
Меня зовут Саша, в SberDevices я занимаюсь системой распознавания речи и тем, как данные могут сделать её лучше. В этой статье я расскажу о новом речевом датасете Golos, который состоит из аудиофайлов и соответствующих транскрипций. Общая длительность записей составляет примерно 1240 часов, частота дискретизации – 16кГц. На текущий момент это самый большой корпус аудиозаписей на русском языке, размеченный вручную. Мы выпустили корпус под лицензией, близкой к CC Attribution ShareAlike, что позволяет его использовать как для научных исследований, так и в коммерческих целях. Я расскажу о том, из чего состоит датасет, каким образом он был собран и каких результатов позволяет достичь.
Структура датасета Golos
Создавая датасет, мы руководствовались желанием решить проблему холодного старта, когда данные от реальных пользователей ещё отсутствовали. Именно это в конечном итоге позволило сделать его общедоступным, так как речи реальных пользователей там нет.
Аудиозаписи в датасете собраны из двух источников. Первый источник – это краудсорсинговая платформа, поэтому мы называем его Crowd-домен. Второй источник – записи, созданные в студии с помощью целевого устройства SberPortal. В нём особая система микрофонов, и это одно из устройств, на котором должно работать наше распознавание речи.
Мы называем этот источник Farfield-домен, так как расстояние от пользователя до устройства обычно достаточно большое. Для записи через SberPortal в студии мы использовали три расстояния: 1, 3 и 5 метров от пользователя до устройства. В каждом домене выделена тренировочная и тестовая часть, полученная структура приведена в таблице:
| Домены | Тренировочная часть | Тестовая часть |
|---|---|---|
| Crowd | 979 796 файлов | 1095 часов | 9994 файлов | 11.2 часов |
| Farfield | 124 003 файлов | 132.4 часов | 1916 файлов | 1.4 часов |
| Итого | 1 103 799 файлов | 1227.4 часов | 11910 файлов | 12.6 часов |
В датасете нет никакой персональной информации, такой как возраст, пол или ID пользователя — всё обезличено. В тренировочной и тестовой частях может встречаться речь одного и того же пользователя.
| Статистика \ Домены | Crowd | Farfield |
|---|---|---|
| Количество | 979796 файлов | 124003 файлов |
| Среднее | 4.0 сек. | 3.8 сек. |
| Стандартное отклонение | 1.9 сек. | 1.6 сек. |
| 1-й перцентиль | 1.4 сек. | 2.0 сек. |
| 50-й перцентиль | 3.7 сек. | 3.5 сек. |
| 95-й перцентиль | 7.3 сек. | 6.8 сек. |
| 99-й перцентиль | 10.5 сек. | 9.6 сек. |
Выше в таблице приведена некоторая статистическая информация о записях: среднее значение, стандартное отклонение и перцентили. На рисунке для наглядности – две гистограммы распределения длин записей:
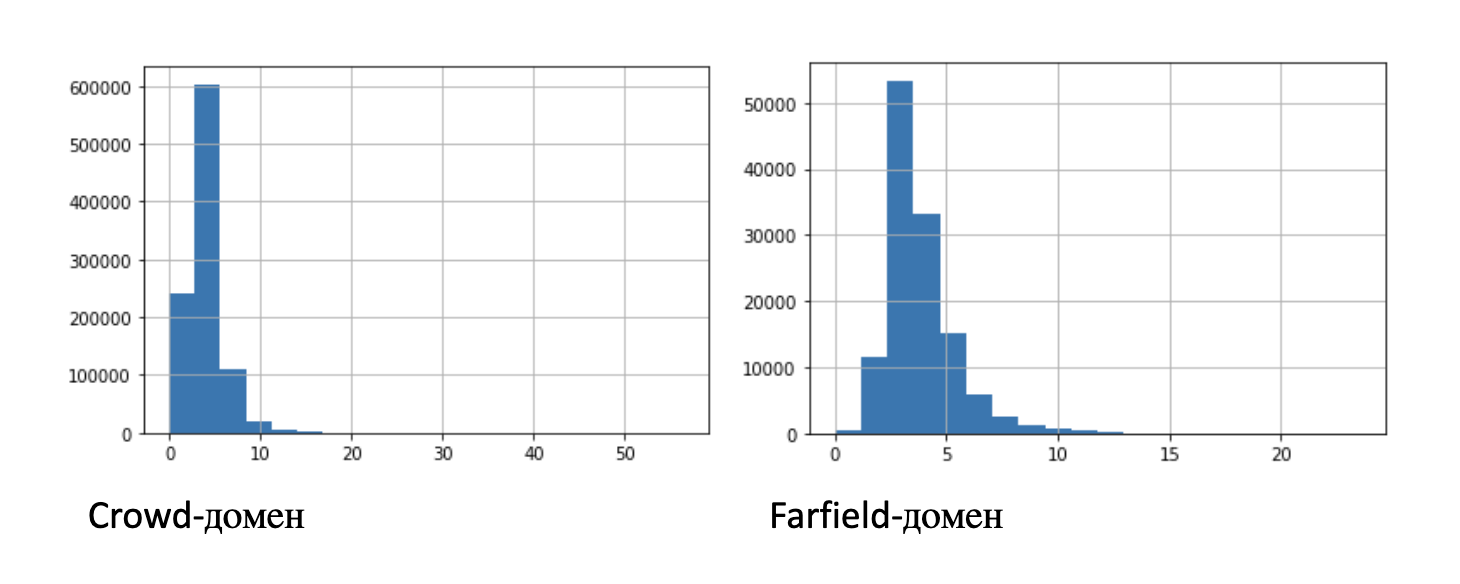
Для экспериментов с ограниченным числом записей мы выделили подмножества меньшей длины: 100 часов, 10 часов, 1 час, 10 минут.
Сбор данных
В SberDevices мы разрабатываем семейство виртуальных ассистентов Салют, поэтому генерировали речь, похожую на запросы пользователей к ассистенту. Для описания запросов в различных доменах – музыке, фильмах, заказе продуктов и других – мы создали систему шаблонов. Они представляют собой выражения, которые описывают структуру запроса и раскладывают его на компоненты. По шаблонам мы можем генерировать разумные запросы, дообучать акустическую модель, создавать по этим запросам языковую модель и многое другое.
Пример шаблонов:
| Шаблон | Пример |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Включи фильм зелёная книга |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | У тебя есть фильм зелёная книга |
| [command_demands_ip] + [film_title_ip] | У тебя есть зелёная книга |
| [film_title_ip] + [command_demands_vp] | зелёная книга поставь |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | фильм зелёная книга поставь |
| [film_title_ip] | зелёная книга |
| [command_demands_vp] + [film_title_ip] | включи зелёная книга |
| [film_syn_ip] + [film_title_ip] | фильм зелёная книга |
| [command_demands_vp] + [film_title_ip] | Включи зелёную книгу |
| ... | ... |
В квадратных скобках – обозначение соответствующей сущности. Далее в таблице для двух сущностей “film_title_ip” и “film_title_vp” проставлены возможные варианты её заполнения:
| film_title_ip | film_title_vp |
|---|---|
| одержимость | одержимость |
| побег | побег |
| красавица и чудовище | красавицу и чудовище |
| остров | остров |
| джейн эйр | джейн эйр |
| грозовой перевал | грозовой перевал |
| ... | ... |
Процесс создания размеченного аудио-датасета состоит из нескольких этапов:
- Шаг 1. Сначала мы создаём шаблоны для некоторого домена.
- Шаг 2. Затем по этим шаблонам мы генерируем какое-то количество текстовых запросов. Если мы работаем с доменом запросов по фильмам и мультфильмам, то они могут выглядеть так:
запусти забавную мордашку
вне правил
запусти в глубине
ежик в тумане
можешь показать кино чернобыль зона отчуждения
включи фильм расемон
покажи кино рабыня изаура
покажи фильм про фому и про ерему
найти киноленту робин гуд мужчины в трико
включи мне альфред хичкок представляет
кинолента у каждого своя ночь - Шаг 3. Пользователи краудсорсинговой платформы разметки «наговаривают» в свои устройства предлагаемые текстовые запросы:
- Шаг 4. Следующий шаг – транскрибация, когда другие разметчики прослушивают записанные другими людьми аудиозаписи и вводят текст, который на них слышат. Допустимые символы – кириллические буквы и пробел. Таким образом было размечено более 80% датасета Golos. Мы можем доверять результатам разметки благодаря тому, что используем систему “ханипотов”, когда в пул разметки подмешиваются задания, для которых мы заранее знаем верный ответ. Если качество работы исполнителя не соответствует нашим стандартам, мы закрываем ему доступ к разметке, а уже выполненные им задания отправляем на переразметку другому человеку.
- Шаг 4*. В какой-то момент, при сборе данных на музыкальную тематику, мы поняли, что они слишком сложны для того, чтобы их транскрибировать, полагаясь исключительно на слух, поэтому мы модифицировали наш подход к разметке. Сначала другие разметчики проверяют, что на записанной аудиозаписи действительно озвучен желаемый текст. Каждая запись показывается пяти разным людям, и, если хотя бы один из них ответил, что текст не совпадает с фразой, произнесённой на записи, то мы отбрасываем такую запись. Аналогично предыдущему пункту, мы валидируем качество разметки с помощью ханипотов.

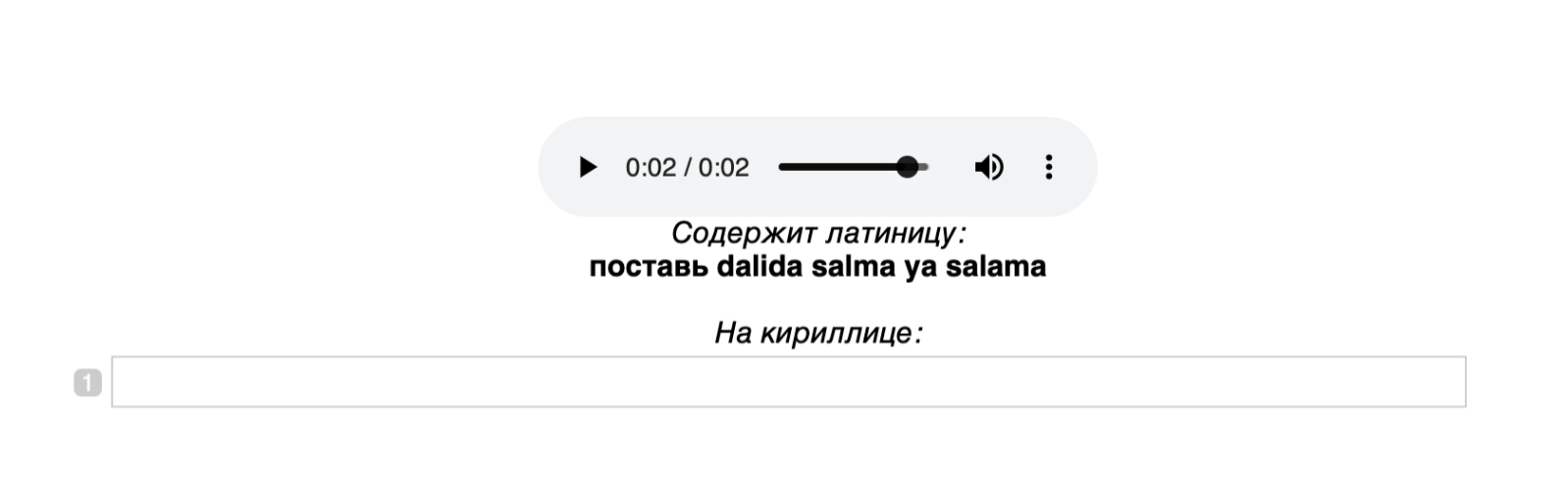
- Шаг 5*. Продолжение разметки сложных записей, таких как музыкальные запросы. Мы хотим, чтобы наш корпус состоял исключительно из кириллических букв и пробелов. Многие из запросов, впрочем, содержат латиницу и диакритические знаки, числа и другие символы. Для того, чтобы избавиться от таких символов, но сохранить данные, мы вновь прибегаем к платформе разметки. Разметчикам предоставляется исходный текст запроса, который может содержать любые символы, и соответствующая аудиозапись, которая была отвалидирована на предыдущем шаге. Они записывают текст запроса, используя только кириллические символы и пробелы. Таким образом разметчики видят задание:

А так выглядит задание после выполнения:
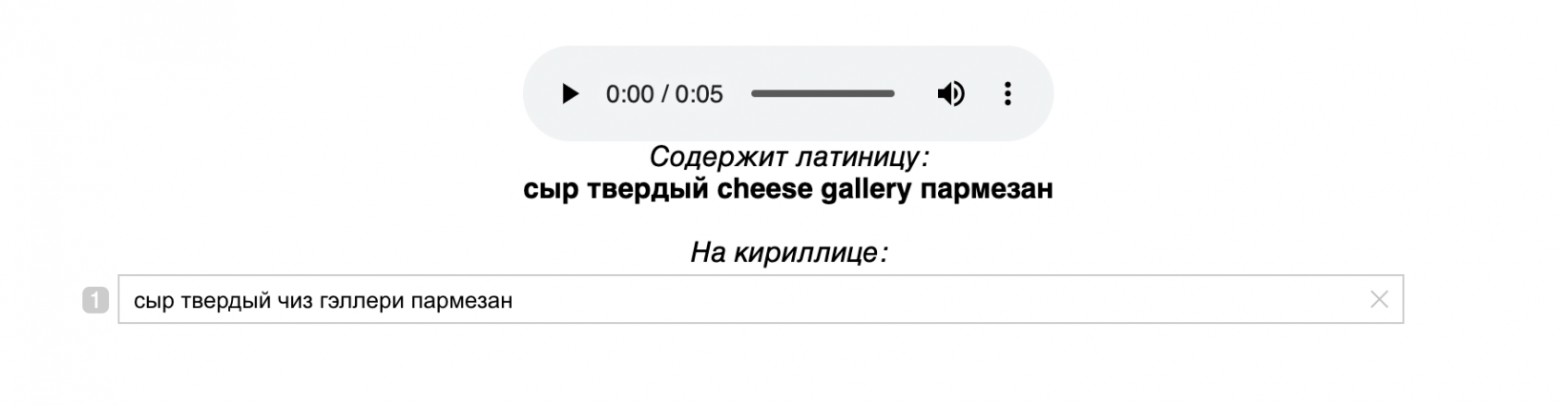
Для нас оказалось крайне важным предоставлять на этом этапе не только аудио, но и исходный текст. Для некоторых записей эта визуальная подсказка очень полезна и помогает лучше воспринимать аудиозапись.
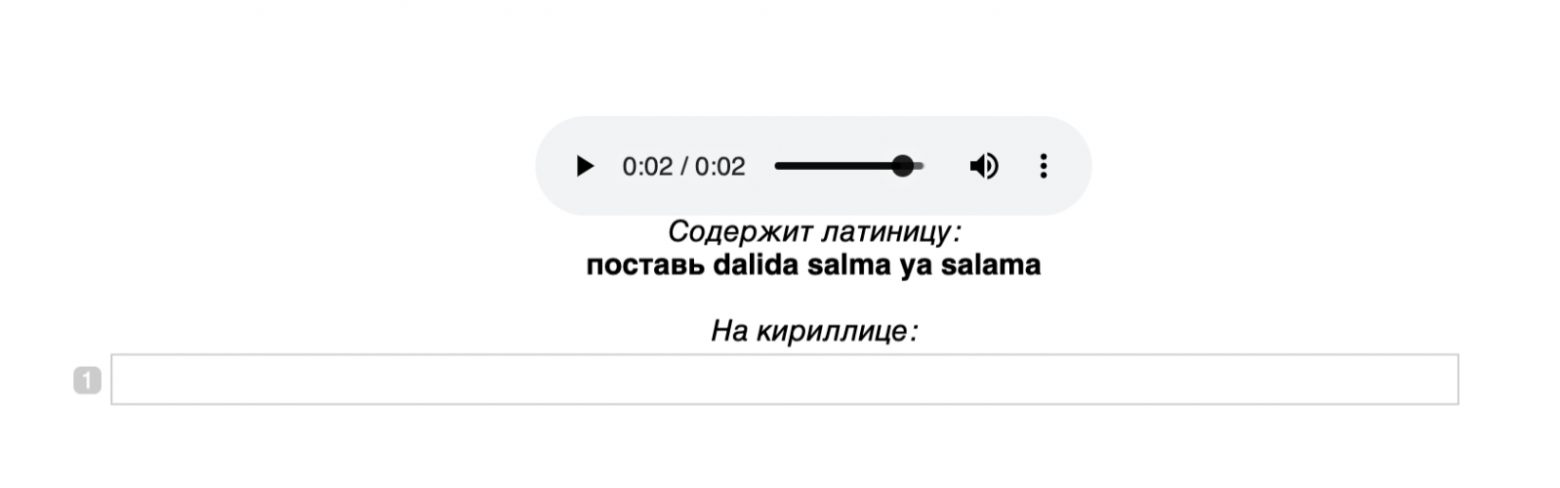
Если текст на латинице не совпадает с тем, что произносится на записи, разметчик указывает то, что слышит на аудиозаписи.
Каждую пару аудио-текст мы показываем 5 разметчикам и смотрим на самую популярную получившуюся транскрипцию на кириллице. Если хотя бы 3 разметчика указали эту транскрипцию, мы используем её как верную при обучении акустической модели.
Такая модификация процесса разметки из простой транскрибации в транскрибацию с подсказкой позволила нам добиться двух важных результатов. Во-первых, сильно повысилась согласованность разметчиков, поскольку им стало намного легче выполнять задание. Во-вторых, по этой же причине значительно увеличилась скорость выполнения заданий. Качество разметки гарантируется благодаря использованию системы ханипотов, которую я описал выше.
Впрочем, важно понимать, что предоставление “подсказки” при транскрибации – хорошая идея лишь тогда, когда мы знаем “идеальную” транскрипцию запроса и хотим каким-то образом её модифицировать. Например, в этой ситуации мы обладали текстом, содержащим латиницу, а также соответствующей этому тексту аудиозаписью (что было проверено в предыдущем пункте пайплайна) и хотели перевести транскрипцию в целиком кириллическую. Предоставление подсказки вносит bias в мышление разметчика, так что он на самом деле начинает слышать то, что указано в ней. Именно поэтому такой подход очень хорошо показал себя в нашем пайплайне, базирующемся на синтетических текстовых данных. В то же время он опасен при использовании на потоковых данных с устройств, когда может показаться заманчивым предоставление в качестве подсказки гипотезы системы распознавания речи.


Описанный процесс создания датасета позволяет сделать разметку максимально качественно, что отличает его от других, созданных автоматически или полуавтоматически. Эти данные мы используем для создания системы распознавания речи в наших устройствах. Благодаря высокому качеству разметки, точность полученной системы сравнима с человеческой. Все данные, вместе с обученными акустической и языковой моделями для распознавания речи, доступны на странице проекта на GitHub, а также в ML Space от Sbercloud, сервисе для обучения моделей машинного обучения, где наш датасет можно бесшовно скачать прямо в интерфейсе. Подробнее об использовании ML Space и о том, как мы с его помощью учили модели распознавания речи, мы расскажем в следующей статье.
В настоящее время существует масса открытых данных на английском языке, но такого качественного русскоязычного датасета не было. Теперь же и на русском языке доступен корпус, который можно использовать для распознавания и синтеза речи, а обученная на них модель показывает очень высокое качество. Мы верим, что датасет Golos даст возможность научному сообществу России двигаться ещё быстрее в совершенствовании русскоязычных речевых технологий.
