
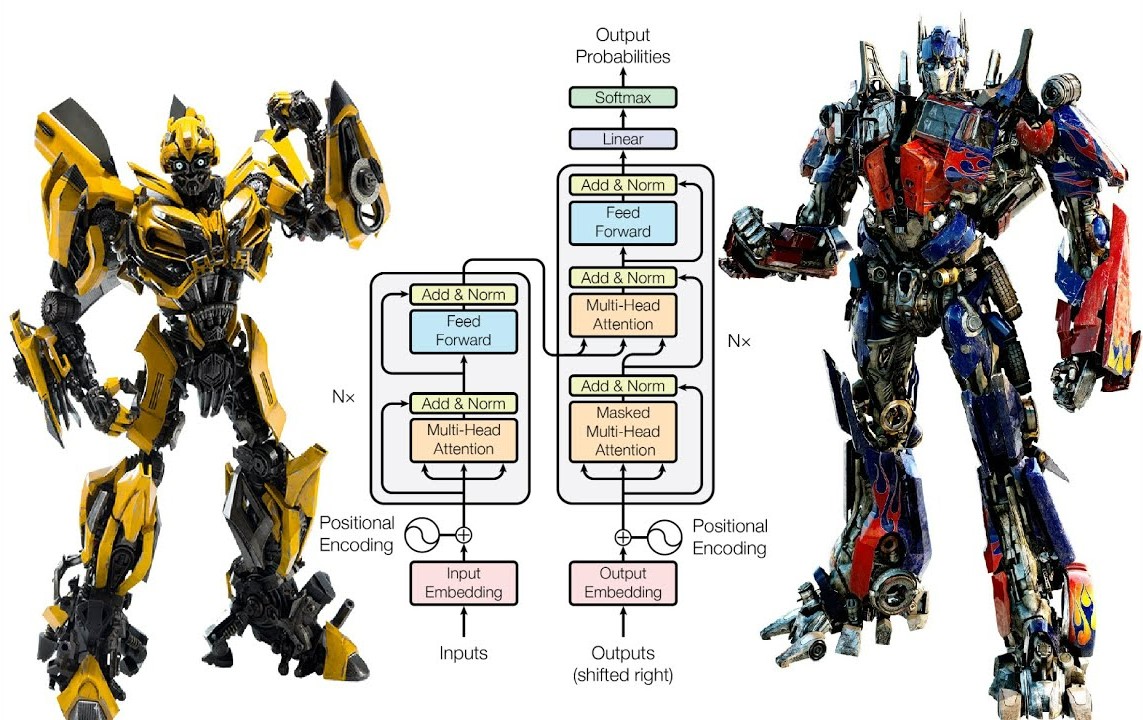
Примечание переводчика: Это вторая часть перевода статьи Attention is all you need, с которой началось развитие больших языковых моделей, в том числе чат-бота ChatGPT. Первую часть можно найти здесь.
▍ 3.5 Позиционное кодирование
Поскольку описываемая модель не содержит рекуррентности или свёрток, для учёта порядка слов в последовательности необходимо дополнительно внести некоторую информацию об относительной и абсолютной позиции элементов в последовательности. Для этого во входную последовательность добавляется вектор позиционного кодирования в конец стеков энкодера и декодера. Этот вектор имеет такую же размерность
 , что и эмбеддинги, поэтому их можно просуммировать. Существует множество решений для получения позиционного вектора: как фиксированные, так и получающиеся в процессе обучения модели [9].
, что и эмбеддинги, поэтому их можно просуммировать. Существует множество решений для получения позиционного вектора: как фиксированные, так и получающиеся в процессе обучения модели [9].В данной работе авторы используют функции синуса и косинуса различной частоты:


Где
 — это позиция, а
— это позиция, а  — измерение. Таким образом, каждое измерение позиционного вектора соответствует синусоиде. Длины волн образуют геометрическую прогрессию от
— измерение. Таким образом, каждое измерение позиционного вектора соответствует синусоиде. Длины волн образуют геометрическую прогрессию от  до
до  . Авторы выбрали эту функцию вследствие предположения, что она позволит модели легко научиться следить за относительными позициями, поскольку для любого фиксированного смещения
. Авторы выбрали эту функцию вследствие предположения, что она позволит модели легко научиться следить за относительными позициями, поскольку для любого фиксированного смещения  ,
,  может быть представлено как линейная функция
может быть представлено как линейная функция  .
.Авторы также провели эксперименты с позиционными векторами, которые получаются в результате обучения [9], и обнаружили, что оба подхода дают почти идентичные результаты (см. таблицу 3, строку (E)). В итоге выбор пал на подход с синусоидой, потому что он позволяет модели работать с более длинными последовательностями, чем те, которые она встречала во время обучения.
4. Почему самовнимание
В этом разделе рассматриваются различные аспекты слоёв самовнимания в сравнении с рекуррентными и свёрточными слоями, обычно используемыми для мэппинга одной последовательности представлений символов переменной длины
 на другую последовательность такой же длины
на другую последовательность такой же длины  , где
, где  , например, в качестве скрытого слоя в типичном энкодере или декодере для задачи преобразования последовательности. Мотивируя использование механизма самовнимания, авторы руководствовались следующими соображениями.
, например, в качестве скрытого слоя в типичном энкодере или декодере для задачи преобразования последовательности. Мотивируя использование механизма самовнимания, авторы руководствовались следующими соображениями.Во-первых, это общая вычислительная сложность на каждом слое. Во-вторых, это объём вычислений, которые можно распараллелить, измеряемый минимальным количеством требуемых последовательных операций.
Наконец, в-третьих, — длина пути между отдалёнными зависимостями в сети. Изучение отдалённых зависимостей является ключевой проблемой во многих задачах преобразования последовательностей. Одним из важнейших факторов, влияющих на возможность выучивания таких зависимостей, является длина путей, которые прямые и обратные сигналы должны пройти в сети. Чем короче эти пути между любой комбинацией позиций во входной и выходной последовательностях, тем легче выучивать отдалённые зависимости [12]. Следовательно, авторы также сравнивают максимальную длину пути между любыми двумя входными и выходными позициями в сетях, состоящих из слоёв разных типов.
| Тип слоя | Сложность (один слой) | Последовательные операции | Максимальная длина пути |
| Самовнимание |  |
 |
|
| Рекуррентный |  |
 |
|
| Свёрточный |  |
|
 |
| Самовнимание (ограниченное) |  |
|
 |
 — это длина последовательности,
— это длина последовательности,  — размерность эмбеддинга, — размер ядра в свёртках и
— размерность эмбеддинга, — размер ядра в свёртках и  — длина окна в ограниченном самовнимании
— длина окна в ограниченном самовниманииКак отмечено в таблице 1, слои самовнимания связывают все позиции в ходе фиксированного количества последовательных операций, в то время как в рекуррентном слое число последовательных операций составляет
. С точки зрения вычислительной сложности, слои самовнимания оказываются быстрее рекуррентных в случаях, когда длина последовательности меньше, чем размерность эмбеддинга . Последнее встречается крайне часто в современных моделях машинного перевода, где для токенизации последовательности используются алгоритмы word-piece [38] или byte-pair [31] кодирования. Чтобы повысить производительность для задач, требующих очень длинных последовательностей, самовнимание может быть ограничено только фрагментом входной последовательности длиной с центром в соответствующей выходной позиции, что увеличит максимальную длину пути до . Этот подход авторы планируют развить в дальнейших исследованиях.Один свёрточный слой с размером ядра
 не соединяет все пары входных и выходных позиций. Для этого требуется стек из
не соединяет все пары входных и выходных позиций. Для этого требуется стек из  свёрточных слоёв в случае смежных ядер или в случае расширенных свёрток [18], что увеличивает длину самых длинных путей между любыми двумя позициями в сети. Свёрточные слои обычно дороже рекуррентных слоёв в раз. Хотя отделяемые (separable) свёртки [6] уменьшают сложность до
свёрточных слоёв в случае смежных ядер или в случае расширенных свёрток [18], что увеличивает длину самых длинных путей между любыми двумя позициями в сети. Свёрточные слои обычно дороже рекуррентных слоёв в раз. Хотя отделяемые (separable) свёртки [6] уменьшают сложность до  , но даже при
, но даже при  сложность отделяемой свёртки равна комбинации слоя самовнимания и поканального (pointwise) полносвязного слоя — подхода, который используется в описываемой модели.
сложность отделяемой свёртки равна комбинации слоя самовнимания и поканального (pointwise) полносвязного слоя — подхода, который используется в описываемой модели.В качестве приятного бонуса самовнимание позволяет сделать модель более интерпретируемой. Авторы приводят примеры распределения внимания по моделям в Приложении к данной статье. Мало того, что отдельные головы внимания явно учатся выполнять разные задачи, многие из них, по-видимому, демонстрируют поведение, связанное с пониманием синтаксической и семантической структуры предложений.
5. Обучение
Этот раздел описывает процесс обучения моделей.
▍ 5.1 Обучающие данные и деление на батчи
Обучение проводилось на стандартном наборе данных англо-немецких переводов WMT 2014, состоящем примерно из 4,5 миллиона пар предложений. Предложения были токенизированы на основе byte-pair подхода [3], общий словарь исходного и целевого языков состоял из около 37000 токенов. Для задачи перевода с английского на французский авторы использовали значительно больший англо-французский набор данных WMT 2014, состоящий из 36 миллионов предложений, векторизованных с помощью word-piece подхода [38] на основе словаря из 32000 токенов. Пары предложений были объединены в группы по схожей длине последовательности. Каждый батч состоял из набора пар предложений, содержащих примерно 25 000 токенов на исходном и 25 000 токенов на целевом языке.
▍ 5.2 Технические средства и время обучения
Авторы обучали модели на одной машине с 8 графическими процессорами NVIDIA P100. Для базовых моделей, использующих описанные в статье гиперпараметры, каждый шаг обучения занимал около 0,4 секунды. Базовые модели были обучены в общей сложности за 100 000 шагов или 12 часов. Для больших моделей (описанных в нижней строке таблицы 3) время одного шага увеличилось до 1,0 секунды, а общее время обучения составило 300 000 шагов (или 3,5 дня).
▍ 5.3 Оптимизатор
Авторы использовали оптимизатор Адама (Adam optimizer) [20] с
 ,
,  и
и  . Скорость обучения варьировалась в ходе обучения по формуле:
. Скорость обучения варьировалась в ходе обучения по формуле:
Это соответствует линейному увеличению скорости обучения для первых
 шагов обучения, а затем её уменьшению пропорционально обратному квадратному корню из номера шага. Авторы использовали
шагов обучения, а затем её уменьшению пропорционально обратному квадратному корню из номера шага. Авторы использовали  .
.▍ 5.4 Регуляризация
Во время обучения использовались следующие виды регуляризации:
Residual Dropout Dropout [33] применяется к выходным данным каждого подслоя, прежде чем они будут добавлены к входным данным подслоя и нормализованы. Кроме того, dropout применяется также к суммам эмббедингов и позиционных векторов как в стеках энкодера, так и в стеках декодера. Для базовой модели используется
 .
.Сглаживание меток Во время обучения авторы использовали сглаживание меток (label smoothing) со значением
 [36]. Это уменьшает перплексию, поскольку модель учится быть более неуверенной, но повышает точность и метрику BLEU.
[36]. Это уменьшает перплексию, поскольку модель учится быть более неуверенной, но повышает точность и метрику BLEU.
6. Результаты
▍ 6.1 Машинный перевод
В задаче WMT 2014 по переводу с английского на немецкий большая модель Трансформера (Transformer (big) в таблице 2) превосходит лучшие модели, о которых сообщалось ранее (включая ансамбли), более чем на 2,0 BLEU, устанавливая новую планку в значении метрики BLEU — 28,4. Конфигурация этой модели указана в нижней строке таблицы 3. Обучение заняло 3,5 дня на 8 графических процессорах P100. Базовая модель также превосходит все ранее опубликованные модели и ансамбли, при этом затраты на обучение были существенно меньше любой из конкурирующих моделей.
В задаче перевода WMT 2014 с английского на французский большая модель Трансформера достигает 41,0 по метрике BLEU, превосходя все ранее опубликованные отдельные модели, затратив при этом на обучение менее 1/4 вычислительных ресурсов предыдущей модели-лидера. Коэффициент dropout для этой модели составил
вместо 0,3.В качестве базовых моделей авторы использовали модель, полученную путём усреднения последних 5 чекпоинтов, записанных с 10-минутными интервалами. Для больших моделей усреднялись последние 20 чекпоинтов. В ходе экспериментов на тестовой выборке авторы выбрали следующие гиперпараметры для лучевого поиска: размер луча 4 и штрафом за длину
 [38]. Максимальная длина выхода во время инференса устанавливается как длина входной последовательности + 50, с возможностью досрочного завершения [38].
[38]. Максимальная длина выхода во время инференса устанавливается как длина входной последовательности + 50, с возможностью досрочного завершения [38].В таблице 2 приведены обобщённые результаты по получившимся моделям и затраты на обучение в сравнении с моделями других архитектур, известных из литературы. Авторы подсчитывают количество операций, используемых для обучения модели, как произведение времени обучения, количества используемых графических процессоров и оценку устойчивой производительности каждого графического процессора в формате числа одинарной точности.
▍ 6.2 Варианты моделей
Чтобы оценить важности различных компонентов Трансформера, в базовую модель внесли ряд изменений и в каждом случае провели измерение качества модели на задаче перевода с английского на немецкий на тестовой выборке newstest2013. Параметры лучевого поиска соответствуют приведённым в прошлом разделе, но без усреднения чекпоинтов. Результаты представлены в таблице 3.


В строках (A) таблицы 3 авторы изменяют количество голов внимания и размерности ключей и значений механизма внимания, сохраняя постоянный объём вычислений, как описано в разделе 3.2.2. В то время как внимание с одной головой показывает результат на 0,9 BLEU хуже, чем наилучшая модель, качество также падает и при слишком большом количестве голов.
В строках (B) таблицы 3 видно, что уменьшение размерности ключа внимания
 ухудшает качество модели. Это говорит о том, что определить совместимость непросто и что здесь может оказаться полезной более сложная функция совместимости, чем скалярное произведение. Также в строках © и (D) видно, что, как и ожидалось, более крупные модели лучше, а droupout очень помогает избежать переобучения. В строке (E) позиционное кодирование с синусоидой заменяется позиционными эмбеддингами [9], полученными в ходе обучения, что приводит к почти идентичным результатам по сравнению с базовой моделью.
ухудшает качество модели. Это говорит о том, что определить совместимость непросто и что здесь может оказаться полезной более сложная функция совместимости, чем скалярное произведение. Также в строках © и (D) видно, что, как и ожидалось, более крупные модели лучше, а droupout очень помогает избежать переобучения. В строке (E) позиционное кодирование с синусоидой заменяется позиционными эмбеддингами [9], полученными в ходе обучения, что приводит к почти идентичным результатам по сравнению с базовой моделью.▍ 6.3 Синтаксический разбор предложений на английском языке
Чтобы оценить, может ли Трансформер хорошо обобщать выученное для решения других задач, были проведены эксперименты на задаче синтаксического разбора предложений на английском языке. Эта задача сопряжена с особыми трудностями: результат подвержен сильным структурным ограничениям и значительно длиннее входных данных. Кроме того, модели на основе RNN не смогли достичь лучших результатов в условиях обучения на малом объёме данных [37].
Авторы обучили 4-слойный Трансформер с
 на части набора данных Wall Street Journal (WSJ) Penn Treebank [25], что составило около 40 тысяч обучающих предложений. Модель также была обучена в рамках обучения с частичным привлечением учителя (semi-supervised) с использованием более крупных и надёжных корпусов Berkley-Parser с примерно 17 миллионами предложений [37]. Для первого варианта обучения авторы взяли словарь из 16 тысяч токенов, а для второго — словарь из 32 тысяч токенов.
на части набора данных Wall Street Journal (WSJ) Penn Treebank [25], что составило около 40 тысяч обучающих предложений. Модель также была обучена в рамках обучения с частичным привлечением учителя (semi-supervised) с использованием более крупных и надёжных корпусов Berkley-Parser с примерно 17 миллионами предложений [37]. Для первого варианта обучения авторы взяли словарь из 16 тысяч токенов, а для второго — словарь из 32 тысяч токенов.После небольшого количества экспериментов были выбраны значения некоторых гиперпараметров, таких как dropout разных типов (раздел 5.4), скорости обучения и размера луча на разделе 22 (Section 22) тестовой выборки, все остальные параметры остались неизменными по сравнению с базовой моделью перевода с английского на немецкий. Во время инференса максимальная длина выходной последовательности была увеличена до размера длины входной последовательности + 300. Авторы использовали размер луча 21 и
 для обоих вариантов обучения.
для обоих вариантов обучения.Полученные результаты в таблице 4 показывают, что, несмотря на отсутствие дообучения под конкретную задачу, модель работает на удивление хорошо, давая лучшие результаты, чем все предыдущие модели, за исключением грамматик рекуррентной нейронной сети (Recurrent Neural Network Grammar) [8].
В отличие от моделей последовательностей RNN [37], Transformer превосходит Berkeley-Parser [29] даже при обучении только на обучающем наборе WSJ из 40 тыс. предложений.
7. Заключение
В данной работе была представлена модель Трансформера — первая модель преобразования последовательности, полностью основанная на механизме внимания, заменяющая рекуррентные слои, которые наиболее часто используются в архитектурах энкодер-декодер, многоголовым самовниманием.
Для задач перевода Трансформер можно обучить значительно быстрее, чем архитектуры, основанные на рекуррентных или свёрточных слоях. В задачах перевода WMT 2014 с английского на немецкий и WMT 2014 с английского на французский были достигнуты самые высокие метрики, а в первой задаче лучшая модель Трансформеров превосходит даже представленные ранее ансамбли.
Авторы воодушевлены будущим моделей, основанных на механизме внимания, и планируют применить их к другим задачам. В частности, планируется распространить применение Трансформера на задачи, связанные с нетекстовыми входными и выходными модальностями, а также исследовать локальные, ограниченные механизмы внимания для эффективной обработки больших входных и выходных данных, таких как изображения, аудио и видео. Ещё одна цель будущих исследований — сделать генерацию менее последовательной.
Код, который был использован для обучения и оценки представленных моделей, доступен по адресу: github.com/tensorflow/tensor2tensor.
Авторы выражают благодарность Налу Калхбреннеру и Стефану Гаусу за их плодотворные комментарии, исправления и вдохновение.
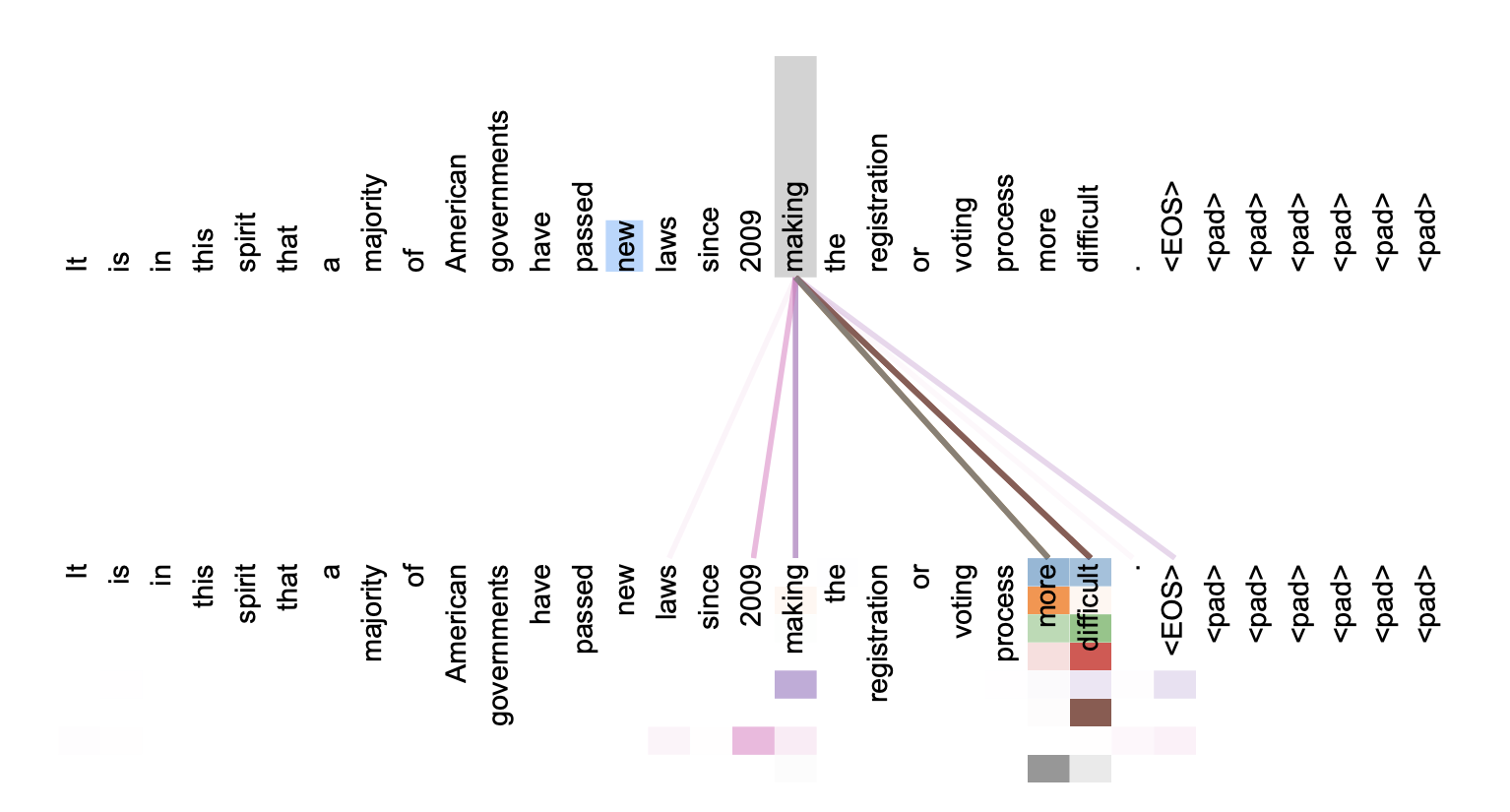
Приложение
▍ Визуализация внимания


Источники
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint
arXiv:1607.06450, 2016.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly
learning to align and translate. CoRR, abs/1409.0473, 2014.
[3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. Massive exploration of neural
machine translation architectures. CoRR, abs/1703.03906, 2017.
[4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine
reading. arXiv preprint arXiv:1601.06733, 2016.
[5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk,
and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical
machine translation. CoRR, abs/1406.1078, 2014.
[6] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv
preprint arXiv:1610.02357, 2016.
[7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation
of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
[8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural
network grammars. In Proc. of NAACL, 2016.
[9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolu-
tional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
[10] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint
arXiv:1308.0850, 2013.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im-
age recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 770–778, 2016.
[12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in
recurrent nets: the difficulty of learning long-term dependencies, 2001.
[13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation,
9(8):1735–1780, 1997.
[14] Zhongqiang Huang and Mary Harper. Self-training PCFG grammars with latent annotations
across languages. In Proceedings of the 2009 Conference on Empirical Methods in Natural
Language Processing, pages 832–841. ACL, August 2009.
[15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring
the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
[16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural
Information Processing Systems, (NIPS), 2016.
[17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In International Conference
on Learning Representations (ICLR), 2016.
[18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Ko-
ray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2,
2017.
[19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks.
In International Conference on Learning Representations, 2017.
[20] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
[21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint
arXiv:1703.10722, 2017.
[22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen
Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint
arXiv:1703.03130, 2017.
[23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task
sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
[24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-
based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
[25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated
corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
[26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In
Proceedings of the Human Language Technology Conference of the NAACL, Main Conference,
pages 152–159. ACL, June 2006.
[27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention
model. In Empirical Methods in Natural Language Processing, 2016.
[28] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive
summarization. arXiv preprint arXiv:1705.04304, 2017.
[29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. Learning accurate, compact,
and interpretable tree annotation. In Proceedings of the 21st International Conference on
Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July
2006.
[30] Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv
preprint arXiv:1608.05859, 2016.
[31] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words
with subword units. arXiv preprint arXiv:1508.07909, 2015.
[32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton,
and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts
layer. arXiv preprint arXiv:1701.06538, 2017.
[33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdi-
nov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine
Learning Research, 15(1):1929–1958, 2014.
[34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory
networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors,
Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates,
Inc., 2015.
[35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural
networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
[36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna.
Rethinking the inception architecture for computer vision. CoRR, abs/1512.00567, 2015.
[37] Vinyals & Kaiser, Koo, Petrov, Sutskever, and Hinton. Grammar as a foreign language. In
Advances in Neural Information Processing Systems, 2015.
[38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine
translation system: Bridging the gap between human and machine translation. arXiv preprint
arXiv:1609.08144, 2016.
[39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. Deep recurrent models with
fast-forward connections for neural machine translation. CoRR, abs/1606.04199, 2016.
[40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. Fast and accurate
shift-reduce constituent parsing. In Proceedings of the 51st Annual Meeting of the ACL (Volume
1: Long Papers), pages 434–443. ACL, August 2013.
arXiv:1607.06450, 2016.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly
learning to align and translate. CoRR, abs/1409.0473, 2014.
[3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. Massive exploration of neural
machine translation architectures. CoRR, abs/1703.03906, 2017.
[4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine
reading. arXiv preprint arXiv:1601.06733, 2016.
[5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk,
and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical
machine translation. CoRR, abs/1406.1078, 2014.
[6] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv
preprint arXiv:1610.02357, 2016.
[7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation
of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
[8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural
network grammars. In Proc. of NAACL, 2016.
[9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolu-
tional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
[10] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint
arXiv:1308.0850, 2013.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im-
age recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 770–778, 2016.
[12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in
recurrent nets: the difficulty of learning long-term dependencies, 2001.
[13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation,
9(8):1735–1780, 1997.
[14] Zhongqiang Huang and Mary Harper. Self-training PCFG grammars with latent annotations
across languages. In Proceedings of the 2009 Conference on Empirical Methods in Natural
Language Processing, pages 832–841. ACL, August 2009.
[15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring
the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
[16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural
Information Processing Systems, (NIPS), 2016.
[17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In International Conference
on Learning Representations (ICLR), 2016.
[18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Ko-
ray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2,
2017.
[19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks.
In International Conference on Learning Representations, 2017.
[20] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
[21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint
arXiv:1703.10722, 2017.
[22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen
Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint
arXiv:1703.03130, 2017.
[23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task
sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
[24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-
based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
[25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated
corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
[26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In
Proceedings of the Human Language Technology Conference of the NAACL, Main Conference,
pages 152–159. ACL, June 2006.
[27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention
model. In Empirical Methods in Natural Language Processing, 2016.
[28] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive
summarization. arXiv preprint arXiv:1705.04304, 2017.
[29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. Learning accurate, compact,
and interpretable tree annotation. In Proceedings of the 21st International Conference on
Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July
2006.
[30] Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv
preprint arXiv:1608.05859, 2016.
[31] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words
with subword units. arXiv preprint arXiv:1508.07909, 2015.
[32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton,
and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts
layer. arXiv preprint arXiv:1701.06538, 2017.
[33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdi-
nov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine
Learning Research, 15(1):1929–1958, 2014.
[34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory
networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors,
Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates,
Inc., 2015.
[35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural
networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
[36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna.
Rethinking the inception architecture for computer vision. CoRR, abs/1512.00567, 2015.
[37] Vinyals & Kaiser, Koo, Petrov, Sutskever, and Hinton. Grammar as a foreign language. In
Advances in Neural Information Processing Systems, 2015.
[38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang
Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine
translation system: Bridging the gap between human and machine translation. arXiv preprint
arXiv:1609.08144, 2016.
[39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. Deep recurrent models with
fast-forward connections for neural machine translation. CoRR, abs/1606.04199, 2016.
[40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. Fast and accurate
shift-reduce constituent parsing. In Proceedings of the 51st Annual Meeting of the ACL (Volume
1: Long Papers), pages 434–443. ACL, August 2013.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх 🕹️

