Известно, что глубокие нейронные сети (DNN) и модели компьютерного зрения, в частности, хорошо справляются с конкретными задачами, но зачастую не могут сделать обобщение при работе с новыми. Так, модель, которая хорошо работает с данными о продуктах питания, может показать себя не очень хорошо на спутниковых изображениях и т. д..
В начале этого года OpenAI опубликовала модель под названием CLIP (Contrastive Language–Image Pre-training). В статье авторы модели привели потрясающие результаты по точности zero-shot-классификации изображений, а также сопоставили тексты и картинки в рамках одной системы. Однако модель OpenAI работает только с английским языком. Можно ли быстро адаптировать её для работы с русским?
Команды R&D SberDevices и Sber AI увлеклись этим вопросом. В этой статье мы расскажем про первые результаты наших исследований CLIP для русского языка, опишем ключевые идеи предложенной модели и поделимся с вами кодом для её использования — решения задач zero-shot image classification.
Что же можно сделать с помощью ruCLIP?
Интуиция
В типичном сценарии классификации есть набор примеров, связанных с набором заранее определённых категорий. В таком наборе количество категорий фиксировано. Если вы обучаете модель различать кошек и собак, а затем решите добавить новый класс «медведь», вам придётся добавить примеры изображений с медведями и обучить новую сеть! Конечно, такие сети обучаются не с нуля, а дотюниваются – отрезается последний полносвязный слой (или несколько слоёв) и добавляется новый, соответствующий новому набору категорий; затем такая модифицированная сеть дообучается классифицировать новые объекты. Тем не менее, и сбор фотографий нового класса, и дообучение сети часто оказываются дорогостоящими операциями (и по времени, и по ресурсам), поэтому являются своего рода узким горлышком для масштабирования такого подхода.
Однако, если удастся создать нейронную сеть, которая будет обучена измерять схожесть произвольного изображения и произвольного текста, то её можно будет использовать с любым набором новых классов без дообучения. Действительно, для заданного изображения будет достаточно просто предоставить текстовое описание классов, посчитать близость каждого описания к изображению, а затем выбрать наиболее близкое описание (класс). Конечно, чтобы это работало успешно, сеть должна научиться хорошим визуальным представлениям и хорошим связям между визуальными образами и текстом.
Как работает CLIP?
CLIP — это модель, состоящая из двух частей (или нейронных сетей):
Image Encoder — часть для кодирования изображений и перевода их в общее векторное пространство. В качестве архитектуры в оригинальной работе берутся ResNet разных размеров и Visual Transformer — тоже разных размеров.
Text Encoder — часть для кодирования текстов и перевода их в общее векторное пространство. В качестве архитектуры в оригинальной работе используется небольшой текстовый Transformer.
Авторы CLIP сообщают, что они собрали набор данных из 400 миллионов пар (изображение, текст) из интернета. Каждая такая пара подается на вход этой нейронной сети, объединяясь в batch с другими аналогичными парами. Учитывая batch из N пар (изображение, текст), CLIP обучен предсказывать, какие из N × N возможных пар (изображение, текст) в пакете действительно соотносятся друг с другом (Рисунок 1). Для этого CLIP выучивает мультимодальное пространство путём совместного обучения Image Encoder и Text Encoder, чтобы максимизировать косинусную близость эмбеддингов изображения и текста N-реальных пар в batch-е и минимизировать косинусную близость эмбеддингов N2 − N неправильных пар. Авторы оптимизируют симметричную кросс-энтропийную функцию потерь над полученными оценками близости.

Во время инференса на основе выбранного набора классов создаётся текст (описание), который затем подаётся на вход Text Encoder. Эмбеддинги текста затем сопоставляются с эмбеддингами изображения, полученными с помощью Image Encoder (Рисунок 2). Выбирается то описание, эмбеддинг которого наиболее близок к эмбеддингу изображения с точки зрения косинусного расстояния.

Обычно классификация учитывает только предварительно определённые классы. Если она находит на картинке собаку, то ей всё равно, будет ли это фотография или набросок собаки и какой конкретно породы. В то время как обучение CLIP в сочетании с большим набором данных заставляет сеть изучать различные аспекты изображений и обращать внимание на детали. Благодаря тому, что лейблы не превращаются в стандартные категориальные переменные (то есть не заменяются на цифры или one-hot encoding векторы), модели удаётся извлечь из них семантическую информацию.
CLIP для русского языка
Изучив оригинальную работу CLIP, мы решили, что хотим создать аналогичную модель для русского языка. Это помогло бы не только нам, но и русскоязычному сообществу в решении задач, связанных с рассматриваемой темой.
Чтобы не начинать работу с нуля, мы решили взять выложенную OpenAI модель CLIP и дообучить её для русского языка. В качестве Image Encoder мы взяли ViT-32 (самая большая модель из выложенных), а в качестве Text Encoder – ранее выложенную нами модель RuGPT3Small. После чего заморозили веса Image Encoder, добавили 2 линейных слоя после энкодеров. Остальное осталось как и прежде. Наша архитектура представлена на Рисунке 3.

Дообучение модели для русского языка происходило на собранных нами датасетах. Вот некоторые из них:
ImageNet — переведённый на русский язык;
Flickr — картинки с русскими описаниями с фотостока;
Ru-wiki — часть картинок из русской Википедии с описаниями.
Всего около 3 млн уникальных пар «картинка-текст». Модель ruCLIP доступна для использования в нашем репозитории. Она обучалась около 5 дней на 16 Tesla GPU V100 с размером batch-а 16 и длиной последовательности 128 для RuGPT3Small Text Encoder на ML Space.
Оценка и использование ruCLIP
Пример использования и загрузки нашей модели для google-colab можно найти тут.
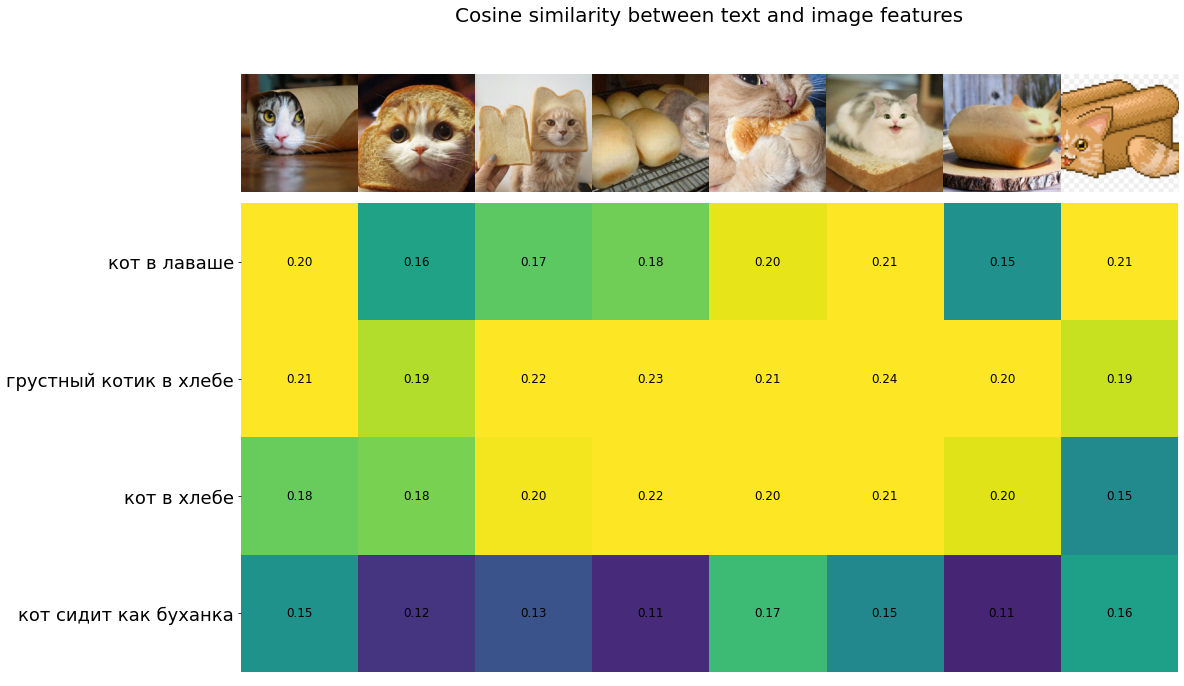
Мы взяли для тестирования те же картинки, что и OpenAI в своём ноутбуке, когда выкладывали модель. Вот так выглядит близость изображений и текстов, взятых из примера:

Также мы проверили на этих картинках способность модели к zero-shot-классификации (Рисунок 5). Для этого мы использовали классы из датасета CIFAR100, переведённые на русский язык.

Также мы измерили точность zero-shot-классификации на датасетах CIFAR10 и CIFAR100.
Top-1 accuracy на нашей модели ruCLIP наборе данных CIFAR100– 0.4057, top-5 accuracy – 0.6975. На Рисунке 6 представлено распределение точности для каждого класса для данного набора данных. Из него можно понять, что модель не видела довольно много изображений классов, однако есть классы, для которых точность zero-shot-классификации превышает 0.7.

Для набора данных CIFAR10 top-1 accuracy – 0.7803 и top-5 accuracy – 0.9834. На Рисунке 7 представлено распределение точности для каждого класса для данного набора данных:

Что дальше?
Будем развивать исследования на стыке CV + NLP и в ближайшее время планируем обучить модель ruCLIP уже большего размера, в том числе со своим энкодером изображений. Будем рады предложениям в комментариях по открытым источникам изображений.
Для чего ещё можно использовать модель?
Мы пробуем ранжировать с помощью ruCLIP «похожесть» оценочного запроса и картинок: на примерах ниже модель отранжировала мемы по степени их близости к запросу «смешной мем». Спойлер: самый смешной — почтальон Печкин.

Самая красивая картина с точки зрения модели — «Портрет госпожи Лизы дель Джокондо» Леонардо да Винчи.

Стоит сделать последовательный шаг в сторону состязательной проверки знаний таких моделей. Смогут ли они отличить животных различных видов, лица с разными эмоциями, виды растений?
Исследование ограничений мультимодальных систем — новое важное направление, отмечаемое и самими создателями CLIP: точность определения объектов на картинке может неожиданно падать при небольших изменениях текстового описания. В исследовании OpenAI добавление класса «ребёнок» понижало качество классификации фотографий людей с 32.3% до 8.7%!
Как будут выглядеть новые тесты для таких ранжирующих моделей, какие качества они будут сочетать? В скором времени нам предстоит это выяснить. Делитесь своими идеями в комментариях — мы открыты к обсуждению, а также всегда рады конструктивной критике :)
Код использования и экспериментов можно найти в нашем репозитории.

