
Любые процессы, связанные с базой, рано или поздно сталкиваются с проблемами производительности запросов к этой базе.
Хранилище данных Ростелекома построено на Greenplum, большая часть вычислений (transform) производится sql-запросами, которые запускает (либо генерирует и запускает) ETL-механизм. СУБД имеет свои нюансы, существенно влияющие на производительность. Данная статья — попытка выделить наиболее критичные, с точки зрения производительности, аспекты работы с Greenplum и поделиться опытом.
В двух словах о Greenplum
Greenplum — MPP сервер БД, ядро которого построено на PostgreSql.
Представляет собой несколько разных экземпляров процесса PostgreSql (инстансы). Один из них является точкой входа для клиента и называется master instance (master), все остальные — Segment instanсe (segment, Независимые инстансы, на каждом из которых хранится своя порция данных). На каждом сервере (segment host) может быть запущено от одного до нескольких сервисов (segment). Делается это для того, чтобы лучше утилизировать ресурсы серверов и в первую очередь процессоры. Мастер хранит метаданные, отвечает за связь клиентов с данными, а также распределяет работу между сегментами.
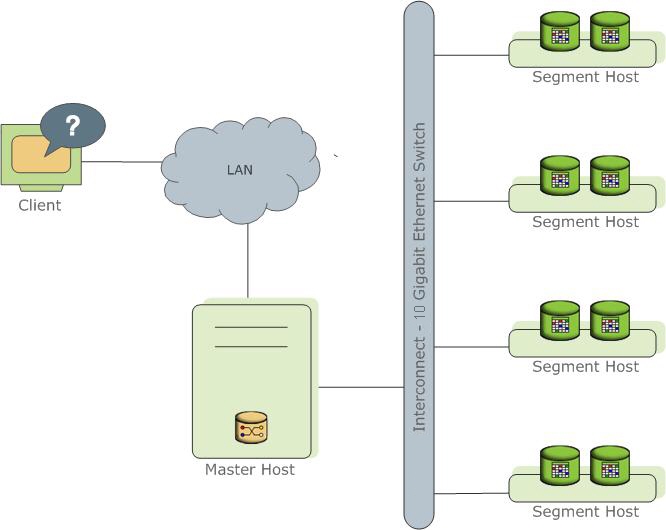
Подробнее можно почитать в официальной документации.
Представляет собой несколько разных экземпляров процесса PostgreSql (инстансы). Один из них является точкой входа для клиента и называется master instance (master), все остальные — Segment instanсe (segment, Независимые инстансы, на каждом из которых хранится своя порция данных). На каждом сервере (segment host) может быть запущено от одного до нескольких сервисов (segment). Делается это для того, чтобы лучше утилизировать ресурсы серверов и в первую очередь процессоры. Мастер хранит метаданные, отвечает за связь клиентов с данными, а также распределяет работу между сегментами.
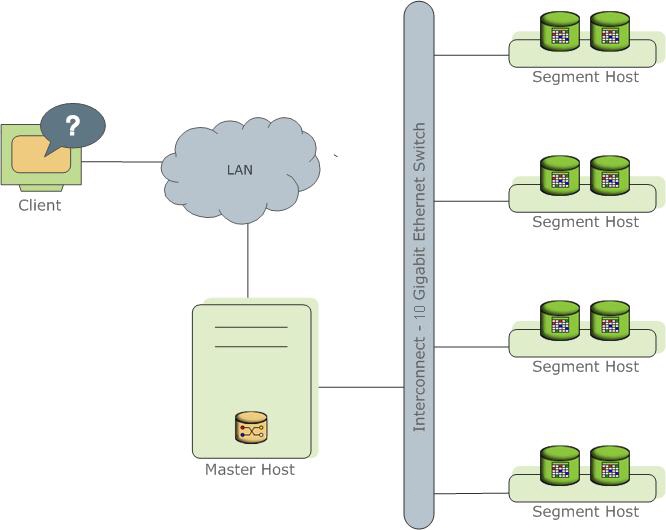
Подробнее можно почитать в официальной документации.
Далее в статье будет много отсылок к плану запроса. Информацию для Greenplum можно получить тут.
Как писать хорошие запросы на Greenplum (ну или хотя бы не совсем печальные)
Поскольку мы имеем дело с распределенной базой данных, важно не только то, как написан sql-запрос, но и то, как хранятся данные.
1. Распределение (Distribution)
Данные физически хранятся на разных сегментах. Разделять данные по сегментам можно случайным образом или по значению хэш-функции от поля или набора полей.
Синтаксис (при создании таблицы):
DISTRIBUTED BY (some_field)Или так:
DISTRIBUTED RANDOMLYПоле дистрибуции должно иметь хорошую селективность и не иметь null-значений (или иметь минимум таких значений), так как записи с такими полями будут распределены на один сегмент, что может привести к перекосам данных.
Тип поля желательно integer. Поле используется для соединения таблиц. Hash join — один из лучших способов соединения таблиц (в плане выполнения запроса), лучше всего работает с этим типом данных.
Для дистрибуции желательно выбирать не больше двух полей, и, конечно, лучше одно, чем два. Дополнительные поля в ключах дистрибуции, во-первых, требуют дополнительное время на хэширование, во-вторых, (в большинстве случаев) потребуют пересылку данных между сегментами, при выполнении джойнов.
Использовать случайное распределение можно, если не получилось подобрать одно или два подходящих поля, а также для небольших табличек. Но надо учесть, что такое распределение лучше всего работает при массовой вставке данных, а не по одной записи. GreenPlum распределяет данные по циклическому алгоритму, причем запускает новый цикл для каждой операции вставки, начиная с первого сегмента, что при частых мелких вставках приводит к перекосам (data skew).
С хорошо подобранным полем распределения все вычисления будут производиться на сегменте, без пересылок данных на другие сегменты. Также для оптимального соединения таблиц (join) одинаковые значения должны быть расположены на одном сегменте.
Распределение в картинках
Хороший ключ распределения:

Плохо подобранный ключ распределения:

Случайное распределение:


Плохо подобранный ключ распределения:

Случайное распределение:

Тип полей, используемых в join, должен быть одинаков во всех таблицах.
Важно: не использовать в качестве полей распределения те, что используются при фильтрации запросов в where, поскольку в этом случае нагрузка при выполнении запроса будет также распределена не равномерно.
2. Секционирование (partitioning)
Секционирование позволяет разделить большие таблицы, например, факты, на логически разделенные куски. Greenplum физически делит вашу таблицу на отдельные таблицы, каждую из которых распределяет по сегментам на основании настроек из п. 1.
Таблицы следует разделять на секции логически, выбирать для этих целей поле, часто используемое в блоке where. В фактовых таблицах это будет период. Таким образом, при правильном обращении к таблице в запросах вы будете работать только с частью всей большой таблицы.
В общем-то, партиционирование достаточно известная тема, и я хотел подчеркнуть, что не стоит выбирать одно и то же поле для партиционирования и распределения. Это приведет к тому, что запрос будет выполняться целиком на одном сегменте.
Пора переходить, собственно, к запросам. Запрос будет выполняться на сегментах по определенному плану:
3. Оптимизатор
В Greenplum есть два оптимизатора, встроенный legacy optimizer и сторонний оптимизатор Orca: GPORCA — Orca — Pivotal Query Optimizer.
Включить GPORCA на запрос:
set optimizer = on;Как правило, оптимизатор GPORCA лучше встроенного. Он адекватнее работает с подзапросами и CTE (подробнее тут ).
Вынесенное обращение к большой таблице в CTE с максимальной фильтрацией данных (не забываем про partition pruning) и явно указанным списком полей — работает очень хорошо.
Он немного видоизменяет план запроса, например, иначе отображает сканируемые партиции:
Стандартный оптимизатор:

Orca:

Также GPORCA позволяет выполнять update поля партиционирования/дистрибуции. Хотя бывают ситуации, когда встроенный оптимизатор отрабатывает лучше. Сторонний оптимизатор очень требователен к статистике, важно не забывать analyze.
Каким бы хорошим оптимизатор ни был, плохо написанный запрос даже Orca не вытянет:
4. Манипуляции с полями в блоке where или условиях соединений (join condition)
Важно помнить, функция, применяемая к полю фильтра или условия джойна, применяется к каждой записи.
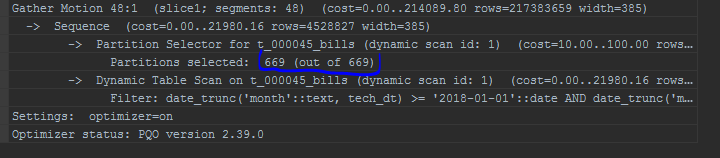
В случае с полем партиционирования (например, date_trunc к полю партиционирования — дате), даже GPORCA не умеет корректно отработать в таком случае, отсечение партиций работать не будет.
-- функция к полю партиционирования
set optimizer = on;
explain
select *
from edw_ods.t_000045_bills c
where date_trunc('month',tech_dt) between to_date('20180101', 'YYYYMMDD') and to_date('20180101', 'YYYYMMDD') + interval '1 month - 1 second'
;
-- без преобразования поля партиционирования
set optimizer = on;
explain
select *
from edw_ods.t_000045_bills c
where tech_dt between to_date('20180101', 'YYYYMMDD') and to_date('20180101', 'YYYYMMDD') + interval '1 month - 1 second'
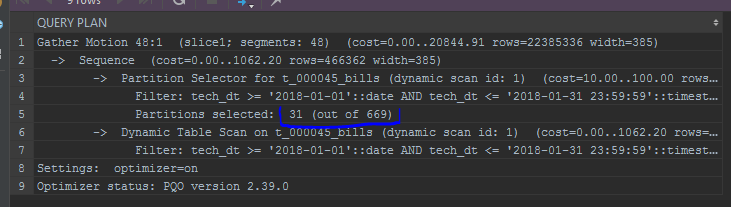
Обращаю также внимание на отображение партиций. Встроенный оптимизатор будет отображать партиции списком:

С осторожностью применять функции к константам в тех же фильтрах по партиции. Пример — все та же date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))
GPORCA вполне справится с таким финтом и корректно отработает, стандартный оптимизатор уже не справится. Впрочем, сделав явное преобразование типа, можно заставить работать и его:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone
А если все сделать не так?
5. Motions
Еще один тип операций, который можно наблюдать в плане запроса — motions. Так отмечены движения данных между сегментами:
- Gather motion — будет отображаться практически в каждом плане, означает объединение результатов выполнения запросов со всех сегментов в один поток (как правило, на мастер).
Две таблицы, распределенные по одному ключу, который используется для джойна, выполняют все операции на сегментах, без перемещения данных. В противном случае происходит Broadcast motion или Redistribution motion: - Broadcast motion — каждый сегмент отправляет свою копию данных на другие сегменты. В идеальной ситуации бродкаст происходит только для маленьких таблиц.
- Redistribution motion — для соединения больших таблиц, распределенных по разным ключам, выполняется перераспределение с целью выполнения соединений локально. Для больших таблиц может быть достаточно затратной операцией.
Broadcast и Redistribution достаточно невыгодные операции. Они выполняются при каждом запуске запроса. Рекомендуется избегать их. Увидев в плане запроса такие пункты, стоит обратить внимание на ключи распределения. Также операции distinct и union являются причиной motions.
Данный список не является исчерпывающим и основан преимущественно на опыте автора. Не получилось найти все и сразу в интернете в свое время. Здесь я постарался выявить наиболее критичные факторы, влияющие на производительность запроса, и разобраться, почему и зачем так происходит.
Статья подготовлена командой управления данными «Ростелекома»
