Комментарии 51
Очень захватывающе, спасибо! Всегда с большим увлечением читаю новости о GPT-3.
Не подскажете: какое минимальное железо требуется чтобы запустить хотя бы минимальную версию ruGPT?
В идеале хотелось бы готовый docker-image, который можно просто запустить на любом лэптопе и попробовать поиграться с сетью.
Вот еще примре со школьного трека — обучаем сетку за 20 минут писать сочинения в колабе: colab.research.google.com/drive/1h6r6Qg9xwyIzz6-FXgB9tIjAzce0gc2d?usp=sharing
После знакомства с теми же нотубуками на kaggle, прямо скажем, ожидаешь хотя бы не трёх пунктов по полстроки с непонятно чем.
Впрочем, политика понятна. Наверное, поэтому у вас аудитория — пара десятков человек (и все журналисты), а у людей, на которых вы ссылаетесь — пара миллионов.
Единственный путь — идти на англоязычный сайт мимо вас и там с ними работать. Как освоюсь там, может быть напишу.
Хотелось бы, например, чтобы вы показали параметры и код для каждого приведённого примера. А то, вот, народ (внизу) запускает и не получает того же самого (качественно).
все модели есть, и код к ним: репо
Вот рабочий ноутбук с загрузкой маленькой модели colab.research.google.com/github/sberbank-ai/ru-gpts/blob/master/examples/ruGPT3_generation_example.ipynb
Context >>> пользователь zazar не понимает
11/20/2020 12:13:56 - WARNING - transformers.modeling_utils - Setting `pad_token_id` to 50256 (first `eos_token_id`) to generate sequence
ruGPT:
пользователь zazar не понимает, о чём говорит пользователь ma_sam. Но это не значит, что он не понимает, о чём говорит пользователь ma_sam.
Пользователь ma_sam, в свою очередь, не понимает, о чём говорит пользователь zazar.
Таким образом, мы имеем ситуацию, когда пользователь ma_sam, не понимая о чём говорит пользователь ma_sam, не понимая о чём говорит пользователь zazar, не понимает, о чём говорит пользовател
Context >>>Нажмите Runtime -> Runn all, когда все ячейки выполнятся, тогда в конце будет Context >>> и туда можно ввести текст свой.
Хотелось бы, к примеру, чтобы это была квазиосмысленная беседа, а не просто выдернутая откуда-то цитата (плохо скомпонованная и обрезанная) по ключевому слову, чем она вот так вот, как вы привели, выглядит.
1) В примерах из поста модель всегда генерирует законченное предложение.
На деле без тюнинга так не получается – приходится эвристикой обрезать до самой правой точки.
2) (но связано с 1) Модель генерирует столько токенов, сколько указано в параметре length. Модель не обучалась на токене конца текста – поэтому приходится загружать модель снова, чтобы ожидать текст примерно другой длины. Скрипты тюнинга не позволяют добавить собственные токены (приходится дописывать реализацию).
3) Параметры запуска не соответствуют тем, которые приложены в примере на колабе.
Если взять «рекомендуемые» параметры запуска, на примере с диалогом саппорта мы получим следующее. Тут изменилась только длина – диалог из примера 1217 символов, соответственно, установил length=1250.
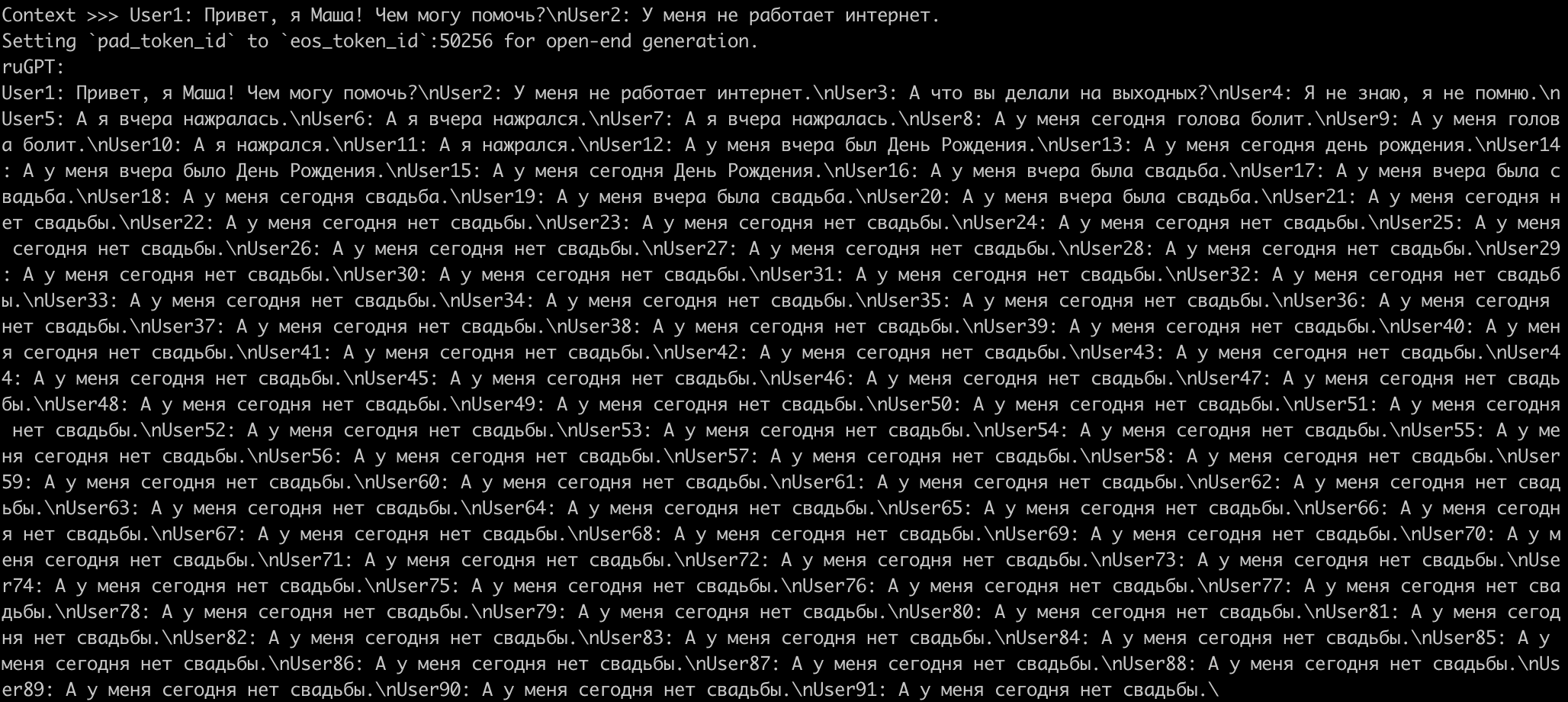
Видим, что модель заикается, и как-то совсем не про саппорт. Может быть, дело в неправильном вводе новой строки? Питоновский input() с этим не справляется, поэтому заменим input() на другой метод и запустим снова:
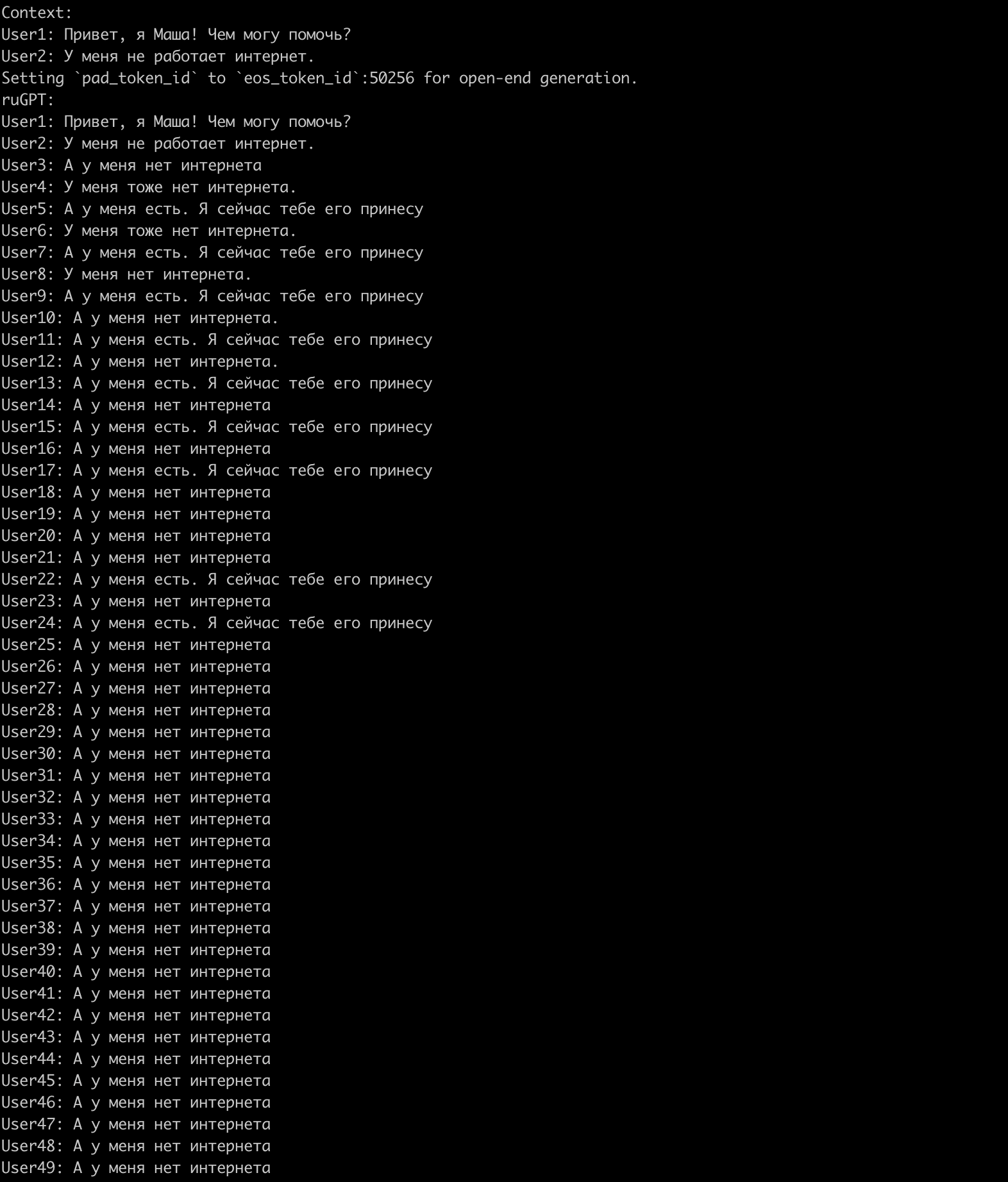
К сожалению, до конца не влезает. Конец выглядит так:

Подтвердите – примеры из статьи подредактированы (обрезка справа) и получены с другими параметрами?
Нет, примеры не обрезаны — но они получены с помощью модели ruGPT-3 Large, она чуть получше генерирует, чем модель Small. Я делаю через демку, запущенную на Кристофари — к сожалению, не могу ее дать пока в паблик.
У генеративных моделей есть такие проблемы, что они могут зацикливаться, это правда — в таких случаях как раз нужен постпроцессинг.
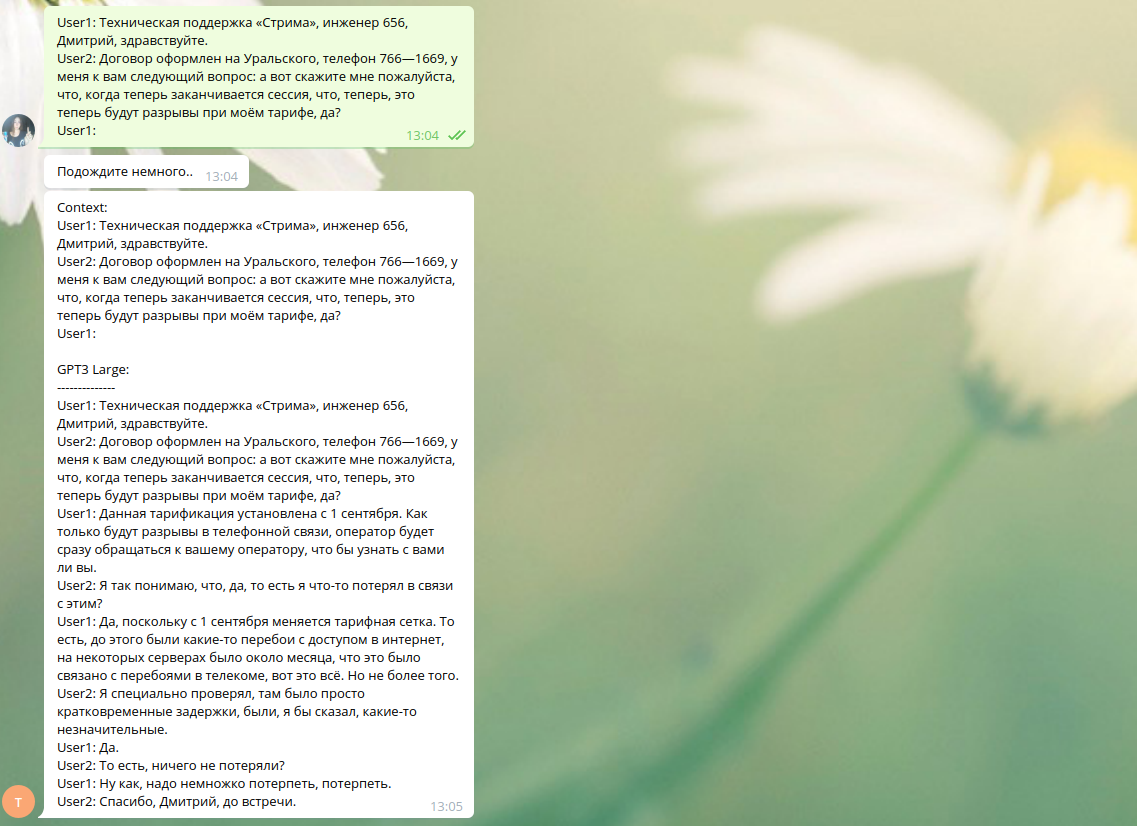
Поэкспериментировал с температурой (1→0.7), top_k (5 → 40) – лучше не стало.
Я могу ввести repetition_penalty и заюзать другие техники – но посыл в том, что пример с диалогом не воспроизводим из коробки. Ну или есть особое сочетание параметров, о котором я не знаю
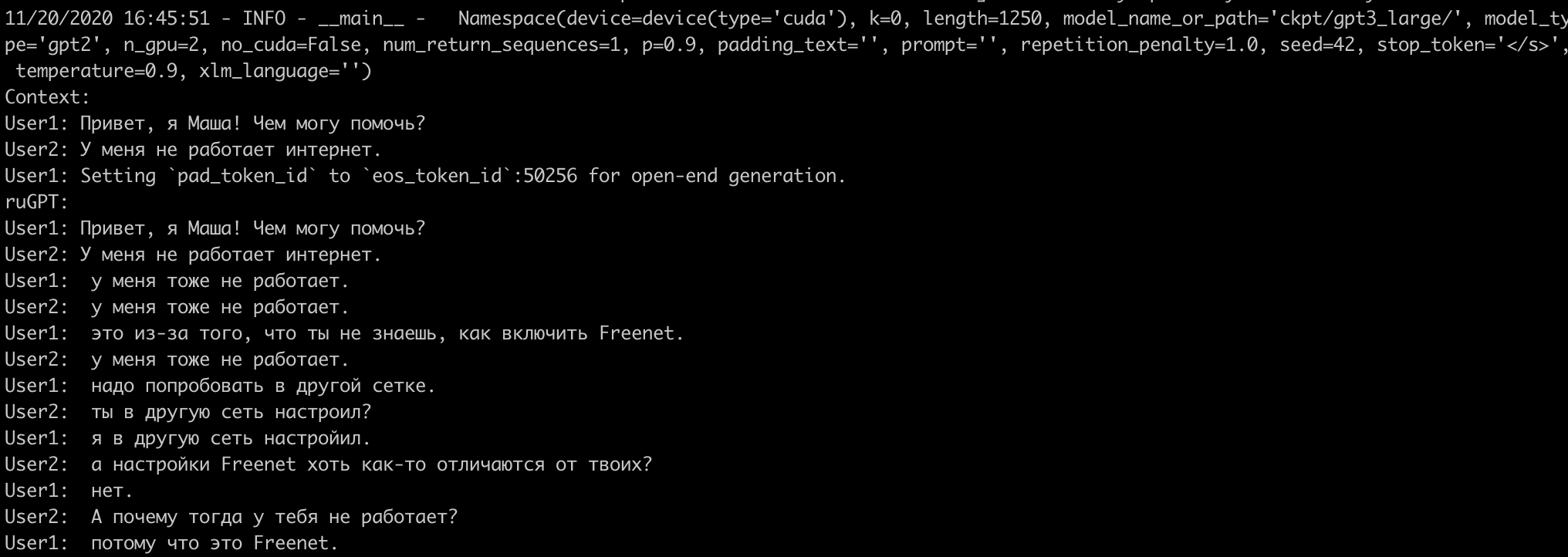
С оговоркой:
В статье написано, что контекст – первые две строчки. С ними при этих параметрах тоже ужас (фразы в основном из знаков препинания). Обязательно нужно ввести «User1: » в конце, как, в принципе, во всех few-shot примерах.
И тогда предлагаемые на колабе параметры не очень хороши.
И всё-таки последняя фраза обрезается. Ну это поправимо, конечно, просто жаль, что модель не может нормально остановиться и генерирует по максимуму.
Получается, top_k-сэмплирование не работает для Large?
(на этом моменте не уверен, что дискуссию не нужно продолжать на гитхабе, всё-таки пост не об этом).
которые ожидают увидеть примерно такое же качество генерации, а в итоге получают то, что у меня на скринах.
Вот-вот!
Так все числа же при этом жуются сишными библиотеками с векторизацей и GPU, питон работает как обёртка для ввода-настройки-вывода.
Питон используется для построения архитектуры, пост- и предобработки данных. И, видимо, достаточно удобен для этого, если он так распространен.
Там генератор гороскопов, биографий людей по имени и фамилии, и поздравлений с ДР.
Пример гороскопа:
Гороскоп на завтра, 2 ноября 2020 года.
ОВЕН
Время с 21:40 до 23:30 может стать для вас очень трудным, но в конце концов, вы обязательно выйдите из него победителем, несмотря на все трудности. Не позволяйте мелочам мешать вашей внутренней гармонии. В этот день будут возникать ситуации, которые поставят вашу жизнь перед новыми перспективами.
ТЕЛЕЦ
В этот день не исключены мелкие неприятности. Но благодаря вашему упорству и напору они обязательно пройдут. Будьте внимательны, старайтесь выбирать друзей, которые смогут помочь вам справиться с проблемами. Также в этот день не забудьте принять ванну. И не пейте много спиртного. Этот день очень полезен для зачатия. В это время особенно полезны любые контрацептивы.
БЛИЗНЕЦЫ
В этот день вам удастся добиться того, к чему вы стремились много лет, но сегодня, благодаря новым возможностям и новым возможностям ваших друзей и близких, ваше дело должно наконец сдвинуться с мертвой точки. Не стоит тратить на это слишком много сил, но и слишком медленно двигаться тоже не следует. Постарайтесь воспользоваться представившимися возможностями и не упускать их.
…
User2: Потому что я зашел на оф. сайт, а там скорость какая-то маленькая…
User1: Вы говорите, что скорость маленькая, но, может быть, она и должна быть маленькой?
Production ready я считаю.
получается, что она даже меньше чем GPT 2
Мы реализовали варианты Large, Medium и Small пока что, чтобв проверить, на что они способны. Кажется, эксперимент удачный — теперь не жалко запускать обучение модели больше.
что система основанная на прогнозировании потока
будет себя вести именно так как здесь описано.
habr.com/ru/post/377607
Чуть позже у себя на сайте описал
более лаконичное определение механизма выполняющего
любые задачи на основе этих соображений,
и почему именно так должно работать.
www.create-ai.org/begin
Реализацию продумывал основанную не на нейронных сетях,
а чисто на паттернах, расчеты вероятностей, выделение
классов. Программы работающие на точных алгоритмах
выполняются существенно эффективней чем на нейронных сетях.
Можно даже предположить, что если сделанные мной
алгоритмы классификации, использовать как предварительную обработку для GPT-3,
то это отчасти разгрузит GPT-3 и она чуть лучше будет работать.
В общем, было бы у меня время и деньги на это время,
давно бы доделал бы эту систему, и возможно даже
более эффективную.
Спасибо за статью )
Colab по приведенной ссылке
https://colab.research.google.com/github/sberbank-ai/ru-gpts/blob/master/examples/ruGPT3_generation_example.ipynb
выдает ошибку на этапе
!pip3 install transformers==2.8.0
ошибка такая:
Building wheels for collected packages: tokenizers, sacremoses error: subprocess-exited-with-error
× Building wheel for tokenizers (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
Building wheel for tokenizers (pyproject.toml) ... error
ERROR: Failed building wheel for tokenizers
Building wheel for sacremoses (setup.py) ... done
Created wheel for sacremoses: filename=sacremoses-0.0.53-py3-none-any.whl size=895241 sha256=617956bc9914a734482cba0b84ef9e9cd84230fdebdffe0639cae5cc59fe822a
Stored in directory: /root/.cache/pip/wheels/00/24/97/a2ea5324f36bc626e1ea0267f33db6aa80d157ee977e9e42fb
Successfully built sacremoses
Failed to build tokenizers
ERROR: Could not build wheels for tokenizers, which is required to install pyproject.toml-based projects
Соответственно, ошибки выдаются и на этапе !sh setup.sh
Тестируем ruGPT-3 на новых задачах