
→ Тестирование Node.js-проектов. Часть 1. Анатомия тестов и типы тестов
Сегодня, во второй части перевода материала, посвящённого тестированию Node.js-проектов, мы поговорим об оценке эффективности тестов и об анализе качества кода.
Цель тестирования заключается в том, чтобы, убедившись в правильности того, что уже сделано, программист мог бы продолжать продуктивную работу над проектом. Очевидно то, что чем больше объём проверенного кода — тем сильнее будет уверенность в том, что всё работает как надо. Показатель покрытия кода тестами указывает на то, сколько строк (ветвей, команд) проверено тестами. Каким же должен быть этот показатель? Понятно, что 10-30% — это слишком мало для того, чтобы дать уверенность в том, что проект будет работать без ошибок. С другой стороны, стремление к 100% покрытию кода тестами может оказаться слишком дорогим удовольствием и способно отвлечь разработчика от самых важных фрагментов программы, заставляя его выискивать в коде те места, до которых существующие тесты не дотягиваются. Если дать более полный ответ на вопрос о том, каким должно быть покрытие кода тестами, то можно сказать, что показатель, к которому стоит стремиться, зависит от разрабатываемого приложения. Например, если вы заняты написанием ПО для следующего поколения самолёта Airbus A380, то 100% — это показатель, который даже не обсуждается. А вот если вы создаёте веб-сайт, на котором будут выставлены галереи карикатур, то, вероятно, и 50% — это уже много. Хотя знатоки тестирования говорят о том, что уровень покрытия кода тестами, к которому стоит стремиться, зависит от проекта, многие из них упоминают цифру в 80%, которая, вероятно, подойдёт для большинства приложений. Например, здесь речь идёт о чём-то в районе 80-90%, причём, по словам автора этого материала, 100% покрытие кода тестами вызывает у него подозрение, так как может указывать на то, что программист пишет тесты только для того чтобы получить в отчёте красивое число.
Для того чтобы пользоваться показателями покрытия кода тестами, вам понадобится соответствующим образом настроить вашу систему непрерывной интеграции (CI, Continuous Integration). Это позволит, если соответствующий показатель не достигает некоего порога, останавливать сборку проекта. Вот сведения о настройке Jest на сбор информации о тестовом покрытии. Кроме того, можно настраивать пороговые значения покрытия не для всего кода, а ориентируясь на отдельные компоненты. Вдобавок к этому рассмотрите возможность обнаружения снижения показателя покрытия кода тестами. Такое происходит, например, при добавлении в проект нового кода. Контроль этого показателя подтолкнёт разработчиков к повышению объёма протестированного кода, или, по крайней мере, к сохранению этого объёма на существующем уровне. С учётом вышесказанного, покрытие кода тестами — это лишь один показатель, оцениваемый количественно, которого недостаточно для полноценной оценки надёжности тестов. Кроме того, как будет показано ниже, его высокие уровни ещё не говорят о том, что «покрытый тестами» код по-настоящему проверяется.
Уверенность программиста в высоком качестве кода и соответствующие показатели, относящиеся к тестированию, идут рука об руку. Программист не может не опасаться ошибок в том случае, если не знает о том, что большая часть кода его проекта покрыта тестами. Эти опасения способны замедлить работу над проектом.
Вот как выглядит типичный отчёт о покрытии кода тестами.
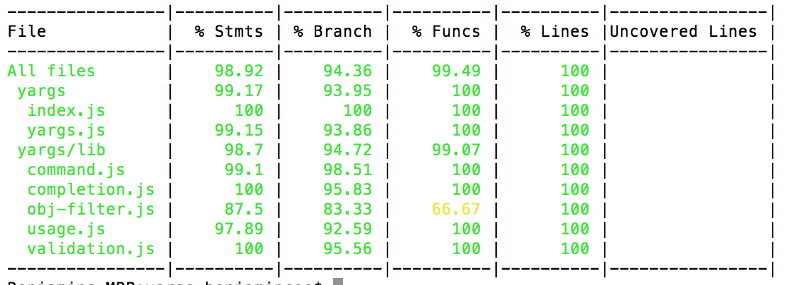
Отчёт о покрытии кода тестами, сформированный средствами Istanbul
Вот пример настройки желаемого уровня покрытия тестами кода компонента и общего уровня этого показателя в Jest.

Настройка желаемого уровня покрытия кода тестами для всего проекта и для конкретного компонента
Некоторые проблемы имеют свойство проскакивать через самые разные системы обнаружения ошибок. Подобные вещи бывает сложно обнаружить с использованием традиционных инструментов. Пожалуй, это не относится к настоящим ошибкам. Скорее речь идёт о неожиданном поведении приложения, которое может иметь разрушительные последствия. Например, часто бывает так, что некоторые фрагменты кода либо никогда не используются, либо вызываются крайне редко. Например, вы думаете, что механизмы класса
Если вы не знаете о том, какие части вашего кода остаются непротестированными, то вы не знаете и о том, откуда можно ждать проблем.
Посмотрите на следующий отчёт и подумайте о том, что в нём выглядит необычно.
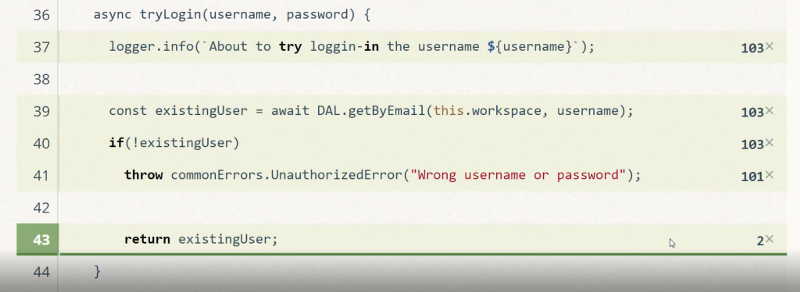
Отчёт, указывающий на необычное поведение системы
Отчёт основан на реальном сценарии использования приложения и позволяет увидеть необычное поведение программы, связанное с входом пользователей в систему. А именно, в глаза бросается неожиданно большое число неудачных попыток входа в систему в сравнении с удачными. После анализа проекта выяснилось, что причиной этого стала ошибка во фронтенде, из-за которой интерфейсная часть проекта постоянно слала соответствующие запросы серверному API для входа в систему.
Традиционные показатели покрытия кода тестами могут быть недостоверными. Так, в отчёте может стоять цифра 100%, но при этом абсолютно все функции проекта будут возвращать неправильные значения. Чем это объяснить? Дело в том, что показатель покрытия кода тестами указывает лишь на то, какие строки кода были выполнены под контролем системы тестирования, но он не зависит от того, было ли что-то по-настоящему проверено, то есть от того, были ли утверждения теста направлены на проверку правильности результатов работы кода. Это напоминает человека, который, вернувшись из заграничной командировки, демонстрирует штампы в паспорте. Штампы доказывают то, что он где-то побывал, но они ничего не говорят о том, сделал ли он то, ради чего ездил в командировку.
Здесь нам на помощь могут прийти мутационные тесты, которые позволяют узнать о том, какой объём кода был реально протестирован, а не просто посещён системой тестирования. Для мутационного тестирования можно воспользоваться JS-библиотекой Stryker. Вот по каким принципам она работает:
Если оказывается, что все «мутанты» были «убиты» (или, по крайней мере, большинство из них не выжило), это даёт более высокий уровень уверенности в высоком качестве кода и тестов, его проверяющих, чем традиционные метрики покрытия кода тестами. При этом время, необходимое для настройки и проведения мутационного тестирования, сопоставимо с тем, которое нужно при использовании обычных тестов.
Если традиционный показатель покрытия кода тестами говорит о том, что тестами покрыто 85% кода — это ещё не значит, что тесты способны выявить ошибки в этом коде.
Вот пример 100% покрытия кода тестами, при котором код оказывается совершенно не протестированным.
Вот отчёт о мутационном тестировании, генерируемый библиотекой Stryker. Он позволяет узнать о том, какой объём кода оказывается непротестированным (на это указывает число «выживших» «мутантов»).

Отчёт Stryker
Результаты этого отчёта позволяют с большей уверенностью, чем обычные показатели покрытия кода тестами, говорить о том, что тесты работают так, как ожидается.
В наши дни линтеры представляют собой мощные инструменты, способны выявлять серьёзные проблемы кода. Рекомендуется, помимо неких базовых правил линтинга (вроде тех, что реализуют плагины eslint-plugin-standard и eslint-config-airbnb), воспользоваться специализированными правилами. Например — это правила, реализуемые средствами плагина eslint-plugin-chai-expect для проверки правильности кода тестов, это правила из плагина eslint-plugin-promise, контролирующие работу с промисами, это правила из eslint-plugin-security, проверяющие код на предмет наличия в нём опасных регулярных выражений. Тут же можно упомянуть и плагин eslint-plugin-you-dont-need-lodash-underscore, который позволяет находить в коде случаи использования методов из внешних библиотек, имеющих аналоги в чистом JavaScript.
Настал чёрный день, проект даёт постоянные сбои в продакшне, а в логах нет сведений о стеках ошибок. Что случилось? Как оказалось, то, что код выбрасывает в виде исключения, на самом деле не является объектом ошибки. В результате в логи сведения о стеке не попадают. Собственно говоря, в такой ситуации программисту можно либо убиться об стену, либо, что куда лучше, потратить 5 минут на настройку линтера, который легко обнаружит проблему и застрахует проект от подобных неприятностей, которые могут возникнуть в будущем.
Вот код, который, по недосмотру, выбрасывает в виде исключения обычный объект, в то время как тут нужен объект типа
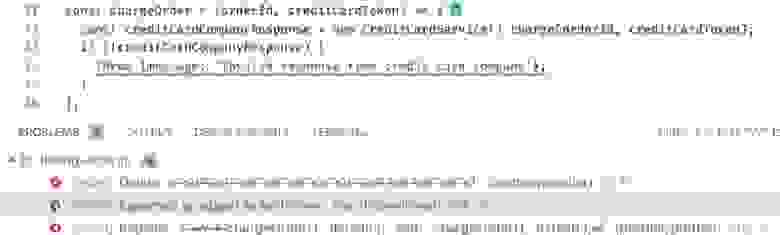
ESLint помогает найти ошибку в коде
Используете централизованную систему непрерывной интеграции, которая помогает контролировать качество кода, тестируя его, применяя линтер, проверяя его на уязвимости? Если так — поспособствуйте тому, чтобы разработчики могли бы запускать эту систему локально. Это позволит им мгновенно проверять их код, что ускоряет обратную связь и сокращает время разработки проекта. Почему это так? Эффективный процесс разработки и тестирования предусматривает множество циклически повторяющихся операций. Код тестируют, потом разработчик получает отчёт, потом, если это нужно, выполняется рефакторинг кода, после чего всё повторяется. Чем быстрее работает цикл обратной связи, чем оперативнее разработчики получают отчёты об испытаниях кода, тем больше итераций улучшения этого кода они могут выполнить. Если же на получение отчёта об испытаниях нужно много времени, это может привести к ухудшению качества кода. Скажем, некто работал над каким-то модулем, потом приступил к работе над чем-то ещё, потом получил отчёт о модуле, который указывает на то, что модуль надо улучшить. Однако, занятый уже совсем другими делами, разработчик не уделит проблемному модулю достаточно внимания.
Некоторые поставщики CI-решений (скажем, это относится к CircleCI) позволяют запускать CI-конвейер локально. Некоторые платные инструменты, вроде Wallaby.js (автор отмечает, что не связан с этим проектом), позволяют быстро получать ценные сведения о качестве кода. Кроме того, разработчик может просто добавить в
Если разработчик получает отчёт о качестве кода через день после написания этого кода, такой отчёт, скорее всего, превратится в нечто вроде формального документа, а испытания кода будут оторваны от работы, не став её естественной частью.
Вот npm-скрипт, выполняющий проверку качества кода. Выполнение проверок распараллеливается. Скрипт выполняется при попытке отправки нового кода в репозиторий. Кроме того, разработчик может запустить его и по своей инициативе.
В обширной экосистеме Kubernetes ещё предстоит прийти к единому мнению об использовании подходящих для развёртывания локальных сред инструментов, хотя такие инструменты появляются довольно часто. Здесь один из возможных подходов заключается в запуске «минимизированного» Kubernetes с использованием средств вроде Minikube или MicroK8s, которые позволяют создавать облегчённые среды, напоминающие реальные. Ещё один подход — это тестирование проектов в удалённой «настоящей» Kubernetes-среде. Некоторые CI-провайдеры (вроде Codefresh) дают возможность взаимодействия со встроенными окружениями Kubernetes, что упрощает работу CI-конвейеров при испытании реальных проектов. Другие позволяют работать с удалёнными Kubernetes-средами.
Использование различных технологий в продакшне и при тестировании требует поддержки двух моделей разработки и приводит к разделению команд программистов и DevOps-специалистов.
Вот пример CI-цепочки, которая, что называется, «на лету», создаёт кластер Kubernetes (это взято отсюда).
Если система тестирования хорошо организована, она станет вашим верным другом, круглосуточно готовым сообщить о проблемах с кодом. Для этого тесты должны выполняться очень быстро. На практике же оказывается, что выполнение в однопоточном режиме 500 модульных тестов, интенсивно использующих процессор, занимает слишком много времени. А такие тесты нужно выполнять весьма часто. К счастью, современные средства для запуска тестов (Jest, AVA, расширение для Mocha) и CI-платформы могут выполнять тесты параллельно, используя несколько процессов, что позволяет значительно улучшить скорость получения отчётов о тестировании. Некоторые CI-платформы даже умеют распараллеливать тесты между контейнерами, что ещё сильнее улучшает цикл обратной связи. Для успешной параллелизации выполнения тестов, локальных или удалённых, тесты не должны зависеть друг от друга. Автономные тесты могут без проблем выполняться в разных процессах.
Получение результатов теста через час после отправки кода в репозиторий, во время работы над новыми возможностями проекта, это отличный способ снизить полезность результатов тестирования.
Благодаря параллельному выполнению тестов библиотека mocha-parallel-test и фреймворк Jest легко обходят Mocha (вот источник этих сведений).

Исследование производительности средств для запуска тестов
Возможно, сейчас вас не особенно заботят проблемы с законом и с плагиатом. Однако почему бы не проверить свой проект на предмет наличия в нём подобных проблем? Существует множество средств для организации таких проверок. Например — это license-checker и plagiarism-checker (это коммерческий пакет, но имеется возможность его бесплатного использования). Подобные проверки несложно встроить в CI-конвейер и проверять проект, например, на наличие зависимостей с ограниченными лицензиями, или на наличие кода, скопированного со StackOverflow, и, вероятно, нарушающего чьи-то авторские права.
Разработчик, совершенно непреднамеренно, может воспользоваться пакетом с неподходящей для его проекта лицензией, или скопипастить коммерческий код, что может привести к юридическим проблемам.
Установим пакет license-checker локально или в CI-окружении:
Проверим с его помощью лицензии, и, если он найдёт то, что нам не подходит, признаем проверку неудачной. CI-система, обнаружив, что при проверке лицензий что-то пошло не так, остановит сборку проекта.

Проверка лицензий
Даже весьма уважаемые и надёжные пакеты, такие, как Express, имеют уязвимости. Для того чтобы выявлять подобные уязвимости, можно воспользоваться специальными инструментами — вроде стандартного средства для аудита npm-пакетов или коммерческого проекта snyk, имеющего бесплатную версию. Эти проверки, наравне с другими, можно сделать частью CI-конвейера.
Для того чтобы защитить свой проект от уязвимостей его зависимостей без использования специальных инструментов, вам придётся постоянно мониторить публикации о таких уязвимостях. Это весьма трудоёмкая задача.
Вот результаты проверки проекта с помощью NPM Audit.

Отчёт о проверке пакета на уязвимости
Дорога в ад вымощена благими намерениями. Эта идея вполне применима к файлу
Если не уделять обновлению пакетов серьёзного внимания, то может оказаться так, что в вашем проекте используются устаревшие версии пакетов, помеченные их авторами как небезопасные.
Утилиту ncu можно использовать для выяснения того, насколько версии пакетов, используемых в проекте, отстают от самых свежих версий этих пакетов.

Анализ проекта средствами ncu
Хотя этот материал и нацелен на всё, что связано с тестированием Node.js-проектов, здесь мы приведём некоторые советы, напрямую к Node.js не относящиеся.
Не обращая внимания на эти рекомендации, вы закрываете глаза на опыт, наработка которого заняла многие годы.
Проверка качества кода будет тем успешнее, чем больше кода удаётся покрыть тестами. Если вы заняты разработкой проекта, который может работать в различных средах, например, на разных версиях Node.js и с разными СУБД, система непрерывной интеграции должна протестировать проект во всех возможных вариантах таких сред. Некоторые CI-системы, для организации подобных испытаний, поддерживают так называемую «матрицу сборки». Некоторые, хотя сами это и не поддерживают, позволяют использовать соответствующие плагины, реализующие эту возможность. Например, предположим, что некоторые ваши клиенты используют mySQL, а некоторые — Postgres. К тому же, у них могут быть установлены различные версии Node.js, скажем — 8, 9 и 10. Используя матрицу сборки можно протестировать продукт во всех вариантах сред, в которых он может оказаться. Делается это путём настройки CI-системы.
Если не проверять работоспособность проекта во всех возможных окружениях, с которыми он может встретиться, можно столкнуться с ошибкой, которая проявляется лишь в специфических условиях. Причём, вероятнее всего, эта ошибка проскочит в продакшн.
Вот пример настройки CI-системы Travis на выполнение тестов с использованием разных версий Node.js.
В этом материале мы рассмотрели рекомендации, касающиеся систем непрерывной интеграции, оценки эффективности тестов и анализа качества кода. Надеемся, вам пригодится то, о чём мы здесь рассказали.
Уважаемые читатели! Какими системами непрерывной интеграции вы пользуетесь?

Сегодня, во второй части перевода материала, посвящённого тестированию Node.js-проектов, мы поговорим об оценке эффективности тестов и об анализе качества кода.
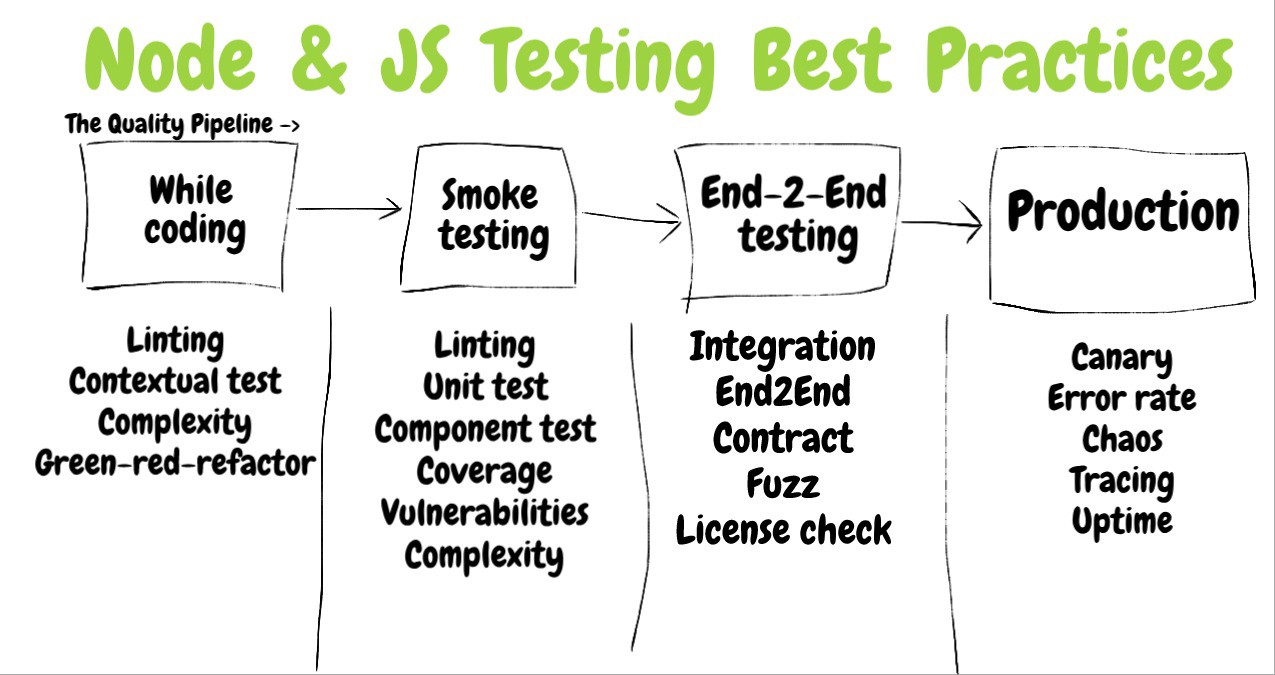
Раздел 3. Оценка эффективности тестов
▍19. Добейтесь достаточно высокого уровня покрытия кода тестами для того, чтобы обрести уверенность в его правильной работе. Обычно хороших результатов даёт примерно 80% покрытие
Рекомендации
Цель тестирования заключается в том, чтобы, убедившись в правильности того, что уже сделано, программист мог бы продолжать продуктивную работу над проектом. Очевидно то, что чем больше объём проверенного кода — тем сильнее будет уверенность в том, что всё работает как надо. Показатель покрытия кода тестами указывает на то, сколько строк (ветвей, команд) проверено тестами. Каким же должен быть этот показатель? Понятно, что 10-30% — это слишком мало для того, чтобы дать уверенность в том, что проект будет работать без ошибок. С другой стороны, стремление к 100% покрытию кода тестами может оказаться слишком дорогим удовольствием и способно отвлечь разработчика от самых важных фрагментов программы, заставляя его выискивать в коде те места, до которых существующие тесты не дотягиваются. Если дать более полный ответ на вопрос о том, каким должно быть покрытие кода тестами, то можно сказать, что показатель, к которому стоит стремиться, зависит от разрабатываемого приложения. Например, если вы заняты написанием ПО для следующего поколения самолёта Airbus A380, то 100% — это показатель, который даже не обсуждается. А вот если вы создаёте веб-сайт, на котором будут выставлены галереи карикатур, то, вероятно, и 50% — это уже много. Хотя знатоки тестирования говорят о том, что уровень покрытия кода тестами, к которому стоит стремиться, зависит от проекта, многие из них упоминают цифру в 80%, которая, вероятно, подойдёт для большинства приложений. Например, здесь речь идёт о чём-то в районе 80-90%, причём, по словам автора этого материала, 100% покрытие кода тестами вызывает у него подозрение, так как может указывать на то, что программист пишет тесты только для того чтобы получить в отчёте красивое число.
Для того чтобы пользоваться показателями покрытия кода тестами, вам понадобится соответствующим образом настроить вашу систему непрерывной интеграции (CI, Continuous Integration). Это позволит, если соответствующий показатель не достигает некоего порога, останавливать сборку проекта. Вот сведения о настройке Jest на сбор информации о тестовом покрытии. Кроме того, можно настраивать пороговые значения покрытия не для всего кода, а ориентируясь на отдельные компоненты. Вдобавок к этому рассмотрите возможность обнаружения снижения показателя покрытия кода тестами. Такое происходит, например, при добавлении в проект нового кода. Контроль этого показателя подтолкнёт разработчиков к повышению объёма протестированного кода, или, по крайней мере, к сохранению этого объёма на существующем уровне. С учётом вышесказанного, покрытие кода тестами — это лишь один показатель, оцениваемый количественно, которого недостаточно для полноценной оценки надёжности тестов. Кроме того, как будет показано ниже, его высокие уровни ещё не говорят о том, что «покрытый тестами» код по-настоящему проверяется.
Последствия отступления от рекомендаций
Уверенность программиста в высоком качестве кода и соответствующие показатели, относящиеся к тестированию, идут рука об руку. Программист не может не опасаться ошибок в том случае, если не знает о том, что большая часть кода его проекта покрыта тестами. Эти опасения способны замедлить работу над проектом.
Пример
Вот как выглядит типичный отчёт о покрытии кода тестами.
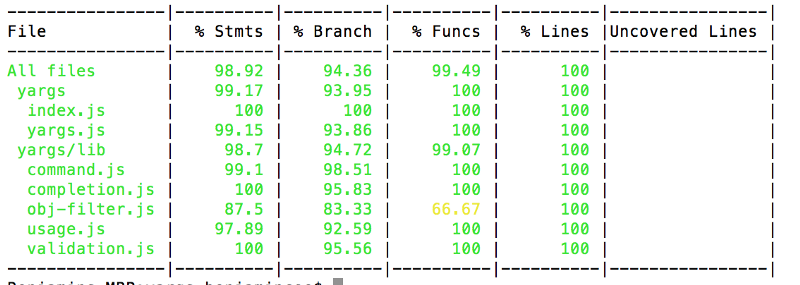
Отчёт о покрытии кода тестами, сформированный средствами Istanbul
Правильный подход
Вот пример настройки желаемого уровня покрытия тестами кода компонента и общего уровня этого показателя в Jest.

Настройка желаемого уровня покрытия кода тестами для всего проекта и для конкретного компонента
▍20. Исследуйте отчёты о покрытии кода тестами для выявления непротестированных участков кода и других аномалий
Рекомендации
Некоторые проблемы имеют свойство проскакивать через самые разные системы обнаружения ошибок. Подобные вещи бывает сложно обнаружить с использованием традиционных инструментов. Пожалуй, это не относится к настоящим ошибкам. Скорее речь идёт о неожиданном поведении приложения, которое может иметь разрушительные последствия. Например, часто бывает так, что некоторые фрагменты кода либо никогда не используются, либо вызываются крайне редко. Например, вы думаете, что механизмы класса
PricingCalculator всегда используются для установки цены товара, но на самом деле оказывается, что этот класс совершенно не используется, а в базе данных есть записи о 10000 товаров, и в интернет-магазине, где используется система, имеется множество продаж… Отчёты о покрытии кода тестами помогают разработчику понять, работает ли приложение так, как оно, по его мнению, должно работать. Кроме того, из отчётов можно узнать о том, какой код проекта не тестируется. Если ориентироваться на общий показатель, указывающий на то, что тесты покрывают 80% кода, нельзя узнать, тестируются ли критически важные части приложения. Для того чтобы сгенерировать подобный отчёт, достаточно соответствующим образом настроить используемое вами средство для запуска тестов. Выглядят такие отчёты обычно довольно симпатично, а их анализ, который не занимает много времени, позволяет обнаруживать всякие неожиданности.Последствия отступления от рекомендаций
Если вы не знаете о том, какие части вашего кода остаются непротестированными, то вы не знаете и о том, откуда можно ждать проблем.
Неправильный подход
Посмотрите на следующий отчёт и подумайте о том, что в нём выглядит необычно.

Отчёт, указывающий на необычное поведение системы
Отчёт основан на реальном сценарии использования приложения и позволяет увидеть необычное поведение программы, связанное с входом пользователей в систему. А именно, в глаза бросается неожиданно большое число неудачных попыток входа в систему в сравнении с удачными. После анализа проекта выяснилось, что причиной этого стала ошибка во фронтенде, из-за которой интерфейсная часть проекта постоянно слала соответствующие запросы серверному API для входа в систему.
▍21. Измеряйте логическое покрытие кода тестами с использованием мутационного тестирования
Рекомендации
Традиционные показатели покрытия кода тестами могут быть недостоверными. Так, в отчёте может стоять цифра 100%, но при этом абсолютно все функции проекта будут возвращать неправильные значения. Чем это объяснить? Дело в том, что показатель покрытия кода тестами указывает лишь на то, какие строки кода были выполнены под контролем системы тестирования, но он не зависит от того, было ли что-то по-настоящему проверено, то есть от того, были ли утверждения теста направлены на проверку правильности результатов работы кода. Это напоминает человека, который, вернувшись из заграничной командировки, демонстрирует штампы в паспорте. Штампы доказывают то, что он где-то побывал, но они ничего не говорят о том, сделал ли он то, ради чего ездил в командировку.
Здесь нам на помощь могут прийти мутационные тесты, которые позволяют узнать о том, какой объём кода был реально протестирован, а не просто посещён системой тестирования. Для мутационного тестирования можно воспользоваться JS-библиотекой Stryker. Вот по каким принципам она работает:
- Она намеренно меняет код, создавая в нём ошибки. Например, код
newOrder.price===0превращается вnewOrder.price!=0. Эти «ошибки» называют мутациями. - Она запускает тесты. Если они оказываются пройденными — значит у нас проблемы, так как тесты не выполняют свою задачу по обнаружению ошибок, и «мутанты», как говорят, «выживают». Если же тесты указывают на ошибки в коде, тогда всё в порядке — «мутанты» «погибают».
Если оказывается, что все «мутанты» были «убиты» (или, по крайней мере, большинство из них не выжило), это даёт более высокий уровень уверенности в высоком качестве кода и тестов, его проверяющих, чем традиционные метрики покрытия кода тестами. При этом время, необходимое для настройки и проведения мутационного тестирования, сопоставимо с тем, которое нужно при использовании обычных тестов.
Последствия отступления от рекомендаций
Если традиционный показатель покрытия кода тестами говорит о том, что тестами покрыто 85% кода — это ещё не значит, что тесты способны выявить ошибки в этом коде.
Неправильный подход
Вот пример 100% покрытия кода тестами, при котором код оказывается совершенно не протестированным.
function addNewOrder(newOrder) {
logger.log(`Adding new order ${newOrder}`);
DB.save(newOrder);
Mailer.sendMail(newOrder.assignee, `A new order was places ${newOrder}`);
return {approved: true};
}
it("Test addNewOrder, don't use such test names", () => {
addNewOrder({asignee: "John@mailer.com",price: 120});
});//Код покрыт тестами на 100%, но, на самом деле, он совершенно не протестированПравильный подход
Вот отчёт о мутационном тестировании, генерируемый библиотекой Stryker. Он позволяет узнать о том, какой объём кода оказывается непротестированным (на это указывает число «выживших» «мутантов»).

Отчёт Stryker
Результаты этого отчёта позволяют с большей уверенностью, чем обычные показатели покрытия кода тестами, говорить о том, что тесты работают так, как ожидается.
- Мутация (mutation) — это код, который был сознательно изменён библиотекой Stryker для проверки эффективности теста.
- Число «убитых» «мутантов» (killed) показывает количество намеренно созданных дефектов кода («мутантов»), которое было выявлено в ходе тестирования.
- Число «выживших» «мутантов» (survived) позволяет узнать о том, сколько дефектов кода тесты не обнаружили.
Раздел 4. Непрерывная интеграция, другие показатели качества кода
▍22. Пользуйтесь возможностями линтеров и прерывайте процесс сборки проекта при обнаружении проблем, о которых они сообщают
Рекомендации
В наши дни линтеры представляют собой мощные инструменты, способны выявлять серьёзные проблемы кода. Рекомендуется, помимо неких базовых правил линтинга (вроде тех, что реализуют плагины eslint-plugin-standard и eslint-config-airbnb), воспользоваться специализированными правилами. Например — это правила, реализуемые средствами плагина eslint-plugin-chai-expect для проверки правильности кода тестов, это правила из плагина eslint-plugin-promise, контролирующие работу с промисами, это правила из eslint-plugin-security, проверяющие код на предмет наличия в нём опасных регулярных выражений. Тут же можно упомянуть и плагин eslint-plugin-you-dont-need-lodash-underscore, который позволяет находить в коде случаи использования методов из внешних библиотек, имеющих аналоги в чистом JavaScript.
Последствия отступления от рекомендаций
Настал чёрный день, проект даёт постоянные сбои в продакшне, а в логах нет сведений о стеках ошибок. Что случилось? Как оказалось, то, что код выбрасывает в виде исключения, на самом деле не является объектом ошибки. В результате в логи сведения о стеке не попадают. Собственно говоря, в такой ситуации программисту можно либо убиться об стену, либо, что куда лучше, потратить 5 минут на настройку линтера, который легко обнаружит проблему и застрахует проект от подобных неприятностей, которые могут возникнуть в будущем.
Неправильный подход
Вот код, который, по недосмотру, выбрасывает в виде исключения обычный объект, в то время как тут нужен объект типа
Error. Иначе в лог не попадут данные о стеке. ESLint находит то, что могло бы стать причиной проблем в продакшне, помогая этих проблем избежать.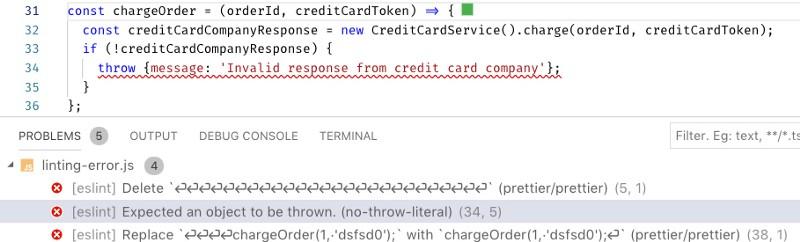
ESLint помогает найти ошибку в коде
▍23. Ускорьте обратную связь благодаря использованию разработчиками локальной системы непрерывной интеграции
Рекомендации
Используете централизованную систему непрерывной интеграции, которая помогает контролировать качество кода, тестируя его, применяя линтер, проверяя его на уязвимости? Если так — поспособствуйте тому, чтобы разработчики могли бы запускать эту систему локально. Это позволит им мгновенно проверять их код, что ускоряет обратную связь и сокращает время разработки проекта. Почему это так? Эффективный процесс разработки и тестирования предусматривает множество циклически повторяющихся операций. Код тестируют, потом разработчик получает отчёт, потом, если это нужно, выполняется рефакторинг кода, после чего всё повторяется. Чем быстрее работает цикл обратной связи, чем оперативнее разработчики получают отчёты об испытаниях кода, тем больше итераций улучшения этого кода они могут выполнить. Если же на получение отчёта об испытаниях нужно много времени, это может привести к ухудшению качества кода. Скажем, некто работал над каким-то модулем, потом приступил к работе над чем-то ещё, потом получил отчёт о модуле, который указывает на то, что модуль надо улучшить. Однако, занятый уже совсем другими делами, разработчик не уделит проблемному модулю достаточно внимания.
Некоторые поставщики CI-решений (скажем, это относится к CircleCI) позволяют запускать CI-конвейер локально. Некоторые платные инструменты, вроде Wallaby.js (автор отмечает, что не связан с этим проектом), позволяют быстро получать ценные сведения о качестве кода. Кроме того, разработчик может просто добавить в
package.json соответствующий npm-скрипт, который выполняет проверки качества кода (тестирует, анализирует линтером, ищет уязвимости), да ещё и использовать пакет concurrently для ускорения выполнения проверок. Теперь, для того чтобы всесторонне проверить код, достаточно будет выполнить единственную команду, вроде npm run quality, и тут же получить отчёт. Кроме того, если испытания кода говорят о наличии в нём проблем, можно отменять коммиты, пользуясь хуками git (для решения этой задачи может пригодиться библиотека husky).Последствия отступления от рекомендаций
Если разработчик получает отчёт о качестве кода через день после написания этого кода, такой отчёт, скорее всего, превратится в нечто вроде формального документа, а испытания кода будут оторваны от работы, не став её естественной частью.
Правильный подход
Вот npm-скрипт, выполняющий проверку качества кода. Выполнение проверок распараллеливается. Скрипт выполняется при попытке отправки нового кода в репозиторий. Кроме того, разработчик может запустить его и по своей инициативе.
"scripts": {
"inspect:sanity-testing": "mocha **/**--test.js --grep \"sanity\"",
"inspect:lint": "eslint .",
"inspect:vulnerabilities": "npm audit",
"inspect:license": "license-checker --failOn GPLv2",
"inspect:complexity": "plato .",
"inspect:all": "concurrently -c \"bgBlue.bold,bgMagenta.bold,yellow\" \"npm:inspect:quick-testing\" \"npm:inspect:lint\" \"npm:inspect:vulnerabilities\" \"npm:inspect:license\""
},
"husky": {
"hooks": {
"precommit": "npm run inspect:all",
"prepush": "npm run inspect:all"
}
}▍24. Выполняйте сквозное тестирование на реалистичном зеркале продакшн-окружения
Рекомендации
В обширной экосистеме Kubernetes ещё предстоит прийти к единому мнению об использовании подходящих для развёртывания локальных сред инструментов, хотя такие инструменты появляются довольно часто. Здесь один из возможных подходов заключается в запуске «минимизированного» Kubernetes с использованием средств вроде Minikube или MicroK8s, которые позволяют создавать облегчённые среды, напоминающие реальные. Ещё один подход — это тестирование проектов в удалённой «настоящей» Kubernetes-среде. Некоторые CI-провайдеры (вроде Codefresh) дают возможность взаимодействия со встроенными окружениями Kubernetes, что упрощает работу CI-конвейеров при испытании реальных проектов. Другие позволяют работать с удалёнными Kubernetes-средами.
Последствия отступления от рекомендаций
Использование различных технологий в продакшне и при тестировании требует поддержки двух моделей разработки и приводит к разделению команд программистов и DevOps-специалистов.
Правильный подход
Вот пример CI-цепочки, которая, что называется, «на лету», создаёт кластер Kubernetes (это взято отсюда).
deploy:
stage: deploy
image: registry.gitlab.com/gitlab-examples/kubernetes-deploy
script:
- ./configureCluster.sh $KUBE_CA_PEM_FILE $KUBE_URL $KUBE_TOKEN
- kubectl create ns $NAMESPACE
- kubectl create secret -n $NAMESPACE docker-registry gitlab-registry --docker-server="$CI_REGISTRY" --docker-username="$CI_REGISTRY_USER" --docker-password="$CI_REGISTRY_PASSWORD" --docker-email="$GITLAB_USER_EMAIL"
- mkdir .generated
- echo "$CI_BUILD_REF_NAME-$CI_BUILD_REF"
- sed -e "s/TAG/$CI_BUILD_REF_NAME-$CI_BUILD_REF/g" templates/deals.yaml | tee ".generated/deals.yaml"
- kubectl apply --namespace $NAMESPACE -f .generated/deals.yaml
- kubectl apply --namespace $NAMESPACE -f templates/my-sock-shop.yaml
environment:
name: test-for-ci▍25. Стремитесь к параллелизации выполнения тестов
Рекомендации
Если система тестирования хорошо организована, она станет вашим верным другом, круглосуточно готовым сообщить о проблемах с кодом. Для этого тесты должны выполняться очень быстро. На практике же оказывается, что выполнение в однопоточном режиме 500 модульных тестов, интенсивно использующих процессор, занимает слишком много времени. А такие тесты нужно выполнять весьма часто. К счастью, современные средства для запуска тестов (Jest, AVA, расширение для Mocha) и CI-платформы могут выполнять тесты параллельно, используя несколько процессов, что позволяет значительно улучшить скорость получения отчётов о тестировании. Некоторые CI-платформы даже умеют распараллеливать тесты между контейнерами, что ещё сильнее улучшает цикл обратной связи. Для успешной параллелизации выполнения тестов, локальных или удалённых, тесты не должны зависеть друг от друга. Автономные тесты могут без проблем выполняться в разных процессах.
Последствия отступления от рекомендаций
Получение результатов теста через час после отправки кода в репозиторий, во время работы над новыми возможностями проекта, это отличный способ снизить полезность результатов тестирования.
Правильный подход
Благодаря параллельному выполнению тестов библиотека mocha-parallel-test и фреймворк Jest легко обходят Mocha (вот источник этих сведений).
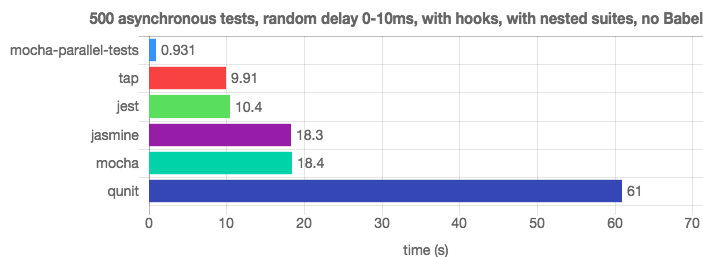
Исследование производительности средств для запуска тестов
▍26. Оградите себя от проблем с законом, используя проверку лицензий и проверку кода на плагиат
Рекомендации
Возможно, сейчас вас не особенно заботят проблемы с законом и с плагиатом. Однако почему бы не проверить свой проект на предмет наличия в нём подобных проблем? Существует множество средств для организации таких проверок. Например — это license-checker и plagiarism-checker (это коммерческий пакет, но имеется возможность его бесплатного использования). Подобные проверки несложно встроить в CI-конвейер и проверять проект, например, на наличие зависимостей с ограниченными лицензиями, или на наличие кода, скопированного со StackOverflow, и, вероятно, нарушающего чьи-то авторские права.
Последствия отступления от рекомендаций
Разработчик, совершенно непреднамеренно, может воспользоваться пакетом с неподходящей для его проекта лицензией, или скопипастить коммерческий код, что может привести к юридическим проблемам.
Правильный подход
Установим пакет license-checker локально или в CI-окружении:
npm install -g license-checkerПроверим с его помощью лицензии, и, если он найдёт то, что нам не подходит, признаем проверку неудачной. CI-система, обнаружив, что при проверке лицензий что-то пошло не так, остановит сборку проекта.
license-checker --summary --failOn BSD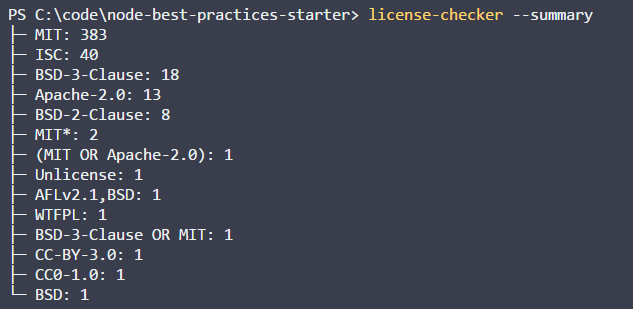
Проверка лицензий
▍27. Постоянно проверяйте проект на наличие уязвимых зависимостей
Рекомендации
Даже весьма уважаемые и надёжные пакеты, такие, как Express, имеют уязвимости. Для того чтобы выявлять подобные уязвимости, можно воспользоваться специальными инструментами — вроде стандартного средства для аудита npm-пакетов или коммерческого проекта snyk, имеющего бесплатную версию. Эти проверки, наравне с другими, можно сделать частью CI-конвейера.
Последствия отступления от рекомендаций
Для того чтобы защитить свой проект от уязвимостей его зависимостей без использования специальных инструментов, вам придётся постоянно мониторить публикации о таких уязвимостях. Это весьма трудоёмкая задача.
Правильный подход
Вот результаты проверки проекта с помощью NPM Audit.

Отчёт о проверке пакета на уязвимости
▍28. Автоматизируйте обновление зависимостей
Рекомендации
Дорога в ад вымощена благими намерениями. Эта идея вполне применима к файлу
package-lock.json, использование которого, по умолчанию, блокирует обновление пакетов. Это происходит даже в случаях, когда проекты приводят в работоспособное состояние командами npm install и npm update. Подобное ведёт либо, в лучшем случае, к использованию устаревших пакетов, либо, в худшем, к появлению в проекте уязвимого кода. Команды разработчиков, в результате, полагаются либо на ручное обновление сведений о подходящих им версиях пакетов, либо на утилиты вроде ncu, которые, опять же, запускаются вручную. Процесс обновления зависимостей лучше всего автоматизировать, ориентируясь на использование наиболее надёжных версий используемых в проекте пакетов. Тут нет единственно правильного решения, однако, в деле автоматизации обновления пакетов можно выделить пару заслуживающих внимания подходов. Первый заключается во внедрении в CI-конвейер чего-то вроде проверки пакетов с помощью npm-outdated или npm-check-updates (ncu). Это позволит выявлять устаревшие пакеты и подтолкнёт разработчиков к их обновлению. Второй подход состоит в использовании коммерческих инструментов, проверяющих код и автоматически делающих пулл-запросы, направленные на обновление зависимостей. В сфере автоматического обновления зависимостей перед нами стоит ещё один интересный вопрос, который касается политики обновления. Если обновляться при выходе каждого нового патча, обновление может создать слишком большую нагрузку на систему. Если обновляться сразу после выхода очередной мажорной версии пакета, это может привести к использованию в проекте нестабильных решений (уязвимости во многих пакетах обнаруживаются именно в самые первые дни после релиза, почитайте об инциденте с eslint-scope). Хорошая политика обновления пакетов может предусматривать наличие некоего «переходного периода», когда локальная версия будет считаться устаревшей не сразу после выхода очередной новой версии, а с некоторой задержкой. Скажем, локально используется версия некоего пакета 1.3.1, но она признаётся нуждающейся в обновлении не с выходом версии этого пакета 1.3.2, а только с выходом версии 1.3.8.Последствия отступления от рекомендаций
Если не уделять обновлению пакетов серьёзного внимания, то может оказаться так, что в вашем проекте используются устаревшие версии пакетов, помеченные их авторами как небезопасные.
Правильный подход
Утилиту ncu можно использовать для выяснения того, насколько версии пакетов, используемых в проекте, отстают от самых свежих версий этих пакетов.

Анализ проекта средствами ncu
▍29. Примите к сведению следующие рекомендации по непрерывной интеграции, не связанные напрямую с Node.js
Рекомендации
Хотя этот материал и нацелен на всё, что связано с тестированием Node.js-проектов, здесь мы приведём некоторые советы, напрямую к Node.js не относящиеся.
- Используйте декларативный синтаксис. Во многих случаях это — единственно возможный вариант, но, например, в старых версиях Jenkins можно применять код или графический интерфейс.
- Выбирайте системы, поддерживающие Docker.
- В первую очередь запускайте самые быстрые тесты. Так, если они найдут ошибки, вы быстрее об этих ошибках узнаете. Сгруппируйте быстрые проверки (например, линтинг и модульные тесты), выполнение которых позволит разработчикам быстро оценить код, и, при необходимости, оперативно внести в него исправления.
- Постарайтесь сделать так, чтобы со всем тем, что генерируется в процессе сборки проекта, было бы удобно работать. Это — отчёты о тестировании, о покрытии кода тестами, о мутационом тестировани, это логи и другие подобные материалы.
- Создавая задания для различных событий, стремитесь к повторному использованию кода. Например, если вы настраиваете задание для обработки коммитов в ветку feature, и ещё одно — для ветки master, посмотрите, можно ли облегчить себе жизнь за счёт совместного использования этими механизмами одного и того же кода (обычно такое вполне возможно).
- Никогда не встраивайте конфиденциальные данные в описания заданий. Подобные сведения надо либо загружать из особого хранилища, либо из настроек задания.
- Следите за правильным версионированием релизов.
- Выполняйте единственную сборку проекта и проводите на ней (например, это может быть образ Docker) все исследования.
- Проводите тестирование в стабильном окружении, которое, между сборками, не меняется. Например, в таком окружении можно держать кэшированную версию
node_modules.
Последствия отступления от рекомендаций
Не обращая внимания на эти рекомендации, вы закрываете глаза на опыт, наработка которого заняла многие годы.
▍30. Используйте концепцию матрицы сборки
Рекомендации
Проверка качества кода будет тем успешнее, чем больше кода удаётся покрыть тестами. Если вы заняты разработкой проекта, который может работать в различных средах, например, на разных версиях Node.js и с разными СУБД, система непрерывной интеграции должна протестировать проект во всех возможных вариантах таких сред. Некоторые CI-системы, для организации подобных испытаний, поддерживают так называемую «матрицу сборки». Некоторые, хотя сами это и не поддерживают, позволяют использовать соответствующие плагины, реализующие эту возможность. Например, предположим, что некоторые ваши клиенты используют mySQL, а некоторые — Postgres. К тому же, у них могут быть установлены различные версии Node.js, скажем — 8, 9 и 10. Используя матрицу сборки можно протестировать продукт во всех вариантах сред, в которых он может оказаться. Делается это путём настройки CI-системы.
Последствия отступления от рекомендаций
Если не проверять работоспособность проекта во всех возможных окружениях, с которыми он может встретиться, можно столкнуться с ошибкой, которая проявляется лишь в специфических условиях. Причём, вероятнее всего, эта ошибка проскочит в продакшн.
Правильный подход
Вот пример настройки CI-системы Travis на выполнение тестов с использованием разных версий Node.js.
language: node_js
node_js:
- "7"
- "6"
- "5"
- "4"
install:
- npm install
script:
- npm run testИтоги
В этом материале мы рассмотрели рекомендации, касающиеся систем непрерывной интеграции, оценки эффективности тестов и анализа качества кода. Надеемся, вам пригодится то, о чём мы здесь рассказали.
Уважаемые читатели! Какими системами непрерывной интеграции вы пользуетесь?

