
Вы написали несколько компонентов с использованием хуков. Возможно — даже создали небольшое приложение. В целом результат вас вполне устраивает. Вы привыкли к API и в процессе работы обнаружили несколько неочевидных полезных приёмов. Вы даже создали несколько собственных хуков и сократили свой код на 300 строк, поместив в них то, что раньше было представлено повторяющимися фрагментами программы. То, что вы сделали, вы показали коллегам. «Отлично получилось», — сказали они о вашем проекте.

Но иногда, когда вы используете
Пытаясь понять — что именно вас не устраивает, вы замечаете, что задаётесь следующими вопросами:
Когда я только начал использовать хуки, меня тоже мучили эти вопросы. Даже когда я готовил документацию, я не мог бы сказать, что в совершенстве владею некоторыми тонкостями. С тех пор у меня было несколько моментов, когда я, вдруг поняв что-то важное, прямо-таки хотел воскликнуть: «Эврика!». О том, что я в эти моменты осознал, я и хочу вам рассказать. То, что вы узнаете сейчас о
Но для того чтобы увидеть ответы на эти вопросы, нам сначала надо сделать шаг назад. Цель этой статьи не в том, чтобы дать её читателям некую пошаговую инструкцию по работе с
У меня в голове всё сошлось только после того, как я перестал смотреть на хук
habr.com/ru/company/ruvds/blog/445276/Йода

Предполагается, что читатель этого материала в определённой степени знаком с API useEffect. Это довольно длинная статья, её можно сравнить с небольшой книгой. Дело в том, что я предпочитаю выражать свои мысли именно так. Ниже, очень кратко, приведены ответы на те вопросы, о которых речь шла выше. Пожалуй, они пригодятся тем, у кого нет времени или желания читать весь материал.
Если тот формат, в котором мы собираемся рассмотреть
Вот краткие ответы на вопросы, поставленные в начале этого материала, предназначенные для тех, кто не хочет читать весь этот текст. Если, читая эти ответы, вы почувствуете, что не очень понимаете смысл прочитанного — полистайте материал. В тексте вы найдёте подробные пояснения. Если же вы собираетесь прочесть всё — этот раздел можете пропустить.
Хотя для воспроизведения функционала
Вот хорошее руководство по загрузке данных с использованием
Рекомендовано выносить за пределы компонентов те функции, которые не нуждаются в свойствах или в состоянии, а те функции, которые используются только эффектами, рекомендуется помещать внутрь эффектов. Если после этого ваш эффект всё ещё пользуется функциями, находящимися в области видимости рендера (включая функции из свойств), оберните их в
Это может происходить тогда, когда загрузка данных выполняется в эффекте, у которого нет второго аргумента, представляющего зависимости. Без него эффекты выполняются после каждой операции рендеринга — а это значит, что установка состояния приведёт к повторному вызову таких эффектов. Бесконечный цикл может возникнуть и в том случае, если в массиве зависимостей указывают значение, которое всегда изменяется. Выяснить — что это за значение можно, удаляя зависимости по одной. Однако, удаление зависимостей (или необдуманное использование
Эффекты всегда «видят» свойства и состояние из рендера, в котором они объявлены. Это помогает предотвращать ошибки, но в некоторых случаях может и помешать нормальной работе компонента. В таких случаях можно для работы с такими значениями в явном виде использовать мутабельные ссылки
Надеюсь, эти ответы на вопросы оказались полезными тем, кто их прочитал. А теперь давайте подробнее поговорим о
Прежде чем мы сможем обсуждать эффекты, нам надо поговорить о рендеринге.
Вот функциональный компонент-счётчик.
Внимательно присмотритесь к строке
В нашем примере
Во время первого вывода компонента значение
React вызывает компонент всякий раз, когда мы обновляем состояние. В результате каждая операция рендеринга «видит» собственное значение состояния
В результате эта строка не выполняет какую-то особую операцию привязки данных:
Она лишь встраивает числовое значение в код, формируемый при рендеринге. Это число предоставляется средствами React. Когда мы вызываем
Самый главный вывод, который можно из этого сделать, заключается в том, что
В этом материале можно найти подробности о данном процессе.
До сих пор всё понятно. А что можно сказать об обработчиках событий?
Взгляните на этот пример. Здесь, через три секунды после нажатия на кнопку, выводится окно сообщения со сведениями о значении, хранящемся в
Предположим, я выполню следующую последовательность действий:
Увеличение значения count после щелчка по кнопке Show alert
Как вы думаете, что выведется в окне сообщения? Будет ли там выведено 5, что соответствует значению
Сейчас вы узнаете ответ на этот вопрос, но, если хотите выяснить всё сами — вот рабочая версия этого примера.
Если то, что вы увидели, кажется вам непонятным — вот вам пример, который ближе к реальности. Представьте себе приложение-чат, в котором, в состоянии, хранится
Механизм вывода окна сообщения «захватил» состояние в момент щелчка по кнопке.
Есть способы реализовать и другой вариант поведения, но мы пока будем заниматься стандартным поведением системы. При построении ментальных моделей технологий важно отличать «путь наименьшего сопротивления» от всяческих «запасных выходов».
Как же всё это работает?
Мы уже говорили о том, что значение
Подобное поведение функций не является чем-то особенным для React — обычные функции ведут себя похожим образом:
В этом примере внешняя переменная
Это объясняет то, как наш обработчик события захватывает значение
В результате каждый рендер, фактически, возвращает собственную «версию»
Именно поэтому в этом примере обработчики событий «принадлежат» конкретным рендерам, а когда вы щёлкаете по кнопке, компонент использует состояние
Внутри каждого конкретного рендера свойства и состояние всегда остаются одними и теми же. Но если в разных операциях рендеринга используются собственные свойства и состояние, то же самое происходит и с любыми механизмами, использующими их (включая обработчики событий). Они тоже «принадлежат» конкретным рендерам. Поэтому даже асинхронные функции внутри обработчиков событий будут «видеть» те же самые значения
Надо отметить, что в вышеприведённом примере я встроил конкретные значения
Этот материал, как вы знаете, посвящён эффектам, но мы пока ещё о них даже не говорили. Сейчас мы это исправим. Как оказывается, работа с эффектами не особенно отличается от того, с чем мы уже разобрались.
Рассмотрим пример из документации, который очень похож на тот, который мы уже разбирали:
Теперь у меня к вам вопрос. Как эффект считывает самое свежее значение
Может быть, тут используется некая «привязка данных», или «объект-наблюдатель», который обновляет значение
Нет.
Мы уже знаем, что в рендере конкретного компонента
И надо отметить, что это не переменная
Каждая версия «видит» значение
React запоминает предоставленную нами функцию эффекта, выполняет её после сброса значений в DOM и позволяет браузеру вывести изображение на экран.
В результате, даже если мы говорим здесь о единственном концептуальном эффекте (обновляющем заголовок документа), он, в каждом рендере, представлен новой функцией, а каждая функция эффекта «видит» свойства и состояние из конкретного рендера, которому она «принадлежит».
Эффект, концептуально, можно представить в качестве части результатов рендеринга.
Строго говоря, это не так (для того, чтобы сделать возможной композицию хуков без необходимости пользоваться неуклюжим синтаксисом или без создания чрезмерной нагрузки на систему). Но в ментальной модели, созданием которой мы тут занимаемся, функции эффектов принадлежат конкретному рендеру точно так же, как обработчики событий.
Для того чтобы убедиться в том, что мы всё это как следует поняли, давайте рассмотрим ещё раз нашу первую операцию рендеринга:
React:
Компонент:
React:
Браузер:
React:
А теперь давайте разберём то, что происходит после щелчка по кнопке. На самом деле, многое тут повторяет предыдущий разбор, но кое-что здесь выглядит иначе:
Компонент:
React:
Компонент:
React:
Браузер:
React:
Теперь мы знаем о том, что эффекты, выполняемые после каждой операции рендеринга, концептуально являются частью вывода компонента, и «видят» свойства и состояние из этой конкретной операции.
Попробуем выполнить мысленный эксперимент. Рассмотрим следующий код:
Что будет выведено в консоль в том случае, если быстро щёлкнуть по кнопке несколько раз?
Как обычно, сейчас мы рассмотрим ответ на этот вопрос. Возможно, вам сейчас может показаться, что это простая задачка, и результат работы этого кода интуитивно понятен. Но это не так! Мы увидим последовательность операций, выполняющих вывод в консоль, каждая из которых принадлежит конкретному рендеру, и, в результате, пользуется собственным значением

Щелчки по кнопке и вывод данных в консоль
Тут вы можете подумать: «Конечно, именно так это и работает! Да и может ли эта программа вести себя иначе?».
Ну, на самом деле,
Дело в том, что

Щелчки по кнопке и вывод данных в консоль
Я вижу иронию в том, что хуки так сильно полагаются на JavaScript-замыкания, а компоненты, основанные на классах, страдают от традиционной проблемы, связанной с неправильным значением, которое попадает в коллбэк функции
Замыкания — это отличный инструмент в том случае, если значение, которое «запирают» в замыкании, никогда не меняется. Это облегчает их использование и размышления о них, так как, в сущности, речь идёт о константах. И, как мы уже говорили, свойства и состояние никогда не меняются в конкретном рендере. Да, кстати, версию этого примера, в которой используются компоненты, основанные на классах, можно исправить, воспользовавшись замыканием.
Сейчас нам важно отметить, что каждая функция внутри механизма рендеринга компонента (включая обработчики событий, эффекты, тайм-ауты или вызовы API внутри них) захватывает свойства и состояние вызова рендера, который их определил.
В результате следующие два компонента эквивалентны:
При этом неважно, выполняется ли внутри компонента «заблаговременное» чтение из свойств или состояния. Они не изменятся! Внутри области видимости отдельно взятого рендера свойства и состояния не изменяются. Надо отметить, что деструктурирование свойств делает это более очевидным.
Конечно, иногда, внутри какого-нибудь коллбэка, объявленного в эффекте, нужно прочитать самое свежее значение, а не то, что было захвачено. Легче всего это сделать, используя ссылки
Учитывайте то, что когда вам нужно прочитать будущие свойства или состояние из функции, принадлежащей ранее выполненной операции рендеринга, то вы, так сказать, пытаетесь плыть против течения. Нельзя сказать, что это неправильно (и иногда это просто необходимо), но менее «чистым» решением может показаться выход за рамки традиционной парадигмы React-разработки. Такой шаг может вести к ожидаемым последствиям, так как это помогает лучше увидеть то, какие фрагменты кода являются ненадёжными и зависящими от таймингов. Когда подобное происходит при работе с классами, это оказывается менее очевидным.
Вот версия нашего примера со счётчиком щелчков, основанная на функции, которая воспроизводит поведение той его версии, которая основана на классе:
Щелчки по кнопке и вывод данных в консоль
Заниматься изменениями чего-либо в React может показаться странной идеей. Однако именно так сам React переназначает значение
Как поясняется в документации, некоторые эффекты могут иметь фазу очистки. В сущности, цель этой операции заключается в том, чтобы «отменять» действия эффектов для вариантов их применения наподобие оформления подписок.
Рассмотрим этот код:
Предположим,
(Но это, на самом деле, не совсем так.)
Пользуясь этой ментальной моделью можно подумать, что операция очистки «видит» старые свойства из-за того, что она выполняется до повторного рендеринга, после чего новый эффект «видит» новые свойства из-за того, что он выполняется после повторного рендеринга. Это — ментальная модель, которая базируется на методах жизненного цикла компонентов, основанных на классах, и здесь она не позволяет добиться точных результатов. Поговорим о причинах этого несоответствия.
React выполняет эффекты только после того, как позволит браузеру вывести изображение на экран. Это ускоряет приложение, так как большинству эффектов не нужно блокировать обновления экрана. Очистка эффекта также откладывается. Предыдущий эффект входит в стадию очистки после повторного рендеринга с новыми свойствами. В результате мы выходим на следующую последовательность действий:
Тут вы можете задаться вопросом о том, как операция очистки предыдущего эффекта всё ещё может видеть «старое» значение
Надо отметить, что мы уже здесь были…

А может это — та же самая кошка?
Приведём цитату из предыдущего раздела: «каждая функция внутри механизма рендеринга компонента (включая обработчики событий, эффекты, тайм-ауты или вызовы API внутри них) захватывает свойства и состояние вызова рендера, который их определил».
Теперь ответ очевиден! В ходе операции очистки эффекта не производится чтение «самых свежих» свойств, что бы это ни значило. Эта операция читает свойства, которые принадлежат рендеру, в котором они определены:
Королевства будут расти и превращаться в пепел, Солнце сбросит внешние оболочки и станет белым карликом, последняя цивилизация исчезнет… Но ничто не заставит свойства, которые «увидела» операция очистки эффекта из первого рендеринга, превратиться во что-то, отличающееся от
Именно это позволяет React работать с эффектами сразу после вывода изображения на экран. Это, без дополнительных усилий со стороны программиста, делает его приложения быстрее. Если нашему коду понадобятся старые значения
Одной из моих любимых особенностей React является то, что эта библиотека унифицирует описание результатов первого рендеринга компонента и обновлений. Это уменьшает энтропию программ.
Предположим, мой компонент выглядит так:
При его использовании совершенно неважно, будет ли сначала отрендерено
Говорят, что важен путь, а не цель. Если говорить о React, то справедливым окажется обратное утверждение. Здесь важна цель, а не то, каким путём к ней идут. В этом и заключается разница между вызовами вида
React синхронизирует DOM с тем, что имеется в текущих свойствах и состоянии. При рендеринге нет разницы между «монтированием» и «обновлением».
Об эффектах стоит размышлять в похожем ключе. Использование
В этом состоит незначительное отличие восприятия
Не должно быть разницы между тем, выполняем ли мы рендеринг компонента сначала со свойством
Надо отметить, что, конечно, выполнение эффекта при каждой операции рендеринга может быть неэффективным вариантом решения некоей задачи. (А в некоторых случаях это может привести к бесконечным циклам).
Как с этим бороться?
Мы уже научили React разборчивости при работе с DOM. Вместо того чтобы касаться DOM при каждой операции повторного рендеринга компонента, React обновляет лишь те части DOM, которые по-настоящему меняются.
Предположим, у нас есть такой код:
Мы хотим обновить его до такого состояния:
React видит два объекта:
React просматривает свойства этих объектов и выясняет, что значение
Можем ли мы сделать что-то подобное этому и с эффектами? Было бы очень хорошо, если можно было бы избежать их повторного запуска в тех случаях, когда в их применении нет необходимости.
Например, возможно, компонент выполняет повторный рендеринг из-за изменения состояния:
Но эффект не использует значение
Может ли React просто… сравнить эффекты?
На самом деле — нет. React не может догадаться о том, что именно делает функция, не вызывая её. (Исходный код не содержит конкретных значений. Он просто включает в себя свойство
Именно поэтому, если нужно избежать ненужных перезапусков эффектов, эффекту можно передать массив зависимостей (такие массивы ещё называют
Это похоже на то, как если бы мы сказали React: «Слушай, я понимаю, что внутрь этой функции ты заглянуть не можешь, но я обещаю, что я будут использовать только
Если окажется так, что зависимости после предыдущего вызова эффекта не менялись, то эффекту нечего будет синхронизировать и React может выполнение этого эффекта пропустить:
Если же хотя бы одно значение из массива зависимостей изменится, то мы будем знать, что при очередном выполнении рендеринга вызов эффекта пропустить нельзя! Ведь иначе ни о какой синхронизации чего-либо с чем-либо не может быть и речи.
Если утаить от React правду о зависимостях — это будет иметь плохие последствия. Интуитивно понятно, что это так, но мне довелось наблюдать за тем, что практически все люди, которые пытались пользоваться
FAQ по хукам даёт пояснения по поводу того, что тут правильно будет сделать. Мы вернёмся к этому примеру позже.
«Но я хочу запустить эффект только при монтировании!», — скажете вы. Пока запомните: если вы указываете зависимости, то в массиве должны быть представлены все значения из компонента, которые используются эффектом. Сюда входят свойства, состояние, функции, то есть — всё, что находится в компоненте и используется эффектом.
Иногда, когда вы так поступаете, это вызывает проблемы. Например, может быть, вы сталкиваетесь с бесконечным циклом загрузки данных, или с тем, что слишком часто пересоздаются сокеты. Решение этой проблемы заключается не в том, чтобы избавиться от зависимостей. Скоро мы это обсудим.
Но, прежде чем мы перейдём к решению, давайте лучше вникнем в суть проблемы.
Если зависимости содержат абсолютно все значения, используемые эффектом, то React знает о том, когда этот эффект нужно перезапустить.

Так как зависимости различаются — эффект перезапускается
Но если мы для этого эффекта укажем, в качестве зависимостей, пустой массив,
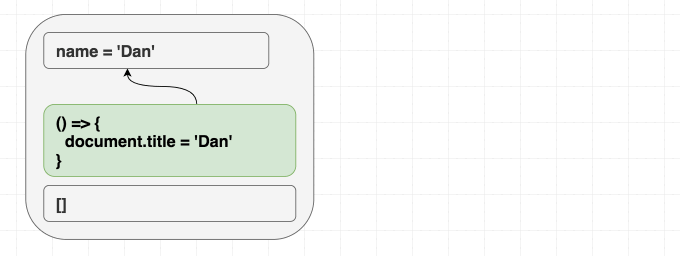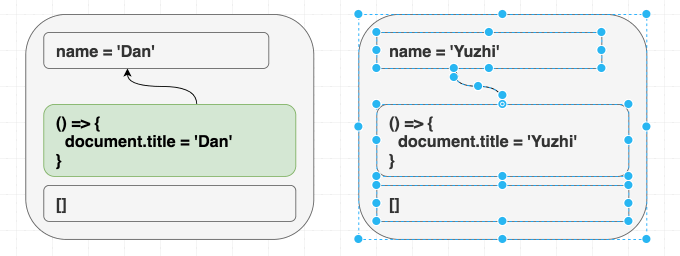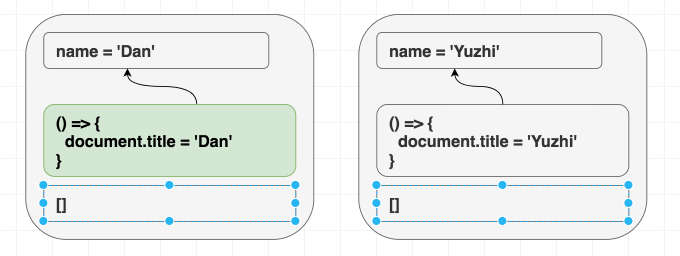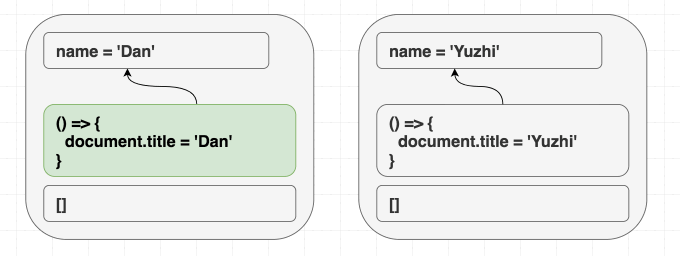
Зависимости выглядят одинаково — эффект повторно не вызывается
В данном случае проблема может показаться очевидной и интуитивно понятной. Но интуиция может подвести в других случаях, когда из памяти «всплывают» идеи, навеянные работой с компонентами, основанными на классах.
Например, предположим, мы создаём счётчик, который увеличивается каждую секунду. Если использовать для его реализации класс, то внутреннее чутьё подскажет нам следующее: «Один раз настроить
Однако, вот незадача, в таком случае счётчик обновится лишь один раз.
Если в голове у вас имеется модель, в соответствии с которой «зависимости позволяют мне указывать на то, когда я хочу повторно вызывать эффект», то этот пример может довести вас до экзистенциального кризиса. Ведь вам нужно, чтобы эффект был вызван лишь один раз, так как в его коде вы, используя
Но если вы знаете о том, что зависимости — это наша подсказка для React обо всём том, что эффект использует из области видимости рендера, то такое поведение этой программы вас не удивит. А именно, эффект использует
В первой операции рендеринга
Мы солгали React, сообщив о том, что наш эффект не зависит от значений из компонента, хотя на самом деле — зависит.
Наш эффект использует
В результате указание пустого массива в качестве списка зависимостей приводит к ошибке. React сравнит зависимости и не станет повторно вызывать эффект.
Зависимости не меняются, поэтому вызов эффекта можно пропустить
Непросто искать решения проблем такого рода в уме. Поэтому я советую вам жёстко придерживаться правила, которое заключается в том, что React всегда нужно честно сообщать о зависимостях эффектов, и в том, чтобы указывать все эти зависимости. Если вы хотите получить поддержку линтера в выполнении этого правила — мы приготовили кое-что для вас и для вашей команды.
Для того чтобы всегда честно сообщать React о зависимостях эффектов, можно воспользоваться одной из двух стратегий. Обычно стоит начать с первой, а затем, если это будет нужно, обратиться ко второй.
Первая стратегия заключается в исправлении массива зависимостей, во внесении в него всех значений, находящихся в компоненте, которые используются внутри эффекта. Добавим в массив зависимостей
Теперь массив зависимостей исправлен. Возможно, такое решение не идеально, но это — первая проблема, которую нам нужно решить. Теперь изменение
Такой подход позволяет решить проблему, но
Зависимости различаются, поэтому эффект мы перезапускаем
Вторая стратегия заключается в изменении кода эффекта таким образом, чтобы ему не понадобилось бы значение, которое меняется чаще, чем нам нужно. Нам не нужно лгать о зависимостях — мы просто хотим изменить эффект так, чтобы у него было бы меньше зависимостей.
Рассмотрим несколько распространённых подходов избавления от зависимостей.
Итак, мы хотим избавиться от зависимости
Для того чтобы это сделать, зададимся вопросом о том, для чего мы используем
Я предпочитаю рассматривать подобные случаи как «ненастоящие зависимости». Да, значение
Именно эту задачу и решает конструкция
Обратите внимание на то, что мы, на самом деле, избавились от зависимости. И мы при этом не обманываем React. Наш эффект больше не выполняет чтение значения
Зависимости не меняются, поэтому эффект повторно не вызывается
Испытать этот пример можно здесь.
Даже хотя этот эффект вызывается лишь один раз, коллбэк
Помните, как мы говорили о том, что синхронизация — это основа ментальной модели эффектов? Интересным аспектом синхронизации является тот факт, что часто нужно, чтобы «сообщения», передаваемые между системами, не были бы привязаны к их состоянию. Например, правка документа в Google Docs не приводит к отправке всей страницы на сервер. Это было бы очень неэффективным решением. Вместо этого на сервер отправляется представление того, что попытался сделать пользователь.
Хотя наш случай и отличается от вышеописанного, похожие рассуждения применимы и к эффектам. Подобный подход способствует отправке из эффектов в компонент лишь минимально необходимого объёма информации. Использование функциональной формы системы обновления состояния, выраженной в виде
Выражение в коде намерения (а не описание в нём результата) похоже на то, как Google Docs решает проблему совместного редактирования документов. Хотя это — и не вполне точная аналогия, функциональные обновления играют в React похожую роль. Они позволяют обеспечить то, что обновления, исходящие из нескольких источников (обработчики событий, подписки эффектов, и так далее) могут быть корректно и предсказуемо применены в пакетном режиме.
Однако даже решение, в котором используется конструкция
Давайте модифицируем предыдущий пример так, чтобы в состоянии было бы две переменных:
Вот рабочая версия этого примера.
Обратите внимание на то, что мы тут React не обманываем. Так как теперь в эффекте используется
Сейчас этот пример работает так: изменение
Но давайте предположим, что нам нужно, чтобы таймер, создаваемый с помощью
Когда установка значения переменной состояния зависит от текущего значения другой переменной состояния, возможно, имеет смысл заменить обе эти переменных с помощью
Когда вы обнаруживаете, что пишете нечто вроде
Поменяем зависимость нашего эффекта
Тут можно посмотреть этот код в деле.
Вы можете задать мне вопрос: «А чем это лучше того, что было?». Ответ заключается в том, что React гарантирует то, что функция
Мы решили проблему!
(Вы можете опустить значения
Внутри эффекта, вместо считывания значений из состояния, выполняется диспетчеризация действия, которое описывает сведения о том, что произошло. Это позволяет нашему эффекту оставаться отделённым от значения состояния
Вот, на тот случай, если вы не видели его раньше, полный код этого примера.
Мы узнали о том, как избавляться от зависимостей в том случае, когда эффекту нужно устанавливать значение переменной состояния, основываясь на предыдущей версии состояния или на другой переменной состояния. Но что если нам, для нахождения следующей версии состояния, нужны свойства? Например, возможно, наше API имеет вид
На самом деле, избавиться от зависимостей можно и в этом случае! Редьюсер можно поместить в компонент, что позволит ему считывать значения свойств:
Применение этого паттерна мешает некоторым оптимизациям, поэтому постарайтесь не использовать его повсюду. Однако, если это нужно, то вы, прибегая к нему, сможете получить доступ к свойствам из редьюсера. Вот работающий пример.
Даже в этом случае гарантируется стабильность сущности
Возможно, сейчас вы задаётесь вопросом о том, что позволяет всему этому правильно работать. Откуда редьюсер «знает» значения свойств, когда вызывается внутри эффекта, который принадлежит другому рендеру? Ответ заключается в том, что когда выполняется функция
Именно поэтому я предпочитаю воспринимать использование
Обычная ошибка при работе с эффектами заключается в том, что функции считают чем-то таким, что не должно присутствовать в составе зависимостей эффектов.
Например, следующий код, вроде бы, выглядит рабочим:
Этот пример подготовлен на основе данной отличной статьи, на которую я рекомендую вам взглянуть.
На самом деле, надо отметить, что этот код всё же работает. Но проблема, выражающаяся в том, что локальную функцию не включили в состав зависимостей эффекта, заключается в том, что, по мере роста компонента, становится сложно понять то, вызывается ли эффект во всех тех случаях, когда он должен вызываться.
Представим, что код нашей функции оказывается разделённым так, как показано ниже, и кроме того то, что он стал в пять раз больше:
Теперь предположим, что, в ходе работы над компонентом мы решили использовать в одной из этих функций свойства или состояние:
Если мы забудем обновить зависимости любого эффекта, вызывающего эти функции (возможно, через обращение к другим функциям), то эффект не сможет синхронизировать изменения свойств и состояния. Звучит это не особенно приятно.
К счастью, у этой проблемы есть простое решение. Если некоторые функции используются только внутри некоего эффекта, их объявления нужно переместить прямо внутрь этого эффекта:
Вот рабочий вариант этого примера.
В чём же заключаются сильные стороны перемещения функций в эффекты? Дело в том, что при таком подходе нам больше не приходится думать о «промежуточных зависимостях». Наш массив зависимостей больше не лжёт React, так как мы по-настоящему не используем в эффекте ничего из внешней области видимости компонента.
Если позже мы отредактируем код
Вот демонстрационная версия этого примера.
Добавляя эту зависимость, мы не просто «успокаиваем React». Её наличие позволяет перезагрузить данные при изменении
Благодаря правилу линтера

Линтер в действии
Это очень удобно.
Иногда перемещение функции внутрь эффекта может оказаться невозможным. Например, несколько эффектов в одном и том же компоненте могут вызывать одну и ту же функцию, и программист не хочет создавать несколько копий такой функции. Или, возможно, эта функция хранится в свойствах компонента.
Можно ли не указывать подобные функции в составе зависимостей эффекта? Я думаю, что нельзя. Повторюсь: эффект не должен лгать React о зависимостях. Обычно можно найти достойное решение подобной проблемы. Типичным заблуждением в подобной ситуации является мысль о том, что «функция никогда не изменится». Но, как мы уже видели, это совсем не так. На самом деле, функция, объявленная внутри компонента, изменяется в каждой операции рендеринга!
Это, и само по себе, является проблемой. Предположим, что два эффекта вызывают функцию
В подобной ситуации перемещение функции
С другой стороны, если быть «честным» при указании зависимостей, можно столкнуться с проблемой. Так как оба эффекта зависят от функции
Эту проблему так и хочется решить, просто исключив функцию
Вместо этого — вот два более простых варианта решения данной проблемы.
Для начала, если функция не использует ничего из области видимости компонента, её можно вынести за пределы компонента и спокойно использовать в эффектах:
Эту функцию не нужно указывать в составе зависимостей, так как она не находится в области видимости рендера и на неё не может подействовать поток данных. И она не может, по случайности, стать зависимой от свойств или состояния.
Вот ещё один вариант решения этой проблемы. Он заключается в том, что функцию можно обернуть в хук useCallback:
Использование
Рассмотрим этот подход и поговорим о том, почему его применение целесообразно. Ранее наш пример выводил результаты поиска по двум запросам (
Попытавшись сделать это, мы тут же заметим отсутствие зависимости
Если исправить зависимости
Благодаря использованию
Это — всего лишь последствия того, что мы принимаем во внимание поток данных и рассматриваем систему с точки зрения синхронизации. То же самое решение работает и для свойств функций, переданных от родительских сущностей:
Так как
Интересно то, что этот паттерн не работает при его использовании с компонентами, основанными на классах, причём, причины этого хорошо иллюстрируют разницу между парадигмами эффектов и методов жизненного цикла компонентов. Рассмотрим следующий код, представляющий собой систему компонентов, основанных на классах, в котором сделана попытка реализовать те же возможности, что и в предыдущем примере:
Возможно, вы думаете сейчас: «Да ладно, Дэн, все мы знаем, что
Конечно,
Но здесь тоже не всё благополучно. Теперь загрузка данных будет выполняться при каждом повторном рендеринге компонента. (Интересным способом подтвердить это будет добавление анимации.) Может быть, надо привязать
Но тогда условие
Единственное реальное решение этой головоломки компонентов, основанных на классах, заключается в том, чтобы проявить мужество и передать само значение
За годы работы с компонентами, основанными на классах, я так привык передавать компонентам-потомкам ненужные свойства и нарушать инкапсуляцию родительских компонентов, что лишь недавно понял то, почему мы вынуждены так поступать.
При работе с классами функциональные свойства, сами по себе, не являются настоящей частью потока данных. Методы используют мутабельную сущность
Функции могут по-настоящему включаться в поток данных благодаря использованию
Аналогично,
Мне хотелось бы подчеркнуть то, что если всюду использовать
В вышеприведённых примерах я предпочитаю, чтобы функция
Вот как может выглядеть традиционный пример загрузки данных в компоненте, основанном на классе:
Как вы, возможно, знаете, этот код содержит ошибки. Он не поддерживает обновления. А вот — ещё один подобный пример, который можно найти в интернете:
Этот код, определённо, лучше, но в нём всё ещё есть проблемы. Причина этого заключается в том, что запросы могут идти не по порядку. Например, я загружаю статью с
То, о чём мы тут говорим, называется состоянием гонки. Это — ситуация, типичная для кода, в котором конструкция
Эффекты не дают нам некоего чудесного решения этой проблемы, хотя программист и получит предупреждение при попытке непосредственной передачи эффекту
Если используемые вами асинхронные механизмы поддерживают отмену операций, то надо отметить, что это замечательно! Это позволяет отменить асинхронный запрос прямо в функции очистки.
Кроме того, простейшим временным решением этой проблемы является контроль асинхронных операций с помощью логических переменных:
В этом материале можно найти подробности о том, как обрабатывать ошибки и состояния загрузки, а также о том, как извлекать подобную логику в собственные хуки. Если вам интересна тема загрузки данных с использованием хуков, я рекомендую вам разобраться с вышеупомянутым материалом.
Если рассматривать побочные эффекты с позиций методов жизненного цикла компонентов, основанных на классах, то окажется, что они ведут себя не так, как то, что рендерит компонент. Рендерингом пользовательского интерфейса управляют свойства и состояние, и интерфейс, гарантированно, будет им соответствовать. В случае же с побочными эффектами это не так. Это — распространённый источник ошибок.
Если смотреть на вещи с точки зрения
Но надо отметить, что для того, чтобы «сделать всё правильно», нужно заранее вложить в проект немало сил и времени. И это может раздражать разработчиков. Хорошо написать код синхронизации, поддерживающий пограничные случаи, по сути, гораздо сложнее, чем вызвать «одноразовый» побочный эффект, который не согласован с результатами рендеринга.
Это может оказаться неудобным в том случае, если
Я видел, как в различных приложениях создаются их собственные хуки, наподобие
До сих пор, например,
В долгосрочной перспективе применение механизма Suspense для загрузки данных даст сторонним библиотекам отличный способ сообщить React о том, что рендеринг надо приостановить до тех пор, пока что-то асинхронное (что угодно: код, данные, изображения) не будет готово к выводу.
Так как возможности
Теперь вы знаете об эффектах практически всё, что знаю я. И если вы, начиная читать этот материал и просмотрев раздел с ответами на вопросы, столкнулись с чем-то непонятным, теперь, надеюсь, всё встало на свои места.


Но иногда, когда вы используете
useEffect, составные части программных механизмов не особенно хорошо стыкуются друг с другом. Вам кажется, что вы что-то упускаете. Всё это похоже на работу с событиями жизненного цикла компонентов, основанных на классах… но так ли это на самом деле? Пытаясь понять — что именно вас не устраивает, вы замечаете, что задаётесь следующими вопросами:
- Как воспроизвести
componentDidMountс помощьюuseEffect? - Как правильно загружать данные внутри
useEffect? Что такое[]? - Нужно ли указывать функции в виде зависимостей эффектов?
- Почему иногда программа попадает в бесконечный цикл повторной загрузки данных?
- Почему иногда внутри эффектов видно старое состояние или встречаются старые свойства?
Когда я только начал использовать хуки, меня тоже мучили эти вопросы. Даже когда я готовил документацию, я не мог бы сказать, что в совершенстве владею некоторыми тонкостями. С тех пор у меня было несколько моментов, когда я, вдруг поняв что-то важное, прямо-таки хотел воскликнуть: «Эврика!». О том, что я в эти моменты осознал, я и хочу вам рассказать. То, что вы узнаете сейчас о
useEffect, позволит вам совершенно чётко разглядеть очевидные ответы на вышеприведённые вопросы.Но для того чтобы увидеть ответы на эти вопросы, нам сначала надо сделать шаг назад. Цель этой статьи не в том, чтобы дать её читателям некую пошаговую инструкцию по работе с
useEffect. Она нацелена на то, чтобы помочь вам, что называется, «грокнуть» useEffect. И, честно говоря, тут не так много всего нужно изучить. На самом деле, большую часть времени мы потратим на забывание того, что знали раньше.У меня в голове всё сошлось только после того, как я перестал смотреть на хук
useEffect через призму знакомых мне методов жизненного цикла компонентов, основанных на классах.«Ты должен забыть то, чему тебя учили»
habr.com/ru/company/ruvds/blog/445276/Йода

Предполагается, что читатель этого материала в определённой степени знаком с API useEffect. Это довольно длинная статья, её можно сравнить с небольшой книгой. Дело в том, что я предпочитаю выражать свои мысли именно так. Ниже, очень кратко, приведены ответы на те вопросы, о которых речь шла выше. Пожалуй, они пригодятся тем, у кого нет времени или желания читать весь материал.
Если тот формат, в котором мы собираемся рассмотреть
useEffect, со всеми его объяснениями и примерами, вам не очень подходит, вы можете немного подождать — до того момента, когда эти объяснения появятся в бесчисленном множестве других руководств. Тут — та же история, что и с самой библиотекой React, которая в 2013 году была чем-то совершенно новым. Для того чтобы сообщество разработчиков распознало бы новую ментальную модель и чтобы появились бы учебные материалы, основанные на этой модели, нужно некоторое время.Ответы на вопросы
Вот краткие ответы на вопросы, поставленные в начале этого материала, предназначенные для тех, кто не хочет читать весь этот текст. Если, читая эти ответы, вы почувствуете, что не очень понимаете смысл прочитанного — полистайте материал. В тексте вы найдёте подробные пояснения. Если же вы собираетесь прочесть всё — этот раздел можете пропустить.
▍Как воспроизвести componentDidMount с помощью useEffect?
Хотя для воспроизведения функционала
componentDidMount можно воспользоваться конструкцией useEffect(fn, []), она не является точным эквивалентом componentDidMount. А именно, она, в отличие от componentDidMount, захватывает свойства и состояние. Поэтому, даже внутри коллбэка, вы будете видеть исходные свойства и состояние. Если вы хотите увидеть самую свежую версию чего-либо, это можно записать в ссылку ref. Но обычно существует более простой способ структурирования кода, поэтому делать это необязательно. Помните о том, что ментальная модель эффектов отличается от той, что применима к componentDidMount и к другим методам жизненного цикла компонентов. Поэтому попытка найти точные эквиваленты может принести больше вреда, чем пользы. Для того чтобы работать продуктивно, нужно, так сказать, «думать эффектами». Основа их ментальной модели ближе к реализации синхронизации, чем к реагированию на события жизненного цикла компонентов.▍Как правильно загружать данные внутри useEffect? Что такое []?
Вот хорошее руководство по загрузке данных с использованием
useEffect. Постарайтесь прочитать его целиком! Оно не такое большое, как это. Скобки, [], представляющие пустой массив, означают, что эффект не использует значения, участвующие в потоке данных React, и по этой причине безопасным можно считать его однократное применение. Кроме того, использование пустого массива зависимостей является обычным источником ошибок в том случае, если некое значение, на самом деле, используется в эффекте. Вам понадобится освоить несколько стратегий (преимущественно, представленных в виде useReducer и useCallback), которые могут помочь устранить необходимость в зависимости вместо того, чтобы необоснованно эту зависимость отбрасывать.▍Нужно ли указывать функции в виде зависимостей эффектов?
Рекомендовано выносить за пределы компонентов те функции, которые не нуждаются в свойствах или в состоянии, а те функции, которые используются только эффектами, рекомендуется помещать внутрь эффектов. Если после этого ваш эффект всё ещё пользуется функциями, находящимися в области видимости рендера (включая функции из свойств), оберните их в
useCallback там, где они объявлены, и попробуйте снова ими воспользоваться. Почему это важно? Функции могут «видеть» значения из свойств и состояния, поэтому они принимают участие в потоке данных. Вот более подробные сведения об этом в нашем FAQ.▍Почему иногда программа попадает в бесконечный цикл повторной загрузки данных?
Это может происходить тогда, когда загрузка данных выполняется в эффекте, у которого нет второго аргумента, представляющего зависимости. Без него эффекты выполняются после каждой операции рендеринга — а это значит, что установка состояния приведёт к повторному вызову таких эффектов. Бесконечный цикл может возникнуть и в том случае, если в массиве зависимостей указывают значение, которое всегда изменяется. Выяснить — что это за значение можно, удаляя зависимости по одной. Однако, удаление зависимостей (или необдуманное использование
[]) — это обычно неправильный подход к решению проблемы. Вместо этого стоит найти источник проблемы и решить её по-настоящему. Например, подобную проблему могут вызывать функции. Помочь решить её можно, помещая их в эффекты, вынося их за пределы компонентов, или оборачивая в useCallback. Для того чтобы избежать многократного создания объектов, можно воспользоваться useMemo.▍Почему иногда внутри эффектов видно старое состояние или встречаются старые свойства?
Эффекты всегда «видят» свойства и состояние из рендера, в котором они объявлены. Это помогает предотвращать ошибки, но в некоторых случаях может и помешать нормальной работе компонента. В таких случаях можно для работы с такими значениями в явном виде использовать мутабельные ссылки
ref (почитать об этом можно в конце вышеупомянутой статьи). Если вы думаете, что видите свойства или состояние из старого рендера, но этого не ожидаете, то вы, возможно, упустили какие-то зависимости. Для того чтобы приучиться их видеть, воспользуйтесь этим правилом линтера. Через пару дней это станет чем-то вроде вашей второй натуры. Кроме того, взгляните на этот ответ в нашем FAQ.Надеюсь, эти ответы на вопросы оказались полезными тем, кто их прочитал. А теперь давайте подробнее поговорим о
useEffect.У каждого рендера есть собственные свойства и состояние
Прежде чем мы сможем обсуждать эффекты, нам надо поговорить о рендеринге.
Вот функциональный компонент-счётчик.
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}Внимательно присмотритесь к строке
<p>You clicked {count} times</p>. Что она означает? «Наблюдает» ли каким-то образом константа count за изменениями в состоянии и обновляется ли она автоматически? Такое заключение можно считать чем-то вроде ценной первой идеи того, кто изучает React, но оно не является точной ментальной моделью происходящего.В нашем примере
count — это просто число. Это не некая магическая «привязка данных», не некий «объект-наблюдатель» или «прокси», или что угодно другое. Перед нами — старое доброе число, вроде этого:const count = 42;
// ...
<p>You clicked {count} times</p>
// ...Во время первого вывода компонента значение
count, получаемое из useState(), равняется 0. Когда мы вызываем setCount(1), React снова вызывает компонент. В этот раз count будет равно 1. И так далее:// Во время первого рендеринга
function Counter() {
const count = 0; // Возвращено useState()
// ...
<p>You clicked {count} times</p>
// ...
}
// После щелчка наша функция вызывается снова
function Counter() {
const count = 1; // Возвращено useState()
// ...
<p>You clicked {count} times</p>
// ...
}
// После ещё одного щелчка функция вызывается снова
function Counter() {
const count = 2; // Возвращено useState()
// ...
<p>You clicked {count} times</p>
// ...
}React вызывает компонент всякий раз, когда мы обновляем состояние. В результате каждая операция рендеринга «видит» собственное значение состояния
counter, которое, внутри функции, является константой.В результате эта строка не выполняет какую-то особую операцию привязки данных:
<p>You clicked {count} times</p>Она лишь встраивает числовое значение в код, формируемый при рендеринге. Это число предоставляется средствами React. Когда мы вызываем
setCount, React снова вызывает компонент с другим значением count. Затем React обновляет DOM для того чтобы объектная модель документа соответствовала бы самым свежим данным, выведенным в ходе рендеринга компонента.Самый главный вывод, который можно из этого сделать, заключается в том, что
count является константой внутри любого конкретного рендера и со временем не меняется. Меняется компонент, который вызывается снова и снова. Каждый рендер «видит» собственное значение count, которое оказывается изолированным для каждой из операций рендеринга.В этом материале можно найти подробности о данном процессе.
У каждого рендера имеются собственные обработчики событий
До сих пор всё понятно. А что можно сказать об обработчиках событий?
Взгляните на этот пример. Здесь, через три секунды после нажатия на кнопку, выводится окно сообщения со сведениями о значении, хранящемся в
count:function Counter() {
const [count, setCount] = useState(0);
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
<button onClick={handleAlertClick}>
Show alert
</button>
</div>
);
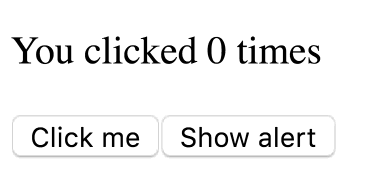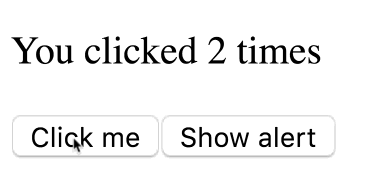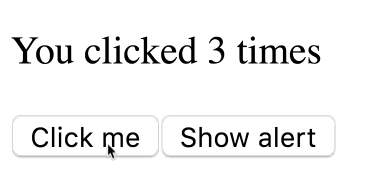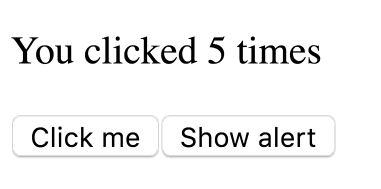
}Предположим, я выполню следующую последовательность действий:
- Доведу значение
countдо 3, щёлкая по кнопкеClick me. - Щёлкну по кнопке
Show alert. - Увеличу значение до 5 до истечения таймаута.
Увеличение значения count после щелчка по кнопке Show alert
Как вы думаете, что выведется в окне сообщения? Будет ли там выведено 5, что соответствует значению
count на момент срабатывания таймера, или 3 — то есть значение count в момент нажатия на кнопку?Сейчас вы узнаете ответ на этот вопрос, но, если хотите выяснить всё сами — вот рабочая версия этого примера.
Если то, что вы увидели, кажется вам непонятным — вот вам пример, который ближе к реальности. Представьте себе приложение-чат, в котором, в состоянии, хранится
ID текущего получателя сообщения, и имеется кнопка Send. В этом материале происходящее рассматривается в подробностях. Собственно говоря, правильным ответом на вопрос о том, что появится в окне сообщения, является 3.Механизм вывода окна сообщения «захватил» состояние в момент щелчка по кнопке.
Есть способы реализовать и другой вариант поведения, но мы пока будем заниматься стандартным поведением системы. При построении ментальных моделей технологий важно отличать «путь наименьшего сопротивления» от всяческих «запасных выходов».
Как же всё это работает?
Мы уже говорили о том, что значение
count является константой для каждого конкретного вызова нашей функции. Полагаю, стоит остановиться на этом подробнее. Речь идёт о том, что наша функция вызывается много раз (один раз на каждую операцию рендеринга), но при каждом из этих вызовов count внутри неё является константой. Эта константа установлена в некое конкретное значение (представляющее собой состояние конкретной операции рендеринга).Подобное поведение функций не является чем-то особенным для React — обычные функции ведут себя похожим образом:
function sayHi(person) {
const name = person.name;
setTimeout(() => {
alert('Hello, ' + name);
}, 3000);
}
let someone = {name: 'Dan'};
sayHi(someone);
someone = {name: 'Yuzhi'};
sayHi(someone);
someone = {name: 'Dominic'};
sayHi(someone);В этом примере внешняя переменная
someone несколько раз переназначается. Такое же может произойти и где-то внутри React, текущее состояние компонента может меняться. Однако внутри функции sayHi имеется локальная константа name, которая связана с person из конкретного вызова. Эта константа является локальной, поэтому её значения в разных вызовах функции изолированы друг от друга! В результате, по прошествии тайм-аута, каждое выводимое окно сообщения «помнит» собственное значение name.Это объясняет то, как наш обработчик события захватывает значение
count в момент щелчка по кнопке. Если мы, работая с компонентами, применим тот же принцип, то окажется, что каждый рендер «видит» собственное значение count:// Во время первого рендеринга
function Counter() {
const count = 0; // Возвращено useState()
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}
// После щелчка наша функция вызывается снова
function Counter() {
const count = 1; // Возвращено useState()
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}
// После ещё одного щелчка функция вызывается снова
function Counter() {
const count = 2; // Возвращено useState()
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
// ...
}В результате каждый рендер, фактически, возвращает собственную «версию»
handleAlertClick. Каждая из таких версий «помнит» собственное значение count:// Во время первого рендеринга
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 0);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // Версия, хранящая значение 0
// ...
}
// После щелчка наша функция вызывается снова
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 1);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // Версия, хранящая значение 1
// ...
}
// После ещё одного щелчка функция вызывается снова
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + 2);
}, 3000);
}
// ...
<button onClick={handleAlertClick} /> // Версия, хранящая значение 2
// ...
}Именно поэтому в этом примере обработчики событий «принадлежат» конкретным рендерам, а когда вы щёлкаете по кнопке, компонент использует состояние
count из этих рендеров.Внутри каждого конкретного рендера свойства и состояние всегда остаются одними и теми же. Но если в разных операциях рендеринга используются собственные свойства и состояние, то же самое происходит и с любыми механизмами, использующими их (включая обработчики событий). Они тоже «принадлежат» конкретным рендерам. Поэтому даже асинхронные функции внутри обработчиков событий будут «видеть» те же самые значения
count.Надо отметить, что в вышеприведённом примере я встроил конкретные значения
count прямо в функции handleAlertClick. Эта «мысленная» замена нам не повредит, так как константа count не может изменяться в пределах конкретного рендера. Во-первых, это константа, во вторых — это число. Можно с уверенностью говорить о том, что так же можно размышлять и о других значениях, вроде объектов, но только в том случае, если мы примем за правило не выполнять изменения (мутации) состояния. При этом нас устраивает вызов setSomething(newObj) с новым объектом вместо изменения существующего, так как при таком подходе состояние, принадлежащее предыдущему рендеру, оказывается нетронутым.У каждого рендера есть собственные эффекты
Этот материал, как вы знаете, посвящён эффектам, но мы пока ещё о них даже не говорили. Сейчас мы это исправим. Как оказывается, работа с эффектами не особенно отличается от того, с чем мы уже разобрались.
Рассмотрим пример из документации, который очень похож на тот, который мы уже разбирали:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}Теперь у меня к вам вопрос. Как эффект считывает самое свежее значение
count?Может быть, тут используется некая «привязка данных», или «объект-наблюдатель», который обновляет значение
count внутри функции эффекта? Может быть count — это мутабельная переменная, значение которой React устанавливает внутри нашего компонента, в результате чего эффект всегда видит её самую свежую версию?Нет.
Мы уже знаем, что в рендере конкретного компонента
count представляет собой константу. Даже обработчики событий «видят» значение count из рендера, которому они «принадлежат» из-за того, что count — это константа, находящаяся в определённой области видимости. То же самое справедливо и для эффектов!И надо отметить, что это не переменная
count каким-то образом меняется внутри «неизменного» эффекта. Перед нами — сама функция эффекта, различная в каждой операции рендеринга.Каждая версия «видит» значение
count из рендера, к которому она «принадлежит»: // Во время первого рендеринга
function Counter() {
// ...
useEffect(
// Функция эффекта из первого рендера
() => {
document.title = `You clicked ${0} times`;
}
);
// ...
}
// После щелчка наша функция вызывается снова
function Counter() {
// ...
useEffect(
// Функция эффекта из второго рендера
() => {
document.title = `You clicked ${1} times`;
}
);
// ...
}
// После ещё одного щелчка функция вызывается снова
function Counter() {
// ...
useEffect(
// Функция эффекта из третьего рендера
() => {
document.title = `You clicked ${2} times`;
}
);
// ..
}React запоминает предоставленную нами функцию эффекта, выполняет её после сброса значений в DOM и позволяет браузеру вывести изображение на экран.
В результате, даже если мы говорим здесь о единственном концептуальном эффекте (обновляющем заголовок документа), он, в каждом рендере, представлен новой функцией, а каждая функция эффекта «видит» свойства и состояние из конкретного рендера, которому она «принадлежит».
Эффект, концептуально, можно представить в качестве части результатов рендеринга.
Строго говоря, это не так (для того, чтобы сделать возможной композицию хуков без необходимости пользоваться неуклюжим синтаксисом или без создания чрезмерной нагрузки на систему). Но в ментальной модели, созданием которой мы тут занимаемся, функции эффектов принадлежат конкретному рендеру точно так же, как обработчики событий.
Для того чтобы убедиться в том, что мы всё это как следует поняли, давайте рассмотрим ещё раз нашу первую операцию рендеринга:
React:
- Дай мне пользовательский интерфейс в условиях, когда в состояние записано число 0.
Компонент:
- Вот результаты рендеринга:
<p>You clicked 0 times</p>. - Кроме того, не забудь выполнить этот эффект после того, как завершишь работу:
() => { document.title = 'You clicked 0 times' }.
React:
- Конечно. Обновляю интерфейс. Эй, браузер, я добавляю кое-что в DOM.
Браузер:
- Отлично, я вывел это на экран.
React:
- Хорошо, теперь я запущу эффект, который мне дал компонент.
- Выполняю
() => { document.title = 'You clicked 0 times' }.
А теперь давайте разберём то, что происходит после щелчка по кнопке. На самом деле, многое тут повторяет предыдущий разбор, но кое-что здесь выглядит иначе:
Компонент:
- Эй, React, установи моё состояние в 1.
React:
- Дай мне пользовательский интерфейс в условиях, когда в состояние записано число 1.
Компонент:
- Вот результаты рендеринга:
<p>You clicked 1 times</p>. - Кроме того, не забудь выполнить этот эффект после того, как завершишь работу:
() => { document.title = 'You clicked 1 times' }.
React:
- Конечно. Обновляю интерфейс. Эй, браузер, я изменил кое-что в DOM.
Браузер:
- Отлично, я вывел изменения на экран.
React:
- Хорошо, теперь я запущу эффект, который мне дал компонент.
- Выполняю
() => { document.title = 'You clicked 1 times' }.
Каждому рендеру принадлежит… всё
Теперь мы знаем о том, что эффекты, выполняемые после каждой операции рендеринга, концептуально являются частью вывода компонента, и «видят» свойства и состояние из этой конкретной операции.
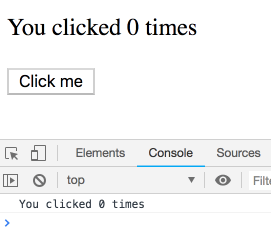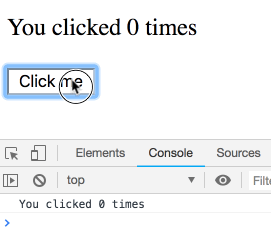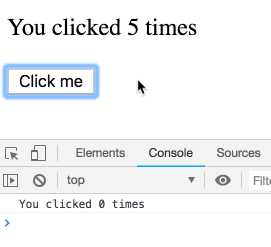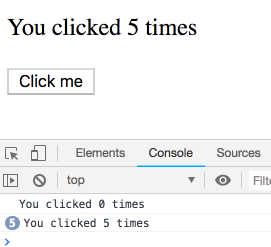
Попробуем выполнить мысленный эксперимент. Рассмотрим следующий код:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}Что будет выведено в консоль в том случае, если быстро щёлкнуть по кнопке несколько раз?
Как обычно, сейчас мы рассмотрим ответ на этот вопрос. Возможно, вам сейчас может показаться, что это простая задачка, и результат работы этого кода интуитивно понятен. Но это не так! Мы увидим последовательность операций, выполняющих вывод в консоль, каждая из которых принадлежит конкретному рендеру, и, в результате, пользуется собственным значением
count. Попробуйте поэкспериментировать с этим примером сами.Щелчки по кнопке и вывод данных в консоль
Тут вы можете подумать: «Конечно, именно так это и работает! Да и может ли эта программа вести себя иначе?».
Ну, на самом деле,
this.setState в компонентах, основанных на классах, работает не так. Поэтому легко допустить ошибку, если полагать, что следующий вариант примера, в котором используется компонент, основанный на классе, эквивалентен предыдущему: componentDidUpdate() {
setTimeout(() => {
console.log(`You clicked ${this.state.count} times`);
}, 3000);
}Дело в том, что
this.state.count всегда указывает на самое свежее значение count, а не на значение, принадлежащее конкретному рендеру. В результате, вместо последовательности сообщений с разными числами, мы, быстро щёлкнув по кнопке 5 раз, увидим 5 одинаковых сообщений.Щелчки по кнопке и вывод данных в консоль
Я вижу иронию в том, что хуки так сильно полагаются на JavaScript-замыкания, а компоненты, основанные на классах, страдают от традиционной проблемы, связанной с неправильным значением, которое попадает в коллбэк функции
setTimeout, которую часто считаю обычной для замыканий. Дело в том, что истинным источником проблемы в этом примере является мутация (React выполняет изменение this.state в классах таким образом, чтобы это значение указывало бы на самую свежую версию состояния), а не механизм замыканий.Замыкания — это отличный инструмент в том случае, если значение, которое «запирают» в замыкании, никогда не меняется. Это облегчает их использование и размышления о них, так как, в сущности, речь идёт о константах. И, как мы уже говорили, свойства и состояние никогда не меняются в конкретном рендере. Да, кстати, версию этого примера, в которой используются компоненты, основанные на классах, можно исправить, воспользовавшись замыканием.
Плывём против течения
Сейчас нам важно отметить, что каждая функция внутри механизма рендеринга компонента (включая обработчики событий, эффекты, тайм-ауты или вызовы API внутри них) захватывает свойства и состояние вызова рендера, который их определил.
В результате следующие два компонента эквивалентны:
function Example(props) {
useEffect(() => {
setTimeout(() => {
console.log(props.counter);
}, 1000);
});
// ...
}
function Example(props) {
const counter = props.counter;
useEffect(() => {
setTimeout(() => {
console.log(counter);
}, 1000);
});
// ...
}При этом неважно, выполняется ли внутри компонента «заблаговременное» чтение из свойств или состояния. Они не изменятся! Внутри области видимости отдельно взятого рендера свойства и состояния не изменяются. Надо отметить, что деструктурирование свойств делает это более очевидным.
Конечно, иногда, внутри какого-нибудь коллбэка, объявленного в эффекте, нужно прочитать самое свежее значение, а не то, что было захвачено. Легче всего это сделать, используя ссылки
ref, почитать об этом можно в последнем разделе этой статьи.Учитывайте то, что когда вам нужно прочитать будущие свойства или состояние из функции, принадлежащей ранее выполненной операции рендеринга, то вы, так сказать, пытаетесь плыть против течения. Нельзя сказать, что это неправильно (и иногда это просто необходимо), но менее «чистым» решением может показаться выход за рамки традиционной парадигмы React-разработки. Такой шаг может вести к ожидаемым последствиям, так как это помогает лучше увидеть то, какие фрагменты кода являются ненадёжными и зависящими от таймингов. Когда подобное происходит при работе с классами, это оказывается менее очевидным.
Вот версия нашего примера со счётчиком щелчков, основанная на функции, которая воспроизводит поведение той его версии, которая основана на классе:
function Example() {
const [count, setCount] = useState(0);
const latestCount = useRef(count);
useEffect(() => {
// Установить мутабельное значение в самое свежее состояние count
latestCount.current = count;
setTimeout(() => {
// Прочитать мутабельное значение с самыми свежими данными
console.log(`You clicked ${latestCount.current} times`);
}, 3000);
});
// ...Щелчки по кнопке и вывод данных в консоль
Заниматься изменениями чего-либо в React может показаться странной идеей. Однако именно так сам React переназначает значение
this.state в классах. В отличие от работы с захваченными свойствами и состоянием, у нас нет никакой гарантии того, что чтение latestCount.current даст один и тот же результат в разных коллбэках. По определению, менять это значение можно в любое время. Именно поэтому этот механизм не применяется по умолчанию, и для того, чтобы им воспользоваться, нужно сделать осознанный выбор.Как насчёт очистки?
Как поясняется в документации, некоторые эффекты могут иметь фазу очистки. В сущности, цель этой операции заключается в том, чтобы «отменять» действия эффектов для вариантов их применения наподобие оформления подписок.
Рассмотрим этот код:
useEffect(() => {
ChatAPI.subscribeToFriendStatus(props.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.id, handleStatusChange);
};
});Предположим,
props — это объект {id: 10} в первой операции рендеринга, и {id: 20} — во второй. Можно подумать, что тут происходит примерно следующее:- React выполняет очистку эффекта для
{id: 10}. - React рендерит интерфейс для
{id: 20}. - React выполняет эффект для
{id: 20}.
(Но это, на самом деле, не совсем так.)
Пользуясь этой ментальной моделью можно подумать, что операция очистки «видит» старые свойства из-за того, что она выполняется до повторного рендеринга, после чего новый эффект «видит» новые свойства из-за того, что он выполняется после повторного рендеринга. Это — ментальная модель, которая базируется на методах жизненного цикла компонентов, основанных на классах, и здесь она не позволяет добиться точных результатов. Поговорим о причинах этого несоответствия.
React выполняет эффекты только после того, как позволит браузеру вывести изображение на экран. Это ускоряет приложение, так как большинству эффектов не нужно блокировать обновления экрана. Очистка эффекта также откладывается. Предыдущий эффект входит в стадию очистки после повторного рендеринга с новыми свойствами. В результате мы выходим на следующую последовательность действий:
- React рендерит интерфейс для
{id: 20}. - Браузер выводит изображение на экран. Пользователь видит интерфейс для
{id: 20}. - React выполняет очистку эффекта для
{id: 10}. - React выполняет эффект для
{id: 20}.
Тут вы можете задаться вопросом о том, как операция очистки предыдущего эффекта всё ещё может видеть «старое» значение
props, содержащее {id: 10}, после того, как в props записано {id: 20}.Надо отметить, что мы уже здесь были…
А может это — та же самая кошка?
Приведём цитату из предыдущего раздела: «каждая функция внутри механизма рендеринга компонента (включая обработчики событий, эффекты, тайм-ауты или вызовы API внутри них) захватывает свойства и состояние вызова рендера, который их определил».
Теперь ответ очевиден! В ходе операции очистки эффекта не производится чтение «самых свежих» свойств, что бы это ни значило. Эта операция читает свойства, которые принадлежат рендеру, в котором они определены:
// Первый рендер, в props записано {id: 10}
function Example() {
// ...
useEffect(
// Эффект из первого рендера
() => {
ChatAPI.subscribeToFriendStatus(10, handleStatusChange);
// Очистка для эффекта из первого рендера
return () => {
ChatAPI.unsubscribeFromFriendStatus(10, handleStatusChange);
};
}
);
// ...
}
// Следующий рендер, в props записано {id: 20}
function Example() {
// ...
useEffect(
// Эффект из второго рендера
() => {
ChatAPI.subscribeToFriendStatus(20, handleStatusChange);
// Очистка для эффекта из второго рендера
return () => {
ChatAPI.unsubscribeFromFriendStatus(20, handleStatusChange);
};
}
);
// ...
}Королевства будут расти и превращаться в пепел, Солнце сбросит внешние оболочки и станет белым карликом, последняя цивилизация исчезнет… Но ничто не заставит свойства, которые «увидела» операция очистки эффекта из первого рендеринга, превратиться во что-то, отличающееся от
{id: 10}.Именно это позволяет React работать с эффектами сразу после вывода изображения на экран. Это, без дополнительных усилий со стороны программиста, делает его приложения быстрее. Если нашему коду понадобятся старые значения
props, они никуда не деваются.Синхронизация, а не жизненный цикл
Одной из моих любимых особенностей React является то, что эта библиотека унифицирует описание результатов первого рендеринга компонента и обновлений. Это уменьшает энтропию программ.
Предположим, мой компонент выглядит так:
function Greeting({ name }) {
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}При его использовании совершенно неважно, будет ли сначала отрендерено
<Greeting name="Dan" />, а потом — <Greeting name="Yuzhi" />, или если компонент просто сразу выведет <Greeting name="Yuzhi" />. И в том и в другом случаях в итоге мы увидим текст Hello, Yuzhi.Говорят, что важен путь, а не цель. Если говорить о React, то справедливым окажется обратное утверждение. Здесь важна цель, а не то, каким путём к ней идут. В этом и заключается разница между вызовами вида
$.addClass и $.removeClass в jQuery-коде (это — то, что мы называем «путём»), и указание того, каким должен быть CSS-класс в React (то есть — того, какой должна быть «цель»).React синхронизирует DOM с тем, что имеется в текущих свойствах и состоянии. При рендеринге нет разницы между «монтированием» и «обновлением».
Об эффектах стоит размышлять в похожем ключе. Использование
useEffect позволяет синхронизировать сущности, находящиеся за пределами дерева React, со свойствами и состоянием.function Greeting({ name }) {
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}В этом состоит незначительное отличие восприятия
useEffect от привычной ментальной модели, в которую входят понятия монтирования, обновления и размонтирования компонентов. Если вы пытаетесь создать эффект, который ведёт себя по-особому при первом рендеринге компонента, то вы пытаетесь плыть против течения! Синхронизация не удастся в том случае, если наш результат зависит от «пути», а не от «цели».Не должно быть разницы между тем, выполняем ли мы рендеринг компонента сначала со свойством
A, потом с B, а потом — со свойством C, и той ситуацией, когда мы сразу же рендерим его со свойством C. Хотя в процессе работы этих двух вариантов кода и могут быть некоторые временные различия (например, возникающие при загрузке каких-либо данных), в итоге конечный результат должен быть тем же самым.Надо отметить, что, конечно, выполнение эффекта при каждой операции рендеринга может быть неэффективным вариантом решения некоей задачи. (А в некоторых случаях это может привести к бесконечным циклам).
Как с этим бороться?
Учим React различать эффекты
Мы уже научили React разборчивости при работе с DOM. Вместо того чтобы касаться DOM при каждой операции повторного рендеринга компонента, React обновляет лишь те части DOM, которые по-настоящему меняются.
Предположим, у нас есть такой код:
<h1 className="Greeting">
Hello, Dan
</h1>Мы хотим обновить его до такого состояния:
<h1 className="Greeting">
Hello, Yuzhi
</h1>React видит два объекта:
const oldProps = {className: 'Greeting', children: 'Hello, Dan'};
const newProps = {className: 'Greeting', children: 'Hello, Yuzhi'};React просматривает свойства этих объектов и выясняет, что значение
children изменилось, для его вывода на экран нужно обновление DOM. При этом оказывается, что className осталось неизменным. Поэтому можно просто поступить так:domNode.innerText = 'Hello, Yuzhi';
// domNode.className трогать не нужноМожем ли мы сделать что-то подобное этому и с эффектами? Было бы очень хорошо, если можно было бы избежать их повторного запуска в тех случаях, когда в их применении нет необходимости.
Например, возможно, компонент выполняет повторный рендеринг из-за изменения состояния:
function Greeting({ name }) {
const [counter, setCounter] = useState(0);
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
<button onClick={() => setCounter(counter + 1)}>
Increment
</button>
</h1>
);
}Но эффект не использует значение
counter из состояния. Эффект синхронизирует document.title со свойством name, но свойство name тут не меняется. Перезапись document.title при каждом изменении counter кажется решением, далёким от идеального.Может ли React просто… сравнить эффекты?
let oldEffect = () => { document.title = 'Hello, Dan'; };
let newEffect = () => { document.title = 'Hello, Dan'; };
// Может ли React увидеть то, что эти функции делают одно и то же?На самом деле — нет. React не может догадаться о том, что именно делает функция, не вызывая её. (Исходный код не содержит конкретных значений. Он просто включает в себя свойство
name.)Именно поэтому, если нужно избежать ненужных перезапусков эффектов, эффекту можно передать массив зависимостей (такие массивы ещё называют
deps), выглядящий как аргумент useEffect: useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]); // Наши зависимостиЭто похоже на то, как если бы мы сказали React: «Слушай, я понимаю, что внутрь этой функции ты заглянуть не можешь, но я обещаю, что я будут использовать только
name и ничего другого из области видимости рендера».Если окажется так, что зависимости после предыдущего вызова эффекта не менялись, то эффекту нечего будет синхронизировать и React может выполнение этого эффекта пропустить:
const oldEffect = () => { document.title = 'Hello, Dan'; };
const oldDeps = ['Dan'];
const newEffect = () => { document.title = 'Hello, Dan'; };
const newDeps = ['Dan'];
// React не может заглянуть в функцию, но он может сравнить зависимости.
// Так как значения зависимостей остались прежними, новый эффект вызывать не нужно.Если же хотя бы одно значение из массива зависимостей изменится, то мы будем знать, что при очередном выполнении рендеринга вызов эффекта пропустить нельзя! Ведь иначе ни о какой синхронизации чего-либо с чем-либо не может быть и речи.
Не лгите React о зависимостях
Если утаить от React правду о зависимостях — это будет иметь плохие последствия. Интуитивно понятно, что это так, но мне довелось наблюдать за тем, что практически все люди, которые пытались пользоваться
useEffect, полагаясь на сложившуюся у них ментальную модель компонентов, основанных на классах, пытаются обойти правила. (И я поначалу поступал точно так же!)function SearchResults() {
async function fetchData() {
// ...
}
useEffect(() => {
fetchData();
}, []); // Нормально ли это? Не всегда. Есть лучшие способы написания такого кода.
// ...
}FAQ по хукам даёт пояснения по поводу того, что тут правильно будет сделать. Мы вернёмся к этому примеру позже.
«Но я хочу запустить эффект только при монтировании!», — скажете вы. Пока запомните: если вы указываете зависимости, то в массиве должны быть представлены все значения из компонента, которые используются эффектом. Сюда входят свойства, состояние, функции, то есть — всё, что находится в компоненте и используется эффектом.
Иногда, когда вы так поступаете, это вызывает проблемы. Например, может быть, вы сталкиваетесь с бесконечным циклом загрузки данных, или с тем, что слишком часто пересоздаются сокеты. Решение этой проблемы заключается не в том, чтобы избавиться от зависимостей. Скоро мы это обсудим.
Но, прежде чем мы перейдём к решению, давайте лучше вникнем в суть проблемы.
Что происходит в том случае, когда зависимости лгут React
Если зависимости содержат абсолютно все значения, используемые эффектом, то React знает о том, когда этот эффект нужно перезапустить.
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]);Так как зависимости различаются — эффект перезапускается
Но если мы для этого эффекта укажем, в качестве зависимостей, пустой массив,
[], тогда, при обновлении данных, используемых в эффекте, он перезапущен не будет: useEffect(() => {
document.title = 'Hello, ' + name;
}, []); // Неправильно: в зависимостях нет nameЗависимости выглядят одинаково — эффект повторно не вызывается
В данном случае проблема может показаться очевидной и интуитивно понятной. Но интуиция может подвести в других случаях, когда из памяти «всплывают» идеи, навеянные работой с компонентами, основанными на классах.
Например, предположим, мы создаём счётчик, который увеличивается каждую секунду. Если использовать для его реализации класс, то внутреннее чутьё подскажет нам следующее: «Один раз настроить
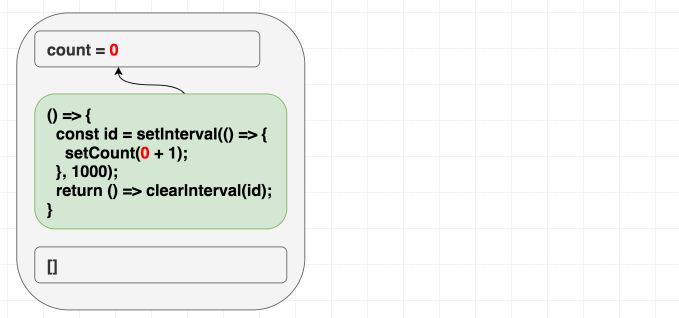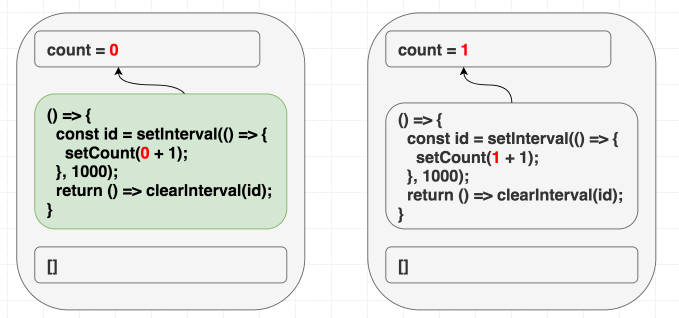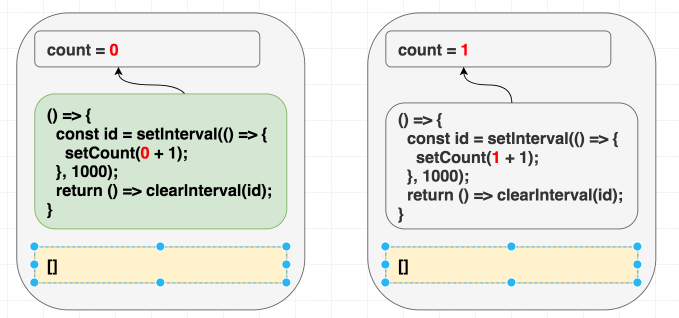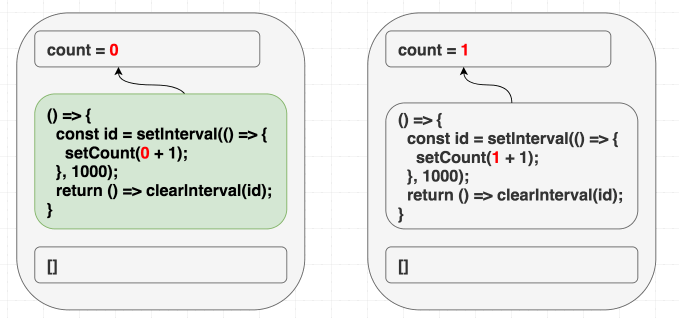
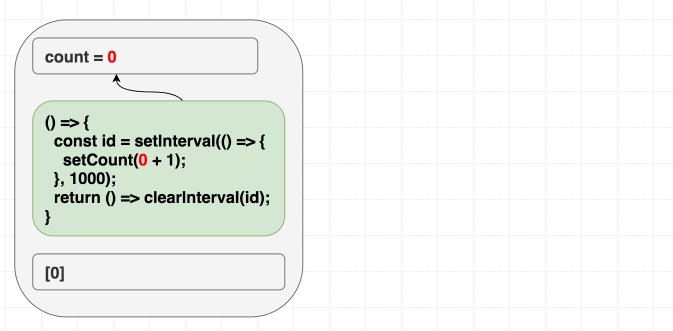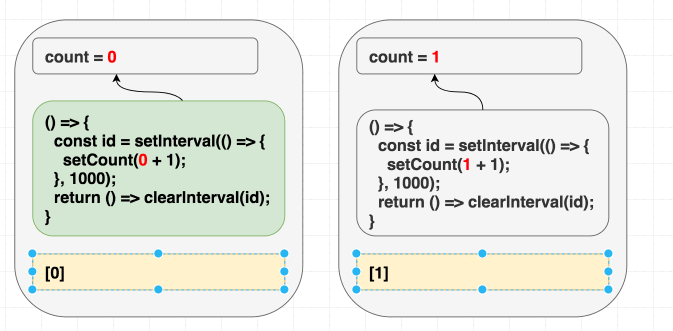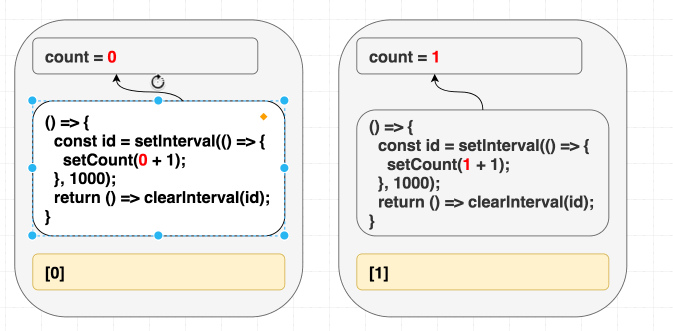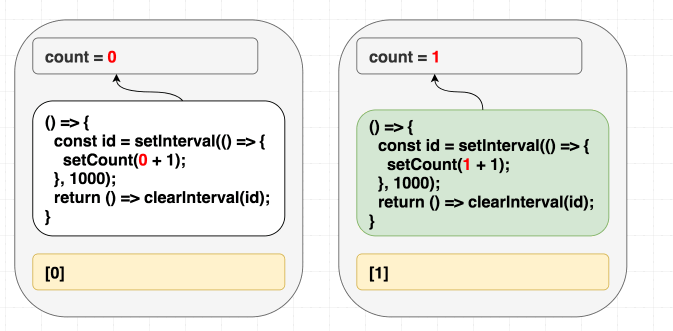
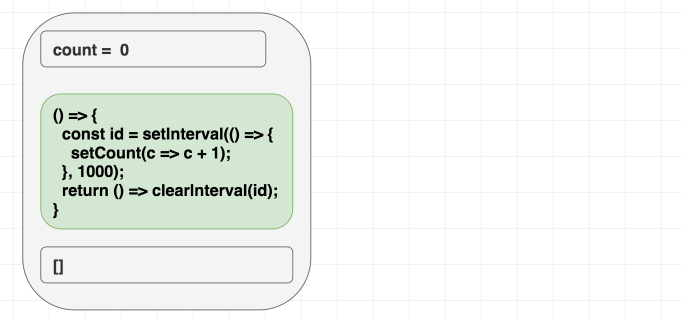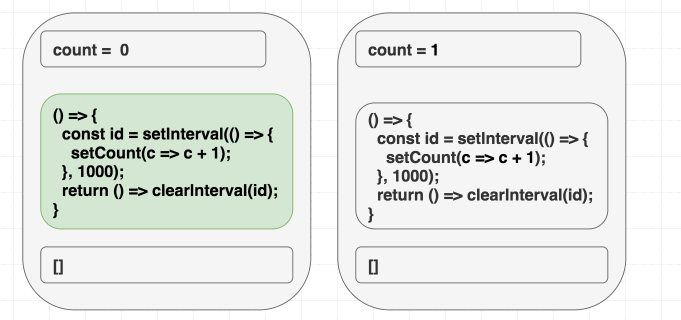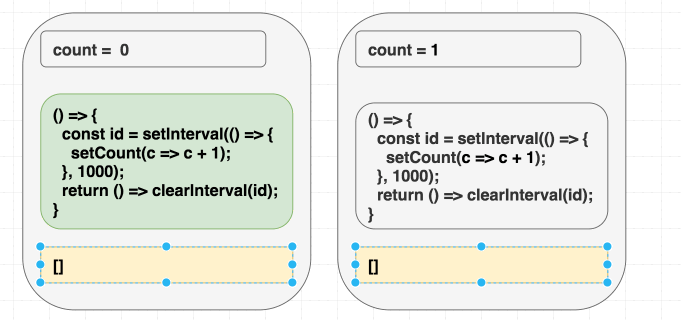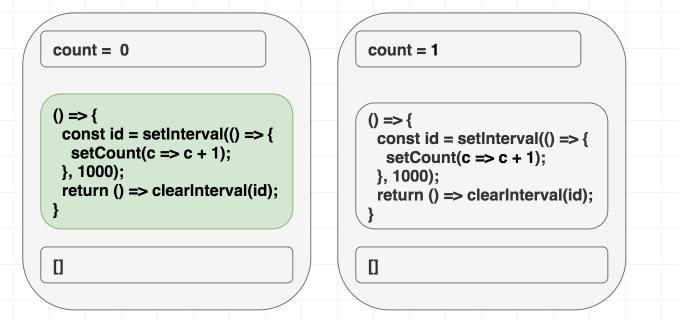
setInterval для запуска счётчика и один раз использовать clearInterval для его остановки». Вот пример реализации этого механизма. Когда мы, в голове, переносим подобный подход, планируя воспользоваться useEffect, то мы, инстинктивно, указываем в качестве зависимостей []. Запустить-то счётчик нам нужно лишь один раз, верно?function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);
return <h1>{count}</h1>;
}Однако, вот незадача, в таком случае счётчик обновится лишь один раз.
Если в голове у вас имеется модель, в соответствии с которой «зависимости позволяют мне указывать на то, когда я хочу повторно вызывать эффект», то этот пример может довести вас до экзистенциального кризиса. Ведь вам нужно, чтобы эффект был вызван лишь один раз, так как в его коде вы, используя
setInterval, запускаете счётчик. Почему же код работает не так, как ожидается?Но если вы знаете о том, что зависимости — это наша подсказка для React обо всём том, что эффект использует из области видимости рендера, то такое поведение этой программы вас не удивит. А именно, эффект использует
count, но мы не сообщили React правду об этом, указав, в качестве списка зависимостей, пустой массив. И когда эта ложь приведёт к проблемам — лишь вопрос времени.В первой операции рендеринга
count равняется 0. В результате setCount(count + 1) в эффекте первого рендера означает setCount(0 + 1). Так как мы никогда этот эффект повторно не вызываем, причиной чему — зависимости в виде [], каждую секунду будет вызываться setCount(0 + 1):// Первый рендеринг, состояние равно 0
function Counter() {
// ...
useEffect(
// Эффект из первого рендера
() => {
const id = setInterval(() => {
setCount(0 + 1); // Всегда setCount(1)
}, 1000);
return () => clearInterval(id);
},
[] // Никогда не перезапускается
);
// ...
}
// В каждом следующем рендере состояние равно 1
function Counter() {
// ...
useEffect(
// Этот эффект всегда игнорируется из-за того, что
// мы солгали React о зависимостях, передав пустой массив.
() => {
const id = setInterval(() => {
setCount(1 + 1);
}, 1000);
return () => clearInterval(id);
},
[]
);
// ...
}Мы солгали React, сообщив о том, что наш эффект не зависит от значений из компонента, хотя на самом деле — зависит.
Наш эффект использует
count — значение, находящееся внутри компонента (но за пределами эффекта): const count = // ...
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);В результате указание пустого массива в качестве списка зависимостей приводит к ошибке. React сравнит зависимости и не станет повторно вызывать эффект.
Зависимости не меняются, поэтому вызов эффекта можно пропустить
Непросто искать решения проблем такого рода в уме. Поэтому я советую вам жёстко придерживаться правила, которое заключается в том, что React всегда нужно честно сообщать о зависимостях эффектов, и в том, чтобы указывать все эти зависимости. Если вы хотите получить поддержку линтера в выполнении этого правила — мы приготовили кое-что для вас и для вашей команды.
Два подхода к честности при работе с зависимостями
Для того чтобы всегда честно сообщать React о зависимостях эффектов, можно воспользоваться одной из двух стратегий. Обычно стоит начать с первой, а затем, если это будет нужно, обратиться ко второй.
Первая стратегия заключается в исправлении массива зависимостей, во внесении в него всех значений, находящихся в компоненте, которые используются внутри эффекта. Добавим в массив зависимостей
count:useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);Теперь массив зависимостей исправлен. Возможно, такое решение не идеально, но это — первая проблема, которую нам нужно решить. Теперь изменение
count приведёт к перезапуску эффекта, каждый следующий вызов счётчика будет ссылаться на значение count из его рендера, выполняя операцию setCount(count + 1):// Первый рендеринг, состояние равно 0
function Counter() {
// ...
useEffect(
// Эффект из первого рендера
() => {
const id = setInterval(() => {
setCount(0 + 1); // setCount(count + 1)
}, 1000);
return () => clearInterval(id);
},
[0] // [count]
);
// ...
}
// Второй рендер, состояние равно 1
function Counter() {
// ...
useEffect(
// Эффект из второго рендера
() => {
const id = setInterval(() => {
setCount(1 + 1); // setCount(count + 1)
}, 1000);
return () => clearInterval(id);
},
[1] // [count]
);
// ...
}Такой подход позволяет решить проблему, но
setInterval будет, при каждом изменении count, очищаться и запускаться снова. Вероятно, нас это не устроит.Зависимости различаются, поэтому эффект мы перезапускаем
Вторая стратегия заключается в изменении кода эффекта таким образом, чтобы ему не понадобилось бы значение, которое меняется чаще, чем нам нужно. Нам не нужно лгать о зависимостях — мы просто хотим изменить эффект так, чтобы у него было бы меньше зависимостей.
Рассмотрим несколько распространённых подходов избавления от зависимостей.
Делаем эффект самодостаточным
Итак, мы хотим избавиться от зависимости
count в эффекте.useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, [count]);Для того чтобы это сделать, зададимся вопросом о том, для чего мы используем
count. Возникает такое ощущение, что мы используем count только в вызове setCount. В таком случае нам, на самом деле, совершенно не нужно иметь count в области видимости. Когда мы хотим обновить состояние, основываясь на предыдущем состоянии, мы можем использовать функциональную форму обновления setState: useEffect(() => {
const id = setInterval(() => {
setCount(c => c + 1);
}, 1000);
return () => clearInterval(id);
}, []);Я предпочитаю рассматривать подобные случаи как «ненастоящие зависимости». Да, значение
count было необходимой зависимостью из-за того, что мы использовали внутри эффекта конструкцию setCount(count + 1). Однако count нам по-настоящему нужно лишь для того, чтобы преобразовать это значение в count + 1 и «вернуть» его React. Но React уже знает о текущем значении count. Всё, что нам нужно сообщить React — это сведения о том, что соответствующее значение состояния, в его текущем виде, нужно увеличить на единицу.Именно эту задачу и решает конструкция
setCount(c => c + 1). Её можно воспринимать как «отправку React инструкции», описывающей то, как должно изменяться состояние. Такая «форма обновления» оказывается полезной и в других случаях, например, если выполняется объединение множества обновлений.Обратите внимание на то, что мы, на самом деле, избавились от зависимости. И мы при этом не обманываем React. Наш эффект больше не выполняет чтение значения
count из области видимости рендера:Зависимости не меняются, поэтому эффект повторно не вызывается
Испытать этот пример можно здесь.
Даже хотя этот эффект вызывается лишь один раз, коллбэк
setInterval, который принадлежит первому рендеру, прекрасно справляется с отправкой инструкции c => c + 1 при каждом срабатывании таймера. Ему не нужно знать текущее значение count. React уже известно это значение.Функциональные обновления и Google Docs
Помните, как мы говорили о том, что синхронизация — это основа ментальной модели эффектов? Интересным аспектом синхронизации является тот факт, что часто нужно, чтобы «сообщения», передаваемые между системами, не были бы привязаны к их состоянию. Например, правка документа в Google Docs не приводит к отправке всей страницы на сервер. Это было бы очень неэффективным решением. Вместо этого на сервер отправляется представление того, что попытался сделать пользователь.
Хотя наш случай и отличается от вышеописанного, похожие рассуждения применимы и к эффектам. Подобный подход способствует отправке из эффектов в компонент лишь минимально необходимого объёма информации. Использование функциональной формы системы обновления состояния, выраженной в виде
setCount(c => c + 1), приводит к передаче гораздо меньшего объёма информации, чем использование конструкции вида setCount(count + 1), так как функциональная форма обновления состояния не «загрязнена» текущим значением count. Она лишь описывает действие, которое нужно выполнить (то есть — «увеличение»). «Думать в стиле React» — значит искать минимально возможное представление состояния. Тот же принцип применим и при планировании обновлений.Выражение в коде намерения (а не описание в нём результата) похоже на то, как Google Docs решает проблему совместного редактирования документов. Хотя это — и не вполне точная аналогия, функциональные обновления играют в React похожую роль. Они позволяют обеспечить то, что обновления, исходящие из нескольких источников (обработчики событий, подписки эффектов, и так далее) могут быть корректно и предсказуемо применены в пакетном режиме.
Однако даже решение, в котором используется конструкция
setCount(c => c + 1), нельзя признать безупречным. Выглядит оно немного странно, да и возможности такой конструкции очень ограничены. Например, нам это не поможет в том случае, когда в состоянии имеются две переменные, значения которых зависят друг от друга, или тогда, когда следующий вариант состояния нужно получить на основе свойств. К счастью у setCount(c => c + 1) есть более мощный родственный паттерн. Он называется useReducer.Отделение обновлений от действий
Давайте модифицируем предыдущий пример так, чтобы в состоянии было бы две переменных:
count и step. В setInterval счётчик будет увеличиваться на значение, записанное в step:function Counter() {
const [count, setCount] = useState(0);
const [step, setStep] = useState(1);
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + step);
}, 1000);
return () => clearInterval(id);
}, [step]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => setStep(Number(e.target.value))} />
</>
);
}Вот рабочая версия этого примера.
Обратите внимание на то, что мы тут React не обманываем. Так как теперь в эффекте используется
step, соответствующим образом изменён список зависимостей. И именно поэтому код выполняется правильно.Сейчас этот пример работает так: изменение
step перезапускает setInterval — так как step является одной из зависимостей эффекта. И, во многих случаях, это именно то, что нужно разработчику! Нет ничего плохого в том, чтобы разрушать то, что было создано средствами эффекта и создавать это заново, и мы, если только на то нет веской причины, не должны этого избегать.Но давайте предположим, что нам нужно, чтобы таймер, создаваемый с помощью
setInterval, не сбрасывался бы при изменении step. Как убрать зависимость step из эффекта?Когда установка значения переменной состояния зависит от текущего значения другой переменной состояния, возможно, имеет смысл заменить обе эти переменных с помощью
useReducer.Когда вы обнаруживаете, что пишете нечто вроде
setSomething(something => ...), это значит, что пришло время серьёзно подумать об использовании редьюсера вместо такого кода. Редьюсер позволяет отделять выражения «действий», которые происходят в компоненте, от того, как в ответ на них обновляется состояние.Поменяем зависимость нашего эффекта
step на зависимость dispatch:const [state, dispatch] = useReducer(reducer, initialState);
const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' }); // Вместо setCount(c => c + step);
}, 1000);
return () => clearInterval(id);
}, [dispatch]);Тут можно посмотреть этот код в деле.
Вы можете задать мне вопрос: «А чем это лучше того, что было?». Ответ заключается в том, что React гарантирует то, что функция
dispatch будет неизменна в течение времени жизни компонента. Поэтому в вышеприведённом примере даже не нужно выполнять повторное создание таймера.Мы решили проблему!
(Вы можете опустить значения
dispatch и setstate и воспользоваться механизмом контейнеризации значений useRef для работы со значениями из зависимостей, так как React гарантирует то, что они будут статичными. Но если их указать — делу это не повредит.)Внутри эффекта, вместо считывания значений из состояния, выполняется диспетчеризация действия, которое описывает сведения о том, что произошло. Это позволяет нашему эффекту оставаться отделённым от значения состояния
step. Эффект не заботит то, как именно мы обновляем состояние. Он просто сообщает нам о том, что произошло. А логика обновления собрана в редьюсере:const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') {
return { count: count + step, step };
} else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}Вот, на тот случай, если вы не видели его раньше, полный код этого примера.
Использование useReducer — это чит-режим хуков
Мы узнали о том, как избавляться от зависимостей в том случае, когда эффекту нужно устанавливать значение переменной состояния, основываясь на предыдущей версии состояния или на другой переменной состояния. Но что если нам, для нахождения следующей версии состояния, нужны свойства? Например, возможно, наше API имеет вид
<Counter step={1} />. Очевидно, в такой ситуации нельзя избежать указания props.step в качестве зависимости эффекта?На самом деле, избавиться от зависимостей можно и в этом случае! Редьюсер можно поместить в компонент, что позволит ему считывать значения свойств:
function Counter({ step }) {
const [count, dispatch] = useReducer(reducer, 0);
function reducer(state, action) {
if (action.type === 'tick') {
return state + step;
} else {
throw new Error();
}
}
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return <h1>{count}</h1>;
}Применение этого паттерна мешает некоторым оптимизациям, поэтому постарайтесь не использовать его повсюду. Однако, если это нужно, то вы, прибегая к нему, сможете получить доступ к свойствам из редьюсера. Вот работающий пример.
Даже в этом случае гарантируется стабильность сущности
dispatch в разных операциях рендеринга. Поэтому её, если нужно, можно убрать из зависимостей эффекта. Её использование не приведёт к перезапуску эффекта.Возможно, сейчас вы задаётесь вопросом о том, что позволяет всему этому правильно работать. Откуда редьюсер «знает» значения свойств, когда вызывается внутри эффекта, который принадлежит другому рендеру? Ответ заключается в том, что когда выполняется функция
dispatch, React просто запоминает действие. Он вызовет редьюсер в ходе следующей операции рендеринга. В этот момент в области видимости будут свежие свойства и вы не будете находиться внутри эффекта.Именно поэтому я предпочитаю воспринимать использование
useReducer как нечто вроде «чит-режима» хуков. Это позволяет мне отделять логику обновления от описания того, что произошло. Это, в свою очередь, помогает мне избавляться от ненужных зависимостей эффектов и избегать их перезапуска, выполняемого чаще, чем необходимо.Перемещение функций в эффекты
Обычная ошибка при работе с эффектами заключается в том, что функции считают чем-то таким, что не должно присутствовать в составе зависимостей эффектов.
Например, следующий код, вроде бы, выглядит рабочим:
function SearchResults() {
const [data, setData] = useState({ hits: [] });
async function fetchData() {
const result = await axios(
'https://hn.algolia.com/api/v1/search?query=react',
);
setData(result.data);
}
useEffect(() => {
fetchData();
}, []); // Нормально ли это?
// ...
Этот пример подготовлен на основе данной отличной статьи, на которую я рекомендую вам взглянуть.
На самом деле, надо отметить, что этот код всё же работает. Но проблема, выражающаяся в том, что локальную функцию не включили в состав зависимостей эффекта, заключается в том, что, по мере роста компонента, становится сложно понять то, вызывается ли эффект во всех тех случаях, когда он должен вызываться.
Представим, что код нашей функции оказывается разделённым так, как показано ниже, и кроме того то, что он стал в пять раз больше:
function SearchResults() {
// Представим, что эта функция имеет большой размер
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=react';
}
// Представим, что и код этой функции гораздо длиннее
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}Теперь предположим, что, в ходе работы над компонентом мы решили использовать в одной из этих функций свойства или состояние:
function SearchResults() {
const [query, setQuery] = useState('react');
// Представим, что эта функция имеет большой размер
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
// Представим, что и код этой функции гораздо длиннее
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}Если мы забудем обновить зависимости любого эффекта, вызывающего эти функции (возможно, через обращение к другим функциям), то эффект не сможет синхронизировать изменения свойств и состояния. Звучит это не особенно приятно.
К счастью, у этой проблемы есть простое решение. Если некоторые функции используются только внутри некоего эффекта, их объявления нужно переместить прямо внутрь этого эффекта:
function SearchResults() {
// ...
useEffect(() => {
// Мы переместили эти функции внутрь эффекта!
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=react';
}
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
fetchData();
}, []); // С зависимостями всё хорошо.
// ...
}Вот рабочий вариант этого примера.
В чём же заключаются сильные стороны перемещения функций в эффекты? Дело в том, что при таком подходе нам больше не приходится думать о «промежуточных зависимостях». Наш массив зависимостей больше не лжёт React, так как мы по-настоящему не используем в эффекте ничего из внешней области видимости компонента.
Если позже мы отредактируем код
getFetchUrl, решив воспользоваться там переменной состояния query, то мы, вероятнее всего, заметим, что редактируем код внутри эффекта. А значит — мы поймём, что query надо добавить в зависимости эффекта: function SearchResults() {
const [query, setQuery] = useState('react');
useEffect(() => {
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
fetchData();
}, [query]); // С зависимостями всё хорошо.
// ...
}Вот демонстрационная версия этого примера.
Добавляя эту зависимость, мы не просто «успокаиваем React». Её наличие позволяет перезагрузить данные при изменении
query. То, как устроены эффекты, принуждает программиста к тому, чтобы он замечал бы изменения в потоке данных и указывал бы на то, как эффекты должны их синхронизировать. Это куда лучше, чем закрывать глаза на такие изменения до тех пор, пока подобное не вызовет ошибку.Благодаря правилу линтера
exhaustive-deps из плагина eslint-plugin-react-hooks можно анализировать код эффектов в процессе его ввода и видеть подсказки, касающиеся неуказанных зависимостей. Другими словами, компьютер может сообщить программисту о том, какие изменения в потоке данных не обрабатываются компонентом правильно.Линтер в действии
Это очень удобно.
Как быть, если поместить функцию внутрь эффекта нельзя?
Иногда перемещение функции внутрь эффекта может оказаться невозможным. Например, несколько эффектов в одном и том же компоненте могут вызывать одну и ту же функцию, и программист не хочет создавать несколько копий такой функции. Или, возможно, эта функция хранится в свойствах компонента.
Можно ли не указывать подобные функции в составе зависимостей эффекта? Я думаю, что нельзя. Повторюсь: эффект не должен лгать React о зависимостях. Обычно можно найти достойное решение подобной проблемы. Типичным заблуждением в подобной ситуации является мысль о том, что «функция никогда не изменится». Но, как мы уже видели, это совсем не так. На самом деле, функция, объявленная внутри компонента, изменяется в каждой операции рендеринга!
Это, и само по себе, является проблемой. Предположим, что два эффекта вызывают функцию
getFetchUrl:function SearchResults() {
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... Загрузим данные и что-то с ними сделаем...
}, []); // Отсутствующая зависимость: getFetchUrl
useEffect(() => {
const url = getFetchUrl('redux');
// ... Загрузим данные и что-то с ними сделаем...
}, []); // Отсутствующая зависимость: getFetchUrl
// ...
}В подобной ситуации перемещение функции
getFetchUrl в один из эффектов — не лучшая идея, так как это не позволит организовать её совместное использование несколькими эффектами.С другой стороны, если быть «честным» при указании зависимостей, можно столкнуться с проблемой. Так как оба эффекта зависят от функции
getFetchUrl (которая, в разных операциях рендеринга, представлена разными сущностями), массивы зависимостей оказываются бесполезными:function SearchResults() {
// Повторно вызывается в каждой операции рендеринга
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... Загрузим данные и что-то с ними сделаем ...
}, [getFetchUrl]); // Зависимости настроены правильно, но они изменяются слишком часто.
useEffect(() => {
const url = getFetchUrl('redux');
// ... Загрузим данные и что-то с ними сделаем...
}, [getFetchUrl]); // Зависимости настроены правильно, но они изменяются слишком часто.
// ...
}Эту проблему так и хочется решить, просто исключив функцию
getFetchUrl из списка зависимостей. Но я не думаю, что это — хорошее решение. Из-за этого сложнее будет ухватить тот момент, когда мы вносим в поток данных изменения, которые должны быть обработаны эффектом. Это ведёт к ошибкам наподобие той, связанной с неправильно работающим таймером, никогда не обновляющим данные, которую мы уже видели.Вместо этого — вот два более простых варианта решения данной проблемы.
Для начала, если функция не использует ничего из области видимости компонента, её можно вынести за пределы компонента и спокойно использовать в эффектах:
// Поток данных на эту функцию не влияет
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
function SearchResults() {
useEffect(() => {
const url = getFetchUrl('react');
// ... Загрузим данные и что-то с ними сделаем...
}, []); // С зависимостями всё в порядке.
useEffect(() => {
const url = getFetchUrl('redux');
// ... Загрузим данные и что-то с ними сделаем...
}, []); // С зависимостями всё в порядке.
// ...
}Эту функцию не нужно указывать в составе зависимостей, так как она не находится в области видимости рендера и на неё не может подействовать поток данных. И она не может, по случайности, стать зависимой от свойств или состояния.
Вот ещё один вариант решения этой проблемы. Он заключается в том, что функцию можно обернуть в хук useCallback:
function SearchResults() {
// Если зависимости не меняются, сущность сохраняется
const getFetchUrl = useCallback((query) => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // С зависимостями коллбэка всё в порядке.
useEffect(() => {
const url = getFetchUrl('react');
// ... Загрузим данные и что-то с ними сделаем...
}, [getFetchUrl]); // С зависимостями эффекта всё в порядке.
useEffect(() => {
const url = getFetchUrl('redux');
// ... Загрузим данные и что-то с ними сделаем...
}, [getFetchUrl]); // С зависимостями эффекта всё в порядке
// ...
}Использование
useCallback напоминает добавление в систему ещё одного уровня проверки зависимостей. Использование этого механизма представляет собой подход к решению нашей проблемы с другой стороны: вместо того, чтобы избегать функций-зависимостей, мы делаем так, что сама функция меняется только тогда, когда это необходимо.Рассмотрим этот подход и поговорим о том, почему его применение целесообразно. Ранее наш пример выводил результаты поиска по двум запросам (
'react' и 'redux'). Но предположим, что мы хотим добавить в компонент поле ввода, которое позволяет пользователю приложения выполнять поиск по любому запросу, представленному свойством состояния query. В результате, вместо того, чтобы рассматривать query в виде аргумента функции, getFetchUrl теперь читает соответствующее значение из локального состояния.Попытавшись сделать это, мы тут же заметим отсутствие зависимости
query в useCallback:function SearchResults() {
const [query, setQuery] = useState('react');
const getFetchUrl = useCallback(() => { // Нет аргумента query
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // Отсутствующая зависимость: query
// ...
}Если исправить зависимости
useCallback и включить в их состав query, то любой эффект, в зависимостях которого есть getFetchUrl, будет перезапускаться при каждом изменении query:function SearchResults() {
const [query, setQuery] = useState('react');
// Сущность не меняется до изменения query
const getFetchUrl = useCallback(() => {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, [query]); // Зависимости коллбэка в порядке.
useEffect(() => {
const url = getFetchUrl();
// ... Загрузим данные и что-то с ними сделаем...
}, [getFetchUrl]); // Зависимости эффекта в порядке.
// ...
}Благодаря использованию
useCallback, если query не меняется, то и getFetchUrl не меняется, а значит, не происходит и перезапуска эффекта. Но если query меняется, тогда изменится и getFetchUrl, и мы выполним повторную загрузку данных. Это похоже на работу в Excel: если изменить значение в какой-то ячейке, то значения в других ячейках, зависящие от значения изменённой ячейки, будут автоматически пересчитаны.Это — всего лишь последствия того, что мы принимаем во внимание поток данных и рассматриваем систему с точки зрения синхронизации. То же самое решение работает и для свойств функций, переданных от родительских сущностей:
function Parent() {
const [query, setQuery] = useState('react');
// Сущность не меняется до изменения query
const fetchData = useCallback(() => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + query;
// ... Загрузим данные и вернём их ...
}, [query]); // С зависимостями коллбэка всё в порядке
return <Child fetchData={fetchData} />
}
function Child({ fetchData }) {
let [data, setData] = useState(null);
useEffect(() => {
fetchData().then(setData);
}, [fetchData]); // С зависимостями эффекта всё в порядке
// ...
}Так как
fetchData из Parent изменяется лишь при изменении значения состояния query, Child не будет выполнять перезагрузку данных до тех пор, пока это не будет нужно приложению.Являются ли функции частью потока данных?
Интересно то, что этот паттерн не работает при его использовании с компонентами, основанными на классах, причём, причины этого хорошо иллюстрируют разницу между парадигмами эффектов и методов жизненного цикла компонентов. Рассмотрим следующий код, представляющий собой систему компонентов, основанных на классах, в котором сделана попытка реализовать те же возможности, что и в предыдущем примере:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... Загрузим данные и что-то с ними сделаем...
};
render() {
return <Child fetchData={this.fetchData} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
render() {
// ...
}
}Возможно, вы думаете сейчас: «Да ладно, Дэн, все мы знаем, что
useEffect — это нечто вроде комбинации componentDidMount и componentDidUpdate. Хватит уже об этом говорить!». Однако работать это не будет даже при использовании componentDidUpdate:class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
// Это условие никогда не будет истинным
if (this.props.fetchData !== prevProps.fetchData) {
this.props.fetchData();
}
}
render() {
// ...
}
}Конечно,
fetchData — это метод класса! (Или, скорее, свойство класса, но это ничего не меняет.) Этот метод не изменится только из-за того, что изменилось состояние. Поэтому this.props.fetchData будет оставаться равным prevProps.fetchData и повторная загрузка данных никогда выполнена не будет. Тогда, может быть, уберём условие? componentDidUpdate(prevProps) {
this.props.fetchData();
}Но здесь тоже не всё благополучно. Теперь загрузка данных будет выполняться при каждом повторном рендеринге компонента. (Интересным способом подтвердить это будет добавление анимации.) Может быть, надо привязать
fetchData к значению this.state.query? render() {
return <Child fetchData={this.fetchData.bind(this, this.state.query)} />;
}Но тогда условие
this.props.fetchData !== prevProps.fetchData всегда будет давать true, даже в том случае, если query не меняется! В результате мы постоянно будем выполнять повторную загрузку данных.Единственное реальное решение этой головоломки компонентов, основанных на классах, заключается в том, чтобы проявить мужество и передать само значение
query компоненту Child. Этот компонент, сам по себе, не будет использовать query, но это может вызвать повторную загрузку данных при изменении query:class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... Загрузим данные и что-то с ними сделаем ...
};
render() {
return <Child fetchData={this.fetchData} query={this.state.query} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
if (this.props.query !== prevProps.query) {
this.props.fetchData();
}
}
render() {
// ...
}
}За годы работы с компонентами, основанными на классах, я так привык передавать компонентам-потомкам ненужные свойства и нарушать инкапсуляцию родительских компонентов, что лишь недавно понял то, почему мы вынуждены так поступать.
При работе с классами функциональные свойства, сами по себе, не являются настоящей частью потока данных. Методы используют мутабельную сущность
this, поэтому нельзя полагаться на выяснение идентичности этих методов. Таким образом, если нам нужно работать с функцией, нам приходится манипулировать другими данными для того, чтобы можно было бы понять, изменилось что-то или нет. Мы не можем выяснить, зависит ли функция this.props.fetchData, переданная из родительского компонента дочернему, от неких данных состояния, или нет, и о том, изменились ли эти данные.Функции могут по-настоящему включаться в поток данных благодаря использованию
useCallback. Мы можем сказать, что, если входные данные функции изменились, то и сама функция изменилась. Если же этого не произошло, то неизменной осталась и функция. Благодаря особенностям useCallback изменения свойств наподобие props.fetchData могут распространяться автоматически.Аналогично,
useMemo позволяет делать то же самое со сложными объектами:function ColorPicker() {
// Не нарушает неглубокую проверку на равенство свойств компонента Child,
// система реагирует лишь на реальное изменение цвета.
const [color, setColor] = useState('pink');
const style = useMemo(() => ({ color }), [color]);
return <Child style={style} />;
}Мне хотелось бы подчеркнуть то, что если всюду использовать
useCallback, это сделает код довольно-таки громоздким. Этот механизм представляет собой хороший «запасной выход», он полезен в тех случаях, когда функция и передаётся дочерним компонентам, и вызывается внутри их эффектов. Или в тех случаях, когда нужно предотвратить нарушение мемоизации дочернего компонента. Но хуки лучше отражают модель системы, в которой полностью избегают передачи коллбэков дочерним компонентам.В вышеприведённых примерах я предпочитаю, чтобы функция
fetchData присутствовала бы либо внутри эффекта (который можно преобразовать в собственный хук), либо была бы представлена импортированной извне сущностью. Я стремлюсь к тому, чтобы эффекты были бы простыми, и коллбэки в них этому не способствуют. («Что если коллбэк props.onComplete изменится в то время, пока на отправленный запрос не получено ответа?») Можно имитировать поведение класса, но это не решит проблему состояния гонки.Состояние гонки
Вот как может выглядеть традиционный пример загрузки данных в компоненте, основанном на классе:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}Как вы, возможно, знаете, этот код содержит ошибки. Он не поддерживает обновления. А вот — ещё один подобный пример, который можно найти в интернете:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
componentDidUpdate(prevProps) {
if (prevProps.id !== this.props.id) {
this.fetchData(this.props.id);
}
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}Этот код, определённо, лучше, но в нём всё ещё есть проблемы. Причина этого заключается в том, что запросы могут идти не по порядку. Например, я загружаю статью с
{id: 10}, потом перехожу на статью с {id: 20}, выполняя ещё один запрос, и ответ на этот запрос приходит до прихода ответа на первый запрос. В результате запрос, который начался раньше, но ответ на который пришёл позже, перезапишет состояние. А это неправильно.То, о чём мы тут говорим, называется состоянием гонки. Это — ситуация, типичная для кода, в котором конструкция
async/await (применение которой означает, что нечто ожидает какого-то результата) смешивается с потоком данных, направленным сверху вниз (свойства и состояние не могут изменяться в то время, когда мы находимся в асинхронной функции).Эффекты не дают нам некоего чудесного решения этой проблемы, хотя программист и получит предупреждение при попытке непосредственной передачи эффекту
async-функции. (Нам, кстати, надо улучшить это предупреждение так, чтобы оно лучше описывало проблемы, которые это может вызвать.)Если используемые вами асинхронные механизмы поддерживают отмену операций, то надо отметить, что это замечательно! Это позволяет отменить асинхронный запрос прямо в функции очистки.
Кроме того, простейшим временным решением этой проблемы является контроль асинхронных операций с помощью логических переменных:
function Article({ id }) {
const [article, setArticle] = useState(null);
useEffect(() => {
let didCancel = false;
async function fetchData() {
const article = await API.fetchArticle(id);
if (!didCancel) {
setArticle(article);
}
}
fetchData();
return () => {
didCancel = true;
};
}, [id]);
// ...
}В этом материале можно найти подробности о том, как обрабатывать ошибки и состояния загрузки, а также о том, как извлекать подобную логику в собственные хуки. Если вам интересна тема загрузки данных с использованием хуков, я рекомендую вам разобраться с вышеупомянутым материалом.
Поднимаем планку
Если рассматривать побочные эффекты с позиций методов жизненного цикла компонентов, основанных на классах, то окажется, что они ведут себя не так, как то, что рендерит компонент. Рендерингом пользовательского интерфейса управляют свойства и состояние, и интерфейс, гарантированно, будет им соответствовать. В случае же с побочными эффектами это не так. Это — распространённый источник ошибок.
Если смотреть на вещи с точки зрения
useEffect, то всё, по умолчанию, является синхронизированным. Побочные эффекты стали частью потока данных React. Если сделать всё правильно, то при каждом вызове useEffect компонент гораздо лучше обрабатывает пограничные случаи.Но надо отметить, что для того, чтобы «сделать всё правильно», нужно заранее вложить в проект немало сил и времени. И это может раздражать разработчиков. Хорошо написать код синхронизации, поддерживающий пограничные случаи, по сути, гораздо сложнее, чем вызвать «одноразовый» побочный эффект, который не согласован с результатами рендеринга.
Это может оказаться неудобным в том случае, если
useEffect играет роль инструмента, которым вы пользуетесь постоянно. Однако это — низкоуровневый строительный блок приложений. Сейчас — самое начало внедрения хуков, поэтому все, особенно — в учебных руководствах, постоянно используют низкоуровневые примеры их применения. Но на практике, вероятнее всего, сообщество будет двигаться в сторону высокоуровневых хуков, по мере того, как будут набирать популярность хорошие API.Я видел, как в различных приложениях создаются их собственные хуки, наподобие
useFetch, который инкапсулирует некоторую логику аутентификации таких приложений, или useTheme, который использует контекст темы. После того, как вы освоитесь с этими инструментами, вы не особенно часто будете прибегать к использованию useEffect. Но гибкость, предоставляемая этим механизмом, идёт на пользу каждому хуку, построенному на его основе.До сих пор, например,
useEffect наиболее часто используется для загрузки данных. Но загрузка данных — это не совсем то, что относится к проблеме синхронизации. Это особенно очевидно по той причине, что зависимости в таких случаях обычно представлены пустым массивом. Что мы вообще синхронизируем с их помощью?В долгосрочной перспективе применение механизма Suspense для загрузки данных даст сторонним библиотекам отличный способ сообщить React о том, что рендеринг надо приостановить до тех пор, пока что-то асинхронное (что угодно: код, данные, изображения) не будет готово к выводу.
Так как возможности
Suspense постепенно покрывают всё больше сценариев загрузки данных, я ожидаю, что useEffect постепенно отойдёт на второй план, став инструментом продвинутых программистов, которым пользуются в случаях, когда нужно синхронизировать свойства и состояние с каким-нибудь побочным эффектом. В отличие от того, как этот механизм работает с загрузкой данных, его применение для подобных целей выглядит совершенно естественным, так как он был спроектирован именно для решения задач синхронизации. Но до тех пор собственные хуки, вроде тех, что показаны здесь, будут представлять собой хороший способ многократного использования логики, ответственной за загрузку данных.Итоги
Теперь вы знаете об эффектах практически всё, что знаю я. И если вы, начиная читать этот материал и просмотрев раздел с ответами на вопросы, столкнулись с чем-то непонятным, теперь, надеюсь, всё встало на свои места.

