
Сегодня мы представляем вашему вниманию перевод второго материала из серии, посвящённой оптимизации instagram.com. Здесь речь пойдёт об улучшении механизма заблаговременного выполнения GraphQL-запросов и о повышении эффективности передачи HTML-данных клиенту.

→ Читать, затаив дыхание, первую часть
В первой части мы говорили о том, как, используя механизмы предварительной загрузки, начинать выполнение запросов на ранних стадиях обработки страницы. То есть — даже до того, как будет загружен скрипт, инициирующий подобные запросы. Учитывая это, можно отметить, что выполнение этих запросов на стадии предварительной загрузки материалов всё ещё означало то, что их выполнение не начиналось до начала рендеринга HTML-страницы на клиенте. А это, в свою очередь, значило, что выполнение запроса не могло начаться раньше, чем клиент отправит серверу запрос и сервер на этот запрос ответит (сюда ещё надо добавить время, необходимое серверу на генерирование HTML-ответа клиенту). На следующем рисунке можно видеть то, что начало выполнения GraphQL-запроса может быть довольно сильно отложено. И это — учитывая то, что выполнять подобные запросы мы начинаем с помощью кода, расположенного в HTML-теге

Предварительное выполнение запроса начинается с заметной задержкой
В теории идеально выглядело бы начало выполнения подобного GraphQL- запроса в тот момент, когда на сервер поступал бы запрос на загрузку соответствующей страницы. Но как сделать так, чтобы браузер начал бы что-то загружать ещё до того, как он получит с сервера хоть какой-то HTML-код? Ответ заключается в том, чтобы отправить ресурс браузеру по инициативе сервера. Может показаться, что для реализации подобного механизма понадобится что-то вроде HTTP/2 Server Push. Но, на самом деле, существует очень старая технология (о которой часто забывают), которая позволяет реализовать подобную схему взаимодействия клиента и сервера. Эта технология отличается универсальной поддержкой браузеров, для её реализации не нужно углубляться в инфраструктурные сложности, характерные для реализации HTTP/2 Server Push. Facebook использует эту технологию с 2010 года (почитайте про BigPipe), да и на других сайтах, вроде Ebay, она тоже находит применение в различных формах. Но возникает такое ощущение, что JavaScript-разработчики одностраничных приложений эту технологию, в основном, либо игнорируют, либо просто ей не пользуются. Речь идёт о прогрессивной загрузке HTML. Эта технология известна под разными названиями: «early flush», «head flushing», «progressive HTML». Она работает благодаря комбинации двух механизмов:
Механизм chunked transfer encoding появился в HTTP/1.1. Он позволяет разбивать HTTP-ответы на множество небольших частей, которые передаются браузеру в потоковом режиме. Браузер «скрепляет» эти части по мере их прибытия, формируя из них полный код ответа. Хотя такой подход предусматривает немалые изменения в том, как страницы формируются на сервере, большинство языков и фреймворков обладают поддержкой выдачи подобных ответов, разбитых на части. В веб-фронтендах Instagram применяется Django, поэтому мы используем объект StreamingHttpResponse. Причина, по которой применение подобного механизма может принести пользу, заключается в том, что он позволяет отправлять HTML-содержимое страницы в браузер в потоковом режиме по мере готовности отдельных частей страницы, а не ждать того момента, когда будет готов полный код страницы. Это означает, что мы можем сбросить (flush) в браузер заголовок страницы практически мгновенно после получения запроса (отсюда и термин «early flush»). Подготовка заголовка не требует особенно больших серверных ресурсов. Это позволяет браузеру приступить к загрузке скриптов и стилей ещё тогда, когда сервер занят генерированием динамических данных для остальных частей страницы. Взглянем на то, к какому эффекту приводит применение этой методики. Вот как выглядит обычная загрузка страницы.
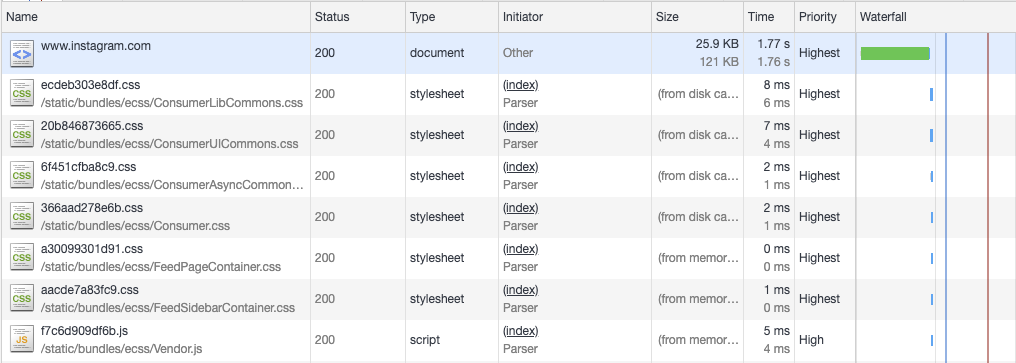
Технология early flush не используется: загрузка ресурсов не начинается до полной загрузки HTML-кода страницы
А вот что происходит в том случае, если сервер, при поступлении запроса, тут же передаёт браузеру заголовок страницы.
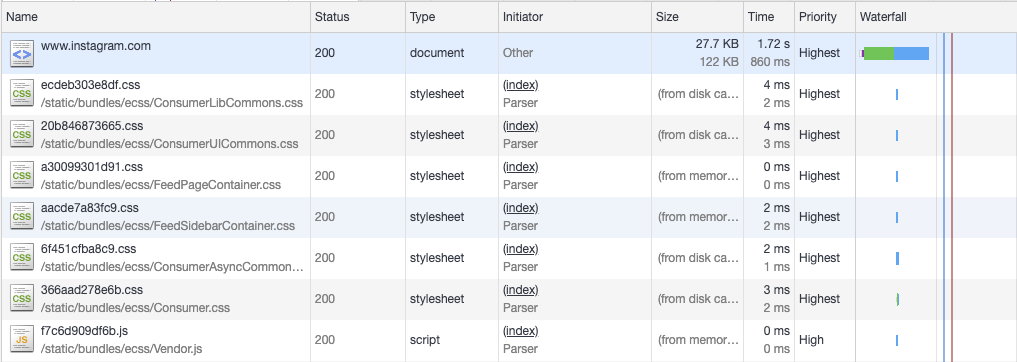
Технология early flush используется: ресурсы начинают загружаться сразу после того, как HTML-теги сбрасываются в браузер
Кроме того, мы можем использовать механизм передачи HTTP-сообщений по частям для отправки данных клиенту по мере их готовности. В случае с приложениями, рендеринг которых выполняется на сервере, эти данные могут быть представлены в форме HTML-кода. Но если речь идёт об одностраничных приложениях вроде instagram.com, сервер может передать клиенту и нечто вроде JSON-данных. Для того чтобы взглянуть на то, как это работает — давайте разберём простейший пример начала работы одностраничного приложения.
Сначала в браузер отправляется исходная HTML-разметка, содержащая JavaScript-код, необходимый для рендеринга страницы. После разбора и выполнения этого скрипта будет выполнен XHR-запрос, загружающий исходные данные, необходимые для рендеринга страницы.
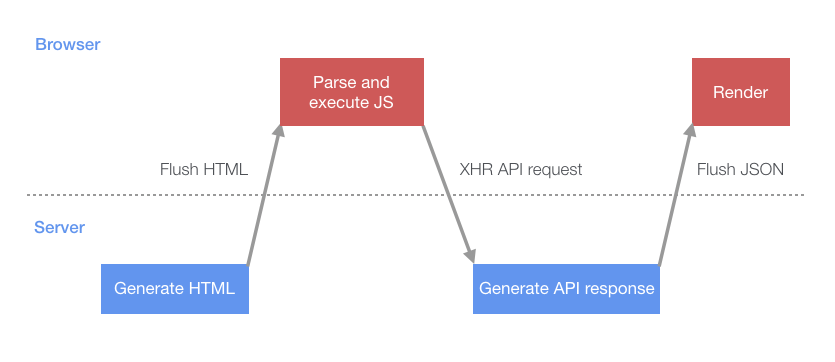
Процесс загрузки страницы в ситуации, когда браузер самостоятельно запрашивает у сервера всё, что ему нужно
Этот процесс предусматривает несколько ситуаций, в которых клиент отправляет серверу запрос и ждёт от него ответа. В результате здесь имеются периоды, когда и сервер и клиент пребывают в бездействии. Вместо того, чтобы сервер ждал бы от клиента выполнения запроса к API, эффективней было бы, если бы сервер начал бы работу по подготовке ответа API сразу после того, как был сгенерирован HTML-код. После того, как ответ был бы готов, сервер мог бы, по своей инициативе, отравить его клиенту. Это означало бы, что к тому времени, когда клиент подготовил бы всё, что нужно для визуализации данных, которые раньше загружались после выполнения запроса к API, эти данные уже, скорее всего, были бы готовы. Клиенту при этом не пришлось бы выполнять отдельный запрос к серверу и ждать от него ответа.
Первый шаг в реализации подобной схемы взаимодействия клиента и сервера заключается в создании JSON-кэша, предназначенного для хранения ответов сервера. Мы разработали эту часть системы, используя маленький скриптовый блок, встроенный в HTML-код страницы. Он играет роль кэша и содержит сведения о запросах, которые будут добавлены в кэш сервером (это, в упрощённой форме, показано ниже).
После сброса HTML-кода в браузер сервер может самостоятельно выполнить запросы к API. После получения ответов на эти запросы сервер сбросит на страницу JSON-данные в виде скриптового тега, содержащего эти данные. Когда браузер получит и разберёт подобный фрагмент HTML-кода страницы, это приведёт к тому, что данные попадут в JSON-кэш. Самое важное здесь то, что браузер будет выводить страницу прогрессивно — по мере того, как он получает фрагменты ответа (то есть — готовые блоки скриптов будут выполняться по мере их поступления в браузер). Это означает, что вполне можно параллельно генерировать на сервере большие объёмы данных и сбрасывать на страницу блоки со скриптами по мере готовности соответствующих данных. Эти скрипты будут немедленно выполняться на клиенте. Это — основа системы BigPipe, применяемой в Facebook. Там множество независимых пейджлетов параллельно загружаются на сервере и передаются клиенту по мере их готовности.
Когда клиентский скрипт готов к тому, чтобы запросить нужные ему данные, он, вместо выполнения XHR-запроса, сначала проверяет JSON-кэш. Если в кэше уже есть результаты запроса — скрипт немедленно получает то, что ему нужно. Если же запрос находится в процессе выполнения — скрипт ждёт результатов.
Всё это приводит к тому, что процесс загрузки страницы становится таким, как на следующей схеме.
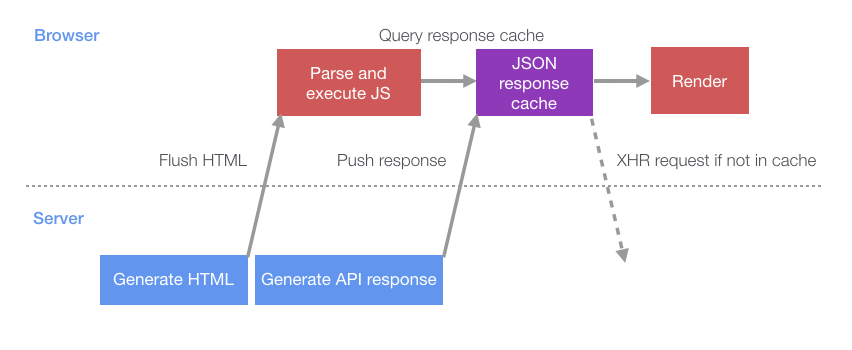
Процесс загрузки страницы в ситуации, когда браузер принимает активное участие в подготовке данных для клиента
Если сравнить это с самым простым способом загрузки страниц, то окажется, что сервер и клиент могут теперь выполнять больше задач в параллельном режиме. Это снижает длительность периодов простоя, в ходе которых сервер и клиент друг друга ждут.
Данная оптимизация оказала сильнейшее положительное влияние на нашу систему. Так, в настольных браузерах загрузка страницы стала завершаться на 14% быстрее, чем раньше. А в мобильных браузерах (из-за более длительных задержек в мобильных сетях) страница стала загружаться на 23% быстрее.
Уважаемые читатели! Планируете ли вы применять рассмотренную здесь методику оптимизации формирования веб-страниц в своих проектах?



→ Читать, затаив дыхание, первую часть
Отправка данных клиенту по инициативе сервера с использованием технологии прогрессивной загрузки HTML
В первой части мы говорили о том, как, используя механизмы предварительной загрузки, начинать выполнение запросов на ранних стадиях обработки страницы. То есть — даже до того, как будет загружен скрипт, инициирующий подобные запросы. Учитывая это, можно отметить, что выполнение этих запросов на стадии предварительной загрузки материалов всё ещё означало то, что их выполнение не начиналось до начала рендеринга HTML-страницы на клиенте. А это, в свою очередь, значило, что выполнение запроса не могло начаться раньше, чем клиент отправит серверу запрос и сервер на этот запрос ответит (сюда ещё надо добавить время, необходимое серверу на генерирование HTML-ответа клиенту). На следующем рисунке можно видеть то, что начало выполнения GraphQL-запроса может быть довольно сильно отложено. И это — учитывая то, что выполнять подобные запросы мы начинаем с помощью кода, расположенного в HTML-теге
<head>, и то, что это — одна из первых задач, которую мы решаем с помощью средств предварительной загрузки данных.
Предварительное выполнение запроса начинается с заметной задержкой
В теории идеально выглядело бы начало выполнения подобного GraphQL- запроса в тот момент, когда на сервер поступал бы запрос на загрузку соответствующей страницы. Но как сделать так, чтобы браузер начал бы что-то загружать ещё до того, как он получит с сервера хоть какой-то HTML-код? Ответ заключается в том, чтобы отправить ресурс браузеру по инициативе сервера. Может показаться, что для реализации подобного механизма понадобится что-то вроде HTTP/2 Server Push. Но, на самом деле, существует очень старая технология (о которой часто забывают), которая позволяет реализовать подобную схему взаимодействия клиента и сервера. Эта технология отличается универсальной поддержкой браузеров, для её реализации не нужно углубляться в инфраструктурные сложности, характерные для реализации HTTP/2 Server Push. Facebook использует эту технологию с 2010 года (почитайте про BigPipe), да и на других сайтах, вроде Ebay, она тоже находит применение в различных формах. Но возникает такое ощущение, что JavaScript-разработчики одностраничных приложений эту технологию, в основном, либо игнорируют, либо просто ей не пользуются. Речь идёт о прогрессивной загрузке HTML. Эта технология известна под разными названиями: «early flush», «head flushing», «progressive HTML». Она работает благодаря комбинации двух механизмов:
- Первый — это передача HTTP-сообщений по частям (HTTP chunked transfer encoding).
- Второй — это прогрессивный рендеринг HTML в браузере.
Механизм chunked transfer encoding появился в HTTP/1.1. Он позволяет разбивать HTTP-ответы на множество небольших частей, которые передаются браузеру в потоковом режиме. Браузер «скрепляет» эти части по мере их прибытия, формируя из них полный код ответа. Хотя такой подход предусматривает немалые изменения в том, как страницы формируются на сервере, большинство языков и фреймворков обладают поддержкой выдачи подобных ответов, разбитых на части. В веб-фронтендах Instagram применяется Django, поэтому мы используем объект StreamingHttpResponse. Причина, по которой применение подобного механизма может принести пользу, заключается в том, что он позволяет отправлять HTML-содержимое страницы в браузер в потоковом режиме по мере готовности отдельных частей страницы, а не ждать того момента, когда будет готов полный код страницы. Это означает, что мы можем сбросить (flush) в браузер заголовок страницы практически мгновенно после получения запроса (отсюда и термин «early flush»). Подготовка заголовка не требует особенно больших серверных ресурсов. Это позволяет браузеру приступить к загрузке скриптов и стилей ещё тогда, когда сервер занят генерированием динамических данных для остальных частей страницы. Взглянем на то, к какому эффекту приводит применение этой методики. Вот как выглядит обычная загрузка страницы.

Технология early flush не используется: загрузка ресурсов не начинается до полной загрузки HTML-кода страницы
А вот что происходит в том случае, если сервер, при поступлении запроса, тут же передаёт браузеру заголовок страницы.

Технология early flush используется: ресурсы начинают загружаться сразу после того, как HTML-теги сбрасываются в браузер
Кроме того, мы можем использовать механизм передачи HTTP-сообщений по частям для отправки данных клиенту по мере их готовности. В случае с приложениями, рендеринг которых выполняется на сервере, эти данные могут быть представлены в форме HTML-кода. Но если речь идёт об одностраничных приложениях вроде instagram.com, сервер может передать клиенту и нечто вроде JSON-данных. Для того чтобы взглянуть на то, как это работает — давайте разберём простейший пример начала работы одностраничного приложения.
Сначала в браузер отправляется исходная HTML-разметка, содержащая JavaScript-код, необходимый для рендеринга страницы. После разбора и выполнения этого скрипта будет выполнен XHR-запрос, загружающий исходные данные, необходимые для рендеринга страницы.

Процесс загрузки страницы в ситуации, когда браузер самостоятельно запрашивает у сервера всё, что ему нужно
Этот процесс предусматривает несколько ситуаций, в которых клиент отправляет серверу запрос и ждёт от него ответа. В результате здесь имеются периоды, когда и сервер и клиент пребывают в бездействии. Вместо того, чтобы сервер ждал бы от клиента выполнения запроса к API, эффективней было бы, если бы сервер начал бы работу по подготовке ответа API сразу после того, как был сгенерирован HTML-код. После того, как ответ был бы готов, сервер мог бы, по своей инициативе, отравить его клиенту. Это означало бы, что к тому времени, когда клиент подготовил бы всё, что нужно для визуализации данных, которые раньше загружались после выполнения запроса к API, эти данные уже, скорее всего, были бы готовы. Клиенту при этом не пришлось бы выполнять отдельный запрос к серверу и ждать от него ответа.
Первый шаг в реализации подобной схемы взаимодействия клиента и сервера заключается в создании JSON-кэша, предназначенного для хранения ответов сервера. Мы разработали эту часть системы, используя маленький скриптовый блок, встроенный в HTML-код страницы. Он играет роль кэша и содержит сведения о запросах, которые будут добавлены в кэш сервером (это, в упрощённой форме, показано ниже).
<script type="text/javascript">
// сервер запишет сюда пути к API, обращения к которым он планирует выполнить самостоятельно,
// что сообщит клиенту о том, что ему нужно подождать данных с сервера, а не
// выполнять подобные запросы по своей инициативе
window.__data = {
'/my/api/path': {
waiting: [],
}
};
window.__dataLoaded = function(path, data) {
const cacheEntry = window.__data[path];
if (cacheEntry) {
cacheEntry.data = data;
for (var i = 0;i < cacheEntry.waiting.length; ++i) {
cacheEntry.waiting[i].resolve(cacheEntry.data);
}
cacheEntry.waiting = [];
}
};
</script>После сброса HTML-кода в браузер сервер может самостоятельно выполнить запросы к API. После получения ответов на эти запросы сервер сбросит на страницу JSON-данные в виде скриптового тега, содержащего эти данные. Когда браузер получит и разберёт подобный фрагмент HTML-кода страницы, это приведёт к тому, что данные попадут в JSON-кэш. Самое важное здесь то, что браузер будет выводить страницу прогрессивно — по мере того, как он получает фрагменты ответа (то есть — готовые блоки скриптов будут выполняться по мере их поступления в браузер). Это означает, что вполне можно параллельно генерировать на сервере большие объёмы данных и сбрасывать на страницу блоки со скриптами по мере готовности соответствующих данных. Эти скрипты будут немедленно выполняться на клиенте. Это — основа системы BigPipe, применяемой в Facebook. Там множество независимых пейджлетов параллельно загружаются на сервере и передаются клиенту по мере их готовности.
<script type="text/javascript">
window.__dataLoaded('/my/api/path', {
// JSON-ответ API, обёрнутый в вызов функции для того, чтобы
// добавить его в JSON-кэш...
});
</script>Когда клиентский скрипт готов к тому, чтобы запросить нужные ему данные, он, вместо выполнения XHR-запроса, сначала проверяет JSON-кэш. Если в кэше уже есть результаты запроса — скрипт немедленно получает то, что ему нужно. Если же запрос находится в процессе выполнения — скрипт ждёт результатов.
function queryAPI(path) {
const cacheEntry = window.__data[path];
if (!cacheEntry) {
// выполняется обычный XHR-запрос к API
return fetch(path);
} else if (cacheEntry.data) {
// сервер уже передал нам необходимые данные
return Promise.resolve(cacheEntry.data);
} else {
// сервер всё ещё готовится к передаче данных,
// поэтому мы становимся в очередь на получение уведомления
// об их готовности
const waiting = {};
cacheEntry.waiting.push(waiting);
return new Promise((resolve) => {
waiting.resolve = resolve;
});
}
}Всё это приводит к тому, что процесс загрузки страницы становится таким, как на следующей схеме.
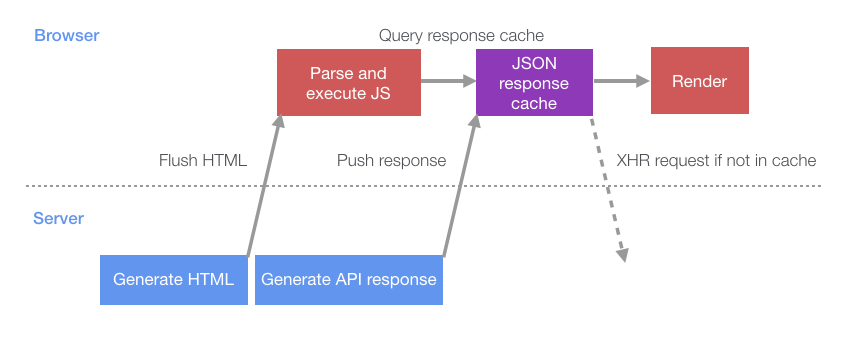
Процесс загрузки страницы в ситуации, когда браузер принимает активное участие в подготовке данных для клиента
Если сравнить это с самым простым способом загрузки страниц, то окажется, что сервер и клиент могут теперь выполнять больше задач в параллельном режиме. Это снижает длительность периодов простоя, в ходе которых сервер и клиент друг друга ждут.
Данная оптимизация оказала сильнейшее положительное влияние на нашу систему. Так, в настольных браузерах загрузка страницы стала завершаться на 14% быстрее, чем раньше. А в мобильных браузерах (из-за более длительных задержек в мобильных сетях) страница стала загружаться на 23% быстрее.
Уважаемые читатели! Планируете ли вы применять рассмотренную здесь методику оптимизации формирования веб-страниц в своих проектах?


