Согласно отчету 2021 SANS Cyber Threat Intelligence (CTI) Survey, 66,3% компаний используют открытые источники для сбора индикаторов компрометации и стараются работать одновременно с несколькими источниками. Казалось бы, сбор индикаторов из открытых источников — достаточно простая задача: надо просто скачать с какого-то сайта файлик txt или csv, и всё. В действительности на этом пути можно столкнуться с большим количеством проблем. В статье мы расскажем, что это могут быть за сложности, от чего зависят структура и формат фида, какие метрики помогают оценить полезность фидов, а также покажем на реальном примере, что можно узнать из фида. Для большей объективности эту статью мы подготовили вместе с Колей Арефьевым из компании RST Cloud, занимающейся агрегацией, обогащением, очисткой и ранжированием индикаторов, публикуемых независимыми ИБ-исследователями.

Какие подводные камни таят в себе открытые источники TI
Сразу оговоримся: обойти проблемы при работе с индикаторами из открытых источников не выйдет. При первой же загрузке таких индикаторов в средства защиты вы получите тысячи срабатываний за сутки. Не разобрав и первые 100 сработок, вероятнее всего, плюнете на это дело и просто отключите фид.
Попробуем описать основные проблемы, которые необходимо будет разрешить при сборе индикаторов из открытых источников:
Подбор источников
Не стоит гнаться за количеством индикаторов в источнике и выбирать те, где индикаторов больше всего. Сделайте выборочную проверку некоторых индикаторов из фида, оцените их с точки зрения количества ложных срабатываний.
Понимание структуры фида
Важно понимать, что за индикаторы компрометации приносит источник. Но зачастую еще важнее собирать не только сами индикаторы, но и связанный с ними контекст, если он есть: временные метки, атрибуцию (кто, кого, когда, зачем, почему и какими инструментами атакует?). Например, контекстом может быть информация о том, почему определенный IP, домен, url или hash попал в фид. Если это С2C, то от какого вредоносного ПО, если фишинговый url, то под какую компанию он сделан.
Агрегация и дедупликация
А что, если несколько источников данных предоставляют одну и ту же информацию об индикаторе компрометации? Дубль? А что, если противоречивую? Кому верить?
Понимание изменений в источнике и актуальность данных
Перед подключением источника необходимо понять, что означает пропадание индикатора из источника, как происходит обновление индикатора. Представьте, что сегодня индикатор был в фиде, а завтра пропал. О чем это говорит? Означает ли это, что индикатор перестал быть вредоносным, или же просто источник приносит только новые индикаторы и не включает в выгрузку старые?
Понимание расписания обновления источников
При сборе индикаторов из открытых источников важно знать не только, как происходят изменения в фиде, но и когда и с какой частотой они публикуются. Если источник публикует только новые индикаторы каждые 4 часа, то стоит разобраться, в какие именно часы это происходит. В противном случае вы рискуете пропустить «сеанс связи» и попросту не получить часть индикаторов, ведь повторно публиковать их уже никто не будет.
Очистка индикаторов
Встретить в открытых индикаторах 127.0.0.1, microsoft.com или SHA256 обычного calc.exe — вполне нормальная ситуация. Чтобы избежать ложных срабатываний, необходимо очищать индикаторы с помощью разнообразных списков исключений.
Обогащение индикаторов
Многие открытые источники индикаторов не снабжают их какой-либо дополнительной информацией. К таким сведениям, например, относятся ASN, Whois, Geo-привязка, данные об открытых портах, запущенных сервисах и т.д. Подумайте, что вам может быть полезно при расследовании инцидентов, в которых могут участвовать индикаторы, и откуда вы сможете получить эту информацию.
Хранение индикаторов в средствах защиты
Было бы просто чудесно, если бы можно было загрузить все собранные за год индикаторы в средства защиты и использовать их для проверки на потоке. К сожалению, чудеса в IT и ИБ случаются очень редко, и хранить в средствах защиты придется лишь столько индикаторов, сколько они способны обеспечить без существенной деградации производительности. Для наглядности приведем статистику RST Cloud по уникальным сетевым IoC, собранным за 365 дней.

От чего зависят структура и формат фида: ищем ответ в «Пирамиде боли»
В статье нам хотелось бы более детально разобраться со структурами фидов и форматами, в которых они поставляются. Это достаточно важный вопрос, так как при сборе индикаторов из открытых источников придется разрабатывать свои парсеры файлов с индикаторами, а затем еще и утилиты для преобразования уже очищенных и обогащенных индикаторов в формат, понятный модулям импорта вашего средства защиты.
В целом, формат фида определяется исходя из модели данных, которую необходимо хранить. Попробуем чуть подробнее раскрыть, что мы понимаем под «моделью данных».
Давайте вспомним «Пирамиду боли», предложенную впервые в 2013 году David J Bianco.
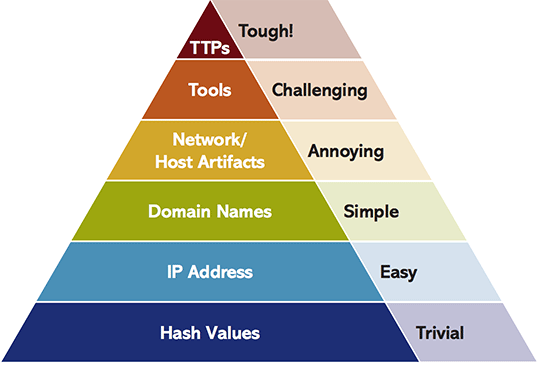
В нижней части пирамиды лежат атомарные сетевые и хостовые индикаторы. Как правило, для их описания в фиде можно использовать плоские структуры данных, сформировав txt- или csv-фид. Для таких структур характерно отсутствие каких-либо вложенностей.
Например, фид такой структуры может выглядеть вот так:
812 | ROGERS-COMMUNICATIONS | 99.250.237.110 | 2021-04-05 04:46:22
852 | ASN852 | 66.183.170.4 | 2021-04-05 02:50:15
1101 | IP-EEND-AS Surfnet B.V. | 192.42.116.13 | 2021-03-31 19:52:48
1101 | IP-EEND-AS Surfnet B.V. | 192.42.116.14 | 2021-04-03 14:50:55
1101 | IP-EEND-AS Surfnet B.V. | 192.42.116.16 | 2021-04-05 09:45:03
1101 | IP-EEND-AS Surfnet B.V. | 192.42.116.17 | 2021-04-04 18:13:59 Или даже вот так:
Family,URL,IP,FirstSeen
Pony,http[:]//officeman[.]tk/admin.php,207[.]180.230.128,01-06-2020
Pony,http[:]//learn[.]cloudience[.]com/admin.php,192[.]145.234.108,01-06-2020
Pony,http://vman23[.]com/admin.php,95.213.204.53,01-06-2020По мере продвижения вверх по пирамиде необходимо описывать всё более и более сложные модели данных. Такое усложнение обусловлено тем, что на более высоких уровнях недостаточно просто описать атомарный индикатор и его атрибуты. В фиде необходимо уже отражать как связки индикаторов, так и целые поведенческие паттерны вредоносных программ, техники и тактики (TTP) хакерских группировок или этапы APT.
Для описания подобных моделей становится недостаточно обычных плоских структур, и здесь уже задействуются такие форматы, как json, yaml, xml или что-то более экзотическое, построенное на их основе. Пример фида, описывающего несколько взаимосвязанных объектов в формате STIX 2, можно посмотреть в этой статье.
Помимо крайних точек в виде плоских структур с одной стороны и сложных структур с высокой степенью вложенности с другой, есть и промежуточные варианты. Как правило, такие фиды формируются в формате json и обладают небольшой глубиной вложенности — от 1 до 3 уровней. Фиды с такой структурой появляются тогда, когда атомарные индикаторы снабжают дополнительным контекстом, позволяющим иметь более полную информацию при расследовании инцидента, где встречаются эти индикаторы. Пример подобного фида приведем ниже.
Пример: о чем можно узнать из фида
Разберем подробнее, что полезного можно найти в фидах с индикаторами, снабженными дополнительным контекстом, на примере структуры доменного индикатора от RST Cloud.
Сам фид состоит из json следующего вида:
{
"id": "572f891c-dd92-31d3-a2e7-c448a4b72b22",
"title": "RST Threat feed. IOC: defender5.coachwithak.com",
"description": "IOC with tags: c2. Related threats: silverfish_group",
"threat": ["silverfish_group"],
"domain": "defender5.coachwithak.com",
"fseen": 1616630400,
"lseen": 1617408000,
"collect": 1617494400,
"tags": ["c2"],
"resolved": {
"ip": {
"a": ["37.48.84.156"],
"cname": []
},
"whois": {
"created": "2019-07-31 20:36:52",
"updated": "2020-08-01 10:58:42",
"expires": "2021-07-31 20:36:52",
"age": 608,
"registrar": "GoDaddycom LLC",
"registrant": "unknown",
"havedata": "true"
}
},
"score": {
"total": 55,
"src": 73.75,
"tags": 0.89,
"frequency": 0.85
},
"fp": {
"alarm": "false",
"descr": ""
}
}Выделим ключевую информацию об индикаторе, которую можно узнать из этого фида:
GUID индикатора.
Краткое описание индикатора — помогает TI-аналитику быстро понять, чем опасен этот индикатор.
Время первого и последнего появления индикатора.
Информация об угрозе, которую несет индикатор. В данном случае домен атрибутирован с APT-группировкой SilverFish (подробнее можно ознакомиться в публичном отчете исследователей).
Теги — дают дополнительный контекст. В данном случае вредоносный домен используется как командный управляющий сервер (C2C).
IP-адреса, в которые резолвится домен, — полезны при анализе логов с сетевых устройств, где присутствуют только IP и нет информации о DNS-резолве.
Whois-информация — помогает TI-аналитику лучше понять, кто и когда зарегистрировал домен. Зачастую для атак регистрируют домены-«однодневки», поэтому важно обращать внимание на то, когда домен зарегистрирован. В нашем примере APT-группировка подошла к вопросу выбора домена для C2C-сервера более основательно и использовала домен с более чем двухгодичным временем жизни.
Вес индикатора — позволяет количественно оценить опасность индикатора. К примеру, индикатор с весом 70 опаснее индикатора с весом 50, и реагировать на появление первого необходимо в первую очередь.
Как правило, вес индикатора рассчитывается по заданной создателем фида формуле. TI-аналитику в общих чертах важно понимать, из чего складывается итоговый вес. В приведенном примере вес индикатора складывается из следующих параметров: доверие к источникам индикатора, его контекст и частота появления.
При работе с индикаторами важно понимать, насколько тот или иной индикатор может быть ложноположительной сработкой (False-Positive), поэтому в его структуре присутствует соответствующий флаг. В данном случае флаг выставлен в false, а это значит, что нахождение такого индикатора в инфраструктуре с высокой долей вероятности говорит о ее компрометации.
На какие метрики смотреть?
Оценка данных threat intelligence — нетривиальная задача, потому что в идеале нужно не только ориентироваться на объективные метрики, но и оценивать релевантность источников данных для специфики деятельности компании или индустрии, учитывать уникальную модель угроз организации, количество ложноположительных обнаружений угроз. Для этого нужен качественный контекст в источниках данных, а также накопленная статистика. Как показывают наши наблюдения, как с первым, так и со вторым, есть проблемки.
Так а что делать-то? Если ничего непонятно, то лучший вариант обычно — начинать с малого и понятного, другими словами, есть слона по кускам. Существует немалое количество метрик, по которым можно сделать вывод о потенциальной пользе фида. На что же стоит смотреть в первую очередь и почему?
Давайте посмотрим, какие метрики можно собрать даже по «голым» опенсорсным фидам, где контекст либо отсутствует, либо он есть, но в минимальном количестве.
Например, можно оценить фид по динамике поступления новых данных, то есть тех индикаторов компрометации, которые фид не присылал ранее:
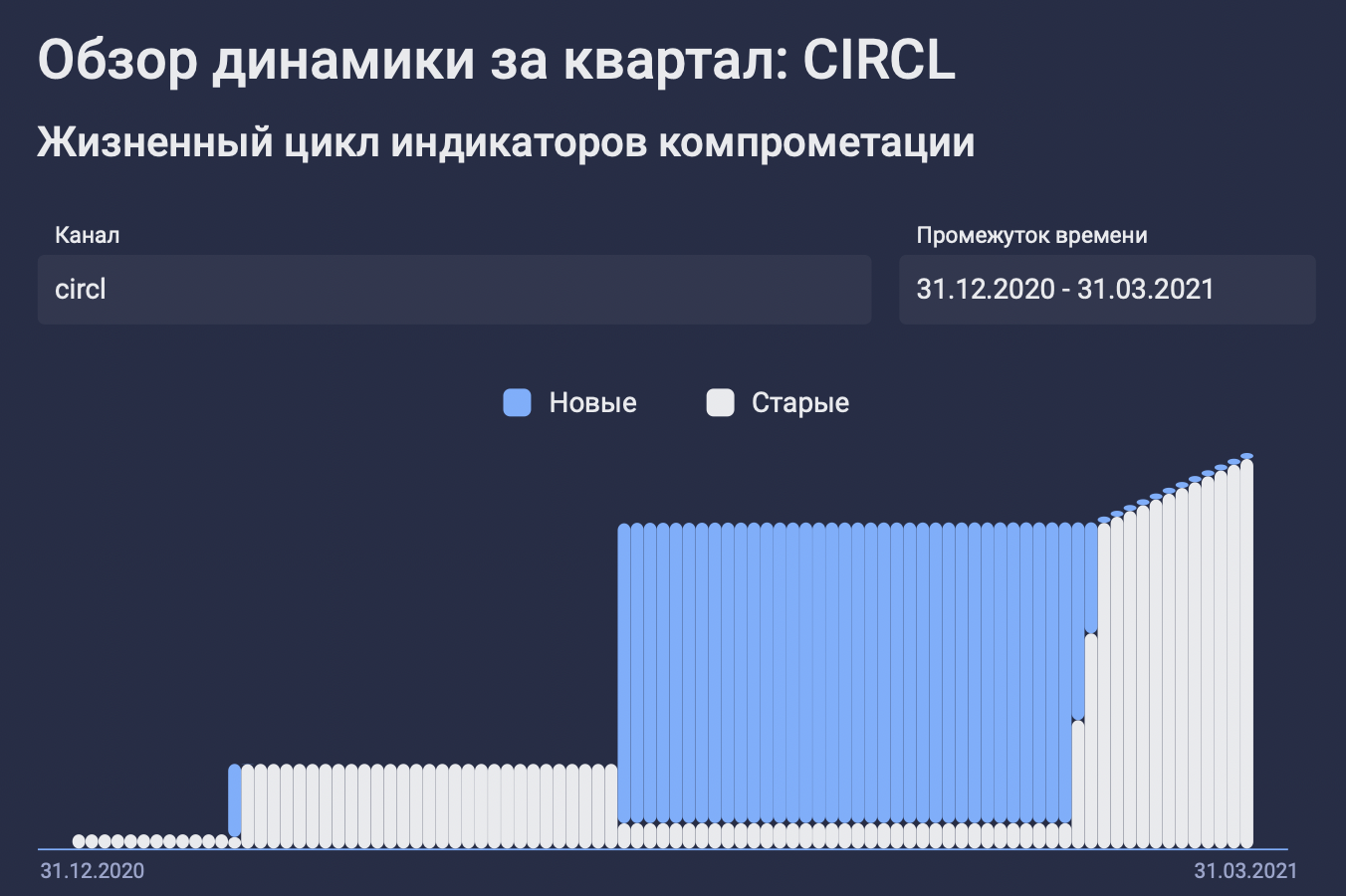
По таким графикам (или таблицам) хорошо видно, насколько часто фид присылает новые данные:

Как можно интерпретировать такую метрику? Факт постоянного получения новых данных позитивный, однако изолированная метрика достаточно неоднозначна, и следует рассматривать ее вкупе с иными метриками, чтобы увидеть картину более широко.
Давайте снова взглянем на опенсорсный фид от CIRCL.lu. Как видно из предыдущего графика, фид достаточно регулярно обновляется. Что же он собой представляет, если посмотреть более обобщенно?
За период в 3 месяца в фиде 157 852 индикатора. Видно, что фид предоставляет разные типы индикаторов компрометации.
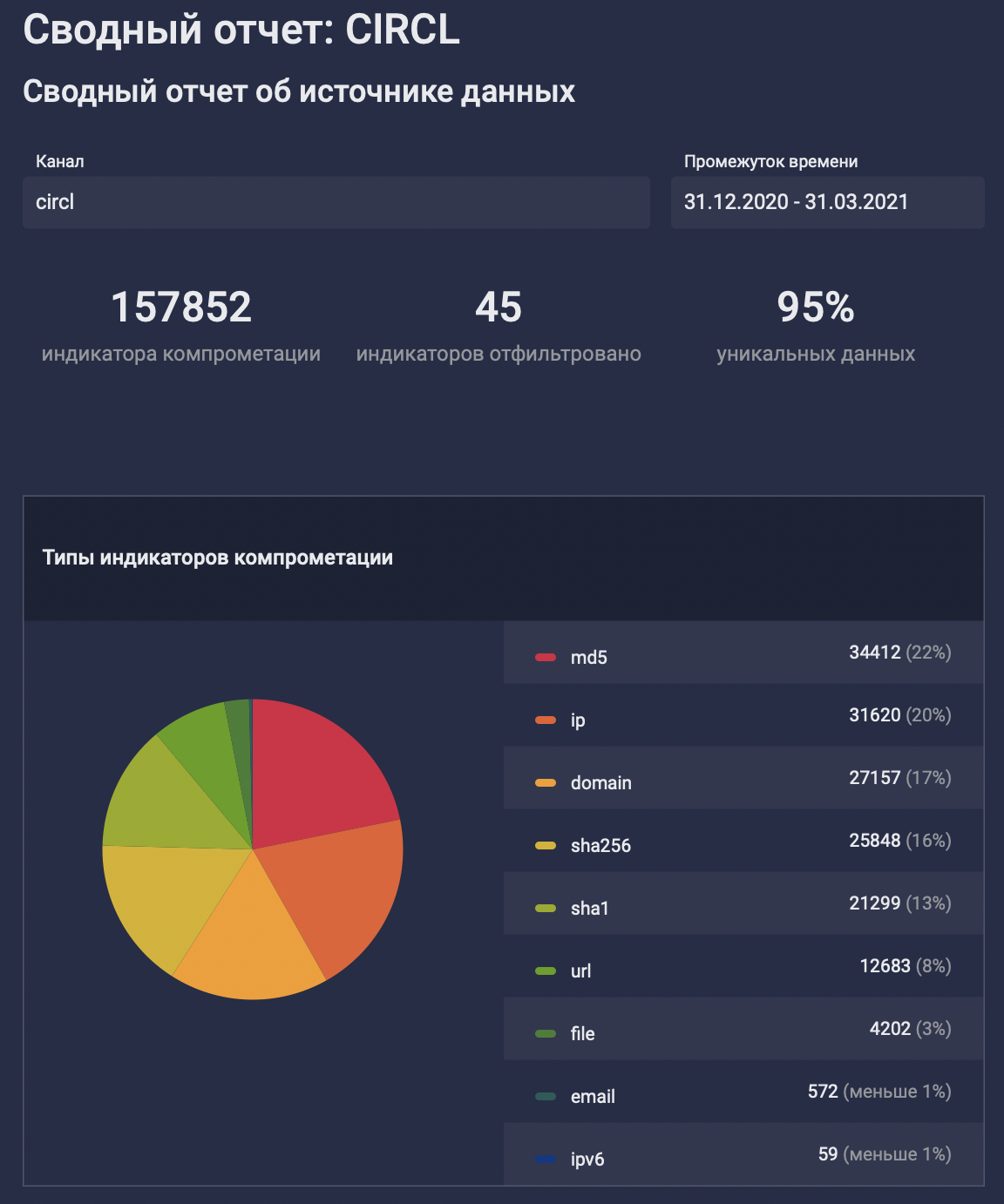
Если посмотреть на фид CIRCL в сравнении с несколькими другими фидами, можно также оценить распределение типов индикаторов компрометации по фидам. Что может дать эта информация пользователю? Например, понимание того, как можно будет использовать такой фид. Ведь обилие хешей обычно требует интеграции с EDR-решениями, хеши довольно бессмысленно искать в потоке трафика или netflow с сетевых устройств:
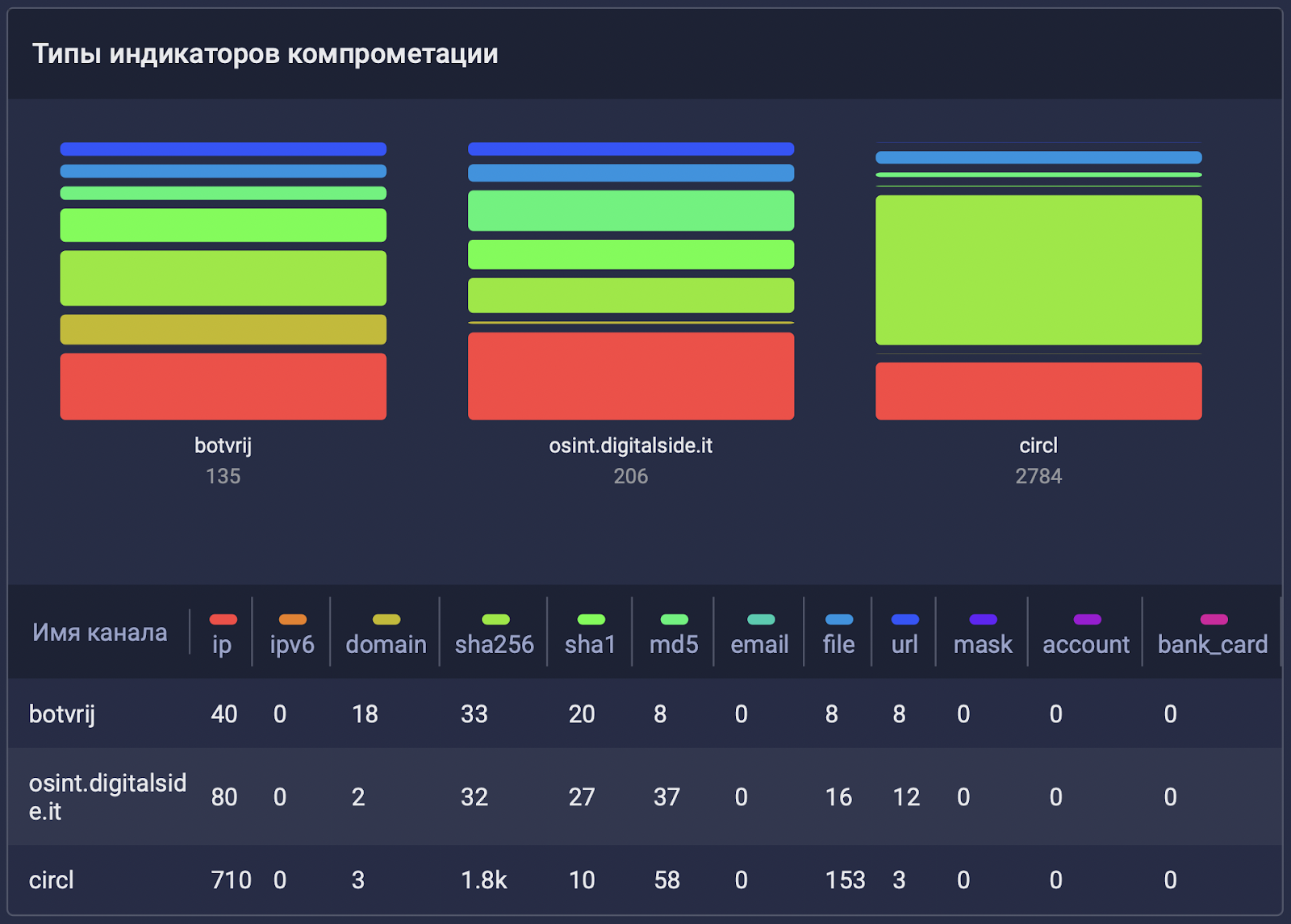
Также стоит взглянуть на распределение данных по типам объектов, которые предоставляют фиды. Ниже видно, что некоторые опенсорсные фиды предоставляют, помимо индикаторов компрометации, тот самый контекст: описание атак в виде отчетов и связи с уязвимостями (CVE). Контекст в TI чертовски полезен: он позволяет понять, что это вообще за угроза и как ей противостоять.
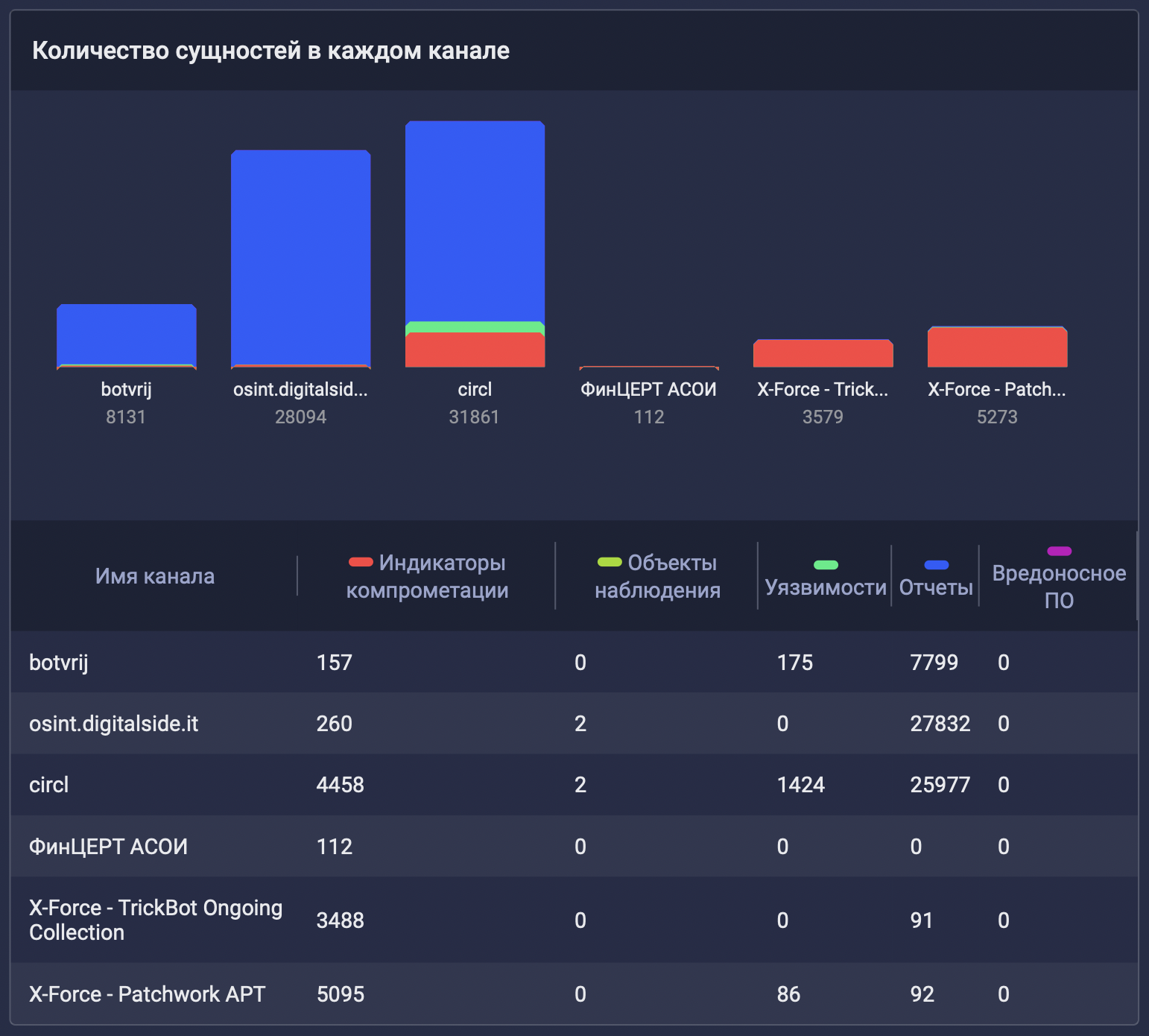
Неплохо взглянуть на метрику среднего времени жизни индикаторов компрометации. Она отражает дельту между временем создания и временем последнего изменения индикатора компрометации, усредненную для всей выборки (обычно удобно смотреть для отдельных источников). Среднее время жизни отвечает на вопрос, насколько часто источник TI обновляет уже имеющиеся индикаторы компрометации. Вкупе с динамикой новых индикаторов компрометации эта метрика позволяет более комплексно оценить источник: не только как часто он присылает новые данные, но и как часто обновляет уже имеющиеся.
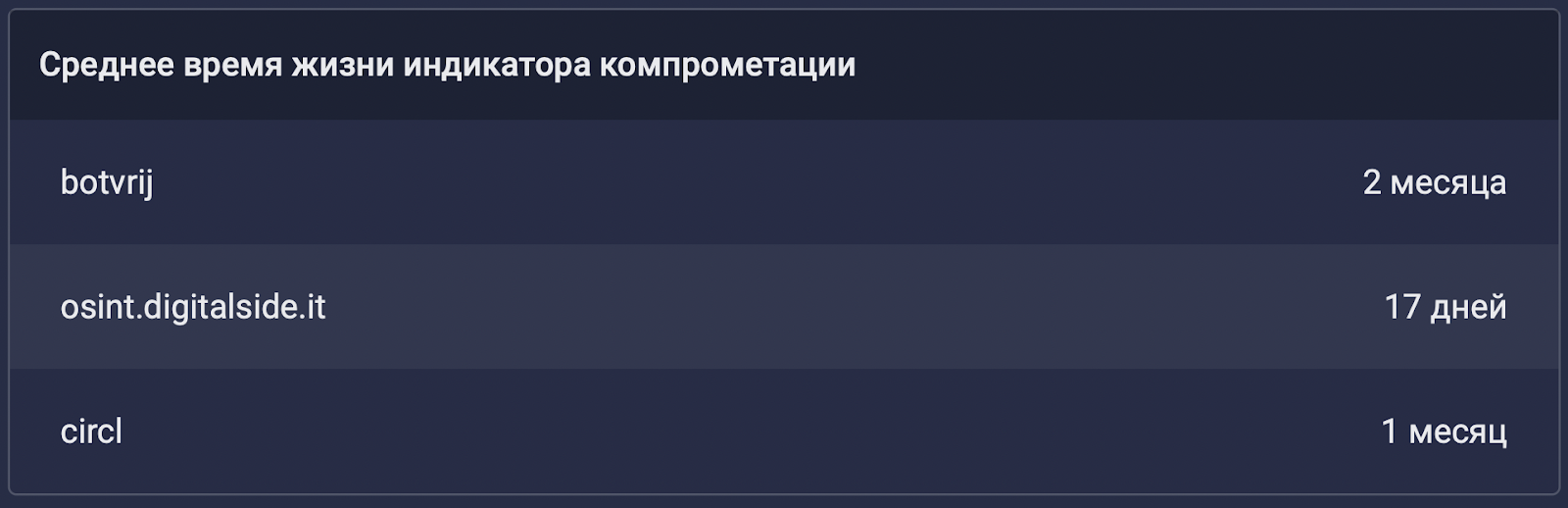
Похожей метрикой может быть среднее время обновления — время от последнего обновления индикаторов компрометации до настоящего момента, усредненное для всей выборки. Эта метрика отвечает на вопрос, насколько оперативно источник данных TI предоставляет данные об изменениях индикаторов компрометации. Вот как это может выглядеть:
Дополнить картину можно метрикой возраста индикаторов компрометации в фиде. Она представляет собой распределение количества индикаторов компрометации в фиде по времени. Иными словами, это позволяет понять, что за фид перед нами: динамично обновляющийся с равномерным поступлением данных либо хранилище археологии.

Интересная метрика, которую стоит брать во внимание, — уникальность данных в различных источниках. Подсчет следующий: для каждого источника данных в выборке (совокупности источников) нужно посчитать вхождения значений индикаторов компрометации из одного источника в другой. В результате можно получить таблицу:

Либо, что даже интересней и наглядней, матрицу пересечения источников. Обычно стоит стремиться к тому, чтобы источники содержали наиболее уникальные данные. Если несколько фидов имеют сильное пересечение между собой, это может свидетельствовать о том, что какой-то фид либо представляет собой агрегатор других фидов, либо один фид тащит часть данных из другого. Небольшие пересечения нормальны — чаще всего это означает, что часть индикаторов компрометации в фидах уже широко известны, и их упоминают несколько фидов.
Ниже приведем пару примеров. В первом примере хорошо видно, что фид CIRCL пересекается всего на 1% и 2% c digitalside и botvrj соответственно, а botvrj — на 30% и 1% c CIRCL и digitalside соответственно (тут все верно, разный процент пересечения между botvrj и CIRCL получился из-за их разных размеров по количеству объектов внутри относительно друг друга).

Во втором примере справедливо видно тотальное пересечение между фидами OTX - Project TajMahal и IBM X-Force Project TajMahal. Это объясняется тем, что фиды рассказывают об одной и той же угрозе.

Вместо выводов
Хотелось бы подвести тут умное заключение, но некоторая недосказанность прямо-таки просится сюда по той причине, что нет единого способа оценить полезность фидов с помощью универсального набора метрик. Пока нужно оценивать источники данных, исходя из специфики индустрии, деятельности организации и ее модели угроз, а это довольно кропотливая ручная работа. В этой статье мы рассмотрели ряд наиболее используемых метрик, с которых стоит начинать погружение в мир TI. Кажется, что высказывание одного популярного Youtube-канала «На нашем канале зрители все выводы делают сами» как нельзя кстати подходит под заключение этой статьи.
Авторы: Антон Соловей, менеджер продукта R-Vision Threat Intelligence Platform,
Николай Арефьев, сооснователь RST Cloud
Другие статьи по теме
