
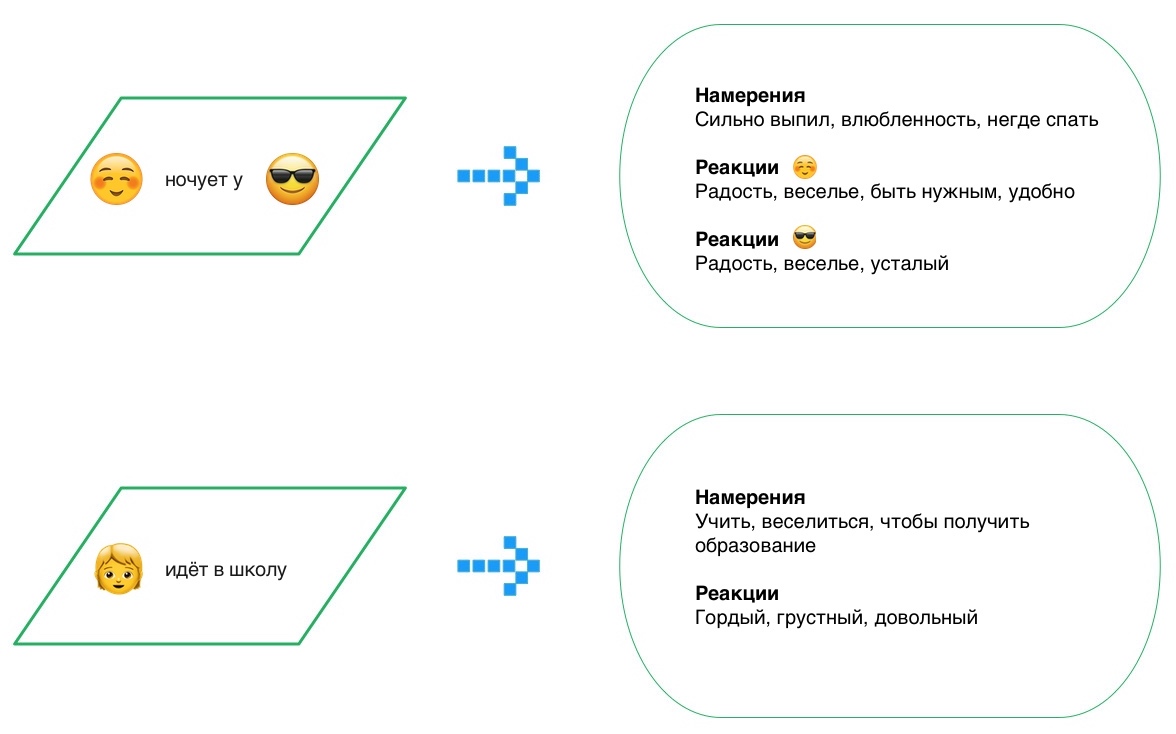
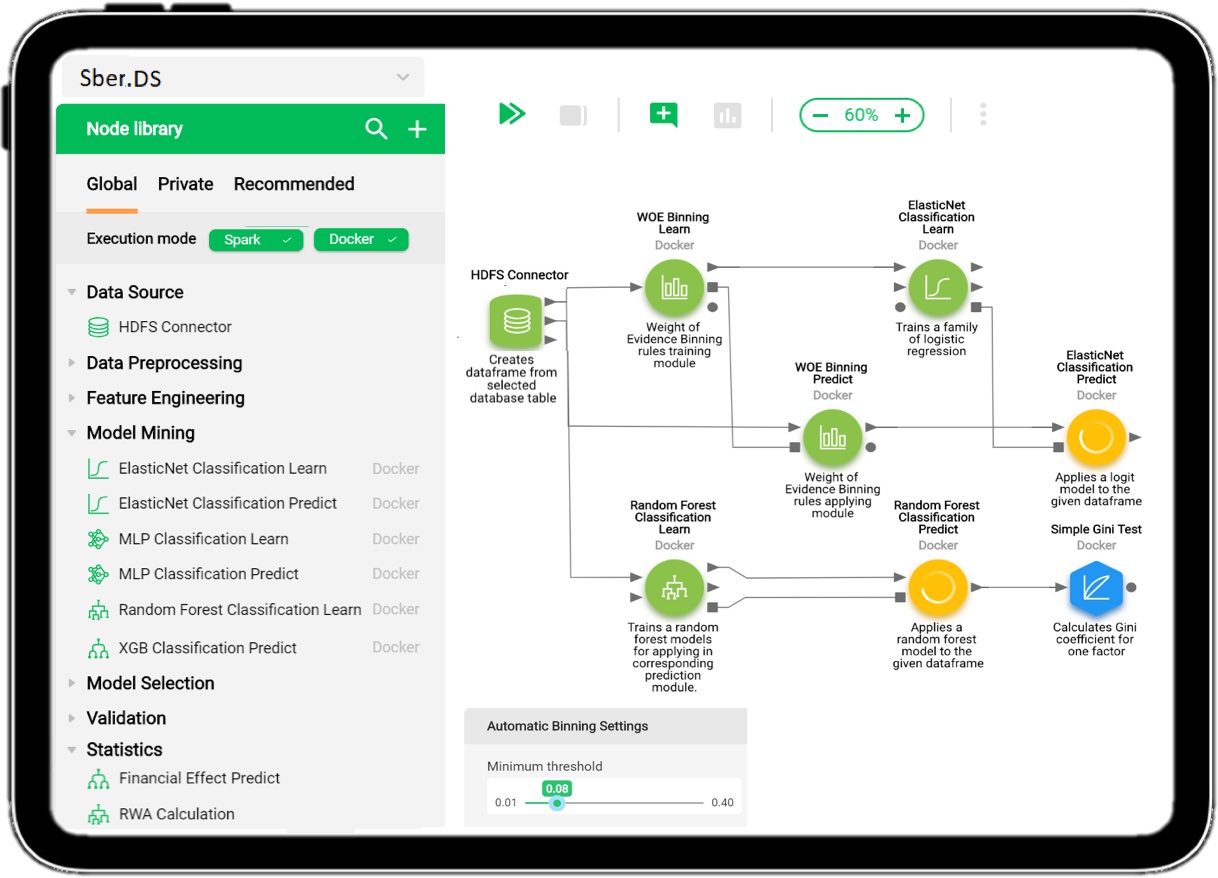
В Сбере есть несколько практик Oracle, которые могут оказаться вам полезны. Думаю, часть вам знакома, но мы используем для загрузки не только ETL-средства, но и хранимые процедуры Oracle. На Oracle PL/SQL реализованы наиболее сложные алгоритмы загрузки данных в хранилища, где требуется «прочувствовать каждый байт».
- Автоматическое журналирование компиляций
- Как быть, если хочется сделать вьюшку с параметрами
- Использование динамической статистики в запросах
- Как сохранить план запроса при вставке данных через database link
- Запуск процедур в параллельных сессиях
- Протягивание остатков
- Объединение нескольких историй в одну
- Нормалайзер
- Визуализация в формате SVG
- Приложение поиска по метаданным Oracle









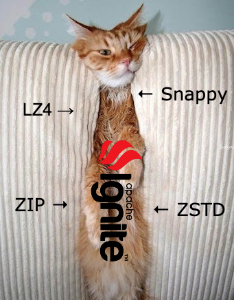 При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.


{kind=link}