
Наша команда в Сбербанке занимается разработкой сервиса сессионных данных, который организует взаимообмен единым Java-контекстом сессии между распределёнными приложениями. Наш сервис крайне нуждается в очень быстрой сериализации Java-объектов, поскольку это часть нашей mission critical задачи. Изначально нам на ум приходили: Google Protocol Buffers, Apache Thrift, Apache Avro, CBOR и др. Первая тройка из перечисленных библиотек требует для сериализации объектов описания схемы их данных. CBOR такой низкоуровневый, что умеет сериализовывать только скалярные значения и их наборы. Нам же была нужна библиотека Java-сериализации, «не задающая лишних вопросов» и не заставляющая вручную разбирать сериализуемые объекты «на атомы». Мы хотели сериализовывать произвольные Java-объекты, не зная о них практически ничего, и хотели делать это максимально быстро. Поэтому мы устроили соревнование для имеющихся Open Source решений задачи Java-сериализации.
Для соревнования мы отобрали наиболее популярные библиотеки Java-сериализации, главным образом, использующие бинарный формат, а также библиотеки, хорошо зарекомендовавшие себя в других обзорах Java-сериализаторов.
Ну что, поехали!
Скорость – вот основной критерий оценки библиотек Java-сериализации, которые являются участниками нашего импровизированного соревнования. Для того чтобы объективно оценить, какая из библиотек сериализации быстрее, мы взяли реальные данные из логов нашей системы и скомпоновали из них синтетические сессионные данные разной длины: от 0 до 1 МБ. По формату данные представляли собой строки и байтовые массивы.
UPD:
Вот, что получилось:
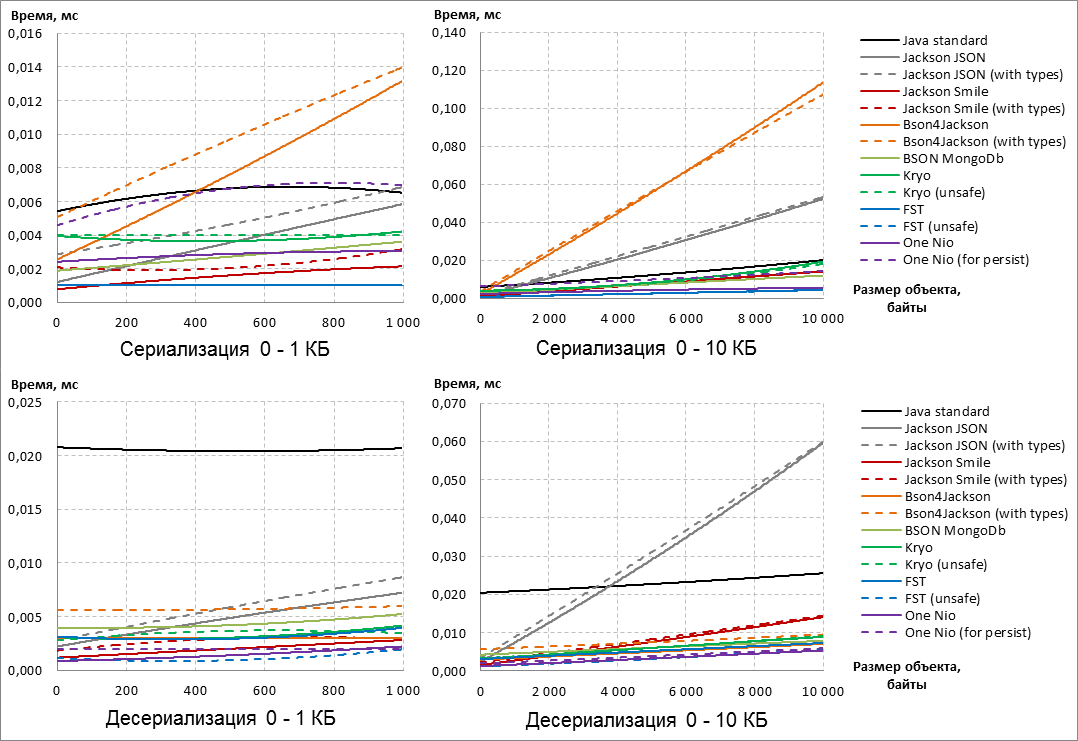
Сначала заметим, что варианты библиотек, добавляющие в результат сериализации дополнительные мета-данные, работают медленнее, чем дефолтные конфигурации этих же библиотек (см. конфигурации «with types» и «for persist»).
В целом, не зависимо от конфигурации аутсайдерами по результатам сериализации становятся Jackson JSON и Bson4Jackson, которые выбывают из гонки.
Кроме того, по результатам десериализации из гонки выбывает Java Standard, т.к. при любом размере сериализуемых данных десериализация кратно медленнее конкурентов.
Взглянем поближе на оставшихся участников:

По результатам сериализации в уверенных лидерах идёт библиотека FST, а при увеличении размера объектов ей «на пятки наступает» One Nio. Заметим, что у One Nio вариант «for persist» сильно медленнее дефолтной конфигурации по скорости сериализации.
Если взглянуть на десериализацию, то видим, что One Nio с увеличением размера данных смог обогнать FST. У последнего, напротив, нестандартная конфигурация «unsafe» заметно быстрее выполняет десериализацию.
Для того чтобы расставить все точки над И, давайте посмотрим на суммарный результат по сериализации и десериализации:
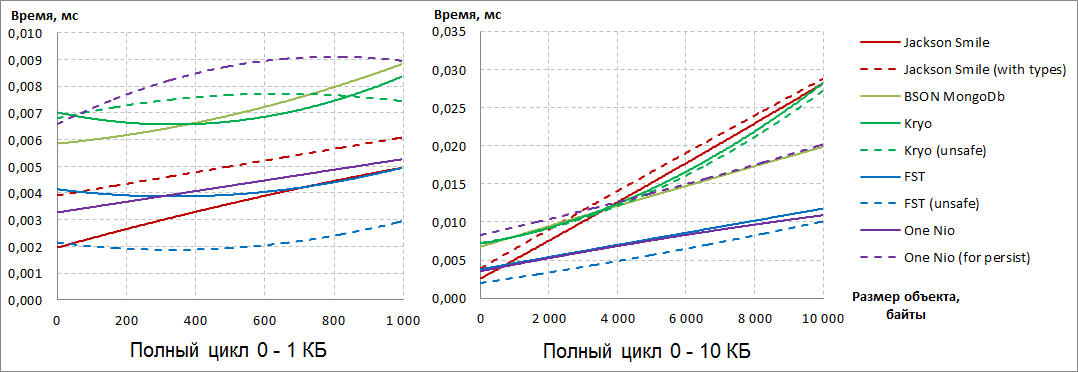
Стало очевидно, что однозначных лидеров два: FST (unsafe) и One Nio.
Если на небольших объектах FST (unsafe) уверенно лидирует, то с ростом размера сериализуемых объектов он начинает уступать и, в конечном счёте, уступает One Nio.
Третью позицию с ростом размера сериализуемых объектов уверенно занимает BSON MongoDb, хотя отрыв от лидеров у него почти двукратный.
Размер результата сериализации – второй важнейший критерий оценки библиотек Java-сериализации. В каком-то плане, от размера результата зависит скорость сериализации/десериализации: компактный результат формировать и обрабатывать быстрее, чем объёмный. Для «взвешивания» результатов сериализации использовались всё те же Java-объекты, сформированные из реальных данных, взятых из логов системы (строк и байтовых массивов).
Кроме того, важным свойством результата сериализации является и то, на сколько он хорошо сжимается (например, для сохранения в БД или других хранилищах). В нашем соревновании мы использовали алгоритм сжатия Deflate, являющийся основой для ZIP и gzip.
Результаты «взвешивания» получились следующими:

Ожидаемо, самыми компактными оказались результаты сериализации у одного из лидеров гонки: One Nio.
Второе место по компактности досталось BSON MongoDb (который занял третье место в гонке).
На третье место по компактности «вырвалась» библиотека Kryo, ранее не сумевшая проявить себя в гонке.
Результаты сериализации этих 3-х лидеров «взвешивания» ещё и отлично сжимаются (почти в двое). Самыми плохосжимаемыми оказались: бинарный эквивалент JSON-а – Smile и сам JSON.
Любопытный факт – все победители «взвешивания» при сериализации добавляют одинаковое количество служебных данных и к маленьким, и к большим сериализуемым объектам.
Перед принятием ответственного решения о выборе победителя, мы решили тщательнейшим образом проверить гибкость каждого сериализатора и его удобство использования.
Для этого мы составили 20 критериев оценки наших сериализаторов-участников соревнования, чтобы «ни одна мышь не проскочила» мимо наших глаз.
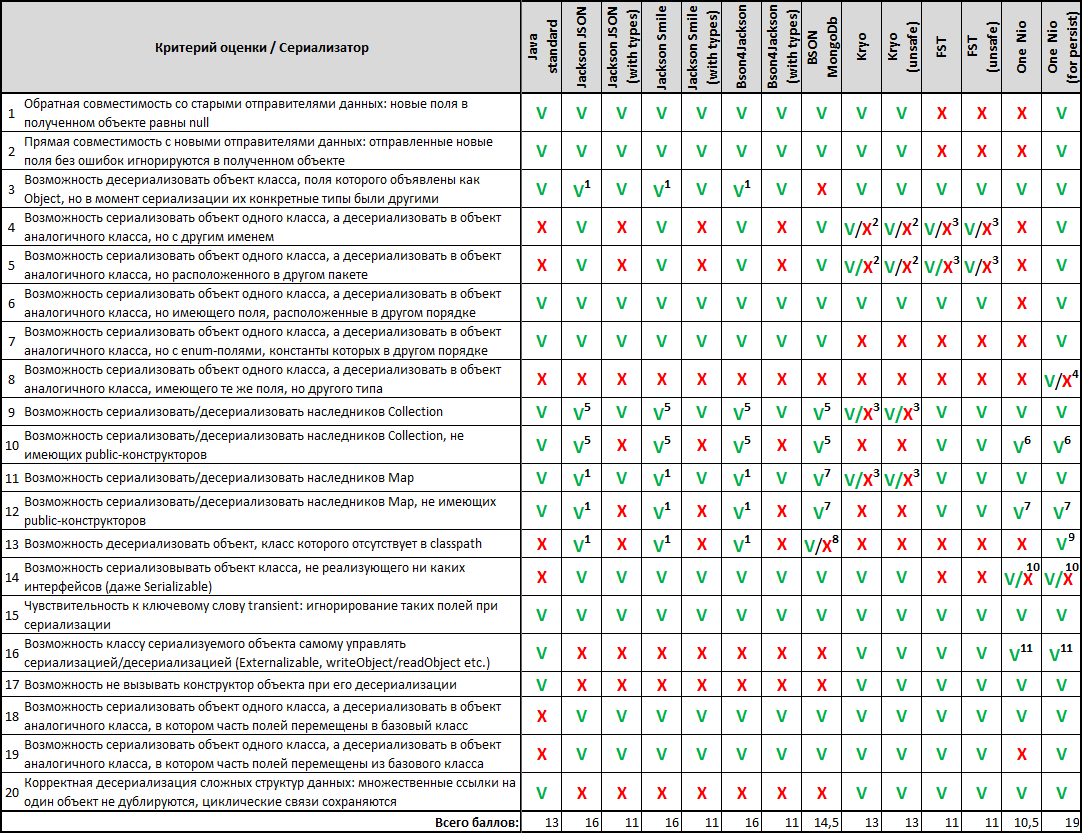
Данный скрупулёзный «осмотр претендентов» был, пожалуй, самым трудоёмким этапом нашего «кастинга». Но зато эти результаты сравнения хорошо открывают глаза на удобство использования библиотек сериализации. В последствие можно использовать эти результаты как справочник.
Как ни обидно было осознавать, но наши лидеры по результатам гонок и взвешивания – FST (unsafe) и One Nio – оказались аутсайдерами по гибкости... Однако нас заинтересовал любопытный факт: One Nio в конфигурации «for persist» (не самая быстрая и не самая компактная) набрала больше всех баллов по гибкости — 19/20. Очень привлекательной выглядела возможность заставить дефолтную (быструю и компактную) конфигурацию One Nio работать также гибко – и способ нашёлся.
В самом начале, когда мы представляли участников соревнования, говорилось о том, что One Nio (for persist) включает в результат сериализации детальную мета-информацию о классе сериализуемого Java-объекта (*). Используя эту мета-информацию при десериализации, библиотека One Nio точно знает, как выглядел класс сериализуемого объекта на момент сериализации. Именно на основании этого знания алгоритм десериализации One Nio является таким гибким, что обеспечивает максимальную совместимость получающихся при сериализации
Оказалось, что мета-информацию (*) можно отдельно получить для указанного класса, сериализовать в
Если произвести эту явную процедуру взаимообмена мета-информацией о классах между распределёнными сервисами, то такие сервисы смогут отправлять друг другу сериализованные Java-объекты, используя дефолтную (быструю и компактную) конфигурацию One Nio. Ведь, пока сервисы запущены, версии классов на их сторонах неизменны, а значит не зачем при каждом взаимодействии «таскать туда-сюда» константную мета-информацию внутри каждого результата сериализации. Таким образом, сделав немного больше действий в начале, затем можно использовать скорость и компактность One Nio одновременно с гибкостью One Nio (for persist). То что нужно!
В результате, для передачи Java-объектов между распределёнными сервисами в сериализованном виде (то, для чего мы и устроили данное соревнование) One Nio оказался победителем по гибкости (19/20).
Среди отличившихся ранее в гонках и взвешивании Java-сериализаторов не плохую гибкость продемонстрировали:
Вспомним результаты прошедших соревнований Java-сериализаторов:
Таким образом, по совокупности достигнутых результатов пьедестал у нас получился следующим:
В Сбербанке в нашем сервисе сессионных данных мы использовали библиотеку One Nio, занявшую первое место в нашем соревновании. С помощью данной библиотеки сериализовывались данные сессионного Java-контекста и передавались между приложениями. Благодаря данной доработке скорость работы сессионного транспорта кратно ускорилась. Нагрузочное же тестирование показало, что на сценариях, приближенных к реальному поведению пользователей в Сбербанк Online, было получено ускорение до 40% только лишь за счёт одной этой доработки. Такой результат означает снижение времени отклика системы на действия пользователей, что увеличивает степень удовлетворённости наших клиентов.
В следующей статье я постараюсь продемонстрировать в действии дополнительное ускорение One Nio, получаемое за счёт использования класса
Участники соревнования
Для соревнования мы отобрали наиболее популярные библиотеки Java-сериализации, главным образом, использующие бинарный формат, а также библиотеки, хорошо зарекомендовавшие себя в других обзорах Java-сериализаторов.
| 1 | Java standard | Стандартная Java-сериализация «из коробки», преобразующая Java-объекты в собственный бинарный формат. |
| 2 | Jackson JSON | Популярная библиотека FasterXML/jackson-databind, преобразующая Java-объекты в стандартный JSON-формат. |
| 3 | Jackson JSON (with types) | Та же библиотека, что и выше, но настроенная таким образом, чтобы включать в результат сериализации full qualified имена Java-классов. Это может быть востребованным при длительном хранении JSON-а (например, в БД) перед десериализацией. Вот, как выглядит такой JSON... Особенности настройки библиотеки... Вместо: |
| 4 | Jackson Smile | Библиотека FasterXML/jackson-dataformats-binary/smile, являющаяся расширением Jackson-а, преобразующая Java-объекты в бинарный эквивалент JSON-формата – Smile. |
| 5 | Jackson Smile (with types) | Та же библиотека, что и выше, но настроенная идентично «Jackson JSON (with types)» (full qualified имена Java-классов включаются в результат сериализации). |
| 6 | Bson4Jackson | Библиотека michel-kraemer/bson4jackson, являющаяся расширением Jackson-а, преобразующая Java-объекты в бинарный эквивалент JSON-формата – BSON. |
| 7 | Bson4Jackson (with types) | Та же библиотека, что и выше, но настроенная идентично «Jackson JSON (with types)» (full qualified имена Java-классов включаются в результат сериализации). |
| 8 | BSON MongoDb | Библиотека mongodb/mongo-java-driver/bson, также преобразующая Java-объекты в BSON-формат. |
| 9 | Kryo | Библиотека EsotericSoftware/kryo, преобразующая Java-объекты в собственный бинарный формат. |
| 10 | Kryo (unsafe) | Та же библиотека, что и выше, но настроенная на использование класса sun.misc.Unsafe для ускорения сериализации/десериализации. Особенности настройки библиотеки... Вместо классов: |
| 11 | FST | Библиотека RuedigerMoeller/fast-serialization, преобразующая Java-объекты в собственный бинарный формат. |
| 12 | FST (unsafe) | Та же библиотека, что и выше, но настроенная на использование класса sun.misc.Unsafe для ускорения сериализации/десериализации. Особенности настройки библиотеки... Вместо: |
| 13 | One Nio | Библиотека odnoklassniki/one-nio, преобразующая Java-объекты в собственный бинарный формат. |
| 14 | One Nio (for persist) | Та же библиотека, что и выше, но настроенная таким образом, чтобы включать в результат сериализации детальную мета-информацию о классе сериализуемого Java-объекта. Это может быть востребованным при длительном хранении byte[] (например, в БД) перед десериализацией. То есть преследуемая цель та же, что у «Jackson JSON (with types)».Особенности настройки библиотеки... Вместо: При такой сериализации object-а в result дополнительно помещается мета-информация:1) full qualified имя класса объекта object,2) имена всех полей этого класса, 3) full qualified имена классов всех этих полей, 4) предыдущие два пункта рекурсивно для класса каждого поля. Используя эту мета-информацию при десериализации, библиотека One Nio будет точно знать, как выглядел класс сериализуемого объекта на момент сериализации. |
Гонки
Скорость – вот основной критерий оценки библиотек Java-сериализации, которые являются участниками нашего импровизированного соревнования. Для того чтобы объективно оценить, какая из библиотек сериализации быстрее, мы взяли реальные данные из логов нашей системы и скомпоновали из них синтетические сессионные данные разной длины: от 0 до 1 МБ. По формату данные представляли собой строки и байтовые массивы.
Примечание: Забегая вперёд, следует сказать, что победители и проигравшие выявились уже на размерах сериализуемых объектов от 0 до 10 КБ. Дальнейшее увеличение размера объектов до 1 МБ не изменило исход соревнования.Конфигурация системы, на которой производились измерения:
В связи с этим, для лучшей наглядности, приведённые ниже графики эффективности работы Java-сериализаторов ограничены размером объектов в 10 КБ.
| Процессор | IntelR CoreTM i7-6700 CPU, 3.4GHz, 8 cores |
| Память | 16 GB |
| Операционная система | Microsoft Windows 10 (64-bit) |
| JRE | IBM J9 VM 1.7.0 |
Примечание: К нашему сожалению, на IBM JRE отказалась работать библиотека One Nio (участники под номерами 13 и 14). Эта библиотека использует классНепосредственное измерение скорости сериализации/десериализации выполнялось с помощью Java Microbenchmark Harness (JMH) – инструмента от OpenJDK для построения и запуска benchmark-ов. Для каждого измерения (одной точки на графике) использовалось 5 секунд для «прогрева» JVM и ещё 5 секунд для самих измерений времени с последующим усреднением.sun.reflect.MagicAccessorImplдля обращения кprivateиfinal(при десериализации) полям классов, минуя проверки уровня доступа. Оказалось, IBM JRE не поддерживает этих основных свойств классаsun.reflect.MagicAccessorImpl, несмотря на то, что сам класс в runtime имеется.
Для того чтобы не удалять данных участников гонки на самом старте (а, согласно Serialization-FAQ, библиотека One Nio обладает широкими возможностями), мы решили сделать fork данной библиотеки, в котором использование классаsun.reflect.MagicAccessorImplбыло бы выключаемым. При выключенном использованииsun.reflect.MagicAccessorImplв нашем fork-е используется классsun.misc.Unsafeдля достижения тех же целей.
Кроме того, в нашем fork-е была выполнена оптимизация сериализации строк – строки стали сериализовываться на 30-40% быстрее при работе на IBM JRE.
В связи с этим, в данной публикации все результаты для библиотеки One Nio получены на собственном fork-е, а не на оригинальной библиотеке.
UPD:
Код JMH-бенчмарка без некоторых деталей
public class SerializationPerformanceBenchmark {
@State( Scope.Benchmark )
public static class Parameters {
@Param( {
"Java standard",
"Jackson default",
"Jackson system",
"JacksonSmile default",
"JacksonSmile system",
"Bson4Jackson default",
"Bson4Jackson system",
"Bson MongoDb",
"Kryo default",
"Kryo unsafe",
"FST default",
"FST unsafe",
"One-Nio default",
"One-Nio for persist"
} )
public String serializer;
public Serializer serializerInstance;
@Param( { "0", "100", "200", "300", /*... */ "1000000" } ) // Toward 1 MB
public int sizeOfDto;
public Object dtoInstance;
public byte[] serializedDto;
@Setup( Level.Trial )
public void setup() throws IOException {
serializerInstance = Serializers.getMap().get( serializer );
dtoInstance = DtoFactory.createWorkflowDto( sizeOfDto );
serializedDto = serializerInstance.serialize( dtoInstance );
}
@TearDown( Level.Trial )
public void tearDown() {
serializerInstance = null;
dtoInstance = null;
serializedDto = null;
}
}
@Benchmark
public byte[] serialization( Parameters parameters ) throws IOException {
return parameters.serializerInstance.serialize(
parameters.dtoInstance );
}
@Benchmark
public Object unserialization( Parameters parameters ) throws IOException, ClassNotFoundException {
return parameters.serializerInstance.deserialize(
parameters.serializedDto,
parameters.dtoInstance.getClass() );
}
}
Вот, что получилось:
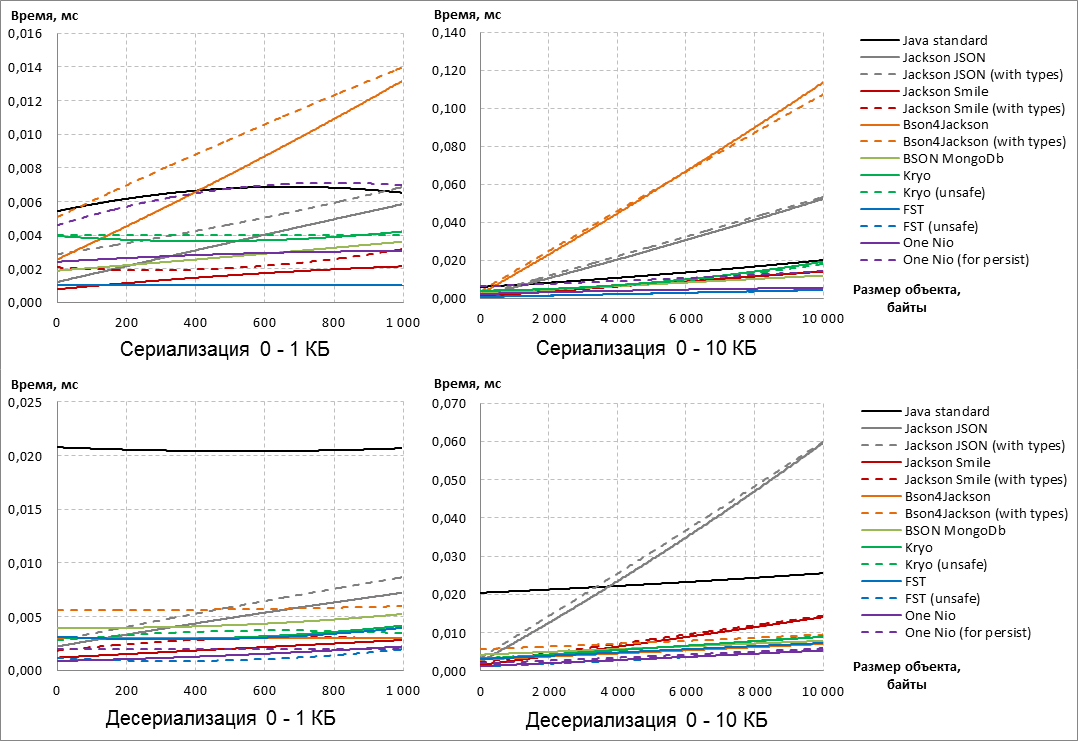
Сначала заметим, что варианты библиотек, добавляющие в результат сериализации дополнительные мета-данные, работают медленнее, чем дефолтные конфигурации этих же библиотек (см. конфигурации «with types» и «for persist»).
В целом, не зависимо от конфигурации аутсайдерами по результатам сериализации становятся Jackson JSON и Bson4Jackson, которые выбывают из гонки.
Кроме того, по результатам десериализации из гонки выбывает Java Standard, т.к. при любом размере сериализуемых данных десериализация кратно медленнее конкурентов.
Взглянем поближе на оставшихся участников:

По результатам сериализации в уверенных лидерах идёт библиотека FST, а при увеличении размера объектов ей «на пятки наступает» One Nio. Заметим, что у One Nio вариант «for persist» сильно медленнее дефолтной конфигурации по скорости сериализации.
Если взглянуть на десериализацию, то видим, что One Nio с увеличением размера данных смог обогнать FST. У последнего, напротив, нестандартная конфигурация «unsafe» заметно быстрее выполняет десериализацию.
Для того чтобы расставить все точки над И, давайте посмотрим на суммарный результат по сериализации и десериализации:
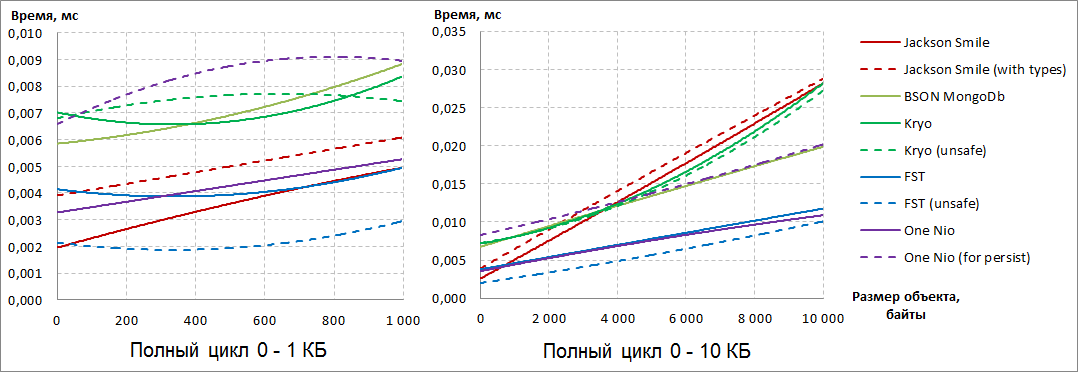
Стало очевидно, что однозначных лидеров два: FST (unsafe) и One Nio.
Если на небольших объектах FST (unsafe) уверенно лидирует, то с ростом размера сериализуемых объектов он начинает уступать и, в конечном счёте, уступает One Nio.
Третью позицию с ростом размера сериализуемых объектов уверенно занимает BSON MongoDb, хотя отрыв от лидеров у него почти двукратный.
Взвешивание
Размер результата сериализации – второй важнейший критерий оценки библиотек Java-сериализации. В каком-то плане, от размера результата зависит скорость сериализации/десериализации: компактный результат формировать и обрабатывать быстрее, чем объёмный. Для «взвешивания» результатов сериализации использовались всё те же Java-объекты, сформированные из реальных данных, взятых из логов системы (строк и байтовых массивов).
Кроме того, важным свойством результата сериализации является и то, на сколько он хорошо сжимается (например, для сохранения в БД или других хранилищах). В нашем соревновании мы использовали алгоритм сжатия Deflate, являющийся основой для ZIP и gzip.
Результаты «взвешивания» получились следующими:
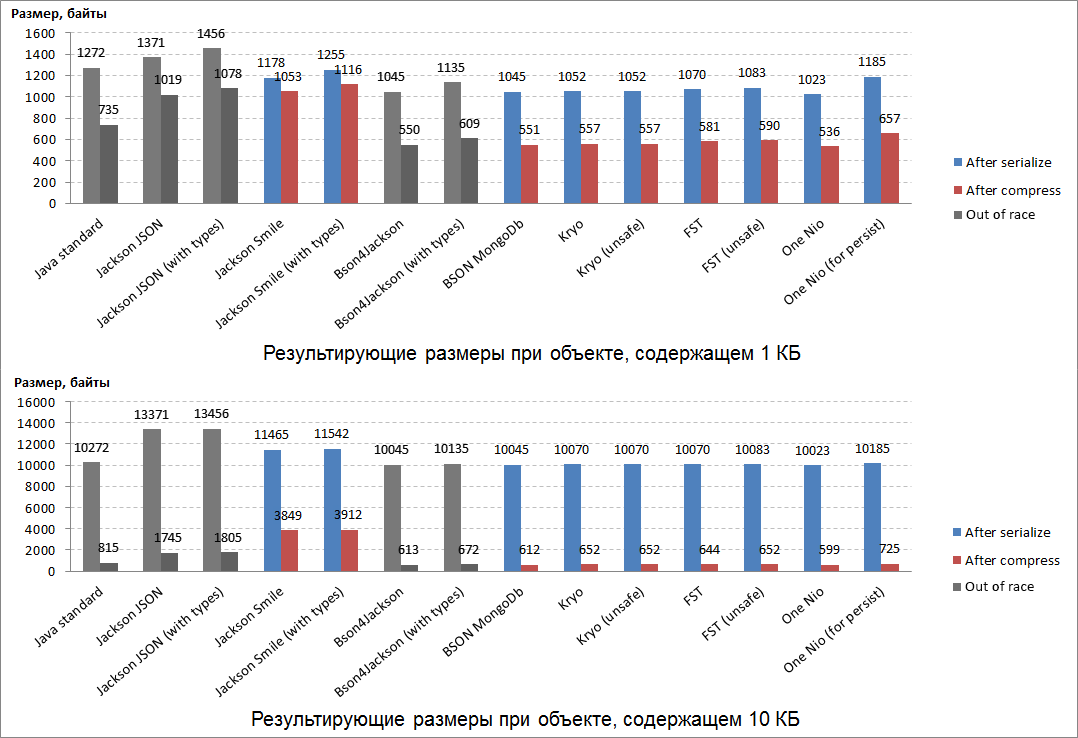
Ожидаемо, самыми компактными оказались результаты сериализации у одного из лидеров гонки: One Nio.
Второе место по компактности досталось BSON MongoDb (который занял третье место в гонке).
На третье место по компактности «вырвалась» библиотека Kryo, ранее не сумевшая проявить себя в гонке.
Результаты сериализации этих 3-х лидеров «взвешивания» ещё и отлично сжимаются (почти в двое). Самыми плохосжимаемыми оказались: бинарный эквивалент JSON-а – Smile и сам JSON.
Любопытный факт – все победители «взвешивания» при сериализации добавляют одинаковое количество служебных данных и к маленьким, и к большим сериализуемым объектам.
Гибкость
Перед принятием ответственного решения о выборе победителя, мы решили тщательнейшим образом проверить гибкость каждого сериализатора и его удобство использования.
Для этого мы составили 20 критериев оценки наших сериализаторов-участников соревнования, чтобы «ни одна мышь не проскочила» мимо наших глаз.

Сноски с пояснениями
UPD: По 13-ому критерию One Nio (for persist) получил ещё один балл (19-ый).1 Десериализуется
2 Для объекта в целом — ДА, для поля объекта — НЕТ.
3 Для объекта в целом — НЕТ, для поля объекта — ДА.
4 С использованием
5 Десериализуется
6 Десериализуется
7 Десериализуется
8 Для объекта в целом и для поля объекта — НЕТ, но если отсутствует класс объекта, располагавшегося в коллекции/Map-е, то ДА (при этом десериализуется
9 Десериализуется автоматически сгенерированный класс-заглушка.
10 В оригинальной библиотеке One Nio — НЕТ, в доработанном в СберТех'е fork-е — ДА.
11 При десериализации даже конструктор не вызывается.
LinkedHashMap.2 Для объекта в целом — ДА, для поля объекта — НЕТ.
3 Для объекта в целом — НЕТ, для поля объекта — ДА.
4 С использованием
sun.reflect.MagicAccessorImpl — ДА: boxing/unboxing, примитивы в BigInteger/BigDecimal/String. Без использования MagicAccessorImpl (доработанный в СберТех'е fork One Nio) — НЕТ.5 Десериализуется
ArrayList.6 Десериализуется
ArrayList или HashSet в зависимости от конкретного сериализованного типа.7 Десериализуется
HashMap.8 Для объекта в целом и для поля объекта — НЕТ, но если отсутствует класс объекта, располагавшегося в коллекции/Map-е, то ДА (при этом десериализуется
HashMap).9 Десериализуется автоматически сгенерированный класс-заглушка.
10 В оригинальной библиотеке One Nio — НЕТ, в доработанном в СберТех'е fork-е — ДА.
11 При десериализации даже конструктор не вызывается.
Данный скрупулёзный «осмотр претендентов» был, пожалуй, самым трудоёмким этапом нашего «кастинга». Но зато эти результаты сравнения хорошо открывают глаза на удобство использования библиотек сериализации. В последствие можно использовать эти результаты как справочник.
Как ни обидно было осознавать, но наши лидеры по результатам гонок и взвешивания – FST (unsafe) и One Nio – оказались аутсайдерами по гибкости... Однако нас заинтересовал любопытный факт: One Nio в конфигурации «for persist» (не самая быстрая и не самая компактная) набрала больше всех баллов по гибкости — 19/20. Очень привлекательной выглядела возможность заставить дефолтную (быструю и компактную) конфигурацию One Nio работать также гибко – и способ нашёлся.
В самом начале, когда мы представляли участников соревнования, говорилось о том, что One Nio (for persist) включает в результат сериализации детальную мета-информацию о классе сериализуемого Java-объекта (*). Используя эту мета-информацию при десериализации, библиотека One Nio точно знает, как выглядел класс сериализуемого объекта на момент сериализации. Именно на основании этого знания алгоритм десериализации One Nio является таким гибким, что обеспечивает максимальную совместимость получающихся при сериализации
byte[].Оказалось, что мета-информацию (*) можно отдельно получить для указанного класса, сериализовать в
byte[] и отправить на ту сторону, где будет происходить десериализация Java-объектов данного класса:С кодом по шагам...
// Сервис №1: Получаем мета-информацию о классе SomeDto
one.nio.serial.Serializer<SomeDto> dtoSerializerWithMeta = Repository.get( SomeDto.class );
byte[] dtoMeta = serializeByDefaultOneNioAlgorithm( dtoSerializerWithMeta );
// Сервис №1: Отправляем dtoMeta сервису №2
// Сервис №2: Восстанавливаем мета-информацию об удалённом классе SomeDto и сообщаем об этом библиотеке One Nio
one.nio.serial.Serializer<SomeDto> dtoSerializerWithMeta = deserializeByOneNio( dtoMeta );
Repository.provideSerializer( dtoSerializerWithMeta );
// Сервис №1: Сериализуем объекты класса SomeDto
byte[] bytes1 = serializeByDefaultOneNioAlgorithm( object1 );
byte[] bytes2 = serializeByDefaultOneNioAlgorithm( object2 );
...
// Сервис №1: Отправляем байты сервису №2
// Сервис №2: Десериализуем байты в объекты класса SomeDto
SomeDto object1 = deserializeByOneNio( bytes1 );
SomeDto object2 = deserializeByOneNio( bytes2 );
...
Если произвести эту явную процедуру взаимообмена мета-информацией о классах между распределёнными сервисами, то такие сервисы смогут отправлять друг другу сериализованные Java-объекты, используя дефолтную (быструю и компактную) конфигурацию One Nio. Ведь, пока сервисы запущены, версии классов на их сторонах неизменны, а значит не зачем при каждом взаимодействии «таскать туда-сюда» константную мета-информацию внутри каждого результата сериализации. Таким образом, сделав немного больше действий в начале, затем можно использовать скорость и компактность One Nio одновременно с гибкостью One Nio (for persist). То что нужно!
В результате, для передачи Java-объектов между распределёнными сервисами в сериализованном виде (то, для чего мы и устроили данное соревнование) One Nio оказался победителем по гибкости (19/20).
Среди отличившихся ранее в гонках и взвешивании Java-сериализаторов не плохую гибкость продемонстрировали:
- BSON MongoDb (14,5/20),
- Kryo (13/20).
Пьедестал
Вспомним результаты прошедших соревнований Java-сериализаторов:
- в гонках первые две строчки рейтинга поделили FST (unsafe) и One Nio, а третье место занял BSON MongoDb,
- на взвешивании победил One Nio, за которым шли BSON MongoDb и Kryo,
- по гибкости, именно для нашей задачи обмена сессионным контекстом между распределёнными приложениями, первое место снова досталось One Nio, а также отличились BSON MongoDb и Kryo.
Таким образом, по совокупности достигнутых результатов пьедестал у нас получился следующим:
- One Nio
В главном соревновании – гонках – делил первое место с FST (unsafe), но на взвешивании и при проверке гибкости существенно обошёл конкурента. - FST (unsafe)
Также очень быстрая библиотека Java-сериализации, однако ей не хватает прямой и обратной совместимости получающихся в результате сериализации байтовых массивов. - BSON MongoDB + Kryo
Эти 2 библиотеки поделили 3-ю строчку нашего рейтинга самых быстрых Java-сериализаторов, не требующих описания структуры данных. Обе библиотеки достаточно сильно отстали от 2-х лидеров по скорости, но при этом являются практически идентичными по компактности и гибкости. У обеих библиотек есть проблемы при сериализацииCollectionиMap, а у BSON MongoDB ещё и нет возможности custom-ного управления сериализацией/десериализацией (Externalizableи т.п.).
В Сбербанке в нашем сервисе сессионных данных мы использовали библиотеку One Nio, занявшую первое место в нашем соревновании. С помощью данной библиотеки сериализовывались данные сессионного Java-контекста и передавались между приложениями. Благодаря данной доработке скорость работы сессионного транспорта кратно ускорилась. Нагрузочное же тестирование показало, что на сценариях, приближенных к реальному поведению пользователей в Сбербанк Online, было получено ускорение до 40% только лишь за счёт одной этой доработки. Такой результат означает снижение времени отклика системы на действия пользователей, что увеличивает степень удовлетворённости наших клиентов.
В следующей статье я постараюсь продемонстрировать в действии дополнительное ускорение One Nio, получаемое за счёт использования класса
sun.reflect.MagicAccessorImpl. К сожалению IBM JRE не поддерживает самых главных свойств этого класса, а, значит, весь потенциал One Nio на этой версии JRE ещё не раскрыт. Продолжение следует.