
2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети CogView позволяет решать ту же задачу — получать изображения из текстов. Но что в России? Разобрать, понять, обучить — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды Sber AI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов — Василия Кандинского и Казимира Малевича:
ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
ruDALL-E Malevich (XL) c 1.3 миллиардами параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
ruDALL-E Malevich (XL) [GitHub, HuggingFace, Kaggle]
Sber VQ-GAN [GitHub, HuggingFace]
ruCLIP Small [GitHub, HuggingFace]
Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Потестировать ruDALL-E Malevich (XL) или посмотреть на результаты генерации можно здесь:
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small уже доступны в DataHub. Модели ruCLIP Large и Super Resolution (Real ESRGAN) скоро будут доступны там же.
Обучение нейросети ruDALL-E на кластере Christofari стало самой большой вычислительной задачей в России:
Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 — всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло 24 256 GPU-дней.
Разберём возможности наших генеративных моделей.
")
Почему Big Tech изучает генерацию изображений
Долгосрочная цель нового направления — создание «мультимодальных» нейронных сетей, которые выучивают концепции в нескольких модальностях, в первую очередь в текстовой и визуальной областях, чтобы «лучше понимать мир».
Генерация изображений может показаться достаточно избыточной задачей в век больших данных и доступа к поисковикам. Однако, она решает две важных потребности, которые пока не может решить информационный поиск:
Возможность точно описать желаемое — и получить персонализированное изображение, которое раньше не существовало.
В любой момент создавать необходимое количество licence-free иллюстраций в неограниченном объеме.
Первые очевидные применения генерации изображений:
Фото-иллюстрации для статей, копирайтинга, рекламы. Можно автоматически (а значит — быстрее и дешевле) создавать иллюстрации к статьям, генерировать концепты для рекламы по описанию:



Иллюстрации, свободные от лицензии фотостоков, тоже можно генерировать бесконечно:

«Векторная иллюстрация с розовыми цветами»

Визуализации дизайна интерьеров — можно проверять свои идеи для ремонта, играть с цветовыми решениями, формами и светом:

«Шикарная гостиная с зелеными креслами» 
«Современное кресло фиолетового цвета» Visual Art — источник визуальных концепций, соединений различных признаков и абстракций:

«Темная энергия»









Более подробно о самой модели и процессе обучения
В основе архитектуры DALL-E — так называемый трансформер. В общем случае трансформер состоит из энкодера и декодера. Общая идея состоит в том, чтобы вычислить embedding по входным данным с помощью энкодера, а затем с учетом известного выхода правильным образом декодировать этот embedding.

В трансформере энкодер и декодер состоят из ряда идентичных блоков.

Основу архитектуры трансформера составляет механизм self-attention. Он позволяет модели понять, какие фрагменты входных данных важны и насколько важен каждый фрагмент входных данных для других фрагментов. Как и LSTM-модели, трансформер позволяет естественным образом моделировать связи «вдолгую». Однако, в отличие от LSTM-моделей, он подходит для распараллеливания и, следовательно, эффективных реализаций.
Первым шагом при вычислении self-attention является создание трёх векторов для каждого входного вектора энкодера (для каждого элемента входной последовательности). Если быть более точным, то для каждого элемента создаются векторы Query, Key и Value. Эти векторы получаются путем перемножения embedding’а и трех матриц, которые мы получаем в процессе обучения. Далее мы используем полученные векторы для формирования self-attention-представления каждого embedding’а, что дает возможность оценить возможные связи в элементах входных данных, а также определить степень «полезности» каждого элемента.
Трансформер также характеризует наличие словаря. Каждый элемент словаря — это токен. В зависимости от модели размер словаря может меняться. Таким образом, входные данные сначала превращаются в последовательность токенов, которая далее конвертируется в embedding с помощью энкодера. Для текста используется свой токенизатор, для изображения сначала вычисляются low-level-фичи, а затем в скользящем окне вычисляются визуальные токены. Применение механизма self-attention позволяет извлечь контекст из входной последовательности токенов в ходе обучения. Следует отметить, что для обучения трансформера требуются большие объёмы (желательно «чистых») данных, о которых мы расскажем ниже.
Как устроен ruDALL-E
Глобальная идея состоит в том, чтобы обучить трансформер (а вернее только его декодер) авторегрессивно моделировать токены текста и изображения как единый поток данных. Однако использование пикселей непосредственно в качестве признаков изображений потребует чрезмерного количества памяти, особенно для изображений с высоким разрешением. Чтобы не учить только краткосрочные зависимости между пикселями и текстами, а делать это более высокоуровнево, обучение модели проходит в 2 этапа:
Предварительно сжатые изображения с разрешением 256х256 поступают на вход автоэнкодера (мы обучили свой SBER VQ-GAN, улучшив метрики для генерации по некоторым доменам, и об этом как раз рассказывали тут, причем также поделились кодом), который учится сжимать изображение в матрицу токенов 32х32. Фактор сжатия 8 позволяет восстанавливать изображение с небольшой потерей качества: см. котика ниже.
Трансформер учится сопоставлять токены текста (у ruDALL-E их 128) и 32×32=1024 токена изображения (токены конкатенируются построчно в последовательность). Для токенизации текстов использовался токенизатор YTTM.

Исходный и восстановленный котик

Важные аспекты обучения
На данный момент в открытом доступе нет кода модели DALL-E от OpenAI. Публикация описывает её общими словами, но обходит вниманием некоторые важные нюансы реализации. Мы взяли наш собственный код для обучения ruGPT-моделей и, опираясь на оригинальную статью, а также попытки воспроизведения кода DALL-E мировым ds-сообществом, написали свой код DALL-E-модели. Он включает такие детали, как позиционное кодирование блоков картинки, свёрточные и координатные маски Attention-слоёв, общее представление эмбеддингов текста и картинок, взвешенные лоссы для текстов и изображений, dropout-токенизатор.
Из-за огромных вычислительных требований эффективно обучать модель можно только в режиме точности fp16. Это в 5-7 раз быстрее, чем обучение в классическом fp32. Кроме того, модель с таким подходом занимает меньше места. Но ограничение точности представления чисел повлекло за собой множество сложностей для такой глубокой архитектуры:
a) иногда встречающиеся очень большие значения внутри сети приводят к вырождению лосса в Nan и прекращению обучения;
b) при малых значениях learning rate, помогающих избежать проблемы а), сеть перестает улучшаться и расходится из-за большого числа нулей в градиентах.
Для решения этих проблем мы имплементировали несколько идей из работы китайского университета Цинхуа CogView, а также провели свои исследования стабильности, с помощью которых нашли ещё несколько архитектурных идей, помогающих стабилизировать обучение. Так как делать это приходилось прямо в процессе обучения модели, путь тренировки вышел долгим и тернистым.
Для распределенного обучения на нескольких DGX мы используем DeepSpeed, как и в случае с ruGPT-3.
Сбор данных и их фильтрация: безусловно, когда мы говорим об архитектуре, нововведениях и других технических тонкостях, нельзя не упомянуть такой важный аспект как данные. Как известно, для обучения трансформеров их должно быть много, причем «чистых». Под «чистотой» мы понимали в первую очередь хорошие описания, которые потом нам придётся переводить на русский язык, и изображения с отношением сторон не хуже 1:2 или 2:1, чтобы при кропах не потерять содержательный контент изображений.
Первым делом мы взялись за те данные, которые использовали OpenAI (в статье указаны 250 млн. пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.
После сбора и фильтрации данных от слишком коротких описаний, маленьких изображений и изображений с непригодным отношением сторон, а также изображений, слабо соответствующих описаниям (мы использовали для этого англоязычную модель CLIP), перевода всех английских описаний на русский язык, был сформирован широкий спектр данных для обучения — около 120 млн. пар изображение-описание.
Кривая обучения ruDALL-E Kandinsky (XXL): как видно, обучение несколько раз приходилось возобновлять после ошибок и уходов в Nan.
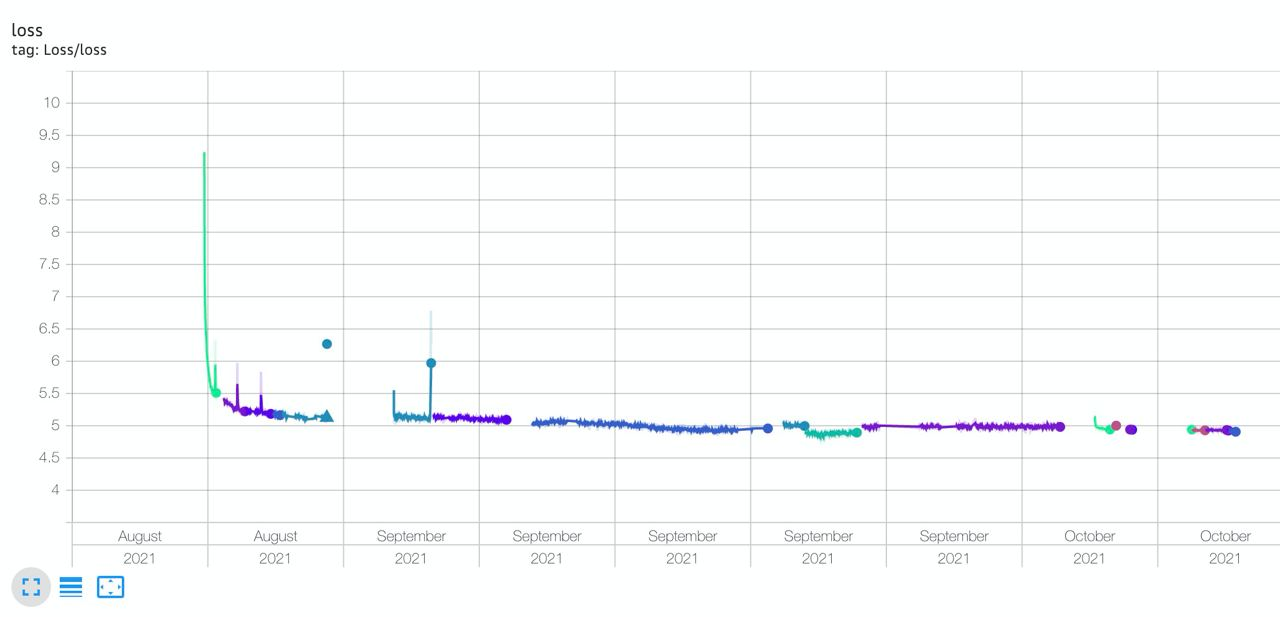
Обучение модели ruDALL-E Kandinsky (XXL) происходило в 2 фазы: 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100.
Подробная информация об обучении ruDALL-E Malevich (XL):

Динамика loss на train-выборке 
Динамика loss на valid-выборке 
Динамика learning rate Обучение модели ruDALL-E Malevich (XL) происходило в 3 фазы: 8 дней на 128 GPU TESLA V100, а затем еще 6.5 и 8.5 дней на 192 GPU TESLA V100, но с немного отличающимися обучающими выборками.
Хочется отдельно упомянуть сложность выбора оптимальных режимов генерации для разных объектов и доменов. В ходе исследования генерации объектов мы начали с доказавших свою полезность в NLP-задачах подходов Nucleus Sampling и Top-K sampling, которые ограничивают пространство токенов, доступных для генерации. Эта тема хорошо исследована в применении к задачам создания текстов, но для изображений общепринятые настройки генерации оказались не самыми удачными. Серия экспериментов помогла нам определить приемлемые диапазоны параметров, но также указала на то, что для разных типов желаемых объектов эти диапазоны могут очень существенно отличаться. И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.




Вот не совсем удачные генерации объектов на примере котиков, сгенерированные по запросу «Котик с красной лентой»:

А вот «Автомобиль на дороге среди красивых гор». Автомобиль слева въехал в какую-то трубу, а справа — странноватой формы.

Пайплайн генерации изображений
Сейчас генерация изображений представляет из себя пайплайн из 3 частей: генерация при помощи ruDALL-E — ранжирование результатов с помощью ruCLIP — и увеличение качества и разрешения картинок с помощью SuperResolution.
При этом на этапе генерации и ранжирования можно менять различные параметры, влияющие на количество генерируемых примеров, их отбор и абстрактность.

В Colab можно запускать инференс модели ruDALL-E Malevich (XL) с полным пайплайном: генерацией изображений, их автоматическим ранжированием и увеличением.
Рассмотрим его на примере с оленями выше.
Шаг 1. Сначала делаем импорт необходимых библиотек
git clone https://github.com/sberbank-ai/ru-dalle
pip install -r ru-dalle/requirements.txt > /dev/null
from rudalle import get_rudalle_model, get_tokenizer, get_vae, get_realesrgan, get_ruclip
from rudalle.pipelines import generate_images, show, super_resolution, cherry_pick_by_clip
from rudalle.utils import seed_everything
seed_everything(42)
device = 'cuda'
Шаг 2. Теперь генерируем необходимое количество изображений по тексту
text = 'озеро в горах, а рядом красивый олень пьет воду'
tokenizer = get_tokenizer()
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
vae = get_vae().to(device)
pil_images, _ = generate_images(text, tokenizer, dalle, vae, top_k=1024, top_p=0.99, images_num=24)
show(pil_images, 24)
Результат:

Шаг 3. Далее производим автоматическое ранжирование изображений и выбор лучших изображений
ruclip, ruclip_processor = get_ruclip('ruclip-vit-base-patch32-v5')
ruclip = ruclip.to(device)
top_images, _ = cherry_pick_by_clip(pil_images, text, ruclip, ruclip_processor, device=device, count=24)
show(top_images, 6)
")
Можно заметить, что один из оленей получился достаточно «улиточным». На этапе генерации можно делать перебор гиперпараметров для получения наиболее удачного результата именно под ваш домен. Опытным путем мы установили, что параметры top_p и top_k контролируют степень абстрактности изображения. Их общие рекомендуемые значения:
top_k=2048, top_p=0.995
top_k=1536, top_p=0.99
top_k=1024, top_p=0.99
Шаг 4. Делаем Super Resolution
realesrgan = get_realesrgan('x4', device=device)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 6)

Для запуска пайплайна с моделью ruDALL-E Kandinsky (XXL) или Malevich (XL) можно также использовать каталог моделей DataHub (ML Space Christofari).
Будущее мультимодальных моделей
Мультимодальные исследования становятся всё более популярны для самых разных задач: прежде всего, это задачи на стыке CV и NLP (о первой такой модели для русского языка, ruCLIP, мы рассказали ранее), а также на стыке NLP и Code. Хотя последнее время становятся популярными архитектуры, которые умеют обрабатывать много модальностей одновременно, например, AudioCLIP. Представляет отдельный интерес Foundation Model, которая совсем недавно была анонсирована исследователями из Стэнфордского университета.
И Сбер не остается в стороне - так в соревновании Fusion Brain Challenge конференции AI Journey предлагается создать единую архитектуру, с помощью которой можно решить 4 задачи:
С2С — перевод с Java на Python;
HTR — распознавание рукописного текста на фотографиях;
Zero-shot Object Detection — детекция на изображениях объектов, заданных на естественном языке;
VQA — ответы на вопросы по картинкам.
По условиям соревнования (которое продлится до 5 ноября) на общие веса нейросети должно приходиться как минимум 25% параметров! Совместное использование весов для разных задач делает модели более экономичными в сравнении с их мономодальными аналогами. Организаторами также был предоставлен бейзлайн решения, который можно найти на официальном GitHub соревнования.
И пока команды соревнуются за первые места, а компании наращивают вычислительные мощности для обучения закрытых моделей, нашим интересом остается open source и расширение сообщества. Будем рады вашим прототипам, неожиданным находкам, тестам и предложениям по улучшению моделей!
Самые важные ссылки:
Коллектив авторов: @rybolos, @shonenkov, @ollmer, @kuznetsoff87, @alexander-shustanov, @oulenspeigel, @mboyarkin, @achertok, @da0c, @boomb0om
