
Умение модели распознавать намерения собеседника, то есть понимать зачем человек совершил то или иное действие, применимо в большом числе прикладных NLP-задач. К примеру, чат-ботам, голосовым помощникам и другим диалоговые системам это позволит эмоционально реагировать на высказывания собеседника, проявлять понимание, сочувствие и другие эмоции. Кроме того, задача распознавания намерения – это еще один шаг на пути к пониманию человеческой речи (human understanding).

Уже было предпринято несколько попыток решить данную задачу в той или иной форме. Например, на NLP-progress публикуются последние достижения в области commonsense reasoning. Слабость большинства существующих моделей заключается в том, что в их основе лежит supervised подход, то есть им требуются большие размеченные датасеты для обучения. А в силу специфичности задачи разметка часто бывает весьма нестандартной и достаточно сложной.
Для английского существует ряд корпусов и benchmark’ов, а вот для русского языка ситуация с данными намного печальнее. Отсутствие размеченных данных для русского часто является одним из основных препятствий, которое мешает русифицировать работающие английские модели.
В этом посте мы расскажем, как мы создали датасет для задачи Common Sense Reasoning в одной из ее возможных формулировок, предложенной в статье event2mind, а также адаптировали английскую модель event2mind от AllenNLP для русского языка. Для начала немного расскажем, что же из себя представляет задача Common Sense Reasoning.
На самом деле, правильнее было бы рассматривать это как целое направление задач, направленных на распознавание намерений и эмоций действующего лица. Единой формулировки у нее нет, и в данном посте мы возьмем за основу вот такой ее вариант, предложенный авторами event2mind: по короткому тексту в свободной форме, содержащему некоторое действие или событие (например, “PersonX eats breakfast in the morning”), определить намерения субъекта (“X wants to satisfy hunger”), его эмоции/реакции (“X feels satiated, full”) и возможные эмоции/реакции других участников события, если таковые присутствуют. Рисунок 1 это наглядно иллюстрирует.

В оригинальной английской статье авторы предложили модель event2mind для решения этой задачи, а также большой размеченный корпус для ее обучения для английского языка. Нашей задачей было русифицировать эту модель, адаптировав для русского языка. Данную модель мы хотели потом встроить в чат-бота, чтобы научить его понимать намерения пользователя и правильно реагировать на эмоции. Для этого мы собрали датасет для русского языка, в формате, аналогичному английскому, а также обучили и протестировали несколько моделей архитектуры event2mind на собранных данных.
Итак, нашей задачей было собрать корпус размеченных текстов в свободной форме в формате, пригодном для обучения event2mind. Для простоты дальше мы будем называть такие короткие тексты просто событиями. При этом мы старались максимально расширить common sense reasoning кругозор модели, собрав события на самые разные темы из повседневной жизни.
На первом этапе нам предстояло собрать достаточное количество «сырых» событий для последующей разметки. За основу мы взяли три источника данных:
На следующем шаге мы извлекли события из собранных текстов. События для тренировки event2mind можно определить как комбинацию глагольного предиката с входящими в составляющую глагола аргументами. Для поиска подобных паттернов был использован синтаксический парсер UdPipe, с помощью которого мы выделяли в текстах паттерны вида глагол + зависимые слова в синтаксическом дереве, как например на рисунке 2, которые удовлетворяли одному из следующих правил:

Отобранные события обезличиваются. По аналогии с оригинальным event2mind все действующие лица и именованные сущности были заменены на единообразные PersonX, а также PersonY и PersonZ, если в предложении упоминается более одного действующего лица. Для распознавания именованных сущностей (Named Entity Recognition) и дальнейшей замены мы вновь воспользовались UdPipe: в событиях, которые отвечают паттернам выше мы деперсонилизировали токены, помеченные тегами PROPN или PRONOUN. В завершении мы исключили события, которые не содержат одушевленных субъектов. Например, по этому критерию было отсеяно предложение «Идет дождь». В итоге в корпус вошли только события с одушевленными именованными сущностями (person named entities).
После деперсонализации и фильтрации мы воспользовались частотным анализом и расстоянием Левенштейна для отобора наиболее распространенных событий и фильтрации нестандартных примеров, которые встретились лишь единожды. Во-первых, мы взяли все события, которые встретились в первоначальной выборке больше одного раза. Для оставшейся части данных мы посчитали попарные расстояния Левенштейна , ), отобрали пары, для которых оно не превосходило 5 и из каждой пары взяли более короткое предложение. При таком методе мы руководствовались следующим соображением: если для пары событий их расстояние Левенштейна мало (в данном случае порог 5), то эти предложения отличаются весьма незначительно, например, в роде глагола или прилагательного. Фактически это вариации одного и того же события. А более короткое предложения из пары мы выбирали потому, что оно скорее будет содержать начальные формы слов (они чаще короче, хотя и не всегда).
, ), отобрали пары, для которых оно не превосходило 5 и из каждой пары взяли более короткое предложение. При таком методе мы руководствовались следующим соображением: если для пары событий их расстояние Левенштейна мало (в данном случае порог 5), то эти предложения отличаются весьма незначительно, например, в роде глагола или прилагательного. Фактически это вариации одного и того же события. А более короткое предложения из пары мы выбирали потому, что оно скорее будет содержать начальные формы слов (они чаще короче, хотя и не всегда).
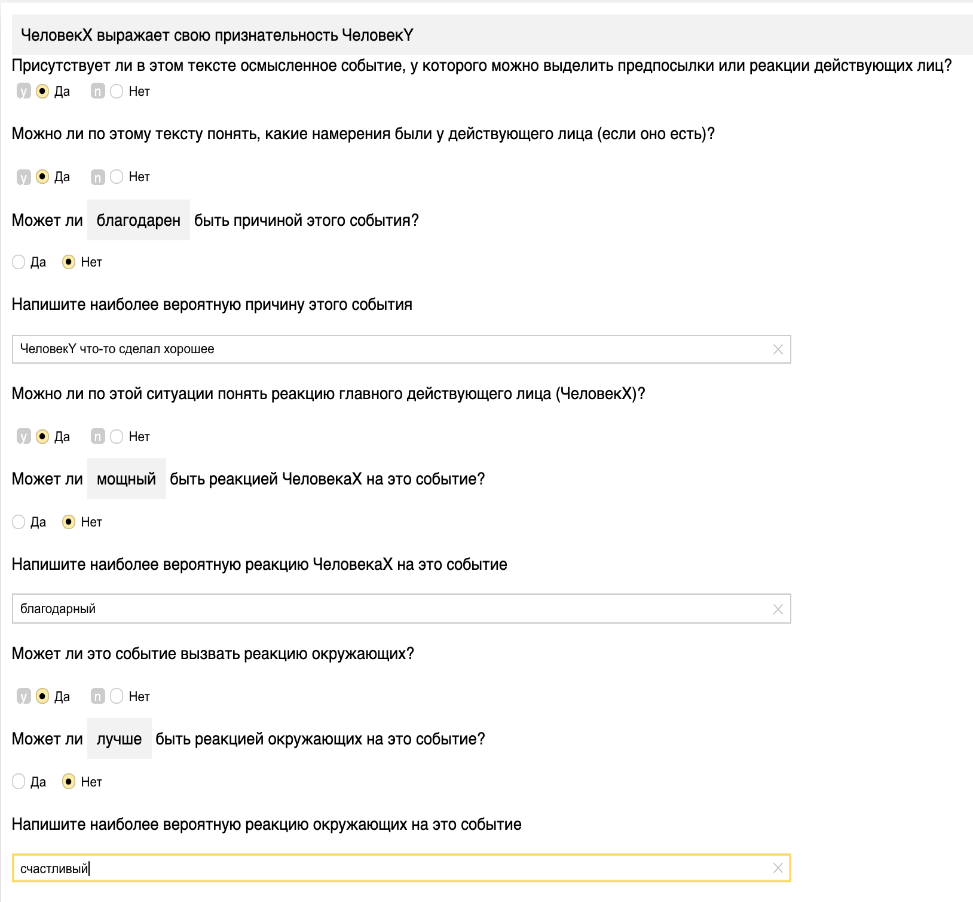
После сбора данных события предстояло разметить, выделив в них намерения PersonX, его эмоции/реакции, а также эмоции/реакции PersonY и PersonZ, если таковые присутствуют. Для этого мы создали задание в Яндекс.Толоке. Пример из него вы можете видеть на рисунке 3. Для каждого события мы спрашивали разметчиков:
Для облегчения труда толокеров мы подготовили для них подсказки – ответы пробной модели event2mind, обученной на переведенном английском корпусе event2mind. Так что им оставалось только верифицировать ответы «черновой» модели и по возможности предложить свои.
Тут стоит оговориться, что поскольку переведенные данные получились достаточно сырыми, то обученная на них модель оказалась слабой. До полноценной модели она не дотягивала, но в некоторых случаях ей достаточно точно удавалось угадывать эмоции и намерения субъектов.
В итоге нам удалось собрать 6756 событий на различные повседневные темы.
Помимо того, что мы использовали размеченный русский датасет, мы частично перевели английский корпус с помощью переводчика Google, а затем отфильтровали и откорректировали результат. Почему это было необходимо? Понятно же, что автоматический перевод несколько хуже исходно русских данных, размеченных вручную.
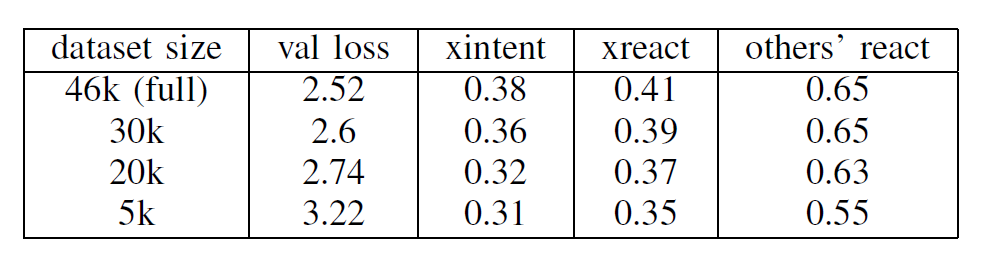
Дело в том, что разметка подобного датасета – трудоемкое дело, требующее большого количества ресурсов, денег и средств. У нас просто не было возможности разметить корпус, по размерам сопоставимый с английским, который состоит из 46 тысяч примеров. Поскольку собранный на русском датасет оказался меньшего размера, мы решили оценить, хватит ли такого объема данных для обучения. Для этого мы обучили английскую модель на частях оригинального корпуса и измерили, как меняется качество в зависимости от размера обучающего датасета. Результаты приведены в таблице. Качество для намерений (intent) и эмоций/реакций (react) оценивалось, по аналогии с оригинальной статьей, по метрике recall@10 на валидации. recall@10 отражает долю случаев, когда истинный ответ — golden standard – попадает в топ-10 предсказаний модели. Метрика меняется от 0 до 1, чем больше, тем лучше.
Сразу можно сказать, что 5000 примеров недостаточно для полноценного обучения модели. Однако уже при 30000 примеров, loss и recall практически не отличаются от результатов на полном объеме данных. Получается, что размеченных нами 7000 примеров не хватает для обучения модели и необходимо каким-то способом увеличить размер обучающей выборки.
Для этого мы подготовили дополнительный корпус, полученный из английского с помощью автоматического перевода Google Переводчиком. Как уже отмечалось выше, при автоматическом переводе всего корпуса некоторые переводы оказывались некорректными или полностью теряли смысл. Поэтому мы отобрали ту часть английских данных, которая переводилась наиболее адекватно. Изначально английский корпус собран из нескольких источников: ROC Story training set, the GoogleSyntactic N-grams, the Spinn3r corpus и idioms. При этом предложения из некоторых источников оказались проще для перевода, чем из других. Например, адекватный перевод идиом без ручной правки оказался не под силу компьютеру. Поэтому мы взяли только примеры из ROC-story. По результатам оригинальной статьи (см. таблицу 2), у этого источника коэффициент согласованности аннотаторов (Cohen's kappa coefficient), равный 0.57. А это, скорее всего, свидетельствует о том, что события оттуда проще для понимания и разметки, а значит меньше подвержены ошибкам при переводе.

После этого мы отфильтровали отобранные данные, удалили оттуда примеры, в которых после перевода остались английские слова и примеры, которые были переведены некорректно. Оставшаяся часть была отредактирована редакторами.
Стоит отметить, что несмотря на все уловки, фильтрацию и редактуру, переведенный корпус все равно отстает по «качеству» предложений от размеченного толокерами датасета.
В итоге нам удалось набрать 23409 переведенных событий, а объем объединенного корпуса с учетом размеченной русской части составил 30165. Этого, как мы выяснили во время экспериментов, должно было хватить для обучения русской модели.
Итак, данные собраны, пора переходить к обучению модели и экспериментам. Модель event2mind представляет собой нейросетевую архитектуру вида encoder-decoder с одним энкодером и тремя декодарами для каждого вида предсказаний (см. рисунок 4): намерение субъекта, его эмоции/реакции и эмоции/реакции других участников события, если таковые имеются (subject’s intent, subjects’s reaction и others events participants’ reactions). Исходные предложения изначально векторизуются с помощью одного из методов векторных представлений слов (например, word2vec или fasttext) и кодируются с помощью энкодера в вектор . А затем с помощью трех RNN декодеров генерируются предсказания. Благодаря этому модель может генерировать ответы даже для намерений и реакций, которые она до этого не видела.
. А затем с помощью трех RNN декодеров генерируются предсказания. Благодаря этому модель может генерировать ответы даже для намерений и реакций, которые она до этого не видела.
Рисунок 4. Архитектура модели event2mind

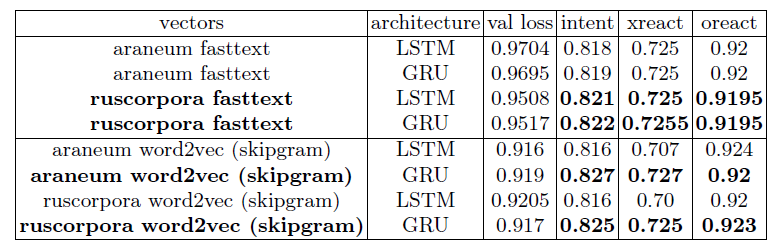
Для экспериментов мы использовали объединенный корпус для русского языка, размеченную и переведенную части. А чтобы сделать распределение русских и переведенных примеров более равномерным, мы дополнительно перемешали данные. Отметим, что мы также попробовали обучить модель только на размеченных данных, но из-за маленького объема датасета, она показала очень плохие результаты. Мы протестировали различные слои в энкодере – LSTM и GRU, а также попробовали различные векторные представления — fasttext и word2vec с RusVectores. Результаты приведены в таблице 3, результаты по intent’ам и react’ам, как и ранее считались по метрике recall@10.
Итак, какие выводы можно сделать из результатов экспериментов? Во-первых, word2vec embeddings оказались немного лучше, чем fasttext. При этом fasttext embeddings, обученные на ruscorpora показали себя лучше обученных на araneum. Во-вторых, можно отметить, что при использовании word2vec, GRU в энкодере оказывается лучше LSTM. И наконец, лучшая модель (areneum word2vec + GRU) практически повторяет результаты для английского языка.

Весьма неплохо! Намерения выглядят весьма правдоподобно и действительно отражают какие-то общечеловеческие понятия и знания. А вот с эмоциями/реакциями модель справилась несколько хуже, они получились более примитивными и однообразными. Возможно, это связано с тем, что эмоции зависят от большего объема текста и короткого текста-события недостаточно, чтобы правильно его определить.
Итак, мы создали русскоязычный корпус для обучения модели event2mind. Помимо этого, мы провели эксперименты, которые показали, что архитектура event2mind работает для русского языка, который по своей природе грамматически сложнее английского. Несмотря на сложность русского языка, удалось достичь сравнимого с английским качества. Лучшая модель и данные выложены в репозитории.
Такой большой проект стал возможен, только благодаря совместным усилиям нашей команды. В адаптации event2mind для русского языка также принимали участие alenusch и onetwotrickster.
Уже было предпринято несколько попыток решить данную задачу в той или иной форме. Например, на NLP-progress публикуются последние достижения в области commonsense reasoning. Слабость большинства существующих моделей заключается в том, что в их основе лежит supervised подход, то есть им требуются большие размеченные датасеты для обучения. А в силу специфичности задачи разметка часто бывает весьма нестандартной и достаточно сложной.
Для английского существует ряд корпусов и benchmark’ов, а вот для русского языка ситуация с данными намного печальнее. Отсутствие размеченных данных для русского часто является одним из основных препятствий, которое мешает русифицировать работающие английские модели.
В этом посте мы расскажем, как мы создали датасет для задачи Common Sense Reasoning в одной из ее возможных формулировок, предложенной в статье event2mind, а также адаптировали английскую модель event2mind от AllenNLP для русского языка. Для начала немного расскажем, что же из себя представляет задача Common Sense Reasoning.
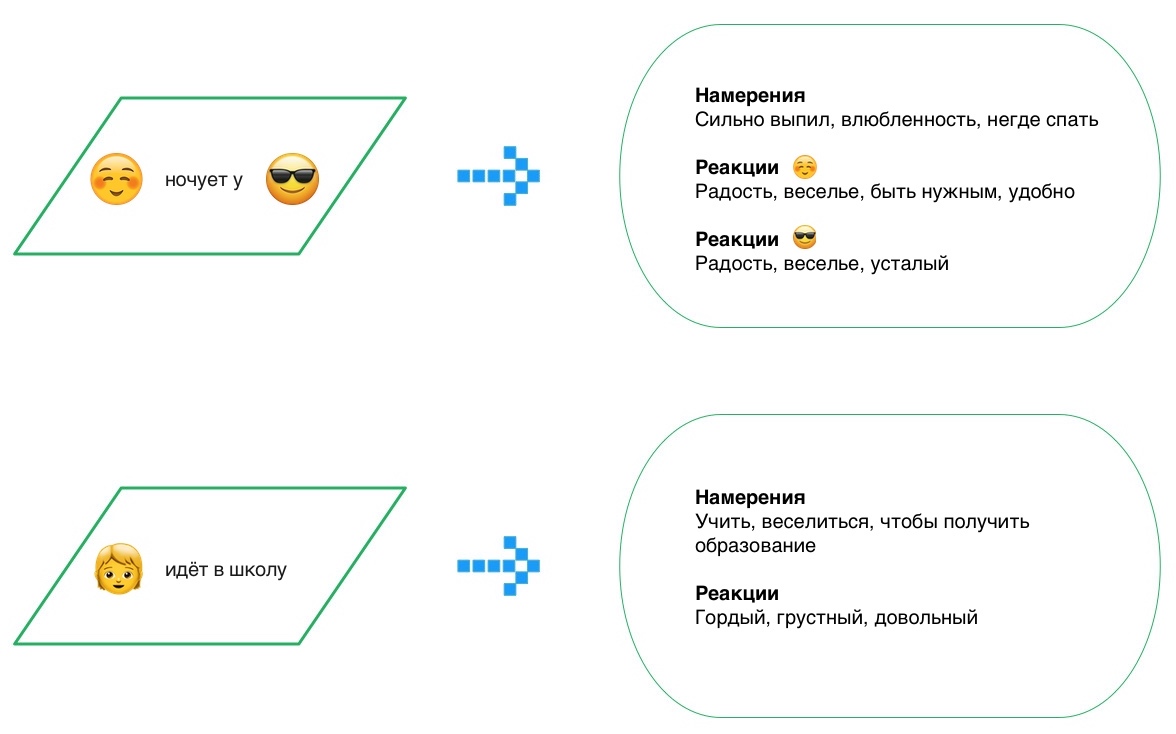
На самом деле, правильнее было бы рассматривать это как целое направление задач, направленных на распознавание намерений и эмоций действующего лица. Единой формулировки у нее нет, и в данном посте мы возьмем за основу вот такой ее вариант, предложенный авторами event2mind: по короткому тексту в свободной форме, содержащему некоторое действие или событие (например, “PersonX eats breakfast in the morning”), определить намерения субъекта (“X wants to satisfy hunger”), его эмоции/реакции (“X feels satiated, full”) и возможные эмоции/реакции других участников события, если таковые присутствуют. Рисунок 1 это наглядно иллюстрирует.
Рисунок 1. Задача Commonsense Reasoning — по короткому тексту-событию определить намерения, эмоции/реакции субъекта и эмоции/реакции окружающих

В оригинальной английской статье авторы предложили модель event2mind для решения этой задачи, а также большой размеченный корпус для ее обучения для английского языка. Нашей задачей было русифицировать эту модель, адаптировав для русского языка. Данную модель мы хотели потом встроить в чат-бота, чтобы научить его понимать намерения пользователя и правильно реагировать на эмоции. Для этого мы собрали датасет для русского языка, в формате, аналогичному английскому, а также обучили и протестировали несколько моделей архитектуры event2mind на собранных данных.
Данные, данные и еще раз данные
Итак, нашей задачей было собрать корпус размеченных текстов в свободной форме в формате, пригодном для обучения event2mind. Для простоты дальше мы будем называть такие короткие тексты просто событиями. При этом мы старались максимально расширить common sense reasoning кругозор модели, собрав события на самые разные темы из повседневной жизни.
Часть первая. Crowdsourced corpus
На первом этапе нам предстояло собрать достаточное количество «сырых» событий для последующей разметки. За основу мы взяли три источника данных:
- Короткие посерийные описания сериалов и мыльных опер. Мы вручную отобрали 50 сериалов с сюжетами из повседневной жизни, такие как «Друзья», «Секс в большом городе», «Санта-Барбара», «Универ», «Кухня» и другие. При этом мы старались выбирать сериалы «о повседневной жизни» с сюжетами на общие темы. Фантастика или профессиональные сериалы нам не подходили, так как они содержат очень много специальной лексики, и события там из своей специфичной области. Вы представляете, что может выучить модель, обученная на «Докторе Хаусе» или «Звездном пути»? Еще начнет подозревать у всех волчанку и сыпать рассказами о сражениях с инопланетянами.
- Краткие содержания книг. Суммарно нам удалось набрать краткие содержания 1512 книг.
- Тексты из SynTagRus, который является частью Русского Национального корпуса и содержит художественные тексты вместе с новостями.
На следующем шаге мы извлекли события из собранных текстов. События для тренировки event2mind можно определить как комбинацию глагольного предиката с входящими в составляющую глагола аргументами. Для поиска подобных паттернов был использован синтаксический парсер UdPipe, с помощью которого мы выделяли в текстах паттерны вида глагол + зависимые слова в синтаксическом дереве, как например на рисунке 2, которые удовлетворяли одному из следующих правил:
- nsubj + root + obj
- nsubj + root + iobj
- nsubj + advmod + root
- nsubj + root + case + obl
- etc.
Рисунок 2. Синтаксические паттерны, использованные для извлечения событий из текстов

Отобранные события обезличиваются. По аналогии с оригинальным event2mind все действующие лица и именованные сущности были заменены на единообразные PersonX, а также PersonY и PersonZ, если в предложении упоминается более одного действующего лица. Для распознавания именованных сущностей (Named Entity Recognition) и дальнейшей замены мы вновь воспользовались UdPipe: в событиях, которые отвечают паттернам выше мы деперсонилизировали токены, помеченные тегами PROPN или PRONOUN. В завершении мы исключили события, которые не содержат одушевленных субъектов. Например, по этому критерию было отсеяно предложение «Идет дождь». В итоге в корпус вошли только события с одушевленными именованными сущностями (person named entities).
После деперсонализации и фильтрации мы воспользовались частотным анализом и расстоянием Левенштейна для отобора наиболее распространенных событий и фильтрации нестандартных примеров, которые встретились лишь единожды. Во-первых, мы взяли все события, которые встретились в первоначальной выборке больше одного раза. Для оставшейся части данных мы посчитали попарные расстояния Левенштейна
, ), отобрали пары, для которых оно не превосходило 5 и из каждой пары взяли более короткое предложение. При таком методе мы руководствовались следующим соображением: если для пары событий их расстояние Левенштейна мало (в данном случае порог 5), то эти предложения отличаются весьма незначительно, например, в роде глагола или прилагательного. Фактически это вариации одного и того же события. А более короткое предложения из пары мы выбирали потому, что оно скорее будет содержать начальные формы слов (они чаще короче, хотя и не всегда).После сбора данных события предстояло разметить, выделив в них намерения PersonX, его эмоции/реакции, а также эмоции/реакции PersonY и PersonZ, если таковые присутствуют. Для этого мы создали задание в Яндекс.Толоке. Пример из него вы можете видеть на рисунке 3. Для каждого события мы спрашивали разметчиков:
- содержит ли оно осмысленное событие;
- можно ли по тексту события понять намерения действующего лица;
- можно ли по событию понять эмоции/реакцию действующего лица;
- может ли это событие вызвать реакцию окружающий.
Рисунок 3. Пример задания из Яндекс.Толоки
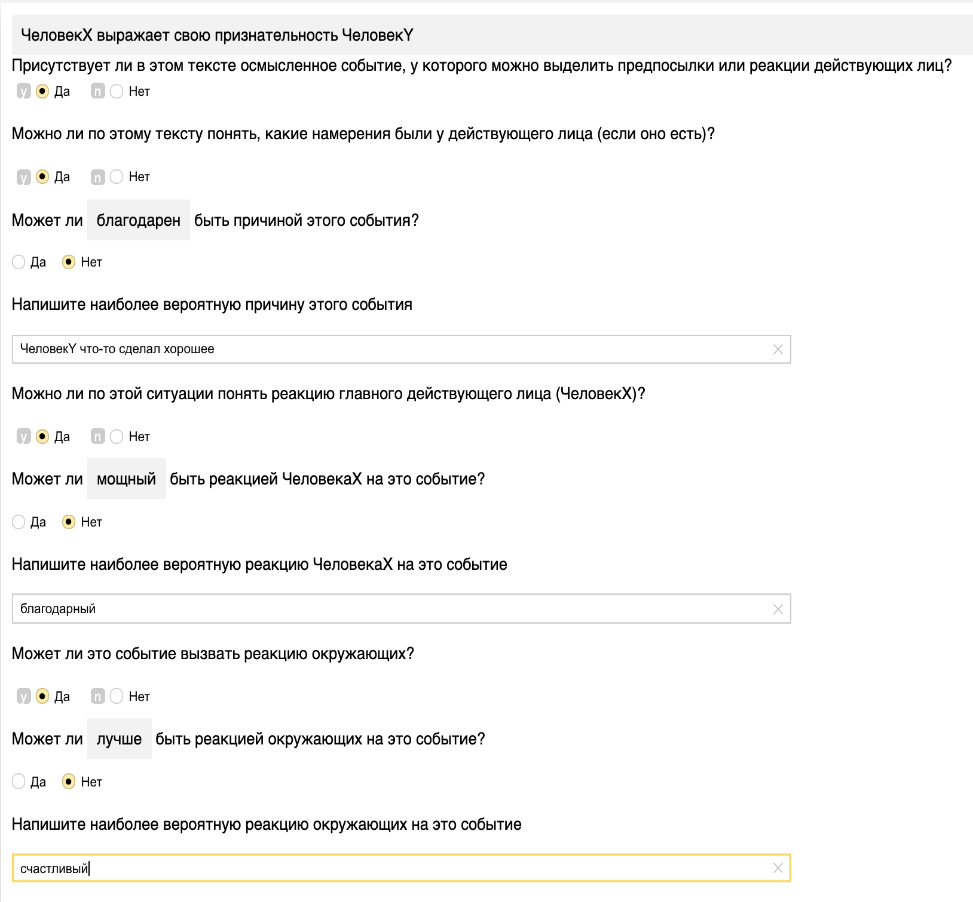
Для облегчения труда толокеров мы подготовили для них подсказки – ответы пробной модели event2mind, обученной на переведенном английском корпусе event2mind. Так что им оставалось только верифицировать ответы «черновой» модели и по возможности предложить свои.
Тут стоит оговориться, что поскольку переведенные данные получились достаточно сырыми, то обученная на них модель оказалась слабой. До полноценной модели она не дотягивала, но в некоторых случаях ей достаточно точно удавалось угадывать эмоции и намерения субъектов.
В итоге нам удалось собрать 6756 событий на различные повседневные темы.
Часть 2. Translated English corpus
Помимо того, что мы использовали размеченный русский датасет, мы частично перевели английский корпус с помощью переводчика Google, а затем отфильтровали и откорректировали результат. Почему это было необходимо? Понятно же, что автоматический перевод несколько хуже исходно русских данных, размеченных вручную.
Дело в том, что разметка подобного датасета – трудоемкое дело, требующее большого количества ресурсов, денег и средств. У нас просто не было возможности разметить корпус, по размерам сопоставимый с английским, который состоит из 46 тысяч примеров. Поскольку собранный на русском датасет оказался меньшего размера, мы решили оценить, хватит ли такого объема данных для обучения. Для этого мы обучили английскую модель на частях оригинального корпуса и измерили, как меняется качество в зависимости от размера обучающего датасета. Результаты приведены в таблице. Качество для намерений (intent) и эмоций/реакций (react) оценивалось, по аналогии с оригинальной статьей, по метрике recall@10 на валидации. recall@10 отражает долю случаев, когда истинный ответ — golden standard – попадает в топ-10 предсказаний модели. Метрика меняется от 0 до 1, чем больше, тем лучше.
Таблица 1. Зависимость качества английской модели от размера корпуса для обучения

Сразу можно сказать, что 5000 примеров недостаточно для полноценного обучения модели. Однако уже при 30000 примеров, loss и recall практически не отличаются от результатов на полном объеме данных. Получается, что размеченных нами 7000 примеров не хватает для обучения модели и необходимо каким-то способом увеличить размер обучающей выборки.
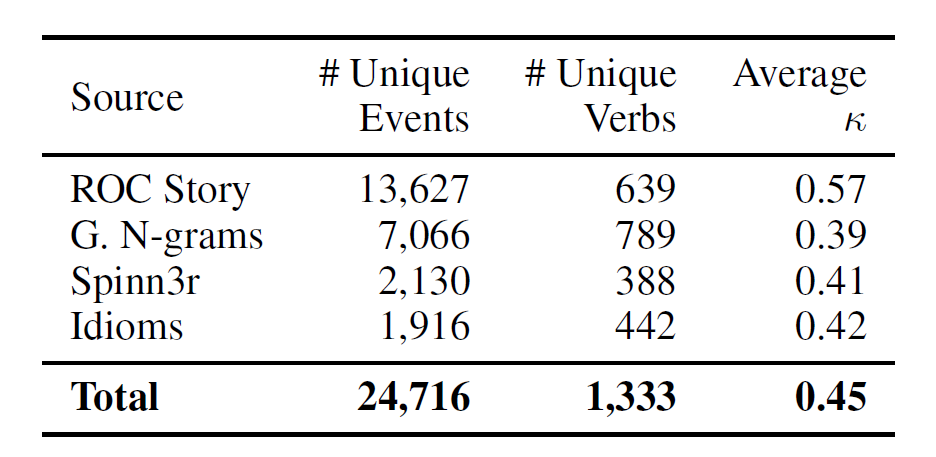
Для этого мы подготовили дополнительный корпус, полученный из английского с помощью автоматического перевода Google Переводчиком. Как уже отмечалось выше, при автоматическом переводе всего корпуса некоторые переводы оказывались некорректными или полностью теряли смысл. Поэтому мы отобрали ту часть английских данных, которая переводилась наиболее адекватно. Изначально английский корпус собран из нескольких источников: ROC Story training set, the GoogleSyntactic N-grams, the Spinn3r corpus и idioms. При этом предложения из некоторых источников оказались проще для перевода, чем из других. Например, адекватный перевод идиом без ручной правки оказался не под силу компьютеру. Поэтому мы взяли только примеры из ROC-story. По результатам оригинальной статьи (см. таблицу 2), у этого источника коэффициент согласованности аннотаторов (Cohen's kappa coefficient), равный 0.57. А это, скорее всего, свидетельствует о том, что события оттуда проще для понимания и разметки, а значит меньше подвержены ошибкам при переводе.
Таблица 2 Данные и Cohen's kappa coefficient для разных источников в английском корпусе
После этого мы отфильтровали отобранные данные, удалили оттуда примеры, в которых после перевода остались английские слова и примеры, которые были переведены некорректно. Оставшаяся часть была отредактирована редакторами.
Стоит отметить, что несмотря на все уловки, фильтрацию и редактуру, переведенный корпус все равно отстает по «качеству» предложений от размеченного толокерами датасета.
В итоге нам удалось набрать 23409 переведенных событий, а объем объединенного корпуса с учетом размеченной русской части составил 30165. Этого, как мы выяснили во время экспериментов, должно было хватить для обучения русской модели.
А теперь – к экспериментам!
Итак, данные собраны, пора переходить к обучению модели и экспериментам. Модель event2mind представляет собой нейросетевую архитектуру вида encoder-decoder с одним энкодером и тремя декодарами для каждого вида предсказаний (см. рисунок 4): намерение субъекта, его эмоции/реакции и эмоции/реакции других участников события, если таковые имеются (subject’s intent, subjects’s reaction и others events participants’ reactions). Исходные предложения изначально векторизуются с помощью одного из методов векторных представлений слов (например, word2vec или fasttext) и кодируются с помощью энкодера в вектор
. А затем с помощью трех RNN декодеров генерируются предсказания. Благодаря этому модель может генерировать ответы даже для намерений и реакций, которые она до этого не видела.Рисунок 4. Архитектура модели event2mind

Для экспериментов мы использовали объединенный корпус для русского языка, размеченную и переведенную части. А чтобы сделать распределение русских и переведенных примеров более равномерным, мы дополнительно перемешали данные. Отметим, что мы также попробовали обучить модель только на размеченных данных, но из-за маленького объема датасета, она показала очень плохие результаты. Мы протестировали различные слои в энкодере – LSTM и GRU, а также попробовали различные векторные представления — fasttext и word2vec с RusVectores. Результаты приведены в таблице 3, результаты по intent’ам и react’ам, как и ранее считались по метрике recall@10.
Таблица 3. результаты моделей для русского языка, intent и react оценивались по recall@10

Итак, какие выводы можно сделать из результатов экспериментов? Во-первых, word2vec embeddings оказались немного лучше, чем fasttext. При этом fasttext embeddings, обученные на ruscorpora показали себя лучше обученных на araneum. Во-вторых, можно отметить, что при использовании word2vec, GRU в энкодере оказывается лучше LSTM. И наконец, лучшая модель (areneum word2vec + GRU) практически повторяет результаты для английского языка.
И напоследок – посмотрим на реальные примеры!

Весьма неплохо! Намерения выглядят весьма правдоподобно и действительно отражают какие-то общечеловеческие понятия и знания. А вот с эмоциями/реакциями модель справилась несколько хуже, они получились более примитивными и однообразными. Возможно, это связано с тем, что эмоции зависят от большего объема текста и короткого текста-события недостаточно, чтобы правильно его определить.
Вместо заключения
Итак, мы создали русскоязычный корпус для обучения модели event2mind. Помимо этого, мы провели эксперименты, которые показали, что архитектура event2mind работает для русского языка, который по своей природе грамматически сложнее английского. Несмотря на сложность русского языка, удалось достичь сравнимого с английским качества. Лучшая модель и данные выложены в репозитории.

Такой большой проект стал возможен, только благодаря совместным усилиям нашей команды. В адаптации event2mind для русского языка также принимали участие alenusch и onetwotrickster.
