Комментарии 163
Почему технология WASM не получила достаточно серьёзного распространения?
Это как? Unity сейчас торчит почти из каждой гейм-разработки.
Станет ли технология WASM чем-то вроде нового стандартного языка для разработки веб-проектов?
javascript — язык очень простой и быстрый в разработке. Зачем его менять на что-то более сложное и непонятное?
JS и WASM это разные ниши. Как java/С# и C++.
Они и не должны друг друга замещать.
Я уверен, что многие фреймворки будут переписывать части потрохов на WASM.
Наверное даже какие-то CMS, включая WP может переписать какие-то потроха на WASM.
Но в основной части веб-разработки WASM не требуется — требуются готовые либы, которые, собственно, уже и есть и продолжают появляться.
В wasm нет, и непонятно когда появится gc. Когда туда компилят шарпы, то тащат свой gc и огребают от этого миллион проблем
Только шарпы ведь специально в wasm не компилят, а затаскивают реализацию виртуальной машины, которая исполняет обычный байткод дотнета. Из ощутимых проблем — это увеличивает размер бандла, хотя код рантайма отлично кэшируется.
Обещают aot компиляцию в будущем
Интересная штука, только несколько смущает что они всю дорогу сопоставляют себя с Typescript, хотя языки настолько далёкие друг от друга, что лучше бы они себя с условным C# сопоставляли. AS — язык со слабой sound системой типов, с возможностью runtime cast-ов. TS — мета-язык транспилируемый почти без изменений в JS с сильной системой типов и полным отсутствием чего-бы то ни было в runtime.
Мне кажется C# и Java имеет с AS больше общего, чем TS.
большая часть проектов WASM написана на C++ или Rust
И что? Не увидел в AS никаких синтаксиса для указателей. Плохо искал? Ручное управление памятью? Вроде документация пишет про GC. Также как не увидел в AS ничего из того, чем славен TS.
Остальную часть вашего сообщения я, если честно, вообще не понял. Вы комментарием не промахнулись?
AssemblyScript implements garbage collection on top of linear memory while the WebAssembly GC (https://github.com/WebAssembly/gc) proposal is still in the works. More precisely it implements multiple runtime variants that are useful for different use cases, with the default being your typical memory manager and GC. The interface of the different variants is always the same, so these are interchangeable, yet differ in their level of sophistication. In case of doubt, starting out with the default is probably just fine.
и про память в целом www.assemblyscript.org/memory.html#importing-memory
По поводу GC, написано же на доступном языке на сайте AS
Как раз оттуда я и взял то что язык использует GC. Отключать GC можно во многих языках. По ссылке ничего особенно интересного нет. Вот тут (следующая ссылка) уже что-то есть:
function __new(size: usize, id: u32): usize
function __pin(ptr: usize): usize
function __unpin(ptr: usize): void
function __collect(): voidПолучается что синтаксиса нет, но есть что-то вроде макросов\встроенных методов. Т.е. при большом желании можно поиграть в C.
Так веб морду вам в любом случае на JS надо будет писать т.к. прямого доступа к DOM у WASM нет.
Стремление использовать один язык для всех возможных задач, скорее всего, выйдет вам боком: тулинг будет неудобным, поддержка сообщества — скудной, а ваши "веб-морды" — тяжелыми. Я искренне считаю сишарп одним из лучших современных языков, но он не является серебряной пулей.
Писать под веб можно и не касаясь джиеса: typescript, reasonml, purescript...
Как человек, который писал на ангуляре 2-7 и который сейчас пишет на Блейзоре могу смело сказать, что писать код и компилить стало в разы быстрее.
Тяжесть морды очень относительна. Сам фреймворк кэшируется и не меняется, из бинарей вырезаются неиспользуемые методы, главное рефлексией не баловаться.
А тулинг всяких вебпаков легкий.Можно использовать Parcel — там практически все из коробки работает. Куда еще легче?
Для сравнения — почитайте, как работает отладка блазора.
Тяжесть морды очень относительна.Да ничего «относительного» тут нет. Вы сначала заставляете пользователя скачать ~2 мегабайта бинарников, т.е. весь рантайм Mono целиком, а не только то, что фактически используется. Потом он начинает интерпретировать уже непосредственно ваш код — про JIT-компиляцию можете забыть, т.к. она будет работать только на уровне «WASM -> Mono», а на уровне «Mono -> ваш код» это невозможно из соображений безопасности.
До тех пор, пока в рантайм WASM не запилят GC и не будет возможности компилировать C# -> WASM напрямую, без промежуточной виртуальной машины, Blazor — не более, чем любопытная игрушка, использовать которую в продакшене можно только на свой страх и риск. А конкретных планов по реализации этой фичи в WASM пока нет, только пропозал…
https://github.com/dotnet/aspnetcore/issues/5466
mkArtakMSFT modified the milestones: Next sprint planning, 6.0.0 11 days ago
mkArtakMSFT added this to 6.0 in ASP.NET Core Blazor & MVC 6.0 11 days ago
While we do expect significant runtime performance improvements from AoT, our investigations so far have shown that AoT trades of improved runtime performance for increased download size. Code that has been AoT compiled to WebAssembly is generally larger than the equivalent .NET IL (just like how natively compiled .NET images are typically larger than the original .NET assemblies), which impacts startup time. This is why we expect AoT will typically be used in a mixed mode, where some of the app has been optimized for runtime performance using AoT, and the rest has been left as interpreted .NET IL for compactness. Initially we may use AoT to optimize common performance critical code paths in Blazor, like component rendering and JSON parsing, and then make the AoT toolchain available to users to decide how they want to optimize their own code. AoT also does impact the availability of dynamic runtime features, like calling code using reflection.
Even with AoT being delayed, we still expect to deliver performance improvements for Blazor WebAssembly in .NET 5. The .NET 5 core libraries are generally more efficient than the Mono ones we're currently using. We are also investigating other performance improvements, like improvements to the GC and the Blazor component rendering algorithm. We are then planning to make previews of AoT support for Blazor WebAssembly available early in the .NET 6 release timeframe (first previews expected in Q1 '21).
В свете вышесказаного использование одного языка для всего, равно как и «выбор» под задачу — равнозначны.
Что качается неповоротливых формочек… Ну поскольку мы и так «выбрали» веб ни о какой «легкости» речь уже не идет. Однако это и не важно! Критерии качества корпоративного софта сильно отличаются от «нормальных». Тут известные баги можно годами не лечить, потому, что известен воркэраунд и главное он известен всем… трем пользоватлям софтины. Тут пользователи по 2 минуты могут ждать отклик веб страницы потому, что альтернатива сделать то-же самое руками за день. И т.д. Я не говорю, что это хорошо, но и не говорю что это однозначно днище и фу фу. Задачи другие. Другие приоритеты.
Писать под веб можно и не касаясь джиеса: typescript, reasonml, purescript...
А можно, не отходя от станка, на шарпе. Об этом собственно и речь. Это именно «выбор» типа «я это знаю хорошо — давайте на этом и делать». И выбор в данном случае осознанный — морда в данном случае побочный продукт а вовсе не основной. Она не видна наружу. От нее требуется только одно — чтоб она была. У пользователей какой критерий «хорошей» софтины? Да чтоб в Excel выгружало 4 гига отчета! :)
Я считаю выбор языков под задачу фикцией.С одной стороны, я понимаю, что в инженерной практике иногда возникает необходимость забить гвоздь микроскопом. Вот прям позарез надо, а вокруг кроме микроскопа вообще ничего нет, и даже если гвоздь войдет криво, а на микроскопе останется царапина — это не важно. Это к вопросу о том, что «от морды необходимо только то, чтобы она была». Если человек понимает риски и идет на этот выбор осознанно — это вполне допустимо.
С другой стороны — отрицание необходимости выбора инструмента под задачу говорит только о вашем уровне компетенции, а то, что никто из вашего круга общения так не делал, вы экстраполируете этот опыт на весь мир и радуетесь, что вам не придется больше иметь дело с этими отвратительными молотками — окончательно авторитет ваших слов на ноль.
Знаете что это за язык? Любой!Опять же, совсем не так. Помимо качеств непосредственно языка, которые вы перечислили, есть также экосистема — набор доступных для него библиотек/фреймворков/движков, решающих определенные задачи.
Например, сам по себе Python не особо предназначен для всякого дата-саенса. В нем по умолчанию нет ни матриц, ни комплексных чисел, ни символьного вычисления, как в каком-нибудь Wolfram Alpha / Mathcad, да и скорость выполнения для числодробилок не впечатляет. Однако самые популярные библиотеки реализованы именно под него, что делает Python выбором номер 1 при необходимости проанализировать массив данных на наличие корреляции или натренировать нейросеть. Аналогично, PHP все еще довольно популярен, но даже отъявленным фанатам не приходит в голову написать на нем, например, 3D-движок или загрузчик операционной системы.
Поэтому писать вы, конечно, вольны на чем угодно. Хоть на сишарпе, хоть на 1С, хоть на батниках — особенно, если этот продукт не нужен никому, кроме трех с половиной человек. Но выдавать в качестве хорошего инженерного решения — увольте.
Вы гоаорите инфраструктура определяет годность «под задачу». Соглашусь. Но инфраструктура не язык. причем примеров масса, когда явно не подхлдящий язык используется именно как «стандарт». Давайте посмотрим:
- JS подходит для ML? TensorFlow
- C# со сборщиком мусора для игр? Unity
- Скриптовый Python для data science? Вы сами этот пример привели.
- Если уж на то пошло, то JS хорош для UI? Просто выбора нет.
И т.д.
Если раньше еще можно было говорить что С имеет преимущество перед Ассемблером потому что..., то с современными языками это уже не так. Да объективные преимущества у разных классов языков есть. Но внутри одного класса? Это даже не смешно уже. Что случше Java или C#? Можно холиварить хоть год. А в реальности? Я знаю C# значит от лучше. Кто-то знает Java — да он же прямо создан для это го проекта!
И насчет загрузчика на PHP… Но есть-же бекэнд на JS :)
У нас была комичная история. Набрали php-шников и скрам-коуча. И стали выбирать, на каком языке делать новый проект для кассовых аппаратов. И какой же язык лучше всего подошёл под задачу, как вы думаете?)
Да что там язык, люди даже фреймворк под задачу не способны выбрать.
Потенциально — ящик пандоры, реальность как всегда удивит больше наших фантазий.
js разминифицировать реально тем более что многие оставляют открытыми map файлы которые позволяют еще и получить исходный код как есть.
Тут же мы получим аналог asm для некоторой виртуальной машины — исходный код не поучить. Без хорошего знания ассемблера и LLVM понять что же делает этот маленький пакет на 620кб который визуально ничего не делает — доступно только избранным.

У того же голанга размер пустого бинарника с реализацией сборщика мусора после tinygo — 20кб — вполне вменяемо по сравнению с 1.6мб blazor-а от c#. Т.е реализация managed-управления памятью уже не проблема прямо поверх wasm-а без таковой.
Т.е реализация managed-управления памятью уже не проблема прямо поверх wasm-а без таковой.
Безусловно. Но когда у вас таких блобов несколько, и каждый тащит свою реализацию рантайма...
Смысл в том, что нет dead code elimination — 1.6Мб — это для пустого проекта практически без пользовательского кода, который никак не использует все это богатство. Если так рассуждать, то 20кб в голанге — это тоже весь богатый рантайм, необходимый для такого же минимального пользовательского кода. Если начать подкидывать своего кода, то размер будет увеличиваться и там и там, просто в одном случае это будет 1.6Мб+, в другом 20кб+.
Wasm хорош для специализированных вычислительных задач, или для игр. Обычный фронт вполне шустро работает на js/ts, если конечно не написан совсем криворукими джунами, которые и васм закосячат. Плюс для фронтовых задач есть фреймворки типа реакта или вью, удобный процесс отладки, декларативно-реактивный подход, который не с потолка был взят, а стал итогом многолетней эволюции. Не вижу смысла отказываться от всех этих удобств ради сомнительного пунктика "не использовать js. Тем более по факту промышленным стандартом становится тайпскрипт, который устранил единственный js-ный недостаток — отсутствие типизации. Js не используется в новых проектах:) А что понапишут новоприбывшие фронтендеры на своих "правильных" языках? Спагетти-портянки в стиле jQuery конца нулевых?)))
Итого: сишный/плюсовой васм имеет практический смысл, остальное — блажь и йуношеский максимализм, не более.
Обычный фронт вполне шустро работает на js/ts, если конечно не написан совсем криворукими джунами, которые и васм закосячат.Ой, я надеюсь ты не про mail.ru или не про online.sberbank.ru
есть фреймворки типа реакта или вью, удобный процесс отладки, декларативно-реактивный подход
Blazor и Yew эксплуатируют React-подобный подход с XML-подобным синтаксисом и реактивностью. Первый из коробки отлаживается прямо в девтулзах хрома.
тайпскрипт, который устранил единственный js-ный недостаток — отсутствие типизации.
В рантайме типов нет, а слабость типизации все так же присутствует.
То что в рантайме типов нет, это преимущество. Представьте, ваш сайт делает запрос ко внешнему API, а формат его ответа поменялся. В слабой типизации, пользователь увидит NaN, но остальная функциональность сайта продолжит работать. А в случае сильной типизации случится рантайм ошибка и сломается вообще всё. Придется в экстренном порядке все бросать и чинить интеграцию с API
А в случае сильной типизации случится рантайм ошибка и сломается вообще всё
Ну нет. Не так. В случае сильной типизации будет ровно то, что вы пропишете. Хотите чтобы приложение кидало ошибку? Тогда после провальной валидации кидайте ошибку. Хотите чтобы в баг-трекер ушло сообщение о проблеме, но пользователь продолжил работу с приложением на удачу? Не вопрос — достройте объект дефолтными значениями.
В случае TS тут скорее играет роль, что типизация игрушечная, и вы можете вообще без какой-либо валидации взять полученное значение "как есть", ибо весь runtime-язык (JS) устроен как "всё есть либо примитив, либо hashmap". Но едва ли это стоит относить к сильной стороне JS. А то что в TS нельзя внятно проверить объект на соответствие типов, потому что runtime информации просто нет — это недостаток. Не на пустом месте берутся все эти io-ts. Но такова уж суть TS, что это мета-язык поверх JS, без своих runtime примитивов.
Валидацию данных на входе в любом языке можно добавить. А вот выбора дать пользователю продолжить работу в строгой типизации нет – потому что шансов наткнуться на ошибку типов намного большое.
Ну выбор между: неполными провалидированными данными, дополненными значениями по-умолчанию где надо и данными, не соответсвующими схеме, — мне кажется очевиден. Вообще довольно странно радоваться тому что приложение может не упасть когда вместо ожидаемых данных по нему бродит неведомо что. Вам правда нравится ситуация когда в каком-нибудь калькуляторе страховки все поля превращаются в NaN? :-) Или что ещё хуже — НЕ превращаются, просто калькулятор врёт.
Если вы настолько сильно недоверяете своему backend-у, то, имхо, это тем более ещё один повод добавить валидацию.
NaN в калькуляторе страховки мне не понравится. Но вот прочитать статью с NaN лайков я смогу, а если там в процессе загрузки будет TypeError – то уже нет
а если там в процессе загрузки будет TypeError – то уже нет
Я понял вашу мысль. Вы готовы мириться с минорными глюками, в пользу принципиальной возможности пользоваться тем или иным интерфейсом, который, в случае наличия валидации, просто бы упал.
Но мне кажется вы занимаетесь самообманом. Ибо, помимо минорных глюков, это ещё источник и мажорных глюков, далеко не все из которых действительно уронят приложение. По той же самой причине. А учитывая что это "отложенные" баги, как, напримре, запись в произвольную область памяти в C++, то никогда не знаешь где и как оно выстрельнет. А учитывая какую вариативность могут нести такие баги… Вы можете наслаждаться ими вечность (ибо о них даже не знают).
Выбирая между двух зол — я бы выбрал "пусть падает". Это приведёт к:
- разработчики научатся ронять не всё приложение а только лишь часть
- бизнес, зависящий от этого приложения, будет чинить баги. И как минимум знать о них
А вот это вебовское "тяп-ляп, ура, вроде работает", меня самого, как веб-разработчика, — бесит.
А то что в TS нельзя внятно проверить объект на соответствие типов, потому что runtime информации просто нет — это недостаток.
А зачем вам проверять его тип в рантайме?
- Мета информация доступная в runtime позволяет проводить автоматическую валидацию (пригодится как во фронте, так и на беке)
- Автоматическое построение каких-нибудь моделей (к примеру в ORM)
- Писать гарантированно работающий код вместо guard-ов (которые недалеко от any ушли)
Я думаю если покопаться, то можно много разных кейсов вспомнить. Особенно если спросить шарпистов\джавистов. По сути у нас уже есть instanceof. И многие на это полагаются. Но это работает только с классами. Рефлексия "для бедных".
Кодогенерация из TS типов почти невыполнима. К примеру я недавно игрался с рядом либ которые генерят валидаторы из типов. Решения разделились на 3 группы
- не работает даже в самых тривиальных случаях
- работает только в самых тривиальных случаях и очень плохо
- в целом работает, но генерирует огроооооомные портянки кода и не умеет в переиспользование кода
Основная причина в том, что система типов в TS слиишком сложная, и позволяет генерировать безумно сложные типы. Не зря люди пишут io-ts модели руками.
Кодогенерация из TS типов почти невыполнима. К примеру я недавно игрался с рядом либ которые генерят валидаторы из типов.
Лично я не "игрался", а некоторое время назад успешно использовал https://github.com/vedantroy/typecheck.macro
Оно не очень хорошо умеет в сложные типы, но я категорически не вижу смысла в попытках "напрягать" генератор пока он не сломается — на практике нужно ехать (провалидировать результат JSON.parse на входе), а не шашечки. Всё сложное можно заменить на композицию из простого, и отдельно после валидации преобразовывать serialization-ready формат к runtime-ready, если в рантайме таки хочется сложных типов. Валидация же нужна на периметре, а не везде.
А можно и в io-ts модели писать, да (оно всё равно сгенерит типы из моделей). Но я подход с привлечением DSL для описания валидации всё равно считаю "шаг назад, два вперед" — не очень хочется брать какой-то DSL, который полностью заменяют типы TS.
На практике всё же надо именно провалидировать JSON: убедиться, что число товаров не является дробным числом, что дата доставки не указывает в прошлое, что в той же дате указан часовой пояс, что номер телефона состоит из цифр и тд. Тут тайпскриптовые типы пасуют. Так что проще не валидатор из типов генерить, а типы из валидатора выводить.
Кажется я его тоже пробовал и быстро отбросил. Передо кандидатами стояли задачи:
- оно должно работать (часть решений работало только в стерильных условиях)
- оно должно уметь в глобальные типы
- оно должно уметь в алгебру типов
- оно должно уметь переиспользовать собственные валидаторы (а то некоторые либы генерируют ТЫСЯЧИ строк кода без переиспользования, там где у io-ts будет строк 10)
- оно должно использовать либо систему резолвинга путей webpack, либо алиасы из tsConfig. Многие решения использовали что-то своё и даже
.tsxфайл не могу за-include-ить - оно не должно ронять всю сборку если валидатор построить не удалось
А в идеале оно:
- должно уметь преобразовывать типы
- уметь рассматривать отсутствующие значения как присутсвующие undefined значения (тонкости нашего бакенда)
- уметь тримать лишние поля
- давать внятные ошибки валидации
В итоге io-ts подошёл почти идеально. Мало лишнего кода (сама либа довольно мелкая, а конструкторы валидаторов не сильно больше самих типов). Умеет в преобразования и вообще очень гибкая. Очень удобно строить наглядные ошибки. По сути мы столкнулись с 2 проблемами:
- очень неудобный синтаксис для
?:, к счастью нам оно почти нигде не нужно - вместо TS типов приходится писать на суржике. Но это терпимо. Я буквально за 5ч переписал ТОННУ типов автозаменами по регуляркам, множественными курсорами и пр. чёрной магией
Но я подход с привлечением DSL для описания валидации всё равно считаю "шаг назад, два вперед" — не очень хочется брать какой-то DSL, который полностью заменяют типы TS.
Я тоже так думал. И убил два дня на эксперименты. Выяснил что ВСЕ существующие решения страшно далеки от поставленных задач и решился на io-ts. Теперь понимаю что изначальная идея о серебрянной пуле была наивной. Такого нет и никогда не будет.
Кстати есть автоматические конверторы из сваггера в io-ts. К сожалению нам не подошли, так как наш swagger часто показывает погоду на Марсе, т.к. пишется руками.
оно должно уметь в алгебру типов
Серьезно? Без алгебры типов не описать приходящее от бека?
оно должно уметь переиспользовать собственные валидаторы
Или это можете сделать вы сами, декомпозировав вход на соответствующие блоки. Но конечно, это будет уже не совсем прям полная автоматика.
оно должно использовать либо систему резолвинга путей webpack, либо алиасы из tsConfig
Собственно, этот ваш пункт хорошо показывает, в какие грабли постоянно влипают люди, которые стали зачем-то использовать ts-specific или webpack-specific резолвинг :-)
оно не должно ронять всю сборку если валидатор построить не удалось
Лично я бы как раз ожидал падения от такого. Но, конечно, в идеале как-то настраиваться бы.
Но io-ts хороший, да. Пусть он мне и не нравится идеологически, но работает он хорошо.
Серьезно? Без алгебры типов не описать приходящее от бека?
Очень много копипасты будет. У нас хватает сущностей почти идентичных (разные версии одного и того же в разрезе времени), но с минимальными отличиями. Где-то полей больше, где-то одно из полей использует более новую модель. И всё это используется одновременно. Так что — да, серьёзно.
Или это можете сделать вы сами, декомпозировав вход на соответствующие блоки. Но конечно, это будет уже не совсем прям полная автоматика.
Если мне нужно очень многое писать руками то зачем мне такой инструмент? io-ts при прочих равных даст гораздо больше преимуществ. А писать руками придётся почти всё. У нас ветвистая система серверных типов.
которые стали зачем-то использовать ts-specific или webpack-specific резолвинг :-)
Ну да, на дворе 2021 год. Писать ../../../../file/file.txt я не буду. Отказываться от tsx я тоже не буду. И разные, включая кастомные, loader-ы нам тоже сильно упрощают жизнь. Overall это жирный плюс. Впрочем это тема для отдельной дискуссии. Я за продвинутый DX, который экономит время и деньги бизнесу.
Лично я бы как раз ожидал падения от такого. Но, конечно, в идеале как-то настраиваться бы.
А зачем вам такое решение? Вам нравится после каждой опечатки минутами ждать пересборки? Не, я пас. TS слишком медленная штука, чтобы её ронять на таких мелочах. Под ронять я имею ввиду совсем ронять. Не ошибку кинуть, а просто тупо убивает процесс.
Ну да, на дворе 2021 год. Писать ../../../../file/file.txt я не буду. Отказываться от tsx я тоже не буду.
Ну, tsx должен работать, потому что он не противоречит стандарту импортов никак (ergo, если в каком-то решении не работает — это да, такое себе решение). А вот насчет относительных импортов в 2021 году я бы поспорил: у меня все импорты пишет и рефакторит IDE, руками я "../../.." никогда даже и в прошлом не писал, а уж сейчас и тем более не намерен. Зато вот всяких import * from 'banana', после которых оказывается, что заимпортировалось 100500 сущностей, из которых отношения к бананам имеет штуки две — я навидался до зубовного скрипа.
А еще я в 2021 году могу просто подвинуть папку в проекте на один уровень вверх или вниз, когда мне код становится надо поудобнее разложить. И никакие импорты от этого не пострадают (IDE их отлично поменяет без моего участия). И три-шейкинг от сторонних магических инструментов мне не нужен, просто потому, что в моем коде ничего лишнего никуда не импортировано, а следить за этим хватает и линтера.
Но вы правы, это тема для другой дискуссии.
ergo, если в каком-то решении не работает — это да, такое себе решение
Все решения у которых отвалился резолвинг — не смогли даже в tsx. Все остальные просто переиспользовали вышестоящий резолвинг (чаще всего это подключение в виде loader-а).
я бы поспорил
Т.е. проблемы с code review и git blame вас ни разу не смущают? :)
btw у меня к vsCode большие вопросы по поддержке рефакторинга и вообще стабильности работы с TS. И даже с git. Возможно vsCode отстой, я не знаю
Т.е. проблемы с code review и git blame вас ни разу не смущают? :)
А какие проблемы? Кто что откуда тянет в код — я вижу в коде, а не в импортах. На сами импорты смотреть на ревью — такая себе идея. В крайнем случае можно посмотреть в импорты для уточнений, или что, кому-то мешают ../../.. при чтении?
btw у меня к vsCode большие вопросы по поддержке рефакторинга и вообще стабильности работы с TS. И даже с git. Возможно vsCode отстой, я не знаю
Сколько не пользуюсь — не видел никаких проблем. Возможно, у меня не было такого количества TSa. Но проекты со сложными типами на пару мегабайт собственной минифицированной сборки без сторонних зависимостей — были, VS Code работал там всё так же отлично, разве что в отдельных случаях intellisense мог ощутимо подтормаживать, потому что подтормаживал сам TS, крутящийся в language server.
Для гита я её никогда не использую, но не потому, что нестабильно, а потому, что есть более удобные средства.
А какие проблемы?
Огромное количество визуального мусора в diff-ах. Как задетых файлов, так лишних строк в них. Особенно при рефакторинге чего-то сильно обобщённого. Перенёс функцию в другой файл — привет 300 левых файлов в MR. Вам правда это нравится? Gitlab вообще скроет вам половину изменений, т.к. они превысили лимит того, что он может показать единоразово. А если MR сложный и нужно бегать между файлами глазами туда сюда… Не, я решительно не понимаю как кому-нибудь может нравиться когда переименовывание и перенос файлов устраивает из MR атомную войну. Разве что если делать code review по принципу "long read = no read => approve" :)
В git blame и прочих манипуляциях с историей тоже большое счастье видеть что половина коммитов тупо мусор. А merge conflict-ы… Ужас.
На сами импорты смотреть на ревью — такая себе идея
Глаза выколоть? :) Мы, кстати, несмотря на инструмент сортировки импортов смотрим их на code-review. Человек легко может подключить не то, что хотел. Или залезть глубже, чем следует. Или организовать reexport-ы ногами не правильно.
Мне кажется ../../../ это каменный век. Нам повезло что import-ы и export-ы к нам пришли поздно и сразу в удобном виде, а не как это в большинстве языков работает. С ними же пришли и алиасы. Избегать их из-за сложности с тулингом — мне вас не понять.
Сколько не пользуюсь — не видел никаких проблем.
У меня две любимых функции в vsCode — reload window и restart TS server. И целые бубны как реанимировать GIT после частичного stage-инга. Откровенно говоря там тонны багов. Не знаю, как вы их не замечаете.
Не, я решительно не понимаю как кому-нибудь может нравиться когда переименовывание и перенос файлов устраивает из MR атомную войну.
Я не вижу ни малейшей причины, по которой переименование/перенос файла не может быть атомарным коммитом. Более того, это один из легчайших атомарных коммитов, которые можно сделать. Точно так же атомарно это идёт в PR/MR.
В git blame и прочих манипуляциях с историей тоже большое счастье видеть что половина коммитов тупо мусор. А merge conflict-ы… Ужас.
Но с любой особой уличной системой импортов (на алиасах, сборных реэкспортах, или еще на чем) вы меняете организационные сложности на сложности функционирования кода, когда импорт файлика на одном конце кодовой базы вдруг разносит весь проект в щепки с другого конца, и надо догадаться, что же пошло не так во всех этих алиасах, реэкспортах, и прочем. Ах ну да, это конечно же в гит не пойдет, потому что еще при сборке умрёт. Наверное это круто.
Но все же на мой взгляд вопросы работы (и даже билда) кода — они всё же сильно важнее вопросов построчного сравнения текстовых файлов (git diff). И если вы принимаете те или иные решения по разработке кода только для того, чтоб у вас файлики исходников "красиво" сравнивались — это чёт вообще ой.
У меня две любимых функции в vsCode — reload window и restart TS server.
У меня первая очень любимая (просто потому, что очень много вещей "передернуть" в VS Code можно только ей, но да и работает она мгновенно), а вот второй вообще ни разу в жизни не пользовался.
Я не вижу ни малейшей причины, по которой переименование/перенос файла не может быть атомарным коммитом.
- MR проще проводить не покоммитно, а цельно. А то вы ревьювите то, что изменено и\или исправлено в последующих коммитах. Особенно когда там несколько итераций
- Это просто тупо неудобно. У вас задето 10 файлов, в них есть ряд изменений. Вам потребовалось переименовать один файл. Что делать? Всё стешить? Или выборочно коммитить? Допустим второе — теперь много ручной работы. А потом она же на MR
В общем я регулярно сталкиваюсь с чем-то подобным когда в feature-ветку, живущую больше 5 дней, merge-ится главная ветка, куда контрибьютили ещё 5 человек. Возникает коммит-смерти, который ревьювить бесполезно и бессмысленно. Но теперь нельзя посмотреть diff с предыдущего просмотра. И приходится смотреть покоммитно выборочно. Писать свои issue к коду и потом их удалять, т.к. они уже не актуальны.
А вы предлагаете так страдать не только при merge-ах, а даже при переименовываниях?
и надо догадаться, что же пошло не так во всех этих алиасах, реэкспортах, и прочем
Для этого не нужен PhD.
Наверное это круто.
Да.
И если вы принимаете те или иные решения по разработке кода только для того, чтоб у вас файлики исходников "красиво" сравнивались — это чёт вообще ой.
Это не "ой". Это правильная архитектура и забота о деньгах бизнеса. Это экономия кучи денег работодателя и упрощение работы коллег. DX. Далеко не пустой звук. И речь не про красиво, а про результат. Если DX на хорошем уровне то у вас меньше багов, меньше технического долга, короче сроки разработки, меньше когнитивная нагрузка на разработчиков, больше удовольствия от работы и т.д…
но да и работает она мгновенно
У меня TS и eslint оттупляется за минуты полторы.
а вот второй вообще ни разу в жизни не пользовался.
Вероятно мы используем разные подмножества TS. У нас бывают зверские сложные типы. И нам не хватает возможностей TS. Каждый серьёзный релиз TS за счастье.
А ещё мы линтим TS по-хардкору (линт правила с учётом типов). И пишем свои линт правила
А вы предлагаете так страдать не только при merge-ах, а даже при переименовываниях?
Я вообще не понял, почему у вас тут "даже". У вас в проекте переименовывания и переносы файлов идут чаще мержей? Серьезно??
Для этого не нужен PhD.
Зависит от того, сколько и каких у вас импортов. При должном рвении легко сделать так, что у вас проект перестанет собираться, но по сообщениям об ошибках вы хрен догадаетесь, где на самом деле проблема. Я лично видел примеры такого рвения.
Это правильная архитектура и забота о деньгах бизнеса.
Лично мне видится скорее классическое "создать самому себе проблемы, а потом мужественно их преодолевать". Когда мержи в проекте начинают представлять собой неиллюзорную проблему — стоит заняться скоупом проекта. Например, поделить его на более мелкие части.
С TS, собственно, у вас та же история. Если постоянно стремиться к тому, чтоб порвать TS — он у вас таки порвётся. Можно работать с небольшими частями, а можно запилить огромный проект, где типы сплошь выводятся друг из друга, а потом перезапускать langserver, да еще и по полторы минуты.
Проекты, которые грузят IDE минут на 20 на холодном старте — я проходил еще во времена, когда на Яве писал. И понял еще тогда, что ничего хорошего в этом нет.
У вас в проекте переименовывания и переносы файлов идут чаще мержей?
В большинстве случаев у нас быстроживущие ветки и merge-ы в feature ветку либо не нужны (ибо нет конфликтов), либо очень компактные. Хотя бывает и прорывает.
Зависит от того, сколько и каких у вас импортов.
Ну обычно нет какого-то резона делать что-то необычайно сложного. Просто иметь возможность обратиться к ближайшему reexport-зонтику от корня. Можно даже просто через ~/. Поэтому PhD не нужен.
Я лично видел примеры такого рвения.
Думаю они не релевантны к нашему разговору :) С дуру можно много что поломать. Но зачем?
Когда мержи в проекте начинают представлять собой неиллюзорную проблему
Ну вот в вашем случае они создают. В нашем — нет. Ведь у нас есть alias от корня и мы можем использовать webpack-loader-ы.
Например, поделить его на более мелкие части.
И это прекрасно, когда я могу делить проект на сколько угодно мелкие части какой угодно вложенности. А не как в примере про MAM. И заметьте я могу переименовывать файлы, дробить их, выносить в поддиректории, много чего делать и… Это никак не скажется на незатронутых файлах. Никакие ../../ нигде не сломаются. Все иморты от "корня до зонтиков" останутся на месте. Файлы не тронуты. Все счастливы.
Я не знаю что вы мне хотите доказать. Я проходил через ../. И проходил с алиасами и лоадерами. Не вижу решительно никакого смысла возвращаться к ../. Я не луддит.
Нам повезло что import-ы и export-ы к нам пришли поздно и сразу в удобном виде, а не как это в большинстве языков работает.
В большинстве языков используются неймспейсы, с ними никакие импорты и не нужны.
А как это работает с standalone функциями? Я namespace-ы видел только в PHP. И то это было давно и я с трудом помню как они там работают.
Скажем есть у меня код:
export const sum = (a: number, b: number): number => a + b;
//
import { sum } from '~/some`;Как оно будет выглядеть в языке с namespace-ми?
const /math/sum = (a: number, b: number): number => a + b;
//
use /math/{sum}
sum(1,2);так?
Ну вот пример на том же TS:
namespace math {
export const sum = (a: number, b: number): number => a + b;
}namespace main {
const sum = math.sum
sum(1, 2 )
}namespace main {
const m = math
n.sum(1, 2 )
}Понятно, спасибо за пример. Т.е. это не противовес import/export-ам, а дополнение. В принципе да, удобно когда нет зависимости от имён файлов от слова совсем. Правда получается та же пляска что и с d.ts файлами. Нужно прочитать весь проект. И линтерам, и IDE, и всем-всем-всем тулам, где есть какой-то анализ. Плюс стоит вопрос порядка подключения.
Именно противовес. Неймспейсы обычно мапятся на ФС. Конкретно для JS/TS нужен только сборщик, умеющий подключать файлы по факту использования неймспейса. Например, MAM.
О. Любопытная статья. Спасибо. Вот откуда в $mol $все_эти_ужасные_названия. Пожалуй в таком виде namespace-ы мне даром не сдались.
Я придерживаюсь противоположных взглядов буквально с каждым вторым доводом в вашей статье. Особенно с тем, что вы трактуете в позитивном ключе. Соглашусь только с тем что у импортов и реэкспортов и правда есть проблемы.
пользователь увидит NaN
Благо, если NaN только в интерфейсе отобразится, а не пойдет дальше под капотом ломать инварианты и шатать бизнес-логику, суля занимательными часами/днями отладки в поисках причины сломанных данных в системе.
А в случае сильной типизации случится рантайм ошибка и сломается вообще всё.
Скорее отлавливаемое исключение (или аналогичная технология обработки ошибок), позволяющее корректно себя обработать или хотя бы показать милое сообщение об ошибке и отправить лог разработчику. Если восстановление работы возможно (и имеет смысл) или затронута лишь незначительная часть приложения/сайта, никто не мешает продолжить работу. Вместо NaN можно написать что-то более осмысленное, например.
не пойдет дальше под капотом ломать инварианты и шатать бизнес-логику
речь про UI, какая там бизнес логика?
хотя бы показать милое сообщение об ошибке и отправить лог разработчику
Тоже можно, в декстопных приложениях так и поступают. Там же и видно как это реализуется на практике – приложение закрывается целиком, предлагая отправить сообщение об ошибке.
речь про UI, какая там бизнес логика?
У нас тут за окошком 2к21 с SPA и прочими serverless во фронтенде.
Там же и видно как это реализуется на практике – приложение закрывается целиком, предлагая отправить сообщение об ошибке.
Вот бы все браузеры падали с сообщением об ошибке, когда пользователь ошибся в домене)
У нас тут за окошком 2к21 с SPA и прочими serverless во фронтенде.
Это никак не отменяет необходимость валидации данных между сервером и клиентом. А что там в браузере в локальном стейте поломалось – не так важно, потому что лечится обновлением страницы. Всякие сложные штуки вроде google docs в расчет не берём, это совсем другая лига
Вот бы все браузеры падали с сообщением об ошибке, когда пользователь ошибся в домене)
От пользователя всегда приходит строка, ошибся он или нет. Тут скорее речь про всякие "Access violation reading location", которые переодически возникают.
Это никак не отменяет необходимость валидации данных между сервером и клиентом.
Это был лишь один пример. Контракты могут быть разломаны локально, проявляться в более хитрых случаях и все так же далеко уплывать, пользуясь «преимуществом» слабой типизации.
Всякие сложные штуки вроде google docs в расчет не берём, это совсем другая лига
Веб развивается, клиенты все жирнее. Поэтому игнорировать эту проблему чревато. Собственно, здесь и обсуждается WASM, как способ использовать более надежные технологии.
речь про всякие «Access violation reading location», которые переодически возникают.
Если считать это обращением к невалидному/нулевому указателю, то в подобном случае и выполнение JS-скрипта так же отпадает.
Непонятно, к чему вы клоните. Представим, завтра в Javascript вводят флаг "use super strict" и типизация становится строгой, как в Python. Как вы думаете, что это нам принесет?
- Больше качественно работающих вебсайтов
- Или больше вебсайтов, показывающих белый экран
А так — да, это позволило бы повысить качество.
Сейчас есть какой-то статус-кво. Вопрос в том, кому будет полезно его изменение в более строгую форму? Что это даст?
Какие бы конкретно костыли пропали, если бы сложение массива и строки (или еще чего-то) начало выбрасывать TypeError?
Угу. Разработка в стиле "как на войне", когда ты никогда не уверен в том, что приложение хотя бы частично работает как нужно. Когда после каждого релиза так и просится regression test. Когда страшно заниматься хоть сколько-нибудь серьёзным рефакторингом большого приложения, потому что нет уверенности вот прямо ни в чём.
Фреймворки, наконец, научатся показывать не белый экран в случае падения одного компонента, а лишь сообщение об ошибке в этом компоненте. Пока что так лишь $mol делает.
А что такое по вашему "бизнесс логика"?
Вся проблема вашего подхода в том, что если формат ответа поменялся, а ваше приложение продолжает работать — оно продолжает работать некорректно и неизвестно, что именно оно теперь делает. Показывает NaN в калькуляторе? Портит пользовательские данные? Вы не знаете! Более того — вы даже не знаете о самом факте поломки, поэтому не можете починить ее быстро, а узнаете о проблеме уже от конкретных пользователей.
Такой подход, когда система продолжает работу во что бы то ни стало, называется Garbage in, garbage out. Противоположный ему подход, который применяют во всех системах, где хоть немного дорожат хранимыми данными — Fail fast.
wasm-код работает в песочнице, для взаимодействия с апи браузера и DOM-ом надо выходить наружу через маршалинг/интероп и вот все это. Если злоупотреблять такими вызовами — скорость падает до уровня обычного js, если нет, то есть буст.
Если логика максимально долго работает без интеропа с апи браузера (webgl сюда же относится), то получается хороший буст. По поводу webgl — работа с гпу подразумевает редкие вызовы с большим объемом данных, так что падение не должно быть значительным.
Вот пример ускорения: https://habr.com/ru/company/skillbox/blog/452190/
Вот не совсем удачный пример ускорения: https://habr.com/ru/company/yandex/blog/475382/
Вот про DOM: https://habr.com/ru/post/347804/
П.С.: Я понимаю, что WASM для другого, но есть более насущные проблемы.
Интерфейс Slack может просто летать но у разработчиков просто руки не от туда ростут… увы толковых frontend девелоперов очень мало. Ну и оишибится с выбором технологии легко, а потом уже размер не будет давать вам все переписать.
Если нет, то такой юзкейс всегда будет тормозить :(
Для таких вещей используется Virtual Scrolling. Он, вероятно, работает несколько иначе, нежели RecyclerView, но тоже без проблем обеспечивают молниеносную производительность. Нет нужды рисовать тысячи комментариев одновременно. Но это не часть DOM, это уже самописные решения. Со своими недостатками, разумеется. Но оно и правда работает молниеносно.
Программы вроде Slack тормозят не из-за DOM, а из-за архитектурных проколов, спешки при разработке, неправильно выставленных приоритетов и т.д… Т.е. аналогичная команда с аналогичными установками в ТЗ на другом языке создаст плюс-минус аналогичный продукт. Что там будет использоваться под капотом дело десятое. Воткнут O(n^2) где хватило бы O(n). Не станут кешировать что-нибудь ресурсоёмкое. Не поставят в параллель что-то, что можно поставить в параллель. Ну и т.д..
Я провёл ряд собеседований на дожность Senior Frontend Developer. Удручающее зрелище. Знаний в области computer science обычно даже зачаточных нет. Понимания используемых технологий тоже. Многие даже своего языка толком не знают.
Впрочем, насколько я могу судить по своим коллегам с других отделов, подобная петрушка творится и в ObjectiveC/Swift/Kotlin. Ребята жалуются что кандидаты не знают элементарных вещей. Имея 5-7+ лет опыта за плечами.
Я для себя сделал вывод что тормозящие фронтенды (любые, включая мобильные) это проблема приоритетов при разработке. А разработка отталкивается от потребностей и пожеланий клиентов. Видимо overall потребители готовы мириться с тормозами, а значит на этом можно сэкономить бюджет.
После приема на работу я какое то время наблюдаю за теми кого одобрил и выводы получились очень неоднозначные.
Были такие люди, которые очень хорошо подкованы в computer science и умели здраво рассуждать, а алгоритмические задачки решали еще до того, как ты успевал рассказать задачу, но при этом локализацию кнопки правили две недели.
С другой стороны были вчерашние фотографы, которые приходили на позицию junior developer и закрывали по 6-7 багов в день, причем качество кода было приемлемое.
Самый необычный кейс. Пришел на собеседование парень, очень сильно разволновался, почти ни на что не ответил. Соответственно получил меньше, чем ожидал, но согласился работать в компании. Когда вышел на работу, оказалось, что один из лучших инженеров в компании.
Таких разных кейсов было несколько десятков.
Исходя из этого, я сделал выводы, что подбор кадров это очень тонкое искусство, нельзя спросить у человека пару алгоритмов, пару типичных задачек и поговорить о какой то теории и сделать вывод плохой или хороший он инженер.
Количество лет опыта не имеет никакого значения.
Навык проходить собеседования и навык работать, это две разные вещи. Кандидатов нужно подбирать под задачи, которые он будет решать и иметь к каждому человеку свой подход.
Регулярно вижу ругающихся на Slack, при этом я тоже им пользуюсь и проблем не замечаю. Работает отзывчиво, что бы ни запускалось в фоне, неважно сколько приложений, или тяжелой сборки проекта.
Может тут что-то не со слаком как таковым, а с настройками воркспейса? Может, админы слишком много плагинов/ботов наподключали?
Ускорить веб на клиентской стороне принципиально можно разве что отказавшись от DOM и зажав разработчиков в некие другие рамки, где им будет сложнее реализовать интерфейс через задницу.
По этому пути идет flutter, но этот путь имеет и обратную сторону в виде на совсем нативного поведения GUI. Что заметно где-то на уровне «зловещей долины» и потому раздражает.
Нифига не ясно как такие сайты потом отлаживать, текущий стек веб-технологий сильно зависим от удобных средств отладки и дебага что так же эволюционировало годами.
ИМХО отладка компилируемого кода веб-приложения это будет больно
JS сейчас тоже весь компилированный через webpack и babel. Символы (sourcemap-в) цепляются — и погнали. А бинарный код изумительно дебажится. Еще в turbo под DOS дебаггер работал, как бы не лучше чем сейчас в хроме — там постоянно что-нибудь с source maps глючит.
Символы (sourcemap-в) цепляются — и погнали
Регулярно включаю\выключаю sourceMap для JS в devTools. Просто потому что дебаг реального кода и того что там на транспайлилось\засорсмапилось это очень разный debugging. Особенно если во время остановок пользоваться консолью. Полагаю в случае WA всё на порядок хуже.
Ну а что вы хотели от поделки, которую придумали фронтендеры? https://t.me/dev_browser/462
WebAssembly в виде Blazor хороша тем, что можно вообще не отлаживать WebAssembly (ну до определенного уровня разумеется) — пишется server-side Blazor приложение и отлаживается чистый нормальный C# в Visual Studio. Да и удаленныый отладчик для реальных WebAssembly скоро завезут.
Ну и чтоб два раза не вставать — тут все говорят про ускорение и вычислительные задачи. Это близко не то, для чего в основном оно будет использоваться. А использоваться оно будет для корпоративных приложений. Есть числодробилка, она конечно и близко не JS. Надо к ней морду. Можно конечно держать отдел фронтэндеров, но зачем если софтиной будет пользоваться человек 10 (но приносить миллионы прибыли), когда можно по быстрому пару формочек написать на том-же шарпе и в прод. А когда надо что-то подправить — опять-же не вылезая из основного языка можно все сделать. Скучно, да. Не cutting edge. Но кровавый энтерпрайз — он такой. Там крутизна и cutting edge в другом.
По сравнению с отладчиком того-же шарпа для JS… просто ничего нет!
Не холивара ради, а в чём именно заключается разница? Никогда не дебажил C#.
Имею такой же опыт. Один и тот же код написанный на C, в случае WA на моей задаче работает в 10 раз медленнее, чем будучи запущенным как обычный бинарник. Не важно с -03 или без. И это код БЕЗ моста с JS-миром. Т.е. чистая числодробилка почему-то тормозит аж десятикратно. Видимо это целое искусство — добиться от WA большой скорости.
Вот кстати да. Писал не так давно компилятор некоего DSL в WASM с целью ускорения — предыдущая версия была в J'S — был неприятно удивлен производительностью именно WASM-машины как таковой. Оно просто тупо медленно, хотя казалось бы. Видимо, человеко-столетия, вложенные в оптимизацию как JS-движков, так и нативных тулчейнов, просто так не догнать...
И потом сам по себе webassembly всё равно без js не работает. Ну даже предположи что было бы всё хорошо и взлетело как flash. Получили бы не контролируемый рост потребления использования ресурсов. Дальше ввод всяких заплаток для ограничения майнинга в браузере и т.п. С другой стороны вот нафига например той же apple полноценная виртуальная машина которая позволяет выполнять приложения в обход их политики тотального контроля.
Так что светлого будущего у wasm скорее всего не будет.
у даже предположи что было бы всё хорошо и взлетело как flash. Получили бы не контролируемый рост потребления использования ресурсов. Дальше ввод всяких заплаток для ограничения майнинга в браузере и т.п.
А чем принципиально отличается JS от WASM в данном случае?
Какие выводы мы можем сделать из этих испытаний? А вот какие: вдумчивое написание JS-кода позволяет получать достаточно высокую производительность и не требует перехода на другие языки программирования.
Wasm или не Wasm?
— https://habr.com/ru/company/ruvds/blog/510904/
Правильный дизайн был бы опустить все API браузера на этот уровень и js тоже компилить в него. Вот тогда — да.
А так — полубесполезная игрушка.
Как автор компилятора, который может перегонять байт-код JVM в WASM могу вставить свои 5 копеек.
Нет доступа к стеку. Делали так из благих побуждений — безопасность и простота реализации виртуальной машины. На деле, в C++ вполне обычная ситуация, когда надо вызвать функцию, передав ей указатель на локальную переменную. Честно говоря, что генерируют компиляторы C++ в Wasm, я не смотрел. Да и в Java так делать нельзя. Зато в Java есть GC, у которого roots находятся в стеке. Как я это обошёл? Завёл shadow stack прямо в хипе. Да, я придумал хитрый алгоритм, который вычисляет для каждого call site минимальный объём обновлений shadow stack. Но всё равно это медленно.
Нельзя поиграться с memory protection. Есть очень много сценариев использования оного. Самый простой — проверка указателей на null. В реализациях C++ или Java здорового человека принято первую страницу делать недоступной и поэтому при попытке записать или прочитать по адресу 0, CPU бросает исключение, которое можно поймать в виде, например, сигнала unix. В Wasm такие трюки не работают и приходится просто перед каждым dereference (например, чтением поля объекта) вставлять проверку. Кстати, т.к. доступа к стеку нет, то приходится в shadow stack маркировать любой такой доступ, чтобы при выбросе исключения правильно воссоздать stack frame.
Казалось бы, нам обещают GC и exception handling в будущих версиях. Но вот я, честно говоря, слабо верю в то, что какая-то прибитая гвоздями спецификация GC сможет учесть разнообразие поведения разных VM в различных экзотических ситуациях, например, с разнообразными weak reference.
Ещё одна претензия к черновику GC: приходится дублировать заголовок. Для нужд GC в Wasm необходимо объявлять типы данных и при аллокации объекта (tuple) в управляемом хипе указывается этот тип. Понятное дело, что физически при этом какое-то количество байт будет отведено на указатель на тип данных. Далее, чтобы реализовать виртуальные вызовы, мне так же надо в объекте хранить указатель на virtual table. Получается, у меня двойной заголовок объекта, потребляющий в два раза больше памяти. Это в то время, как у нормальных людей заголовок объекта сразу и vtable описывает и layout объекта для GC.
Отсутствует вообще какая-либо стандартная библиотека или хотя бы набор инструкций для некоторых важных операций, вроде копирования участка памяти, обнуления участка памяти, работы с плавающими числами (например, какой-нибудь isNaN) и т.д.
Какой-то очень мутный застрявший процесс. Вот вышла несколько лет назад спека 1.0 и дальше комитет только заседает и заседает, генерирует какие-то кривые черновики, а воз и ныне там. Похоже на ситуацию с застрявшей спекой XHTML в своё время.
Ну и хотел бы так же добавить, что в итоге идея "скомпилировать байт-код в JS", хотя и кажется людям, далёким от всей этой кухни, каким-то ужасным хаком, на деле оказывается гораздо более жизнеспособной, чем компиляция в Wasm.
Нет доступа к стеку.
Честно говоря, что генерируют компиляторы C++ в Wasm, я не смотрел.
- В тех примерах, что я смотрел, компиляторы C++ стараются избегать передачи через стек, используя locals
- Если все-таки стек нужен, то считается, что указатель на вершину стека хранится по смещению 4 в памяти
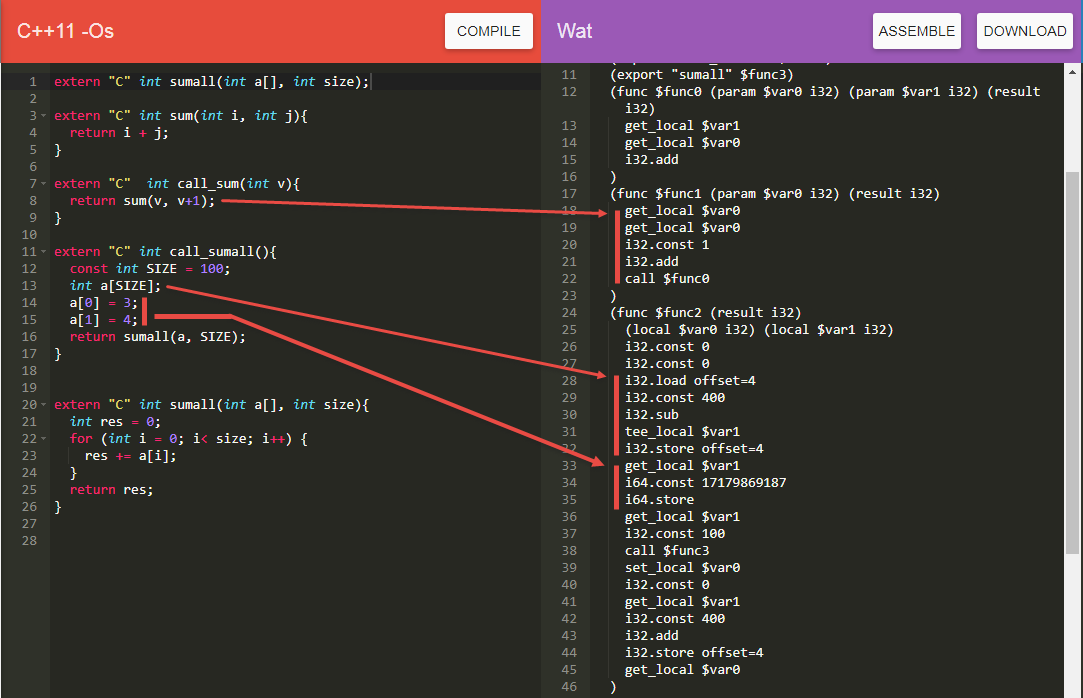
Online-компилятор тут. Вроде бы там есть возможность ссылку на код создать, но не понял, как, так что:
extern "C" int sumall(int a[], int size);
extern "C" int sum(int i, int j){
return i + j;
}
extern "C" int call_sum(int v){
return sum(v, v+1);
}
extern "C" int call_sumall(){
const int SIZE = 100;
int a[SIZE];
a[0] = 3;
a[1] = 4;
return sumall(a, SIZE);
}
extern "C" int sumall(int a[], int size){
int res = 0;
for (int i = 0; i< size; i++) {
res += a[i];
}
return res;
}В тех примерах, что я смотрел, компиляторы C++ стараются избегать передачи через стек, используя locals
Так это и возможно сделать только если параметр передаётся в виде value. А если в виде ссылки, то единственный сценарий, когда, КМК, это можно оптимизировать — если компилятор решил заинлайнить функцию. Во всех иных ситуациях если вы явно попросите у C++ передать указатель или ссылку на переменную в стеке, то он и передаст указатель или ссылку соответственно. Это не особо возможно оптимизировать.
Если все-таки стек нужен, то считается, что указатель на вершину стека хранится по смещению 4 в памяти
Что по сути и есть тот самый медленный shadow stack взамен быстрого нативного.
У нас на проекте одна из основных причин, по которой не используется wasm — поддержка IE
Самая большая проблема, на мой взгляд, это отсутствие поддержки Garbage Collection, что делает бессмыссленным переход многих популярных языков, которые уже умеют транслироваться в эффективный JavaScript. А это огромные кодовые базы Typescript, Java, Scala, Kotlin, Elm…
Возиться с указателями в стиле си, или переучиваться на Rust чтобы писать под веб — это такое себе.
Мне кажется сейчас основная проблема WASM это необходимость тянуть рантайм в браузер, точнее его вес, что делает загрузку страницы слишком долгой для продакшена. Плюс необкатанность технологии, которая ставит крест на выборе в пользу WASM на серьезном проекте.
А вот для создания админок технология выглядит очень даже интересно.
У меня аж Флеш плеер потёк из браузера. Крайне он специфичный. Поживём увидим, что будет с WASM
Так что тут надо скорее придумывать песочницы для мессенджеров и приложения для них же, ну и в разработку стандартов для ботов вкладываться, если вы действительно смотрите в будущее.
WASM идеально ложится в стек веб-разработки на Rust. Обе эти технологии положительно связаны друг с другом.
Что я только что прочитал? «Смотрите, технология для решения узкоспециализированных задач. Давайте разберемся, что с ней не так, что она не получила широкого распространения»
Ну если совсем по теме, то для половины задач из приведенного списка нужен SIMD. Если кто-то хорошо знает WASM, подскажите, в каком состоянии SIMD в нём сейчас? Нужна ли поддержка браузеров, есть ли уже где-то?
WASM нужен для двух вещей. первая — единая кодовая база. я не хочу создавать по 10 алгоритмов на C#, потом на JS, и при изменении какогото из них по пол дня тестировать работают ли они одинаково. WASM позволяет мне писать на C# вобще всё и не заморачиваться с тем как и где оно работает. в больших проектах это очень важно и позволяет избежать лишних специалистов по фронт-енду например. про производительность не знаю, насколько ли это важно — если тензорфлоу сделали значит наверно да, это вторая причина
Так если не важно про производительность, вы можете прямо сейчас компилировать c# с js, и это будет работать надежнее, чем WASM.
подскажите пожалуйста, что это за решение? очень интересно
Я год назад писал статью
Что не так с WebAssembly?