать детальные данные результата, находить конкретную статью по которой произошло расхождение, искать его причины.

Представление результатов сверок для пользователей в APEX
На данный момент у нас получилось работоспособное и активно используемое приложение для сверок данных. Конечно же у нас в планах дальнейшее развитие как количества и качества сверок, так и развития самой платформы. Собственная разработка позволяет нам изменять и дорабатывать функционал достаточно быстро.
Статья подготовлена командой управления данными «Ростелекома»
