
В наши дни, если вы пишете некое Python-приложение, то вам, скорее всего, придётся оснащать его функционалом HTTP-клиента, который способен общаться с HTTP-серверами. Повсеместное распространение REST API сделало HTTP-инструменты уважаемыми жителями бесчисленного множества программных проектов. Именно поэтому любому программисту необходимо владеть паттернами, направленными на организацию оптимальной работы с HTTP-соединениями.

Существует множество HTTP-клиентов для Python. Самым распространённым среди них, и, к тому же, таким, с которым легко работать, можно назвать requests. Сегодня этот клиент является стандартом де-факто.
Первая оптимизация, которую стоит принять во внимание при работе с HTTP, заключается в использовании постоянных соединений с веб-серверами. Постоянные соединения стали стандартом начиная с HTTP 1.1, но многие приложения до сих пор их не применяют. Этот недочёт легко объяснить, зная о том, что при использовании библиотеки
Соединения хранятся в пуле соединений (он, по умолчанию, рассчитан на 10 соединений). Размер пула можно настраивать:
Повторное использование TCP-соединения для отправки нескольких HTTP-запросов даёт приложению множество преимуществ в производительности:
Протокол HTTP 1.1, кроме того, поддерживает возможности конвейерной обработки запросов. Это позволяет отправлять несколько запросов в рамках одного и того же соединения, не дожидаясь ответов на ранее отправленные запросы (то есть — отправлять запросы «пакетами»). К несчастью, эту возможность библиотека
У
Разумно спроектированное приложение может смягчить эту проблему благодаря использованию пула потоков, наподобие тех, которые предоставляет
Этот весьма полезный паттерн реализован в библиотеке requests-futures. При этом использование объектов
По умолчанию создаётся воркер с двумя потоками, но программа легко может это значение настроить, передав объекту
Как уже было сказано, библиотека
Начиная с Python 3.5 в стандартные возможности языка входят средства асинхронного программирования с использованием
Все описанные выше подходы (использование
Ниже представлен пример кода, в котором HTTP-клиент отправляет запросы серверу
Вот какие результаты были получены после запуска этой программы:
Вот диаграмма результатов.
Результаты исследования производительности разных способов выполнения HTTP-запросов
Совершенно неудивительно то, что самой медленной оказалась простейшая синхронная схема выполнения запросов. Дело тут в том, что здесь запросы выполняются один за другим, без повторного использования соединения. Как результат, на то, чтобы выполнить 10 запросов, уходит 12 секунд.
Применение объекта
Если ваша система и ваша программа позволяют работать с потоками, то это — веская причина для того, чтобы задуматься об использовании потоков для параллелизации запросов. Потоки, однако, создают некоторую дополнительную нагрузку на систему, они, так сказать, не «бесплатны». Их нужно создавать, запускать, нужно дожидаться завершения их работы.
Если вы хотите пользоваться быстрым асинхронным HTTP-клиентом, то вам, если только вы не пишете на старых версиях Python, стоит обратить самое серьёзное внимание на
Альтернатива
Ещё одна оптимизация работы с сетевыми ресурсами, которая может оказаться полезной в плане повышения производительности приложений, заключается в использовании потоковой передачи данных. Стандартная схема обработки запросов выглядит так: приложение отправляет запрос, после чего тело этого запроса загружается за один заход. Параметр
Вот как выглядит организация потоковой обработки данных с использованием
Вот как организовать потоковую обработку данных с помощью
Избавление от необходимости одномоментной загрузки полного содержимого ответа важно в тех случаях, когда надо предотвратить потенциальную возможность бесполезного выделения сотен мегабайт памяти. Если программе не нужен доступ к ответу как к единому целому, если она может работать и с отдельными фрагментами ответа, то, вероятно, лучше всего будет прибегнуть именно к методам потоковой работы с запросами. Например, если вы собираетесь сохранить данные из ответа сервера в файл, то чтение и запись их по частям будет гораздо эффективнее в плане использования памяти, чем чтение всего тела ответа, выделение огромного объёма памяти и последующая запись всего этого на диск.
Надеюсь, мой рассказ о разных способах оптимизации работы HTTP-клиентов поможет вам выбрать то, что лучше всего подойдёт именно вашему Python-приложению.
Уважаемые читатели! Если вам известны ещё какие-нибудь способы оптимизации работы с HTTP-запросами в Python-приложениях — просим ими поделиться.



Существует множество HTTP-клиентов для Python. Самым распространённым среди них, и, к тому же, таким, с которым легко работать, можно назвать requests. Сегодня этот клиент является стандартом де-факто.
Постоянные соединения
Первая оптимизация, которую стоит принять во внимание при работе с HTTP, заключается в использовании постоянных соединений с веб-серверами. Постоянные соединения стали стандартом начиная с HTTP 1.1, но многие приложения до сих пор их не применяют. Этот недочёт легко объяснить, зная о том, что при использовании библиотеки
requests в простом режиме (например — применяя её метод get) соединение с сервером закрывается после получения ответа от него. Для того чтобы этого избежать, приложению нужно использовать объект Session, который позволяет многократно использовать открытые соединения:import requests
session = requests.Session()
session.get("http://example.com")
# Соединение используется повторно
session.get("http://example.com")Соединения хранятся в пуле соединений (он, по умолчанию, рассчитан на 10 соединений). Размер пула можно настраивать:
import requests
session = requests.Session()
adapter = requests.adapters.HTTPAdapter(
pool_connections=100,
pool_maxsize=100)
session.mount('http://', adapter)
response = session.get("http://example.org")Повторное использование TCP-соединения для отправки нескольких HTTP-запросов даёт приложению множество преимуществ в производительности:
- Снижение нагрузки на процессор и снижение потребности в оперативной памяти (из-за того, что меньше соединений открываются одновременно).
- Уменьшение задержек при выполнении запросов, идущих друг за другом (нет процедуры TCP-рукопожатия).
- Исключения могут выбрасываться без дополнительных затрат времени на закрытие TCP-соединения.
Протокол HTTP 1.1, кроме того, поддерживает возможности конвейерной обработки запросов. Это позволяет отправлять несколько запросов в рамках одного и того же соединения, не дожидаясь ответов на ранее отправленные запросы (то есть — отправлять запросы «пакетами»). К несчастью, эту возможность библиотека
requests не поддерживает. Однако конвейерная обработка запросов может быть не такой быстрой, как их параллельная обработка. И, кроме того, тут уместно обратить внимание вот на что: ответы на «пакетные» запросы должны отправляться сервером в той же последовательности, в какой он получил эти запросы. В результате получается не самая эффективная схема обработки запросов по принципу FIFO («first in, first out» — «первым пришёл — первым ушёл»).Параллельная обработка запросов
У
requests есть, кроме того, ещё один серьёзный недостаток. Это — синхронная библиотека. Вызов метода наподобие requests.get("http://example.org") блокирует программу до получения полного ответа HTTP-сервера. То, что приложению приходится ждать и ничего не делать, можно счесть минусом данной схемы организации взаимодействия с сервером. Можно ли сделать так, чтобы программа занималась чем-нибудь полезным вместо того, чтобы просто ждать?Разумно спроектированное приложение может смягчить эту проблему благодаря использованию пула потоков, наподобие тех, которые предоставляет
concurrent.futures. Это позволяет быстро организовать параллелизацию HTTP-запросов:from concurrent import futures
import requests
with futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = [
executor.submit(
lambda: requests.get("http://example.org"))
for _ in range(8)
]
results = [
f.result().status_code
for f in futures
]
print("Results: %s" % results)Этот весьма полезный паттерн реализован в библиотеке requests-futures. При этом использование объектов
Session прозрачно для разработчика:from requests_futures import sessions
session = sessions.FuturesSession()
futures = [
session.get("http://example.org")
for _ in range(8)
]
results = [
f.result().status_code
for f in futures
]
print("Results: %s" % results)По умолчанию создаётся воркер с двумя потоками, но программа легко может это значение настроить, передав объекту
FuturSession аргумент max_workers или даже собственный исполнитель. Например, это может выглядеть так:FuturesSession(executor=ThreadPoolExecutor(max_workers=10))Асинхронная работа с запросами
Как уже было сказано, библиотека
requests полностью синхронна. Это приводит к блокировке приложения во время ожидания ответа от сервера, что плохо сказывается на производительности. Одно из решений этой проблемы — выполнение HTTP-запросов в отдельных потоках. Но использование потоков — это дополнительная нагрузка на систему. К тому же это означает введение в программу схемы параллельной обработки данных, что устраивает не всех.Начиная с Python 3.5 в стандартные возможности языка входят средства асинхронного программирования с использованием
asyncio. Библиотека aiohttp предоставляет разработчику асинхронный HTTP-клиент, созданный на базе asyncio. Эта библиотека позволяет приложению отправлять целые серии запросов и продолжать работу. При этом для отправки очередного запроса не нужно ждать ответа на ранее отправленный запрос. В отличие от конвейерной обработки HTTP-запросов, aiohttp отправляет запросы параллельно, пользуясь несколькими соединениями. Это позволяет избежать «проблемы FIFO», описанной выше. Вот как выглядит использование aiohttp:import aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return response
loop = asyncio.get_event_loop()
coroutines = [get("http://example.com") for _ in range(8)]
results = loop.run_until_complete(asyncio.gather(*coroutines))
print("Results: %s" % results)Все описанные выше подходы (использование
Session, потоков, concurrent.futures или asyncio) предлагают разные способы ускорения HTTP-клиентов.Производительность
Ниже представлен пример кода, в котором HTTP-клиент отправляет запросы серверу
httpbin.org. Сервер поддерживает API, умеющее, кроме прочего, имитировать систему, которой для ответа на запрос нужно много времени (в данном случае это 1 секунда). Здесь реализованы все рассмотренные выше техники и выполнено измерение их производительности:import contextlib
import time
import aiohttp
import asyncio
import requests
from requests_futures import sessions
URL = "http://httpbin.org/delay/1"
TRIES = 10
@contextlib.contextmanager
def report_time(test):
t0 = time.time()
yield
print("Time needed for `%s' called: %.2fs"
% (test, time.time() - t0))
with report_time("serialized"):
for i in range(TRIES):
requests.get(URL)
session = requests.Session()
with report_time("Session"):
for i in range(TRIES):
session.get(URL)
session = sessions.FuturesSession(max_workers=2)
with report_time("FuturesSession w/ 2 workers"):
futures = [session.get(URL)
for i in range(TRIES)]
for f in futures:
f.result()
session = sessions.FuturesSession(max_workers=TRIES)
with report_time("FuturesSession w/ max workers"):
futures = [session.get(URL)
for i in range(TRIES)]
for f in futures:
f.result()
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
await response.read()
loop = asyncio.get_event_loop()
with report_time("aiohttp"):
loop.run_until_complete(
asyncio.gather(*[get(URL)
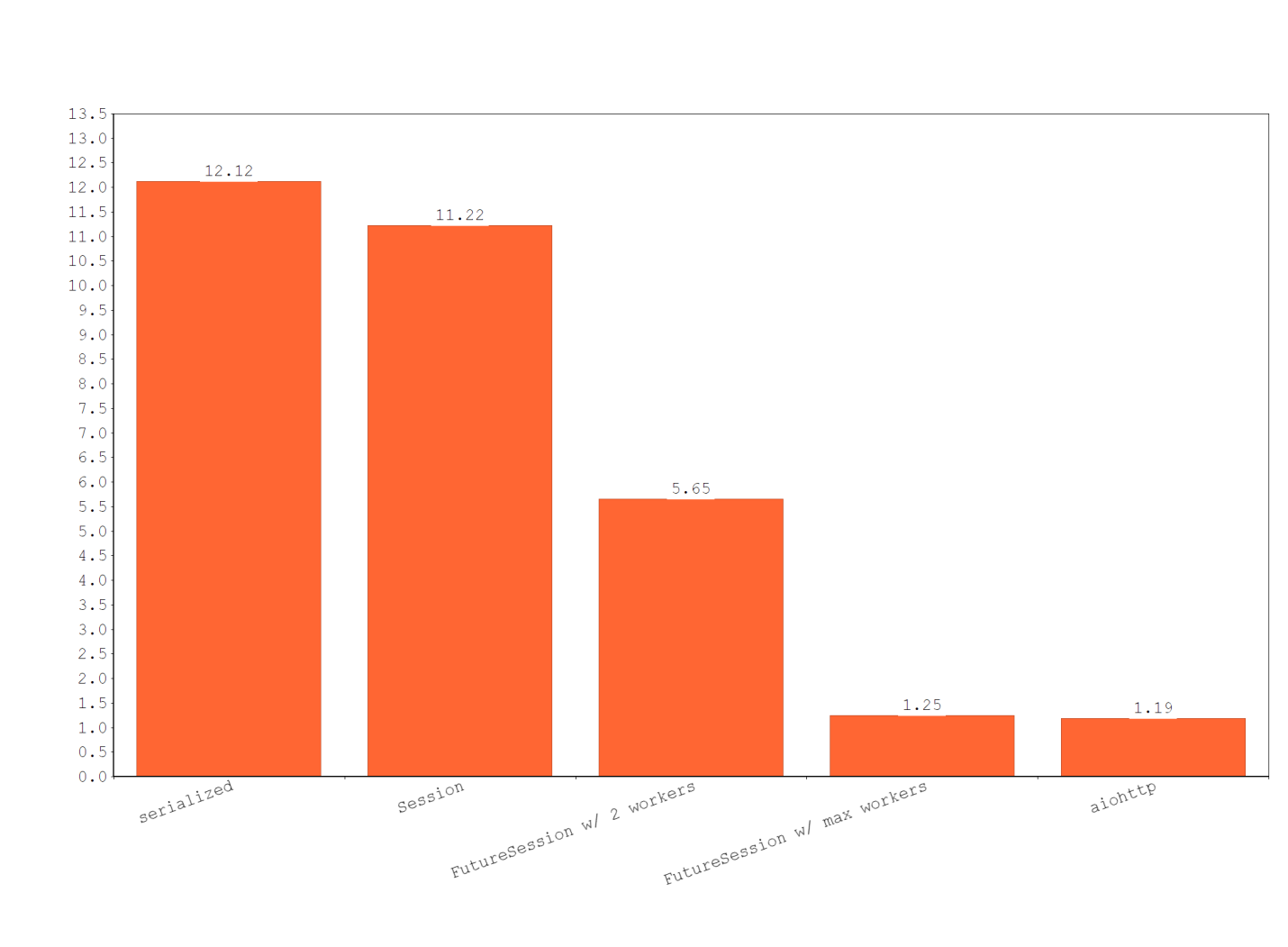
for i in range(TRIES)]))Вот какие результаты были получены после запуска этой программы:
Time needed for `serialized' called: 12.12s
Time needed for `Session' called: 11.22s
Time needed for `FuturesSession w/ 2 workers' called: 5.65s
Time needed for `FuturesSession w/ max workers' called: 1.25s
Time needed for `aiohttp' called: 1.19sВот диаграмма результатов.

Результаты исследования производительности разных способов выполнения HTTP-запросов
Совершенно неудивительно то, что самой медленной оказалась простейшая синхронная схема выполнения запросов. Дело тут в том, что здесь запросы выполняются один за другим, без повторного использования соединения. Как результат, на то, чтобы выполнить 10 запросов, уходит 12 секунд.
Применение объекта
Session, и, в результате, многократное использование соединений, позволяет сэкономить 8% времени. Это — уже очень хорошо, да и достичь этого весьма просто. Любому, кто заботится о производительности, стоит использовать хотя бы объект Session.Если ваша система и ваша программа позволяют работать с потоками, то это — веская причина для того, чтобы задуматься об использовании потоков для параллелизации запросов. Потоки, однако, создают некоторую дополнительную нагрузку на систему, они, так сказать, не «бесплатны». Их нужно создавать, запускать, нужно дожидаться завершения их работы.
Если вы хотите пользоваться быстрым асинхронным HTTP-клиентом, то вам, если только вы не пишете на старых версиях Python, стоит обратить самое серьёзное внимание на
aiohttp. Это — самое быстрое решение, лучше всего поддающееся масштабированию. Оно способно обрабатывать сотни параллельных запросов.Альтернатива
aiohttp, не особенно хорошая альтернатива — параллельное управление сотнями потоков.Потоковая обработка данных
Ещё одна оптимизация работы с сетевыми ресурсами, которая может оказаться полезной в плане повышения производительности приложений, заключается в использовании потоковой передачи данных. Стандартная схема обработки запросов выглядит так: приложение отправляет запрос, после чего тело этого запроса загружается за один заход. Параметр
stream, который поддерживает библиотека requests, а так же атрибут content библиотеки aiohttp, позволяют отойти от этой схемы.Вот как выглядит организация потоковой обработки данных с использованием
requests:import requests
# Воспользуемся `with` для того чтобы обеспечить закрытие потока ответа и возможность
# возвращения соединения обратно в пул.
with requests.get('http://example.org', stream=True) as r:
print(list(r.iter_content()))Вот как организовать потоковую обработку данных с помощью
aiohttp:import aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.content.read()
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(get("http://example.com"))]
loop.run_until_complete(asyncio.wait(tasks))
print("Results: %s" % [task.result() for task in tasks])Избавление от необходимости одномоментной загрузки полного содержимого ответа важно в тех случаях, когда надо предотвратить потенциальную возможность бесполезного выделения сотен мегабайт памяти. Если программе не нужен доступ к ответу как к единому целому, если она может работать и с отдельными фрагментами ответа, то, вероятно, лучше всего будет прибегнуть именно к методам потоковой работы с запросами. Например, если вы собираетесь сохранить данные из ответа сервера в файл, то чтение и запись их по частям будет гораздо эффективнее в плане использования памяти, чем чтение всего тела ответа, выделение огромного объёма памяти и последующая запись всего этого на диск.
Итоги
Надеюсь, мой рассказ о разных способах оптимизации работы HTTP-клиентов поможет вам выбрать то, что лучше всего подойдёт именно вашему Python-приложению.
Уважаемые читатели! Если вам известны ещё какие-нибудь способы оптимизации работы с HTTP-запросами в Python-приложениях — просим ими поделиться.


