
Несмотря на свою кажущуюся банальность, темы о вычислении синуса достаточно регулярно появляются на хабре. И каждый раз их авторы или делают сомнительные утверждения, или получают сомнительные результаты. Не в силах более терпеть, я тоже решил поучаствовать и внести свой, не менее сомнительный вклад в этот вопрос.
▍ Введение
Существуют три основных подхода к аппроксимации функций многочленами:
1. Разложение в ряд Тейлора:
Наиболее простой, наиболее известный (потому что его проходят в школе) и наименее эффективный. По сути представляют собой аппроксимацию через конечное количество производных в отдельно взятой точке, откуда и следуют его недостатки — ошибка аппроксимации возрастает по мере удаления от этой точки, далеко не для всех функций быстро сходится, для некоторых функций не сходится вообще, для некоторых функций в некоторых точках не применим вообще.
2. Метод наименьших квадратов:
Чуть менее известный, более сложный, но и более эффективный. Его идея заключается в минимизации площади между функцией и её аппроксимирующим многочленом. Недостатком является тот факт, что из минимизации площади вовсе не следует минимизация максимальных отклонений — поэтому ошибка аппроксимации хоть и осциллирует, но всё равно имеет тенденцию возрастать на краях диапазона.
3. Многочлены Чебышева:
Ещё более сложный, наименее известный, но часто наиболее оптимальный метод. Оптимальность его проистекает из того, что ошибка распределена по всему диапазону и ограничение максимального отклонения задаётся by design. Сложность вытекает из того, что сначала нужно считать коэффициенты для каждого отдельного многочлена Чебышева через далеко не простые интегралы даже для простых функций (в частности, для синуса получаются функции Бесселя, которые далеко не в каждом калькуляторе присутствуют), а затем их пересчитывать для суммарного итогового многочлена с запасом по точности. К счастью, имея в своём распоряжении современные системы компьютерной алгебры, всё это можно сделать лёгким движением руки, даже не вникая особо глубоко в математические основы происходящего.
Следует заметить, что этими тремя методы аппроксимации вовсе не ограничиваются — можно и производные считать в нескольких точках, а не только в одной, и другие разложения в степенные ряды применять, и рациональные многочлены использовать (например, аппроксимацию Паде и его вариации), а также различные варианты мини-макс алгоритмов.
▍ Подготовка
Используя Wolfram Mathematica, определим функцию, возвращающую аппроксимирующий многочлен заданного порядка для произвольной функции:
код ChebyshevApproximation для Mathematica
ChebyshevApproximation[n_, f_, x_] := N[Table[Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, -1, 1}], {k, 0, n}], 20] //
#[[1]]/2 + Sum[#[[k+1]] ChebyshevT[k, x], {k, 1, n}] & // SimplifyЗдесь точность полученных коэффициентов равна 20 десятичным знакам — для наших целей этого достаточно. Можно также задать отдельные реализации для чётных/нечётных функций, чтобы ускорить вычисления. Для нечётных функций она будет выглядеть как
код ChebyshevOddApproximation для Mathematica
ChebyshevOddApproximation[n_, f_, x_] := N[Table[2 Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, 0, 1}], {k, 1, n, 2}], 20] //
Sum[#[[((k+1)/2)]] ChebyshevT[k, x], {k, 1, n, 2}] & // Simplifyа для чётных как:
код ChebyshevEvenApproximation для Mathematica
ChebyshevEvenApproximation[n_, f_, x_] := N[Table[2 Integrate[
f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, 0, 1}], {k, 0, n, 2}], 20] //
#[[1]]/2 + Sum[#[[((k+2)/2)]] ChebyshevT[k, x], {k, 2, n, 2}] & //
Simplify
Примечание
В случае, если для выбранной функции аналитическое решение не находится, то можно использовать численное интегрирование, заменив Integrate наNIntegrate. Здесь ситуация осложняется тем, что на границах интервала (-1,1) подынтегральное выражение устремляется в бесконечность — что может потребовать дополнительную настройку параметров интегрирования, прежде всего увеличения точности вычислений и задания исключающих условий для аргумента. Также может потребоваться отбрасывание близких к нулю коэффициентов, являющихся результатом погрешности для чётных/нечётных функций.
код NChebyshevApproximation для Mathematica
NChebyshevApproximation[n_, f_, x_] := N[Simplify[Table[
NIntegrate[f ChebyshevT[k, x] (2/(\[Pi] Sqrt[1-x^2])), {x, -1, 1},
WorkingPrecision ->30, Exclusions->x^2 == 1, MaxRecursion -> 25], {k, 0, n}] //
Map[Sign[#] Max[0, (Abs[#]-10^-20)] &, #] & //
#[[1]]/2 + Sum[#[[k+1]] ChebyshevT[k, x], {k, 1, n}] &], 20]▍ Начало
Наиболее надёжный способ ускорить вычисление синуса — просто уменьшить степень аппроксимирующего многочлена, пожертвовав точностью. При использовании многочленов Чебышева количество верных знаков ориентировочно соответствует степени многочлена
 . Для примера возьмём 7-ю степень — её вполне достаточно для задач визуализации:
. Для примера возьмём 7-ю степень — её вполне достаточно для задач визуализации:
код для Mathematica
f = Sin[x Pi/2];
p7 = ChebyshevApproximation[7, f, x]Получили многочлен:

Реально полученную погрешность можно увидеть, если вывести на график разницу между исходной функцией и этим многочленом:
код для Mathematica
Plot[f - p7 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic}, WorkingPrecision -> 20] // Quiet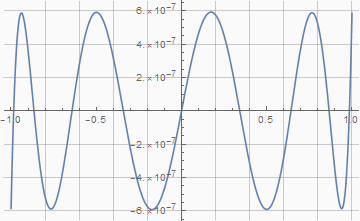
По графику видно, что на краях диапазона погрешность принимает максимальное значение. Это значит, что sin(90°) с таким многочленом будет равен не единице, а 0.999999414195269. Если важно, чтобы была именно единица — то для этого можно пойти на хитрость и немного расширить диапазон аппроксимации таким образом, чтобы отклонение на краях
 стало близким к нулю. Значение этого «немного» (как множитель при аргументе синуса) будем находить итеративно через численный поиск корня ошибки (разницы между функцией и аппроксимирующим многочленом), наиболее близким к единице.
стало близким к нулю. Значение этого «немного» (как множитель при аргументе синуса) будем находить итеративно через численный поиск корня ошибки (разницы между функцией и аппроксимирующим многочленом), наиболее близким к единице.
код для Mathematica
p71 = Block[{z = 1, p},
Do[p = ChebyshevOddApproximation[7, Sin[x Pi/2/z], x] /. x -> x z // Simplify;
z *= (x /. FindRoot[(p-Sin[x Pi/2])==0, {x, 1}]), 5]; p]Результат:

Вот как теперь выглядит график отклонений:
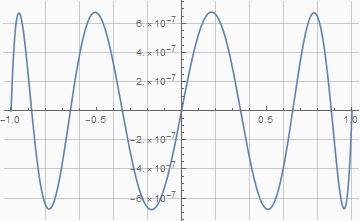
Погрешность неизбежно выросла, но совершенно незначительно.
Чтобы получить полноценную функцию синуса, необходимы вспомогательные манипуляции для приведения аргумента к диапазону
, учёта цикличности и симметрии. Для экспорта полученного многочлена в код нам также пригодятся вспомогательные (уже имеющиеся) функции: HornerForm — для преобразования многочлена к схеме Горнера, и CForm — для преобразования его к виду, традиционно используемого в си-подобных языках программирования.
код экспорта для Mathematica
CForm[HornerForm[p71] /. x^2 -> xx]
Сами функции будут выглядеть так:
Версия для С#
double Sin7(double x)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double xx = x * x;
double y = x * (1.5707903005870776 + xx * (-0.6458858977085938 +
xx*(0.07941798513358536 - 0.0043223880120647346 * xx)));
return sign^per ? -y : y;
}
Версия для С/С++
double Sin7(double x)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
int per = ((xf >> 1) & 1) == 1;
double xx = x * x;
double y = x * (1.5707903005870776 + xx * (-0.6458858977085938 +
xx*(0.07941798513358536 - 0.0043223880120647346 * xx)));
return sign ^ per ? -y : y;
}В версии для C/C++ тип bool заменён на int — как показали измерения, компилятор в этом случае генерирует более эффективный код.
Здесь нужно сделать важное замечание. В целях оптимизации для получения целой части аргумента здесь используется не функция Floor(x), а приведение к целому типу (чтобы избежать вызова внешней библиотечной функции). Это приводит к тому, что аргумент не должен превышать максимальное для int значение, а именно 2147483647. Тип int можно заменить на long (а правильнее — на unsigned long), но в зависимости от платформы и компилятора это также может привести к замедлению кода. На достаточно больших значениях аргумента также возрастает погрешность из-за разности порядков у аргумента и периода
 . Подобные ограничения являются неизбежной расплатой за более быстрый код.
. Подобные ограничения являются неизбежной расплатой за более быстрый код.▍ Продолжение
При увеличении степени многочлена увеличивается количество вычислений и как следствие, накапливается дополнительная погрешность. Поэтому для близкой к double точности разумно разбить диапазон
 на два и для каждого рассчитывать отдельный многочлен. Для левой части будем считать многочлен для
на два и для каждого рассчитывать отдельный многочлен. Для левой части будем считать многочлен для  , а для правой для
, а для правой для  (косинус «переворачивается» для того, чтобы выкинуть постоянную константу, смещающую ошибку к центру, обеспечив таким образом равенство
(косинус «переворачивается» для того, чтобы выкинуть постоянную константу, смещающую ошибку к центру, обеспечив таким образом равенство  ). После получения таким образом многочленов нужно вернуть аргумент к исходному диапазону, пересчитав коэффициенты заменой
). После получения таким образом многочленов нужно вернуть аргумент к исходному диапазону, пересчитав коэффициенты заменой  . Опытным путём было установлено, что для достижения необходимой точности достаточно 13-ой и 12-ой степени (для синуса и косинуса соответственно):
. Опытным путём было установлено, что для достижения необходимой точности достаточно 13-ой и 12-ой степени (для синуса и косинуса соответственно):
код для Mathematica
fs4 = Sin[x Pi/4];
p13 = ChebyshevOddApproximation[13, fs4, x];
fc4 = 1-Cos[x Pi/4];
p12 = ChebyshevEvenApproximation[12, fc4, x];
Row[{CForm[(p13 /. x -> 2 x // HornerForm) /. x^2 -> xx] // Framed,
CForm[(p12 /. x -> 2 x // HornerForm) /. x^2 -> xx] // Framed}]
GraphicsRow[{
Plot[fs4 - p13 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]] // Quiet,
Plot[fc4 - p12 // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]] // Quiet},
ImageSize -> Large, Spacings -> 5]Графики ошибок:

Здесь ошибка для косинуса получилась чуть больше, чем у синуса — но это не имеет значения, потому что они всё равно замаскируются накопленными погрешностями при вычислении многочлена.
Версия для C#
double Sin13(double x)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double y;
if (x <= 0.5)
{
double xx = x * x;
y = x * (1.5707963267948965822 + xx * (-0.6459640975062407217 +
xx * (0.07969262624592800593 + xx * (-0.0046817541307639977752 +
xx * (0.00016044114022967599853 + xx * (-3.5986097146969802712e-6 +
5.629793865626169033e-8 * xx))))));
}
else
{
x = 1.0 - x;
double xx = x * x;
y = 1.0 - xx * (1.2337005501361513498 + xx * (-0.25366950789986513871 +
xx * (0.020863480734953519901 + xx * (-0.0009192599500952791151 +
xx * (0.000025200135454917479526 - 4.6552987291490935821e-7 * xx)))));
}
return sign^per ? -y : y;
}
Версия для C/C++
Такая реализация уже почти соответствует точности большинству библиотечных реализаций, но всё равно уступает им по точности в несколько бит.
double Sin13(double x)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
if ((xf & 1) == 1)
x = 1 - x;
int per = (xf >> 1) & 1;
double y;
if (x <= 0.5)
{
double xx = x * x;
y = x * (1.5707963267948965822 + xx * (-0.6459640975062407217 +
xx * (0.07969262624592800593 + xx * (-0.0046817541307639977752 +
xx * (0.00016044114022967599853 + xx * (-3.5986097146969802712e-6 +
5.629793865626169033e-8 * xx))))));
}
else
{
x = 1.0 - x;
double xx = x * x;
y = 1.0 - xx * (1.2337005501361513498 + xx * (-0.25366950789986513871 +
xx * (0.020863480734953519901 + xx * (-0.0009192599500952791151 +
xx * (0.000025200135454917479526 - 4.6552987291490935821e-7 * xx)))));
}
return sign ^ per ? -y : y;
}Такая реализация уже почти соответствует точности большинству библиотечных реализаций, но всё равно уступает им по точности в несколько бит.
▍ Табличный метод
Наивное представление о табличном методе состоит в том, что в таблице хранятся заранее вычисленные значения для узловых точек, а промежуточные значения получаются интерполяцией между ними. Заранее вычисленные значения действительно имеются, но промежуточные значения вычисляются не интерполяцией, а используя тригонометрические тождества:


где
 и
и  берутся из таблицы, а
берутся из таблицы, а  и
и  вычисляются через многочлены небольшой степени. Это даёт чуть большее предыдущего способа время выполнения, но из которого на вычисление собственно синуса приходится в 2 раза меньше времени.
вычисляются через многочлены небольшой степени. Это даёт чуть большее предыдущего способа время выполнения, но из которого на вычисление собственно синуса приходится в 2 раза меньше времени.Оптимальный размер таблицы n выбирается экспериментально, чтобы разница между функциями
 ,
,  и их аппроксимирующими многочленами выбранной степени не превышала заданной погрешности. Для 5-ой степени достаточно таблицы из 128-и значений, для 3-й потребуется уже 1024.
и их аппроксимирующими многочленами выбранной степени не превышала заданной погрешности. Для 5-ой степени достаточно таблицы из 128-и значений, для 3-й потребуется уже 1024.
код для Mathematica
With[{count = 128, n = 5, m = 6},
fs = Sin[x Pi/2/count];
ps = ChebyshevOddApproximation[n, fs, x];
fc = Cos[x Pi/2/count];
pc = ChebyshevEvenApproximation[m, fc, x];
Row[{CForm[(ps // HornerForm) /. x^2 -> xx] // Framed,
CForm[(pc // HornerForm) /. x^2 -> xx] // Framed}]
GraphicsRow[{
Plot[fs - ps // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 20, Background -> Hue[0.14, 0, 0.98]],
Plot[fc - pc // Evaluate, {x, -1, 1},
GridLines -> {(Range[10] - 5)/5, Automatic},
WorkingPrecision -> 25, Background -> Hue[0.14, 0, 0.98]]
}, ImageSize -> 700, Spacings -> 5] // Quiet
]Графики ошибок для 5-ой (синус) и 6-ой (косинус) степеней:
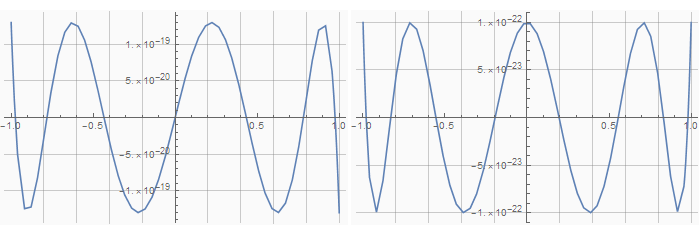
Код для получения таблицы тоже предельно прост:
With[{n = 128}, Table[N[Sin[x Pi/2], 18], {x, 0, 1, 1/n}]]
Результат:
{0, 0.0122715382857199261, 0.024541228522912288, 0.0368072229413588323,
0.0490676743274180143, 0.0613207363022085778, 0.0735645635996674235,
0.0857973123444398905, 0.098017140329560602, 0.110222207293883059,
0.122410675199216198, 0.134580708507126186, 0.146730474455361752,
0.158858143333861442, 0.170961888760301226, 0.183039887955140959,
0.195090322016128268, 0.20711137619221855, 0.219101240156869797,
0.23105810828067112, 0.24298017990326389, 0.254865659604514572,
0.266712757474898386, 0.278519689385053105, 0.290284677254462368,
0.302005949319228067, 0.313681740398891477, 0.325310292162262934,
0.336889853392220051, 0.348418680249434568, 0.359895036534988149,
0.371317193951837543, 0.382683432365089772, 0.393992040061048109,
0.405241314004989871, 0.416429560097637183, 0.427555093430282094,
0.438616238538527638, 0.4496113296546066, 0.460538710958240024,
0.471396736825997649, 0.482183772079122749, 0.492898192229784037,
0.503538383725717559, 0.514102744193221727, 0.524589682678468906,
0.534997619887097211, 0.545324988422046422, 0.555570233019602225,
0.565731810783613197, 0.575808191417845301, 0.58579785745643886,
0.595699304492433343, 0.605511041404325514, 0.615231590580626845,
0.624859488142386377, 0.634393284163645498, 0.643831542889791465,
0.653172842953776764, 0.662415777590171761, 0.671558954847018401,
0.680600997795453051, 0.689540544737066925, 0.698376249408972854,
0.707106781186547524, 0.715730825283818654, 0.724247082951466921,
0.732654271672412835, 0.740951125354959091, 0.749136394523459325,
0.757208846506484548, 0.765167265622458926, 0.773010453362736961,
0.780737228572094478, 0.788346427626606262, 0.795836904608883536,
0.80320753148064491, 0.810457198252594792, 0.817584813151583697,
0.824589302785025264, 0.831469612302545237, 0.838224705554838043,
0.844853565249707073, 0.851355193105265142, 0.85772861000027207,
0.863972856121586738, 0.870086991108711419, 0.876070094195406607,
0.88192126434835503, 0.887639620402853948, 0.89322430119551532,
0.898674465693953843, 0.903989293123443332, 0.909167983090522377,
0.914209755703530655, 0.919113851690057744, 0.923879532511286756,
0.928506080473215566, 0.932992798834738888, 0.937339011912574923,
0.941544065183020778, 0.945607325380521326, 0.949528180593036667,
0.953306040354193837, 0.956940335732208865, 0.960430519415565811,
0.963776065795439867, 0.966976471044852109, 0.970031253194543993,
0.972939952205560145, 0.975702130038528544, 0.978317370719627633,
0.980785280403230449, 0.983105487431216327, 0.985277642388941245,
0.987301418157858382, 0.989176509964780973, 0.990902635427780025,
0.992479534598709998, 0.993906970002356042, 0.995184726672196886,
0.996312612182778013, 0.997290456678690216, 0.998118112900149207,
0.998795456205172393, 0.999322384588349501, 0.99969881869620422,
0.999924701839144541, 1}Значения синуса и косинуса из неё получаются в зависимости от того, индексировать её с начала в конец или наоборот. Стоит уточнить, что здесь по факту размер получается на единицу больше, то есть 129 (из-за замыкающей единицы для
 ). Сам же размер как степень двойки выбран для того, чтобы избежать потери точности при умножении на него аргумента и обеспечить табличную точность в значениях
). Сам же размер как степень двойки выбран для того, чтобы избежать потери точности при умножении на него аргумента и обеспечить табличную точность в значениях  (что может быть полезным в алгоритмах быстрого преобразования Фурье). В случае если аргумент синуса удобнее задавать в других единицах — скажем, в градусах — то размер таблицы разумно делать кратным 90, чтобы получать максимально точные значения при целых значениях аргумента.
(что может быть полезным в алгоритмах быстрого преобразования Фурье). В случае если аргумент синуса удобнее задавать в других единицах — скажем, в градусах — то размер таблицы разумно делать кратным 90, чтобы получать максимально точные значения при целых значениях аргумента.
Версия для C#
double[] sincostable = {...};
void SinCos(double x, out double sina, out double cosa)
{
x *= 0.63661977236758134308; // 2/Pi
bool sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
bool rev = (xf & 1) == 1;
if (rev)
x = 1 - x;
bool per = ((xf >> 1) & 1) == 1;
double z = x * 128;
int zf = (int)z;
z -= zf;
double sint = sincostable[zf];
double cost = sincostable[128 - zf];
double zz = z * z;
double ss = z * (0.012271846303085128928 + zz * (-3.0801968454884792651e-7 +
2.3193461291439683491e-12 * zz));
double cc = 1.0 - zz * (0.000075299105843272081 + zz*(-9.449925567834354484e-10 +
4.7437807891647010749e-15 * zz));
sina = (sign ^ per) ? -sint * cc - cost * ss : sint * cc + cost * ss;
cosa = (rev ^ per) ? sint * ss - cost * cc : cost * cc - sint * ss;
}
Версия для C/C++
const double sincostable[] = {...};
void SinCosByTable(double x, double* sina, double* cosa)
{
x *= 0.63661977236758134308; // 2/Pi
int sign = x < 0.0;
x = sign ? -x : x;
int xf = (int)x;
x -= xf;
int rev = xf & 1;
if (rev)
x = 1 - x;
int per = (xf >> 1) & 1;
double z = x * 128;
int zf = (int)z;
z -= zf;
double sint = sincostable[zf];
double cost = sincostable[128 - zf];
double zz = z * z;
double ss = z * (0.012271846303085128928 + zz * (-3.0801968454884792651e-7 +
2.3193461291439683491e-12 * zz));
double cc = 1.0 - zz * (0.000075299105843272081 + zz * (-9.449925567834354484e-10 +
4.7437807891647010749e-15 * zz));
*sina = (sign ^ per) ? -sint * cc - cost * ss : sint * cc + cost * ss;
*cosa = (rev ^ per) ? sint * ss - cost * cc : cost * cc - sint * ss;
}Табличный метод можно использовать и по-другому — только для синуса, если разбить интервал
 на несколько и хранить в ней коэффициенты аппроксимирующих многочленов небольшой степени для каждого из них по отдельности. Но таким образом не получится сэкономить за счёт чётности/нечётности функций — и для многочлена скажем 5-ой степени придётся хранить и вычислять все 6 коэффициентов — что не даст прироста в производительности, но зато может дать несколько дополнительных бит точности.
на несколько и хранить в ней коэффициенты аппроксимирующих многочленов небольшой степени для каждого из них по отдельности. Но таким образом не получится сэкономить за счёт чётности/нечётности функций — и для многочлена скажем 5-ой степени придётся хранить и вычислять все 6 коэффициентов — что не даст прироста в производительности, но зато может дать несколько дополнительных бит точности.▍ Как тестировать
Когда речь идёт о реализации с меньшей точностью, то можно сравнивать значения с библиотечной реализацией и таким образом считать максимальное отклонение. Однако на точности близкой к double такой подход не прокатит — поскольку библиотечные реализации тоже имеют погрешности. Можно экспортировать значения в Wolfram Mathematica, но это сложнее и имеет свои тонкости, поскольку преобразование числа в формате double к текстовому десятичному виду также может искажать значения младших бит; или же можно экспортировать стороннюю библиотеку с заведомо большей точностью и сравнивать результаты уже в ней. Однако есть и другой путь — считать какую-нибудь функцию, значение которой можно посчитать аналитически, и сравнивать с этим значением полученный результат. У какой реализации будет наименьшее отклонение — та и точнее.
Хорошим кандидатом для этого является функция, суммирующая квадраты синусов с аргументами, равномерно распределённых в диапазоне от
 до
до  . Возведение в квадрат позволяет избежать ситуации, когда положительные отклонения в значениях будут компенсироваться отрицательными. Ну а аналитическим результатом такого суммирования будет не что иное, как
. Возведение в квадрат позволяет избежать ситуации, когда положительные отклонения в значениях будут компенсироваться отрицательными. Ну а аналитическим результатом такого суммирования будет не что иное, как  (сюрприз), то есть:
(сюрприз), то есть:

Примечание
Любители математики могут попробовать доказать эти равенства самостоятельно — я же их получил просто используя функцию FullSimplify в Mathematica.
Также нужно учитывать, что некоторые современные оптимизирующие компиляторы (в частности C++ от Intel и Microsoft) могут распознать сумму и вычислять её в 4 параллельных потоках на регистрах AVX, что при замерах производительности может показать значительное превосходство библиотечных реализаций (да, я столкнулся с этим). Чтобы этого избежать, можно на каждом этапе менять знак (то есть считать функцию
 ), аналитическим результатом которой будет ноль (для
), аналитическим результатом которой будет ноль (для  ). Но такой подход подойдёт только для замера производительности и оценить погрешность по отклонению результата от нуля уже не получится — поскольку будет происходить взаимная компенсация погрешностей.
). Но такой подход подойдёт только для замера производительности и оценить погрешность по отклонению результата от нуля уже не получится — поскольку будет происходить взаимная компенсация погрешностей.Можно рассмотреть и другие сценарии — например, вращать единичный вектор через комплексное умножение, который должен вернуться в исходное состояние, или же выполнять прямое и обратное FFT, и сравнивать полученный результат с исходным — но здесь мы не будем на этом подробно останавливаться, поскольку выбор корректного метода тестирования сильно зависит от конкретной цели использования.
Вариант тестирования для C#
using System;
using System.Diagnostics;
…
using System.Diagnostics;
…
long count = (long)1e9;
Stopwatch sw = new Stopwatch();
double sum, secs;
sum = 0.0;
sw.Restart();
for (long i = -count; i <= count; i++)
{
double x = (double)i * Math.PI / count;
double y = Math.Sin(x);
sum += y * y;
}
secs = sw.ElapsedMilliseconds / 1000.0;
Console.WriteLine("mathsin\t{0}\t{1}", secs, sum - count);
...
// повторить для других реализаций
Вариант тестирования для C/C++
#define _USE_MATH_DEFINES
#include <math.h>
#include <time.h>
...
long n = (long)1e9;
double sum;
double sign;
sum = 0;
sign = 1;
clock_t t = clock();
for (long i = -n; i <= n; i++)
{
double x = (double)i * M_PI / n;
double y = sin(x);
sum += y * y * sign;
sign = -sign;
sign = -sign;
}
t = clock() - t;
std::cout << "mathsin: dur: " << double(t) / CLOCKS_PER_SEC << ", " << sum - n << endl;
...
// повторить для других реализацийВ варианте для C/C++ добавлено немного бесполезных вычислений во избежание автоматической векторизации. Также по-хорошему его можно реализовать на шаблонах, чтобы не дублировать одинаковые куски кода для разных функций.
В обоих случаях время измеряется в секундах с точностью до миллисекунд. Сделано это для того, чтобы привести результаты к общему знаменателю и не зависеть от платформо-зависимых средств и отсутствующем в си std::chrono. Ну и заодно стимулировать выполнять код достаточно долго, чтобы накопилось хотя бы несколько секунд.
▍ Заключение и результаты
При замерах производительности все рассмотренные реализации оказались быстрее библиотечных и на C#, и на C++ с компилятором от Microsoft. На C++ была дополнительно протестирована функция fsincos из математического сопроцессора FPU процессоров x86/x64, которая тоже умеет считать и синус, и косинус одновременно.
Сводная таблица по результатам замеров на Core i7:
| реализация \ ускорение (в разы) | C# (.NET 4.8) | C++ (VS2019) | C++ vs. C# |
| библиотечная | 1 | 1 | 2.8 |
| Sin7 | 6.06 | 2.07 | 1.09 |
| Sin13 | 4.08 | 1.25 | 1.1 |
| SinCos | 2.62 | 1.21 | 1.3 |
| fsincos (FPU) | - | 0.28 | - |
Как обстоят дела с множеством других компиляторов и платформ — это тема отдельного исследования, которым, если честно, заниматься совсем не хочется. Но было бы интересно увидеть результаты от другого независимого источника.
Измерения точности с накоплениями погрешностей также дали вполне ожидаемый результат и на больших
разницы в реализациях не было (за исключением Sin7) — сказывалось накопление погрешностей уже от самого суммирования квадратов. Можно было, конечно, использовать алгоритм суммирования Кэхэна — но это имело бы смысл лишь в том случае, если использовать его и в реальных задачах тоже.Насколько скорость рассмотренных реализаций стоит нескольких дополнительных бит погрешности — каждый решает сам для себя самостоятельно. Однако лично я сам думаю, что если погрешность в несколько последних бит имеет критически важное значение — то точности double тут явно недостаточно и нужно переходить на другие типы данных. Также для увеличения точности вычислений можно использовать специальные техники — но это тема уже для отдельной статьи.

