В предыдущей статье мы изучили, как читать внешние необработанные данные. А сегодня познакомимся с оператором SET, который считывает стандартные наборы данных SAS (SAS Data Set), научимся создавать срезы данных, настраивать постоянные атрибуты, а также изучим несколько полезных функций SAS. Я снова постараюсь изложить материал максимально простым языком, используя как можно больше примеров.

 Допустим данные хранятся в формате EXCEL в директории C:\workshop\habrahabr. Импортируем электронную таблицу, создадим из нее срез, создадим новые вычисляемые столбцы, используя функции SAS, а затем разобьем данный набор данных на два.
Допустим данные хранятся в формате EXCEL в директории C:\workshop\habrahabr. Импортируем электронную таблицу, создадим из нее срез, создадим новые вычисляемые столбцы, используя функции SAS, а затем разобьем данный набор данных на два.

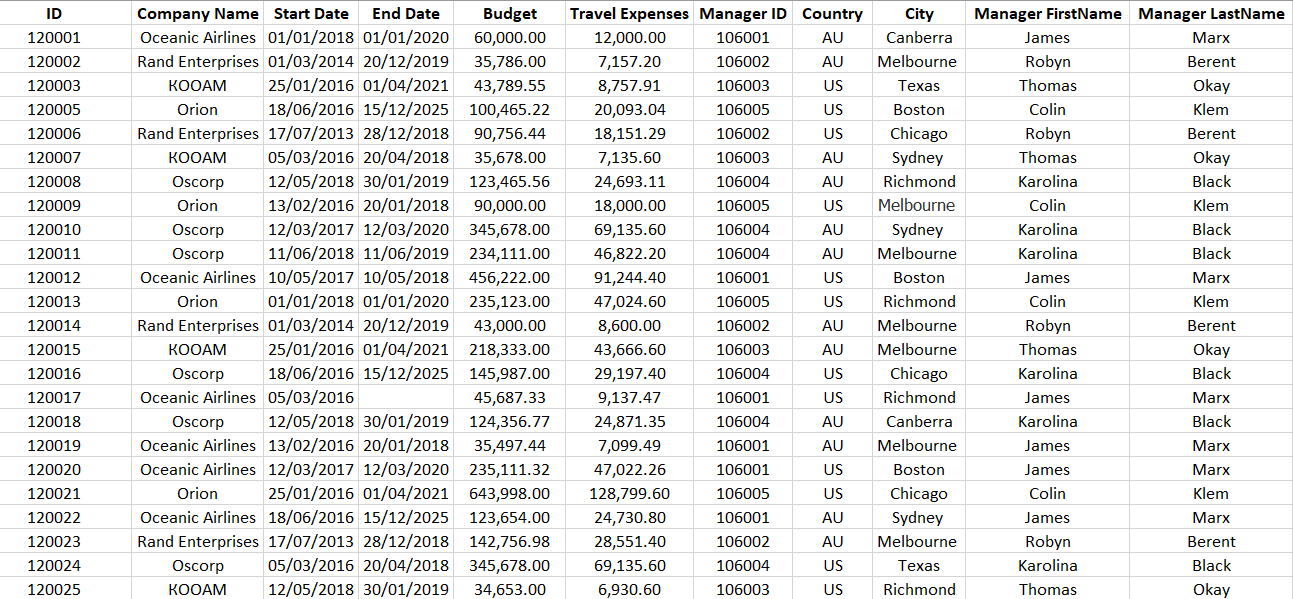
Файл excel хранится в указанной выше директории и имеет следующий вид:
Фрагмент файла:
Применим процедуру PROC IMPORT для преобразование электронной таблицы в набор данных SAS:
Опция validvarname=V7 задает «правильные» с точки зрения SAS имена полей: все недопустимые символы заменяет знаками нижнего подчеркивания. О правилах именования переменных можно прочитать в Уроке 1.
Зададим фильтр сразу при чтении внешнего файла, например, выберем только те наблюдения, в которых дата окончания работ не пропущена. Обратите внимание, на синтаксис параметра where.
Рассмотрим детально операторы шага PROC IMPORT:
Datafile – определяет полный путь и имя внешнего файла
Dbms — определяет тип данных для импорта.
Out – идентифицирует выходной набор данных SAS с одно- или двухуровневым именем SAS (имя библиотеки и имя набора данных).
Replace – перезаписывает существующий набор данных SAS.
Getnames – Указывает, генерирует ли PROC IMPORT имена переменных SAS из значений данных в первой строке во входном внешнем файле.
Запустим шаг PROC IMPORT и изучим LOG:
Распечатаем полученный набор данных SAS:
Вывод процедуры PROC PRINT показан ниже:
Фрагмент:

Также в SAS UE вы можете воспользоваться вкладкой «Результаты» и ознакомиться с импортированным набором данных SAS.


Чтение набора данных SAS реализуется на шаге DATA с помощью оператора SET:
Рассмотрим общий синтаксис оператора SET:
Если вы не указываете в операторе SET набор данных, то он читает наблюдения из последнего созданного набора данных SAS.
В операторе SET можно указать несколько наборов данных, в этом случае SAS Data Sets допишутся один под другой (аналог UNION в SQL).
Также на шаге DATA может быть два оператора SET, в этом случае таблицы объединяются по общему столбцу. Подробнее о двух операторах SET можно прочитать, например, в этой статье.
Простейший код, создающий копию набора данных SAS, выглядит следующим образом:
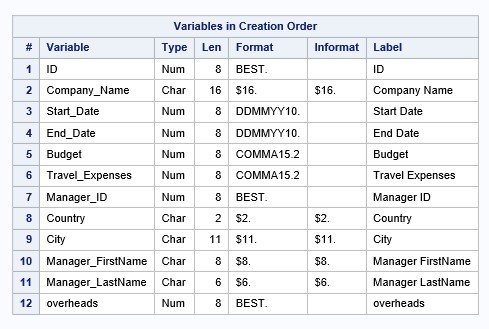
Изучить дескриптор набора данных SAS можно с помощью процедуры PROC CONTENTS (см. Урок 2). В данном уроке, мы распечатаем компоненту дескриптора с помощью процедуры PROC DATASETS:
Фрагмент результатов:
Зададим постоянный формат для переменных Travel_Expenses и Budget:
Проверим атрибуты наборы данных SAS:

Все функции SAS можно можно изучить в справочнике SAS 9.4 Functions and CALL Routines: Reference, Fifth Edition .
Кроме того, если нет подходящей функции для выполнения той или иной задачи, можно воспользоваться процедурой PROC FCMP и создать свою функцию.
В рамках данного урока мы изучим три функции YRDIF, SUM и CATS.
Для подсчета разницы в датах в годах мы будем использовать функцию YRDIF.
Напомню, что дата в формате SAS представляет собой количество дней, начиная с 01 января 1960 года (см. Урок 1). На представленных данных, нам необходимо вычислить время выполнения работ:
Обратите внимание, что с помощью формата 3.1 для переменной Lead_Time, мы округлили вычисленные значения в отчете (!) до 1 знака после запятой. Оператор формат не меняет значения в наборе данных SAS!
Фрагмент результатов:

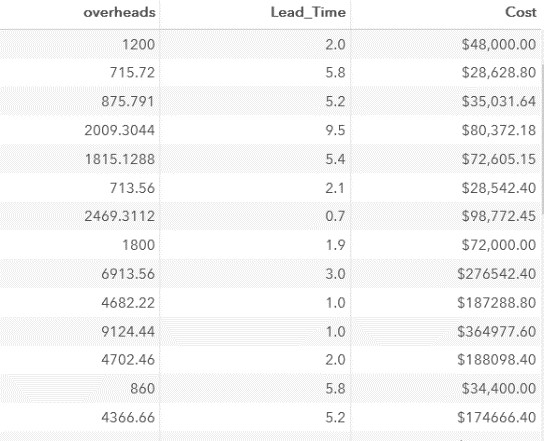
Далее вычислим стоимость работ без командировочных расходов:
Фрагмент результатов:
В рамках нашей задачи стоимость работ без учета командировочных расходов мы вычислили без использования функции. В нашей таблице нет пропущенных значений, если бы одна из переменных (Budget или Travel_Expenses) имела бы пропущенное значение, результатом был «миссинг».
Например:
Создадим тестовый набор данных:
Вычислим разницу переменных Budget Travel_Expenses
Результат выполнения данного шага:
Для того, чтобы получить корректный результат, можно использовать функцию SUM.
Данная функция относится к категории функций описательной статистики. Функции описательной статистики игнорируют пропущенные значения.
Написание кода через SUM:
В этом случае результат выполнения шага выглядит следующим образом:

Третий вычисляемый столбец – это адрес электронной почты менеджера. Его можно «собрать» из столбцов Manager_FirstName, Manager_LastName и значения habr.com
Для объединения текстовых значений в одну строку можно использовать функцию CATS.
Фрагмент результатов:
Изучим дескриптор созданного набора данных:
Фрагмент дескриптора:
Обратите внимание на длину переменной Email.Она составляет 200 байт, это длина, возвращаемая по умолчанию функцией CATS. Если изучить атрибуты переменных Manager_FirstName и Manager_LastName, то мы можем убедиться, что на переменную Email достаточно 8+6+длина строки ‘@habr.com’, то есть еще 9 байт, итого 23. Почему стоит на это обратить внимание? Все недостающие символы добиваются пробелами, что сказывается на размере набора данных и на больших объемах данных будет сказываться на производительности.
Для того, чтобы задать длину переменной Email явно, необходимо использовать оператор LENGTH:
Фрагмент дескриптора

Создадим детализированный столбец на основании переменной Lead_Time, учитывая следующие условия:
Создать детализированный столбец можно разными способами, например, самый простой и очевидный вариант — использовать условную обработку. Её можно реализовать с помощью следующих операторов:
На больших объемах данных эффективнее использовать последние два варианта.
Добавим условие, которое выбирает только те наблюдения, в которых значение переменной Detail не равно ‘above 5 years’. При использовании where в качестве фильтра будет возникать синтаксическая ошибка:

Оператор where не используется для вычисляемых столбцов. Для отбора нужных нам переменных необходим выборочный оператор IF. Он отменяет вывод наблюдения в создаваемый набор данных:
Обратите также внимание, что выборочный оператор IF требует арифметический оператор. Мы не можем написать, например, так:
В Log выведется ошибка:

В новом наборе данных SAS не должны присутствовать переменные Manager_FirstName и Manager_LastName. Данное требование реализуется с помощью параметра DROP, так же можно использовать оператор DROP.
Разбиваем созданный набор данных SAS на два по заданному условию
На одном шаге DATA можно создать несколько наборов данных SAS. Создадим для каждой страны отдельный набор данных.
Чтобы проверить, какие значения есть в столбце Country, можно, например, использовать процедуру PROC FREQ.
Данный шаг считает, сколько раз то или иное значение из переменной Country встречается в указанном в параметре data= наборе данных SAS.
Результат выполнения данного шага будет следующим:
Итак, создадим два набора данных на одном шаге DATA, используя оператор OUTPUT и условную обработку:
Запустим код и посмотрим LOG:

Это кратко о чтении наборов данных SAS и их настройке. В следующей статье мы познакомимся с Вами с объединением наборов данных с помощью операторов MERGE и SET.
А в качестве P.S. напомню структуру наших уроков по SAS BASE:
Статьи, которые уже опубликованы:
В следующих статьях хочется осветить такие вопросы, как объединение таблиц в SAS Base (merge, set), условная обработка, циклы, функции SAS, создание пользовательских форматов, SAS Macro, PROC SQL.
 Буду рада обратной связи в комментариях! Какие еще темы Вы хотели бы увидеть в статьях?
Буду рада обратной связи в комментариях! Какие еще темы Вы хотели бы увидеть в статьях?


Импорт электронной таблицы и задание фильтра

Файл excel хранится в указанной выше директории и имеет следующий вид:
Фрагмент файла:

Применим процедуру PROC IMPORT для преобразование электронной таблицы в набор данных SAS:
options validvarname=v7;
proc import datafile="C:\workshop\habrahabr\company.xlsx"
dbms=xlsx
out=company
replace;
getnames=yes;
run;Опция validvarname=V7 задает «правильные» с точки зрения SAS имена полей: все недопустимые символы заменяет знаками нижнего подчеркивания. О правилах именования переменных можно прочитать в Уроке 1.
Зададим фильтр сразу при чтении внешнего файла, например, выберем только те наблюдения, в которых дата окончания работ не пропущена. Обратите внимание, на синтаксис параметра where.
options validvarname=v7;
proc import datafile="C:\workshop\habrahabr\company.xlsx"
dbms=xlsx
out=company (where=(End_Date not is missing))
replace;
getnames=yes;
run;
Рассмотрим детально операторы шага PROC IMPORT:
Datafile – определяет полный путь и имя внешнего файла
Dbms — определяет тип данных для импорта.
Out – идентифицирует выходной набор данных SAS с одно- или двухуровневым именем SAS (имя библиотеки и имя набора данных).
Replace – перезаписывает существующий набор данных SAS.
Getnames – Указывает, генерирует ли PROC IMPORT имена переменных SAS из значений данных в первой строке во входном внешнем файле.
Запустим шаг PROC IMPORT и изучим LOG:

Распечатаем полученный набор данных SAS:
proc print data=work.company noobs;
run;Вывод процедуры PROC PRINT показан ниже:
Фрагмент:
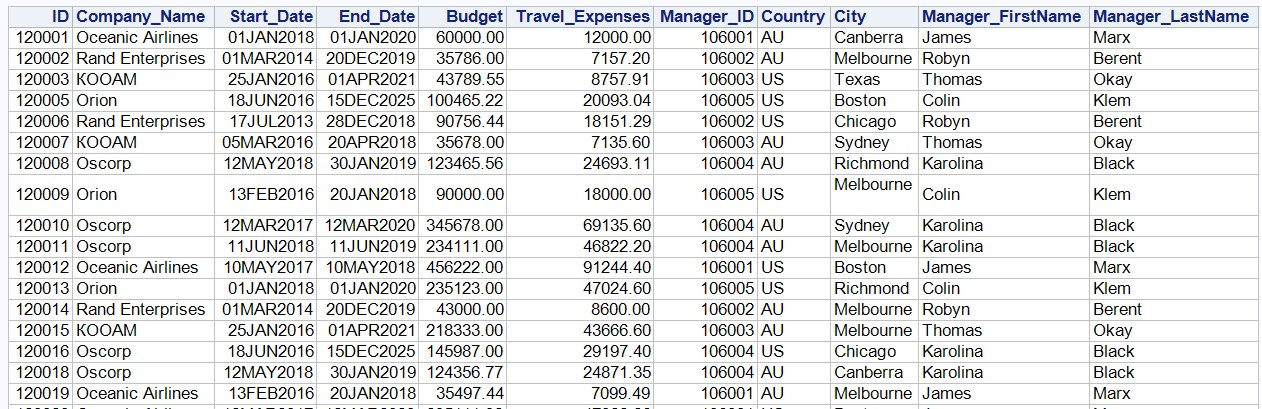
Также в SAS UE вы можете воспользоваться вкладкой «Результаты» и ознакомиться с импортированным набором данных SAS.

Чтение наборов данных SAS

Чтение набора данных SAS реализуется на шаге DATA с помощью оператора SET:
Рассмотрим общий синтаксис оператора SET:
SET<SAS-data-set(s) <(data-set-options(s) )> > <options>;Если вы не указываете в операторе SET набор данных, то он читает наблюдения из последнего созданного набора данных SAS.
В операторе SET можно указать несколько наборов данных, в этом случае SAS Data Sets допишутся один под другой (аналог UNION в SQL).
Также на шаге DATA может быть два оператора SET, в этом случае таблицы объединяются по общему столбцу. Подробнее о двух операторах SET можно прочитать, например, в этой статье.
Простейший код, создающий копию набора данных SAS, выглядит следующим образом:
data company1;
set company;
run;Настройка дескриптора набора данных SAS
Изучить дескриптор набора данных SAS можно с помощью процедуры PROC CONTENTS (см. Урок 2). В данном уроке, мы распечатаем компоненту дескриптора с помощью процедуры PROC DATASETS:
proc datasets library=work nolist;
contents data=company order=varnum;
quit;Фрагмент результатов:
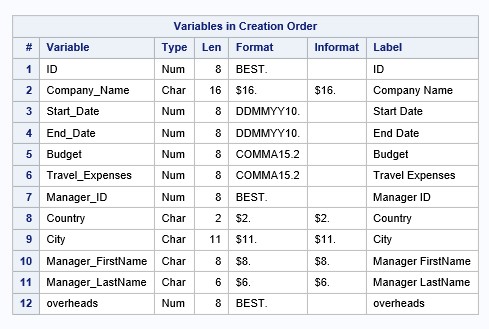
Зададим постоянный формат для переменных Travel_Expenses и Budget:
data company;
set company;
format Travel_Expenses Budget dollar10.2;
run;Проверим атрибуты наборы данных SAS:
proc datasets library=work nolist;
contents data=company order=varnum;
quit;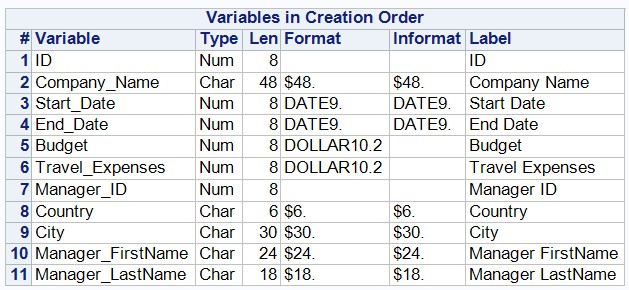
Создание вычисляемых столбцов
Все функции SAS можно можно изучить в справочнике SAS 9.4 Functions and CALL Routines: Reference, Fifth Edition .
Кроме того, если нет подходящей функции для выполнения той или иной задачи, можно воспользоваться процедурой PROC FCMP и создать свою функцию.
В рамках данного урока мы изучим три функции YRDIF, SUM и CATS.
Для подсчета разницы в датах в годах мы будем использовать функцию YRDIF.
Напомню, что дата в формате SAS представляет собой количество дней, начиная с 01 января 1960 года (см. Урок 1). На представленных данных, нам необходимо вычислить время выполнения работ:
data company1;
set work.company;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
format Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
run;
Обратите внимание, что с помощью формата 3.1 для переменной Lead_Time, мы округлили вычисленные значения в отчете (!) до 1 знака после запятой. Оператор формат не меняет значения в наборе данных SAS!
Фрагмент результатов:
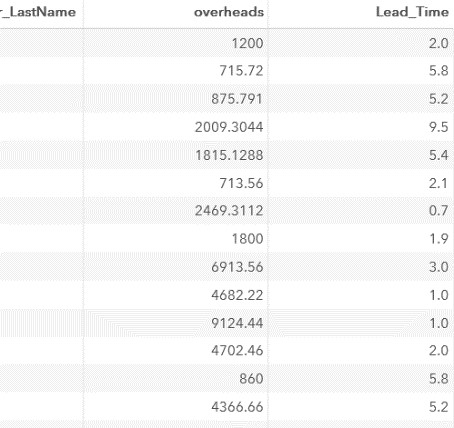
Далее вычислим стоимость работ без командировочных расходов:
data company1;
set work.company;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
run;Фрагмент результатов:
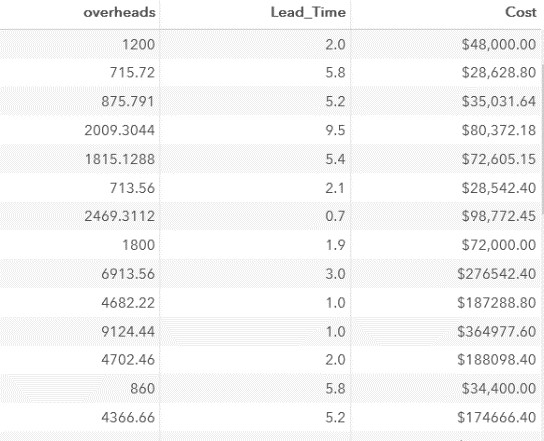
В рамках нашей задачи стоимость работ без учета командировочных расходов мы вычислили без использования функции. В нашей таблице нет пропущенных значений, если бы одна из переменных (Budget или Travel_Expenses) имела бы пропущенное значение, результатом был «миссинг».
Например:
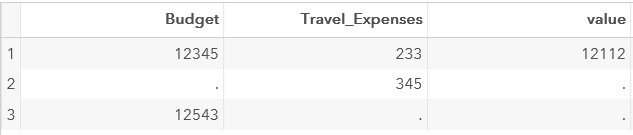
Создадим тестовый набор данных:
data test;
input Budget Travel_Expenses;
datalines;
12345 233
. 345
12543 .
;Вычислим разницу переменных Budget Travel_Expenses
data test;
set test;
value=Budget-Travel_Expenses;
run;Результат выполнения данного шага:
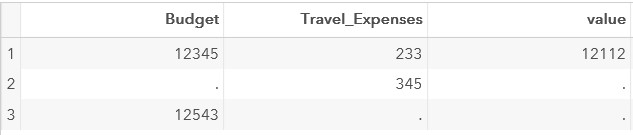
Для того, чтобы получить корректный результат, можно использовать функцию SUM.
Данная функция относится к категории функций описательной статистики. Функции описательной статистики игнорируют пропущенные значения.
Написание кода через SUM:
data test;
set test;
value=sum(Budget,-Travel_Expenses);
run;В этом случае результат выполнения шага выглядит следующим образом:
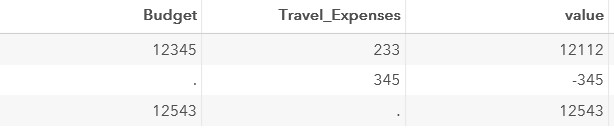
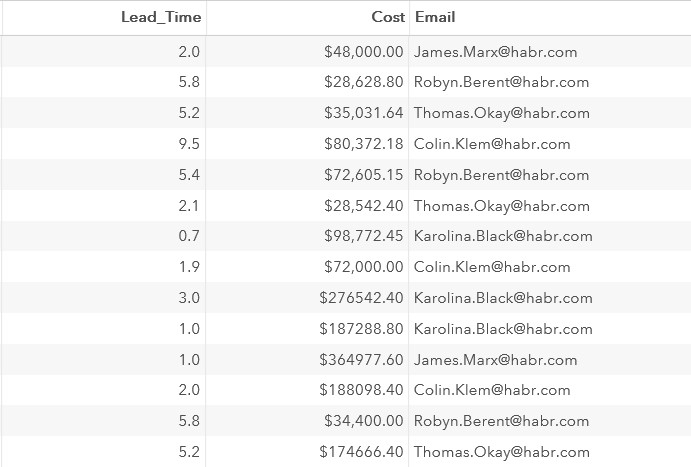
Третий вычисляемый столбец – это адрес электронной почты менеджера. Его можно «собрать» из столбцов Manager_FirstName, Manager_LastName и значения habr.com
Для объединения текстовых значений в одну строку можно использовать функцию CATS.
data company1;
set work.company;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com');
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
run;Фрагмент результатов:
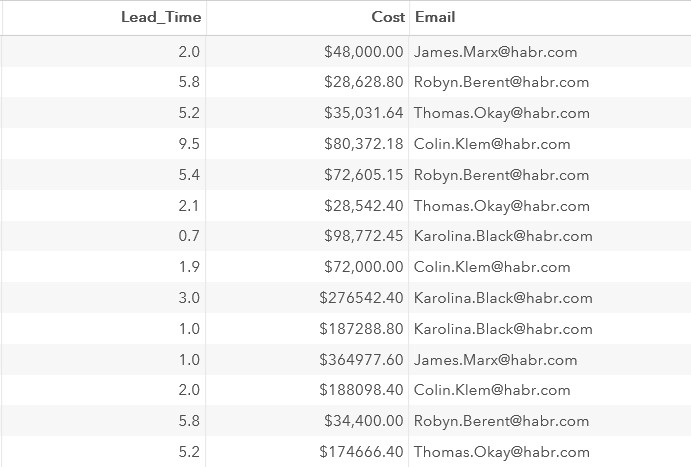
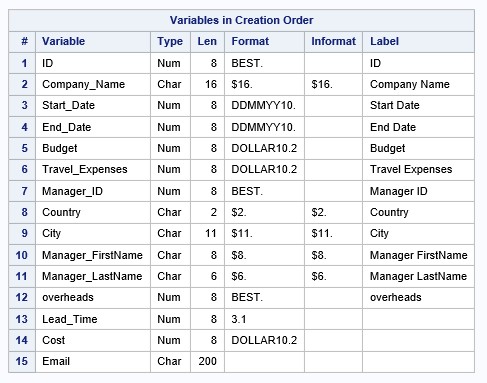
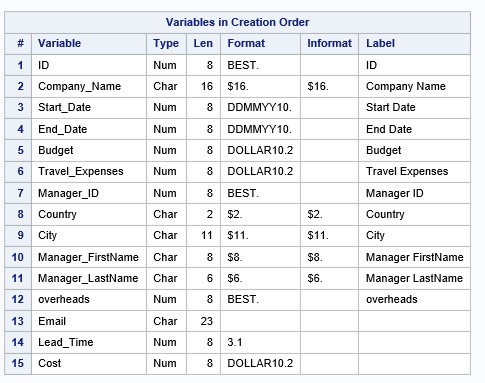
Изучим дескриптор созданного набора данных:
proc contents data=work.company1 varnum;
run;Фрагмент дескриптора:

Обратите внимание на длину переменной Email.Она составляет 200 байт, это длина, возвращаемая по умолчанию функцией CATS. Если изучить атрибуты переменных Manager_FirstName и Manager_LastName, то мы можем убедиться, что на переменную Email достаточно 8+6+длина строки ‘@habr.com’, то есть еще 9 байт, итого 23. Почему стоит на это обратить внимание? Все недостающие символы добиваются пробелами, что сказывается на размере набора данных и на больших объемах данных будет сказываться на производительности.
Для того, чтобы задать длину переменной Email явно, необходимо использовать оператор LENGTH:
data company1;
set work.company;
length Email $23;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com');
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
run;
Фрагмент дескриптора
Создадим детализированный столбец на основании переменной Lead_Time, учитывая следующие условия:
- Если значение переменной Lead_Time менее 1, то столбец Detail имеет значение less than 1 year.
- Если значение переменной Lead_Time в диапазоне от 1 до 2, включая границы, то столбец Detail имеет значение 1-2 years.
- Если значение переменной Lead_Time в диапазоне от 2 до 3, исключая 2, то столбец Detail имеет значение 2-3 years.
- Если значение переменной Lead_Time в диапазоне от 3 до 4, исключая 3, то столбец Detail имеет значение 3-4 years.
- Если значение переменной Lead_Time в диапазоне от 4 до 5, исключая 4, то столбец Detail имеет значение 4-5 years.
- Во всех остальных случаях столбец Detail имеет значение above 5 years.
Создать детализированный столбец можно разными способами, например, самый простой и очевидный вариант — использовать условную обработку. Её можно реализовать с помощью следующих операторов:
- IF-THEN-ELSE
- ELSE IF
- SELECT-WHEN
На больших объемах данных эффективнее использовать последние два варианта.
data company1;
set work.company;
length Email $23;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com');
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
if Lead_Time<1 then detail='less than a year';
else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years';
else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years';
else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years';
else if Lead_Time>4 and Lead_Time<=5 then detail='4-5 years';
else detail='above 5 years';
run;Добавим условие, которое выбирает только те наблюдения, в которых значение переменной Detail не равно ‘above 5 years’. При использовании where в качестве фильтра будет возникать синтаксическая ошибка:

Оператор where не используется для вычисляемых столбцов. Для отбора нужных нам переменных необходим выборочный оператор IF. Он отменяет вывод наблюдения в создаваемый набор данных:
data company1;
set work.company;
length Email $23;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com');
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
if Lead_Time<1 then detail='less than a year';
else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years';
else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years';
else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years';
else if Lead_Time>4 and Lead_Time<=5 then detail='2-3 years';
else detail='above 5 years';
if detail ne 'above 5 years';
run;Обратите также внимание, что выборочный оператор IF требует арифметический оператор. Мы не можем написать, например, так:
if detail contains 'above 5 years';В Log выведется ошибка:

Настраиваем набор данных SAS.
В новом наборе данных SAS не должны присутствовать переменные Manager_FirstName и Manager_LastName. Данное требование реализуется с помощью параметра DROP, так же можно использовать оператор DROP.
data company1 (drop=Manager_FirstName Manager_LastName);
set work.company;
length Email $23;
Lead_Time=yrdif(Start_Date, End_Date, 'actual');
Cost=Budget-Travel_Expenses;
Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com');
format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1;
if Lead_Time<1 then detail='less than a year';
else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years';
else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years';
else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years';
else if Lead_Time>4 and Lead_Time<=5 then detail='2-3 years';
else detail='above 5 years';
if detail ne 'above 5 years';
run;Разбиваем созданный набор данных SAS на два по заданному условию
На одном шаге DATA можно создать несколько наборов данных SAS. Создадим для каждой страны отдельный набор данных.
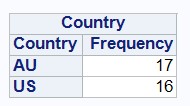
Чтобы проверить, какие значения есть в столбце Country, можно, например, использовать процедуру PROC FREQ.
proc freq data=company1;
table Country /nocum nopercent;
run;Данный шаг считает, сколько раз то или иное значение из переменной Country встречается в указанном в параметре data= наборе данных SAS.
Результат выполнения данного шага будет следующим:

Итак, создадим два набора данных на одном шаге DATA, используя оператор OUTPUT и условную обработку:
data US AU;
set work.company1;
if Country='AU' then output AU;
if Country='US' then output US;
run;Запустим код и посмотрим LOG:

Это кратко о чтении наборов данных SAS и их настройке. В следующей статье мы познакомимся с Вами с объединением наборов данных с помощью операторов MERGE и SET.
А в качестве P.S. напомню структуру наших уроков по SAS BASE:
Статьи, которые уже опубликованы:
- Основы программирования на SAS BASE. Урок 1.
- Основы программирования на SAS BASE. Урок 2. Доступ к данным
- Основы программирования на SAS BASE. Урок 3. Чтение текстовых файлов.
- С четвертым уроком вы только что ознакомились.
В следующих статьях хочется осветить такие вопросы, как объединение таблиц в SAS Base (merge, set), условная обработка, циклы, функции SAS, создание пользовательских форматов, SAS Macro, PROC SQL.
 Буду рада обратной связи в комментариях! Какие еще темы Вы хотели бы увидеть в статьях?
Буду рада обратной связи в комментариях! Какие еще темы Вы хотели бы увидеть в статьях?