
Добрый день! Меня зовут Данил Липовой, наша команда в Сбертехе начала использовать HBase в качестве хранилища оперативных данных. В ходе его изучения накопился опыт, который захотелось систематизировать и описать (надеемся, что многим будет полезно). Все приведенные ниже эксперименты проводились с версиями HBase 1.2.0-cdh5.14.2 и 2.0.0-cdh6.0.0-beta1.
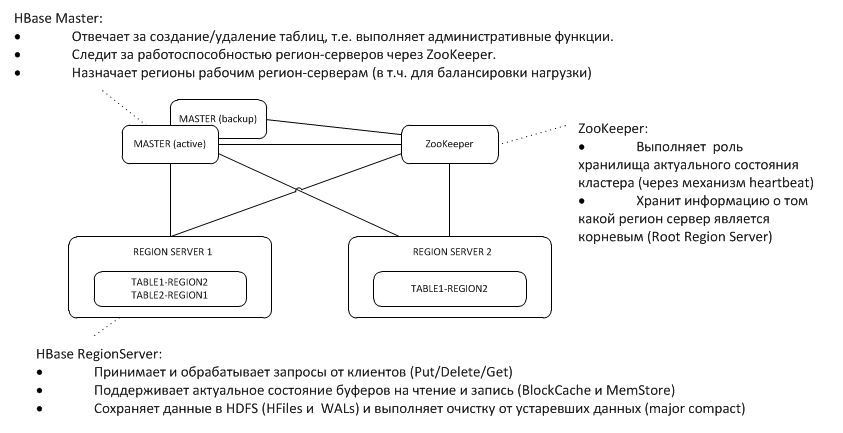
Резервный Master слушает heartbeat активного на узле ZooKeeper и в случае исчезновения берет функции мастера на себя.
Сначала рассмотрим самый простой случай – запись объекта ключ-значение в некую таблицу при помощи put(rowkey). Клиент сначала должен выяснить, где расположен корневой регион сервер (Root Region Server — RRS), который хранит таблицу hbase:meta. Эту информацию он получает от ZooKeeper. После чего он обращается к RRS и читает таблицу hbase:meta, из которой извлекает информацию, какой RegionServer (RS) отвечает за хранение данных по заданному ключу rowkey в интересующей его таблице. В целях дальнейшего использования мета-таблица кэшируется клиентом и поэтому последующие обращения идут быстрее, напрямую к RS.
Далее RS, получив запрос, первым делом пишет его в WriteAheadLog (WAL), что необходимо для восстановления в случае падения. Затем сохраняет данные в MemStore. Это буфер в памяти, который содержит отсортированный набор ключей данного региона. Таблица может быть разбита на регионы (партиции), каждый из которых содержит непересекающийся набор ключей. Это позволяет, разместив регионы на разных серверах, получать более высокую производительность. Однако, несмотря на очевидность этого утверждения, далее мы увидим, что это работает не во всех случаях.
После размещения записи в MemStore клиенту возвращается ответ, что запись сохранена успешно. При этом реально она хранится только в буфере и попадет на диск только после того, как пройдет некоторый интервал времени или при наполнении его новыми данными.

При выполнении операции «Delete» физического удаления данных не происходит. Они просто помечаются как удаленные, а само уничтожение происходит в момент вызова функции major compact, про которую подробнее написано в п.7.
Файлы в формате HFile копятся в HDFS и время от времени запускается процесс minor compact, который просто склеивает маленькие файлы в более крупные, ничего не удаляя. Со временем это превращается проблему, которая проявляется только при чтении данных (к этому вернемся чуть позже).
Кроме описанного выше процесса загрузки есть гораздо более эффективная процедура, в которой заключается пожалуй самая сильная сторона этой БД – BulkLoad. Она заключается в том, что мы самостоятельно формируем HFiles и подкладываем на диск, что позволяет превосходно масштабироваться и достигать весьма приличных скоростей. По сути, ограничением тут является не HBase, а возможности железа. Ниже приведены результаты загрузки на кластере, состоящим из 16 RegionServers и 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока), версия HBase 1.2.0-cdh5.14.2.

Тут видно, что увеличивая кол-во партиций (регионов) в таблице, а также экзекуторов Spark, получаем приращение скорости загрузки. Также скорость зависит от объема записи. Крупные блоки дают прирост в измерении МБ/сек, мелкие в количестве вставленных записей в единицу времени, при прочих равных.
Также можно запустить загрузку в две таблицы одновременно и получить удвоение скорости. Ниже видно, что запись блоков 10 КБ сразу в две таблицы идет со скоростью около 600 Мб/сек в каждую (суммарно 1275 Мб/сек), что совпадает со скоростью записи в одну таблицу 623 МБ/сек (см. №11 выше)

А вот второй запуск с записями в 50 КБ показывает, что скорость загрузки растет уже незначительно, что говорит о приближении к предельным значениям. При этом нужно иметь в виду, что на сам HBASE тут нагрузки практически не создается, все что от него требуется, это сначала отдать данные из hbase:meta, а после подкладки HFiles, сбросить данные BlockCache и сохранить буфер MemStore на диск, если он не пустой.
Если считать, что вся информация из hbase:meta уже у есть клиента (см. п.2), то запрос уходит сразу на тот RS, где хранится нужный ключ. Сначала поиск осуществляется в MemCache. Вне зависимости от того, есть там данные или нет, поиск осуществляется также в буфере BlockCache и при необходимости в HFiles. Если данные были найдены в файле, то они помещаются в BlockCache и при следующем запросе будут возвращены быстрее. Поиск в HFile происходит относительно быстро благодаря использованию фильтра Блюма, т.е. считав небольшой объем данных он сразу определяет, содержит ли этот файл нужный ключ и если нет, то переходит к следующему.

Получив данные из этих трех источников RS формирует ответ. В частности, он может передать сразу несколько найденных версий объекта если клиент запросил версионность.
Буферы MemStore и BlockCache занимают до 80% выделенной on-heap памяти RS (остальное зарезервировано для сервисных задач RS). Если типичный режим использования такой, что процессы пишут и сразу читают эти же данные, то имеет смысл уменьшить BlockCache и увеличить MemStore, т.к. при записи данные в кэш на чтение не попадают, то использование BlockCache будет происходить реже. Буфер BlockCache состоит из двух частей: LruBlockCache (всегда on-heap) и BucketCache (как правило off-heap или на SSD). BucketCache стоит использовать, когда запросов чтение очень много и они не помещаются в LruBlockCache, что приводит к активной работе Garbage Collector. При этом радикального роста производительности от использования кэша на чтение ждать не стоит, однако к этому мы еще вернемся в п. 8
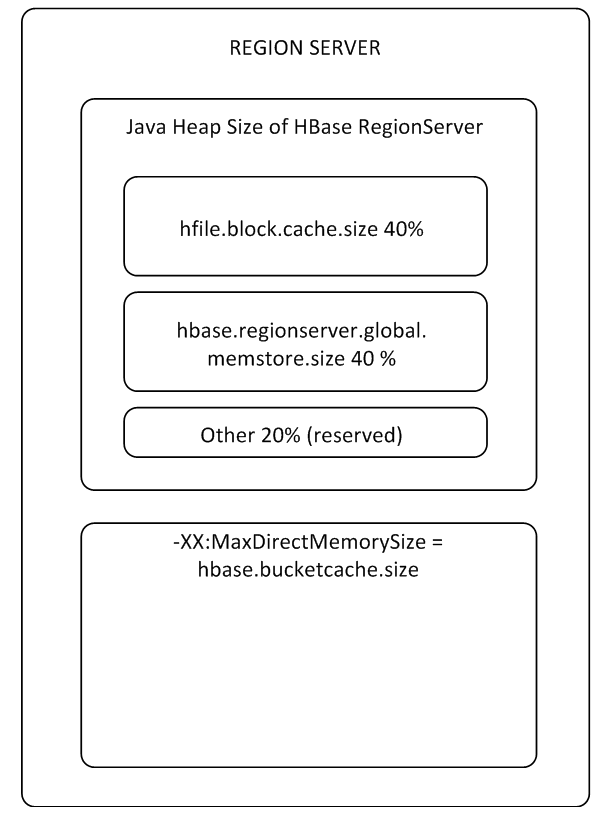
BlockCache один на весь RS, а MemStore для каждой таблицы свой (по одному на каждый Column Family).
Как описано в теории, при записи данные в кэш не попадают и действительно, такие параметры CACHE_DATA_ON_WRITE для таблицы и «Cache DATA on Write» для RS установлены в false. Однако на практике, если записать данные в MemStore, потом сбросить его на диск (очистив таким образом), затем удалить получившийся файл, то выполнив get запрос мы успешно получим данные. Причем даже если совсем отключить BlockCache и забить таблицу новыми данными, затем добиться сброса MemStore на диск, удалить их и запросить из другой сессии, то они все равно откуда-то извлекутся. Так что HBase хранит в себе не только данные, но и таинственные загадки.
Параметр «Cache DATA on Read» установлен false. Если есть идеи, добро пожаловать обсудить это в комментариях.
Обработка одиночных запросов (Get/Put/Delete) довольно дорогая операция, поэтому следует объединять по возможности их в List или List, что позволяет получать значительный прирост производительности. Особенно это касается операции записи, а вот при чтении есть следующий подводный камень. На графике ниже показано время чтения 50 000 записей из MemStore. Чтение производилось в один поток и по горизонтальной оси показано количество ключей в запросе. Тут видно, что при увеличении до тысячи ключей в одном запросе время выполнения падает, т.е. скорость увеличивается. Однако при включенном по умолчанию режиме MSLAB после этого порога начинается радикальное падение производительности, причем чем больше объем данных в записи, тем больше время работы.

Тесты выполнялись на виртуалке, 8 ядер, версия HBase 2.0.0-cdh6.0.0-beta1.
Режим MSLAB призван уменьшить фрагментацию heap, которая возникает из-за перемешивания данных нового и старого поколений. В качестве решения проблемы при включении MSLAB данные помещаются в относительно небольшие ячейки (chunk) и обрабатываются порциями. В результате, когда объем в запрошенном пакете данных превышает выделенный размер, то производительность резко падает. С другой стороны выключение данного режима также не желательно, так как приведет к остановкам по причине GC в моменты интенсивной работы с данными. Хорошим выходом является увеличение объемов ячейки, в случае активной записи через put одновременно с чтением. Стоит отметить, что проблема не возникает если после записи выполнять команду flush которая сбрасывает MemStore на диск или если осуществляется загрузка при помощи BulkLoad. В таблице ниже показано, что запросы из MemStore данных большего объема (и одинакового количества) приводят к замедлению. Однако увеличивая chunksize возвращаем время обработки к норме.
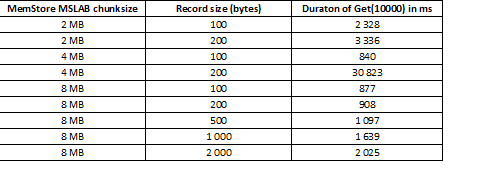
Кроме увеличения chunksize помогает дробление данных по регионам, т.е. сплитинг таблиц. Это приводит к тому, что на каждый регион приходит меньшее количество запросов и если они помещаются в ячейку, отклик остается хорошим.
Так как HBase является key-value хранилищем и партиционирование осуществляется по ключу, то крайне важно разделять данные равномерно по всем регионам. Например партиционирование такой таблицы на три части приведет тому что данные будут разбиты на три региона:

Бывает, что это приводит к резкому замедлению, если загружаемые в дальнейшем данные будут иметь вид к примеру long значений в большинстве своем начинающихся с одной и той же цифры, например:
1000001
1000002
…
1100003
Так как ключи хранятся в виде массива байт, все они будут начинаться одинаково и относиться к одному региону #1 хранящему этот диапазон ключей. Есть несколько стратегий разбиения:
HexStringSplit – Превращает ключ в строку с шестнадцатеричным кодированием в диапазоне «00000000» => «FFFFFFFF» и заполняя слева нулями.
UniformSplit – Превращает ключ в массив байт с шестнадцатеричным кодированием в диапазоне «00» => «FF» и заполняя справа нулями.
Кроме того можно указать любой диапазон или набор ключей для разбиения и настроить автосплитинг. Однако одним из наиболее простых и эффективных подходов является UniformSplit и использование конкатенации хэша, например старшей пары байт от прогона ключа через функцию CRC32(rowkey) и собственно rowkey:
hash + rowkey
Тогда все данные будут распределены равномерно по регионам. При чтении первые два байта просто отбрасываются и остается исходный ключ. Также RS контролирует количество данных и ключей в регионе и при превышении лимитов автоматически разбивает его на части.
Так как за каждый набор ключей отвечает только один регион, решением проблем связанными с падениями RS или выводом из эксплуатации является хранение всех необходимых данных в HDFS. При падении RS мастер обнаруживает это через отсутствие heartbeat на узле ZooKeeper. Тогда он назначает обслуживаемый регион другому RS и так как HFiles хранятся в распределенной файловой системе, то новый хозяин вычитывает их и продолжает обслуживать данные. Однако, так как часть данных может быть в MemStore и не успела попасть в HFiles, для восстановления истории операций используется WAL, которые также хранятся в HDFS. После наката изменений, RS способен отвечать на запросы, однако переезд приводит к тому, что часть данных и процессы их обслуживающие оказываются на разных нодах, т.е. снижается locality.
Решением проблемы является major compaction – эта процедура перемещает файлы на те ноды, которые за них отвечают (туда где расположены их регионы), в результате чего во время этой процедуры резко возрастает нагрузка на сеть и диски. Однако в дальнейшем доступ к данным заметно ускоряется. Кроме того, major_compaction выполняет объединение всех HFiles в один файл в рамках региона, а также очищает данные в зависимости от настроек таблицы. Например, можно задать количество версий объекта, которое необходимо сохранять или время его жизни, после истечении которого объект физически удаляется.
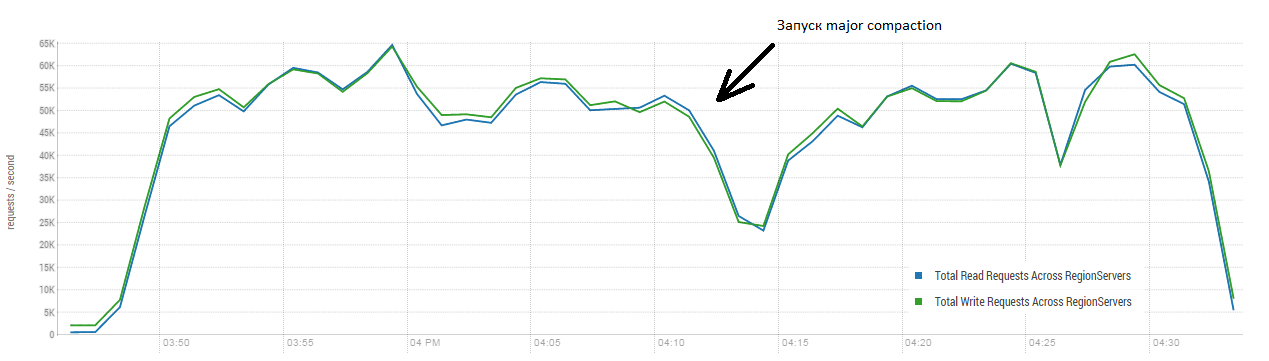
Эта процедура может произвести весьма позитивное влияние на работу HBase. На картинке ниже видно, как деградировала производительность в результате активной записи данных. Тут видно как в одну таблицу 40 потоков писали и 40 потоков одновременно читали данные. Пишущие потоки формируют все больше и больше HFiles, которые вычитываются другими потоками. В результате все больше данных нужно удалять из памяти и в конце концов начинает работать GC, который практически парализует всю работу. Запуск major compaction привел к чистке образовавшихся завалов и восстановлению производительности.

Тест выполнялся на 3-х DataNode и 4-х RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2
Стоит отметить, что запуск major compaction выполнялся на «живой» таблице, в которую активно писали и читали данные. В сети встречалось утверждение, что это может привести к некорректному ответу при чтении данных. Для проверки был запущен процесс, который генерировал новые данные и писал их в таблицу. После чего сразу же читал и сверял совпадает ли полученное значение с тем что было записано. Во время работы этого процесса около 200 раз запускался major compaction и ни одного сбоя не зафиксировано. Возможно проблема проявляется редко и только во время высокой загрузки, поэтому более безопасно все-таки планово останавливать процессы записи и чтения и выполнять очистку не допуская таких просадок GC.
Также major compaction не влияет на состояние MemStore, для сброса его на диск и компактификации нужно использовать flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
Как уже было сказано, наибольший успех HBase показывает там, где ему ничего не нужно делать, при выполнении BulkLoad. Впрочем, это касается большинства систем и людей. Однако этот инструмент годится скорее для массовой укладки данных большими блоками, тогда как если процесс требует выполнения множества конкурирующих запросов на чтение и запись, используются описанные выше команды Get и Put. Для определения оптимальных параметров были произведены запуски при различных комбинациях параметров таблиц и настроек:
— Put
— Get
— Get+Put
— BlockCache = включался или выключался
— BlockSize = 65 Кб или 16 Кб
— Партиций = 1, 5 или 30
— MSLAB = включен или выключен
Таким образом блок выглядит так:
a. Включался/выключался режим MSLAB.
b. Создавалась таблица, для который устанавливались следующие параметры: BlockCache = true/none, BlockSize = 65/16 Kb, Партиций = 1/5/30.
c. Устанавливалось сжатие GZ.
d. Запускалось 10 потоков одновременно делающих 1/10 операций put/get/get+put в эту таблицу записями по 100/1000/10000 байт, выполняя 50 000 запросов подряд (ключи рандомные).
e. Пункт d повторялся три раза.
f. Время работы всех потоков усреднялось.
Были проверены все возможные комбинации. Предсказуемо, что при увеличении размера записи скорость будет падать или что отключение кэширование приведет к замедлению. Однако цель была понять степень и значимость влияния каждого параметра, поэтому собранные данные были поданы на вход функции линейной регрессии, что дает возможность оценить достоверность при помощи t-статистики. Ниже приведены результаты работы блоков выполняющих операции Put. Полный набор комбинаций 2*2*3*2*3 = 144 варианта + 72 т.к. некоторые были выполнены дважды. Поэтому в сумме 216 запусков:

Тестирование производилось на мини-кластере состоящим из 3-х DataNode и 4-х RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
Наиболее высокая скорость вставки 3.7 сек была получена при выключенном режиме MSLAB, на таблице с одной партицией, с включенным BlockCache, BlockSize = 16, записями по 100 байт по 10 штук в пачке.
Наиболее низкая скорость вставки 82.8 сек была получена при включенном режиме MSLAB, на таблице с одной партицией, с включенным BlockCache, BlockSize = 16, записями по 10000 байт по 1 штуке.
Теперь посмотрим на модель. Мы видим хорошее качество модели по R2, но совершенно понятно, что экстраполяция тут противопоказана. Реальное поведение системы при изменении параметров будет не линейным, эта модель нужна не для прогнозов, а для понимания, что произошло в пределах заданных параметров. Например тут мы видим по критерию Стьюдента, что для операции Put не имеют значения параметры BlockSize и BlockCache (что в общем вполне предсказуемо):

А вот то, что увеличение количества партиций ведет к снижению производительности несколько неожиданно (мы уже видели позитивное влияние увеличения количества партиций при BulkLoad), хотя и объяснимо. Во первых для обработки приходится формировать запросы к 30 регионам вместо одного, а объем данных не такой, чтобы это дало выигрыш. Во вторых общее время работы определяется самым медленным RS, а так как количество DataNode меньше количества RS часть регионов имеют нулевую локальность. Ну и посмотрим на пятерку лидеров:

Теперь оценим результаты выполнения блоков Get:

Количество партиций потеряло значимость, что вероятно объясняется тем, что данные хорошо кэшируются и кэш для чтения наиболее значимый (статистически) параметр. Естественно, что увеличение кол-ва сообщений в запросе – тоже весьма полезно для производительности. Лучшие результаты:

Ну и наконец посмотрим на модель блока который выполнял сначала get, а потом put:

Тут все параметры значимы. И результаты лидеров:

Ну и наконец запустим более-менее приличную нагрузку, но всегда более интересно когда есть с чем сравнивать. На сайте DataStax – ключевого разработчика Cassandra есть результаты НТ ряда NoSQL хранилищ, в том числе HBase версии 0.98.6-1. Загрузка осуществлялась 40 потоками, размер данных 100 байт, диски SSD. Результат тестирования операций Read-Modify-Write показал такие результаты.
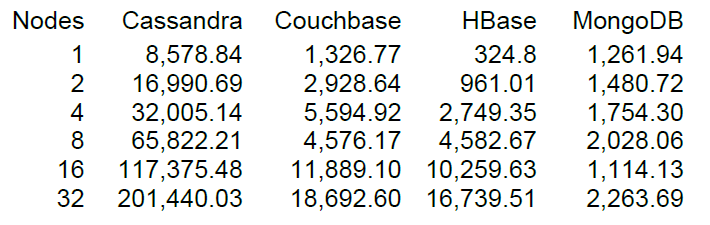
Насколько я понял, чтение осуществлялось блоками по 100 записей и для 16 нод HBase тест DataStax показал производительность 10 тыс. операций в секунду.
Удачно, что в нашем кластере тоже 16 нод, но не очень «удачно», что на каждом по 64 ядра (потока), тогда как в тесте DataStax лишь по 4. С другой стороны у них диски SSD, а у нас HDD и более новая версия HBase и утилизация CPU во время нагрузки практически увеличивалась не значительно (визуально на 5-10 процентов). Однако тем не менее попробуем запуститься на этой конфигурации. Настройки таблиц по умолчанию, чтение производится в диапазоне ключей от 0 до 50 млн. случайным образом (т.е. по сути каждый раз новый). В таблице 50 миллионов записей, разбита на 64 партиции. Ключи захешированы по crc32. Настройки таблиц дефолтные, MSLAB включен. Запуск 40 потоков, каждый поток читает набор из 100 случайных ключей и тут же пишет сгенерированные 100 байт по этим ключам обратно.
Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
Средний результат ближе к 40 тыс. операций в секунду, что существенно лучше, чем в тесте DataStax. Однако в целях эксперимента можно несколько изменить условия. Довольно маловероятно, что все работа будет вестись исключительно с одной таблицей, а также только с уникальными ключами. Предположим что есть некий «горячий» набор ключей который генерирует основную нагрузку. Поэтому попробуем создать нагрузку более крупными записями (10 КБ), также пачками по 100, в 4 разных таблицы и ограничив диапазон запрашиваемых ключей 50 тыс. На графике ниже показан запуск 40 потоков, каждый поток читает набор из 100 ключей и тут же пишет случайные 10 КБ по этим ключам назад.

Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
В ходе нагрузки несколько раз запускался major compaction, как было показано выше без этой процедуры производительность будет постепенно деградировать, однако во время выполнения также возникает дополнительная нагрузка. Просадки вызваны разными причинами. Иногда потоки заканчивали работу и пока они перезапускались возникала пауза, иногда сторонние приложения создавали нагрузку на кластер.
Чтение и сразу же запись — один из наиболее тяжелых сценариев работы для HBase. Если делать только put запросы небольшого размера, например по 100 байт, объединив их в пачки по 10-50 тыс штук, можно получить сотни тысяч операций в секунду и аналогично дела обстоят с запросами только на чтение. Стоит отметить, что результаты радикально лучше тех, что получились у DataStax больше всего за счет запросов блоками по 50 тыс.

Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
Данная система достаточно гибко настраивается, однако влияние большого количества параметров все еще остается неизвестным. Часть из них была протестирована, но не вошла в результирующий набор тестов. Например, предварительные эксперименты показали незначительную значимость такого параметра как DATA_BLOCK_ENCODING, который кодирует информацию, используя значения из соседних ячеек, что вполне объяснимо для данных сгенерированных случайным образом. В случае использования большого количества повторяющихся объектов выигрыш может быть значительным. В целом можно сказать, что HBase производит впечатление достаточно серьезной и продуманной БД, которая при операциях с большими блоками данных может быть достаточно производительной. Особенно если есть возможность разнести во времени процессы чтения и записи.
Если что-то на ваш взгляд недостаточно раскрыто, готов рассказать подробнее. Предлагаем делиться своим опытом или подискутировать если с чем-то не согласны.
- Общая архитектура
- Запись данных в HBASE
- Чтение данных из HBASE
- Кэширование данных
- Пакетная обработка данных MultiGet/MultiPut
- Стратегия разбивки таблиц на регионы (спилитинг)
- Отказоустойчивость, компактификация и локальность данных
- Настройки и производительность
- Нагрузочное тестирование
- Выводы
1. Общая архитектура

Резервный Master слушает heartbeat активного на узле ZooKeeper и в случае исчезновения берет функции мастера на себя.
2. Запись данных в HBASE
Сначала рассмотрим самый простой случай – запись объекта ключ-значение в некую таблицу при помощи put(rowkey). Клиент сначала должен выяснить, где расположен корневой регион сервер (Root Region Server — RRS), который хранит таблицу hbase:meta. Эту информацию он получает от ZooKeeper. После чего он обращается к RRS и читает таблицу hbase:meta, из которой извлекает информацию, какой RegionServer (RS) отвечает за хранение данных по заданному ключу rowkey в интересующей его таблице. В целях дальнейшего использования мета-таблица кэшируется клиентом и поэтому последующие обращения идут быстрее, напрямую к RS.
Далее RS, получив запрос, первым делом пишет его в WriteAheadLog (WAL), что необходимо для восстановления в случае падения. Затем сохраняет данные в MemStore. Это буфер в памяти, который содержит отсортированный набор ключей данного региона. Таблица может быть разбита на регионы (партиции), каждый из которых содержит непересекающийся набор ключей. Это позволяет, разместив регионы на разных серверах, получать более высокую производительность. Однако, несмотря на очевидность этого утверждения, далее мы увидим, что это работает не во всех случаях.
После размещения записи в MemStore клиенту возвращается ответ, что запись сохранена успешно. При этом реально она хранится только в буфере и попадет на диск только после того, как пройдет некоторый интервал времени или при наполнении его новыми данными.

При выполнении операции «Delete» физического удаления данных не происходит. Они просто помечаются как удаленные, а само уничтожение происходит в момент вызова функции major compact, про которую подробнее написано в п.7.
Файлы в формате HFile копятся в HDFS и время от времени запускается процесс minor compact, который просто склеивает маленькие файлы в более крупные, ничего не удаляя. Со временем это превращается проблему, которая проявляется только при чтении данных (к этому вернемся чуть позже).
Кроме описанного выше процесса загрузки есть гораздо более эффективная процедура, в которой заключается пожалуй самая сильная сторона этой БД – BulkLoad. Она заключается в том, что мы самостоятельно формируем HFiles и подкладываем на диск, что позволяет превосходно масштабироваться и достигать весьма приличных скоростей. По сути, ограничением тут является не HBase, а возможности железа. Ниже приведены результаты загрузки на кластере, состоящим из 16 RegionServers и 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока), версия HBase 1.2.0-cdh5.14.2.

Тут видно, что увеличивая кол-во партиций (регионов) в таблице, а также экзекуторов Spark, получаем приращение скорости загрузки. Также скорость зависит от объема записи. Крупные блоки дают прирост в измерении МБ/сек, мелкие в количестве вставленных записей в единицу времени, при прочих равных.
Также можно запустить загрузку в две таблицы одновременно и получить удвоение скорости. Ниже видно, что запись блоков 10 КБ сразу в две таблицы идет со скоростью около 600 Мб/сек в каждую (суммарно 1275 Мб/сек), что совпадает со скоростью записи в одну таблицу 623 МБ/сек (см. №11 выше)

А вот второй запуск с записями в 50 КБ показывает, что скорость загрузки растет уже незначительно, что говорит о приближении к предельным значениям. При этом нужно иметь в виду, что на сам HBASE тут нагрузки практически не создается, все что от него требуется, это сначала отдать данные из hbase:meta, а после подкладки HFiles, сбросить данные BlockCache и сохранить буфер MemStore на диск, если он не пустой.
3. Чтение данных из HBASE
Если считать, что вся информация из hbase:meta уже у есть клиента (см. п.2), то запрос уходит сразу на тот RS, где хранится нужный ключ. Сначала поиск осуществляется в MemCache. Вне зависимости от того, есть там данные или нет, поиск осуществляется также в буфере BlockCache и при необходимости в HFiles. Если данные были найдены в файле, то они помещаются в BlockCache и при следующем запросе будут возвращены быстрее. Поиск в HFile происходит относительно быстро благодаря использованию фильтра Блюма, т.е. считав небольшой объем данных он сразу определяет, содержит ли этот файл нужный ключ и если нет, то переходит к следующему.

Получив данные из этих трех источников RS формирует ответ. В частности, он может передать сразу несколько найденных версий объекта если клиент запросил версионность.
4. Кэширование данных
Буферы MemStore и BlockCache занимают до 80% выделенной on-heap памяти RS (остальное зарезервировано для сервисных задач RS). Если типичный режим использования такой, что процессы пишут и сразу читают эти же данные, то имеет смысл уменьшить BlockCache и увеличить MemStore, т.к. при записи данные в кэш на чтение не попадают, то использование BlockCache будет происходить реже. Буфер BlockCache состоит из двух частей: LruBlockCache (всегда on-heap) и BucketCache (как правило off-heap или на SSD). BucketCache стоит использовать, когда запросов чтение очень много и они не помещаются в LruBlockCache, что приводит к активной работе Garbage Collector. При этом радикального роста производительности от использования кэша на чтение ждать не стоит, однако к этому мы еще вернемся в п. 8

BlockCache один на весь RS, а MemStore для каждой таблицы свой (по одному на каждый Column Family).
Как описано в теории, при записи данные в кэш не попадают и действительно, такие параметры CACHE_DATA_ON_WRITE для таблицы и «Cache DATA on Write» для RS установлены в false. Однако на практике, если записать данные в MemStore, потом сбросить его на диск (очистив таким образом), затем удалить получившийся файл, то выполнив get запрос мы успешно получим данные. Причем даже если совсем отключить BlockCache и забить таблицу новыми данными, затем добиться сброса MemStore на диск, удалить их и запросить из другой сессии, то они все равно откуда-то извлекутся. Так что HBase хранит в себе не только данные, но и таинственные загадки.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Параметр «Cache DATA on Read» установлен false. Если есть идеи, добро пожаловать обсудить это в комментариях.
5. Пакетная обработка данных MultiGet/MultiPut
Обработка одиночных запросов (Get/Put/Delete) довольно дорогая операция, поэтому следует объединять по возможности их в List или List, что позволяет получать значительный прирост производительности. Особенно это касается операции записи, а вот при чтении есть следующий подводный камень. На графике ниже показано время чтения 50 000 записей из MemStore. Чтение производилось в один поток и по горизонтальной оси показано количество ключей в запросе. Тут видно, что при увеличении до тысячи ключей в одном запросе время выполнения падает, т.е. скорость увеличивается. Однако при включенном по умолчанию режиме MSLAB после этого порога начинается радикальное падение производительности, причем чем больше объем данных в записи, тем больше время работы.

Тесты выполнялись на виртуалке, 8 ядер, версия HBase 2.0.0-cdh6.0.0-beta1.
Режим MSLAB призван уменьшить фрагментацию heap, которая возникает из-за перемешивания данных нового и старого поколений. В качестве решения проблемы при включении MSLAB данные помещаются в относительно небольшие ячейки (chunk) и обрабатываются порциями. В результате, когда объем в запрошенном пакете данных превышает выделенный размер, то производительность резко падает. С другой стороны выключение данного режима также не желательно, так как приведет к остановкам по причине GC в моменты интенсивной работы с данными. Хорошим выходом является увеличение объемов ячейки, в случае активной записи через put одновременно с чтением. Стоит отметить, что проблема не возникает если после записи выполнять команду flush которая сбрасывает MemStore на диск или если осуществляется загрузка при помощи BulkLoad. В таблице ниже показано, что запросы из MemStore данных большего объема (и одинакового количества) приводят к замедлению. Однако увеличивая chunksize возвращаем время обработки к норме.

Кроме увеличения chunksize помогает дробление данных по регионам, т.е. сплитинг таблиц. Это приводит к тому, что на каждый регион приходит меньшее количество запросов и если они помещаются в ячейку, отклик остается хорошим.
6. Стратегия разбиения таблиц на регионы (спилитинг)
Так как HBase является key-value хранилищем и партиционирование осуществляется по ключу, то крайне важно разделять данные равномерно по всем регионам. Например партиционирование такой таблицы на три части приведет тому что данные будут разбиты на три региона:

Бывает, что это приводит к резкому замедлению, если загружаемые в дальнейшем данные будут иметь вид к примеру long значений в большинстве своем начинающихся с одной и той же цифры, например:
1000001
1000002
…
1100003
Так как ключи хранятся в виде массива байт, все они будут начинаться одинаково и относиться к одному региону #1 хранящему этот диапазон ключей. Есть несколько стратегий разбиения:
HexStringSplit – Превращает ключ в строку с шестнадцатеричным кодированием в диапазоне «00000000» => «FFFFFFFF» и заполняя слева нулями.
UniformSplit – Превращает ключ в массив байт с шестнадцатеричным кодированием в диапазоне «00» => «FF» и заполняя справа нулями.
Кроме того можно указать любой диапазон или набор ключей для разбиения и настроить автосплитинг. Однако одним из наиболее простых и эффективных подходов является UniformSplit и использование конкатенации хэша, например старшей пары байт от прогона ключа через функцию CRC32(rowkey) и собственно rowkey:
hash + rowkey
Тогда все данные будут распределены равномерно по регионам. При чтении первые два байта просто отбрасываются и остается исходный ключ. Также RS контролирует количество данных и ключей в регионе и при превышении лимитов автоматически разбивает его на части.
7. Отказоустойчивость и локальность данных
Так как за каждый набор ключей отвечает только один регион, решением проблем связанными с падениями RS или выводом из эксплуатации является хранение всех необходимых данных в HDFS. При падении RS мастер обнаруживает это через отсутствие heartbeat на узле ZooKeeper. Тогда он назначает обслуживаемый регион другому RS и так как HFiles хранятся в распределенной файловой системе, то новый хозяин вычитывает их и продолжает обслуживать данные. Однако, так как часть данных может быть в MemStore и не успела попасть в HFiles, для восстановления истории операций используется WAL, которые также хранятся в HDFS. После наката изменений, RS способен отвечать на запросы, однако переезд приводит к тому, что часть данных и процессы их обслуживающие оказываются на разных нодах, т.е. снижается locality.
Решением проблемы является major compaction – эта процедура перемещает файлы на те ноды, которые за них отвечают (туда где расположены их регионы), в результате чего во время этой процедуры резко возрастает нагрузка на сеть и диски. Однако в дальнейшем доступ к данным заметно ускоряется. Кроме того, major_compaction выполняет объединение всех HFiles в один файл в рамках региона, а также очищает данные в зависимости от настроек таблицы. Например, можно задать количество версий объекта, которое необходимо сохранять или время его жизни, после истечении которого объект физически удаляется.
Эта процедура может произвести весьма позитивное влияние на работу HBase. На картинке ниже видно, как деградировала производительность в результате активной записи данных. Тут видно как в одну таблицу 40 потоков писали и 40 потоков одновременно читали данные. Пишущие потоки формируют все больше и больше HFiles, которые вычитываются другими потоками. В результате все больше данных нужно удалять из памяти и в конце концов начинает работать GC, который практически парализует всю работу. Запуск major compaction привел к чистке образовавшихся завалов и восстановлению производительности.

Тест выполнялся на 3-х DataNode и 4-х RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2
Стоит отметить, что запуск major compaction выполнялся на «живой» таблице, в которую активно писали и читали данные. В сети встречалось утверждение, что это может привести к некорректному ответу при чтении данных. Для проверки был запущен процесс, который генерировал новые данные и писал их в таблицу. После чего сразу же читал и сверял совпадает ли полученное значение с тем что было записано. Во время работы этого процесса около 200 раз запускался major compaction и ни одного сбоя не зафиксировано. Возможно проблема проявляется редко и только во время высокой загрузки, поэтому более безопасно все-таки планово останавливать процессы записи и чтения и выполнять очистку не допуская таких просадок GC.
Также major compaction не влияет на состояние MemStore, для сброса его на диск и компактификации нужно использовать flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Настройки и производительность
Как уже было сказано, наибольший успех HBase показывает там, где ему ничего не нужно делать, при выполнении BulkLoad. Впрочем, это касается большинства систем и людей. Однако этот инструмент годится скорее для массовой укладки данных большими блоками, тогда как если процесс требует выполнения множества конкурирующих запросов на чтение и запись, используются описанные выше команды Get и Put. Для определения оптимальных параметров были произведены запуски при различных комбинациях параметров таблиц и настроек:
- Запускалось 10 потоков одновременно 3 раза подряд (назовем это блоком потоков).
- Время работы всех потоков в блоке усреднялось и являлось итоговым результатом работы блока.
- Все потоки работали с одной и той же таблицей.
- Перед каждым запуском блока потоков выполнялся major compaction.
- Каждый блок выполнял только одну из следующих операций:
— Put
— Get
— Get+Put
- Каждый блок выполнял 50 000 повторений своей операции.
- Размер записи в блоке 100 байт, 1000 байт или 10000 байт (random).
- Блоки запускались с различным количеством запрашиваемых ключей (или один ключ или 10).
- Блоки запускались при различных настройках таблицы. Изменялись параметры:
— BlockCache = включался или выключался
— BlockSize = 65 Кб или 16 Кб
— Партиций = 1, 5 или 30
— MSLAB = включен или выключен
Таким образом блок выглядит так:
a. Включался/выключался режим MSLAB.
b. Создавалась таблица, для который устанавливались следующие параметры: BlockCache = true/none, BlockSize = 65/16 Kb, Партиций = 1/5/30.
c. Устанавливалось сжатие GZ.
d. Запускалось 10 потоков одновременно делающих 1/10 операций put/get/get+put в эту таблицу записями по 100/1000/10000 байт, выполняя 50 000 запросов подряд (ключи рандомные).
e. Пункт d повторялся три раза.
f. Время работы всех потоков усреднялось.
Были проверены все возможные комбинации. Предсказуемо, что при увеличении размера записи скорость будет падать или что отключение кэширование приведет к замедлению. Однако цель была понять степень и значимость влияния каждого параметра, поэтому собранные данные были поданы на вход функции линейной регрессии, что дает возможность оценить достоверность при помощи t-статистики. Ниже приведены результаты работы блоков выполняющих операции Put. Полный набор комбинаций 2*2*3*2*3 = 144 варианта + 72 т.к. некоторые были выполнены дважды. Поэтому в сумме 216 запусков:

Тестирование производилось на мини-кластере состоящим из 3-х DataNode и 4-х RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
Наиболее высокая скорость вставки 3.7 сек была получена при выключенном режиме MSLAB, на таблице с одной партицией, с включенным BlockCache, BlockSize = 16, записями по 100 байт по 10 штук в пачке.
Наиболее низкая скорость вставки 82.8 сек была получена при включенном режиме MSLAB, на таблице с одной партицией, с включенным BlockCache, BlockSize = 16, записями по 10000 байт по 1 штуке.
Теперь посмотрим на модель. Мы видим хорошее качество модели по R2, но совершенно понятно, что экстраполяция тут противопоказана. Реальное поведение системы при изменении параметров будет не линейным, эта модель нужна не для прогнозов, а для понимания, что произошло в пределах заданных параметров. Например тут мы видим по критерию Стьюдента, что для операции Put не имеют значения параметры BlockSize и BlockCache (что в общем вполне предсказуемо):

А вот то, что увеличение количества партиций ведет к снижению производительности несколько неожиданно (мы уже видели позитивное влияние увеличения количества партиций при BulkLoad), хотя и объяснимо. Во первых для обработки приходится формировать запросы к 30 регионам вместо одного, а объем данных не такой, чтобы это дало выигрыш. Во вторых общее время работы определяется самым медленным RS, а так как количество DataNode меньше количества RS часть регионов имеют нулевую локальность. Ну и посмотрим на пятерку лидеров:

Теперь оценим результаты выполнения блоков Get:

Количество партиций потеряло значимость, что вероятно объясняется тем, что данные хорошо кэшируются и кэш для чтения наиболее значимый (статистически) параметр. Естественно, что увеличение кол-ва сообщений в запросе – тоже весьма полезно для производительности. Лучшие результаты:

Ну и наконец посмотрим на модель блока который выполнял сначала get, а потом put:

Тут все параметры значимы. И результаты лидеров:

9. Нагрузочное тестирование
Ну и наконец запустим более-менее приличную нагрузку, но всегда более интересно когда есть с чем сравнивать. На сайте DataStax – ключевого разработчика Cassandra есть результаты НТ ряда NoSQL хранилищ, в том числе HBase версии 0.98.6-1. Загрузка осуществлялась 40 потоками, размер данных 100 байт, диски SSD. Результат тестирования операций Read-Modify-Write показал такие результаты.

Насколько я понял, чтение осуществлялось блоками по 100 записей и для 16 нод HBase тест DataStax показал производительность 10 тыс. операций в секунду.
Удачно, что в нашем кластере тоже 16 нод, но не очень «удачно», что на каждом по 64 ядра (потока), тогда как в тесте DataStax лишь по 4. С другой стороны у них диски SSD, а у нас HDD и более новая версия HBase и утилизация CPU во время нагрузки практически увеличивалась не значительно (визуально на 5-10 процентов). Однако тем не менее попробуем запуститься на этой конфигурации. Настройки таблиц по умолчанию, чтение производится в диапазоне ключей от 0 до 50 млн. случайным образом (т.е. по сути каждый раз новый). В таблице 50 миллионов записей, разбита на 64 партиции. Ключи захешированы по crc32. Настройки таблиц дефолтные, MSLAB включен. Запуск 40 потоков, каждый поток читает набор из 100 случайных ключей и тут же пишет сгенерированные 100 байт по этим ключам обратно.

Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
Средний результат ближе к 40 тыс. операций в секунду, что существенно лучше, чем в тесте DataStax. Однако в целях эксперимента можно несколько изменить условия. Довольно маловероятно, что все работа будет вестись исключительно с одной таблицей, а также только с уникальными ключами. Предположим что есть некий «горячий» набор ключей который генерирует основную нагрузку. Поэтому попробуем создать нагрузку более крупными записями (10 КБ), также пачками по 100, в 4 разных таблицы и ограничив диапазон запрашиваемых ключей 50 тыс. На графике ниже показан запуск 40 потоков, каждый поток читает набор из 100 ключей и тут же пишет случайные 10 КБ по этим ключам назад.

Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
В ходе нагрузки несколько раз запускался major compaction, как было показано выше без этой процедуры производительность будет постепенно деградировать, однако во время выполнения также возникает дополнительная нагрузка. Просадки вызваны разными причинами. Иногда потоки заканчивали работу и пока они перезапускались возникала пауза, иногда сторонние приложения создавали нагрузку на кластер.
Чтение и сразу же запись — один из наиболее тяжелых сценариев работы для HBase. Если делать только put запросы небольшого размера, например по 100 байт, объединив их в пачки по 10-50 тыс штук, можно получить сотни тысяч операций в секунду и аналогично дела обстоят с запросами только на чтение. Стоит отметить, что результаты радикально лучше тех, что получились у DataStax больше всего за счет запросов блоками по 50 тыс.

Стенд: 16 DataNode и 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 потока). Версия HBase 1.2.0-cdh5.14.2.
10. Выводы
Данная система достаточно гибко настраивается, однако влияние большого количества параметров все еще остается неизвестным. Часть из них была протестирована, но не вошла в результирующий набор тестов. Например, предварительные эксперименты показали незначительную значимость такого параметра как DATA_BLOCK_ENCODING, который кодирует информацию, используя значения из соседних ячеек, что вполне объяснимо для данных сгенерированных случайным образом. В случае использования большого количества повторяющихся объектов выигрыш может быть значительным. В целом можно сказать, что HBase производит впечатление достаточно серьезной и продуманной БД, которая при операциях с большими блоками данных может быть достаточно производительной. Особенно если есть возможность разнести во времени процессы чтения и записи.
Если что-то на ваш взгляд недостаточно раскрыто, готов рассказать подробнее. Предлагаем делиться своим опытом или подискутировать если с чем-то не согласны.
