
Вы, наверное, в последнее время часто слышите о новых продуктах Сбера, со многими из них сталкиваетесь как клиенты.
А есть в Сбере крупные и сложные технологические проекты, которые напрямую не видны для клиентов, но от их запуска сильно зависит успех клиентских продуктов. Сложность связана с необходимостью трансформировать приложения, которые каждую секунду обеспечивают непрерывность текущего бизнеса Сбера, а масштаб обусловлен большим количеством функционала, который востребован 68 млн клиентов. В статье я расскажу об одном из таких очень больших изменений — запуске новой платформы для СберБанк Онлайн.

Это вводный текст о новой платформе, поэтому в нем не будем глубоко уходить в практические детали, а постараемся дать общее представление.
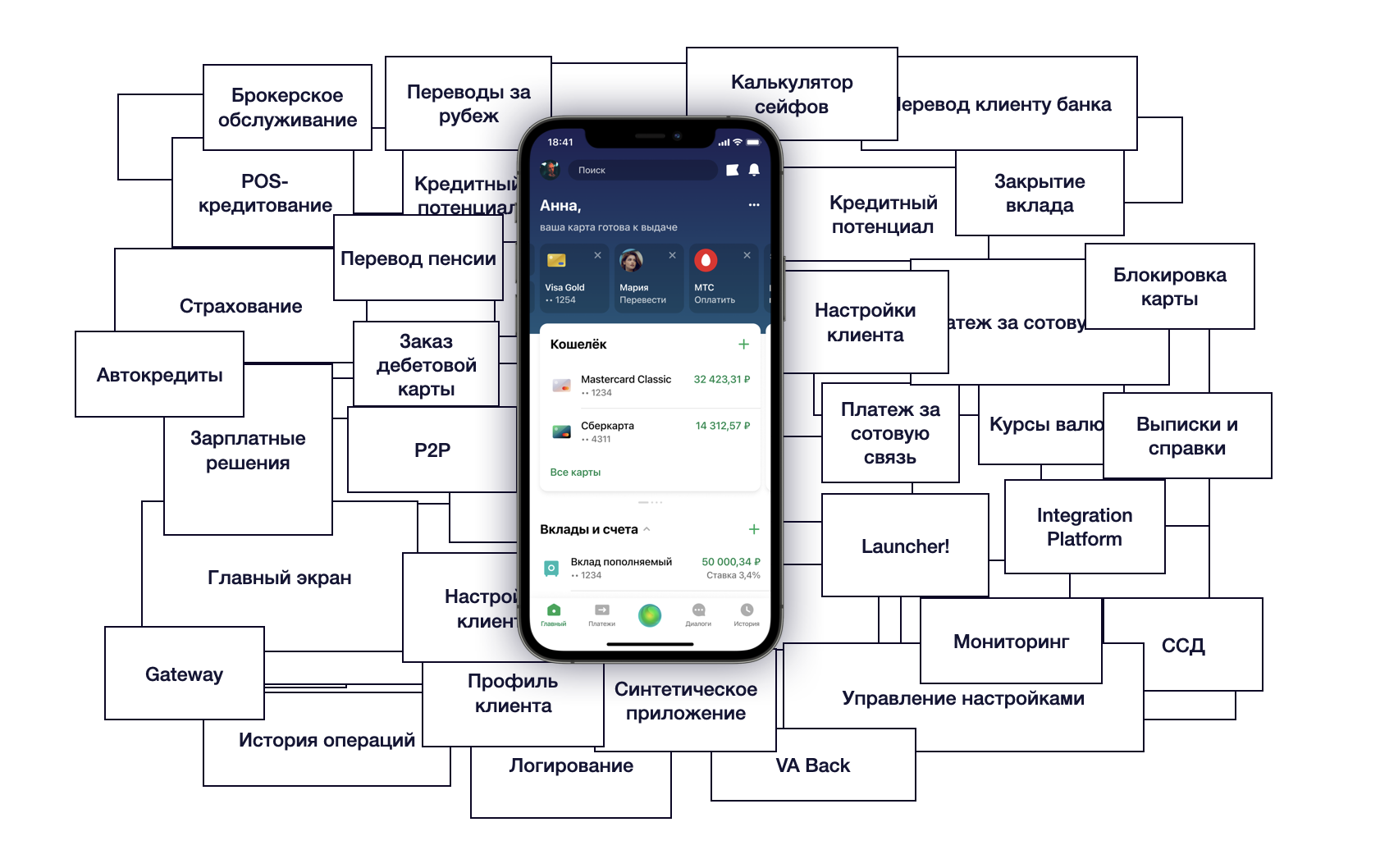
В какой-то момент, когда Сбер ещё был Сбербанком, а технологическая трансформация только начиналась, появилась идея, что флагманское приложение СберБанк Онлайн может разрабатывать не одно подразделение, а весь банк, а впоследствии и вся Группа Сбер. А у команды, которая раньше разрабатывала это приложение самостоятельно, появилась задача создать платформу, которая построит параллельную и независимую разработку в СберБанк Онлайн.
Уточним вводные, с которыми предстояло работать:
продуктовых команд будет много (несколько сотен — в ближайшей перспективе и тысячи — в перспективе). Размер одной команды — около 10 человек, возможность разрабатывать функционал end-to-end;
T2M по бизнес-функционалу — 2‒3 недели. Разумеется, срочные фиксы должны выходить на клиентов в течение часов;
приложения должны иметь лучший клиентский опыт и высокие оценки в App Store и Google Play;
текущий сервер-сайд и фронтальные приложения — монолиты с многолетней историей;
менять колёса надо на ускоряющемся ходу. Пользователей уже перевалило за 45 млн, нагрузка каждый день растёт. Речь и о количестве TPS, и о количестве новых фич, которые нужны бизнесу;
большинство операций — банковские. Это к тому, что платёжные транзакции, в отличие от, например, развлекательного контента, нельзя терять ни в коем случае. А если мы не отразим корректный остаток по картам в момент входа, сразу положим контакт-центры высоким количеством обращений клиентов;
надёжность и безопасность — высшие приоритеты.
Теперь пару слов о том, что мы называем сервер-сайдом СберБанк Онлайн. Как правило, сервер-сайд в крупной организации можно условно разделить на два основных слоя — мидл, который обеспечивает надёжность, доступность и хороший UX клиентских приложений, и бэкенд, который хранит и обрабатывает мастер-данные по разным системам (например, карточный процессинг, вклады или «Кредитная фабрика»).

Когда мы говорим «сервер-сайд приложений СберБанк Онлайн», имеем в виду именно мидл-слой, который отвечает за следующий функционал:
бизнес-приложения (прикладные), которые реализуют конечный функционал для пользователей приложений;
аутентификацию пользователя в приложении;
наполнение распределённого кэша в памяти серверов приложений при установке клиентской сессии, который обеспечивает доступность, низкое время отклика и надёжность при большом количестве запросов от приложений;
общие страницы приложения (главный экран, история операций и т. д.);
логирование, мониторинг, авторизацию и другой функционал для надёжности и безопасности.
Список на этом не заканчивается, но должен дать общее представление. Явно ещё раз подчеркну, что бэкенд не входил в объём поставленной задачи.
Зачем новая платформа
Недавно СберБанк Онлайн отметил свой десятый день рождения, и на протяжении этой истории в качестве мидл-слоя служил монолит. Надо отдать должное, он с достоинством пережил активную стадию роста пользовательской и функциональной нагрузки. Но всё время рос и по большей части представлял собой сильно связанный код, где прикладной функционал был прочно переплетён с тем, который обеспечивал надёжность и доступность. Поэтому невозможно было продолжать увеличивать интенсивность разработки при одновременном сокращении T2M. Очевидное решение — уменьшить связанность кода, чтобы проходить все этапы производства без сильного влияния одного функционала на другой.
Достичь низкой связанности можно было двумя способами. Первый — глубокий рефакторинг текущего Legacy с целью разделить прикладной и платформенный функционалы на отдельные компоненты, которые взаимодействуют по зафиксированным контрактам. И второй — создание платформы с нуля с последующей миграцией прикладного функционала и пользователей. По совокупности причин выбрали второй вариант.
Ключевые моменты
Итак, мы примерно определились, зачем делаем новую платформу, дальше самое главное — добиться результата. А опыт подсказывал, что добиться его на таком большом масштабе непросто. Поэтому заранее спланировали ключевые моменты, на которых в первую очередь надо держать фокус.
Разделили сервисы на две группы — платформенные и прикладные
Как бы мы ни старались делать микросервисы максимально независимыми, всегда будут те, от которых зависят все. Появляются общие сервисы из-за необходимости централизованного управления платформой. Например, логирование у нас общее, потому что логи зачастую собираются в результате проблемы клиента, а не отдельного сервиса
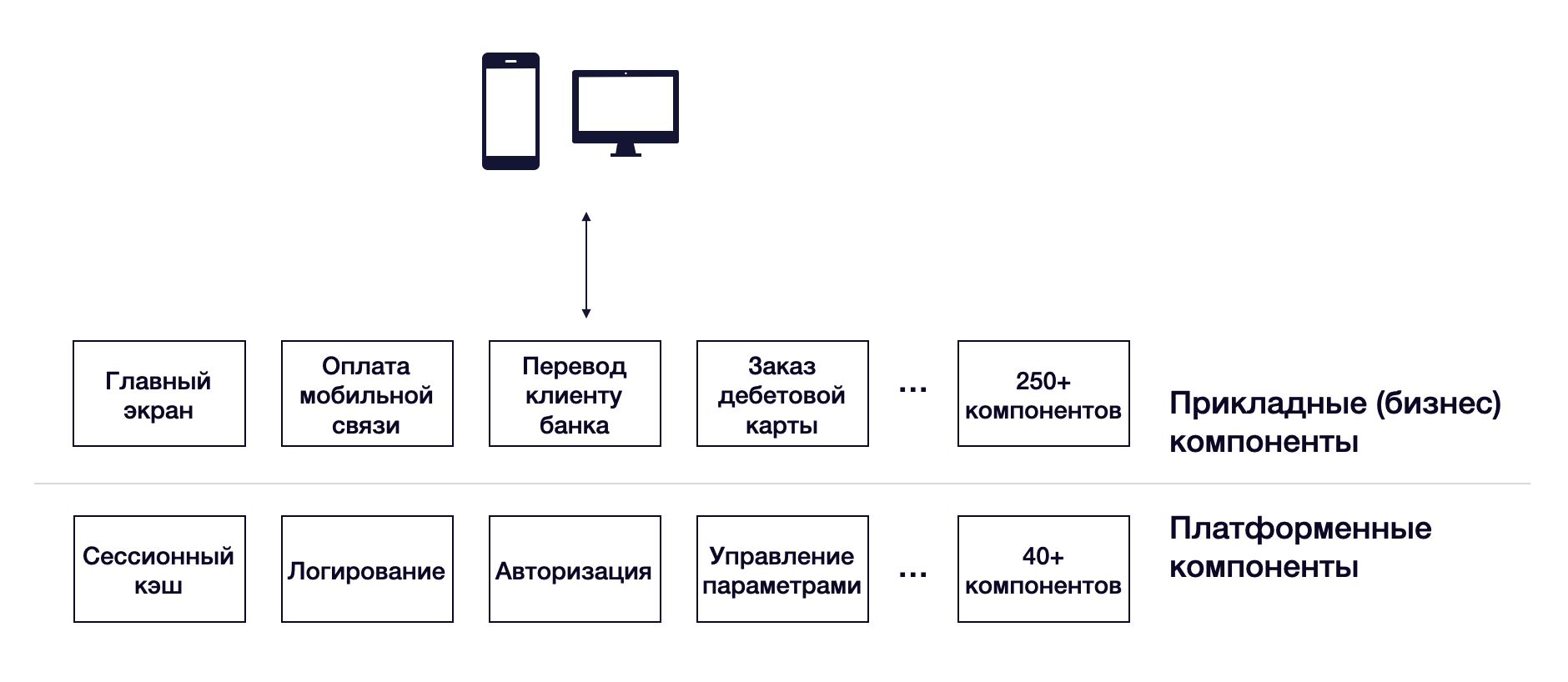
Для таких сервисов невозможно обеспечить T2M в пару недель, потому что все пользуются логированием, и, если мы не протестируем потребителей во время нового релиза, есть риск потерять в качестве.
Поэтому платформенные и прикладные сервисы мы условно разделили по количеству зависимостей. Если от сервиса зависит множество других, то мы помещаем его в платформенный слой. Если от сервиса не зависят другие сервисы, то мы помещаем его в прикладной. При этом стараемся минимизировать количество зависимостей, а, следовательно, и количество платформенных сервисов.
Почему мы акцентируем внимание на количестве связей? Если грубо, то каждая зависимость — это дополнительный тестовый кейс или несколько кейсов. Кроме того, при росте количества связей мы получаем высокую спутанность и, как следствие, циклические зависимости. И неутешительные сроки по исправлению дефектов. Всё это напрямую влияет на T2M.
Таким образом, у нас появляются горизонтальные связи в рамках одного слоя и вертикальные — между слоями. В платформенном слое мы допускаем горизонтальные зависимости, в прикладном — стараемся их избегать (исключения возможны, но именно исключения, и мы следим за этим).
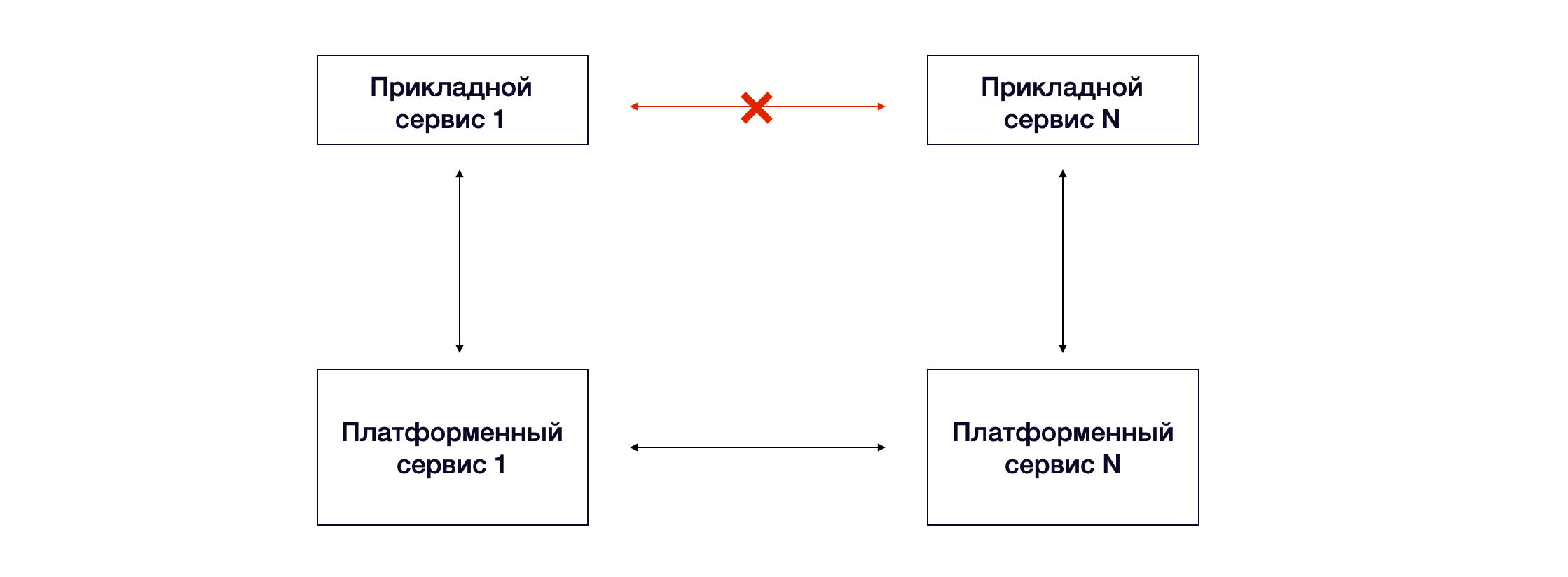
В нашем случае получилось порядка 40 платформенных и около 10 пилотных бизнес-сервисов на старте. На данный момент количество платформенных сервисов почти не изменилось, а число прикладных проектов превысило 250.
Создали отдельные релизные процессы

Платформенные и прикладные сервисы отвечают разным требованиям и свойствам. Платформенные — максимальная стабильность и отказоустойчивость. Прикладные — лучший клиентский опыт, минимальное влияние на другие сервисы и максимальная скорость разработки.
Если мы начнём тестирование и платформы, и прикладных сервисов на одном общем стенде, то длительный процесс отладки платформенного сервиса приведёт к такому же времени отладки прикладных сервисов + времени на их собственное тестирование. Поэтому мы выделили отдельные тестовые контуры для платформы и прикладов.
Так как основных слоя два, то и контуров достаточно двух. На платформенном контуре производится сборка и отладка платформенного релиза. В зависимости от зрелости инструментов DevOps и процессов производства, на контуре может быть разное количество стендов. Но главное, чтобы в итоге мы получили стабильную версию платформы.
После этого её можно передавать на контур с бизнес-потребителями, где они производят тестирование в своём быстром релизном цикле.
Ввели контроль платформенного API
Понятная вещь, о которой все говорят, но которая не всегда случается. Обязательные правила, которые мы применили:
на старте проекта попросили всех владельцев платформенных сервисов опубликовать свои контракты как можно раньше, ещё до того, как началась разработка. После чего они не должны были меняться. Здесь многое упирается в профессионализм людей, которые проектируют API. Мы доверили это самым опытным сотрудникам внутри команд, отвечающих за разработку сервисов;
создали инструмент, который осуществляет контроль этого API. У нас для этого есть отдельный компонент — синтетическое приложение. О нём чуть позже;
сделали процесс согласования изменения API максимально дорогим:
согласование изменений архитектурой платформы;
согласование со всеми потребителями API;
согласование с руководителями. Инициатор изменений должен был получить ОК от двух ключевых людей — владельца СберБанк Онлайн и руководителя программы внедрения новой платформы. Да, им лично приходилось объяснять, почему API всё-таки нужно поменять и как так случилось, что делать это нужно после того, как началась разработка. И да, такие кейсы были, но штучные. По сравнению с потоком изменений, которые были до введения контроля, — ничтожное количество.
Важно отметить, что мы строго контролируем API в рамках минорных релизов платформы и не строго (изменения возможны, но согласуются с архитектурой) — в рамках мажорных релизов.
Следим за удобством разработки на платформе
Случается так, что платформу сделали, а пользоваться ей неудобно. Вроде как клиент платформы — внутренний, поэтому может потерпеть. Это большая ошибка, особенно когда потребителей платформы много. И мы создали независимый орган, который следит за клиентским опытом потребителей платформы и отстаивает их интересы — «Синтетическое приложение».
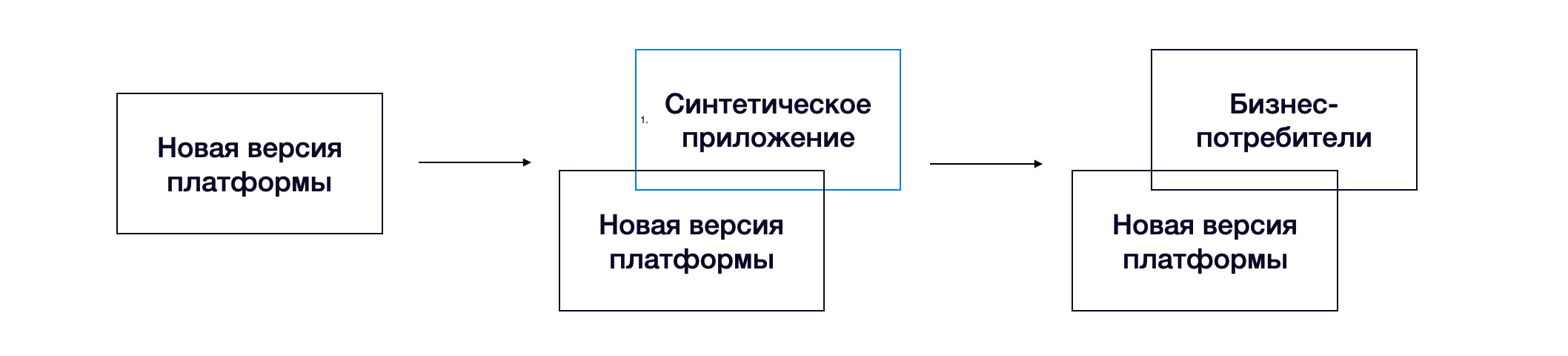
Эта команда играет ключевую роль — собирает отдельные сервисы платформы в единый продукт. У ребят много задач:
выпуск POM/BOM. Большая часть платформенного API предоставляется в виде клиентских библиотек. Ребята из «Синтетического приложения» собирают их вместе, разрешают конфликты зависимостей и публикуют для потребителей POM- и BOM-файлы;
контроль обратной совместимости API. Кроме проверки на конфликт зависимостей, все библиотеки проходят тестирование на бинарную совместимость с предыдущими версиями;
тестирование платформы в качестве бизнес-потребителя. После того как каждый компонент платформы прошёл своё компонентное тестирование, важно убедиться, что собранная конфигурация платформы стабильна. Сделать это можно с помощью бизнес-потребителя. Но тогда бизнес-проект будет нести на себе все риски отладки дефектов в платформе. Тем более один бизнес-проект может не выявить проблем, которые специфичны другому. Поэтому мы делаем это с помощью специального приложения, которое похоже на реальное бизнес-приложение, но содержит максимально возможное количество кейсов использования платформенных сервисов и покрыто кучей тестов. Таким образом, бизнес-потребители приходят уже на стабильную версию платформы, а риски пересборок из-за дефектов на платформе значительно меньше;
контроль за документацией. Идеальному сервису документация не нужна. Но сервисы неидеальны. Кроме того, как бы вы ни старались сделать платформенные компоненты универсальными, требования от потребителей будут отличаться. Компенсировать эти отличия позволяют возможности конфигурирования, которые тоже надо документировать и описывать. Опять же, если платформенных сервисов много и в промышленной эксплуатации уже несколько версий платформы, то даже навигация по документации становится непростой задачей;
СSI и обратная связь. Продукт не может быть хорошим, если нет механизма обратной связи от клиентов. Мы проводим регулярную оценку CSI и сессии обратной связи с потребителями платформы. После этого направляем фидбэк в команды разработки платформенных сервисов и контролируем, что «боли» клиентов не останутся без внимания;
сообщество разработчиков. Разработка на платформе становится легче и результативнее, если есть инструменты прямого взаимодействия с её разработчиками и можно пообщаться с коллегами, которые раньше вас пришли на платформу. У нас основным инструментом такого взаимодействия выступает сообщество разработчиков. У них есть чаты, где они могут задать любые вопросы по разработке на платформе, митапы и воркшопы, на которых можно получить новые и обменяться своими знаниями. Основная польза от этой истории для прикладного разработчика — помощь сообщества. Главная польза для ребят из платформы — прямое взаимодействие со своими потребителями.
Архитектурный контроль
Для всех прикладных сервисов мы ввели необходимость прохождения ревью архитектуры. Основная задача этого ревью — исключить влияние прикладного компонента на другие и на платформу в целом. Ошибка в проектировании прикладного сервиса может привести к тому, что повышенная нагрузка на один из платформенных сервисов вызовет недоступность всей платформы, а, следовательно, и всего СберБанк Онлайн. Кроме того, на архитектурном ревью мы следим за горизонтальными вызовами между прикладными сервисами.
Где мы сейчас и что делаем дальше
Внедрение платформы случилось порядка двух лет назад, и сейчас уверенно можно говорить, что оно успешно решило основные вызовы, которые перед ним ставились. В настоящее время у нас уже более 250 проектов, количество которых постоянно растёт.

Мы существенно сократили T2M для прикладных проектов относительно Legacy, где релизный процесс предполагал включение в релиз за шесть месяцев до полной раскатки. Точные цифры назвать сложно, так как они зависят от доработок смежных систем, но мы уменьшили время от подачи заявки в релиз до прома до трёх недель.
Тем не менее мы ещё в начале пути и ещё много задач, которые предстоит решить:
миграция профиля и сессии. Мы обеспечили запуск проектов, но Legacy продолжает оставаться источником основных данных по профилю клиента. В отличие от запуска атомарных клиентских сценариев, это то, что нельзя разработать рядом и потом плавно переключиться. Приходится много дорабатывать одновременно: и Legacy, и новое приложение. Всё это — под огромной пользовательской нагрузкой. Весьма сложная история, достойная отдельной статьи;
нормальный технологический стек и удобство разработки. Если вы обратили внимание, в цели проекта не входило внедрение нового стека. Даже больше: мы сознательно от него отказались. Основной аргумент — не увеличивать сложность на и так сложном проекте. Если смена стека с точки зрения разработки несёт приемлемые риски, то с точки зрения эксплуатации и внедрения риски очень высокие. Так как надёжность, доступность и безопасность — самые важные критерии, которым мы следуем при любой разработке в СберБанк Онлайн, то и требования к инфраструктуре и эксплуатации очень высокие. Поэтому смена стека в run-time требует большой аккуратности, что неизбежно сказалось бы на сроках.
Так что наши разработчики счастливо программируют на Java 8. А деплоится это всё на вендорском JDK. Многие, кто слышит об этом на наших собеседованиях, расплываются в улыбке от счастья. Или не от счастья, мы точно не знаем. Если серьёзно, то это надо менять, и одна из текущих задач на платформе сейчас — смена стека. А для прикладных команд мы обсуждаем возможность разработки на Kotlin.
Кроме того, на платформе много специфики этой платформы. Это тоже нехорошо, так как создаёт высокий порог вхождения для новых разработчиков и способствует изоляции от внешнего мира тех, кто давно на проекте. У нас есть трек активностей, направленных на то, чтобы изменить это в лучшую сторону.
Спасибо за внимание, жду вопросы в комментариях.
