

Бывало, замечаешь в коде «нехороший» модуль или функцию и тут же тянутся руки их отрефакторить. Но как потом убедиться, что правки не сломали какой-нибудь сценарий в приложении или вовсе не положили продакшен? Этих ситуаций можно избежать, если в проекте есть тесты.
Меня зовут Александр Моргунов, я техлид в Самокате. Пишу на TypeScript, React, ReactNative. В разное время писал тесты для фронтенда, бэкенда и мобилок. В этом посте хочется поговорить о том, как можно тестировать современные фронтенд-приложения и какие подходы к тестированию сейчас актуальны.
Надеюсь, пост будет полезен для фронтендеров и тестировщиков, которые хотели бы свериться по дополнительным практикам для написания тестов. А бэкендеры смогут лишний раз посмотреть на схожесть и различия в тестировании для бэка и фронтенда.
Почему инженеры не пишут тесты?
Здесь у меня получился вот такой список.
Первая причина — неочевидность пользы тестов. Думаю каждый, кто когда-либо писал их, попадал в ситуацию, когда терялось само понимание, зачем нужен тест. Особенно если он не проверяет какие-то важные функции или вовсе пишется на какую-то малоиспользуемую функциональность.
Вторая причина – инфраструктура. Даже если инженер пересилил себя и написал тесты, то его ждёт второй барьер в виде часто сложной и долгой настройки инфраструктуры. Даже если она уже настроена, непонятно как же писать такие полезные тесты, чтобы они правда помогали приложению не падать.
Третьей причиной можно спокойно записывать сложность написания таких тестов.
Четвёртая причина, которую любят использовать некоторые менеджеры (персонажи вымышлены, совпадения случайны) — «у нас нет на тесты времени, мы продуктовыми фичами занимаемся».
Против всего этого есть два аргумента, которые на мой взгляд оправдывают написание тестов.
Первый – мы убеждаемся в том, что после каждого релиза наша основная функциональность не будет сломана и продолжит работать.
Второй – при внедрении новых фич, и особенно при рефакторинге, мы убеждаемся в том, что ничего не разломали в нашем приложении.
Дополнительно мы получаем документацию в виде кода. В том случае если есть фрагменты с legacy-кодом либо со сложной бизнес-логикой, по тестам можно понять, как вообще этот код предполагалось использовать, или какие кейсы предполагались к использованию.
Помимо этого, тесты помогают нам разбирать проблемы в архитектуре, но об этом чуть далее.
Основные подходы к написанию тестов для фронтенда
Здесь хочется кратко рассказать про пирамиду тестирования. Её придумали очень давно, ещё для бэкенда, и она делит всё тестирование на типы.
Обычно выделяют три типа:
юнит-тесты – используются для тестирования функций, модулей, классов в изоляции от всего приложения;
интеграционные тесты – тестируют взаимодействие между нашими модулями;
end-to-end тесты – воздействуют на систему через её внешние интерфейсы и проверяют ожидаемую реакцию системы через эти же интерфейсы.
Также пирамида показывает, сколько тестов должно быть в проекте по пропорции. Юнит-тестов должно быть больше всего, а end-to-end – меньше всего.

Чем ниже к основанию пирамиды располагаются тесты, тем они быстрее работают, тем стабильнее и быстрее пишутся. Но чем выше тесты к вершине пирамиды, тем они приносят больше бизнес-ценности.
Насчёт всего этого есть альтернативное мнение. Вот, например, что пишет крутой фронтендер Кент Си Доддс:
Чем ваши тесты больше похожи на то, как приложение используют, тем больше полезности и уверенности они вам принесут.
В контексте фронтенда Кент доработал обычную пирамиду тестирования и ввёл так называемый трофей тестирования.

В трофее тестирования у нас изменяется пропорция и добавляется дополнительный слой в самом основании – статические тесты. Он отвечает за тестирование ошибок типов, то есть за типизацию, и за различные синтаксические ошибки. Это достигается с помощью линтеров, Web IDE и какого-нибудь типизированного языка программирования, например, TypeScript. О последнем я хочу рассказать вам историю из жизни.
Время увлекательных историй
Кусок кода, который вы видите ниже, был написан пару лет назад для мобильного приложения и нужен для обновления пользовательского Access Token, чтобы пользоваться приложением.
refreshAccessToken() {
try {
/* ... */
} catch (error) {
const isNotInternetNetworkError = error.status;
if (isNotInternetNetworkError) {
this.data = undefined;
}
this.deps.softAppRestart();
}
}В нём не так интересно, как обновляется сам пользовательский токен, нежели что происходит, если токен мы не смогли обновить. В этом случае мы всегда перезагружаем приложение, и если у пользователя не было проблем с интернет-соединением, то мы удаляем пользовательские данные, то есть поле this.data мы приравниваем к undefined. Другими словами, мы разлогиниваем пользователя.
Для отсутствия соединения я представляю такие случаи, когда пользователь едет в метро или лифте, а приложение в этот момент пытается обновить Access Token. Чтобы не разлогинить пользователя, мы просто перезагружаем приложение.
Так что же произошло с фрагментом обновления пользовательского токена?
Когда случилась вся эта история, нас активно ддосили, ломались бэкенды, и для того, чтобы решить часть проблем, было решено удалить из базы данных так называемые Refresh Tokens, с помощью которых как раз и обновляются Access Tokens.
Это бы привело к тому, что всех пользователей просто разлогинило. Неприятно, конечно, но помогло бы решить текущие проблемы.
После того как все Refresh Tokens были удалены, приложение внезапно перестало работать у всех пользователей, и они стали видеть экран с заглушкой.

Мы попали в бесконечный цикл, в котором пользователи загружают приложение, мы пытаемся обновить Access Token, не можем его обновить, потому что Refresh Token уже в базе не хранится, и вместо того, чтобы пользователя разлогинить, мы просто перезагружаем приложение, и так по кругу.
Проблема крылась в том, что наш объект Error, который выкидывался в блоке Catch, был типа Any, иными словами, TypeScript неявно приводил его к этому типу.
В современных версиях и строгом режиме TypeScript не приводит Error к типу Any, а приводит к Unknown, и дальше можно будет уже самим привести нужный тип. Но у нас использовалась та версия, которая этого не делала.
Если бы мы просто добавили условие и сузили Error до нужной нам ошибки, Axios Error, Axios (НТТР-транспорт, который мы использовали в мобильном приложении), то нам TypeScript сразу подчеркнул ошибку и указал, что в переменной Error нет поля status.
catch (error) {
if (isApiError(error)) { // error: AxiosError
const isNetworkError = !error.status;
// ^^^^^
// Property 'status' does not
// exist on type 'AxiosError<any>'
if (!isNetworkError) {
this.data = undefined;
}
}
this.deps.softAppRestart();
}
Зайдя в исходники Axios, мы бы могли увидеть, что поле Status нужно было взять из error.response.status. Вот так приложение может сломаться из-за небольшой, но глупой ошибки.
catch (error) {
if (isApiError(error)) { // error: AxiosError
const isNetworkError = !error.response.status; // 👍
if (!isNetworkError) {
this.data = undefined;
}
}
this.deps.softAppRestart();
}Казалось бы, причём тут тесты? А притом, что раньше на это все писали юнит-тесты, а сейчас с помощью строгой типизации подобные кейсы можно отловить прямо в коде. Нижний слой в трофее тестирования помогает нам решать и поймать огромное количество таких ошибок.

Структура теста
Файл с тестом я обычно создаю либо рядом с тестируемым модулем, либо создаю поддиректорию Tests, куда складываю все тесты.
Тест состоит из двух основных компонентов – блоков Describe и It. Дескрайбы могут быть вложенными, они описывают тестируемый модуль, тестируемую функцию, либо позволяют сгруппировать какие-то определённые связанные тест-кейсы.
А внутри блока It мы описываем сам тест. Я люблю так называть дескрайбы и иты, чтобы это можно было прочитать одним предложением.
Например, в нашем примере функция refreshAccessToken из service/Auth должна при сетевой ошибке очищать данные пользователя.
describe('service/Auth', () => {
describe('refreshAccessToken', () => {
it('должен при сетевой ошибке отчищать данные юзера', () => {
// Тело теста
});
});
});
Юнит-тесты принято писать по паттерну Triple A, когда мы группируем тело теста в три основные части.
it('должен при сетевой ошибке отчищать данные юзера', async () => {
const authService = new AuthService({...});
// мок сетевого запроса
await authService.refreshAccessToken();
expect(authService.data).toEqual(undefined);
});
В Arrange мы инициализируем наши сервисы, подготавливаем моки.
В Act – вызываем тестируемый метод.
В Expect или Assert – проверяем данные, которые мы получили реально, сравниваем с данными, которые мы ожидали получить.
Когда какой тест писать
Юнит-тесты
Юнит-тесты выполняются на стороне NodeJS. Их можно писать, следуя практике Test Driven Development, когда вначале мы описываем тест-кейсы, а потом реализуем непосредственно сам код.
Я использую моменты из этой практики, например, когда нужно накидать интерфейс, либо какие-то ограниченные случаи, чтобы о них потом не забыть.
Юнит-тесты подходят как для библиотек, так и для модулей со сложной логикой — какими-то ветвлениями или с большим количеством состояний.
На одном из моих проектов у нас было написано порядка 25 тысяч юнит-тестов, и 90% из них были написаны только ради того, чтобы прошёл чек в GitHub и можно было дальше перевести задачу. По сути тесты были синтетические, на самые простые React-компоненты и функции писалось по несколько тестов.
Но как бы ни были хороши и просты юнит-тесты, как бы они быстро ни выполнялись, они не гарантируют того, что наше приложение будет вообще работать, так как они тестируют наши модули изолированно друг от друга.

Что касается мобильного приложения, у меня есть показательный пример, когда нужно писать юнит-тесты.
В мобильном приложении Самоката есть различные разделы, например, «Быстро» или «Бьюти», и у каждого раздела есть свой SLA доставки. Он отображается в нескольких местах приложения: в названии под витриной, в капсуле с корзиной и потом уже при заказе.
const getRoundMinutes = (value: number, options: Options) => {
if (value > options.roundTo30.from) {
const accuracy = 30;
const mod = value % accuracy;
if (mod < options.roundTo30.roundUpFromMod) {
return Math.floor(value / accuracy) * accuracy;
} else {
return Math.ceil(value / accuracy) * accuracy;
}
} else if (value >= options.roundTo10.from) {
const accuracy = 10;
const mod = value % accuracy;
if (mod < options.roundTo10.roundUpFromMod) {
return Math.floor(value / accuracy) * accuracy;
} else {
return Math.ceil(value / accuracy) * accuracy;
}
} else if (value >= options.roundTo5.from) {
// ...Выше представлен только фрагмент метода, который позволяет нам округлить и отформатировать для каждого места количество минут, то есть наш SLA, к нужному формату. Сразу можно понять, что это отличный кандидат для того, чтобы написать юнит-тесты.
Мы полностью покрыли его юнит-тестами, потому что при попытке что-то изменить либо доработать большая вероятность что-то сломать.
Для себя же я вывел правило: если я по фрагменту кода не могу за 1-2 минуты разобраться, что тут вообще происходит, из-за количества состояний, либо какой-нибудь сложной алгебры, то надо писать юнит-тесты.
Е2Е-тесты
Если Кент Си Доддс сказал, что нужно писать тесты, которые были бы максимально приближены к реальному использованию приложения, то давайте писать только одни Е2Е-тесты.
Напомню, что Е2Е-тесты требуют для себя браузер (там тесты выполняются) и настроенное окружение в виде подготовленных API и бэкенда, чтобы у нас тест реально туда ходил.
Из всего этого следует, что такие тесты тяжело писать, поддерживать и отлаживать.
Представьте кейс, в котором нам нужно протестировать регистрацию. Мы не можем регистрировать одновременно или друг за другом одного и того же пользователя и нам нужно придумывать, как мы эти тесты будем выполнять и, возможно, как-то чистить базу. Тестовые API периодически будут падать, а вместе с ними и тесты.
Поэтому Е2Е-тестов должно быть намного меньше, чем юнитов, и они должны быть написаны только для самых критичных пользовательских сценариев. Условно, это авторизация, регистрация, оплата, добавление товаров в корзину и так далее.
Приведу пример на основе одного из своих прошлых проектов. У нас было написано порядка 3000 Е2Е-тестов и выполнялся этот пак порядка 3-4 часов. Но самая большая проблема была даже не с самими тестами, а с падениями. В каждом прогоне падало около 5% тестов. Кажется, что это немного, но на самом деле это целых 150 тестов.
Релизный тестировщик мог целый день сидеть и разбирать, почему же эти 150 тестов упали. Часть тестов падала, потому что браузер мог лагануть, часть тестов – потому что API был недоступен, и только какая-то небольшая доля могла упасть, потому что и правда были проблемы. Ко всему этому релизы у нас были ежедневные, и тестировщик мог просто 40 часов в неделю отлаживать эти упавшие тесты. Для тестирования это жуткая боль.
Интеграционные тесты
Ранее вы могли заметить, что в трофее тестирования очень много места уделено интеграционным тестам, и это неспроста. Что это такое?
Это тесты, которые выполняются на среде NodeJS, и каждый из них выполняется в изолированном окружении. Если мы тестируем два-три модуля, мы используем их, а всё остальное окружение, внешние API, мы либо мокаем, либо подготавливаем для них стабы, и не используем.
Интеграционные тесты, помимо проверки различной бизнес-логики либо инфраструктуры, также могут тестировать пользовательские сценарии, как и Е2Е-тесты. Для них не требуется какого-то отдельно настроенного окружения и в отличие от юнит-тестов, они не тестируют одно и то же с одних и тех же сторон, но тестируют модуль в целом.
Я сделал сводную табличку по типам тестов и различным параметрам. Жирным выделено то, что выделяет тест на фоне других. Даже по этим параметрам можно понять, что интеграционные тесты выигрывают у тех же юнитов и Е2Е-тестов.
unit | integration | e2e | |
Где выполняются | NodeJS | NodeJS | NodeJS + Browser |
Для чего используются | библиотечный код и сложная ветвистая логика | пользовательские сценарии, взаимодействие модулей | критичные пользовательские сценарии |
Настройка окружения | изолированные | изолированные | нужны отдельные API стенды |
Скорость выполнения | быстрые | быстрые | медленные |
Бизнес ценность | маленькая | средняя | высокая |
Отдельно хочется сказать про Black Box. Это такой подход к тестированию, который говорит о том, что нам не нужно знать, как работает наш модуль либо функция внутри – нам важно, что мы подаём на вход и что получаем на выходе.
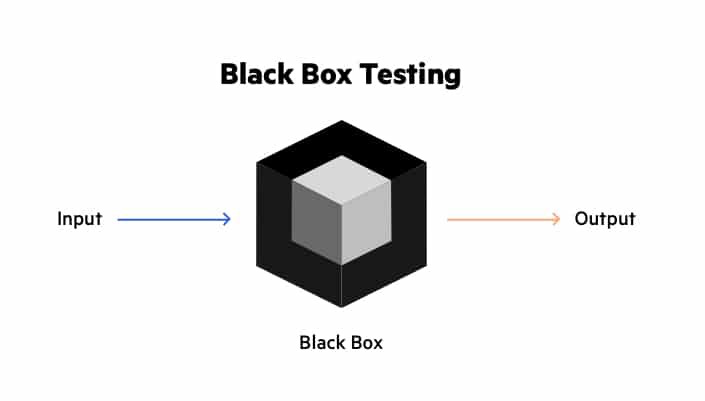
Например, у нас есть функция по сложению элементов массива. На вход мы подаём массив, на выходе мы получаем сумму. И нам неважно, как функция устроена внутри, будь это просто обычный перебор массива и сложения, аккумуляция значений, либо это будет какое-нибудь параллельное вычисление на веб-воркерах, когда массив бьём и отправляем их асинхронно вычисляться. В данном подходе это неважно.
Почти во всех тестах я рекомендую использовать именно этот способ, потому что он обладает большим преимуществом по сравнению с White Box, когда мы завязаны на реализацию. Если мы как-то меняем внутренние API нашего модуля, нам не нужно переписывать тесты, потому что они завязаны именно на внешний API.
Стек для тестов
Jest
Сейчас самым популярным решением для запуска тестов является Jest. Это очень сложная и большая монорепа с кучей различных хелперов и инструментов для того, чтобы мы без проблем могли покрывать наш код тестами.
Я не скажу, что с Jest у вас не будет проблем (их будет много), но почти на все проблемы есть ответы и примерные варианты решения на Stack Overflow либо GitHub Issues – вы наверняка найдёте то, что искали. На Jest можно запускать юнит-тесты, интеграционные тесты и даже Е2Е-тесты.

testing-library
Я считаю, что каждый фронтенд-разработчик должен как минимум знать про эту библиотеку, даже если он её не использует. Она применяется для тестирования компонентов, и у неё есть очень крутая особенность. Она использует подход Black Box, и с помощью неё можно тестировать код на различных фреймворках, будь это Vue, React, Svetle, либо вообще это может быть какой-то ваш самописный движок. Также с помощью testing-library можно тестировать и свои собственные компоненты. Она не завязывается на внутреннюю реализацию и предоставляет единый API для всех решений, который мы можем использовать.
describe('<Foo />', () => {
async it('should display baz', () => {
render(<Foo bar="baz" />);
fireEvent.click(screen.getByText('Change to foo'))
await waitFor(() => screen.getByRole('heading'))
expect(screen.getByRole('heading')).toHaveTextContent('foo')
});
});В этом фрагменте кода приведён пример теста с помощью testing-library. Мы монтируем в данном случае компонент, далее кликаем по какому-то элементу, ждём, пока у нас появится ещё один элемент и в конце проверяем, что в появившемся элементе содержится определённый текст.
Это уже пример даже не юнит-теста, а интеграционного UI-теста, когда мы по шагам проходим пользовательский сценарий и что-то проверяем.
Testing-library рендерит наши компоненты на стороне NodeJS (т.е на сервере) и для этого «под капотом» она использует библиотеку jsdom, которая предоставляет API браузера в NodeJS-среде.
У нас в NodeJS появляется глобальный объект Document, мы можем там внедрить какой-то HTML, либо загидрировать React-приложение и работать с ним (удалять ноды, искать ноды и тд).
Также в юнит-тестах и в интеграционных нам нужно мокать внешние запросы. Для этого можно использовать, например, mock service worker либо nock.
Для Е2Е-тестов, если вы решите их написать, или будете с ними заниматься, сейчас рекомендую cypress, очень крутое решение, которое позволяет писать простые и надёжные тесты.
Для генерации каких-то фейковых фикстур, например, банковских карт, емейлов — рекомендую решение faker.
Если вы хотите получить красивый отчёт, то есть библиотека jest-allure, которая позволяет по выполнению тестов сформировать HTML-страничку с их прогоном.
Как написать интеграционный тест
Переходим к самой интересной части. Если они такие полезные, как их правильно писать? Для этого я собрал небольшое приложение на React. По клику на кнопку пользователь получает случайную гифку с котиком. Я думаю, вы согласитесь, что если пользователь придёт и не получит котика, потому что там внедрится какой-то баг, это будет очень страшно, поэтому напишем интеграционный тест и обезопасим наших пользователей.
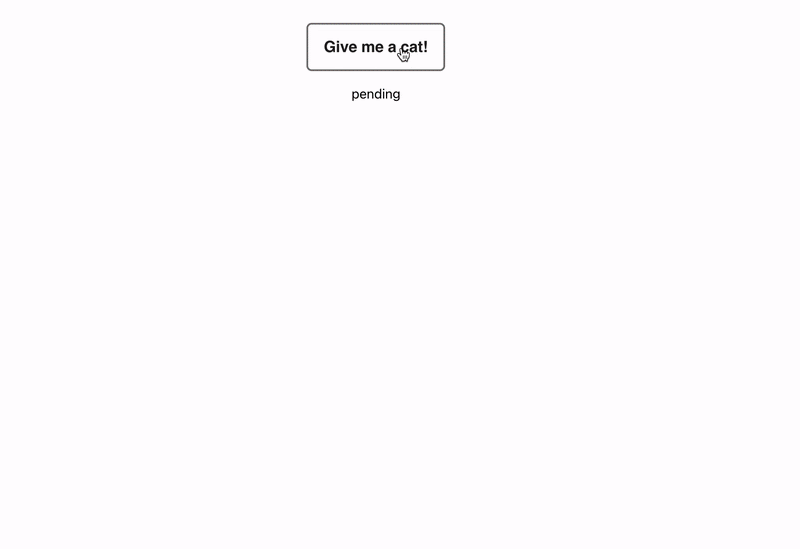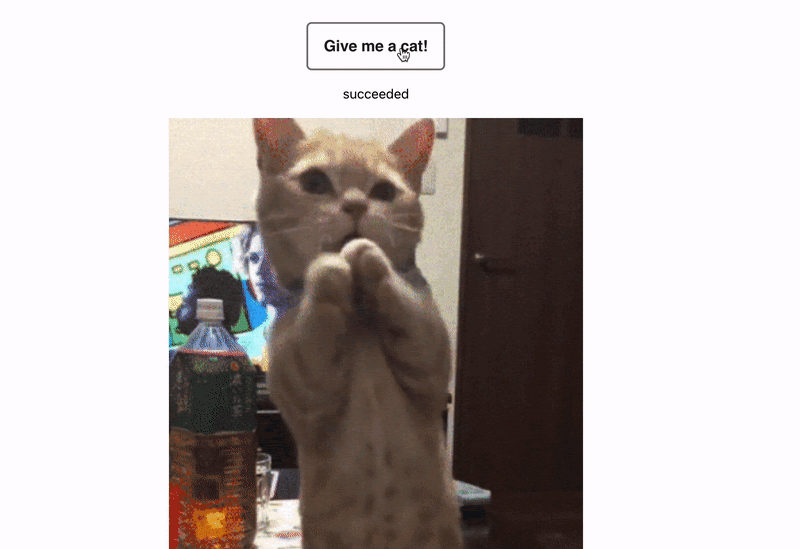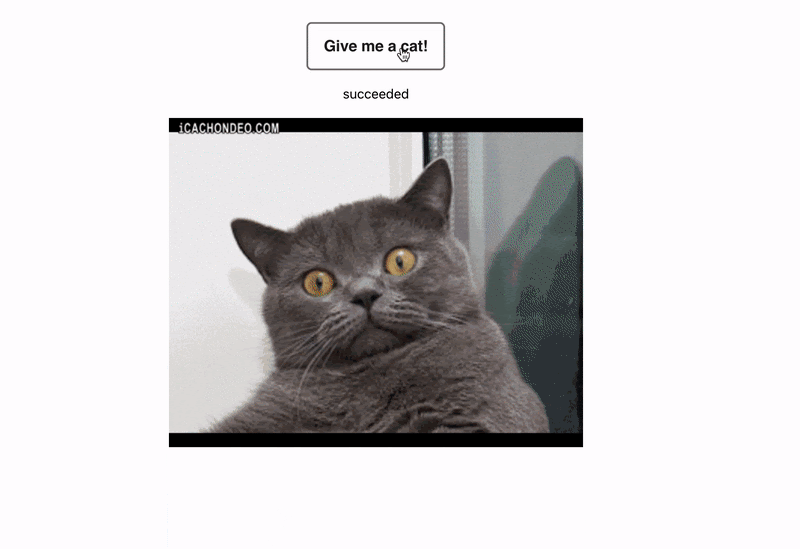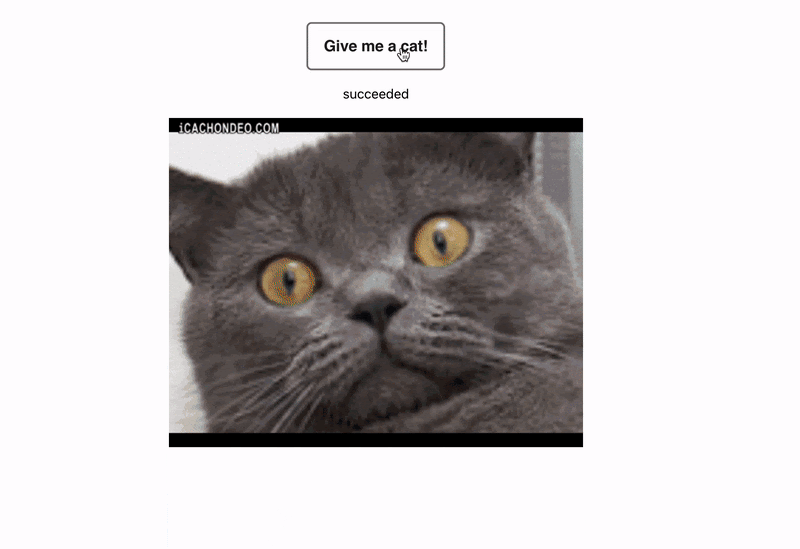
Перед тем как написать интеграционный тест, нам нужно понять, какие шаги в нём будут. В данном случае нам нужно смонтировать наш компонент. Будет отображаться только кнопка.
Вторым шагом – нажать на кнопку, третьим шагом – показать loader и ждать, пока у нас загрузится изображение, и в конце проверить то, что на изображении у нас отображается наш котик, то есть проверить source изображения, и убедиться, что там будет то, что мы заранее подготовили.

Возникает вопрос о том, что мы заранее подготовили. Где-то между шагами нам нужно замокать ответ от сервера, чтобы не отправлять реальный запрос в API.
Сам тест можно оформить по обычной схеме в виде дескрайбов и итов. Но в тело теста для удобства можно использовать самописный хелпер step, который позволит нам все эти шаги как-то структурировать и писать не общей кашей, а немного их разделить.
Заготовка для теста:
describe('feature/Сat', () => {
it('должен при нажатии на кнопку загружать нового кота', async () => {
await step('1. Монтируем компонент', () => {});
await step('2. Кликаем по кнопке "Give me a cat"', () => {});
await step('3. Ждем завершение загрузки', () => {});
await step('4. Проверяем появление гифки на странице', () => {});
});
});Также с помощью хелпера можно потом эти красивые шаги перенести в отчёт, чтобы там видеть информацию по каждому шагу, например, сколько каждый шаг выполнялся по времени.
Прежде, чем приступим к написанию самих этих шагов, разберём парочку моментов. Сначала я очень рекомендую создавать отдельный конфиг для Jest для интеграционных тестов, со своими настройками, своей маской для файлов и так далее.
// jest.config.js
if (process.env.INTEGRATION_MODE) {
module.exports.testMatch = ['**/*.intergration.spec.tsx'];
module.exports.setupFiles.push('<rootDir>/tests/global.ts');
// ...
}
В простом кейсе можно не создавать отдельный конфиг, можно просто задать какую-то переменную окружения и уже в существующем конфиге подменять свои настройки. Выше я показал, что обычно для интеграционных тестов задаётся своя маска для файла, .integration.spec.tsx, чтобы их отделять от юнит-тестов.
Дальше нужно подготовить пейдж-объекты. Это такие объекты либо классы, которые позволяют нам инкапсулировать логику работы с нашими дом-узлами или компонентами в едином месте. Покажу это на примере.
const datePickerPO = {
selector: '.date-picker',
open: () => {/*...*/},
setDay: (day: number) => {/*...*/},
close: () => {/*...*/},
}
// ...
datePickerPO.open();
datePickerPO.setDay(5);
datePickerPO.close();Например, у нас есть Datepicker, можем создать обычный объект, DatePickerPO, в нём указать selector, чтобы мы могли найти Datepicker, и методы для открытия попапа, для выбора необходимого дня и для закрытия. Потом в нашем тесте мы будем уже использовать не какие-то методы и селекторы для поиска, а непосредственно уже наш Page Object. Это позволяет сократить и код текста и избавиться от дублирования.
class LoginPagePO extends PagePO {
get username () { return $('#username') }
get password () { return $('#password') }
get submitBtn () { return $('form button[type="submit"]') }
get flash () { return $('#flash') }
get headerLinks () { return $$('#header a') }
async open () {}
async submit () {}
}На самом деле нет определённого формата для описания пейдж-объектов, всё зависит от инструментов, которые вы используете. Например, Page Object может быть классом, который наследуется от какого-то базового пейдж-объекта, и там уже будет задаваться по своей форме.
В нашем же случае пейдж-обжет для приложения с котиком будет выглядеть следующим образом.
У нас есть какие-то методы, чтобы кликнуть по кнопке, метод GetLoader, чтобы получить наш Loader и проверить его, и есть метод, который позволяет ожидать, пока у нас Loader скроется, уйдёт из Dom.
fireEvent, getByTestId, queryByTestId, waitForElementToBeRemoved — места, которые предоставляет как раз testing-library для работы с нашим домом.
export const awesomeCatPO = {
clickToButton() {
fireEvent.click(getByTestId(document.body, 'button'));
},
getLoader() {
return queryByTestId(document.body, "loader");
},
async waitForLoaderHide() {
await waitForElementToBeRemoved(() => {
return this.getLoader()
})
},
// ...
}Клик по кнопке можно заменить на Button Page Object, то есть, пейдж-объекты могут быть вложенные, и в идеале для каждого UI-компонента должен быть написан свой Page Object.
export const awesomeCatPO = {
clickToButton() {
fireEvent.click(getByTestId(document.body, 'button'));
buttonPO.click();
},
getLoader() {
return queryByTestId(document.body, "loader");
},
async waitForLoaderHide() {
await waitForElementToBeRemoved(() => {
return this.getLoader()
})
},
// ...
}
Далее нам нужен Helper для монтирования в Dom. Обычно компоненты не будут работать в изоляции от всего приложения, как бы нам этого ни хотелось. Для этого подготавливается какой-то универсальный Helper, который подготавливает глобальные объекты (например, Store), необходимые для рендеринга компонента, и используются потом уже в тестах.
function mountComponent<P>({ Component, props, state }) {
const store = mockStore();
return {
component: render(
<Provider store={store}>
<Component props={props} />
</Provider>,
),
store,
};
}Разработчики testing-library не предоставили из коробки функциональность, чтобы мы могли искать dom-элементы по CSS-классу либо по индификатору. По мнению разработчиков testing-library, пользователь не ищет элементы по CSS-классу, пользователь ищет элементы по плейсхолдерам, по тексту на кнопках и в тестах нужно это учитывать.
С одной стороны это правда, но с другой, практической стороны искать элементы по тексту/лейблу/плейсхолдеру довольно сложно во многих кейсах. Поэтому можно указывать data-testid атрибут у компонентов, с помощью которого потом можно будет искать элементы в тестах. В нашем случае мы задаём data-testid атрибут для контейнера, лоадера, кнопки и изображения.

В коде это выглядит примерно так.
return (
<div data-tid="awesome-cat">
<img data-tid="image" src={catImageUrl} />
</div>
);
С одной стороны это немного засоряет наш код какой-то тестовой информацией, с другой стороны мы всегда понимаем, на какие элементы у нас завязаны тесты. Если мы что-то меняем, то это значит, что надо поменять и тест. Ещё один плюс — мы не завязываем наш UI именно на вёрстку, то есть после смены местами компонентов, либо изменения классов тест продолжит работать.
В заключение нам нужно замокать всё нужное и ненужное. Нам нужно замокать стили, картинки, внешние API-запросы, какие-то глобальные модули, так как у нас всё должно работать в изоляции. В принципе всё это можно сделать с помощью стандартных средств Jest.
Подытожим, что нужно сделать:
настроить Jest,
написать пейдж-объекты – это можно делать итерационно, если мы пишем тест для кнопки, то и Page Object пишем только для кнопки
написать Helper для монтирования (итерационно)
написать data-testid атрибуты (итерационно),
замокать всё нужное и ненужное,
подключить красивый вывод отчёта (по желанию).
Всё, давайте приступим к шагам. У нас есть уже заготовленный Helper Mount Component, с помощью него монтируем компонент.
await step('1. Монтируем компонент', () => {
mountComponent({
Component: AwesomeCat,
state: {/* ... */},
});
});Второй шаг. У нас есть заготовленный Page Object, нам достаточно вызвать уже готовый метод Click to Button, то есть имитировать кнопку клик по кнопке.
await step('2. Кликаем по кнопке "Give me a cat"', () => {
PO.clickToButton();
});Далее мы мокаем ответ от сервера, в данном случае это достаточно просто сделать с помощью даже встроенных средств Jest. На фрагменте показано, как мы подготавливаем фикстуру ответа от API, который нам предоставляет API.
jest.mock('axios');
function mockGiphyRequst() {
axios.get.mockResolvedValue({/* ... */});
}Третий шаг. Мы ждём завершения загрузки, но вначале проверяем, что Loader в принципе появился. Для этого мы используем наш кастомный Page Object и кастомный Matcher toBeInTheDocument, который предоставляет Jest, и из пейдж-объекта ждём, пока спиннер не скроется.
await step('3. Ждем завершения загрузки', async () => {
expect(PO.getLoader()).toBeInTheDocument();
await PO.waitForLoaderHide();
});На четвёртом шаге мы проверяем то, что у нас появилось изображение, и проверяем поле Source – там мы должны были получить тот путь до изображения, который мы замокали заранее. Всё, мы написали полноценный интеграционный тест с пейдж-объектами, с data-testid атрибутами.
await step('4. Проверяем появление гифки на странице', () => {
expect(PO.getImage()).toBeInTheDocument();
expect(PO.getImage()).toHaveAttribute('src', 'mocked.gif');
});Какие мы ещё получаем дополнительные бонусы от интеграционных тестов? Первое, что мы получаем по сравнению с Е2Е-тестами — очень дешёвую проверку пользовательских сценариев.
Также интеграционные тесты позволяют проверить модульность нашей системы, и если нам при написании какого-то теста приходится замокать всё подряд и использовать кучу модулей от приложений – соответственно, у нас с модульностью что-то не так, модули связаны и, возможно, стоит об этом задуматься.
И ещё один бонус – как и в Е2Е-тестах, шаги для тестов могут нам помогать писать QA-инженеры. В простой схеме можно просто прийти к тестировщику, попросить его накидать тест-кейсов, а можно построить полноценный процесс. Тимлид или бизнес ставит задачу, разработчик выполняет. В это время тестировщик пишет тест-кейсы для наших интеграционных тестов, и в конце в рамках отдельной задачки разработчик по этим написанным кейсам просто реализует наши тесты.
Проблемы интеграционных тестов
Первая проблема – это моки для внешних зависимостей. На реальных тестах у нас скорее всего будет не один запрос, а 2-4 и всё это мокать, подготавливать для этого фикстуры – довольно тяжело.
По своему опыту могу сказать, что появляется очень большой соблазн начать писать какую-то фабрику либо генератор для создания этих фикстур, но потом это всё настолько усложняется, что при написании теста правильно настроить генератор становится сложнее, чем написать сам тест.
Обычно я рекомендую использовать простые json-объекты, то есть самые примитивные фикстуры. Да, они будут немного дублироваться и при изменении API придётся их переделывать, но это сделать намного проще, чем возиться с генераторами.
Следующая проблема — сложность дебага. Так как у нас нет визуальной части, тесты выполняются в NodeJS, то при падении теста нам testing-library любезно предоставит HTML и сообщение об ошибке. На простом примере это не выглядит чем-то проблемным, но когда у нас компоненты сложные, мы получаем огромную портянку кода и ошибочку (кнопка не нажалась или элемент не появился), в этом довольно сложно разбираться.
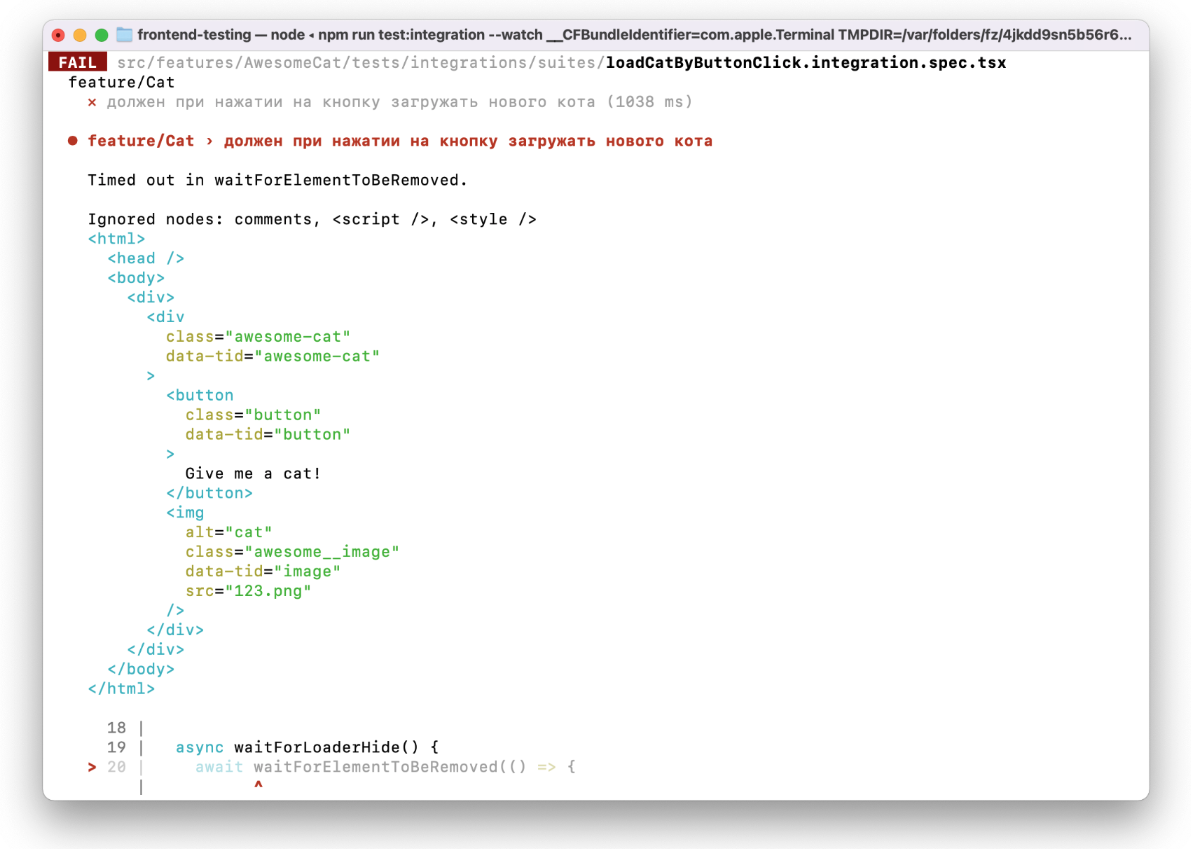
Но есть хорошее решение jest-preview, которое локально позволит запустить браузер и прогнать наш интеграционный тест прямо там. Нужно будет немного помучаться с настройкой, потому что нам нужно полностью собрать приложение, с CSS и картинками, но это того стоит.
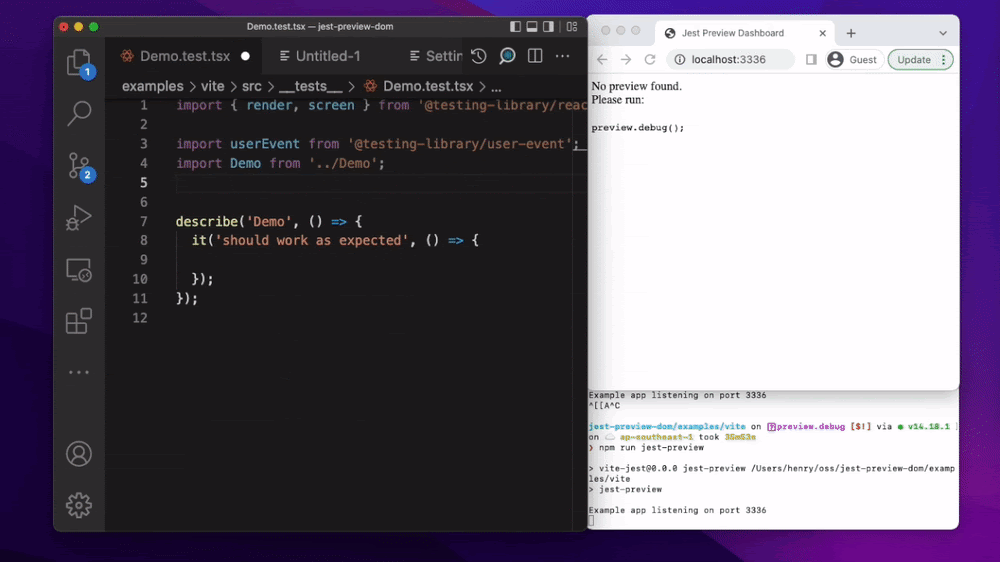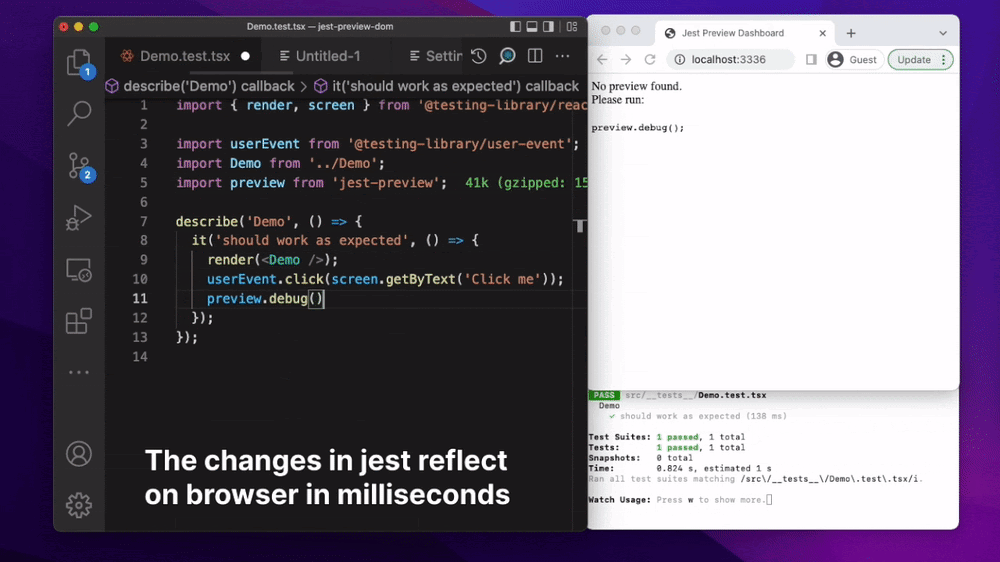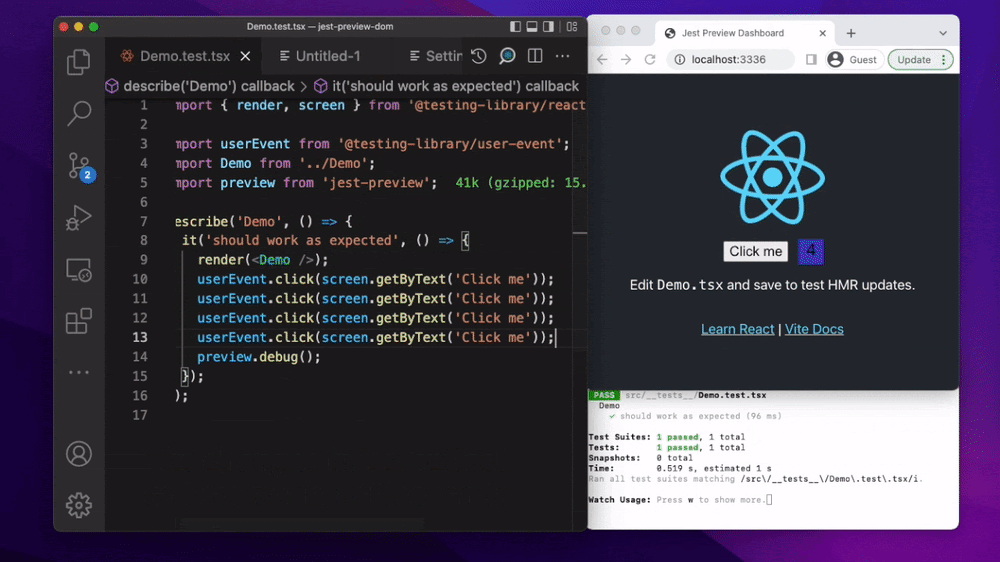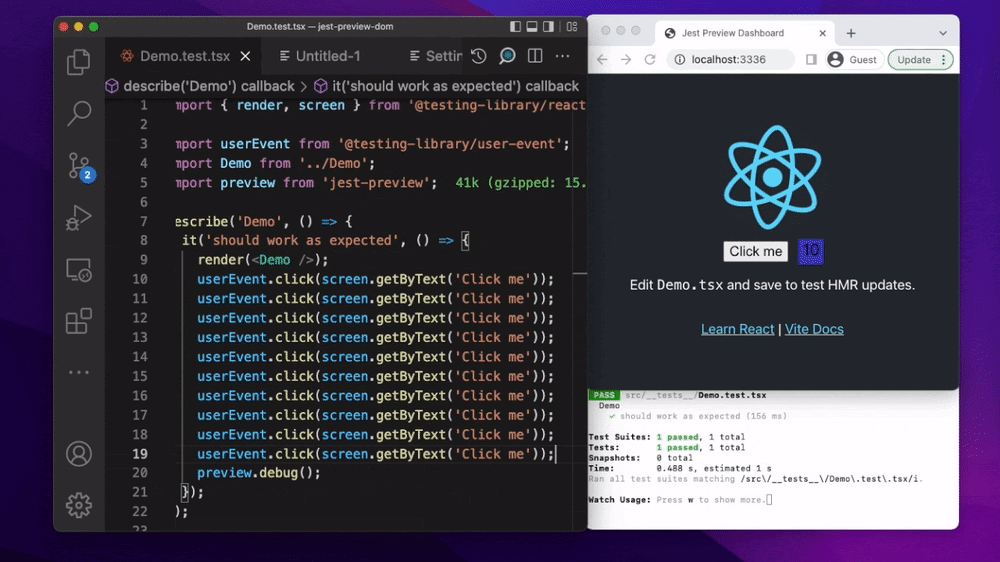
Ещё одна особенность интеграционных тестов – это отсутствие визуальной части. На NodeJS, например, на какой-нибудь форме регистрации кнопка с регистрацией может просто быть скрыта обычным CSS, либо перекрываться другим блоком.
Чтобы решить эту проблему, обычно вводят дополнительный слой тестирования – так называемые «скриншотные тесты». Они позволяют отрендерить компонент в браузере, возможно, в headless browser, сгенерировать скриншот и потом этот скриншот сравнивать с новыми полученными скриншотами.

На мой взгляд, скриншотные тесты обязательны для UIKit и для каких-то продуктовых сложных компонентов. Их фишка в том, что данные тесты могут использовать заготовленные для нас хелперы, data-testid атрибуты из интеграционных тестов.
Ниже пример скриншотного теста. Мы используем кастомный Matcher для того чтобы делать скриншот.
describe('feature/Сat', () => {
it('должен рендерить в начальном состоянии', async () => {
mountComponent({ Component: AwesomeCat });
expect(await page.screenshot()).toMatchImageSnapshot();
});
});Финальные напутствия по части тестов для фронтенда
В заключение я собрал немного информации и видео по теме.
Мои заметки в телеграме: RTL и Как пишем компонентные тесты.
Доклад с конференции “Подлодка” про эффективное тестирование.
Доклад про testing-library от моего бывшего коллеги Василия Кузенкова.
Доклад с HolyJS про скриншотное тестирование.
Код проекта, на примере которого мы разбирались с тестами в это статье – я выложил на GitHub, заглядывайте.
Если вы на своём проекте не пишете юнит-тесты, то попробуйте написать. Я уверен, что у вас есть какой-то фрагмент кода, про который никто не знает, как он работает, либо постоянно там случаются какие-то баги. Я думаю, если вы напишете юнит-тесты, то ваша команда будет вам благодарна.
Если есть время, то можно попробовать написать интеграционный тест. По секрету скажу, что необязательно описывать пейдж-объекты, data-testid атрибуты и всё остальное; достаточно подключить testing-library и начать тестировать какие-то пользовательские сценарии на небольших компонентах. Если у вас есть в проекте UIKit, попробуйте скриншотные тесты.
Как писал Кент Си Доддс: «Пишите тесты, не слишком много, и больше интеграционных». Спасибо, что прочитали!
