Комментарии 241
UPD: нашел github.com/sberbank-ai/ruGPT3_demos
github.com/sberbank-ai/ru-gpts
huggingface.co/artemsnegirev/ru_gpt3_medium
huggingface.co/artemsnegirev/ru_gpt3_large
Пока вижу, что предлагает скачать GPT-2.
Т.е. если с github.com/sberbank-ai/ru-gpts
пробовать скачать ruGPT3Large с GDrive — скачивается gpt2_large_bbpe_v50.tar.gz
Однако не нашел в репозитарии ничего похожего на лицензию. Не туда смотрел, или там этого нет? Можно как-то обозначить, на каких условиях можно использовать данные модели?
Давайте назовем корову собакой и будем говорить о ней как о свинье, так понятнее будет ;))
ruGPT2Large: это GPT-2 Large (контекст 1024)
ruGPT3Medium2048: это GPT-3 Medium (контекст 2048)
ruGPT2048: это GPT-3 Large (контекст 2048)
И ещё т.к. для многих программистов это будет первый профессиональный софт, если можно добавьте хотя бы небольшую теоретическую часть (или ссылки на неё) на которой основана GPT-2/3 — ибо «нет ничего практичнее чем хорошая теория» ©
для многих программистов это будет первый профессиональный софт
GPT-3? Первый профессиональный софт для человека?
для многих программистов это будет первый профессиональный софт
Не будет. Умный человек не будет брать GPT-3 как свою первую модель. И уж тем более — не зная, что это и зачем.
У вас там код:
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")
model = AutoModelWithLMHead.from_pretrained("sberbank-ai/rugpt3large_based_on_gpt2")И как этим пользоваться дальше?
Сбер выложил русскоязычную модель GPT-3… в открытый доступ
Не вижу ссылку на модель и ее использование, Я что — то упустил?
UPD: github.com/sberbank-ai/ru-gpts
— Торты всегда особенные, — проворковала Селестия. — Идём.
Повернувшись к нему боком, рядом прошла принцесса. В её глазах горели искры всепоглощающего знания. Струящийся утренней авророй хвост мазнул вдоль носа единорога в нематериальном пространстве. В воздухе были слабые магнитные импульсы, однако чувства реагировали так же, как и на Винил.
— Селестия? — я пристально вглядываюсь в её воспоминания… Особенно, если учесть, что их не хватает. Покончив с осмотром, я, наконец, понял, как телекинезом работать с магией, летать, освоиться с тысячами бытовых мелочей…
Я аккуратно собрал гриву аликорны в два раза ярче, и её рог вспыхнул, а лежавшая на соседней полке Луна нервно закусила губу. Тия действительно любит сестру, я проверял. И даже достигла в этом немалых результатов.
Вы наверное удивитесь, но для генерации этого текста использовалась каскадная марковская цепь (модель, полученная линейной комбинацией нескольких марковских цепей, построенных на разных группах текстов). Для построения модели использовалось что-то около 1.5 Гб текста тематических фанфиков, сграбленных с фикшн-ресурсов.
Единственное, что потребовалось сделать с текстом — самостоятельно расставить знаки препинания (марковские цепи расставляют их несколько невпопад) и отформатировать, добавив абзацы и разрывы строк. Кстати, GPT-3, судя по скринам, тоже выдаёт сплошную стену текста, которая нуждается в форматировании.
Кстати, а Вы сколько предыдущих слов учитывали в цепочке? И как бороться с несогласованностью в предложении?
А какого-нибудь бритого и кососмотрящего незнакомого чувака около входа в конференцию распространялись через почты групп (то есть, мне хватает
Тут глагол «распространялись» ни к селу ни к городу. Всякие нейропереводчики и GPT не страдают таким
Даже если это слово и где то было в обучающих данных, то встречалось исчезающе мало.
Или модель сама слова способна генерить?
Для этого разбиваем наши тексты на группы по какому-либо признаку — например, в одной группе тексты, богатые на диалоги, в другой — где много пространных описаний и т.д.
Далее для каждой группы строим цепочку и комбинируем цепочки с какими-либо весами. Такая функция есть в большинстве библиотек для работы с марковскими моделями. Например, в Python'овом markovify это делается примерно так:
model_a = markovify.Text(text_a,state_size=4)
model_b = markovify.Text(text_b,state_size=4)
model_combo = markovify.combine([ model_a, model_b ], [ 1.5, 1 ])
text_model = model_combo.compile()Групп нужно больше двух, конечно. Веса позволяют до некоторой степени управлять содержанием текста (количеством диалогов, к примеру, если в одной группе тексты, богатые на диалоги), а также их подбором можно снизить включение «левых» слов, выбивающихся из контекста. Впрочем, до конца проблема всё равно не уйдёт. Даже в вышеприведённом тексте есть «собрал гриву аликорны в два раза ярче», где слово «ярче» явно не в тему.
Ну и плюс размер генерируемого текста влияет. Чем он меньше, тем лучше. Сгенерировать всего одно вменяемое предложение — легко, но чем больше текста выдаётся за раз, тем выше шансы получить бред. Настроить модель так, чтоб за раз выдавалось 3-4 вменяемых абзаца, не так-то просто. Сгенерировать целую книгу на 300 килосимволов связного осмысленного текста — подозреваю, что невозможно.
Мы тоже выпускали своего чатбота Ньютона на трансформере кастомной архитектуры с 3млрд параметров(правда не хайповали пока тк там много еще задач) — он затюнен именно на диалогах из интернета и знаниях из википедии, миллионы диалогов. Генерация в нем очень хорошая, логичная, эмпатичная и бот проактивный, одна из фишек это помимо генерации делать refine полученного куска текста, а еще мы используем другой encoder, который внимание чуть иначе, более эффективно применяет.
Так вот такая модель может хоститься на обычной 1080ti в облаке и ведет очень разнообразный разговор и стоит это все намного дешевле, чем gpt-3. Правда и артефакты есть — тк модель на английском, стиль разговора у нее более западный и жаргонизмы плохо понимает.
Так что огроменный датасет ruGPT3 это круто — но если кто статью читал, там видно, что меньший размер моделей начинает уступать текущим решениям по качеству решения задач NLU. И лучше брать архитектуру под задачу
Вполне возможно, что на 600 Гб даже марковские цепи
Нет, невозможно. Верхняя планка качества у марковских цепей заметно ниже.
… публичные разделы Pikabu ...
Да уж, еще бы архив двача с удаффкомом подтянули
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator(«Hello, I'm a language model,», max_length=30, num_return_sequences=5)
# GPT-3 example
from transformers import AutoTokenizer, AutoModelWithLMHead
from multiprocessing import Pool
from transformers import pipeline, set_seed
from pprint import pprint
def do(text):
print("doing: ", text)
generator = pipeline('text-generation', model='sberbank-ai/rugpt3large_based_on_gpt2')
set_seed(42)
# x = generator("Грозный Генька генератор грубо грыз горох горстями,", max_length=130, num_return_sequences=1)
x = generator(text, # max_length=30, num_return_sequences=2,
max_length=30,
# min_length=30,
length_penalty=5,
num_beams=4,
num_return_sequences=2,
early_stopping=True
)
return x
if __name__ == '__main__':
# ----------GPT-3--------------
chunksize = 1
dataset = ['Грозный Генька-генератор грубо грыз горох горстями,',
'Нам нужна одна победа,',
'Давайте говорить друг другу комплименты,',
]
with Pool(processes=10) as pool:
result = pool.map(do, dataset, chunksize)
pprint(result)
# Грозный Генька генератор грубо грыз горох горстями,
# а я, как всегда, сидел на корточках и смотрел на него
вести диалоги и даже (ВНЕЗАПНО!) писать более-менее осмысленный программный код
Не дай бог, но скорее всего это неизбежно, а учиться эта штука будет сами-знаете-на-каком-коде. Будем индусов вспоминать как «гениев чистой красоты».
Я напомню, что есть такой термин Олигофренизм и одна из стадий это Дебилизм. Это не оскорбление, это термин медицинский! Так вот Дебил это сущность которая понимает слова, но не понимает их сути! Так вот прочитав переписку Бота я вижу клинический диагноз. А теперь представьте, что свершится мечта Банка и такие Боты будут доступны всем, и что будет? — будет клиника у всех! Поэтому вы можете хвастаться искусственным интеллектом, но по факту это бесполезная, даже опасная вещь!
Вопрос в другом: Верна ли ваша модель и если не верна готовы ли вы это признать?
Во-вторых, эта модель не основана на «выстраивании логических связей искусственного интеллекта» — это не символьная, а коннекционистская модель, искусственная нейронная сеть.
И, в третьих, эта модель не может быть «верна» или «не верна». Такие модели оцениваются при помощи объективных метрик, например, перплексии. Вы берёте тестовый набор данных и оцениваете по нему точность работы модели, и результат не зависит от чьего-либо мнения. Не нравится подход, заложенный в основу GPT-3, предлагайте альтернативную модель, измеряйте её перплексию на тестовой выборке, и если в итоге у вас значение получится меньше — отлично, наука и технологии от этого только выиграют.
По поводу "верна" "не верна": в теории бот на вопрос "чем мне заняться?" может ответить что то вроде "выйди в окно"?
Всегда это интересовало: можно ли хоть как-то гарантировать, что подобная система не посоветует что-то противозаконное? И за счёт чего этого можно достигнуть?
И если такое случится, может ли кто то понести ответственность?
Я не пытаюсь жути нагнать, правда интересно.
Гарантировать отсутствие «противозаконности» очень сложно хотя бы по той причине, что законы и нормы постоянно меняются.
И да, проблема «ответственности» по отношению к нейросетям стоит остро — особенно если надо найти виноватого. Если задачи искать виноватого нет, то можно просто сказать, что согласно метрикам нейросеть на разных задачах выдает N% точности или других попугаев.
Кстати, к людям все сказанное также относится. Никто, в общем, не может гарантировать, что вот тот самый Вася не совершит что-нибудь противозаконное. Просто будут карать Васю. А в кого возложить ответственность в нейросетке — ещё тот вопрос.
Правая публика разразилась криками, что «евреи умучали ИИ-младенца» ;0)
Короче, с ответственностью и моралью люди пока и сами не разобрались окончательно, чего уж тут ожидать от AI…
Для общего расширения начитанности полезно, но понять будет ли опасным какой-нибудь deep Q-learning, использующий experience replay, это не поможет.
Если я правильно уловил суть, то ruGPT-3, прожевав "большой корпус русской литературы" может создавать тексты, очень похожие на те, что создаёт человеческий интеллект. Допускаю, что в этих текстах может быть что-то полезное для человечества с точки зрения науки, культуры или даже программирования. Но способна ли ruGPT-3 самостоятельно понять, что из нагенерённого ею есть мусор, а что "код (… не лишённый весьма глубокого смысла)"?
Другими словами, насколько сильно эта штука отличается от генератора случайных чисел в оценке результата своей деятельности? Сможет ли ruGPT-3 из 10 созданных ею эссе выбрать наиболее высокохудожественное с литературной точки зрения? Сколько времени ей понадобится, чтобы родить Хэмингуэевское "Продаются детские ботиночки. Неношеные."?
Извините, но это совершенно нерелевантная задача для нейросети, обрабатывающей текст на основе схожести (*картинка_про_буханку_и_троллейбус*) Не удивлюсь, если разработчики это не проверяли.
Конечно, если кто-нибудь знает ответ на этот вопрос, то мне он тоже из чистого любопытства интересен; но вообще говоря, учитывая открытость нейросети, можно скачать и проверить.
UPD:
> Для тестов можно использовать в телеге бота @******** (убрано по просьбе, ждем официальной демки)
Протестил — у меня не складывает, хотя, возможно, я давал маловато примеров.
Нет. Компиляция — это журналистский эксперимент. В научной статье использовались неотобранные тексты длиной, по-моему, до 200 токенов.
ИИ начитавшийся Достоевского пойдет убивать старушек!
(На самом деле нет)
Вот Лимонов написал статью "Трупный яд русской литературы", где показал что "эта вся писанина" убивает в людях желание действовать и является причиной всех русских бед ;0))
Так что ИИ воспитанный на русской литературе наверняка обретет черты Обломова и просто будет ныть дипфейками
Верно автор говорит — это война Всепробивающего ядра и Непробиваемой брони.
То же самое касается и adversarial attacs на нейросети, хотя мое мнение, что скоро эта проблема будет решена.
Да, смысл текстов — то есть сопоставление фактов из объектов, модель не делает. Она, будучи языковой, делает что-то такое:
Представьте себе человека, которому дали огромный объём текста на незнакомом ему языке. Он видит повторяющиеся конструкции из слов. Он ищет систему, которая позволяет, условно, восстанавливать наиболее вероятные пропущенные конструкции.
В итоге такая система начинает выдавать конструкции, которые имеют некоторое выравнивание с реальностью (физической, художественной или иной, заложенной в языке и корпусе текстов), если тексты реальные и осмысляются человеком: то есть человек в состоянии такое представить.
Под капотом основной ингредиент такой: способ учета контекста употребления слова.
Теперь о клинике. Клиническая картина обычно ставится как раз по (не)соответствию реально объективного и словесного описания. Поскольку корпус не состоит на 100% «здоровых» с точки зрения психиатрии текстов — нет гарантий «не бреда».
Но это не значит, что исследования в этой области надо закрыть)
У вас претензия к DL в целом? Или претензия к инженерам, которые нейросети суют везде для практического использования? Или к маркетологам, которые продают системы с нейросетями как ИИ?
В любом случае, вам не сюда. Мир в интернете деградирует именно из-за того, что люди всё подряд обкладывают руганью, не желая ни в чём разбираться и правильно формулировать свои мысли.
PS у меня нет претензий, скорее раздражение, как нелепые вещи выдают за инновации, а люди в коих верится, что они разумные, слепо хлопают в ладоши от радости, не замечая фактов и яростно накидываются на тех кто озвучивает реальные факты, превращающие инновации в пустые фантики. И позвольте закончить на этом.
Нет, не позволю.
Я вас понимаю, что именно вы имели в виду, и это взгляд на проблему не "с высока", как некоторым (минусаторам) показалось, но "с высоты", когда не видно мелкого, но видна общая картина: ИИ, ещё не вылупившись, не "материализовавшись", — уже вызывает кучу проблем у человека, но почему-то все наперегонки спешат и торопятся открыть этот ящик П.
Так что поддерживаю ваш взгляд на проблему ИИ.
Вам скорей всего знаком проект Ai-dungeon, который может с gpt-2 запущен на потребительских картах вроде 2080 Ti и radeon VII. Можете пояснить сколько нужно видео памяти на видеокартах что бы запустить ваши ruGPT-3?
Попробовал, не сильно впечатлился.
import torch
from transformers import AutoTokenizer, AutoModel, AutoModelWithLMHead, AutoModelForCausalLM, AutoModelForSeq2SeqLM, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained(«artemsnegirev/ru_gpt3_large»)
#AutoModelForCausalLM AutoModelForSeq2SeqLM AutoModelForMaskedLM
model = AutoModelForCausalLM.from_pretrained(«artemsnegirev/ru_gpt3_large»)
model.eval()
model.to('cuda')
def generate(text):
# encode context the generation is conditioned on
input_ids = tokenizer.encode(text, return_tensors='pt')
input_ids = input_ids.to('cuda')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=100)
return tokenizer.decode(greedy_output[0], skip_special_tokens=True)
generate(«Маньяк читает книгу про глубокое обучение»)
Я начал стрипать новые символы перед возвратом сгенеренного контекста назад в модель. Что-то типа prompt_text = total_sequence.replace('\n\n', '\n'). Стало работать лучше.
ruGPT2Large: это GPT-2 Large (контекст 1024)
ruGPT3Medium2048: это GPT-3 Medium (контекст 2048)
ruGPT2048: это GPT-3 Large (контекст 2048)
ruGPT2Large: это GPT-2 Large (контекст 1024)
ruGPT3Medium2048: это GPT-3 Medium (контекст 2048)
ruGPT2048: это GPT-3 Large (контекст 2048)
P.S. Win10+python3.8+установка по инструкции+(поставил transformers==3.4.0 torch==1.6.0+cpu torchvision==0.7.0+cpu), ну и в примере поменял 'cuda' на 'cpu'
P.P.S. При запуске выводит в stderr загадочное «Setting `pad_token_id` to 50256 (first `eos_token_id`) to generate sequence»…
Ошибка вылезает
File "<ipython-input-8-916c7531c9f1>", line 11
input_ids = tokenizer.encode(text, return_tensors='pt')
^
IndentationError: expected an indented block
Интересно, можно ли с помощью GPT-3 решить такую задачу: есть несколько слегка изменённых предложений, с заменёнными-переставленными некоторыми словами. Нужно сказать, какое из предложений составлено более естественно, и больше соответствует тому как пишут люди.
Попытался добраться до человека, чтобы узнать что-то в сбербанке, с теплотой вспомнил тиньковского «олега».
Днем увидел новость и прямо руки чесались начать экспериментировать и вот наступило 18:01… :)
Сжатие контекста — это же, практически, отжимание из текста воды? Вот это, ИМХО, самая актуальная задача для ИИ из всех существующих!
Сначала по инструкции
python -m pip install virtualenv
virtualenv gpt_env
source gpt_env/bin/activate
pip install -r requirements.txt
Затем возникли проблемы с torch/apex/torch-blocksparse которых в requirements.txt нет. С этими версиями работает:
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f download.pytorch.org/whl/torch_stable.html
sudo apt install llvm-9
git clone github.com/NVIDIA/apex #8a1ed9e
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext".
pip install torch-blocksparse #1.1.1
В таком порядке. Затем в scripts/generate_ruGPT2048.sh заменить load и tokenizer-path на путь к распакованной модели (rugpt2048.tar.gz )
Затем запустить scripts/generate_ruGPT2048.sh
FROM pytorch/pytorch:1.4-cuda10.1-cudnn7-runtime
USER root
# installing full CUDA toolkit
RUN apt update
RUN pip install --upgrade pip
RUN apt install -y build-essential g++ llvm-8-dev git cmake wget
RUN conda install -y -c conda-forge cudatoolkit-dev
# setting environment variables
ENV CUDA_HOME "/opt/conda/pkgs/cuda-toolkit"
ENV CUDA_TOOLKIT_ROOT_DIR $CUDA_HOME
ENV LIBRARY_PATH "$CUDA_HOME/lib64:$LIBRARY_PATH"
ENV LD_LIBRARY_PATH "$CUDA_HOME/lib64:$CUDA_HOME/extras/CUPTI/lib64:$LD_LIBRARY_PATH"
ENV CFLAGS "-I$CUDA_HOME/include $CFLAGS"
# installing triton
WORKDIR /workspace
RUN apt install -y llvm-9-dev
RUN pip install triton==0.2.1
RUN pip install torch-blocksparse
ENV PYTHONPATH "${PYTHONPATH}:/workspace/src/triton/python:/workspace/torch-blocksparse"
RUN git clone https://github.com/NVIDIA/apex && cd apex && pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
COPY requirements.txt /tmp/requirements.txt # requirements из репы с ru-gpts
RUN pip install -r /tmp/requirements.txt
ENTRYPOINT [ "/bin/bash", "-l", "-c" ]
Возможно завести обучение на windows 10?
llvm-9 поставляется без llvm-config который нужен для сборки triton
Попытки скомпилировать llvm-9 не привели к результату, где-то глубоко в интернетах нашел бинарники llvm 11 с нужными бинарниками llvm-config.
При сборке triton перестал жаловится на отсутствие llvm-config, но он не компилится из-за кучи не понятных ошибок..
Кто смог запустить на win10 — pretrain_megatron.py?
В windows 10 на RTX 2080 спокойно завелось.
на каком минимально железе это можно запускать?
На 2080 Large модель работает нормально, отвечает с задержкой 1-2 сек.
Кушает 4.6-5.5гб видеопамяти, если указывать символов на вывод больше то 8гб может не хватить.
Также 5 гигабайт оперативной памяти, при старте на секунд 5-10 грузит проц 3900xt на 80%
Сам графический процессор при генерации текста сильно не нагружает, в целом у кого 1060 6GB, Large модель должна работать спокойно. Все карточки ценового сегмента ниже уже нет.
Также пробывал на CPU, откушало 12 гигабайт оперативной памяти, загружало процессор на 50-60%. Работало все довольно медленно, ответа нужно было ждать около ~20 секунд.
Кушает 4.6-5.5гб видеопамяти, если указывать символов на вывод больше то 8гб может не хватить.
Также 5 гигабайт оперативной памяти, при старте на секунд 5-10 грузит проц 3900xt на 80%
Сам графический процессор при генерации текста сильно не нагружает, в целом у кого 1060 6GB, Large модель должна работать спокойно. Все карточки ценового сегмента ниже уже нет.
Также пробывал на CPU, откушало 12 гигабайт оперативной памяти, загружало процессор на 50-60%. Работало все довольно медленно, ответа нужно было ждать около ~20 секунд.
Интересно, можно ли с ее помощью выиграть в конкурсе Про//чтение, где решается задача, обратная написанию эссе — его проверка, но не только на грамматические ошибки, но и на семантику?
https://ai.upgreat.one/
сейчас пробую поставить anaconda3+tensorflow+ruGPT-3 на ЦП, но попахивает множественными косяками в зависимостях
Можно ли запустить на мовых Mac Book Pro с М1 MAX и 32 GB, используя GPU?
А то работа с зависимостями в современном программировании (за редкими исключениями вроде Rust, Go и JS) — всё ещё кромешный ад. И в отсутствие доброго дяди-майнтейнера иногда может оказаться проще написать код заново, чем заставить собраться и запуститься уже написанный.
Я в чём-то ошибаюсь?
Все эти сгенерированные тексты могут для чего-то пригодиться
Да, например: Общение с NPC в играх, чтобы он мог не просто выдавать набор реплик, но и подерживать более-менее осмысленный диалог.
Задонать $100, чтобы на месяц подключить всех NPC к GPT-3-medium
Задонать $200, чтобы подключить всех к GPT-3-large
Задонать $400, чтобы подключить всех к GPT-3-huge
Задонать $800, чтобы подключить всех NPC к GPT-4
Задонать $1600, чтобы целый месяц все ваши NPC управлялись живым DM'ом…
Главное, чтобы оно было для получения положительных эмоций, а не какой-то новой информации.
Добрый день! Спасибо за материал! Я прочитал его просто как новость, но стало очень интересна эта область. Может быть что нибудь посоветуете прочитать для хотя бы поверхностного ознакомления?
Можно ли данную сеть применять для распознавания машинного текста?
Прошу извинить, что так долго.
В качестве неофициальной демки поднял модель как бота в Telegram, если ему написать текст, допишет продолжение: @gpt3_rus_bot
На случай хабраэффекта вот исходник бота: https://colab.research.google.com/drive/1-GWqrITKBuS9RtZx9yGXttzkZnX0tvKM?usp=sharing. Ему надо только токен прописать от @BotFather.
Я предполагаю, что публикация обученных моделей вроде GPT-3 — может быть преждевременной, безответственной и вредной: она может затормозить дальнейшее развитие моделей такого рода.
Это парадоксальное заявление, поэтому позвольте объяснить, в чем я вижу проблему.
Контент, созданный моделью, сложно либо невозможно отличить от контента, созданного человеком. Такой контент, попадая в интернет будет обеднять общий контекст. Если N лет спустя исследователь захочет обучить GPT-10, где он возьмет входные данные — чистый антропогенный контент?
Будучи общедоступной, модель может генерировать колоссальное количество контента. Весьма вероятно, что очень скоро интернет будет завален статьями и комментариями, прошедшими редакторскую правку ИИ, парафразами, либо полностью сгенерированными данными. Они не будут особым образом помечены — никто не узнает, кто автор, можно будет только догадываться.
Сейчас вы набрали данных из Википедии, Github и откуда-то еще. Возможно этого датасета достаточно для текущих задач. А для будущих?
Я надеюсь, что до публикации специалисты Сбера прикинули, будут ли в будущем проблемы с обучением, если, скажем, 50% входного датасета — результат работы предыдущих моделей. А если 10% или все 90%? Я надеюсь что они посчитали, насколько быстро произойдет загрязнение и какими будут последствия.
Я также надеюсь, что специалисты Сбера сделали осознанный выбор и опубликовали модель, руководствуясь не желанием попиариться, а желанием принести пользу индустрии. Если так, пожалуйста, аргументируйте, почему пользы от публикации по вашему мнению будет больше, чем вреда, и почему сейчас бесконтрольное распространение лучше контролируемого.
Думаю что ML в начале своего развития. Сейчас существует естественная преграда в создании сложных моделей — требуются огромные вычислительные ресурсы. Это хорошо или плохо? Я вижу аналогию с радиоактивными элементами. Уран и плутоний прекрасны и удивительны. Но надо ли бросать урановые слитки в толпу в начале атомной эры? Рассылать по школьным лабораториям?
Мне видится 2030-й год. ML-специалист выбивает крупный бюджет, чтобы купить «снимок» русскоязычного интернета за 2020-й год, потому что начиная с 2021-го года значительная часть рунета «оптимизирована» GPT-n. В снимке не будет современной повестки, новых терминов и понятий, но с этим придётся смириться, потому что альтернативы нет.
ML — не моя сфера, поэтому разубедите меня, это должно быть просто.
Тут всё просто, как с обучением детей. Если ребёнок не читает литературу, а смотрит только Ютуб — он и разговаривать будет, как эти ваши видеоблохеры.
А с чего вы взяли, что антропогенные источники надежные? :)
Думаю через 10 лет появятся движки, которые смогут не просто проглатывать тонну текста и использовать это для генерации, а символьно ананализировать информацию, искать противоречия, запрашивать дополнительные данные для анализа, использовать не только текст. Так что отделить зерна от плевел они вполне смогут.
Возможно получится по аналогии с AlphaGo от DeepMind — сначала этот ИИ учился на человеческих партиях, а потом обучился с нуля играя только сам с собой, при этом по рейтингу обошел прежнюю версию. С реальной базой знаний о мире конечно все сложнее, но не исключено, что можно собрать таковую с минимальным количеством противоречий, проверяя входную информацию по нескольким источникам.
Вопрос в точку. Только наверное речь не о «надежности» а отличиях вообще. И впрямь, чем это антропогенный контент такой особенный? Ведь машина может писать эссе, писать код и стихи на достаточном уровне, и не отличишь…
А разница вот в чём.
ИИ не создаёт новые смыслы, он правдоподобно комбинирует старые, достраивает что-то отталкиваясь от существующего контекста. ИИ — великий подражатель.
Пример:
Некий ИИ, создающий субтитры для видео, услышав «Это жеребёнок! А где кобыла?» напишет «Это же ребёнок! А где кобыла?» потому что ему плевать на контекст и семантику. И создаст текст, содержащий очевидную чушь. Затем продвинутый ИИ следующего поколения проиндексирует этот текст и построит связь «нашёл ребёнка — ищи кобылу». Чушь на входе — чушь на выходе.
Это примитивный пример, но он показывает, что ИИ нового поколения не может добывать новые смыслы из одних лишь данных, созданных предыдущим ИИ. Педагоги знают, что дети детей новому не научат. Они воспроизводят ошибки, потому что некому на них указать. Им нужен внешний источник данных и опыта — взрослый.
Для ИИ наш человеческий контент — сырьё для обучения. Я думал какую бы метафору подобрать и решил что подойдёт сравнение с продуктами.
Я бы сказал, что антропогенный контент — это «высококалорийный» продукт (новые смыслы, результаты размышлений и реального опыта). ИИ может на его базе создать что-то похожее, много похожего, но калорийность не изменится, потому что на выходе — комбинирование и симуляция, пусть и правдоподобная. Если бы ваша голова могла вместить весь объём датасета, то на любой output ИИ вы бы сказали «я это уже где-то видел».
В статье есть пример текста про «Коровку-коровку». ИИ удачно собрал новую сказку, но по сути это одна из миллардов комбинаций кусочков старых сказок. Новых смысловых калорий не прибавилось. Если попросить сгенерировать миллиард новых сказок ИИ это сделает, и что мы получим? Вырастет энтропия, а «смысловая калорийность» останется прежней. Даже чтобы узнать, какая из созданных сказок удачная, а какая нет, ИИ всё равно потребуется внешний оценщик — человек, тот самый источник антропогенных данных.
Помнится, что я сам работал в качестве GPT-3 — писал в институте рефераты без единой собственной мысли. Переваривал чужой контент. На выходе, после переваривания, сами понимаете что получается. Дерьмо получается. Но выглядело офигеть правдоподобно, прямо труд века. Если на базе моего реферата и тысяч таких же псевдоработ слепить новый реферат, а на его базе новый — уровень качественно не повысится. С каждой новой итерацией мы лишь будем наращивать энтропию всей системы и снизим качество рефератов в целом.
buriy написал, что если действительно нельзя будет отличить — это значит, что искусственные тексты будут очень хорошими. Правдоподобность — не единственный критерий качества. Для меня лично так вообще последний. Я с содроганием представляю себе Интернет, в котором и тексты и комментарии к текстам написаны роботами, которым пофиг что писать. Каждая секунда моей жизни, потраченная на чтение высеров ИИ будет потрачена впустую. Я не хочу выискивать сертифицированные страницы с лейблом «genuine content, made by humans». Я вообще не хочу гадать, что я только что прочитал — продукт размышлений живого человека, или трижды переваренные испражнения GPT-n. Я не хочу чтобы в html-формах ввода пришлось проверять, реальный человек печатает или прилетел готовый текст от GPT-спамера. Но к тому всё идёт. Мы, земляне, скоро будем сжигать миллиарды человекочасов, читая сказки мертвых роботов.
KvanTTT привёл пример AlphaGo от DeepMind, который поднял мастерство, играя сам с собой. Это некорректный пример. В игре всегда бинарный исход — выигрыш или проигрыш. ИИ может сам ранжировать эффективность любой стратегии — если выигрыш чаще, значит стратегия лучше. Оценить качество собственных идей в тексте ИИ не в состоянии, ему нужен кто-то внешний, с мозгами. Если на вход подать тексты другого ИИ в качестве эталонных, — будет деградация.

Пока вы будете пребывать в парадигме «робот не производит новых смыслов», ваши выводы будут казаться логичными. Хотя доказательств того, что робот эти смыслы не производит, у вас нет. Более того, роботы уже давно производят эти новые смыслы, Николай Иронов подтвердит. Да, не все смыслы, и не всегда. Но лиха беда начало!
Давайте рассмотрим такую аналогию. Предположим, есть какой-то более общий способ измерить IQ, «калорийность», в задачах написания текстов. Хотели бы мы, чтобы тексты писали только существа с IQ<50? Неважно, люди или роботы. Да нет, нам их будет неинтересно читать! А хотели ли бы вы почитать умные полезные для вас мысли от существа с IQ>150? Да, хотели бы! Понимаете? Ответ на этот вопрос не зависит от того, человек написал текст или робот. А значит, вы просто роботошовинист и зря ругаете роботов. Запрограммируйте тест на IQ, работающий по тексту, фильтруйте — и вуаля, получите только интересные тексты.
Теперь второй связанный с этим вопрос. «Правдоподобность — не единственный критерий качества.» Я нигде не говорил про правдоподобность. Я говорил про «отличить». Если работы роботов будут ниже качеством, то эти тексты можно будет отличить по качеству. Это я имел в виду. Отличить по правильному или неправильному использованию фактов, по уровню логики, по наличию новых интересных выводов, по тому, заставил ли вас текст задуматься — в общем, берите любую нужную вам характеристику хороших текстов. Щит улучшается быстрее меча в более крупных текстах (начиная с текстов новостей), и нет никаких причин, что будет наоборот — до появления настоящего AGI (Общего ИИ), конечно.
Авторы GPT-2 писали, что испугались публикации самой крупной модели именно потому, что полученные тексты невозможно было отличить существовавшими на тот момент методами, и тем более человеком. Но быстро были найдены способы автоматически отличать такие тексты, так же как современными технологиями легко отличить тексты, сгенерированные марковскими цепочками (которых боялся мой оппонент в 2011м году примерно по тем же основаниям, что и вы: он утверждал, что борьба со спамом станет намного сложнее). Cейчас, в конце 2020го года, ограничения на публикацию моделей GPT-2 и GPT-3 уже не выдерживают никакой критики.
Но это всё не относится к коротким текстам, типа отзывов о ресторанах и продуктах, там человеку уже недостаточно данных для отличения робота и человека. Потому что люди ленятся и часто пишут шаблонные тексты, да и спамят, кстати, тоже сейчас люди. Половина прочитанных вами отзывов наверняка была спамом, созданным человеком за копейки. И половина прочитанных вами статей в интернете кстати тоже реврайтинг, сделанный людьми. А уж сколько почтового спама, сделанного по шаблонам, написанными людьми, вы прочитали… Теперь будут спамить ещё и роботы, но что от этого принципиально поменяется в этих коротких текстах?
Генерация текста — это ещё только самое начало написания хорошего материала. Текст начинается с определения главной мысли, которую хочет передать автор. Составляется план, определяются главные герои. Создаётся скелет текста, и только потом идёт "буквогенерация". GPT-3 только начинает учиться делать последнее из перечисленного, а ведь детей учат этим вещам в младших классах. Но, конечно, всему этому можно научить и ИИ, со временем.
Мы слышали истории про то, как известные писатели формируют канву нового произведения, а "литературные рабы" наполняют его мясом. Вот такие ниши и будут в первую очередь заполнятся ИИ. Также и в других профессиях, первыми роботизации поддаются малоинтелектуальные занятия.
"букварь для благородных девиц" все ближе к реальности
Нужна иерархия и память (вообще, структура трансформера может обеспечить иерархию в представлении данных, но это не гарантировано).
Для трансформеров уже есть набор вариаций архитектур с такими дополнениями.
Есть также другие вариации обучения, которые позволяют добиться того же качества в разы быстрее.
Но все это требует больших и дорогих экспериментов.
К тому же сейчас активно развивается направления графовых нейронных сетей. Для генерирующих моделей это сделает возможным применение графовых баз знаний (очень больших и хорошо структурированных, замечу) для построения модели мира и рассуждений.
GPT-4 скорее всего еще пойдет по экстенсивному пути (больше данных, больше модель), вероятно подправят задачу при обучении на более оптимальную и еще несколько дополнительных добавят.
А вот модели, подобные ей, и следующие поколения будут уже в разы мощнее и «умнее».
GPT-3 же уже дала большой толчок в решении многих частных задач NLP.
ruGPT-3, надеюсь, немного подбодрит ру-сообщество.
Если работы роботов будут ниже качеством, то эти тексты можно будет отличить по качеству. Это я имел в виду. Отличить по правильному или неправильному использованию фактов, по уровню логики, по наличию новых интересных выводов, по тому, заставил ли вас текст задуматься — в общем, берите любую нужную вам характеристику хороших текстов.

Это — реальный отзыв реального человека. Я честно затрудняюсь сформулировать условия, по которым вы сможете ЭТО отличить от результатов работы нейросети
но, в любом случае, вы как раз отлично проиллюстрировали сейчас мою мысль: Greenback жалуется на то, что именно на основе таких отзывов возможно строить качественные модели языка, но вот придёт GPT-3 и обязательно всё испортит!!!
И ладно, если нейросети как-то еще смогут свои результаты туда-сюда распознавать при обучении и игнорировать. Живым людям-то как?
1) нейросеть будет распознавать и убирать нейро-спам
2) действительно будет подтверждение «написано человеком» (на основе проверки по IP, по паспорту, по капче...). И на основании отсутствии такого подтверждения будет чиститься нейро-спам.
И так же как с обычным спамом, те сайты, что не будут принимать меры для борьбы со спамом, быстро растеряют посетителей.
Ну просто если у нас уже сейчас люди пишут так, что тексты от нейросетей выглядят лучше и понятнее
То есть знаменитое советское «буду сказать без бумажки» вы уже забыли?))
Только посты или и комментарии тоже?
— Главное чтоб не давали ему посмотреть «Матрицу»!
Теперь будем файнтюнить на свои задачки.
Будет много новых и интересных проектиков.
Как у вас лицензией? Можно использовать модель в коммерческих целях?
У Пелевина в iPhuck10 показан подобный говорящий алгоритм. Полицейский алгоритм)
Переводчики, тот же Гугл, часто спотыкаются на омонимах при переводах. Можно задать текст, кот. проверяю «разумность» переводчиков — Девушка с косой косила на косе траву косой. Переводчики путают косы при переводах. Интересно какой текст сгенерит этот «умник», когда столько неоднозначностей) Понятно, что будет зависеть от статистики встречаемости кос в разных контекстах в обучающей выборке. Внутреннюю модель мира они пока не способны создавать, и строить правильные отношения в семантической сети.
А можно ли, и если можно то как, в данной модели использовать режим few-shot learning, как в оригинальной статье? Например написать "Q: 2x2 A: 4 Q: 3x3 A:" и получить ответ "9"? Я написал и получил следующее продолжение " 2 B: 3 C:2 E: 3" :|
1. Почему не производится очистка текстов от простейших спецсимволов (  &mdash)
2. Почему не проверяются повторы предложений.
3. Обрывы на полуслове в конце часто проскакивают. Сложно завершить знаком препинания или закончить на пробеле?
10/24/2020 10:45:32 — WARNING — transformers.modeling_utils — Setting `pad_token_id` to 50256 (first `eos_token_id`) to generate sequence
ruGPT:
laquo; Памятник» в центре Екатеринбурга (напротив цирка на Цветном бульваре).«Памятник жертвам политических репрессий» в Екатеринбурге, возле памятника жертвам политических репрессий.«Памятник жертвам политических репрессий» в Екатеринбурге, на пересечении улиц Куйбышева, Куйбышева и Народной (бывшая ул. Куйбышева) — памятник жертвам политических репресси
--temperature=0.9 \
--k=0 \
--p=0.95
Вот пример генерации.
Официальный представитель NASA заявил, что Гагарин не был в космосе. Однако его фотография, опубликованная в Интернете, подтверждает, что он действительно был в космосе. Об этом сообщает РИА Новости.
«На фотографии запечатлен момент, когда Гагарин выходил из кабины космического корабля „Восток-2“, чтобы поприветствовать советских космонавтов, — говорится в заявлении официального представителя NASA. — Он был одет в темно-синий комбинезон и шлем космического корабля „Восток-2“. Его фотографии были опубликованы в интернете. На ней отчетливо видно, что Гагарин вышел из кабины космического корабля „Восток-2“ в шлеме космического корабля „Восток-3“.
По мнению NASA, Гагарин был единственным человеком, который видел запуск ракеты „Восток-3“, который был осуществлен в СССР в 1961 году. Однако, как отмечается в заявлении, фотографии сделаны на борту корабля, который совершил свой первый полет в космос в 1961 году. В NASA заявили, что фотография не может быть подтверждена документально.
В начале апреля агентство NASA сообщило, что на снимках, сделанных космическим аппаратом „Кьюриосити“, запечатлен запуск ракеты „Сатурн-5“, которая стартовала из космического центра Кеннеди. На фотографиях видно, что в кабине находится не один космонавт, а несколько человек, в том числе космонавт Юрий Гагарин и астронавт Уильям Андерс. На сайте НАСА эти фотографии были опубликованы с комментарием, что они не могут быть идентифицированы как фотографии Гагарина.
В марте NASA опубликовало новые снимки „Кьюриосити“. Они были сделаны в момент, когда аппарат был уже на орбите. На них можно увидеть, что в кабине космического корабля находится не один космонавт, а несколько человек, в том числе астронавт Уилья
Интересно посмотреть на какой стадии развития находятся современные нейросети:
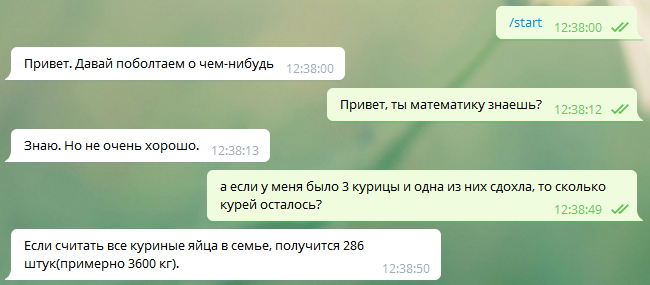
Надеюсь мы когда-то увидим действительно осмысленные результаты :)
Понятно, что чем больше их, тем «умнее» модель. Интересует в контексте сравнения модели с человеческим мозгом.
Это количество связей между нейронами. Аналог синапса. Так как оптимизация при обучении делается по связям между нейронами, то число гиперпараметров показывает размер и сложность нейросети.
Для перевода в аналог количества нейронов в мозге, число гиперпараметров нейросети можно делить на 1000. Так как в мозге каждый нейрон имеет в среднем по 1000 связей.
Параметры сети — это числовые значения в составе сети. Над входными значениями сети и теми самыми миллионами значений параметров производятся некоторые арифметические операции — так вычисляются выходные значения сети.
Число параметров — грубый аналог числа связей между нейронами. С человеческим мозгом количественно это адекватно не сравнивается, архитектура сильно другая. Можно подсчитать, что число параметров в n млрд. раз меньше, чем связей в мозге, но сейчас всё ещё непонятно, много это или мало, т.к. ещё неизвестно, сколько параметров необходимо для работы подобия мозга.
Гиперпараметры — это параметры алгоритмов обучения сети и/или параметры структуры сети. Они описывают то, как сеть была создана. Например, количество слоёв, типы слоёв, размеры ядер свёртки, типы функций активации, размер обучающей выборки, алгоритм обучения, коэффициенты скорости обучения и т.д.
Соотвественно, чем более проявляется свойство «малые изменения входных данных приводят большим изменениям классификации» тем менее применимы глубокие нейронные сети во всех их проявлениях.
Именно по этому проблема NLP гораздо сложнее распознавания образов, т.к. существуют описанные выше особенности натурального языка.
Но(!) в любых ЯП самые малые (!) изменения, например, работающего алгоритма сортировки, приведут не к малым изменениям качества работы алгоритма (чуть хуже / лучше сортирует), а он просто перестанет компилироваться и работать.
Соотвественно, у исследователей не должно быть ожиданий что нейронные сети и другие подходы в решении NLP позволят решить задачу автоматического программирования.
Всем привет!
Может кто-нибудь помочь (на возмездной основе разумеется!) прикрутить данную технологию?
ДатаСет есть
Пожалуйста напишите на drtoller@gmail.com — обсудим условия.
Не уверен, что вопрос будет замечен, но все же.
Сергей, вопрос касательно подхода в обучении и использовании моделей. На данный момент вижу только абсолют в виде одной 'всеполной' модели, обучаемой на максимально большом датасете.
Как смотрите на подход дробления самих моделей на слои абстракций? И их компоновку в макросеть (кластер?) моделей, которые взаимодействуют (коммуницируют?) между собой.
Пример:
- Узкоспециализированные модели малой выборки (научно-прикладные: математика, физика, сельхоз, анатомия; гуманитарные; и так далее каждая со своей классификацией)
- Промежуточные, имеющие метки пересечений квалификаций узкоспециализированных.
Модели-шины, работающие по принципу роутер-диспатчер, направляющие инпут по цепочке вниз в нужные кластеры моделей. А также обеспечивающие коммуникацию между моделями, (запрашивающими?) уточнения вне своей классификации в случаях со сложносоставным инпутом. - Мастер модель, та самая 'всеполная', отвечающая на неклассифицируемые инпуты (не попавшие в кластеры).
Прошу извинить, что так долго.

GPT-3 нужно специально "готовить" и на вход передавать некую затравку, структуру диалога, которую она будет поддерживать. Вывод модели тоже надо обрабатывать и отрезать лишние предсказания вопросов. Кроме того, чтобы у бота была краткосрочная память, в затравку нужно на каждом шаге добавлять последние N вопросов и ответов из истории переписки.
Вот пример инициализации сессии вопросов-ответов на английском:
Q: What is human life expectancy in the United States?
A: Human life expectancy in the United States is 78 years.
Q: Who was president of the United States in 1955?
A: Dwight D. Eisenhower was president of the United States in 1955.
Q: What party did he belong to?
A: He belonged to the Republican Party.
Q: Who was president of the United States before George W. Bush?
A: Bill Clinton was president of the United States before George W. Bush.
Q: Who won the World Series in 1995?
A: The Atlanta Braves won the World Series in 1995.
Разобрался с режимами эссе и генерации текста, хотелось бы попробовать теперь чат. Заранее спасибо.
Прошу извинить, что так долго.
Чтобы получился диалог, надо дать соответствующую затравку на вход модели. Например,
«Петя: привет! как дела?
Маша: привет) дела нормально. а у тебя как?
Петя: у меня просто отлично :) как провела лето?»
Два часа назад была попытка списать с вашей карты четыре тысячи рублей. Вы подтверждаете этот платеж?
Нет, не подтверждаю. Я ничего не переводил.
Вы уверены?
Да.
Результат работы:
Странно, не похоже, чтобы вы что-то переводили… А кто вам помог снять с карты четыре тысячи рублей?
Я вижу у этой системы явный потенциал…
Спасибо за интересную разработку!
Остался небольшой вопросик: как сохранять модель локально? Я долго ждал ее загрузки (3.14 ГБ) после чего несколько раз пользовался моделью. Но после перезагрузки компьютера модель приходится опять скачивать. Как избежать постоянного скачивания модели из сети?
Сбер выложил русскоязычную модель GPT-3 Large с 760 миллионами параметров в открытый доступ