
На часах 7:15 утра. Наша техподдержка завалена работой. О нас только что рассказали в передаче «Good Morning America» и множество тех, кто впервые посещает наш сайт, столкнулось с ошибками.
У нас настоящий аврал. Мы, прямо сейчас, до того, как потеряем возможность превратить посетителей ресурса в новых пользователей, собираемся выкатить пакет исправлений. Один из разработчиков кое-что подготовил. Он думает, что это поможет справиться с проблемой. Мы размещаем ссылку на обновлённую версию программы, пока ещё не ушедшей в продакшн, в чат компании, и просим всех её протестировать. Работает!
Наши героические инженеры запускают скрипты для развёртывания систем и через считанные минуты обновление уходит в бой. Внезапно число звонков в техподдержку удваивается. Наше срочное исправление что-то поломало, разработчики хватаются за git blame, а инженеры в это время откатывают систему к предыдущему состоянию.

Автор материала, перевод которого мы сегодня публикуем, полагает, что всего этого можно было бы избежать благодаря TDD.
Я давно уже не попадал в подобные ситуации. И дело не в том, что разработчики перестали совершать ошибки. Дело в том, что уже многие годы в каждой команде, которой я руководил и на которую я оказывал влияние, применялась методология TDD. Ошибки, конечно, всё ещё случаются, но проникновение в продакшн проблем, способных «повалить» проект, снизилось практически до нуля, даже несмотря на то, что частота обновления ПО и количество задач, которые нужно решить в процессе обновления, экспоненциально выросли с тех пор, когда случилось то, о чём я рассказал в начале.
Когда кто-то спрашивает меня о том, почему ему стоит связываться с TDD, я рассказываю ему эту историю, и могу вспомнить ещё с десяток похожих случаев. Одна из важнейших причин, по которым я перешёл на TDD, заключается в том, что эта методология позволяет улучшить покрытие кода тестами, что ведёт к тому, что в продакшн попадают на 40-80% меньше ошибок. Это то, что мне нравится в TDD больше всего. Это снимает с плеч разработчиков целую гору проблем.
Кроме того, стоит отметить, что TDD избавляет разработчиков от страха внесения изменений в код.
В проектах, в работе над которыми я принимаю участие, наборы автоматических модульных и функциональных тестов практически ежедневно предотвращают попадание в продакшн кода, который способен серьёзно нарушить работу этих проектов. Например, сейчас я смотрю на 10 автоматических обновлений библиотеки, сделанных на прошлой неделе, таких, перед выпуском которых без использования TDD, я опасался бы того, что они могут что-то испортить.
Все эти обновления были автоматически интегрированы в код, и они уже используются в продакшне. Я не проверял ни одного из них вручную, и совершенно не беспокоился о том, что они могут плохо отразиться на проекте. При этом, мне, для того чтобы привести этот пример, не пришлось долго думать. Я просто открыл GitHub, взглянул на недавние слияния, и увидел то, о чём рассказал. Та задача, которую раньше решали вручную (или, ещё хуже, задача, которую игнорировали), теперь представляет собой автоматизированный фоновый процесс. Можно попытаться сделать нечто подобное и без хорошего покрытия кода тестами, но я бы не рекомендовал так поступать.
TDD расшифровывается как Test Driven Development (разработка через тестирование). Процесс, реализуемый в ходе применения этой методологии очень прост:

Тесты выявляют ошибки, тесты завершаются успешно, выполняется рефакторинг
Вот основные принципы применения TDD:
На первый взгляд может показаться, что написание тестов означает значительное увеличение объёма кода проекта, и то, что всё это отнимает у разработчиков много дополнительного времени. В моём случае, поначалу, всё так и было, и я пытался понять, как, в принципе, можно писать тестируемый код, и как добавлять тесты к коду, который был уже написан.
Для TDD характерна определённая кривая обучаемости, и пока новичок карабкается по этой кривой, время, необходимое на разработку, может увеличиться на 15-35%. Часто именно так всё и происходит. Но где-то года через 2 после начала использования TDD начинает происходить нечто невероятное. А именно, я, например, стал, с предварительным написанием модульных тестов, программировать быстрее, чем раньше, когда TDD не пользовался.
Несколько лет назад я реализовывал, в клиентской системе, возможность работы с фрагментами видеоклипа. А именно, речь шла о том, чтобы можно было бы позволить пользователю указывать начало и конец фрагмента записи, и получать ссылку на него, что дало бы возможность ссылаться на конкретное место в клипе, а не на весь этот клип.
Работа у меня не шла. Проигрыватель доходил до конца фрагмента и продолжал её воспроизводить, а я не имел представления о том, почему это так.
Я полагал, что проблема заключается в неправильном подключении прослушивателей событий. Мой код выглядел примерно так:
Процесс поиска проблемы выглядел так: внесение изменений, компиляция, перезагрузка, щелчок, ожидание… Эта последовательность действий повторялась снова и снова.
Для того чтобы проверить каждое из вносимых в проект изменений, нужно было потратить почти минуту, а я испытывал невероятно много вариантов решения задачи (большинство из них — по 2-3 раза).
Может я допустил ошибку в ключевом слове
Я, наконец, поместил
Я установил в программу точку останова для того чтобы разобраться в том, что происходит. Я исследовал значение
Я не забыл об этом и годы спустя. И всё — благодаря тому ощущению, которое испытал, всё же найдя ошибку. Вы, наверняка, знаете, о чём я говорю. Со всеми это случалось. И, пожалуй, каждый сможет узнать себя в этом меме.

Вот как я выгляжу, когда программирую
Если бы я писал ту программу сегодня, я бы начал работу над ней примерно так:
Возникает ощущение, что тут куда больше кода, чем в этой строчке:
Но в том-то всё и дело. Этот код действует как спецификация. Это — и документация, и доказательство того, что код работает так, как того требует эта документация. И, так как эта документация существует, если я изменю порядок работы с маркером времени окончания фрагмента, мне не придётся беспокоиться о том, нарушил ли я в ходе внесения этих изменений правильность работы со временем окончания клипа.
Вот, кстати, полезный материал по написанию модульных тестов, таких же, как тот, который мы только что рассмотрели.
Смысл не в том, сколько времени занимает ввод этого кода. Смысл в том, сколько времени занимает отладка в том случае, если что-то идёт не так. Если код окажется неправильным, тест выдаст отличный отчёт об ошибке. Я сразу же буду знать о том, что проблема заключается не в обработчике события. Я буду знать о том, что она либо в
Начиная новый проект я, в качестве одного из первых дел, выполняю настройку скрипта-наблюдателя, который автоматически запускает модульные тесты при каждом изменении некоего файла. Я часто программирую, используя два монитора. На одном из них открыта консоль разработчика, в которой выводятся результаты выполнения подобного скрипта, на другом выводится интерфейс среды, в которой я пишу код. Когда я вношу в код изменение, я обычно, в пределах 3 секунд, узнаю о том, рабочим оказалось это изменение или нет.
Для меня TDD — это гораздо больше, чем просто страховка. Это — возможность постоянного и быстрого, в режиме реального времени, получения сведений о состоянии моего кода. Мгновенное вознаграждение в виде пройденных тестов, или мгновенный отчёт об ошибках в том случае, если я сделал что-то не так.
Мне хотелось бы сделать одно признание, хоть признавать это и неловко: я не представлял себе, как создавать приложения до того, как я изучил TDD и модульное тестирование. Я не представляю, как меня вообще брали на работу, но, после того, как я провёл собеседования с многими сотнями разработчиков, я могу с уверенностью сказать, что в похожей ситуации находится множество программистов. Методология TDD научила меня почти всему, что я знаю об эффективной декомпозиции и композиции программных компонентов (я имею в виду модули, функции, объекты, компоненты пользовательского интерфейса и прочее подобное).
Причина этого заключается в том, что модульные тесты принуждают программиста к тестированию компонентов в изоляции друг от друга и от подсистем ввода-вывода. Если модулю предоставляются некие входные данные — он должен выдать некие, заранее известные, выходные данные. Если он этого не сделает, тест завершается с ошибкой. Если сделает — тест завершается успешно. Смысл тут заключается в том, что модуль должен работать независимо от остального приложения. Если вы тестируете логику работы состояния, у вас должна быть возможность делать это без вывода чего-либо на экран или сохранения чего-нибудь в базу данных. Если вы тестируете формирование пользовательского интерфейса, то у вас должна быть возможность тестировать его без необходимости загрузки страницы в браузер или обращения к сетевым ресурсам.
Кроме прочего, методология TDD научила меня тому, что жизнь становится гораздо проще в том случае, если при разработке компонентов пользовательского интерфейса стремиться к минимализму. Кроме того, от пользовательского интерфейса следует изолировать бизнес-логику и побочные эффекты. С практической точки зрения это означает, что если вы используете UI-фреймворк, основанный на компонентах, вроде React или Angular, целесообразным может быть создание презентационных компонентов, отвечающих за вывод чего-либо на экран, и компонентов-контейнеров, которые друг с другом не смешиваются.
Презентационный компонент, получающий некие свойства, всегда формирует один и тот же результат. Подобные компоненты можно легко проверить, используя модульные тесты. Это позволяет узнать, правильно ли компонент работает со свойствами, и то, корректна ли некая условная логика, используемая при формировании интерфейса. Например, возможно, компонент, формирующий список, не должен выводить ничего кроме приглашения на добавление в список нового элемента в том случае, если список пуст.
Я знал о принципе разделения ответственности задолго до того, как освоил TDD, но я не знал о том, как разделять ответственность между разными сущностями.
Модульное тестирование позволило мне изучить использование моков для тестирования чего-либо, а затем я узнал, что мокинг — это признак того, что, возможно, с кодом что-то не так. Это меня ошеломило и полностью изменило мой подход к композиции программного обеспечения.
Вся разработка программного обеспечения — это композиция: процесс разбиения больших проблем на множество мелких, легко решаемых проблем, а затем создание решений для этих проблем, которые и формируют приложение. Мокинг, выполняемый ради модульных тестов, указывает на то, что атомарные единицы композиции, на самом деле, не атомарны. Изучение того, как избавиться от моков, не ухудшая покрытие кода тестами, позволило мне узнать о том, как выявлять бесчисленное множество скрытых причин сильной связанности сущностей.
Это позволило мне, как разработчику, профессионально вырасти. Это научило меня тому, как писать гораздо более простой код, который легче расширять, поддерживать, масштабировать. Это относится и к сложности самого кода, и к организации его работы в больших распределённых системах наподобие облачных инфраструктур.
Я уже говорил о том, что TDD, в первую очередь, ведёт к улучшению покрытия кода тестами. Причина этого заключается в том, что мы не начинаем писать код реализации некоей возможности до тех пор, пока не напишем тест, проверяющий правильность работы этого будущего кода. Сначала пишем тест. Потом позволяем ему завершиться с ошибкой. Потом пишем код реализации возможности. Тестируем код, получаем сообщение об ошибке, добиваемся правильного прохождения испытаний, выполняем рефакторинг и повторяем этот процесс.
Этот процесс позволяет создать «заграждение», через которое способны «перескочить» лишь очень немногие ошибки. Эта защита от ошибок оказывает удивительное воздействие на весь коллектив разработчиков. Оно избавляет от страха перед командой merge.
Высокий уровень покрытия кода тестами позволяет команде избавиться от желания вручную проконтролировать любое, даже маленькое изменение кодовой базы. Изменения кода становятся естественной частью рабочего процесса.
Избавления от страха внесения изменений в код напоминает смазывание некоей машины. Если этого не делать, машина, в конце концов, остановится — до тех пор, пока её не смажут и снова не запустят.
Без этого страха процесс работы над программами оказывается гораздо более спокойным, чем прежде. Pull-запросы не откладывают до последнего. CI/CD-система запустит тесты, и, если тесты окажутся неудачными, остановит процесс внесения изменений в код проекта. При этом сообщения об ошибках и сведения о том, где именно они произошли, очень сложно будет не заметить.
В этом-то всё и дело.
Уважаемые читатели! Пользуетесь ли вы методикой TDD при работе над своими проектами?

У нас настоящий аврал. Мы, прямо сейчас, до того, как потеряем возможность превратить посетителей ресурса в новых пользователей, собираемся выкатить пакет исправлений. Один из разработчиков кое-что подготовил. Он думает, что это поможет справиться с проблемой. Мы размещаем ссылку на обновлённую версию программы, пока ещё не ушедшей в продакшн, в чат компании, и просим всех её протестировать. Работает!
Наши героические инженеры запускают скрипты для развёртывания систем и через считанные минуты обновление уходит в бой. Внезапно число звонков в техподдержку удваивается. Наше срочное исправление что-то поломало, разработчики хватаются за git blame, а инженеры в это время откатывают систему к предыдущему состоянию.
Автор материала, перевод которого мы сегодня публикуем, полагает, что всего этого можно было бы избежать благодаря TDD.
Почему я использую TDD?
Я давно уже не попадал в подобные ситуации. И дело не в том, что разработчики перестали совершать ошибки. Дело в том, что уже многие годы в каждой команде, которой я руководил и на которую я оказывал влияние, применялась методология TDD. Ошибки, конечно, всё ещё случаются, но проникновение в продакшн проблем, способных «повалить» проект, снизилось практически до нуля, даже несмотря на то, что частота обновления ПО и количество задач, которые нужно решить в процессе обновления, экспоненциально выросли с тех пор, когда случилось то, о чём я рассказал в начале.
Когда кто-то спрашивает меня о том, почему ему стоит связываться с TDD, я рассказываю ему эту историю, и могу вспомнить ещё с десяток похожих случаев. Одна из важнейших причин, по которым я перешёл на TDD, заключается в том, что эта методология позволяет улучшить покрытие кода тестами, что ведёт к тому, что в продакшн попадают на 40-80% меньше ошибок. Это то, что мне нравится в TDD больше всего. Это снимает с плеч разработчиков целую гору проблем.
Кроме того, стоит отметить, что TDD избавляет разработчиков от страха внесения изменений в код.
В проектах, в работе над которыми я принимаю участие, наборы автоматических модульных и функциональных тестов практически ежедневно предотвращают попадание в продакшн кода, который способен серьёзно нарушить работу этих проектов. Например, сейчас я смотрю на 10 автоматических обновлений библиотеки, сделанных на прошлой неделе, таких, перед выпуском которых без использования TDD, я опасался бы того, что они могут что-то испортить.
Все эти обновления были автоматически интегрированы в код, и они уже используются в продакшне. Я не проверял ни одного из них вручную, и совершенно не беспокоился о том, что они могут плохо отразиться на проекте. При этом, мне, для того чтобы привести этот пример, не пришлось долго думать. Я просто открыл GitHub, взглянул на недавние слияния, и увидел то, о чём рассказал. Та задача, которую раньше решали вручную (или, ещё хуже, задача, которую игнорировали), теперь представляет собой автоматизированный фоновый процесс. Можно попытаться сделать нечто подобное и без хорошего покрытия кода тестами, но я бы не рекомендовал так поступать.
Что такое TDD?
TDD расшифровывается как Test Driven Development (разработка через тестирование). Процесс, реализуемый в ходе применения этой методологии очень прост:
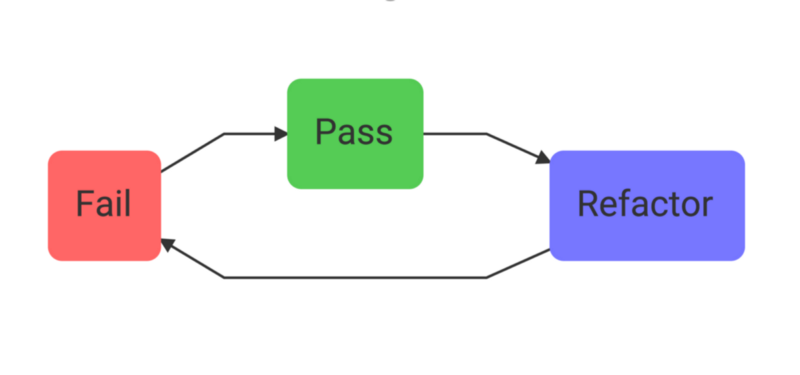
Тесты выявляют ошибки, тесты завершаются успешно, выполняется рефакторинг
Вот основные принципы применения TDD:
- Прежде чем писать код реализации некоей возможности, пишут тест, который позволяет проверить, работает ли этот будущий код реализации, или нет. Прежде чем переходить к следующему шагу, тест запускают и убеждаются в том, что он выдаёт ошибку. Благодаря этому можно быть уверенным в том, что тест не выдаёт ложноположительные результаты, это — своего рода тестирование самих тестов.
- Создают реализацию возможности и добиваются того, чтобы она успешно прошла тестирование.
- Выполняют, если это нужно, рефакторинг кода. Рефакторинг, при наличии теста, который способен указать разработчику на правильность или неправильность работы системы, вселяет в разработчика уверенность в его действиях.
Как TDD может помочь сэкономить время, необходимое на разработку программ?
На первый взгляд может показаться, что написание тестов означает значительное увеличение объёма кода проекта, и то, что всё это отнимает у разработчиков много дополнительного времени. В моём случае, поначалу, всё так и было, и я пытался понять, как, в принципе, можно писать тестируемый код, и как добавлять тесты к коду, который был уже написан.
Для TDD характерна определённая кривая обучаемости, и пока новичок карабкается по этой кривой, время, необходимое на разработку, может увеличиться на 15-35%. Часто именно так всё и происходит. Но где-то года через 2 после начала использования TDD начинает происходить нечто невероятное. А именно, я, например, стал, с предварительным написанием модульных тестов, программировать быстрее, чем раньше, когда TDD не пользовался.
Несколько лет назад я реализовывал, в клиентской системе, возможность работы с фрагментами видеоклипа. А именно, речь шла о том, чтобы можно было бы позволить пользователю указывать начало и конец фрагмента записи, и получать ссылку на него, что дало бы возможность ссылаться на конкретное место в клипе, а не на весь этот клип.
Работа у меня не шла. Проигрыватель доходил до конца фрагмента и продолжал её воспроизводить, а я не имел представления о том, почему это так.
Я полагал, что проблема заключается в неправильном подключении прослушивателей событий. Мой код выглядел примерно так:
video.addEventListener('timeupdate', () => {
if (video.currentTime >= clip.stopTime) {
video.pause();
}
});Процесс поиска проблемы выглядел так: внесение изменений, компиляция, перезагрузка, щелчок, ожидание… Эта последовательность действий повторялась снова и снова.
Для того чтобы проверить каждое из вносимых в проект изменений, нужно было потратить почти минуту, а я испытывал невероятно много вариантов решения задачи (большинство из них — по 2-3 раза).
Может я допустил ошибку в ключевом слове
timeupdate? Правильно ли я понял особенности работы с API? Работает ли вызов video.pause()? Я вносил в код изменения, добавлял console.log(), переходил обратно в браузер, нажимал на кнопку Обновить, щёлкал по позиции, находящейся у конца выделенного фрагмента, а потом терпеливо ждал до тех пор, пока клип не будет проигран полностью. Логирование внутри конструкции if ни к чему не привело. Это выглядело как подсказка о возможной проблеме. Я скопировал слово timeupdate из документации к API для того чтобы быть абсолютно уверенным в том, что, вводя его, не допустил ошибку. Снова обновляю страницу, снова щёлкаю, снова жду. И снова программа отказывается правильно работать.Я, наконец, поместил
console.log() за пределами блока if. «Это не поможет», — думал я. В конце концов, выражение if было настолько простым, что я просто не представлял себе, как можно записать его неправильно. Но логирование в данном случае сработало. Я подавился кофе. «Да что же это такое!?» — подумал я.Закон отладки Мёрфи. То место программы, которое вы никогда не тестировали, так как свято верили в то, что оно не может содержать ошибок, окажется именно тем местом, где вы найдёте ошибку после того, как, совершенно вымотавшись, внесёте в это место изменения лишь из-за того, что уже попробовали всё, о чём только могли подумать.
Я установил в программу точку останова для того чтобы разобраться в том, что происходит. Я исследовал значение
clip.stopTime. Оно, к моему удивлению, равнялось undefined. Почему? Я снова взглянул на код. Когда пользователь выбирает время окончания фрагмента, программа размещает в нужном месте маркер конца фрагмента, но не устанавливает значение clip.stopTime. «Я — невероятный идиот, — подумал я, — меня нельзя подпускать к компьютерам до конца жизни».Я не забыл об этом и годы спустя. И всё — благодаря тому ощущению, которое испытал, всё же найдя ошибку. Вы, наверняка, знаете, о чём я говорю. Со всеми это случалось. И, пожалуй, каждый сможет узнать себя в этом меме.

Вот как я выгляжу, когда программирую
Если бы я писал ту программу сегодня, я бы начал работу над ней примерно так:
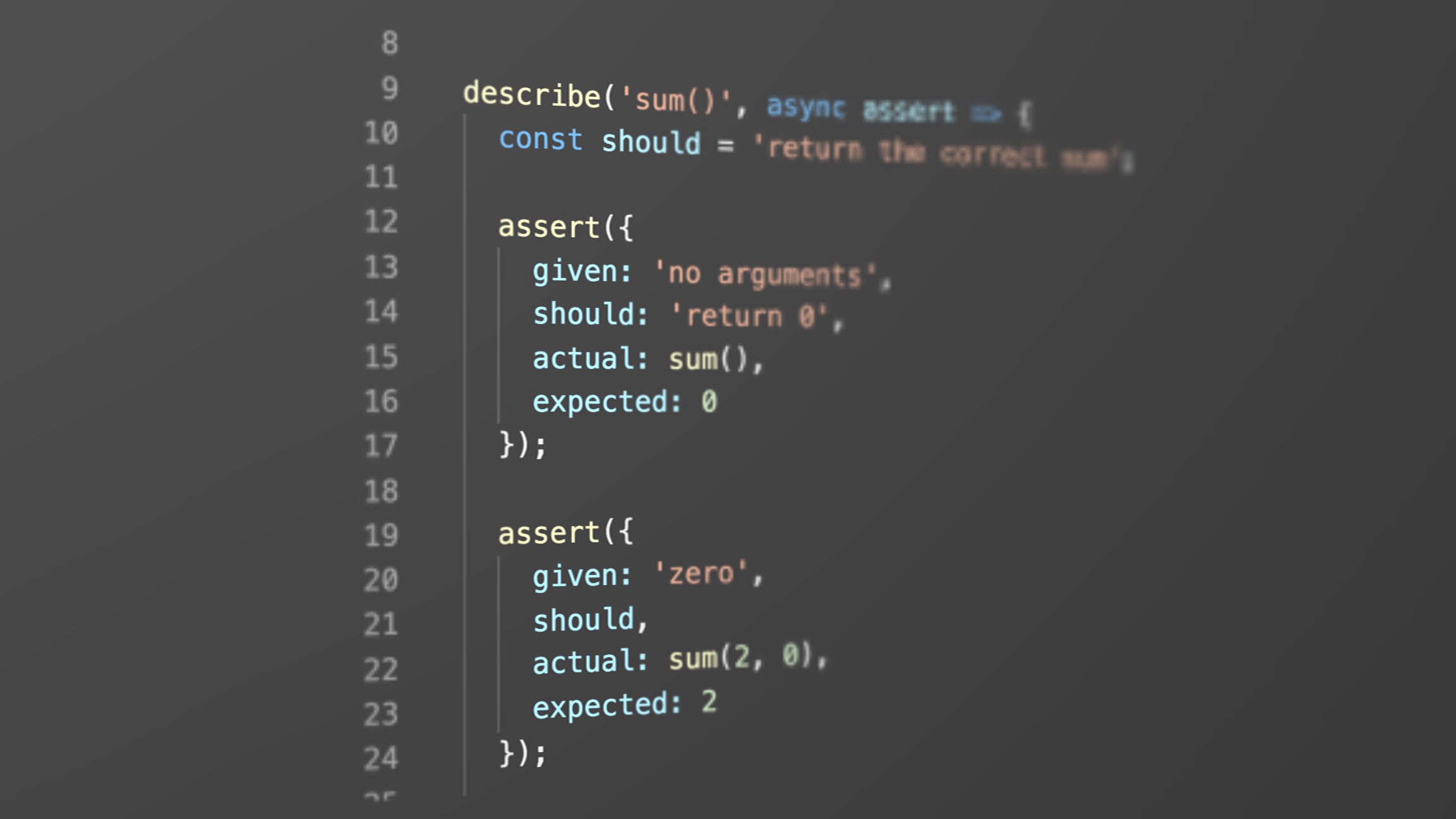
describe('clipReducer/setClipStopTime', async assert => {
const stopTime = 5;
const clipState = {
startTime: 2,
stopTime: Infinity
};
assert({
given: 'clip stop time',
should: 'set clip stop time in state',
actual: clipReducer(clipState, setClipStopTime(stopTime)),
expected: { ...clipState, stopTime }
});
});Возникает ощущение, что тут куда больше кода, чем в этой строчке:
clip.stopTime = video.currentTimeНо в том-то всё и дело. Этот код действует как спецификация. Это — и документация, и доказательство того, что код работает так, как того требует эта документация. И, так как эта документация существует, если я изменю порядок работы с маркером времени окончания фрагмента, мне не придётся беспокоиться о том, нарушил ли я в ходе внесения этих изменений правильность работы со временем окончания клипа.
Вот, кстати, полезный материал по написанию модульных тестов, таких же, как тот, который мы только что рассмотрели.
Смысл не в том, сколько времени занимает ввод этого кода. Смысл в том, сколько времени занимает отладка в том случае, если что-то идёт не так. Если код окажется неправильным, тест выдаст отличный отчёт об ошибке. Я сразу же буду знать о том, что проблема заключается не в обработчике события. Я буду знать о том, что она либо в
setClipStopTime(), либо в clipReducer(), где реализовано изменение состояния. Благодаря тесту я знал бы о том, какие функции выполняет код, о том, что он выводит на самом деле, и о том, что от него ожидается. И, что более важно, те же самые знания будут и у моего коллеги, который, через полгода после того, как я написал код, будет внедрять в него новые возможности.Начиная новый проект я, в качестве одного из первых дел, выполняю настройку скрипта-наблюдателя, который автоматически запускает модульные тесты при каждом изменении некоего файла. Я часто программирую, используя два монитора. На одном из них открыта консоль разработчика, в которой выводятся результаты выполнения подобного скрипта, на другом выводится интерфейс среды, в которой я пишу код. Когда я вношу в код изменение, я обычно, в пределах 3 секунд, узнаю о том, рабочим оказалось это изменение или нет.
Для меня TDD — это гораздо больше, чем просто страховка. Это — возможность постоянного и быстрого, в режиме реального времени, получения сведений о состоянии моего кода. Мгновенное вознаграждение в виде пройденных тестов, или мгновенный отчёт об ошибках в том случае, если я сделал что-то не так.
Как методология TDD научила меня писать более качественный код?
Мне хотелось бы сделать одно признание, хоть признавать это и неловко: я не представлял себе, как создавать приложения до того, как я изучил TDD и модульное тестирование. Я не представляю, как меня вообще брали на работу, но, после того, как я провёл собеседования с многими сотнями разработчиков, я могу с уверенностью сказать, что в похожей ситуации находится множество программистов. Методология TDD научила меня почти всему, что я знаю об эффективной декомпозиции и композиции программных компонентов (я имею в виду модули, функции, объекты, компоненты пользовательского интерфейса и прочее подобное).
Причина этого заключается в том, что модульные тесты принуждают программиста к тестированию компонентов в изоляции друг от друга и от подсистем ввода-вывода. Если модулю предоставляются некие входные данные — он должен выдать некие, заранее известные, выходные данные. Если он этого не сделает, тест завершается с ошибкой. Если сделает — тест завершается успешно. Смысл тут заключается в том, что модуль должен работать независимо от остального приложения. Если вы тестируете логику работы состояния, у вас должна быть возможность делать это без вывода чего-либо на экран или сохранения чего-нибудь в базу данных. Если вы тестируете формирование пользовательского интерфейса, то у вас должна быть возможность тестировать его без необходимости загрузки страницы в браузер или обращения к сетевым ресурсам.
Кроме прочего, методология TDD научила меня тому, что жизнь становится гораздо проще в том случае, если при разработке компонентов пользовательского интерфейса стремиться к минимализму. Кроме того, от пользовательского интерфейса следует изолировать бизнес-логику и побочные эффекты. С практической точки зрения это означает, что если вы используете UI-фреймворк, основанный на компонентах, вроде React или Angular, целесообразным может быть создание презентационных компонентов, отвечающих за вывод чего-либо на экран, и компонентов-контейнеров, которые друг с другом не смешиваются.
Презентационный компонент, получающий некие свойства, всегда формирует один и тот же результат. Подобные компоненты можно легко проверить, используя модульные тесты. Это позволяет узнать, правильно ли компонент работает со свойствами, и то, корректна ли некая условная логика, используемая при формировании интерфейса. Например, возможно, компонент, формирующий список, не должен выводить ничего кроме приглашения на добавление в список нового элемента в том случае, если список пуст.
Я знал о принципе разделения ответственности задолго до того, как освоил TDD, но я не знал о том, как разделять ответственность между разными сущностями.
Модульное тестирование позволило мне изучить использование моков для тестирования чего-либо, а затем я узнал, что мокинг — это признак того, что, возможно, с кодом что-то не так. Это меня ошеломило и полностью изменило мой подход к композиции программного обеспечения.
Вся разработка программного обеспечения — это композиция: процесс разбиения больших проблем на множество мелких, легко решаемых проблем, а затем создание решений для этих проблем, которые и формируют приложение. Мокинг, выполняемый ради модульных тестов, указывает на то, что атомарные единицы композиции, на самом деле, не атомарны. Изучение того, как избавиться от моков, не ухудшая покрытие кода тестами, позволило мне узнать о том, как выявлять бесчисленное множество скрытых причин сильной связанности сущностей.
Это позволило мне, как разработчику, профессионально вырасти. Это научило меня тому, как писать гораздо более простой код, который легче расширять, поддерживать, масштабировать. Это относится и к сложности самого кода, и к организации его работы в больших распределённых системах наподобие облачных инфраструктур.
Как TDD помогает экономить рабочее время команд?
Я уже говорил о том, что TDD, в первую очередь, ведёт к улучшению покрытия кода тестами. Причина этого заключается в том, что мы не начинаем писать код реализации некоей возможности до тех пор, пока не напишем тест, проверяющий правильность работы этого будущего кода. Сначала пишем тест. Потом позволяем ему завершиться с ошибкой. Потом пишем код реализации возможности. Тестируем код, получаем сообщение об ошибке, добиваемся правильного прохождения испытаний, выполняем рефакторинг и повторяем этот процесс.
Этот процесс позволяет создать «заграждение», через которое способны «перескочить» лишь очень немногие ошибки. Эта защита от ошибок оказывает удивительное воздействие на весь коллектив разработчиков. Оно избавляет от страха перед командой merge.
Высокий уровень покрытия кода тестами позволяет команде избавиться от желания вручную проконтролировать любое, даже маленькое изменение кодовой базы. Изменения кода становятся естественной частью рабочего процесса.
Избавления от страха внесения изменений в код напоминает смазывание некоей машины. Если этого не делать, машина, в конце концов, остановится — до тех пор, пока её не смажут и снова не запустят.
Без этого страха процесс работы над программами оказывается гораздо более спокойным, чем прежде. Pull-запросы не откладывают до последнего. CI/CD-система запустит тесты, и, если тесты окажутся неудачными, остановит процесс внесения изменений в код проекта. При этом сообщения об ошибках и сведения о том, где именно они произошли, очень сложно будет не заметить.
В этом-то всё и дело.
Уважаемые читатели! Пользуетесь ли вы методикой TDD при работе над своими проектами?

