Привет, Хабр! В данной статье мы, консультанты практики аналитики департамента поддержки продаж, рассмотрим важность корректной оценки качества моделирования при решении аналитических задач. В рамках нашей работы нам часто приходится решать задачи построения прогнозных моделей на данных заказчика. При этом, от заказчиков может приходить не только описание аналитической задачи, но и процедура оценки качества разработанных моделей. И иногда бывает так, что заказчик предлагает сравнить ежа с ужом. Чаще всего с таким можно встретиться, когда данные заранее разделены на обучающую и тестовую выборки, потому что сбор данных для обеих выборок может незначительно отличаться.
Именно такая ситуация была у нас в одном из кейсов, где заказчик хотел проверить “силу” таргетированных коммуникаций.

Банк провел разовую кампанию, в рамках которой обзванивал часть своих клиентов (~10тыс. клиентов) и предлагал купить определенный кредитный продукт. По окончании кампании были собраны данные об отклике на коммуникации. Банк описал нам не только саму задачу, которую необходимо решить, но также указал, как и на каких данных нужно строить модель, а также как проверять качество.
Что требовалось от нас:
Качество построенной модели предполагалось проверять на клиентах, которые участвовали в кампании. Т.е. если модель предсказывает, что клиент склонен к покупке кредитного продукта и по результатам коммуникации у этого клиента получился положительный отклик, то считается, что модель корректно предсказала отклик.
Уже на этапе обсуждения способа оценки качества было высказано опасение о некорректности такого способа оценки. Причины некорректности две.
Во-первых, разные целевые переменные на этапе построения модели и на этапе оценки её качества. Строится модель прогнозирования факта подачи заявки на кредитный продукт без какой-либо коммуникации, а качество проверяется по результатам применения модели к задаче прогнозирования отклика на коммуникацию.
Во-вторых, клиенты, которые участвовали в кампании могли сильно отличатся от всех клиентов (т.к. разумно предполагать, что для участия в кампании клиенты отбирались по некоторым критериям).
Несмотря на опасения, мы договорились попробовать построить модель с текущей постановкой задачи. Однако мы запросили часть данных с результатами обзвона по клиентам для использования в качестве независимой (тестовой) выборки.
Пока ждали часть данных с результатами обзвона, построили модель на клиентах, которые не участвовали в кампании (~200тыс. клиентов, около 5% купили кредитный продукт). Получились хорошие результаты (Gini ~ 0.75 на обучающей, валидационной и тестовой выборках).
Позже нам выгрузили данные по части клиентов, которые участвовали в кампании. К этим данным применили прежде построенную модель. При применении модели к этой части выборки результаты оставляли желать лучшего (Gini = 0.16).
Начали разбираться с выборкой клиентов, которые участвовали в кампании, и обнаружили, что распределение данных во многих переменных абсолютно не совпадает с распределением данных клиентов, которые не участвовали в кампании.
Отсюда объяснение плохих результатов. Попробовали построить модель на той части клиентов, которые участвовали в кампании (около 5тыс. – отклик = 8%). Результат плохой (недостаточно данных – плохие показатели качества — Gini ~0.3).
В итоге было выдвинуто несколько предположений скудного результата моделирования:
Коллегам из банка были представлены вышеизложенные доводы и задачу было решено переделать.
В новой постановке задачи от нас требовалось предсказать отклик на регулярную кампанию. Однако в этот раз у нас были данные по коммуникациям по этой же кампании ранее. В итоге получился успешный проект (удалось увеличить отклик более чем в 2 раза).
В итоге возвращаемся к основам моделирования:
Именно такая ситуация была у нас в одном из кейсов, где заказчик хотел проверить “силу” таргетированных коммуникаций.

Постановка задачи
Банк провел разовую кампанию, в рамках которой обзванивал часть своих клиентов (~10тыс. клиентов) и предлагал купить определенный кредитный продукт. По окончании кампании были собраны данные об отклике на коммуникации. Банк описал нам не только саму задачу, которую необходимо решить, но также указал, как и на каких данных нужно строить модель, а также как проверять качество.
Что требовалось от нас:
- Построить модель для предсказания отклика на коммуникацию.
- Для построения модели использовать данные по клиентам, которые не участвовали в кампании. Для этого банк выдал нам обезличенные данные по всем клиентам, исключив из выборки тех клиентов, которые участвовали в разовой кампании.
- В качестве целевого события при построении модели использовать факт подачи заявки на кредитный продукт, который предлагался в рамках кампании.
Качество построенной модели предполагалось проверять на клиентах, которые участвовали в кампании. Т.е. если модель предсказывает, что клиент склонен к покупке кредитного продукта и по результатам коммуникации у этого клиента получился положительный отклик, то считается, что модель корректно предсказала отклик.
Первые опасения
Уже на этапе обсуждения способа оценки качества было высказано опасение о некорректности такого способа оценки. Причины некорректности две.
Во-первых, разные целевые переменные на этапе построения модели и на этапе оценки её качества. Строится модель прогнозирования факта подачи заявки на кредитный продукт без какой-либо коммуникации, а качество проверяется по результатам применения модели к задаче прогнозирования отклика на коммуникацию.
Во-вторых, клиенты, которые участвовали в кампании могли сильно отличатся от всех клиентов (т.к. разумно предполагать, что для участия в кампании клиенты отбирались по некоторым критериям).
Несмотря на опасения, мы договорились попробовать построить модель с текущей постановкой задачи. Однако мы запросили часть данных с результатами обзвона по клиентам для использования в качестве независимой (тестовой) выборки.
Моделирование
Пока ждали часть данных с результатами обзвона, построили модель на клиентах, которые не участвовали в кампании (~200тыс. клиентов, около 5% купили кредитный продукт). Получились хорошие результаты (Gini ~ 0.75 на обучающей, валидационной и тестовой выборках).
Позже нам выгрузили данные по части клиентов, которые участвовали в кампании. К этим данным применили прежде построенную модель. При применении модели к этой части выборки результаты оставляли желать лучшего (Gini = 0.16).
Распределения

Начали разбираться с выборкой клиентов, которые участвовали в кампании, и обнаружили, что распределение данных во многих переменных абсолютно не совпадает с распределением данных клиентов, которые не участвовали в кампании.
Примерно так выглядели распределения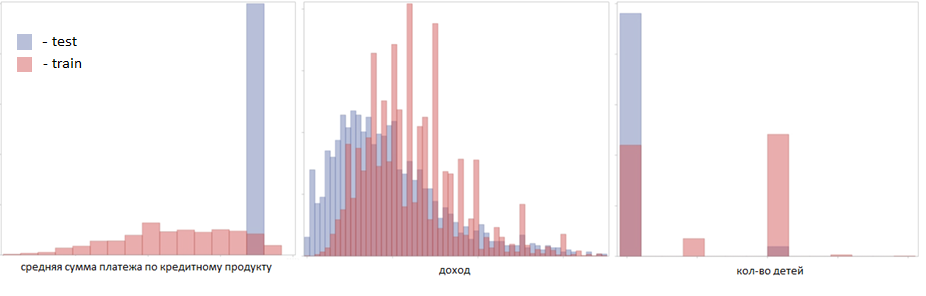
NDA не позволяет оставить отметки на осях.

NDA не позволяет оставить отметки на осях.
Отсюда объяснение плохих результатов. Попробовали построить модель на той части клиентов, которые участвовали в кампании (около 5тыс. – отклик = 8%). Результат плохой (недостаточно данных – плохие показатели качества — Gini ~0.3).
Проблемы
В итоге было выдвинуто несколько предположений скудного результата моделирования:
- Разные целевые переменные (помним, что обучаемся определять склонность к покупке кредитного продукта, а предсказываем отклик на коммуникацию).
- Выборка клиентов, участвовавших в кампании, сформирована не случайным образом, из-за чего распределения предикторов в ней может отличаться от распределения в генеральной совокупности всех клиентов банка.
- в выборке клиентов, не участвовавших в кампании, присутствуют клиенты, которые не могут подавать заявки на кредит
- у клиентов, участвовавших в кампании, практически отсутствуют кредитные продукты: лишь у 2% есть записи в истории кредитных платежей, против 19% клиентов, не участвовавших в кампании.
- Недостаточно данных по результатам кампании для того, чтобы использовать их для построения модели.
Решение проблем
- Необходимо всегда в самом начале определять корректные критерии оценки результата.
- Целевые переменные должны быть одинаковые.
- Данные, на которых предлагают обучатся, и на которых предлагают тестировать результат, должны быть из одной генеральной совокупности.
- Необходимо заранее обсуждать рамки проекта (и чтобы они распространялись на обучающие и тестовые выборки).
- Недостаток данных – либо изменение задачи (чтобы было достаточно), либо ожидание новых коммуникаций.
Итог
Коллегам из банка были представлены вышеизложенные доводы и задачу было решено переделать.
В новой постановке задачи от нас требовалось предсказать отклик на регулярную кампанию. Однако в этот раз у нас были данные по коммуникациям по этой же кампании ранее. В итоге получился успешный проект (удалось увеличить отклик более чем в 2 раза).
Выводы
В итоге возвращаемся к основам моделирования:
- Необходимо всегда понимать совпадает ли то, что мы моделируем, с тем, что хочет от нас заказчик. В данном случае, чтобы предсказать отклик на коммуникации необходимо было иметь данные по коммуникациям.
- Данные должны быть из одной генеральной совокупности. Если модель будет обучаться на одних закономерностях, а в тестовой выборке сталкиваться с другими закономерностями, то мало шансов получить хороший показатель качества на тестовой выборке.
